当前位置:网站首页>基于 TiDB 场景式技术架构过程 - 理论篇
基于 TiDB 场景式技术架构过程 - 理论篇
2022-07-05 13:57:00 【TiDB社区干货传送门】
背景
从事数据架构多年,一直被问到一些问题,例如:what、why。
- what:产品的数据架构是怎样的
- why:为什么是怎样的,选型依据是怎么样的
我一直回答不好这个问题,一是因为从研发转向数据架构规划,自己一直处在学习中,二是解决的问题,在问题发生时都没有可参考的大厂经验,也是处在摸索阶段。最近数据架构逐渐稳定,从 TiDB 社区活动中也受益颇多,做了很多数据架构的思考,借着 6.0 的发布,谈一下自己总结的数据技术架构方法,通过一个案例,场景式展现整个设计过程。通过本文的一些描述,希望能够给初步踏上架构选型之路上的同学们一些帮助。
声明
数据架构的选型需要参考的因素很多,因能力有限,本文所述只是基于作者视角做的一些总结、分享,如有常识性错误,请及时通知作者修改。 本文是从整体架构过程中,抽取数据架构有关的过程做分析,作为企业级架构过程参考可能有所不足。 本文是一个架构理论总结,其 POC 过程尽量还原真实情况,可能存在疏漏,仅供参考。
数据架构的一般过程
总结我司多年的经验,数据架构的一般过程如下:
- 架构需求分析
- 技术产品选型
- POC 设计与测试
- 整体架构设计
各阶段输入 / 输出如下:
| 阶段 | 输入 | 输出 |
|---|---|---|
| 架构需求分析 | 系统需求说明书 | 技术需求矩阵、架构权衡点 |
| 技术产品选型 | 权衡点矩阵 | 备选产品清单 |
| POC 设计与测试 | 备选产品清单 | POC 场景设计、POC 验证结果 |
| 整体架构设计 | POC 验证结果 | 数据架构设计说明书 |
本文遵从上述数据架构设计的一般过程,从实际项目抽象一个典型的项目作为模板,叙述上述过程的具体实践。
架构需求分析
架构需求分析一般从系统需求说明书入手,本节抽取系统需求说明书中的一分部内容说明,最后形成技术需求矩阵、架构权衡点。
企业组织架构
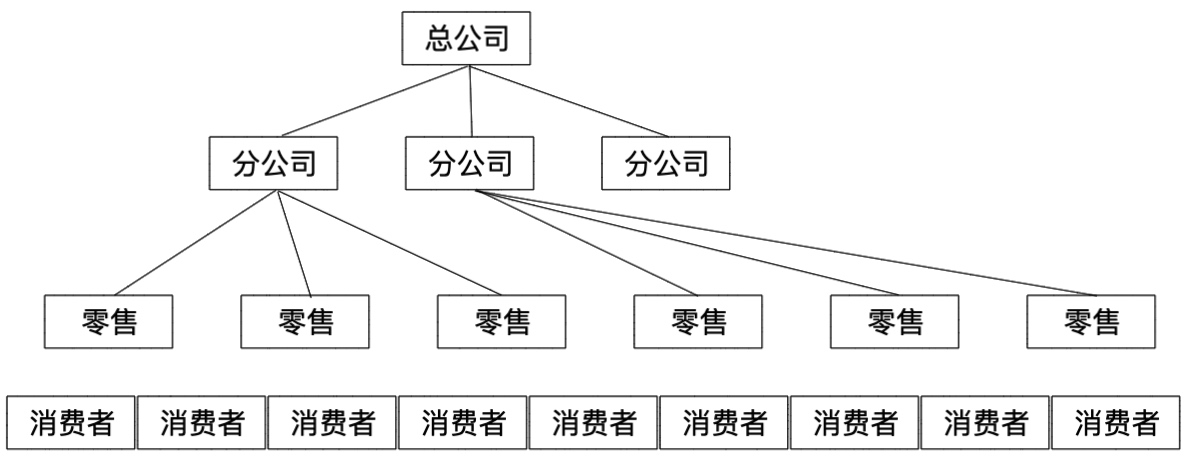
组织说明:
- 总公司:管理主体,对系统的主要诉求是浏览器端的各层级管理报表,实时大屏需求。
- 分公司:实际的经营主体,对系统的主要诉求是浏览器端的实时管理报表,实时大屏,模型分析需求、标签。通过模型分析评价专卖店的运行情况,发现风险,通过标签分析本省或者本地区消费者的消费偏好,管理本省或者本地区营销活动。
- 零售:分为店长端和店员端应用,店长端主要通过微信小程序浏览本店实时交易报表、管理库存、管理活动 / 折扣,店员端主要通过桌面端完成商品销售。
- 消费者:消费者通过微信小程序完成附件店铺寻找、商品预览、活动预览等功能。
组件规划与特性分析
抽象上述各组织产品需求,设计模块如下: 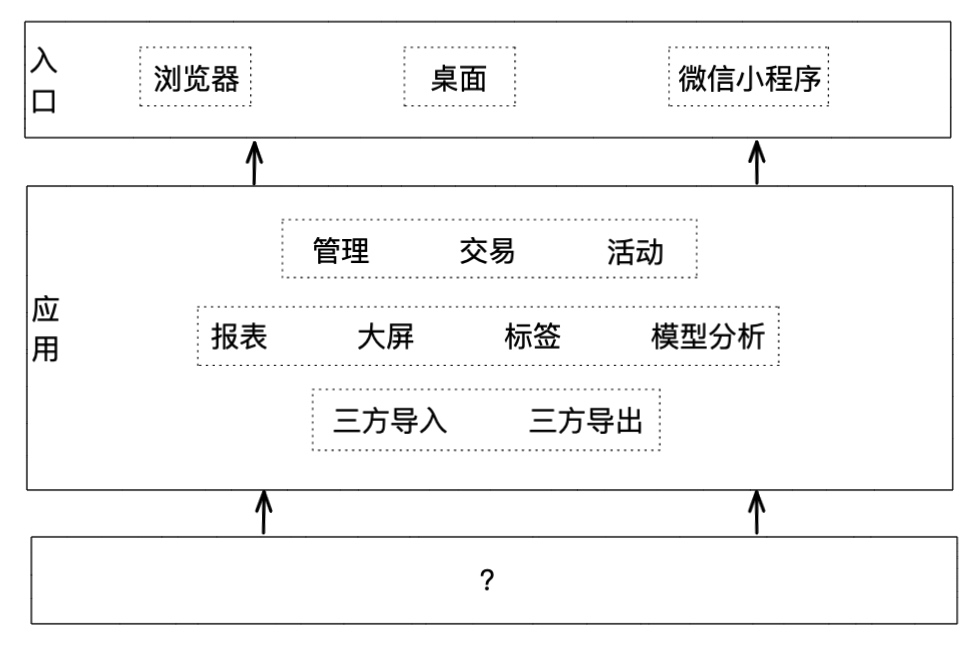 应用模块技术需求分析:
应用模块技术需求分析:
- 交易型应用:管理、交易、活动;强事务、高并发,活动开展时存在热点商品问题,此类功能相对固定,需求变更不多,但稳定性要求极高
- 分析型应用:报表、大屏、标签、模型分析;低延迟、实时在线分析、海量离线计算,此类功能需求多,需求变更多,工作量占比在 80%,要求极度灵活的报表组织能力和数据分析能力
- 接口型应用:应对第三方交易对接,接受或者输出实时、批量销售库存信息,此类功能遵循一个稳定的接口规范,变更较少,但要考虑流量消峰、数据审计、传输补偿等安全问题,技术比较复杂
根据咨询公司数据反馈,专卖店日均销售笔数为 60 笔,专卖店中的旗舰店,日均交易超过 1200 笔。单日估计最大订单数量 1000 万,即订单表单日存储数据量约 1000 万,一年的订单表数据 36 亿,按照以前的项目经验,仅估算交易数据,项目整体数据量一年约 72 亿。
非功能性约束:
- 交易功能响应时间小于 1 秒,针对网络短暂不稳定的情况,需提供解决方案。管理应用响应时间小于 3 秒,分析型应用小于 3 秒
- 需符合当前主流安全标准(非本文描述范围,也较为敏感,简单处理)
- 实时分析需能查询三年以内的交易明细数据,3 年之外的交易数据可以做归档处理。归档数据需能够再次读取
- 兼容目前主流云平台部署,可以实现基于云的弹性伸缩
硬件采购约束:
- 硬件部署在自建机房
- 硬件设备需按需投入,分阶段投入
- 本次建设暂不考虑多中心设计
- 基于成本原因,优先采用开源产品
技术需求矩阵
根据组织需求和产品模块设计,转化为对技术组件的需求:
| 组织级别 | 报表 | 大屏 | 模型分析 | 标签 | 管理 | 销售 | 活动 |
|---|---|---|---|---|---|---|---|
| 总公司 | OLAP T+1 | OLAP T+1 | |||||
| 分公司 | OLAP 实时 | OLAP 实时 | 离线计算、OLAP T+1 | 离线计算、全文搜索 | OLTP | ||
| 专卖店 | OLTP | OLTP、高速缓存 | OLTP | ||||
| 消费者 | LBS | OLTP、高速缓存 |
客户背景分析
客户方属于成本敏感性一般的企业,对高端硬件的投入以实际需求为主,年初预算、年中采购、年末审计。客户方有独立的信息部门,但技术能力较弱,没有技术储备,信息部门的负责人思路较为超前,对新技术有较多了解,愿意采用较为先进的技术解决问题。
研发团队背景分析
研发团队有前端研发、后端研发、数据研发、运维四组人组成,前端研发与数据架构关系较小,不做介绍,其他三组人背景如下:
- 后端研发:java 语言背景,以 28 岁以下年轻人为主,占比 80%,具有基本 java 研发能力与基本的 SQL 基础,剩余 20% 为 java 技术专家,负责封装基础组件,与中间件的交互,平台级组件
