当前位置:网站首页>Crawler - basic use of selenium, no interface browser, other uses of selenium, cookies of selenium, crawler cases
Crawler - basic use of selenium, no interface browser, other uses of selenium, cookies of selenium, crawler cases
2022-08-04 14:04:00 【There is a car on the mountain】
系列文章目录
第二章 代理搭建、爬取视频网站、爬取新闻、BeautifulSoup4介绍、bs4 遍历文档树、bs4搜索文档树、bs4使用选择器
第三章 selenium基本使用、无界面浏览器、selenium的其他用法、selenium的cookie、爬虫案例
一、selenium基本使用
由于requests不能执行js,有的页面内容,我们在浏览器中可以看到,But there is no corresponding data in the response,这个时候可以使用selenium模块.
selenium:Simulates the operation of the browser,完成人的行为
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
1.安装selenium
pip install selenium
2.下载浏览器驱动
由于seleniumA browser is required,So we also need to prepare the browser driver
Take Google as an example here:
Google Chrome driver is inaccessible due to the wall,So you can use the mirror site provided by Taobao
Google Chrome Drive Mirror Site

查看谷歌浏览器版本
第一种:You can find about browser in settings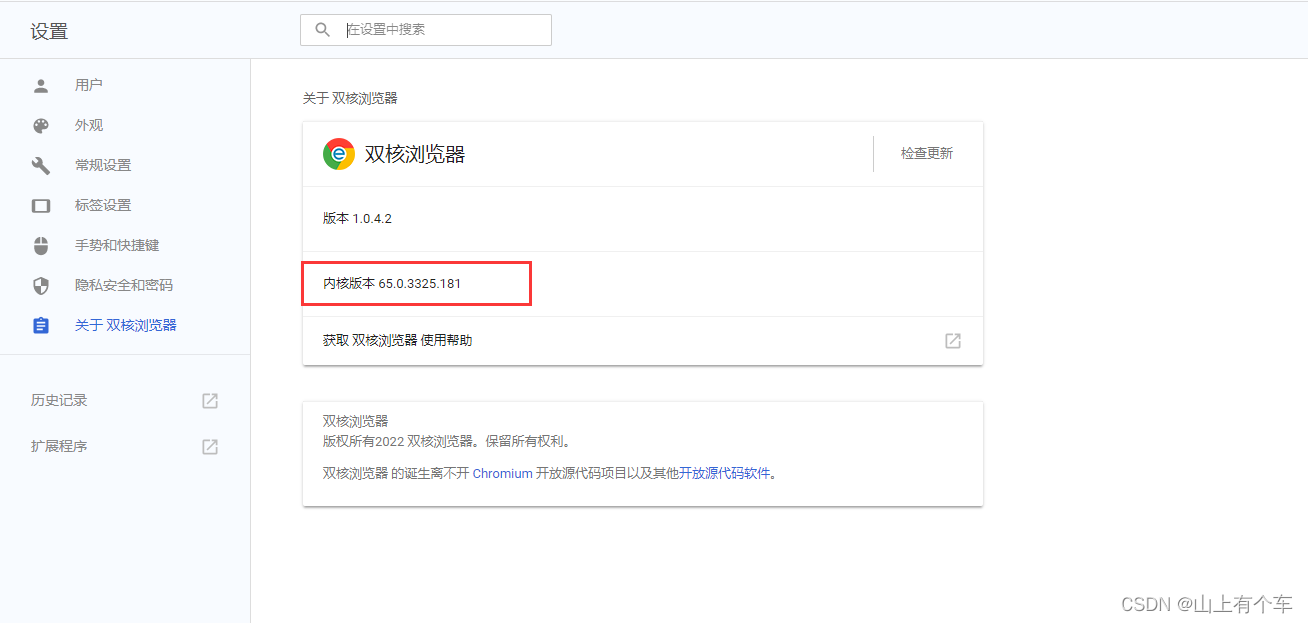
第二种:
在地址栏输入
chrome://version/

