当前位置:网站首页>07 data import sqoop
07 data import sqoop
2022-07-02 10:26:00 【Lucky lucky】
The first 1 Chapter Sqoop brief introduction
Sqoop Is an open source tool , Mainly used in Hadoop(Hive) With traditional databases (mysql、postgresql…) Transfer of data between , You can put a relational database ( for example : MySQL ,Oracle ,Postgres etc. ) The data in Hadoop Of HDFS in , Can also be HDFS The data in a relational database .
Sqoop Project starts at 2009 year , First as Hadoop A third-party module of exists , Later in order to allow users to quickly deploy , Also for developers to be able to more rapid iterative development ,Sqoop Become an independent Apache project .
Sqoop2 The latest version of is 1.99.7. Please note that ,2 And 1 Are not compatible , And the features are incomplete , It's not intended for production deployment .
The first 2 Chapter Sqoop principle
Translate the import or export command to mapreduce Program to achieve .
In translation mapreduce Mainly right inputformat and outputformat Customization .
The first 3 Chapter Sqoop install
install Sqoop The premise is that Java and Hadoop Environment .
3.1 Download and unzip
Download address :
http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
http://archive.apache.org/dist/sqoop/1.4.6/
Upload installation package sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz To virtual machine
decompression sqoop Install the package to the specified directory , Such as :
$ tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
3.2 Modify the configuration file
Sqoop The configuration file of is similar to most big data frameworks , stay sqoop In the root directory conf Directory .
1) Rename profile
$ mv sqoop-env-template.sh sqoop-env.sh
2) Modify the configuration file
sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.2
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.2
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export ZOOCFGDIR=/opt/module/zookeeper-3.4.10
export HBASE_HOME=/opt/module/hbase
3.3 Copy JDBC drive
Copy jdbc Drive to sqoop Of lib Under the table of contents , Such as :
$ cp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/
3.4 verification Sqoop
We can go through a certain command To verify sqoop Whether the configuration is correct :
$ bin/sqoop help
There are some Warning Warning ( Warning message omitted ), And with the help command output :
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
3.5 test Sqoop Whether it can successfully connect to the database
$ bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password 000000
The following output appears :
information_schema
metastore
mysql
oozie
performance_schema
The first 4 Chapter Sqoop A simple use case of
4.1 Import data
stay Sqoop in ,“ Import ” The concept refers to : From non big data cluster (RDBMS) To big data cluster (HDFS,HIVE,HBASE) Data transmission in , be called : Import , That is to use import keyword .
4.1.1 RDBMS To HDFS
determine Mysql The service is on normally
stay Mysql Create a new table and insert some data
$ mysql -uroot -p000000
mysql> create database company;
mysql> create table company.staff(id int(4) primary key not null auto_increment, name varchar(255), sex varchar(255));
mysql> insert into company.staff(name, sex) values('Thomas', 'Male');
mysql> insert into company.staff(name, sex) values('Catalina', 'FeMale');
- Import data
(1) Import all
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
(2) Query import
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id <=1 and $CONDITIONS;'
(3) Import the specified column
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,sex \
--table staff
(4) Use sqoop Keyword filter query import data
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--where "id=1"
4.1.2 RDBMS To Hive
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive
4.1.3 RDBMS To Hbase
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table company \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--num-mappers 1 \
--split-by id
hbase> create 'hbase_company,'info'
(5) stay HBase in scan This table shows the following
hbase> scan ‘hbase_company’
4.2、 Derived data
stay Sqoop in ,“ export ” The concept refers to : From big data cluster (HDFS,HIVE,HBASE) To non big data cluster (RDBMS) Data transmission in , be called : export , That is to use export keyword .
