当前位置:网站首页>ACL 2022 | decomposed meta learning small sample named entity recognition
ACL 2022 | decomposed meta learning small sample named entity recognition
2022-07-01 17:26:00 【PaperWeekly】

author | Huiting wind
Company | Beijing University of Posts and telecommunications
Research direction | natural language understanding

Paper title :
Decomposed Meta-Learning for Few-Shot Named Entity Recognition
Thesis link :
https://arxiv.org/abs/2204.05751
Code link :
https://github.com/microsoft/vert-papers/tree/master/papers/DecomposedMetaNER
Abstract
Few samples NER The purpose of the system is to identify new named entity classes through a small number of annotation samples . This paper proposes a decomposition meta learning method to solve small samples NER, By decomposing the original problem into two processes: small sample span prediction and small sample entity classification . say concretely , We treat span prediction as a sequence labeling problem and use MAML Algorithm training span predictor comes Find better model initialization parameters and enable the model to quickly adapt to new entities . For entity classification , We have put forward MAML-ProtoNet, One MAML Enhanced prototype network , can Find a good embedding space to better distinguish the span of different entity classes . In more than one benchmark The experiment on shows that , Our method has achieved better results than the previous method .

Intro
NER The purpose is to locate and recognize predefined entity classes in the text span, such as location、organization. In standard supervised learning NER The architecture of medium and deep learning has achieved great success . However , in application ,NER Our model usually needs to quickly adapt to some new and unprecedented entity classes , And it is usually expensive to label a large number of new samples . therefore , Small sample NER In recent years, it has been widely studied .
Before about small samples NER Our research is based on token Level measurement learning , Put each query token Compare metrics with prototypes , Then for each token Assign tags . Many recent studies have shifted to span level measurement learning , Able to bypass token Since the tag and clearly use the representation of phrases .
However, these methods may not be so effective when encountering large field deviations , Because they directly use the learning metrics without adapting the target domain . let me put it another way , These methods do not fully mine the information that supports set data . The current method still has the following limitations :
1. The decoding process requires careful handling of overlapping spans ;
2. Non entity type “O” Usually noise , Because these words have little in common .
Besides , When targeting a different field , The only available information is only a few support samples , Unfortunately , These samples were only used in the process of calculating similarity in the reasoning stage in the previous method .
To address these limitations , This paper presents a decomposition meta learning method , The original problem is decomposed into two processes: span prediction and entity classification . In particular :
1. For small sample span prediction , We regard it as a sequence annotation problem to solve the problem of overlapping span . This process aims to locate named entities and is category independent . Then we only classify the marked spans , This can also eliminate “O” Impact of noise like . When training the span detection module , We used MAML Algorithm to find good model initialization parameters , After updating the sample with a small number of target domain support sets , It can quickly adapt to new entity classes . When the model is updated , The span boundary information of a specific field can be effectively used by the model , So that the model can be better migrated to the target field ;
2. For entity classification , Adopted MAML-ProtoNet To narrow the gap between the source domain and the target domain .
We're in some benchmark We did experiments on , Experiments show that our proposed framework is better than the previous SOTA The model performs better , We also made qualitative and quantitative analysis , Effects of different meta learning strategies on model performance .

Method
This article follows the traditional N-way-K-shot Small sample setting , Examples are shown in the following table (2-way-1-shot):

The following figure shows the overall structure of the model :

2.1 Entity Span Detection
There is no need to classify specific entity classes in the span detection stage , Therefore, the parameters of the model can be shared among different fields . Based on this , We use MAML To promote domain invariant internal representation learning, rather than learning specific domain characteristics . The meta learning model trained in this way is more sensitive to the samples in the target domain , Therefore, only a small number of samples need to be fine tuned to achieve good results without over fitting .
2.1.1 Basic Detector
The base detector is a standard sequence annotation task , use BIOES Annotation strategy , For a sequence of sentences {xi}, Use an encoder to get its context representation h, And then through softmax Generate probability distribution .

