当前位置:网站首页>Fluentd is easy to use. Combined with the rainbow plug-in market, log collection is faster
Fluentd is easy to use. Combined with the rainbow plug-in market, log collection is faster
2022-07-03 06:08:00 【xuhss_ com】
High quality resource sharing
| Learning route guidance ( Click unlock ) | Knowledge orientation | Crowd positioning |
|---|---|---|
| 🧡 Python Actual wechat ordering applet 🧡 | Progressive class | This course is python flask+ Perfect combination of wechat applet , From the deployment of Tencent to the launch of the project , Create a full stack ordering system . |
| Python Quantitative trading practice | beginner | Take you hand in hand to create an easy to expand 、 More secure 、 More efficient quantitative trading system |

There was an article about EFK(Kibana + ElasticSearch + Filebeat) Plug in log collection .Filebeat The plug-in is used to forward and centralize log data , And forward them to Elasticsearch or Logstash To index , but Filebeat As Elastic A member of the , Only in Elastic Used throughout the system .
Fluentd
Fluentd It's an open source , Distributed log collection system , From different services , Data source collection log , Filter logs , Distributed to a variety of storage and processing systems . Support for various plug-ins , Data caching mechanism , And it requires very few resources , Built in reliability , Combined with other services , It can form an efficient and intuitive log collection platform .
This article is introduced in Rainbond Use in Fluentd plug-in unit , Collect business logs , Output to multiple different services .
One 、 Integration Architecture