- 数据研发:python 语言背景,spark 实践经验,SQL 较为熟练,以固化离线汇总需求、利用 python 建模、客户实时数据查询需求为主要工作内容
- 运维:人数很少,多年 mysql 数据库运维经验,多团队共享一个运维团队,兼职 DBA 工作
研发团队最严重的问题是 DBA 与研发配置不合理,SQL 审核工作可能不到位,有线上 SQL 性能风险;运维为多个研发团队共享,运维工作需要高度工具化,减少、减轻运维工作量,才能保证项目正常开展。
权衡点矩阵
结合技术需求矩阵、客户背景分析、研发团队背景分析,跟相关技术架构决策者沟通后,总结架构权衡点如下:
| 权衡点 | 需求来源 |
|---|---|
| OLTP MySql 协议 | 技术需求矩阵、研发团队背景分析 |
| OLAP MySql 协议 | 技术需求矩阵、研发团队背景分析 |
| TP、AP 统一入口 | 架构决策 |
| 具备冷热数据分离能力 | 架构决策、硬件采购约束 |
| 具备 CDC 能力 | 架构决策、硬件采购约束 |
| 本地部署,非云产品 | 硬件采购约束 |
| 可方便的进行硬件扩容 | 硬件采购约束 |
| 具有 java 客户端、python 客户端 | 研发团队背景分析 |
| 具有良好的可观测性、具有自诊断、自修复,或者部分实现了自诊断、自修复特性 | 研发团队背景分析 |
| 社区活跃,支持良好,有较多案例 | 架构决策 |
| 能够适配 Spark,实现并行读写 | 研发团队背景分析 |
设计此表格的目的是在架构选型时做评估用,类似于招标文件中的技术要求,各个数据库产品需要应标。表中的架构决策是指架构师和相关决策者根据经验增加的要求。
数据库架构选型
先画个图表看看我们到底需要哪种类型的数据库:
| | 分布式 | 集群 | 单机 | 云部署 | 本地部署 | | ---- | --- | -- | :- | :-- | :--- | | OLTP | | | | | | | OLAP | | | | | | | HTAP | | | | | | | KV | | | | | | | 文档 | | | | | | | 图数据库 | | | | | | | 列簇 | | | | | | | 时序 | | | | | | | 空间 | | | | | | | 内存 | | | | | | | 搜索引擎 | | | | | |
内存数据库、搜索引擎因我司技术平台技术集成的原因,没有什么可选择性,采用 Redis、Elasticsearch,其他类型在这次规划中,可以重新选择。
OLTP 架构选型
目前 OLTP 类型的数据库,分为单体数据库和分布式数据库,基于本项目的数据量估算和成本原因,不采用开源单体数据库,采用开源分布式数据库,目前开源分布式数据库有三种架构方式:
- 分库分表 + 中间件
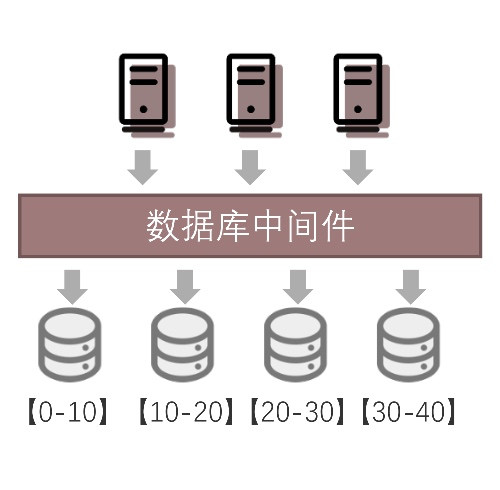