4.2.1 HIVE/HDFS To RDBMS
$ bin/sqoop export \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--num-mappers 1 \
--export-dir /user/hive/warehouse/staff_hive \
--input-fields-terminated-by "\t"
4.3 Script packaging
Use opt Format file packaging sqoop command , And then execute
1) Create a .opt file
$ mkdir opt
$ touch opt/job_HDFS2RDBMS.opt
2) To write sqoop Script
$ vi opt/job_HDFS2RDBMS.opt
export
--connect
jdbc:mysql://hadoop102:3306/company
--username
root
--password
000000
--table
staff
--num-mappers
1
--export-dir
/user/hive/warehouse/staff_hive
--input-fields-terminated-by
"\t"
3) Execute the script
$ bin/sqoop --options-file opt/job_HDFS2RDBMS.opt
The first 5 Chapter Sqoop Some common commands and parameters
5.1 List of common commands
Here's a list for you Sqoop Common parameters during operation , For reference , You can refer to the source code of the corresponding class for further learning .
| Serial number | command | class | explain |
|---|---|---|---|
| 1 | import | ImportTool | Import data into the cluster |
| 2 | export | ExportTool | Export cluster data |
| 3 | codegen | CodeGenTool | Get the data of a table in the database to generate Java And pack Jar |
| 4 | create-hive-table | CreateHiveTableTool | establish Hive surface |
| 5 | eval | EvalSqlTool | see SQL Execution results |
| 6 | import-all-tables | ImportAllTablesTool | Import all tables under a database to HDFS in |
| 7 | job | JobTool | Used to generate a sqoop The task of , After generation , The task is not performed , Unless you use the command to perform the task . |
| 8 | list-databases | ListDatabasesTool | List all database names |
| 9 | list-tables | ListTablesTool | List all tables under a database |
| 10 | merge | MergeTool | take HDFS All the data in different directories are put together , And stored in the specified directory |