When collecting component logs , Just open in the component Fluentd plug-in unit , This article will demonstrate the following two ways :
- Kibana + ElasticSearch + Fluentd
- Minio + Fluentd
We will Fluentd Made into Rainbond Of General type plug-ins , After the app starts , The plug-in also starts and automatically collects logs for output to multiple service sources , The whole process has no intrusion into the application container , And strong expansibility .
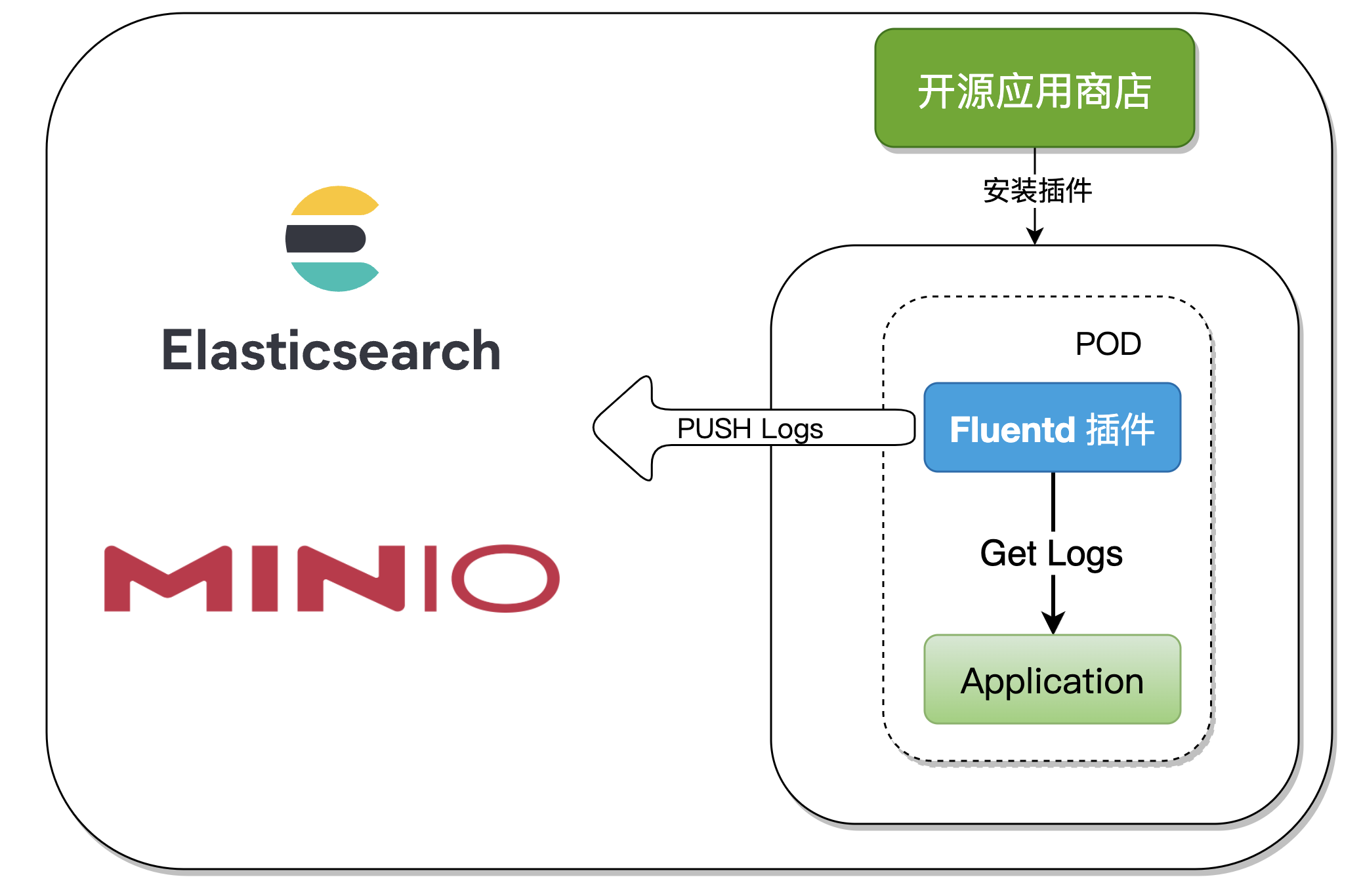
Two 、 Plug in principle analysis
Rainbond V5.7.0 There's a new : Install plug-ins from the open source app store , The plug-ins in this article have been released to the open source app store , When we use it, we can install it with one click , Modify the configuration file as required .
Rainbond The plug-in architecture is relative to Rainbond Part of the application model , The plug-in is mainly used to realize the application container extension operation and maintenance capability . The implementation of operation and maintenance tools has great commonality , Therefore, the plug-in itself can be reused . The plug-in must be bound to the application container to have runtime state , To realize an operation and maintenance capability , For example, performance analysis plug-ins 、 Network governance plug-in 、 Initialize the type plug-in .
In the production Fluentd In the process of plug-in , Using the General type plug-ins , You can think of it as one POD Start two Container,Kubernetes Native supports a POD Start multiple Container, But the configuration is relatively complex , stay Rainbond The plug-in implementation in makes the user operation easier .
