当前位置:网站首页>[Multi-task model] Progressive Layered Extraction: A Novel Multi-Task Learning Model for Personalized (RecSys'20)
[Multi-task model] Progressive Layered Extraction: A Novel Multi-Task Learning Model for Personalized (RecSys'20)
2022-08-01 20:01:00 【chad_lee】
Tencent's video recommendation team,建模的目标包含用户的多种不同的行为:点击,分享,评论等等.每次请求,The ranking points of the candidates are calculated according to the formula:
score = p V T R w V T R × p V C R w V C R × p S H R w S H R × … × p C M R w C M × f ( video l e n ) \text { score }=p V T R^{w V T R} \times p V C R^{w V C R} \times p S H R^{w S H R} \times \ldots \times p_{C M R}^{w C M} \times f(\text { video } l e n) score =pVTRwVTR×pVCRwVCR×pSHRwSHR×…×pCMRwCM×f( video len)
其中w是超参,表示相对重要性

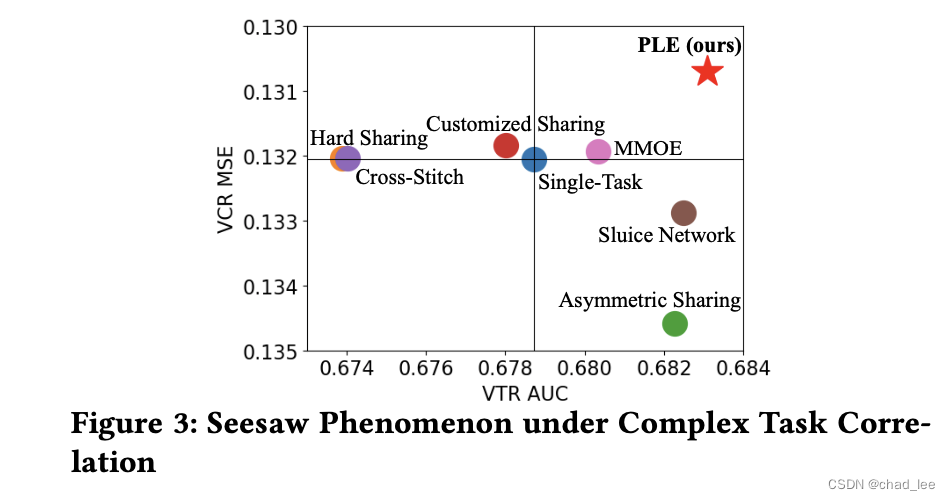
There are often complex relationships between multiple targets,Therefore, the phenomenon of seesaw often appears when modeling multiple targets at the same time,i.e. multiple tasksnegative transfer的问题:
GCG
MMOEIn theory, there is an optimal situation where features can be automatically selected,But this situation depends:1、gateCan you choose;2、也依赖expertCan produce a variety of characteristics(所有expert输出类似,无可奈何).
因此本文提出的Customized Gate ControlMake this problem a little easier,Divide experts into big peers and small peers,both sharedexpert们,每个task也有专门的expert们,A little less difficult.
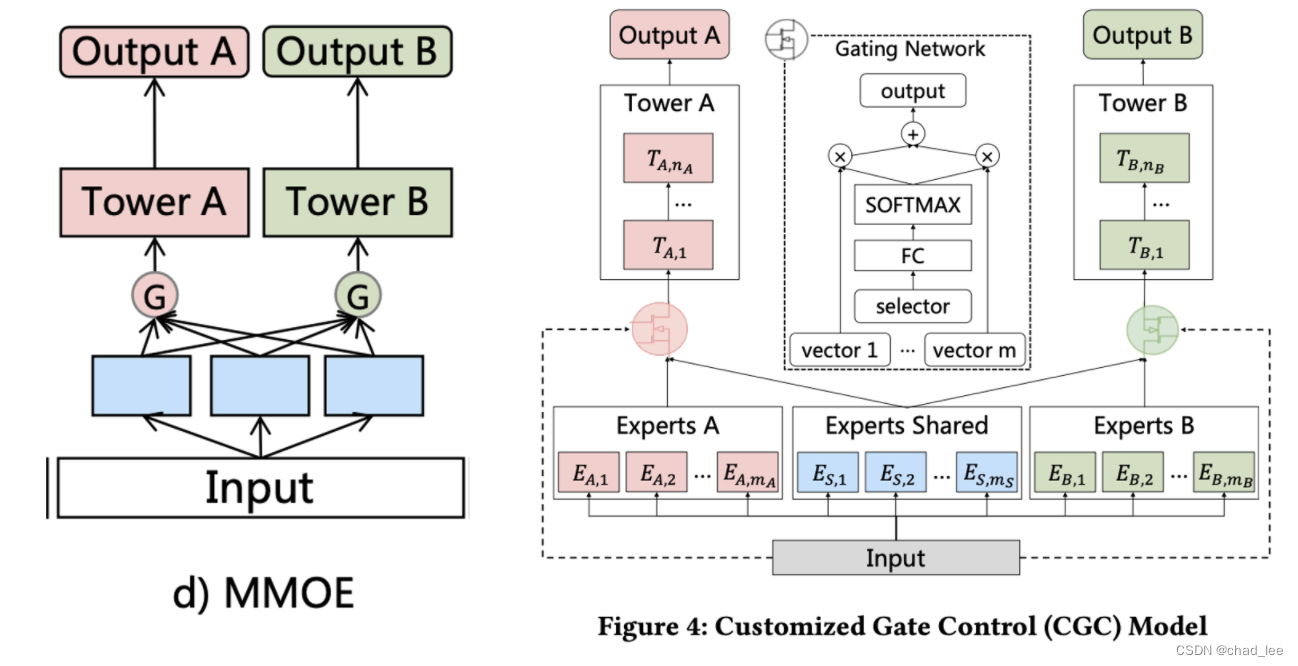
这样EA只被taskA训,EB只被taskB训,Guaranteed at least.
input是x,任务k的输出是
y k ( x ) = t k ( g k ( x ) ) y^{k}(x)=t^{k}\left(g^{k}(x)\right) yk(x)=tk(gk(x))
其中 t k t^k tk是这个任务的NN tower, g k ( x ) g^{k}(x) gk(x) 是第kThe output of the gating network for each task:
g k ( x ) = w k ( x ) S k ( x ) g^{k}(x)=w^{k}(x) S^{k}(x) gk(x)=wk(x)Sk(x)
其中x是原始输入, w k ( x ) w^{k}(x) wk(x)是一个加权函数,Corresponds to the weight of each expert respectively,是一个softmax的输出:
w k ( x ) = Softmax ( W g k x ) w^{k}(x)=\operatorname{Softmax}\left(W_{g}^{k} x\right) wk(x)=Softmax(Wgkx)
其中 W g k ∈ R ( m k + m s ) × d W_{g}^{k} \in R^{\left(m_{k}+m_{s}\right) \times d} Wgk∈R(mk+ms)×d,mk和ms是 shared experts 和 specific experts 的个数. S k ( x ) S^{k}(x) Sk(x)is the output vector of all expertscontackcalled togetherselected matrix:
S k ( x ) = [ E ( k , 1 ) T , E ( k , 2 ) T , … , E ( k , m k ) T , E ( s , 1 ) T , E ( s , 2 ) T , … , E ( s , m s ) T ] T S^{k}(x)=\left[E_{(k, 1)}^{T}, E_{(k, 2)}^{T}, \ldots, E_{\left(k, m_{k}\right)}^{T}, E_{(s, 1)}^{T}, E_{(s, 2)}^{T}, \ldots, E_{\left(s, m_{s}\right)}^{T}\right]^{T} Sk(x)=[E(k,1)T,E(k,2)T,…,E(k,mk)T,E(s,1)T,E(s,2)T,…,E(s,ms)T]T
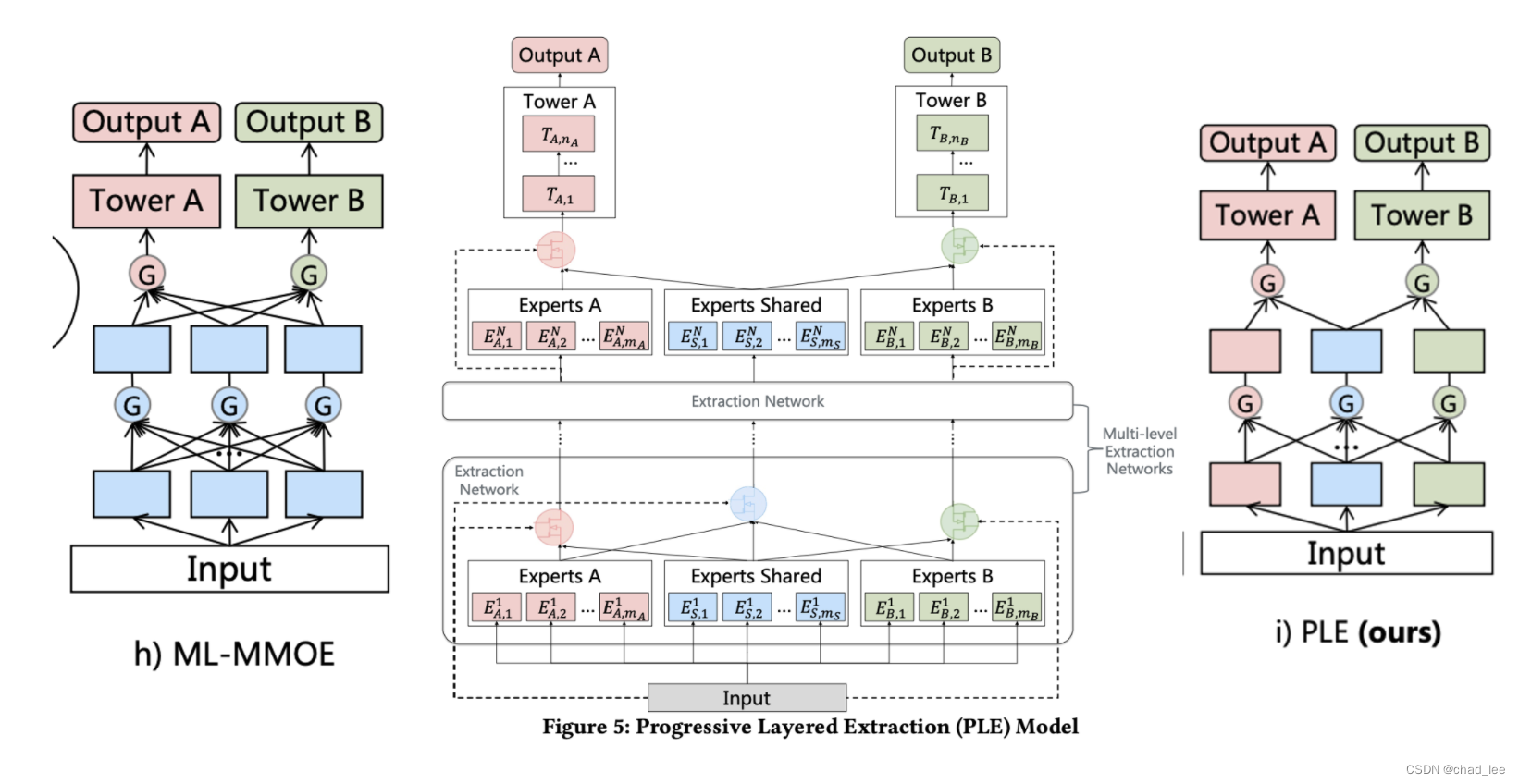
PLE
But there are also problems after dividing small peers,不同taskThe role of the auxiliary supervision signal is small again(Because the difference from the independent model is only one sharedexpert,能力有限).所以PLEIt is to connect several layers of expert networks,让共享expert更强一些.
优化方法
Half of the multi-objective task optimization is to set different weights for different subtasks,损失函数加权:
L ( θ 1 , … … , θ K , θ s ) = ∑ k = 1 K ω k L k ( θ k , θ s ) L\left(\theta_{1}, \ldots \ldots, \theta_{K}, \theta_{s}\right)=\sum_{k=1}^{K} \omega_{k} L_{k}\left(\theta_{k}, \theta_{s}\right) L(θ1,……,θK,θs)=k=1∑KωkLk(θk,θs)
But this paper considers the problem of inconsistency in the training sample space in more detail:

比如用户只有点击后才能进行分享和评论.本文是在 Loss 上进行一定的优化,联合训练这些任务,在计算每个任务的损失时需要把样本空间相同的合并,并忽略不在自己样本空间的样本,即不同的任务仍使用其各自样本空间中的样本.I understand it to mean a time when the model is updated,不会同时用SHR和CTR的loss来更新
At the same time, this paper also considers different tasks to set a dynamic weight,比如task k的初始loss权重为 ω k , 0 \omega_{k, 0} ωk,0,那么在第t个epoch的时候loss权重为:
ω k ( t ) = ω k , 0 × γ k t \omega_{k}^{(t)}=\omega_{k, 0} \times \gamma_{k}^{t} ωk(t)=ωk,0×γkt
其中 γ k t \gamma_{k}^{t} γkt is the update rate of the previous step.
边栏推荐
猜你喜欢

因斯布鲁克大学团队量子计算硬件突破了二进制
Greenplum Database Source Code Analysis - Analysis of Standby Master Operation Tools
部署zabbix

WhatsApp group sending actual combat sharing - WhatsApp Business API account

使用Huggingface在矩池云快速加载预训练模型和数据集
Compse编排微服务实战
图文详述Eureka的缓存机制/三级缓存

安全作业7.25

MySQL你到底都加了什么锁?
Greenplum数据库源码分析——Standby Master操作工具分析
随机推荐
57: Chapter 5: Develop admin management services: 10: Develop [get files from MongoDB's GridFS, interface]; (from GridFS, get the SOP of files) (Do not use MongoDB's service, you can exclude its autom
XSS range intermediate bypass
PROE/Croe如何编辑已完成的草图,让其再次进入草绘状态
openresty 动态黑白名单
实用新型专利和发明专利的区别?秒懂!
【节能学院】智能操控装置在高压开关柜的应用
数据库系统原理与应用教程(070)—— MySQL 练习题:操作题 101-109(十四):查询条件练习
通配符 SSL/TLS 证书
面试突击70:什么是粘包和半包?怎么解决?
第58章 结构、纪录与类
10 个 PHP 代码安全漏洞扫描程序
【Untitled】
C语言实现-直接插入排序(带图详解)
Ha ha!A print function, quite good at playing!
瀚高数据导入
解除360对默认浏览器的检测与修改
数据库系统原理与应用教程(071)—— MySQL 练习题:操作题 110-120(十五):综合练习
Pytorch模型训练实用教程学习笔记:三、损失函数汇总
使用微信公众号给指定微信用户发送信息
regular expression