| 11 | metastore | MetastoreTool | Record sqoop job Metadata information , If it doesn't start metastore example , The default metadata storage directory is :~/.sqoop, If you want to change the storage directory , Can be found in the configuration file sqoop-site.xml Change in . |
| 12 | help | HelpTool | Print sqoop Help information |
| 13 | version | VersionTool | Print sqoop Version information |
5.2 command & Parameters,
I just listed some Sqoop Common commands , For different commands , There are different parameters , Let's list one by one .
Let's first introduce the common parameters , So called common parameters , That's what most commands support .
5.2.1 Common parameters : Database connection
| Serial number | Parameters | explain |
|---|---|---|
| 1 | - -connect | Connected to a relational database URL |
| 2 | - -connection-manager | Specify the connection management class to use |
| 3 | - -driver | Hadoop root directory |
| 4 | - -help | Print help |
| 5 | - -password | Password to connect to the database |
| 6 | - -username | User name to connect to the database |
| 7 | - -verbose | Print out the details in the console |
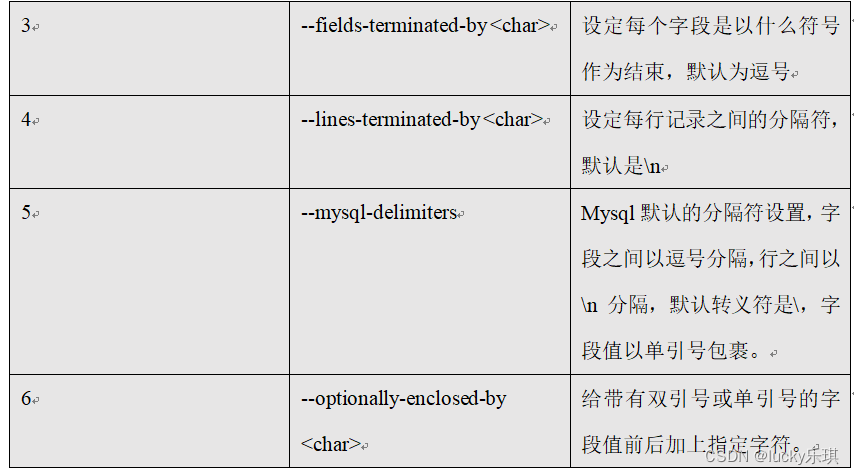
5.2.2 Common parameters :import

5.2.3 Common parameters :export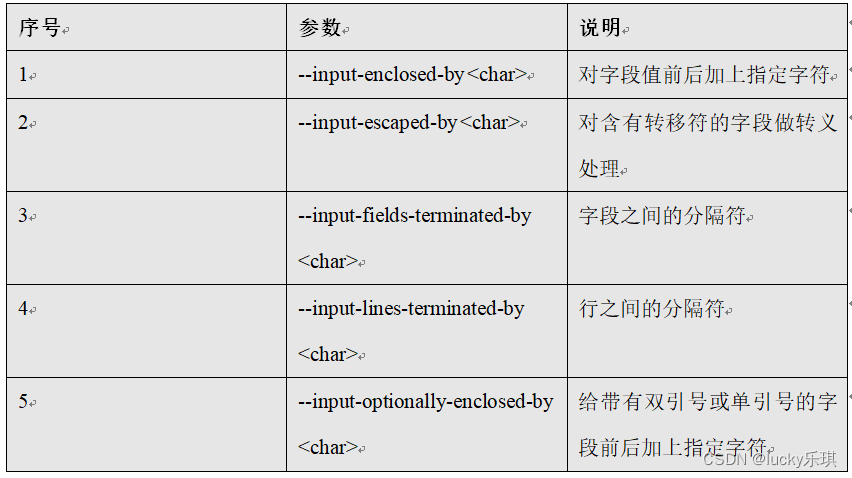
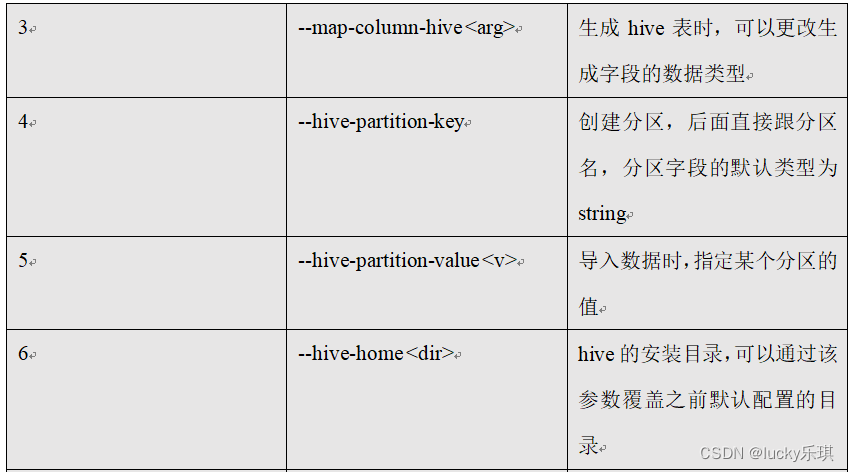
5.2.4 Common parameters :hive


After the introduction of common parameters , Let's follow the command to introduce the specific parameters corresponding to the command .
5.2.5 command & Parameters :import
Import data from a relational database into HDFS( Include Hive,HBase) in , If the import is Hive, So when Hive When there is no corresponding table in , Automatically create .