说明:此种架构,在成熟的单体数据库与应用之间加数据代理层,在数据代理层中配置放置规则,实现数据分库分表、读写分离。 优势:底层数据库较为成熟,成本低,稳定性好 劣势:随着数据量的增大,分片规则、扩缩容等方面的工作面对较多挑战;如果做了读写分离,强一致性读很难保障,都需要加注解;集群可观测性不友好。
- 去中心化的分布式数据库
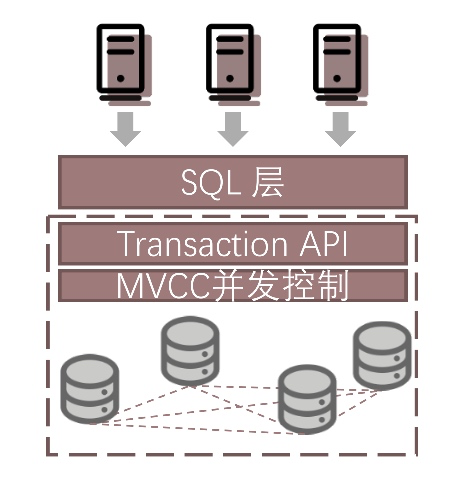
说明:此种架构目前作为分布式的架构最为常见,也就是大家经常说的 Shared-nothing 架构。此架构节点之间不共享数据,可以平滑的扩缩容,通过共识算法保证多副本的可用性。 优势:高内聚、低耦合;有较为广泛的应用;可以动态水平扩展;可保证强一致性。
- 共享存储分布式数据库
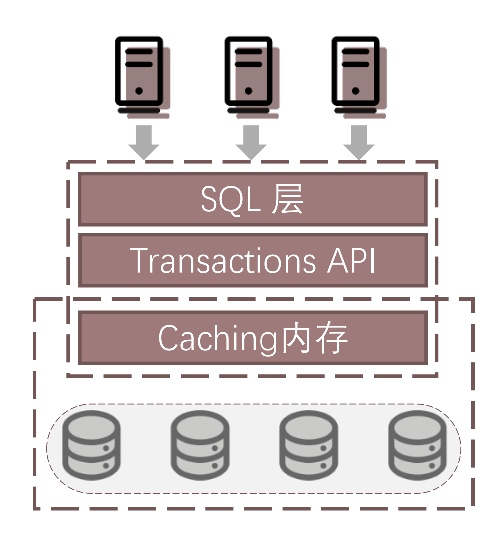
说明:此架构多个计算节点共享一个存储集群,多个节点之间无需日志复制,用物理文件复制代替。 优势:此种架构依赖于底层硬件的创新,例如非易失存储、远程直接数据存取等技术,我认为是未来分布式数据库发现的方向之一,由于减少了主从之间日志复制的环节,系统的稳定性有了更可靠的保障。 劣势:目前类似技术被大厂绑定,常规采购很难低成本获得类似硬件,而且此类技术也不算成熟。
ETL 与 OLAP 架构选型
OLAP 的数据一般来源于 OLTP,可能会有第三方数据补充,ETL 一般伴随着 TP 和 AP 选型的不同而改变从 OLTP 同步数据到 OLAP,存在四种方式:
- 定时抽取
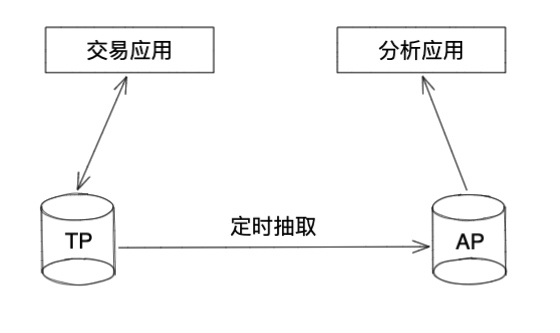
说明:此架构通过设置每日定时任务,根据 timestamp 等字段,抽取每日增量到分析库,基于分析库做离线计算与在线分析。 优势:实现简单,工具成熟 劣势:实时性不足;抽取过程容易干扰 TP 正常业务;抽取一般在凌晨,一旦抽取失败,工作时间发现并修复,会严重干扰 TP 业务。
- 实时同步
说明:此架构通过 TP 数据库的 CDC 技术同步数据到流处理平台,AP 数据库主动或者被动从流处理平台获取增量数据,批量回放到库表中。 优势:数据相对实时;对 TP 干扰小;随时进行数据回放修复同步错误。 劣势:无法保证强一致性;一般需要在应用端建立两个数据源,应用开发人员需要分清楚 TP 和 AP 业务。
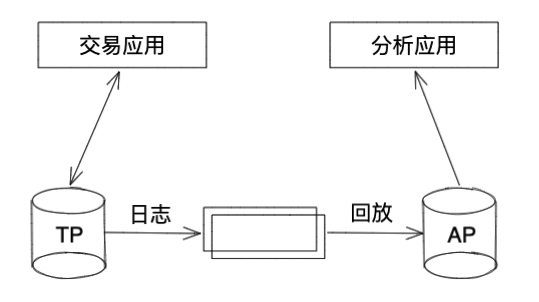
- 日志同步

说明:此架构常见于 HTAP 数据库,数据库内建 TP 和 AP 两个存储模型,TP 和 AP 之间通过日志同步,应用通过一个统一入口访问,访问入口根据 SQL 代价或者其他评估方案自动采用不同引擎提供服务,不必感知底层实现。 优势:TP 和 AP 之间可以保证强一致性;应用无需过多关心底层实现,通过一个入口访问。 劣势:对硬件有较高要求
- 共享存储
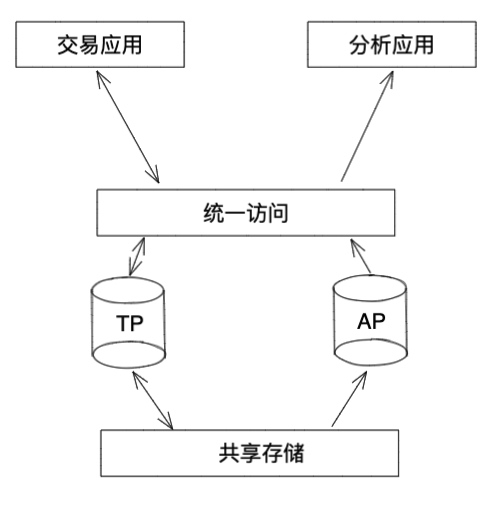