3.selenium的基础使用
The driver is placed in the project path or in environment variables
from selenium import webdriver
# 首先创建一个webdriver实例对象
bro=webdriver.Edge() # 此处以edge浏览器为例 可以使用参数executable_path指定浏览器驱动exe位置(已弃用)
# Or use google etc,都有对应的方法 bro=webdriver.Chrome()
bro.implicitly_wait(10) # This function is usually used,Opening a browser to enter a website will wait a fixed number of seconds before proceeding
bro.get('https://www.baidu.com')# 调用get方法,相当于输入url进入对应网站
bro.close()# Close this tab
bro.quite()# 关闭浏览器
# 操作完毕,Usually you need to close the tab or browser
模拟登陆百度
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
bro = webdriver.Chrome()
bro.implicitly_wait(10) # 隐士等待,No matter which tag is found on the page,如果找不到,会等待最多10s钟
bro.get('https://www.baidu.com/')
# Click to log in there are various options such as:
# 1 根据标签id号,获取标签
# btn=bro.find_element_by_id('s-top-loginbtn') # 老版本
# btn=bro.find_element(by=By.ID, value='s-top-loginbtn') # 新版本
# 2 Find tags by text:a标签的文字
btn = bro.find_element(by=By.LINK_TEXT, value='登录')
# 点击一下按钮
btn.click()
# 用户名,密码输入框
username = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__userName')
password = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__password')
# 写入文字
username.send_keys('百度账号')
password.send_keys('Baidu Password')
btn_login=bro.find_element(by=By.ID,value='TANGRAM__PSP_11__submit')
btn_login.click()
bro.close() # 关闭标签
4.selenium的基础方法
4.1 查找控件
find_element_by_id # 根据id
find_element_by_link_text # 根据a标签的文字
find_element_by_partial_link_text # 根据a标签的文字模糊匹配
find_element_by_tag_name # 根据标签名
find_element_by_class_name # 根据类名
find_element_by_name # 根据name属性
find_element_by_css_selector # css选择器
find_element_by_xpath # xpath
## The above is the old syntax,Below is the new syntax,只需要修改byParameters can be based on text、name、css等进行查找
bro.find_element(by=By.ID,value='TANGRAM__PSP_11__submit')
4.2 点击某个按钮
标签对象.click()
submit_btn = bro.find_element(by=By.ID,value='TANGRAM__PSP_11__submit')
submit_btn.click()# 点击注册按钮
4.3 向输入框中写内容
标签对象.send_keys(内容)
username_input = bro.find_element(by=By.ID,value='username')
username_input.send_keys('kkkk23123')# 输入用户名
二、selenium无界面浏览器
使用selenium操作浏览器时,It is not necessary to watch the graphical interface all the time,At this time, you can set my interface browser,And can get the currenthtml内容
# First import the settings module,Each browser has its own settings module
# from selenium.webdriver.chrome.options import Options
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
# edge_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
edge_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
edge_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
edge_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
driver=webdriver.Edge(options=edge_options)
driver.get('https://www.cnblogs.com/')
print(driver.page_source) # 当前页面的内容(html内容)
driver.close()
三、selenium的其他用法
1. Get the position property size,文本
标签.location The location of the tab in the browser,Based on the upper left corner of the label
标签.size The size of this label
标签.id 不是标签的id号,Rather, the label is used throughouthtml中的唯一标识
标签.tag_name 该标签的名字
标签.get_attribute(‘src’) Get the attributes of that tag eg:width、src、height、css、id等
接下来以12306为例,Obtain the information of the QR code when scanning the QR code to log in,And save the QR code as a picture
import time
import base64
from selenium import webdriver
from selenium.webdriver.common.by import By
bro=webdriver.Edge()
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
bro.implicitly_wait(10)
btn=bro.find_element(By.LINK_TEXT,'扫码登录')
btn.click()
time.sleep(1)
img=bro.find_element(By.ID,'J-qrImg')
print(img.location) # The location of the tab in the browser,Based on the upper left corner of the label {'x': 782, 'y': 254}
print(img.size) # The size of this label {'height': 158, 'width': 158}
print(img.id) # 不是标签的id号,Rather, the label is used throughouthtml中的唯一标识 9e2e6caf-d8bf-480b-b3dc-706b7fcc784e
print(img.tag_name) # 该标签的名字 img
s=img.get_attribute('src')# 通过get_attributeto get the attributes of that tag egwidth、src、height、css、id等
with open('code.png','wb') as f:
res=base64.b64decode(s.split(',')[-1])
f.write(res)
bro.close()
2. 等待元素被加载
程序操作页面非常快,所以在取每个标签的时候,The label may not have a load number,需要设置等待
There are two kinds of waiting:
- 强制等待:使用time.sleep(),Will wait no matter what
