当前位置:网站首页>DAB-DETR: DYNAMIC ANCHOR BOXES ARE BETTER QUERIES FOR DETR翻译
DAB-DETR: DYNAMIC ANCHOR BOXES ARE BETTER QUERIES FOR DETR翻译
2022-07-06 21:39:00 【jjw_zyfx】
点击下载论文
代码
摘要
我们在本篇论文中展示一种新颖的查询公式,即在 DETR上使用动态锚框 (DEtection TRansformer)并深入了解查询在DETR中的作用。这种新公式直接使用盒子坐标作为Transformer解码器中的查询并动态的逐层更新他们。使用方框坐标不仅有助于使用显式位置先验来改进特征相似性查询,消除DETR中训练收敛缓慢的问题,而且允许我们使用方框宽度和高度信息调整位置注意力图。这样的设计清楚地表明,DETR中的查询可以实现为以级联方式逐层执行软ROI池。因此,在相同设置下,在基于DETR的检测模型中,它在MS-COCO基准上的性能最好,例如,使用ResNet50-DC5作为骨架训练50轮的AP为45.7%。我们还进行了大量实验来验证我们的分析,并验证了我们方法的有效性。代码位于https://github.com/SlongLiu/DAB-DETR.
1、引言
目标检测是计算机视觉中一项具有广泛应用的基本任务。大多数经典检测器是基于卷积架构的,在过去十年中取得了显著进展(Ren等人,2017;Girshick,2015;Redmon等人,2016;Bochkovskiy等人,2020;Ge等人,2021)。最近,Carion等人(2020)提出了一种基于 Transformer的端到端的检测器,并名为DETR(DEtection TRansformer),它消除了手动设计组件的需要,例如锚框,与现代基于锚框的检测器(例如Faster RCNN)相比,表现出了良好的性能(Ren等人,2017)。
与基于锚框的检测器相比, DETR 模型将目标检测作为一组预测问题,并使用100个可学习查询来探测和池化图像中的特征,从而在不需要使用非最大抑制的情况下进行预测,然而,由于其查询的设计和使用效率低下,DETR的训练收敛速度非常慢,通常需要500个周期才能实现良好的性能。为了解决这一问题,许多后续工作试图改进DETR查询的设计,以实现更快的训练收敛和更好的性能(Zhu et al., 2021; Gao et al., 2021; Meng et al., 2021; Wang et al., 2021).
尽管取得了这些进展,但学习查询在DETR中的作用仍然没有得到充分理解或利用。虽然之前的大多数尝试使DETR中的每个查询更明确地与一个特定的空间位置相关联,而不是与多个位置相关联,但技术解决方案有很大不同。例如, Conditional DETR通过基于内容特征调整查询来更好地匹配图片特征来学习条件空间查询。
在这些研究的推动下,我们进一步研究了Transformer解码器中的交叉注意力模块,并建议使用锚盒,即4D盒坐标(x、y、w、h)作为DETR中的查询,并逐层更新他们。这种新的查询公式通过考虑每个锚盒的位置和大小,为交叉注意力模块引入了更好的空间先验,这也导致了更简单的实现和对DETR中的查询的作用有了更深入的理解。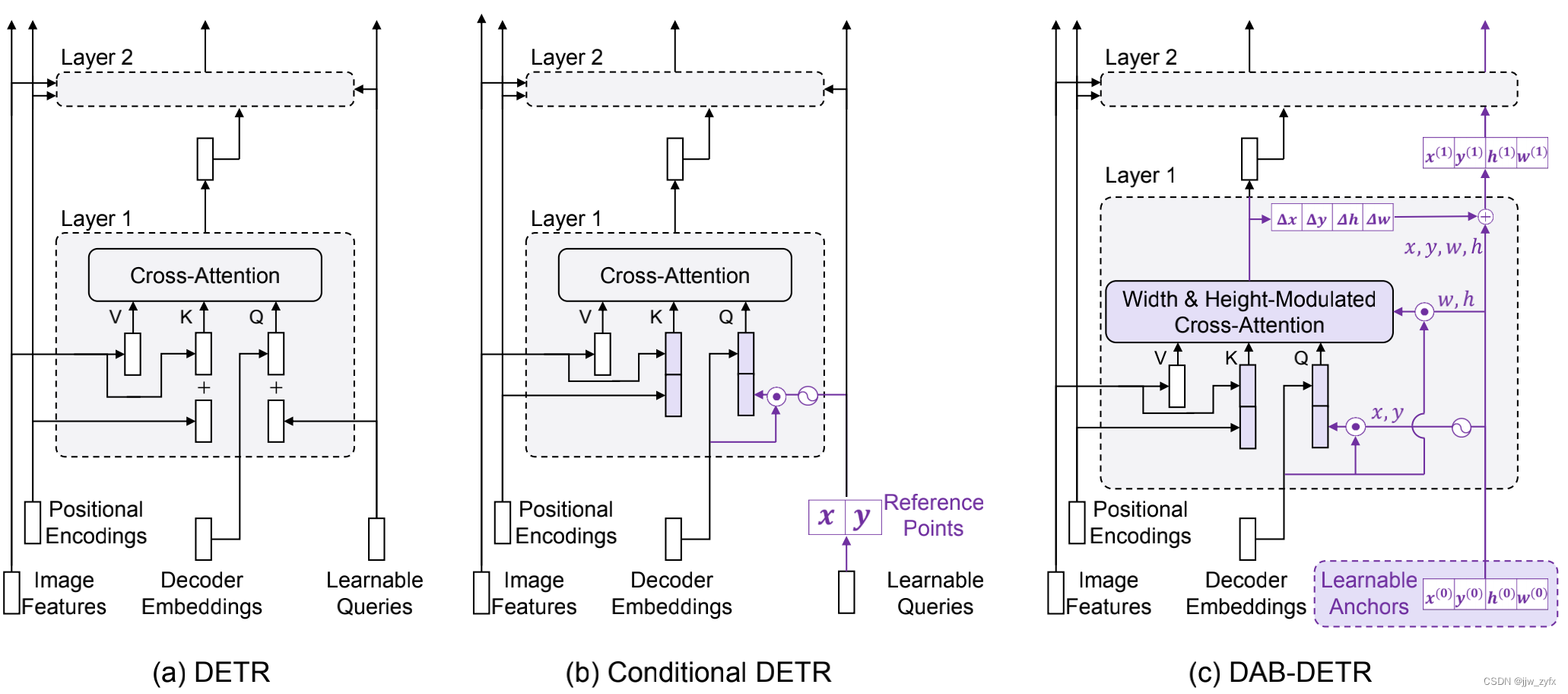