说明:此架构的 TP 和 AP 引擎公用一个共享存储,数据不存在复制过程。 优势:没有日志的逻辑复制过程,用物理文件复制代替(共享存储特性),实时性好,系统负担小。 劣势:技术不太成熟,依赖于新的硬件,例如非易失存储、远程直接数据存取等技术。
模型、标签架构选型
受研发团队背景和模块复用要求的限制,模型、标签复用 python(Jupyter Notebook)、spark(SparkSQL) 等已经实现的组件,不再过多考虑其他方案。
备选产品圈定
首先参考一下,墨天伦的排名,筛选开源、关系型数据库,选取 TOP5 如下:  根据架构权衡点的要求,所选定数据库要求本地部署、兼容 MySQL 协议,排除 PolarDB、GaussDB、openGauss,只剩下 TiDB、OceanBase,根据权衡点,绘制对组件情况如下:
根据架构权衡点的要求,所选定数据库要求本地部署、兼容 MySQL 协议,排除 PolarDB、GaussDB、openGauss,只剩下 TiDB、OceanBase,根据权衡点,绘制对组件情况如下:
| 权衡点 | TiDB | OceanBase |
|---|---|---|
| OLTP MySql 协议 | 支持 | 支持 |
| OLAP MySql 协议 | 支持 | 支持 |
| TP、AP 统一入口 | 支持 | 支持 |
| 具备冷热数据分离能力 | 支持放置策略 | 支持放置策略 |
| 具备 CDC 能力 | 支持 | 支持 |
| 本地部署,非云产品 | 支持 | 支持 |
| 可方便的进行硬件扩容 | 支持 | 支持 |
| 具有 java 客户端、python 客户端 | 兼容 MySQL 客户端 | 兼容 MySQL 客户端 |
| 具有良好的可观测性,具有自诊断、自修复,或者部分实现了自诊断、自修复特性 | 流量可视化、SQL 语句分析、慢查询分析、集群诊断、Clinic | OCP、SQL Diagnoser |
| 社区活跃,支持良好,有较多案例 | 另行分析 | 另行分析 |
| 能够适配 Spark,实现并行读写 | 支持 TiKV 直读、直写,支持直读 TiFlash | 支持 JDBC 读写 |
在社区方面的表现见下表(数据截止到 20220601):
| 开源项目 | 发版模式 | 已解决 Issues(github) | Star/Fork | 社区版本用户数量 |
|---|---|---|---|---|
| TiDB | 基于同一个版本库,开源版本与商业版本同步发版 | 9K+ | 31.5K/5.1K | 2K+ |
| OceanBase | 基于不同的版本库,开源版本落后于商业版本,同步频率未知 | 400+ | 4.3K/972 | 400+ |