3、 ... and 、EFK Log collection practices
Fluentd-ElasticSearch7 The output plug-in writes log records to Elasticsearch. By default , It uses batch API Create record , The API In a single API Call to perform multiple index operations . This reduces overhead and can greatly improve indexing speed .
3.1 Operation steps
application (Kibana + ElasticSearch) And plug-ins (Fluentd) Can be deployed with one click through the open source app store .
- Connect with the open source app store
- Search the app store for
elasticsearchAnd install7.15.2edition . - Team view -> plug-in unit -> Install from the app store
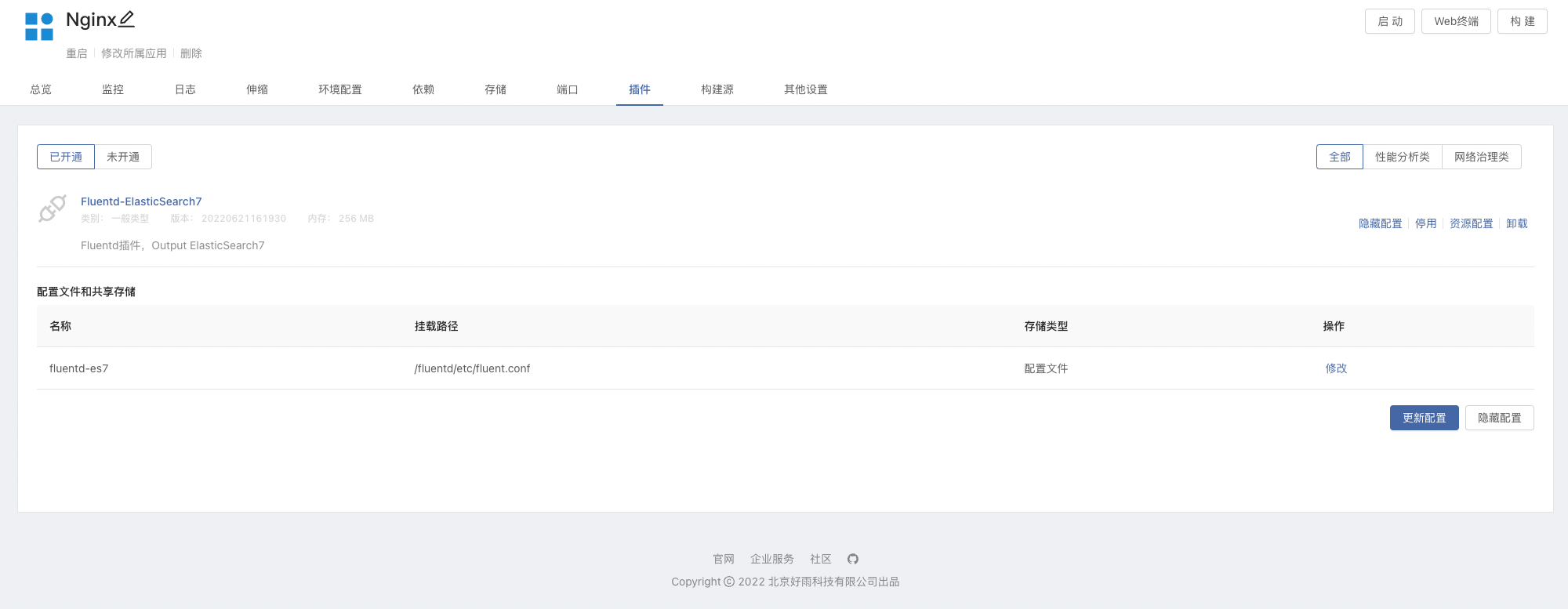
Fluentd-ElasticSearch7plug-in unit - Create components based on images , Mirror usage
nginx:latest, And mount storagevar/log/nginx. Use hereNginx:latestAs a demonstration- After the storage is mounted in the component , The plug-in will also mount the storage on its own , And access to Nginx Generated log files .
- stay Nginx Open plug-ins in the component , It can be modified as needed
FluentdThe configuration file , Refer to the profile introduction section below .
- add to ElasticSearch rely on , take Nginx Connect to ElasticSearch, Here's the picture :
- visit
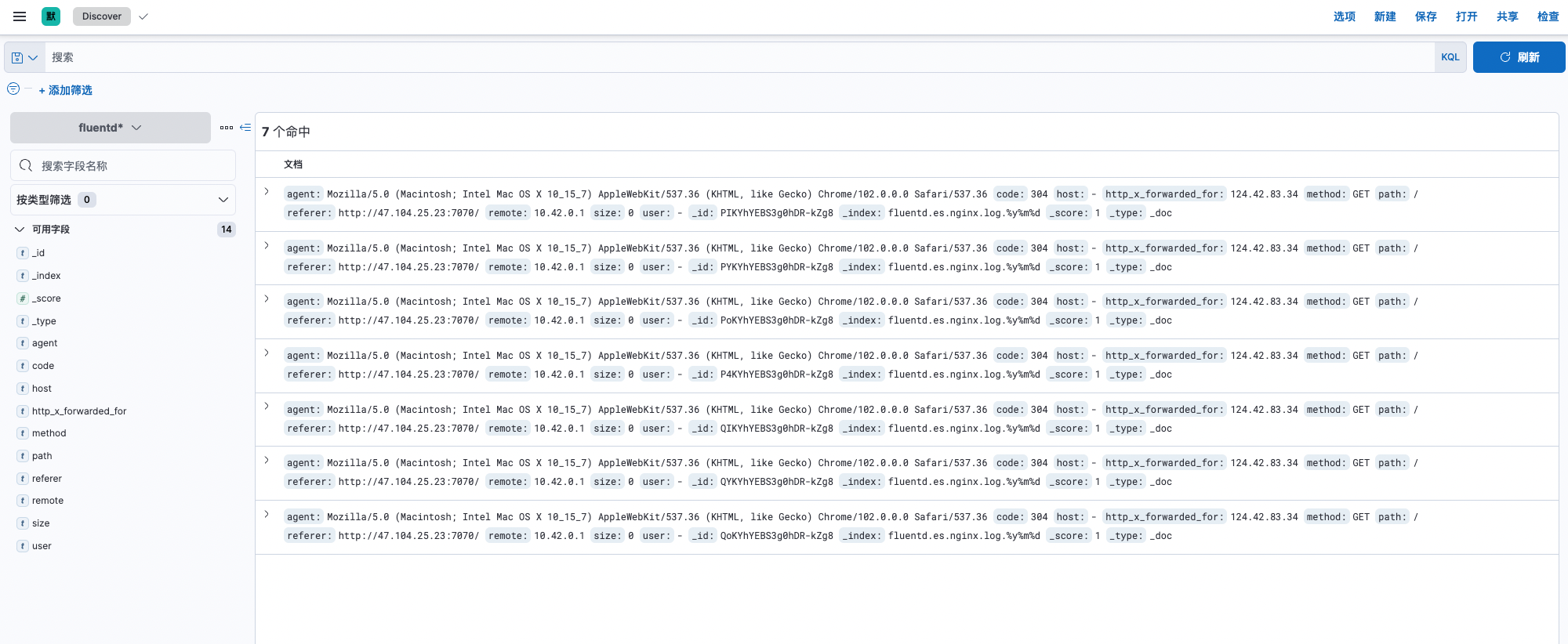
Kibanapanel , Enter into Stack Management -> data -> Index management , You can see that the existing index name isfluentd.es.nginx.log, - visit
Kibanapanel , Enter into Stack Management -> Kibana -> Index mode , Create index mode . - Enter into Discover, The log is displayed normally .