- 显式等待:当等待的条件满足后(Generally used to determine whether the element that needs to wait is loaded),就继续下一步操作.等不到就一直等,如果在规定的时间之内都没找到,那么就跳出Exception.
- 隐式等待:selenium对象.implicitly_wait(10)
2.1强制等待
直接在代码中调用time.sleep即可
2.2显式等待
#显式等待模块
from selenium.webdriver.support.ui import WebDriverWait
#显式等待条件
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wd = webdriver.Edge()
wd.get('https://www.baidu.com')
#wd是webdriver对象,10是最长等待时间,0.5是每0.5秒去查询对应的元素.until后面跟的等待具体条件,EC是判断条件,检查元素是否存在于页面的 DOM 上.
login_btn=WebDriverWait(wd,10,0.5).until(EC.presence_of_element_located((By.ID, "s-top-loginbtn")))
#点击元素
login_btn.click()
2.3隐式等待
Implicit wait is a global setting,It takes effect globally after one setting
隐式等待设置了一个最长等待时间,在规定时间内网页加载完成(也就是一般情况下你看到浏览器标签栏那个小圈不再转就代表加载完成),则执行下一步,否则一直等到时间结束,然后执行下一步.
from selenium import webdriver
from selenium.webdriver.common.by import By
bro=webdriver.Edge()
bro.implicitly_wait(10)
bro.get('https://www.baidu.com')
3. 元素操作
3.1搜索标签
| 方法 | 作用 |
|---|---|
| find_element | 找第一个,搭配ByOther methods below can be implemented |
| find_elements | 找所有,搭配ByOther methods below can be implemented |
| find_element_by_id | 根据id |
| find_element_by_link_text | 根据a标签的文字 |
| find_element_by_partial_link_text | 根据a标签的文字模糊匹配 |
| find_element_by_tag_name | 根据标签名 |
| find_element_by_class_name | 根据类名 |
| find_element_by_name | 根据name属性 |
| find_element_by_css_selector | css选择器 |
| find_element_by_xpath | xpath |
find_element与find_elements如下:
selenium对象.find_element(by=By.ID,value=‘TANGRAM__PSP_11__submit’)
selenium对象.find_elements(By.LINK_TEXT, ‘美好的一天’)
3.2 点击
标签.click()
3.3 写入文字
标签.send_keys(value)
3.4 清空
标签.clear()
3.5 Swipe the screen to the bottom
selenium对象.execute_script('scrollTo(0,document.body.scrollHeight)')
4. 执行js代码
selenium对象.execute_script(js代码)
5. 切换选项卡
selenium对象.execute_script('window.open()') # 打开新的选项卡
selenium对象.switch_to.window(selenium对象.window_handles[1]) # Select the tab from0开始
6. 浏览器前进后退
selenium对象.back() # 后退
selenium对象.forward() # 前进
7. 异常处理
Used when doing browser operationstry except来进行
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
bro=webdriver.Edge()
try:
bro.get('https://www.pearvideo.com/category_8')
time.sleep(1)
bro.get('https://www.baidu.com')
raise Exception('报错了')
except Exception as e:
print(e)
finally: # Be there anywayfinally中关闭浏览器
bro.quit()
四、selenium的cookie
selenium对象.get_cookies() # 获取浏览器中cookie The obtained format is a set of dictionaries in a list
selenium对象.add_cookie() # 将cookie写入浏览器中 The added format is a dictionary
五、爬虫案例
使用seleniumLike all pages of the blog garden
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
bro = webdriver.Edge()
bro.implicitly_wait(10)
def login():
bro.get('https://account.cnblogs.com/')
# Find the Username and Password boxes
username = bro.find_element(By.ID, 'mat-input-0')
password = bro.find_element(By.ID, 'mat-input-1')
username.send_keys('')
password.send_keys('')
input() # Log in manually in an open browser
cookie = bro.get_cookies() # 将登录的cookie保存下来
with open('./cookie.json', 'w', encoding='utf-8') as f:
json.dump(cookie, f)
def is_login():
bro.get('https://account.cnblogs.com/')
# 读取保存的cookie添加到网页,进入登录状态
with open('cookie.json', 'r', encoding='utf-8') as f:
res = json.load(f)
for item in res:
bro.add_cookie(item)
bro.get('https://account.cnblogs.com/')
bro.refresh()
def aricte_dig_up(start, stop):
home = bro.find_element(By.CSS_SELECTOR,
'body > app-root > app-main-layout > app-navbar > mat-toolbar > mat-toolbar-row > div:nth-child(1) > a.mat-tooltip-trigger.logo')
home.click()
for i in range(start, stop+1):
# Jump to the corresponding page
pag = bro.find_element(By.CSS_SELECTOR, '#paging_block > div > a.p_%s.current'%i)
pag.click()
#获取文章id
arictes = bro.find_elements(By.CSS_SELECTOR, '#post_list article')
aricte_ids = []
for aricte in arictes:
aricte_ids.append(aricte.get_attribute('data-post-id'))
#Like the article you get
for post_id in aricte_ids:
up_btn = bro.find_element(By.ID, 'digg_control_%s'%post_id)
up_btn.click()
if __name__ == '__main__':
key = False # False A semi-automatic login will take place,After successful login, please press Enter on the console,程序结束后将key更改为TrueLike the designated page of the blog garden
if key:
login()
else:
is_login()
aricte_dig_up(1, 1) # The first parameter is the starting page number,The second parameter is the ending page number
bro.close()
边栏推荐
猜你喜欢