OceanBase 盛名已久,但因为开源时间晚于 TiDB,数据上并不好看,但 OceanBase 的发版方式,让开源版本与商业版本的核心特性有较大差距,TiDB 的开源版本与商业版本是同一套代码,开源用户完全可以跟随版本发布使用到最新的特性和 BUG 修复,在这一点上 TiDB 比 OceanBase 更具有优势。 可观测性对数据库的运维十分重要,TiDB 的流量可视化可以更直观的观测到读写热点,Clinic 可以一键打通本地环境与社区专家的沟通渠道,这两方面也具有一定优势。 根据以上分析,本次架构设计中 TiDB 列为 POC 测试产品,OceanBase 列为备选产品。
POC 设计与测试
POC 设计一般考虑几个方面的功能:
- 核心业务场景:核心业务场景是指数据库上线之后需要解决的关键场景,核心业务场景支持不好,可以一票否决数据库选型。
- 典型性能场景:典型性能场景是指系统可能会遇到的高并发、热点读写场景,是数据库选型在本项目中的能力上线,通常类似场景也会涉及到内存数据库与关系型数据库的配合,需要根据场景,提出合理解决方案,并尝试靠近设计目标。
- 价值导向场景:价值导向场景一般指项目甲方的关键人员所使用的功能场景,如果保障此类场景的稳定,需要通过架构设、资源隔离等多种手段达到目标。 根据前文功能设计,选取 POC 场景如下:
- 压力测试 - 登录:测试登录性能瓶颈
- 压力测试 - 订单提交:测试订单提交性能瓶颈
- 压力测试 - 商品信息查询:测试商品信息查询瓶颈,由于存在多级缓存,最终测试结果并不能表达关系型数据库的能力。
- 压力测试 - 三表关联性能测试:选取典型的报表查询 SQL,至少是三表关联的查询
- 稳定性测试 - 登录:由于客户场景存在持续性压力高峰,对登录做超过 6 小时的稳压测试
- 稳定性测试 - 热点混合场景:由于客户场景存在持续性压力高峰,对 1、2、3 三个场景做混合负载稳压测试
- 稳定性测试 -HTAP 混合场景:由于客户场景存在持续性压力高峰,2、4 两个场景做混合负载稳压测试
我们一般使用 metesphere 或者 jmeter 测试。metesphere 一般用于正式环境压力测试,有很多优秀的特性,部署时需要有一定的资源保障,jmeter 即开即用,兼容多种测试场景,本文截取 jmeter 的部分截图做一些展示和说明。 jmeter 截图:  grafana 截图:
grafana 截图: 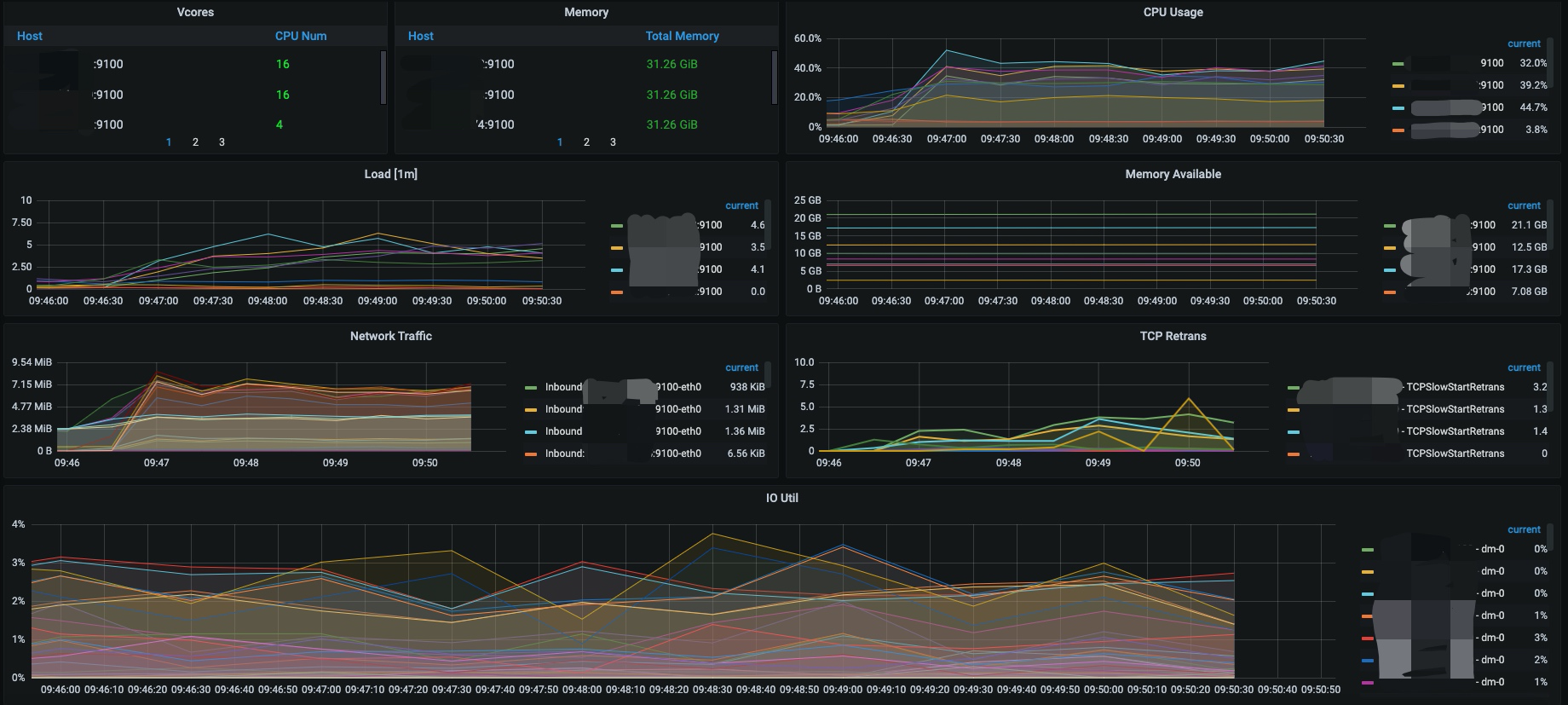 其实简言之,就是在 average 合理的范围区间里(一般是非功能性需求,订单提交 1 秒之内,查询 3 秒之内),当 cpu、内存、磁盘 IO 达到 100% 时,Throughput 稳定在哪个值,这个值就是并发。经过多轮参数调整和回归测试,最后得到的最大值就是最优并发。
其实简言之,就是在 average 合理的范围区间里(一般是非功能性需求,订单提交 1 秒之内,查询 3 秒之内),当 cpu、内存、磁盘 IO 达到 100% 时,Throughput 稳定在哪个值,这个值就是并发。经过多轮参数调整和回归测试,最后得到的最大值就是最优并发。
总体数据架构设计
总体架构设计由于牵扯到很多本文不涉及的内容,这里就不详述了。