1) command :
Such as : Import data to hive in
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--hive-import
Such as : Incrementally import data to hive in ,mode=append
append Import :
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--num-mappers 1 \
--fields-terminated-by "\t" \
--target-dir /user/hive/warehouse/staff_hive \
--check-column id \
--incremental append \
--last-value 3
Screaming hint :append Cannot be associated with –hive- Wait for parameters to be used at the same time (Append mode for hive imports is not yet supported. Please remove the parameter --append-mode)
Such as : Incrementally import data to hdfs in ,mode=lastmodified
First in mysql Create a table and insert several pieces of data :
mysql> create table company.staff_timestamp(id int(4), name varchar(255), sex varchar(255), last_modified timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
mysql> insert into company.staff_timestamp (id, name, sex) values(1, 'AAA', 'female');
mysql> insert into company.staff_timestamp (id, name, sex) values(2, 'BBB', 'female');
Import some data first :
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff_timestamp \
--delete-target-dir \
--m 1
Then import part of the data incrementally :
mysql> insert into company.staff_timestamp (id, name, sex) values(3, 'CCC', 'female');
$ bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff_timestamp \
--check-column last_modified \
--incremental lastmodified \
--last-value "2017-09-28 22:20:38" \
--m 1 \
--append
Screaming hint : Use lastmodified The way to import data is to specify that the incremental data is to –append( Additional ) Still –merge-key( Merge )
Screaming hint :last-value The specified value will be included in the incremental imported data
2) Parameters :



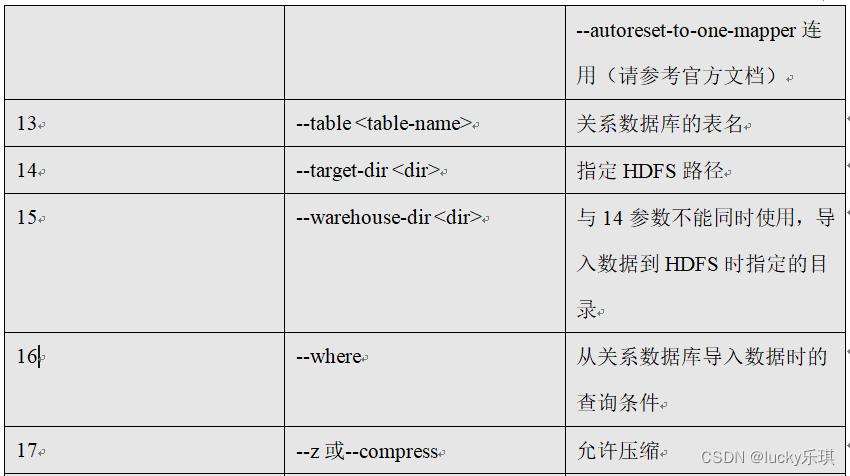
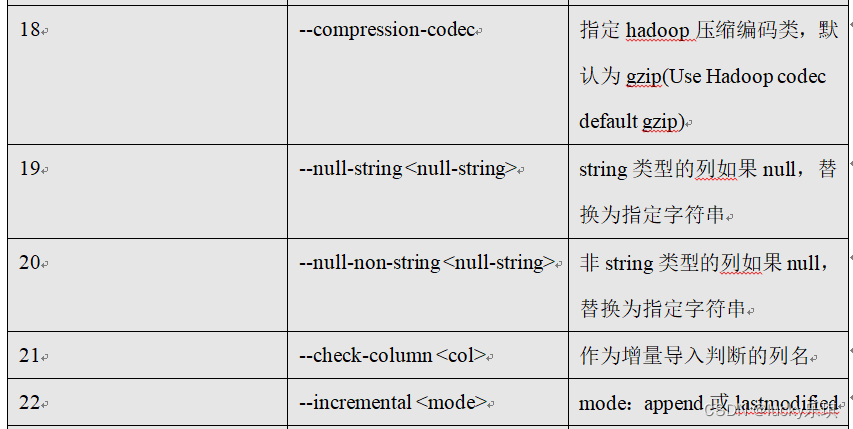
5.2.6 command & Parameters :export
from HDFS( Include Hive and HBase) The winning data is exported to the relational database .