3.2 Profile Introduction
Profile reference Fluentd file output_elasticsearch.
@type tail
path /var/log/nginx/access.log,/var/log/nginx/error.log
pos_file /var/log/nginx/nginx.access.log.pos
@type nginx
tag es.nginx.log
@type elasticsearch
log\_level info
hosts 127.0.0.1
port 9200
user elastic
password elastic
index\_name fluentd.${tag}
chunk\_limit\_size 2M
queue\_limit\_length 32
flush\_interval 5s
retry\_max\_times 30
Configuration item explanation :
The input source of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | Collection log type ,tail Indicates that the log contents are read incrementally |
| path | Log path , Multiple paths can be separated by commas |
| pos_file | Used to mark the file that has been read to the location (position file) Path |
| Log format analysis , According to your own log format , Write corresponding parsing rules . |
The output of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | The type of service output to |
| log_level | Set the output log level to info; The supported log levels are :fatal, error, warn, info, debug, trace. |
| hosts | elasticsearch The address of |
| port | elasticsearch The port of |
| user/password | elasticsearch User name used / password |
| index_name | index The name of the definition |
| Log buffer , Used to cache log events , Improve system performance . Memory is used by default , You can also use file file | |
| chunk_limit_size | Maximum size of each block : Events will be written to blocks , Until the size of the block becomes this size , The default memory is 8M, file 256M |
| queue_limit_length | The queue length limit for this buffer plug-in instance |
| flush_interval | Buffer log flush event , Default 60s Refresh the output once |
| retry_max_times | Maximum number of times to retry failed block output |
The above is only part of the configuration parameters , Other configurations can be customized with the official website documents .
Four 、Fluentd + Minio Log collection practices
Fluentd S3 The output plug-in writes log records to the standard S3 Object storage service , for example Amazon、Minio.
4.1 Operation steps
application (Minio) And plug-ins (Fluentd S3) Can be deployed with one click through the open source application store .
Connect with the open source app store . Search the open source app store for
minio, And install22.06.17edition .Team view -> plug-in unit -> Install from the app store
Fluentd-S3plug-in unit .visit Minio 9090 port , The user password is Minio Components -> Get from dependency .
establish Bucket, Custom name .
Get into Configurations -> Region, Set up Service Location
- Fluentd In the configuration file of the plug-in
s3_regionThe default isen-west-test2.
- Fluentd In the configuration file of the plug-in
Create components based on images , Mirror usage
nginx:latest, And mount storagevar/log/nginx. Use hereNginx:latestAs a demonstration- After the storage is mounted in the component , The plug-in will also mount the storage on its own , And access to Nginx Generated log files .