▲ fθ: Encoder

▲ A probability distribution
The training error of the model adds a maximum term to the cross entropy loss to alleviate the high loss token The problem of insufficient learning :

▲ Cross entropy loss
Viterbi decoding is used in the reasoning stage , Here we have no training transfer matrix , Simply add some restrictions to ensure that the predicted label does not violate BIOES Annotation rules of .
2.1.2 Meta-Learning Procedure
Specifically speaking, the meta training process , First, randomly sample a group of training episode:
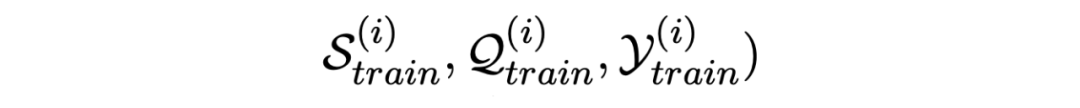
Use the support set for inner-update The process :
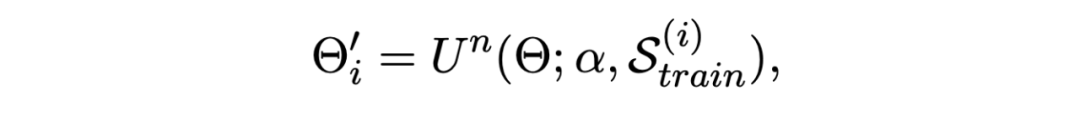
among Un representative n Step gradient update , The loss adopts the loss function mentioned above . Then use the updated parameters Θ' Evaluate on the query set , Will a batch In all of the episode Sum of losses , The training goal is to minimize this loss :

Update the original parameters of the model with the above losses Θ, Here we use the first derivative to approximate :
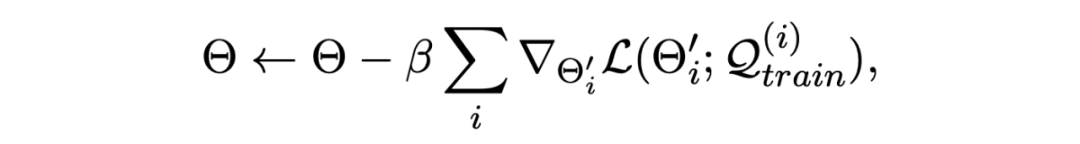
MAML Mathematical derivation reference :MAML
https://zhuanlan.zhihu.com/p/181709693
In the reasoning stage, the cross entropy loss mentioned in the base model is used to fine tune the support set , Then use the fine tuned model on the query set to test .
2.2 Entity Typing
The entity classification module uses the prototype network as the basic model , Use MAML The algorithm enhances the model , Make the model get a more representative embedded space to better distinguish different entity classes .
2.2.1 Basic Model
Here another encoder is used to input token Encoding , Then use the span detection module to output the span x[i,j], All in the span token The representation is averaged to represent the representation of this span :
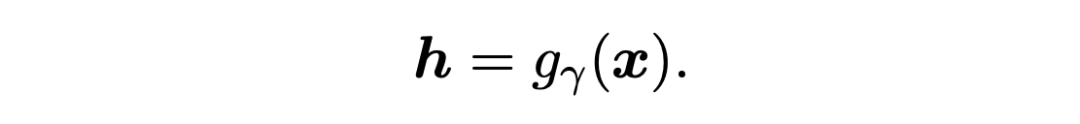
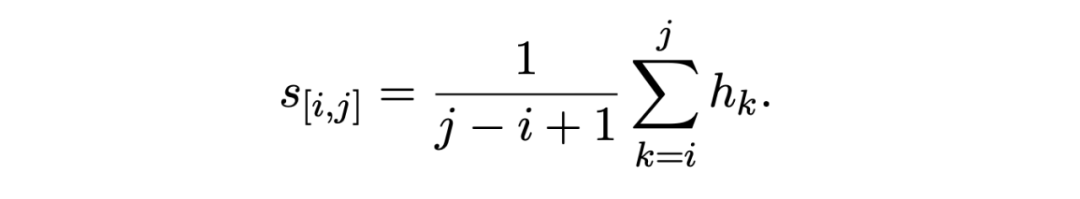
Follow the setup of the prototype network , Use the summation average of the spans belonging to the same entity class in the support set as the representation of the class prototype :
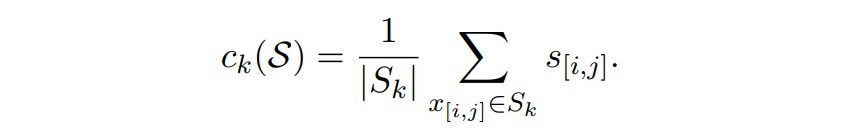
The training process of the model first uses the support set to calculate the representation of each class prototype , Then for each span in the query set , The probability of belonging to a certain class is calculated by calculating the distance from it to the prototype of that class :
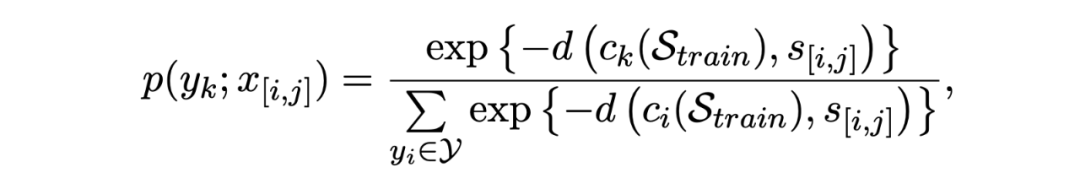
The training goal of the model is a cross entropy loss :