Figure 1: DETR, Conditional DETR和我们提出的DAB-DETR的比较。为了清楚起见,我们只显示Transformer解码器中的交叉注意力部分。(a) DETR对所有层使用可学习查询,没有任何自适应,这是其训练收敛缓慢的原因。(b) Conditional DETR主要对每一层的可学习查询进行调整,以提供更好的参考查询点来池化图片特征图中的特征。相反,(c)DAB-DETR直接使用动态更新的锚盒来提供参考查询点(x,y)和参考锚大小(w,h),以改进交叉注意力计算。我们用紫色标记模块之间的差异。
该公式背后的关键见解是,DETR中的每个查询由两部分组成:内容部分(解码器自注意力输出)和位置部分(例如,DETR中的可学习查询)。交叉注意力权重是通过将查询与一组键进行比较来计算的,该键由两部分组成,即内容部分(编码图像特征)和位置部分(位置嵌入)。因此,Transformer解码器中的查询可以解释为基于查询到特征相似性度量的特征图中的特征池,该特征池同时考虑了内容和位置信息。虽然内容相似性用于池化语义相关的特征,但位置相似性为查询位置周围的池化特征提供位置约束。这种注意力计算机制促使我们将查询表述为锚定框,如图1(c)所示,允许我们使用锚定框的中心位置(x,y)来池化中心周围的特征,并使用锚定框的(w,h)来调节交叉注意力图,使其适应锚定框大小。此外,由于使用坐标作为查询,锚定框可以被逐层动态更新。这样,DETR中的查询可以实现为以级联方式逐层执行软ROI池。
我们通过使用锚框大小来调节交叉注意力,为池化特征提供了更好的先验位置。由于交叉注意力可以池化整个特征图中的特征,因此为每个查询提供适当的先验位置是至关重要,以使交叉注意力模块聚焦于与目标对象对应的局部区域。它还可以加速DETR的训练收敛速度。大多数以前的工作通过将每个查询与特定位置相关联来改进DETR,但它们假设固定大小的各向同性高斯位置先验,这不适用于不同尺度的对象。利用每个查询锚框中可用的信息(w,h),我们可以将高斯位置先验调制为椭圆形。更具体地说,我们将交叉注意力权重(在softmax之前)的x部分和y部分分别除以宽度和高度,这有助于高斯先验更好地匹配不同尺度的对象。为了进一步改进位置先验,我们还引入了一个温度参数来调整位置注意的波动,这在以前的所有工作中都被忽略了。
总之,我们提出的DAB-DETR(动态锚盒DETR)通过直接学习锚框作为查询,呈现了一种新的模拟查询。该公式对查询的作用有了更深入理解,允许我们使用锚框来调节Transformer解码器中的位置交叉注意力图,并逐层执行动态锚框更新。我们的结果表明,在相同的COCO目标检测基准设置下,DAB-DETR在类DETR架构中获得了最佳性能。当使用单个ResNet-50(He等人,2016)模型作为骨架训练50轮时,我们所提的方法可以实现45.7%的AP。我们还进行了大量实验来验证我们的分析,并验证了我们方法的有效性。
2、相关工作