总结
本文虽然基于 TiDB 6.0 进行选型,但并不详述 TiDB 6.0 的新特性,也不是实践类文章,鉴于在有限的篇幅中想要描述一个很复杂的事情,行文稍显啰嗦,请各位海涵,并多多指导,帮助作者改进。
边栏推荐
- 如何将 DevSecOps 引入企业?
- [buuctf.reverse] 152-154
- 2022 driller (drilling) examination question bank and simulation examination
- Attack and defense world web WP
- RK3566添加LED
- 【华南理工大学】考研初试复试资料分享
- Brief introduction to revolutionary neural networks
- 登录界面代码
- [South China University of technology] information sharing of postgraduate entrance examination and re examination
- ::ffff:192.168.31.101 是一个什么地址?
猜你喜欢

laravel-dompdf导出pdf,中文乱码问题解决
Set up a website with a sense of ceremony, and post it to the public 2/2 through the intranet
Brief introduction to revolutionary neural networks
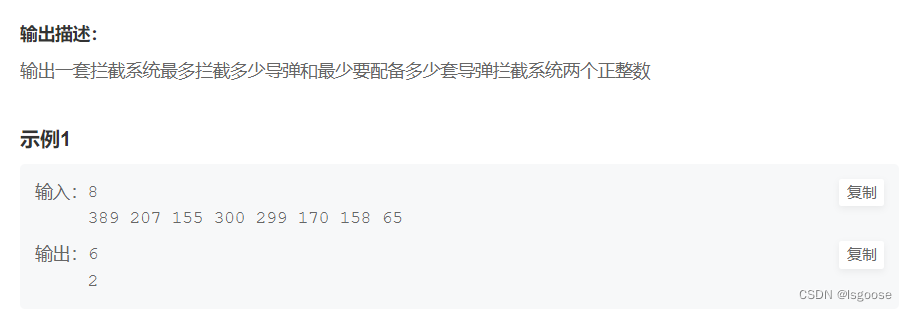
牛客网:拦截导弹
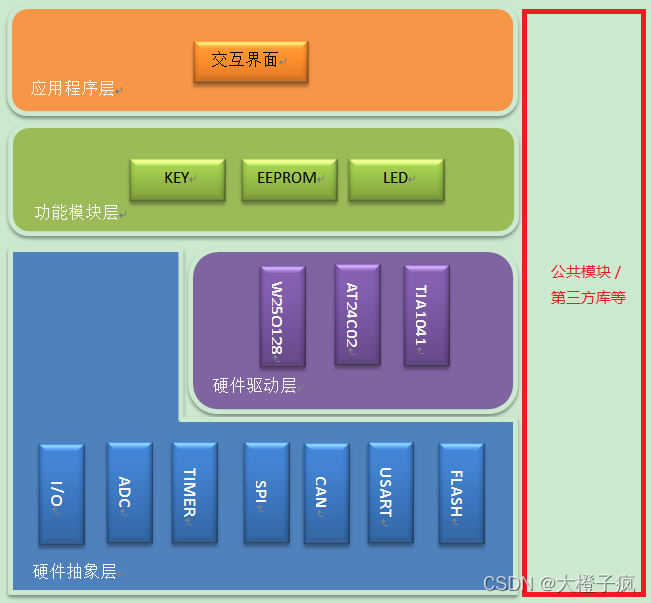
Embedded software architecture design - message interaction
![[public class preview]: basis and practice of video quality evaluation](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[public class preview]: basis and practice of video quality evaluation
![UE源码阅读[1]---由问题入手UE中的延迟渲染](/img/fa/f33242b01e4da973fa36c2c6f23db6.png)
UE源码阅读[1]---由问题入手UE中的延迟渲染
These 18 websites can make your page background cool
The development of speech recognition app with uni app is simple and fast.