Interviewer: Tell me the difference between NIO and BIO

Redis 复习计划 - Redis主从数据一致性和哨兵机制
MySQL性能指标TPS\QPS\IOPS如何压测?

封装、继承、多态的联合使用实现不同等级学生分数信息的统计
漏洞复现 - - - Alibaba Nacos权限认证绕过
![[UML] Summary of Information System Analysis and Design Knowledge Points](/img/a2/32267c5bfdf8114c4c723278a1897c.png)
[UML] Summary of Information System Analysis and Design Knowledge Points

centos7安装mysql急速版
如何查找endnote文献中pdf文件的位置
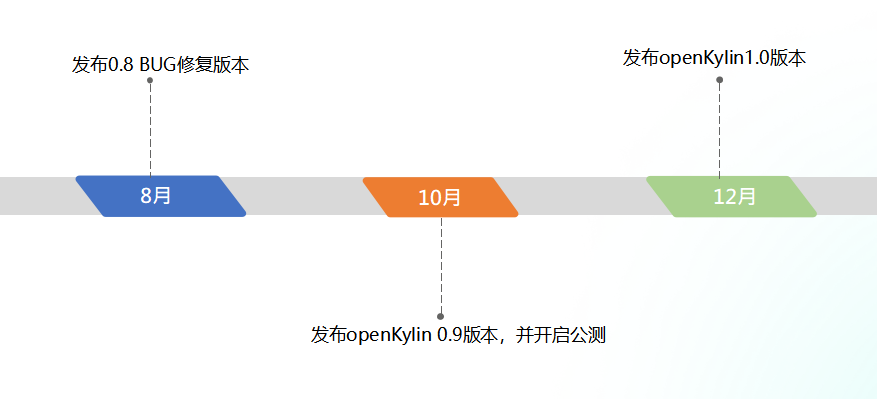
开放麒麟 openKylin 版本规划敲定:10 月发布 0.9 版并开启公测,12 月发布 1.0 版

考研上岸又转行软件测试,从5k到13k完美逆袭,杭州校区小哥哥拒绝平庸终圆梦!
随机推荐
企业应当实施的5个云安全管理策略
MPLS experiment
BZOJ 1798 维护序列 (多校连萌,对线段树进行加乘混合操作)
SLAM 04.视觉里程计-1-相机模型
router---Programmatic navigation
异步编程概览
metaRTC5.0新版本支持mbedtls(PolarSSL)
odoo13笔记点
Redis 复习计划 - Redis主从数据一致性和哨兵机制
SLAM 05.视觉里程计-2-特征法
router---模式
《社会企业开展应聘文职人员培训规范》团体标准在新华书店上架
如何查找endnote文献中pdf文件的位置
错误 AttributeError type object 'Callable' has no attribute '_abc_registry' 解决方案
PAT甲级:1040 Longest Symmetric String
并发刺客(False Sharing)——并发程序的隐藏杀手
CCF GLCC正式开营|九州云开源专家携丰厚奖金,助力高校开源推广
Interviewer: Tell me the difference between NIO and BIO
C# 动态加载卸载 DLL
PAT甲级:1038 Recover the Smallest Number