大多数经典检测器是基于锚框的,使用锚框(Ren等人,2017;Girshick,2015;Sun等人,2021)或锚点(Tian等人,2019;Zhou等人,2019)。相反,DETR(Carion等人,2020)是一种完全无锚检测器,使用一组可学习向量作为查询。许多后续工作试图从不同角度解决DETR收敛缓慢的问题。Sun等人(2020)指出,DETR训练缓慢的原因是由于解码器中的交叉注意力,因此提出了一种仅编码器模型。Gao 等人(2021)引入了高斯先验来控制交叉注意力。尽管他们的性能有所提高,但他们没有对训练速度慢以及查询在DETR中的作用给出一个恰当的解释。
改进DETR的另一个方向与我们的工作更相关,即深入理解查询在DETR中的作用。由于DETR中的可学习查询通常用于为特征池化提供位置约束,大多数相关工作试图使DETR中的每个查询与特定空间位置相关更明确,而不是与普通DETR中的多个位置模式相关。例如,Deformable DETR(Zhu等人,2021)直接将2D参考点视为查询,并预测每个参考点的可变形采样点,以执行可变形交叉注意力操作。Deformable DETR(Meng等人,2021)将注意力公式解耦,并基于参考坐标生成位置查询。Efficient DETR(Yao等人,2021)引入了密集预测模块,来选出top-K位置作为目标查询。尽管这些工作将查询与位置信息联系起来,但它们对使用锚框没有给出明确的公式。
Table 1:具有代表性的相关模型与我们的DAB-DETR模型的比较。术语“学习合唱?”询问模型是否直接学习2D点或4D锚框作为可学习参数。术语“参考锚框”是指是否模型预测相对于参考点/锚框的相对坐标。术语“动态锚框”表示模型是否逐层更新锚框。术语“标准注意力”意思是模型是否在交叉注意力模块中利用了标准密集注意力。术语“物体尺度调整注意力”是指注意力是否经过调整以更好地匹配多尺度目标。术语“大小调整注意力”是指注意力是否经过调整以更好地匹配多尺度目标。术语“更新空间学习过的查询?”表示学习过的查询是否逐层更新。注意,稀疏RCNN不是类似DETR的架构。我们在这里列出了它们与我们类似的锚框公式。对这些模型进行更详细的比较看附录B。
与以往工作中可学习查询向量包含盒子坐标信息的假设不同,我们的方法基于一个新的视角,即查询中包含的所有信息都是盒子坐标。也就是说,对于DETR来说锚框是更好的查询。同时期的工作Anchor DETR(Wang等人,2021)也建议直接学习锚点,而与之前的其他工作一样,它忽略了锚点宽度和高度信息。除DETR外,Sun等人(2021)提出了一种通过直接学习盒子的稀疏检测器,该检测器与我们具有类似的锚框公式,它抛弃了Transformer结构,并利用硬ROI对齐进行特征提取。表1总结了这些相关工作与我们所提出的DAB-DETR之间的主要差异。我们在五个维度上将我们的模型与相关的工作进行了比较:是否模型直接学习锚框,是否模型预测参考坐标(在其中间阶段),是否模型逐层更新参考锚框,是否模型使用标准密集交叉注意力,是否注意力被调制以更好地匹配不同比例的对象。是否模型会逐层更新已学过的查询。类似DETR模型的更详细比较见附录B。对于对表格有疑问的读者,我们推荐本节内容。
3、为什么一个位置先验可以加快训练?