1) command :
Such as :
$ bin/sqoop export \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--export-dir /user/company \
--input-fields-terminated-by "\t" \
--num-mappers 1
2) Parameters :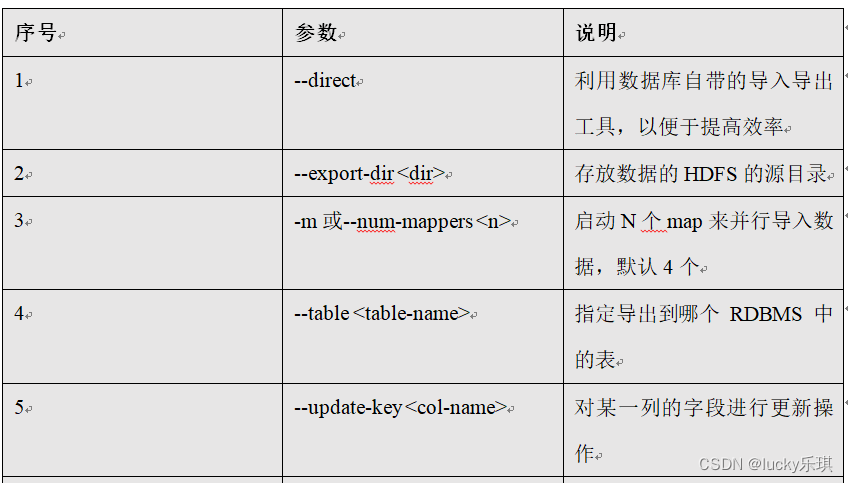


5.2.7 command & Parameters :codegen
Map tables in a relational database to a Java class , There are fields corresponding to each column in this class .
Such as :
$ bin/sqoop codegen \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--bindir /home/admin/Desktop/staff \
--class-name Staff \
--fields-terminated-by "\t"
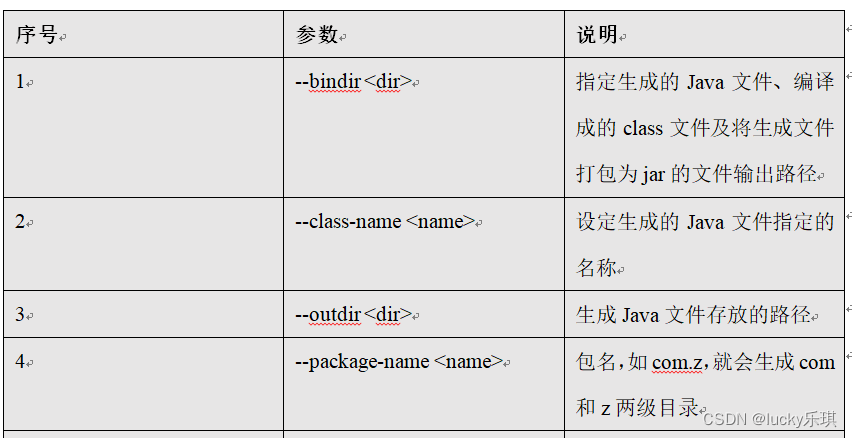

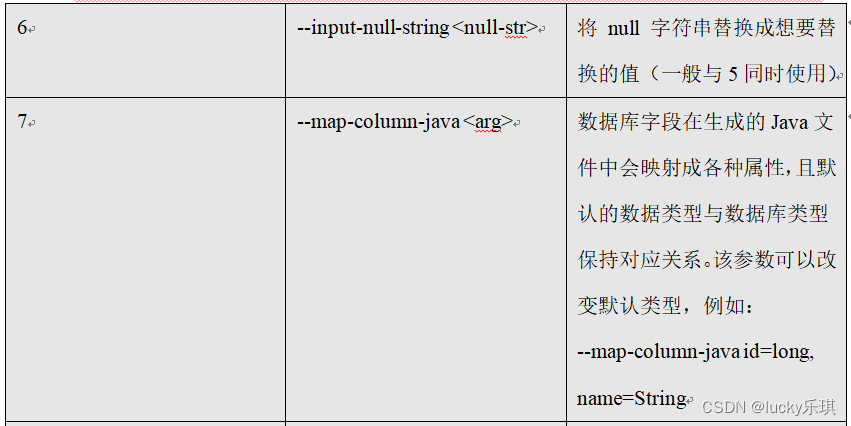
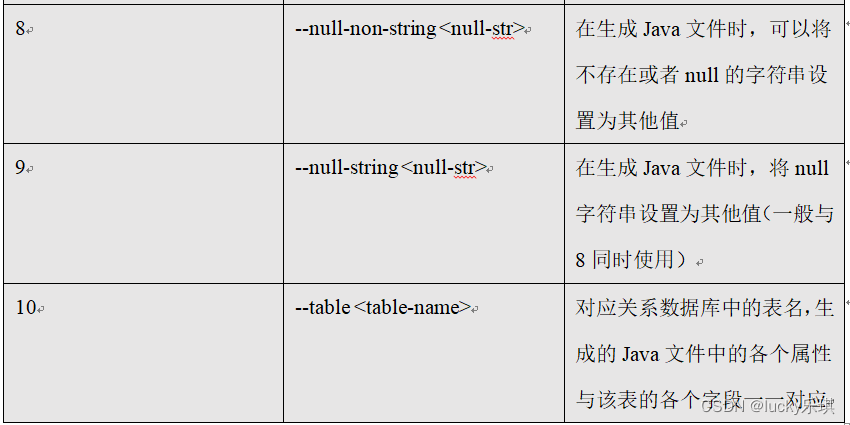
5.2.8 command & Parameters :create-hive-table
Generate the... Corresponding to the table structure of the relational database hive Table structure .
command :
Such as :
$ bin/sqoop create-hive-table \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--hive-table hive_staff