The reasoning stage is simply to calculate which kind of prototype is closest :
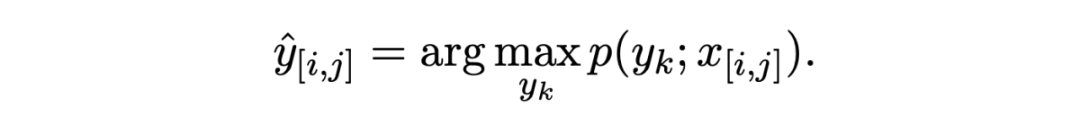
2.2.2 MAML Enhanced ProtoNet
The setting of this process and the application in span detection MAML Agreement , Also use MAML Algorithm to find a better initialization parameter , Refer to the above for the detailed process :

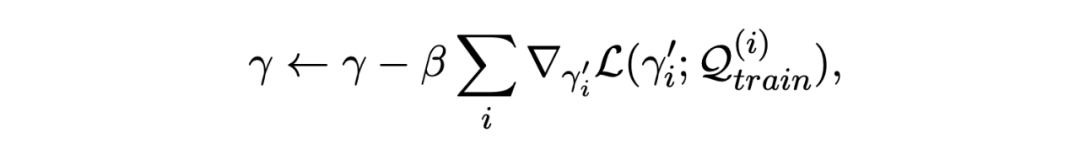
The reasoning stage is also consistent with the above , I won't elaborate here .

experiment
3.1 Data sets and settings
In this paper Few-NERD, One for few-shot NER Launched data sets and cross-dataset, Integration of data sets in four different fields . about Few-NERD Use P、R、micro-F1 As an evaluation indicator ,cross-dataset use P、R、F1 As an evaluation indicator . Two independent encoders are used in this paper BERT, Optimizer usage AdamW.
3.2 Main experiment
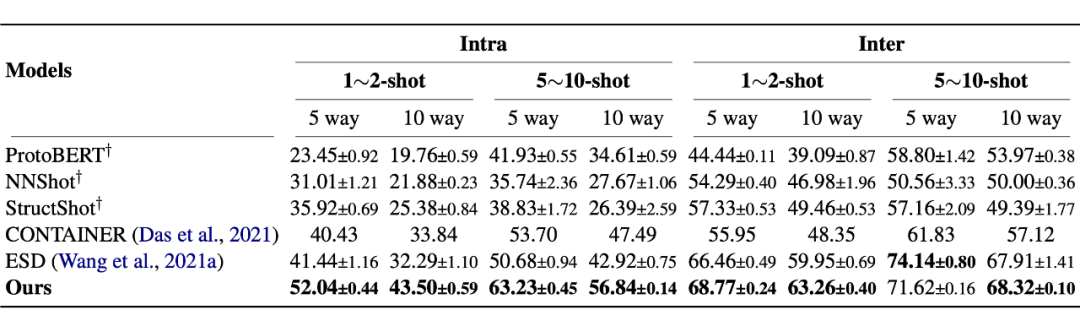
▲ Few-NERD