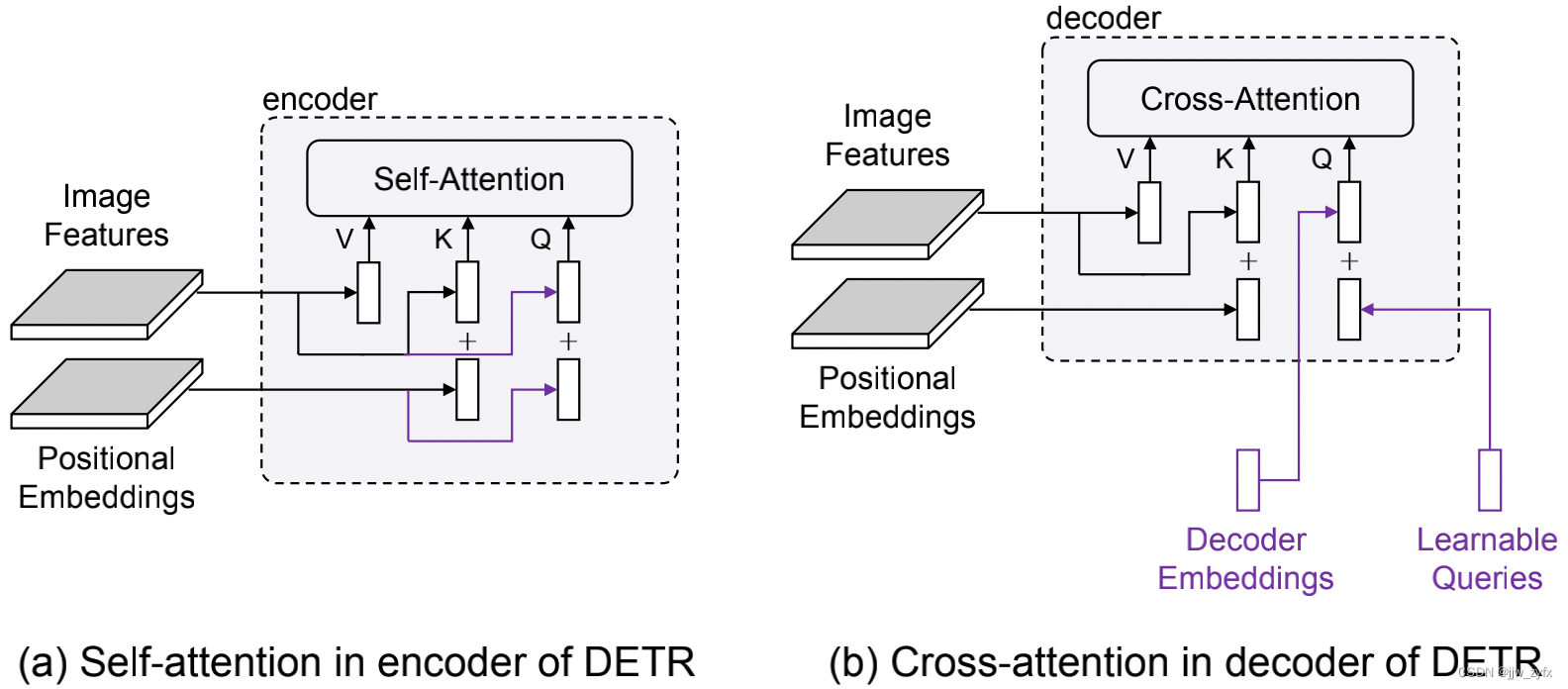
**Figure 2: **DETR编码器中的自注意力和解码器中的交叉注意力的比较。于它们具有相同的键和值组件,所以唯一的区别在于查询。编码器中的每个查询由图像特征(内容信息)和位置嵌入(位置信息)组成,而解码器中的每个查询由解码器嵌入(内容信息)和可学习查询(位置信息)组成。两个模块之间的差异用紫色标记出来。
已经有很多工作来加快DETR的训练收敛速度,但对其方法的有效性的原因缺乏统一的理解。Sun等人(2020)表明,交叉注意力模块是慢收敛的主要原因,但是他们为了更快的训练而简单的删除了解码器。我们根据他们的分析,找出交叉注意力中的哪个子模块会影响性能。比较编码器中的自注意力模块和解码器中的交叉注意力模块,我们发现其输入之间的关键差异来自查询,如图2所示。当解码器嵌入初始化为0时,它们被投影到与第一个交叉注意力模块后的相同的空间作为图像特征。之后,它们将在解码器层中经历与编码器层中的图像特征相似的过程。因此,根本原因可能是由于可学习的查询。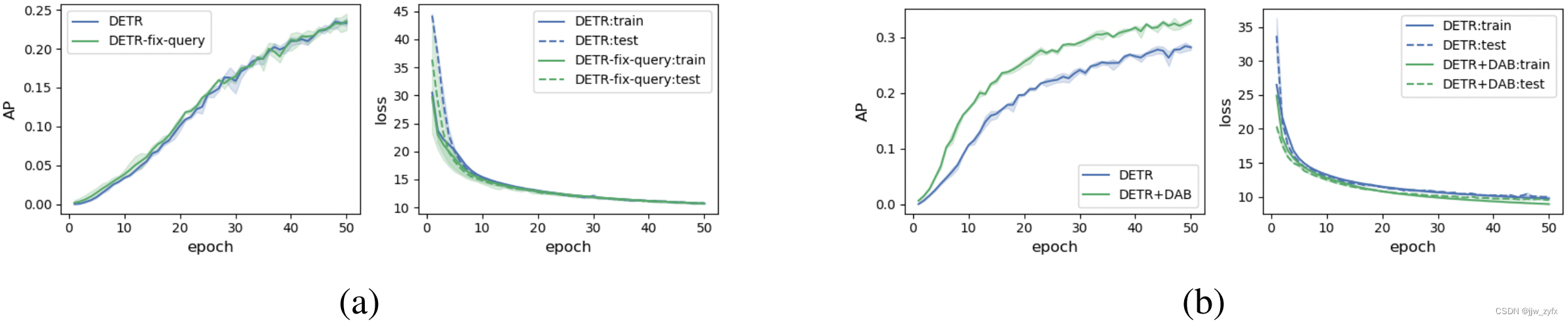
Figure 3: a):原始DETR和具有固定查询的DETR的训练曲线。b) :原始DETR和DETR+DAB的训练曲线。我们将每个实验运行3遍,并绘制每个项目的平均值和95%置信区间。
交叉注意力导致模型慢收敛的两个原因:1)由于优化挑战,很难学习查询;2)已学习的查询中的位置信息编码方式与用于图像特征的正弦位置编码方式不同。为了确定这是否是第一个原因,我们重用了来自DETR的经过良好学习的查询(保持它们固定),只训练其他模块。图3(a)中的训练曲线表明,固定查询仅在非常早期的阶段(例如前25轮)略微改善了收敛性。因此,查询学习(或优化)可能不是关键问题。
Figure 4:我们为DETR、Conditional DETR和我们提出的DAB-DETR可视化了在位置查询和位置键之间的位置注意力。(a)中的四个注意力图是随机抽样的,我们在(b)和(c)上选择了与(a)中相似查询位置的图形。颜色越深,注意力权重越大,反之亦然。(a) DETR中的每个注意力图都是通过来自一个特征图中的已学习的查询和位置嵌入之间执行点积来计算的,并且可以具有多种模式和非集中注意力。(b) Conditional DETR中的位置查询与图像位置嵌入以相同的方式编码,从而生成类似高斯的注意力图。然而,它不适应不同尺度的目标。(c)DABDETR使用锚点的宽度和高度信息显式调整注意力地图,使其更适合对象大小和形状。调整的注意力可以被视为有助于执行软ROI池。
然后,我们转向第二种可能性,并试图找出已学习的查询是否具有一些不需要的属性。由于已学习的查询用于过滤某些区域中的目标,我们在图4(a)中可视化了一些在已学习的查询和图像特征位置嵌入之间的位置注意图。每个查询可以被视为一个位置先验让解码器关注感兴趣的区域。虽然它们作为位置约束,但也具有不需要的属性:多模式和几乎均匀的注意力权重。例如,图4(a)顶部的两个注意力图具有两个或多个集中中心,当图像中存在多个目标时,很难定位目标。图4(a)的底图聚焦在过大或过小的区域,因此无法将有用的位置信息注入特征提取过程。