Parameters :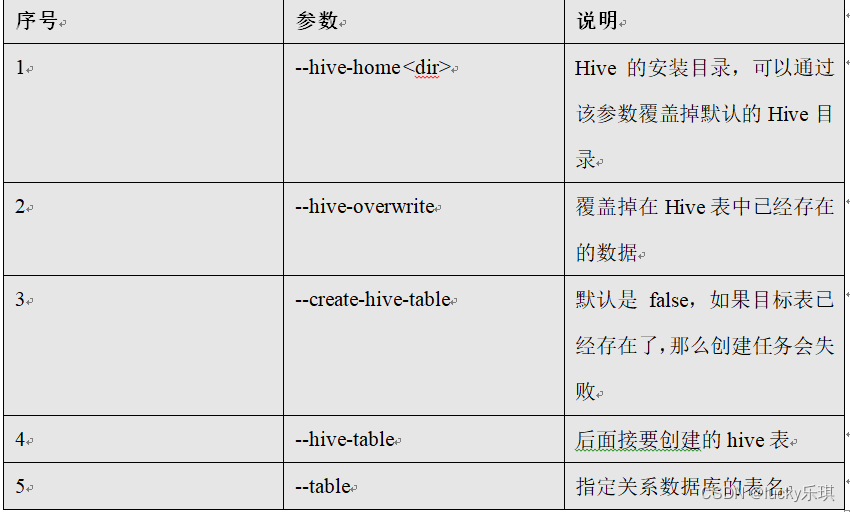
5.2.9 command & Parameters :eval
It can be used quickly SQL Statement to operate on a relational database , Often used in import Before the data , Get to know SQL Is the statement correct , Is the data normal , And the results can be displayed on the console .
command :
Such as :
$ bin/sqoop eval \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--query "SELECT * FROM staff"
Parameters :
5.2.10 command & Parameters :import-all-tables
Can be RDBMS All tables in are imported into HDFS in , Each table corresponds to a HDFS Catalog
command :
Such as :
$ bin/sqoop import-all-tables \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--warehouse-dir /all_tables
Parameters :
5.2.11 command & Parameters :job
Used to generate a sqoop Mission , It will not be executed immediately after generation , It needs to be done manually .