Enter into Nginx In component , Opening Fluentd S3 plug-in unit , Modify... In the configuration file
s3_buckets3_region
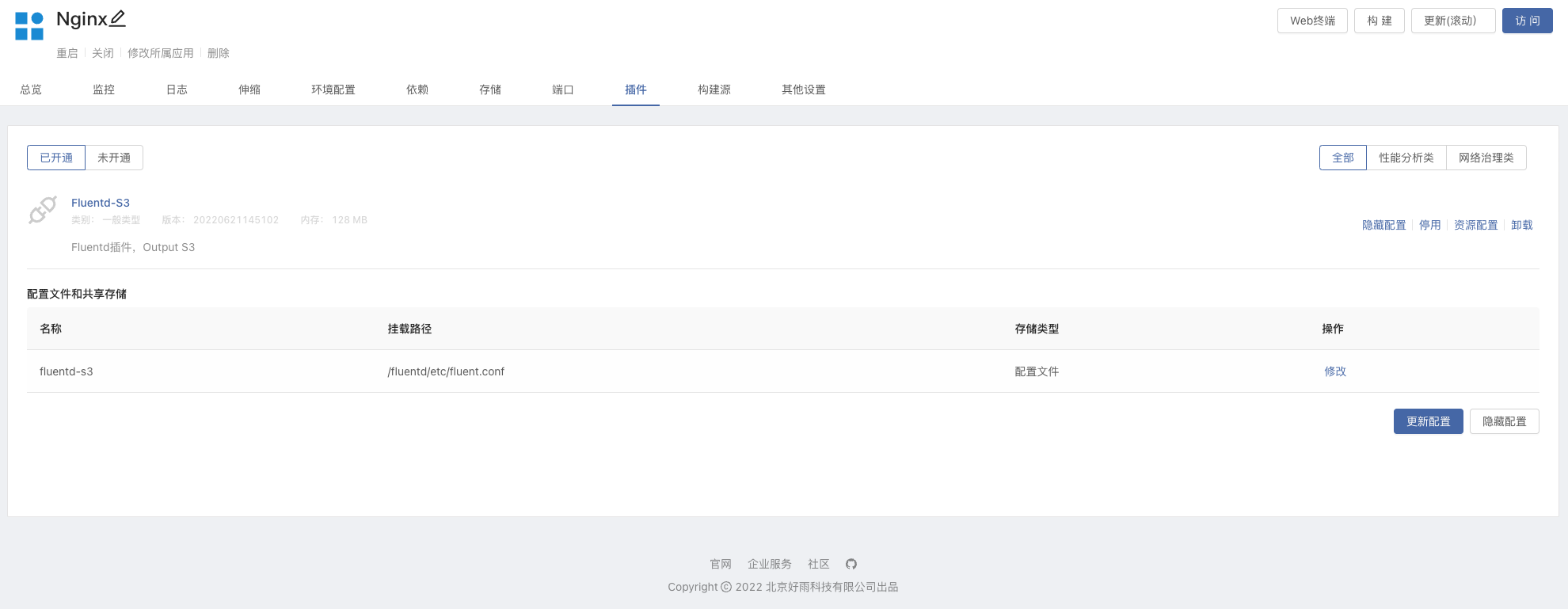
- Build dependencies ,Nginx Component dependency Minio, Update the component to make it effective .
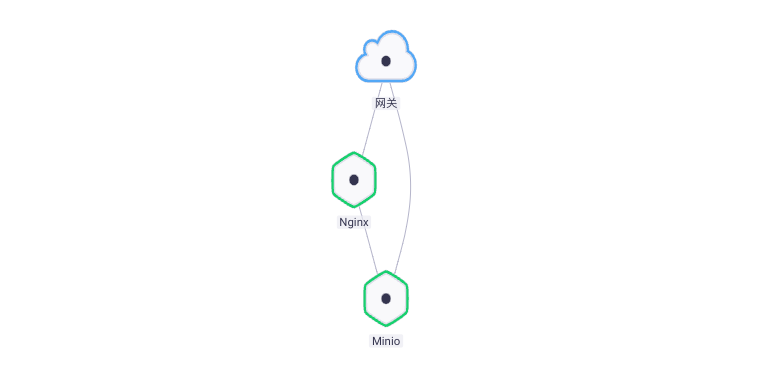
- visit Nginx service , Let it generate logs , In a moment, you can Minio Of Bucket see .

4.2 Profile Introduction
Profile reference Fluentd file Apache to Minio.
