当前位置:网站首页>Spark based distributed parallel processing optimization strategy - Merrill Lynch data
Spark based distributed parallel processing optimization strategy - Merrill Lynch data
2022-06-26 09:19:00 【Merrill Lynch data tempodata】
because Spark In the use of JDBC When reading relational model data in , Single thread task execution is adopted by default . When the amount of data is large , Memory overflows are often found 、 The problem of low performance . Repartition after expanding memory read , It will consume time , Waste resources .
therefore , Develop and read relational model data concurrently , It can effectively improve the concurrency of task processing , Reduce the amount of data processing for a single task , And then improve the processing efficiency .
Distributed concurrent processing optimization
( One ) General idea
For concurrent reading of relational models, partition fields must be selected first , Determine the interval between concurrent partitions according to the field type and the number of partitions key value . hypothesis key Values can divide the model data evenly into multiple logical partitions , according to key Values constitute query conditions to read model data concurrently . The key points include :
1、 Rules for selecting partition fields
(a) Preliminarily determine the first character or numeric field in the model .
2、 Number of divisions
(a) Give the default number of partitions , After test reading and writing, follow 1000w The data volume gives the recommended resource allocation and the number of default partitions .
(b) Allow users to customize the configuration .
3、 Static partition policy
(a) Numerical type : Convert to characters in reverse order , The interval between concurrent partitions is determined according to the character range of value bits and the number of partitions key value , Carry out multi partition construction .
(b) Character : In reverse order, the interval between concurrent partitions is determined according to the single character value range and the number of partitions key value , Carry out multi partition construction .
( Two ) Overall processing flow
The overall processing flow is shown in the figure :
Rules for verifying and processing the number of partitions : The number of partitions must be within [1,range] Within the scope of , If the lower limit is exceeded, it will be treated as a partition , Exceed the upper limit according to the upper limit range Handle . The maximum number of partitions supported (range) The character type is 64 Of 4 Power , The numerical type is 10000.
( 3、 ... and ) Threshold range concurrent reads
The threshold range can be read concurrently, which is suitable for models with numeric partition fields .
The key parameters :
partitionColumn: Partition field name
lowerBound: Lower limit of value
upperBound: Upper value limit
numPartitions: Number of divisions
( Four ) Default concurrent read
The default concurrent read is for partitioned fields of character and numeric types , Obtain the filter condition of approximate average score according to the value range of the type , Allocate data to different logical partitions according to conditions , And use concurrent execution to improve data reading efficiency .
1、 The model is read concurrently
The model concurrent reading design adopts different interface calling methods according to the number of partitions .
► The number of partitions is 1
val url = "jdbc:mysql://host:3306/test"
val prop = new java.util.Properties
prop.setProperty("user", "***")
prop.setProperty("password", "***")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val df = spark.sqlContext.read.jdbc(url,"tname",prop)
url For database connection string information .
tname Is the table name of the query , Query criteria are also supported , Form like :
(select * from ronghe_mysql_bigint_50wwhere cast(RY_YGGH as UNSIGNED) > 250000)tmp
prop For database connection information 、 user name 、 password 、driver Wait for configuration information .
► The number of partitions is greater than 1
val url = "jdbc:mysql://host:3306/test"
val prop = new java.util.Properties
prop.setProperty("user", "***")
prop.setProperty("password", "***")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val df = spark.sqlContext.read.jdbc(url,"tname",predicates,prop)
The number of concurrent reads from multiple partitions is 1 The partition pre partition condition is added to the parameter of .
among ,predicates Pre partition conditions for partitions ,Array[String], Filter the data according to the content of each element when reading .
2、 Partition pre partition conditions
Partition pre partition condition is string data composed of multiple conditions .
val predicates = Array[String](
" cols < '3'",
" cols >= '3' and cols <'6'",
" cols >= '6'
)
Partition pre partition conditions include partition condition columns and comparison values . The partition condition value consists of the selected partition fields and their operations , The comparison value is the static partition interval value . Consider the ordered numerical type 、 The character type is used in business scenarios. The high order is similar to the low order, and the difference is obvious , Therefore, the partition fields are processed in reverse order .
Assume that the partition field is splitCol.
splitCol When it's a numeric type : Partition condition column cols by reverse(cast(splitColas char)).
splitCol When it is a character type : Partition condition column cols by reverse(splitCol).
Suppose the partition interval value is splitKeys(Array[String]), The length is L. The contrast value is constructed in the way of left closing and right opening .