我们推测,DETR中查询的多模特性可能是其训练慢的根本原因,我们认为引入显式位置先验来约束局部区域上的查询对于训练是可取的。为了验证这一假设,我们用动态锚框取代DETR中的查询公式,动态锚盒可以强制每个查询集中在特定区域,并将此模型命名为DETR+DAB。图3(b)中的训练曲线表明,在检测AP和训练/测试损失方面,与DETR相比,DETR+DAB具有更好的性能。注意,DETR和DETR+DAB之间的唯一区别是查询的公式化,没有引入其他技术,如300查询或焦点丢失。结果表明,在解决了DETR查询的多模式问题后,我们可以实现更快的训练收敛速度和更高的检测精度。
之前的一些工作也有类似的分析,并证实了这一点。例如,SMCA(Gao等人,2021)通过在参考点周围应用预定义的高斯映射来加速训练。条件DETR(Meng等人,2021)使用显式位置嵌入作为位置查询进行训练,产生类似于高斯核的注意力图,如图4(b)所示。虽然显式位置先验在训练中表现良好,但它们忽略了目标的尺度信息。相反,我们提出的DAB-DETR明确考虑了目标比例信息,以自适应调整注意力权重,如图4(c)所示。
4、DAB-DETR
4.1、概述
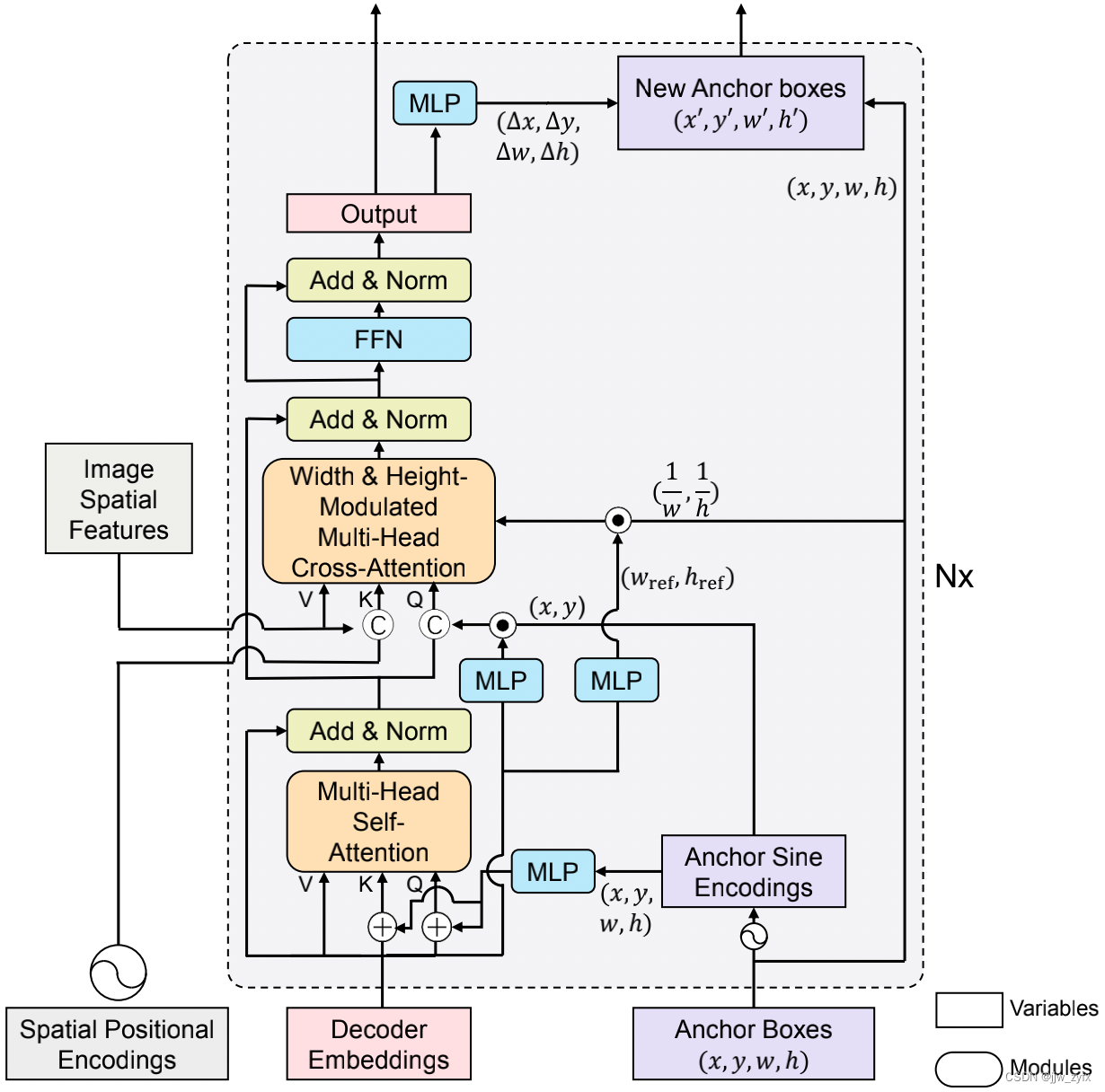
Figure 5:我们所提的DAB-DETR的框架
继DETR(Carion等人,2020年)之后,我们的模型是一种端到端目标检测器,它包含了一个CNN骨架,Transformer(Vaswani等人,2017年)编码器和解码器,以及盒子和标签的预测头。我们主要改进了解码器部分,如图5所示。
给定一个图片我们用CNN 作为骨架来提取图片的空间特征,然后用 Transformer 编码器去精炼CNN的特征,然后,将包括位置查询(锚盒)和内容查询(解码器嵌入)的双重查询输入解码器,来探测与锚框相对应且与内容查询具有相似模式的目标。双重查询将逐层更新来逐渐接近真实的目标对象。最终解码器层的输出通常通过预测头预测带有标签和盒子的目标,然后进行二分图匹配以计算DETR中的损失。为了说明我们的动态锚箱的通用性,我们还设计了一种更强大的DABDeformable-DETR,详见附录。
4.2、直接学习锚框
如第一部分中所述的DETR中查询的作用,我们建议直接学习查询框或锚框,并从这些锚框中导出位置查询。每个解码器层有两个注意力模块,包括自注意力模块和交叉注意力模块,分别用于查询更新和特征探测。每个模块都需要查询、键和值来执行基于注意力的值聚合,但这些三元组的输入不同。我们将 A q = ( x q , y q , w q , h q ) A_q=(x_q,y_q,w_q,h_q) Aq=(xq,yq,wq,hq)表示为第q个锚点, x q , y q , w q , h q ∈ R 、 和 C q ∈ R D 和 P q ∈ R D x_q,y_q,w_q,h_q∈ \Bbb R、 和C_q∈ \Bbb R^D和P_q∈ \Bbb R^D xq,yq,wq,hq∈R、和Cq∈RD和Pq∈RD作为其相应的内容查询和位置查询,其中D是解码器嵌入和位置查询的维度。