@type tail
path /var/log/nginx/access.log
pos_file /var/log/nginx/nginx.access.log.pos
tag minio.nginx.access
@type nginx
@type s3
aws\_key\_id "#{ENV['MINIO\_ROOT\_USER']}"
aws\_sec\_key "#{ENV['MINIO\_ROOT\_PASSWORD']}"
s3\_endpoint http://127.0.0.1:9000/
s3\_bucket test
s3\_region en-west-test2
time\_slice\_format %Y%m%d%H%M
force\_path\_style true
path logs/
@type file
path /var/log/nginx/s3
timekey 1m
timekey\_wait 10s
chunk\_limit\_size 256m
Configuration item explanation :
The input source of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | Collection log type ,tail Indicates that the log contents are read incrementally |
| path | Log path , Multiple paths can be separated by commas |
| pos_file | Used to mark the file that has been read to the location (position file) Path |
| Log format analysis , According to your own log format , Write corresponding parsing rules . |
The output of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | The type of service output to |
| aws_key_id | Minio user name |
| aws_sec_key | Minio password |
| s3_endpoint | Minio Access address |
| s3_bucket | Minio Bucket name |
| force_path_style | prevent AWS SDK Destroy endpoint URL |
| time_slice_format | Each file name is stamped with this time stamp |
| Log buffer , Used to cache log events , Improve system performance . Memory is used by default , You can also use file file | |
| timekey | Every time 60 Seconds to refresh the accumulated chunk |
| timekey_wait | wait for 10 Seconds to refresh |
| chunk_limit_size | Maximum size of each block |
Last
Fluentd The plug-in can flexibly collect business logs and output multiple services , And combine Rainbond One click installation in plug-in market , Make our use easier 、 quick .
at present Rainbond Open source plug-in application market Flunetd Plugins are just Flunetd-S3Flunetd-ElasticSearch7, Welcome to contribute plug-ins !
边栏推荐
- Detailed explanation of findloadedclass
- Loss function in pytorch multi classification
- Use telnet to check whether the port corresponding to the IP is open
- 88. 合并两个有序数组
- [teacher Zhao Yuqiang] Cassandra foundation of NoSQL database
- Jedis source code analysis (I): jedis introduction, jedis module source code analysis
- Apt update and apt upgrade commands - what is the difference?
- The programmer shell with a monthly salary of more than 10000 becomes a grammar skill for secondary school. Do you often use it!!!
- Understand the first prediction stage of yolov1
- [teacher Zhao Yuqiang] calculate aggregation using MapReduce in mongodb
猜你喜欢
![[function explanation (Part 2)] | [function declaration and definition + function recursion] key analysis + code diagram](/img/29/1644588927226a49d4b8815d8bc196.jpg)
[function explanation (Part 2)] | [function declaration and definition + function recursion] key analysis + code diagram
Maximum likelihood estimation, divergence, cross entropy

Clickhouse learning notes (2): execution plan, table creation optimization, syntax optimization rules, query optimization, data consistency

Kubernetes notes (10) kubernetes Monitoring & debugging

.NET程序配置文件操作(ini,cfg,config)
![[teacher Zhao Yuqiang] calculate aggregation using MapReduce in mongodb](/img/cc/5509b62756dddc6e5d4facbc6a7c5f.jpg)
[teacher Zhao Yuqiang] calculate aggregation using MapReduce in mongodb
Bio, NiO, AIO details

Oauth2.0 - explanation of simplified mode, password mode and client mode

智牛股--03
【系统设计】邻近服务
随机推荐
1. Sum of two numbers
Es remote cluster configuration and cross cluster search
Kubernetes notes (V) configuration management
BeanDefinitionRegistryPostProcessor
[function explanation (Part 2)] | [function declaration and definition + function recursion] key analysis + code diagram
Jedis source code analysis (II): jediscluster module source code analysis
Detailed explanation of iptables (1): iptables concept
[teacher Zhao Yuqiang] MySQL high availability architecture: MHA
It is said that the operation and maintenance of shell scripts are paid tens of thousands of yuan a month!!!
Get a screenshot of a uiscrollview, including off screen parts
Why should there be a firewall? This time xiaowai has something to say!!!
Solve the 1251 client does not support authentication protocol error of Navicat for MySQL connection MySQL 8.0.11
The programmer shell with a monthly salary of more than 10000 becomes a grammar skill for secondary school. Do you often use it!!!
[teacher Zhao Yuqiang] Cassandra foundation of NoSQL database
Clickhouse learning notes (I): Clickhouse installation, data type, table engine, SQL operation
理解 YOLOV1 第一篇 预测阶段
Crontab command usage
Pytorch builds the simplest version of neural network
Analysis of Clickhouse mergetree principle
Migrate data from Mysql to tidb from a small amount of data