The first condition is cols < splitKeys(0);
The second condition is cols >= splitKeys(0) and cols < splitKeys(1);
The first i The first condition is cols >= splitKeys(i-2)and cols < splitKeys(i-1);
The last condition is cols >= splitKeys(L-1).
3、 Number of divisions
Model concurrent read design , The partition interval value is represented by four characters . that , The range of values that can be expressed is the fourth power of the number of values that can be taken for each .
Set each character to take 64 individual , The number of values a number can take 10, That is, the maximum number of partitions supported (range): Character (64 Of 4 Power )、 Numerical type (10000).
4、 Get the static partition interval value
Realize the idea
Find the partition interval value according to the character range of the field type , That is, to find the approximate average position point of the range represented by the interval value .
Assume that the partition interval value is represented by four characters .( set up N Zones )
The idea of looking for the interval value of numeric characters :
(1) The number value is [0,9]( The decimal point is not considered for the time being , Bitwise will be assigned less than 0 Corresponding partition ), Scope of representation :1, 2, 3,……,9998,9999.
(2) Find the size range of each partition S, Indicates the number of ranges divided by the number of partitions (10^4/(N-1)).
(3)S-1,2S-1,3S-1,……,(N-1)*S-1 That is, the interval value that can divide the four digits equally .
The idea of finding the interval value of character type ( Value range 64 Characters , optimization algorithm ):
(1) According to the degree of common use , Determine the value range of each character of the interval value as :Array(’.’, ‘0’, ‘1’, ‘2’, ‘3’,‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’,‘K’, ‘L’, ‘M’, ‘N’, ‘O’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’,‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’, ‘j’, ‘k’, ‘l’, ‘m’, ‘n’, ‘o’, ‘p’,‘q’, ‘r’, ‘s’, ‘t’, ‘u’, ‘v’, ‘w’, ‘x’, ‘y’, ‘z’, ‘~’)
(2) Infrequently used characters will be grouped into the nearest partition , Chinese characters will be assigned to the last partition , Avoid exclusive use of a partition by infrequently used characters , To reduce the consumption of resources .
(3) Find the size range of each segment S, Indicates the number of ranges divided by the number of partitions (64^4/(N-1))
(4) The interval value between the same number characters , Interpret character spacing values as 64 Decimal digit ( Shift operation can be used to obtain ), that S-1,2S-1,3S-1,……,(N-1)*S-1 It is a number that approximately divides four characters equally , The string formed by the characters in each corresponding character interval value array is the interval value .
Decimal to 64 Base number , Number in decimal keyInt For example ,tmp Is the result array after conversion :digitsNum Is the number of digits 4.
for (j <- 1 to digitsNum) {
tmp(digitsNum - j) = charactors(keyInt & (charLength - 1))
keyInt >>= 6
}
The idea of finding the interval value of character type ( Any character in the value range , General algorithms ):
It is consistent with the general search idea of character type character interval value , But it is not limited by the number of value ranges .
(1) According to the degree of common use , Determine the value range of each character of the interval value as Array(……), The number of elements is m.
(2) Infrequently used characters will be grouped into the nearest partition , Chinese characters will be assigned to the last partition , Avoid exclusive use of a partition by infrequently used characters , To reduce the consumption of resources .
(3) Find the size range of each segment S, Indicates the number of ranges divided by the number of partitions (m^4/(N-1)).
(4) The interval value between the same number characters , Interpret character spacing values as m Decimal digit , that S-1,2S-1,3S-1,……,(N-1)*S-1 It is a number that approximately divides four characters equally , The string corresponding to these numbers is the interval value of the average character range ( The character string formed by the characters in the character interval value array corresponding to each digit of the number is the interval value ).
Decimal to m Base number , Number in decimal keyInt For example ,tmp Is the result array after conversion :digitsNum Is the number of digits 4.
for (j <- 1 to digitsNum) {
tmp(digitsNum - j) = charactors(keyInt % m)
keyInt = math.floor(keyInt / m).toInt
}
test result
In the data asset platform , With 50 ten thousand 、1000 Million data for synchronous performance test , The test results are shown in the table below :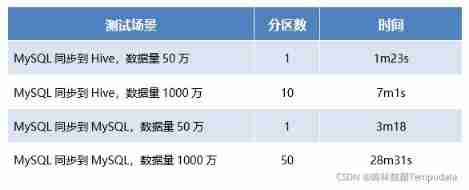
Summary and prospect
Reading data concurrently according to the partition field for processing can effectively improve the data processing capacity , But the value range of the partitioned field 、 The impact of data distribution , The effect is different , In the future, the partition policy will be continuously optimized , To meet the performance requirements of various business scenarios .
边栏推荐
- Error importerror: numpy core. multiarray failed to import
- 【C】青蛙跳台阶和汉诺塔问题(递归)
- Solutions for safety management and control at the operation site
- 3大问题!Redis缓存异常及处理方案总结
- MySQL在服务里找不到(未卸载)
- Yolov5 advanced camera real-time acquisition and recognition
- MATLAB basic operation command
- Applet realizes picture preloading (picture delayed loading)
- Unity connects to Turing robot
- JSON file to XML file
猜你喜欢