给定一个锚框 A q A_q Aq,他的位置查询 P q P_q Pq通过如下公式生成: P q = M L P ( P E ( A q ) ) , ( 1 ) P_q = \mathbf{MLP(PE}(A_q)), \quad\quad\quad\quad\quad\quad\quad(1) Pq=MLP(PE(Aq)),(1)其中,PE表示从浮点数中生成正弦嵌入的位置编码,MLP的参数在所有层中共享。由于Aq是四元数,我们在这里重载PE运算符: P E ( A q ) = P E ( x q , y q , w q , h q ) = C a t ( P E ( x q ) , P E ( y q ) , P E ( w q ) , P E ( h q ) ) . ( 2 ) \mathbf{PE}(A_q) = \mathbf{PE}(x_q, y_q, w_q, h_q) = \mathbf{Cat(PE}(x_q), \mathbf{PE}(y_q), \mathbf{PE}(w_q), \mathbf{PE}(h_q)).\quad\quad(2) PE(Aq)=PE(xq,yq,wq,hq)=Cat(PE(xq),PE(yq),PE(wq),PE(hq)).(2) Cat的是串联函数。在我们的实现中,位置编码函数PE将浮点数映射到D/2维的向量:如PE: R → R D / 2 \Bbb R\rightarrow\Bbb R^{D/2} R→RD/2。因此,函数MLP将2D维向量投影到D维:MLP: R 2 D → R D \Bbb R^{2D}\rightarrow\Bbb R^{D} R2D→RD,MLP模块有两个子模块,每个子模块由线性层和ReLU激活函数组成,在第一个线性层进行特征压缩。
在自注意力模块中,三个查询、键和值都具有相同的内容项,而查询和键包含额外的位置项: S e l f − A t t n : Q q = C q + P q , K q = C q + P q , V q = C q , ( 3 ) \mathbf{Self-Attn}: Q_q = C_q + P_q, K_q = C_q + P_q, V_q = C_q, \quad\quad\quad\quad(3) Self−Attn:Qq=Cq+Pq,Kq=Cq+Pq,Vq=Cq,(3)
受Conditional DETR(Meng等人,2021)的启发,我们将位置和内容串联在一起,作为交叉注意力模块中的查询和键,因此,我们可以将内容和位置对查询到特征相似性的贡献解耦,该相似性计算为查询和键之间的点积。为了重新缩放位置嵌入,我们还利用了条件空间查询(Meng等人,2021)。更具体地说,我们学习 M L P ( c s q ) : R D → R D \mathbf{MLP}^{(csq)}: \Bbb R^D\rightarrow\Bbb R^D MLP(csq):RD→RD 获得基于内容信息的比例向量,并用它与位置嵌入执行元素乘法: C r o s s − A t t n : Q q = C a t ( C q , P E ( x q , y q ) ⋅ M L P ( c s q ) ( C q ) ) , \mathbf{Cross-Attn: }\quad\quad\quad\quad\quad