当前位置:网站首页>The strongest installation of the twin tower model, Google is playing "antique" again?
The strongest installation of the twin tower model, Google is playing "antique" again?
2022-07-07 21:55:00 【Zhiyuan community】
The twin tower model has proved to be a very effective modeling method in search and question and answer tasks , The theory and business are quite mature . The two towers share different degrees according to parameters , It usually falls into two categories :Simese dual encoder and Asymmetric dual encoder, The former parameter structure is completely symmetrical , The latter is not completely symmetrical ( Hereinafter referred to as" SDE and ADE).
This paper is after the long silence of the twin towers , Google pushed it to the center of the universe again , And open the strongest export of the twin towers , Explore the differences and connections between the two in detail , More empirical conclusions of the double tower structure are also given through experiments . It is suitable for old drivers to recall classics and Xiaobai again and make a deep and systematic introduction ~
Thesis title :
Exploring Dual Encoder Architectures for Question Answering
Thesis link :
https://arxiv.org/abs/2204.07120
background
First of all, what is popular science SDE and ADE? The dual encoder network structure will text1 and text2 Respectively encoded into vector representation , Then calculate the sum of the two cosine Equidistance function measures its similarity .SDE Is a twin network that fully shares parameters , That is, although it is a double tower , But actually query/user and doc/item Share a set of parameters ;ADE Only some parameters are shared or not shared at all , It is an independent two parameter network . What they have in common is that they will not interact deeply , contrast BERT Is a typical interactive network . A typical application of double tower structure is recall or Rough row , Scenarios that require strict computing speed .

The modeling idea of twin towers is relatively simple and easy to understand . This article is short and concise , The highlight is Provide a more general conclusion under the twin tower application scenario , Explain several questions clearly :
- ADE and SDE stay QA Which one works better on the task ?
- ADE What are the reasons for poor performance ? What's the solution ?
The author draws a reliable conclusion through reasonable and detailed experiments , Xiaobai can also quickly get To how in ( towards ) real ( guide ) Examination ( t ) Do a section ( Remit ) study ( newspaper ).

experiment
The author in QA The retrieval task is carried out 5 An experiment , Calculation query And candidates answer(doc or passage) The similarity of , The evaluation task is MS MARCO and MultiReQA. Model encoder Is based on transformer,cosine As a distance measurement function , The goal is to explore the influence of the sharing degree of parameters on the modeling effect . 5 A group of experimental networks are the standards of Figure 1 SDE and ADE, as well as 3 Variant structure :• ADE with shared token embedder (ADE-STE) • ADE with frozen token embedder (ADE-FTE) • ADE with shared projection layer (ADE-SPL) The experimental results are as follows :

The experimental conclusion :
- ADE Performance on multiple tasks is significantly inferior to SDE. The reasonable explanation given by the author is due to ADE The essence is two networks with different parameters , So the query and doc Map to two completely different vector spaces . This point later gives more powerful evidence .
- ADE-SPL Our performance is comparable to SDE. after 3 The first experiment is the structure proposed by the author to explore the degree of parameter sharing , At the same time, it also gives which part of the network is limited ADE The key to the effect . Just share or fix the bottom token embedder The effect improvement brought by parameters is not obvious , But when the last top-level parameters share a full connection layer , Can get and SDE The effect of proximity . Why? ? The author's guess is because of the last MLP The parameters are constrained to the same vector space again .
To further illustrate the problem , The author conducted another experiment , take NaturalQuestions Test set query and answer Calculate in advance , And then through t-SNE Map and cluster into a two-dimensional space , Be surprised to find ,dual encoder The performance of depends on whether the last two are in a comparable vector space .

边栏推荐
- 【JDBC Part 1】概述、获取连接、CRUD
- 为什么Win11不能显示秒数?Win11时间不显示秒怎么解决?
- [C language] advanced pointer --- do you really understand pointer?
- Open source OA development platform: contract management user manual
- 三元表达式、各生成式、匿名函数
- Jerry's configuration of TWS cross pairing [article]
- Virtual machine network configuration in VMWare
- Tupu digital twin coal mining system to create "hard power" of coal mining
- 强化学习-学习笔记9 | Multi-Step-TD-Target
- An overview of the latest research progress of "efficient deep segmentation of labels" at Shanghai Jiaotong University, which comprehensively expounds the deep segmentation methods of unsupervised, ro
猜你喜欢

The little money made by the program ape is a P!
Talk about relational database and serverless
Have you ever been confused? Once a test / development programmer, ignorant gadget C bird upgrade
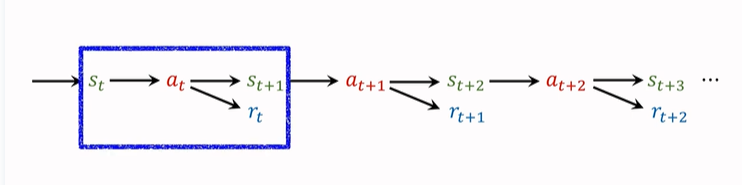
强化学习-学习笔记9 | Multi-Step-TD-Target

How to turn on win11 game mode? How to turn on game mode in win11
![Jerry's test box configuration channel [chapter]](/img/d4/fb67f5ee0fe413c22e4e5cd5037938.png)
Jerry's test box configuration channel [chapter]
The new version of onespin 360 DV has been released, refreshing the experience of FPGA formal verification function
The function is really powerful!
Automatic classification of defective photovoltaic module cells in electronic images
648. Word replacement
随机推荐
Ternary expressions, generative expressions, anonymous functions
Devil daddy B1 hearing the last barrier, break through with all his strength
How does win11 unblock the keyboard? Method of unlocking keyboard in win11
Jerry's about TWS channel configuration [chapter]
Goal: do not exclude yaml syntax. Try to get started quickly
How much does it cost to develop a small program mall?
Build your own website (18)
Kirin Xin'an operating system derivative solution | storage multipath management system, effectively improving the reliability of data transmission
Deadlock conditions and preventive treatment [easy to understand]
Usage of MySQL subquery keywords (exists)
为什么Win11不能显示秒数?Win11时间不显示秒怎么解决?
Reinforcement learning - learning notes 9 | multi step TD target
Win11如何解禁键盘?Win11解禁键盘的方法
Solve the problem of using uni app mediaerror mediaerror errorcode -5
单词反转实现「建议收藏」
Focusing on safety in 1995, Volvo will focus on safety in the field of intelligent driving and electrification in the future
Wechat official account oauth2.0 authorizes login and displays user information
Actual combat: sqlserver 2008 Extended event XML is converted to standard table format [easy to understand]
Win11U盘不显示怎么办?Win11插U盘没反应的解决方法
HOJ 2245 浮游三角胞(数学啊 )