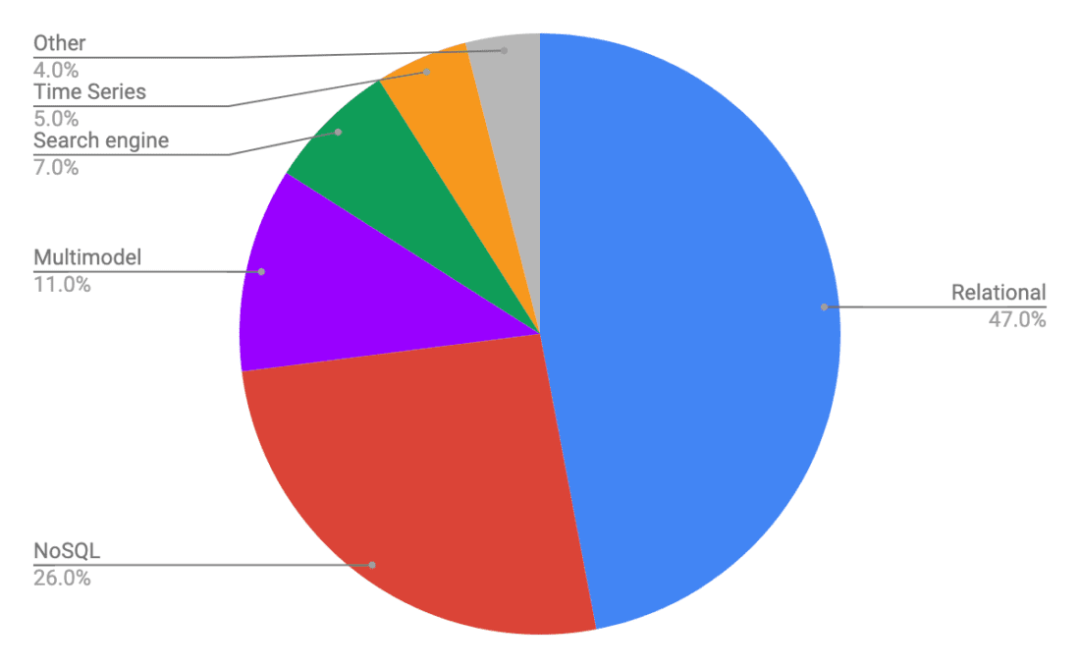
几款分布式数据库的对比
随机推荐
Self built shooting range 2022
Financial one account Hong Kong listed: market value of 6.3 billion HK $Ye wangchun said to be Keeping true and true, long - term work
Routing in laravel framework
几款分布式数据库的对比
laravel-dompdf导出pdf,中文乱码问题解决
Blue Bridge Cup study 2022.7.5 (morning)
清大科越冲刺科创板:年营收2亿 拟募资7.5亿
Embedded software architecture design - message interaction
Why do I support bat to dismantle "AI research institute"
Simple process of penetration test
poi设置列的数据格式(有效)
UE source code reading [1]--- starting with problems delayed rendering in UE
Google EventBus 使用详解
[buuctf.reverse] 152-154
web3.eth. Filter related
Those things I didn't know until I took the postgraduate entrance examination
Ueditor + PHP enables Alibaba cloud OSS upload
Matlab learning 2022.7.4
Idea remote debugging agent
关于Apache Mesos的一些想法