Solutions for safety management and control at the operation site

Self taught neural network series - 9 convolutional neural network CNN

设置QCheckbox 样式的注意事项

Master data management of scientific research institutes? Suppliers or customers? I am a correspondent

ThreadLocal
What is optimistic lock and what is pessimistic lock

Phpcms V9 mobile phone access computer station one-to-one jump to the corresponding mobile phone station page plug-in

【C】青蛙跳台阶和汉诺塔问题(递归)
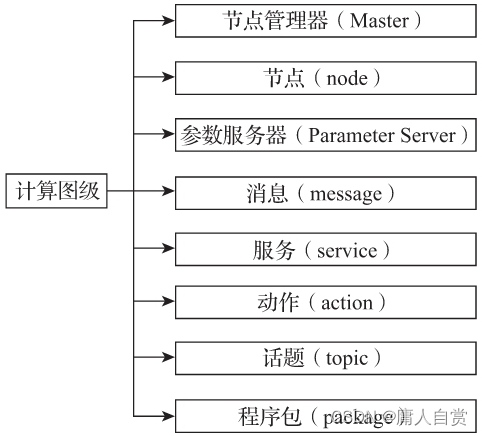
简析ROS计算图级
Analysis of ROS calculation diagram level
随机推荐
Is it safe to dig up money and make new debts
Pycharm [debug] process stuck
Principe et application du micro - ordinateur à puce unique - Aperçu
行为树 文件说明
Self learning neural network series - 8 feedforward neural networks
Principle and application of single chip microcomputer -- Overview
[qnx hypervisor 2.2 user manual]12.1 terminology (I)
HDU - 6225 little boxes (\u int128)
运行时端常用类的介绍
Board end power hardware debugging bug
《一周搞定数电》-逻辑门
51单片机ROM和RAM
Edit type information
"One week's work on Analog Electronics" - Basic amplification circuit
Some commands for remote work
51 single chip microcomputer ROM and ram
MySQL cannot be found in the service (not uninstalled)
Detectron2 draw confusion matrix, PR curve and confidence curve
Unity connects to Turing robot
板端电源硬件调试BUG