▲ Cross-Dataset
3.3 Ablation Experiment

3.4 analysis
For span detection , The author used a fully supervised span detector to carry out the experiment :

The author analyzes , Not fine tuned model predicted Broadway It is a wrong prediction for the new entity class (Broadway Appears in the training data ), Then fine tune the model by using new entity class samples , It can be seen that the model can predict the correct span , however Broadway This span is still predicted . This shows that although the traditional fine tuning can make the model obtain certain new class information , But there is still a big deviation .
Then the author compares MAML Enhanced models and unused MAML Model F1 indicators :

MAML The algorithm can make better use of the data of the supporting set , Find a better initialization parameter , Enable the model to quickly adapt to the new domain .
Then the author analyzes MAML How to improve the prototype network , First, indicators MAML The enhanced prototype network will be improved :

Then the author makes a visual analysis :

As can be seen from the above figure ,MAML The enhanced prototype network can better distinguish various types of prototypes .

Conclusion
This paper presents a two-stage model , Span detection and entity classification for small samples NER Mission , Both stages of the model use meta learning MAML Methods to enhance , Get better initialization parameters , The model can be quickly adapted to the new domain through a small number of samples . This article is also an enlightening article , We can see from the indicators , Meta learning method for small samples NER The task has been greatly improved .
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- 【牛客网刷题系列 之 Verilog快速入门】~ 优先编码器电路①
- 6月刊 | AntDB数据库参与编写《数据库发展研究报告》 亮相信创产业榜单
- Pytest learning notes (13) -allure of allure Description () and @allure title()
- Redis Distributed Lock
- Soft test network engineer full truth simulation question (including answer and analysis)
- 美国国家安全局(NSA)“酸狐狸”漏洞攻击武器平台技术分析报告
- 【splishsplash】关于如何在GUI和json上接收/显示用户参数、MVC模式和GenParam
- Depth first traversal and breadth first traversal [easy to understand]
- 单例模式的懒汉模式跟恶汉模式的区别
- Research Report on development monitoring and investment prospects of China's smart environmental protection industry (2022 Edition)
猜你喜欢
【Try to Hack】vulnhub DC4

Redis distributed lock

Machine learning 11 clustering, outlier discrimination
机器学习11-聚类,孤立点判别

Why should you consider using prism

存在安全隐患 起亚召回部分K3新能源

Girls who want to do software testing look here

In aks, use secret in CSI driver mount key vault

多线程并发之CountDownLatch阻塞等待
Babbitt | yuan universe daily must read: Naixue coin, Yuan universe paradise, virtual stock game Do you understand Naixue's tea's marketing campaign of "operation pull full"
随机推荐
官宣!香港科技大学(广州)获批!
拼接字符串,得到字典序最小的结果
String类
Soft test software designer full truth simulation question (including answer analysis)
机器学习11-聚类,孤立点判别
Determine whether the linked list is a palindrome linked list
开发那些事儿:EasyCVR集群设备管理页面功能展示优化
PHP实现敏感词过滤系统「建议收藏」
Encryption and decryption of tinyurl in leetcode
【C补充】【字符串】按日期排序显示一个月的日程
Research Report on development monitoring and investment prospects of China's smart environmental protection industry (2022 Edition)
Sword finger offer II 015 All modifiers in the string
Report on Market Research and investment prospects of ammonium dihydrogen phosphate industry in China (2022 Edition)
Jojogan practice
Radhat builds intranet Yum source server
[Verilog quick start of Niuke network question brushing series] ~ priority encoder circuit ①
(16) ADC conversion experiment
为什么你要考虑使用Prisma
Alibaba cloud, Zhuoyi technology beach grabbing dialogue AI
Computed property “xxx“ was assigned to but it has no setter.