Q_q = \mathbf{Cat}(C_q, \mathbf{PE}(x_q, y_q) · \mathbf{MLP}^{(csq)}(C_q)), Cross−Attn:Qq=Cat(Cq,PE(xq,yq)⋅MLP(csq)(Cq)), K x , y = C a t ( F x , y , P E ( x , y ) ) , V x , y = F x , y , ( 4 ) \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad K_{x,y} = \mathbf{Cat}(F_{x,y}, \mathbf{PE}(x, y)), V_{x,y} = F_{x,y},\quad\quad\quad(4) Kx,y=Cat(Fx,y,PE(x,y)),Vx,y=Fx,y,(4)其中 F x , y ∈ R D F_{x,y} ∈ \Bbb R^D Fx,y∈RD是位置(x,y)处的图像特征,·是元素乘法。查询和键中的位置嵌入都是基于二维坐标生成的,这使得比较位置相似性更加一致,正如(Meng等人,2021;Wang等人,2021)之前的工作。
4.3、锚框更新
使用坐标作为学习查询,可以逐层更新坐标。相反,对于高维嵌入的查询,例如DETR(Carion等人,2020)和Conditional DETR(Meng等人,2021),很难执行逐层查询细化,因为不清楚如何将更新的锚转换回高维查询嵌入。
根据之前的实践(朱等人,2021;王等人,2021),我们通过预测头预测相对位置 (∆x, ∆y, ∆w, ∆h)然后后更新每层中的锚。如图5所示。注意,不同层中的所有预测头共享相同的参数。
4.4、宽度和高度调制高斯核

Figure 6:由宽度和高度调整的位置注意力图。
传统的位置注意力图被用作高斯先验,如左侧图6所示。但先验只是假设对所有对象的各向同性和固定大小,忽略其尺度信息(宽度和高度)。为了改进位置先验,我们建议将尺度信息注入注意力图中。
原始位置注意力图中的键相似性查询计算为两个坐标编码的点积之和: A t t n ( ( x , y ) , ( x r e f , y r e f ) ) = ( P E ( x ) ⋅ P E ( x r e f ) + P E ( y ) ⋅ P E ( y r e f ) ) / D , ( 5 ) \mathbf{Attn}((x, y),(x_{ref}, y_{ref})) = ( \mathbf{PE}(x) · \mathbf{PE}(x_{ref}) + \mathbf{PE}(y) · \mathbf{PE}(y_{ref}))/\sqrt D, \quad\quad(5) Attn((x,y),(xref,yref))=(PE(x)⋅PE(xref)+PE(y)⋅PE(yref))/D,(5)其中其中 1 / D 1/\sqrt D 1/D用于重新缩放值和Vaswani等人(2017)的建议一样。