command :
Such as :
$ bin/sqoop job \
--create myjob -- import-all-tables \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000
$ bin/sqoop job \
--list
$ bin/sqoop job \
--exec myjob
Screaming hint : Be careful import-all-tables And the one on the left – There is a space between
Screaming hint : If you need to connect metastore, be –meta-connect jdbc:hsqldb:hsql://linux01:16000/sqoop
Parameters :
Screaming hint : In the execution of a job when , If you need to enter the database password manually , You can do the following optimization
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.</description>
</property>
5.2.12 command & Parameters :list-databases
command :
Such as :
$ bin/sqoop list-databases \
--connect jdbc:mysql://hadoop102:3306/ \
--username root \
--password 000000
** Parameters :** Same as common parameters
5.2.13 command & Parameters :list-tables
command :
Such as :
$ bin/sqoop list-tables \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000
Parameters : Same as common parameters
5.2.14 command & Parameters :merge
take HDFS The data under different directories in is merged and put into the specified directory
Data environment :
new_staff
1 AAA male
2 BBB male
3 CCC male
4 DDD male
old_staff
1 AAA female
2 CCC female
3 BBB female
6 DDD female
Screaming hint : The separator between the columns of the upper data should be \t, The separator between lines is \n, If you copy directly , Please check it .
command :
Such as :
establish JavaBean:
$ bin/sqoop codegen \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--bindir /home/admin/Desktop/staff \
--class-name Staff \
--fields-terminated-by "\t"
Began to merge :
$ bin/sqoop merge \
--new-data /test/new/ \
--onto /test/old/ \
--target-dir /test/merged \
--jar-file /home/admin/Desktop/staff/Staff.jar \
--class-name Staff \
--merge-key id
result :
1 AAA MALE
2 BBB MALE
3 CCC MALE
4 DDD MALE
6 DDD FEMALE
Parameters :

5.2.15 command & Parameters :metastore
Recorded Sqoop job Metadata information , If the service is not started , So default job The storage directory of metadata is ~/.sqoop, Can be found in sqoop-site.xml Revision in China .
command :
Such as : start-up sqoop Of metastore service
$ bin/sqoop metastore
Parameters :
边栏推荐
- Brief analysis of edgedb architecture
- 【Unity3D】无法正确获取RectTransform的属性值导致计算出错
- Eslint reports an error
- How much is it to develop a system software in Beijing, and what funds are needed to develop the software
- 两数之和,求目标值
- Ue5 - AI pursuit (blueprint, behavior tree)
- Sum the two numbers to find the target value
- VLAN experiment
- Alibaba cloud ack introduction
- Message mechanism -- getting to know messages and message queues for the first time
猜你喜欢

sqoop创建job出现的一系列问题解决方法
Configuration programmée du générateur de plantes du moteur illusoire UE - - Comment générer rapidement une grande forêt
![[ue5] two implementation methods of AI random roaming blueprint (role blueprint and behavior tree)](/img/dd/cbe608fcbbbdf187dd6f7312271d2e.png)
[ue5] two implementation methods of AI random roaming blueprint (role blueprint and behavior tree)
Blender multi lens (multi stand) switching
Matlab generates DSP program -- official routine learning (6)
【虚幻4】UMG组件的简介与使用(更新中...)
Mock Server基本使用方法
Blender stone carving

Pytest framework implements pre post
Ue5 - AI pursuit (blueprint, behavior tree)
随机推荐
【虚幻】自动门蓝图笔记
Basic notes of illusory AI blueprint (10000 words)
【Unity3D】无法正确获取RectTransform的属性值导致计算出错
SAP Spartacus express checkout design
Following nym, the new project Galaxy token announced by coinlist is gal
【避坑指南】使用UGUI遇到的坑:Text组件无法首行缩进两格
2837xd code generation module learning (3) -- IIC, ECAN, SCI, watchdog, ECAP modules
About the college entrance examination
Blender摄像机环绕运动、动画渲染、视频合成
2021-09-12
Understand the composition of building energy-saving system
【虚幻4】从U3D到UE4的转型之路
02-taildir source
VLAN experiment
[unity3d] production progress bar - make image have the functions of filled and sliced at the same time
webUI自动化学习
Introduction and Principle notes of UE4 material
2021-09-12
ERROR 1118 (42000): Row size too large (&gt; 8126)
Beautiful and intelligent, Haval H6 supreme+ makes Yuanxiao travel safer