我们(在 softmax之前) 通过分别除以来自x部分和y部分的相对锚框的宽和高来调整位置注意力图,以平滑高斯先验,从而更好地匹配不同尺度的对象: M o d u l a t e A t t n ( ( x , y ) , ( x r e f , y r e f ) ) = ( P E ( x ) ⋅ P E ( x r e f ) w q , r e f w q + P E ( y ) ⋅ P E ( y r e f ) h q , r e f h q ) / D , ( 6 ) \mathbf{ModulateAttn}((x, y),(x_{ref}, y_{ref})) = ( \mathbf{PE}(x) · \mathbf{PE}(x_{ref})\frac{w_{q,ref}}{w_q }+ \mathbf{PE}(y) · \mathbf{PE}(y_{ref})\frac{h_{q,ref}}{h_q})/\sqrt D, (6) ModulateAttn((x,y),(xref,yref))=(PE(x)⋅PE(xref)wqwq,ref+PE(y)⋅PE(yref)hqhq,ref)/D,(6)其中其中, w q 和 h q 是 锚 A q w_q和h_q是锚A_q wq和hq是锚Aq的宽度和高度, w q , r e f 和 h q , r e f w_{q,ref}和h_{q,ref} wq,ref和hq,ref是参考宽度和高度是通过以下公式计算的: w q , r e f , h q , r e f = σ ( M L P ( C q ) ) . ( 7 ) w_{q,ref}, h_{q,ref} = σ(\mathbf{MLP}(C_q)).\quad\quad\quad\quad\quad\quad(7) wq,ref,hq,ref=σ(MLP(Cq)).(7)这种调整过的位置注意力有助于我们提取不同宽度和高度的目标的特征,调整过的注意力的可视化如图6所示。
4.5、温度调节
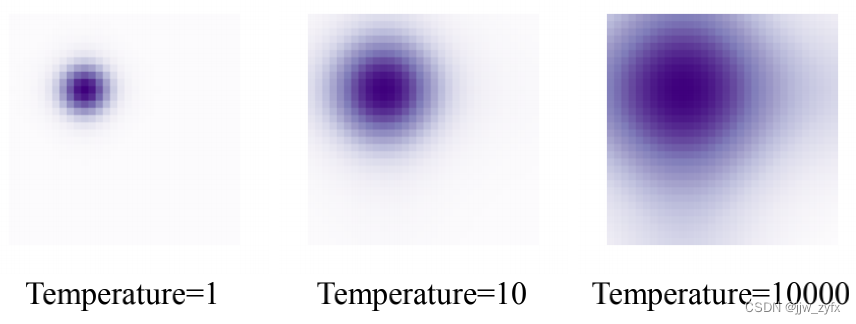
Figure 7:不同温度下的位置注意力图
对于位置编码,我们使用正弦函数(Vaswani等人,2017),其定义为: P E ( x ) 2 i = s i n ( x T 2 i / D ) , P E ( x ) 2 i + 1 = c o s ( x T 2 i / D ) , ( 8 ) \mathbf{PE}(x)_{2i} = sin(\frac{x}{T^{2i/D}}), \mathbf{PE}(x)_{2i+1} = cos(\frac{x}{T^{2i/D}}), \quad\quad\quad(8) PE(x)2i=sin(T2i/Dx),PE(x)2i+1=cos(T2i/Dx),(8)其中T是手动设计温度,上标2i和2i+1表示编码向量中的指数。等式(8)中的温度T影响位置先验的大小,如图7所示。T越大,注意力图越平坦,反之亦然。注意,在自然语言处理中,温度T被(Vaswani等人,2017)硬编码为10000,其中x的值是整数表示单词在句子中的位置。然而,在DETR中,x的值是介于0和1之间的浮点值,表示边界框坐标。因此,对于视觉任务需要非常高温度值这一点与NLP不同。在这项工作中,我们在所有模型中根据经验选择T=20。
5 、实验
我们在附录A中展示了训练细节。
5.1、主要结果
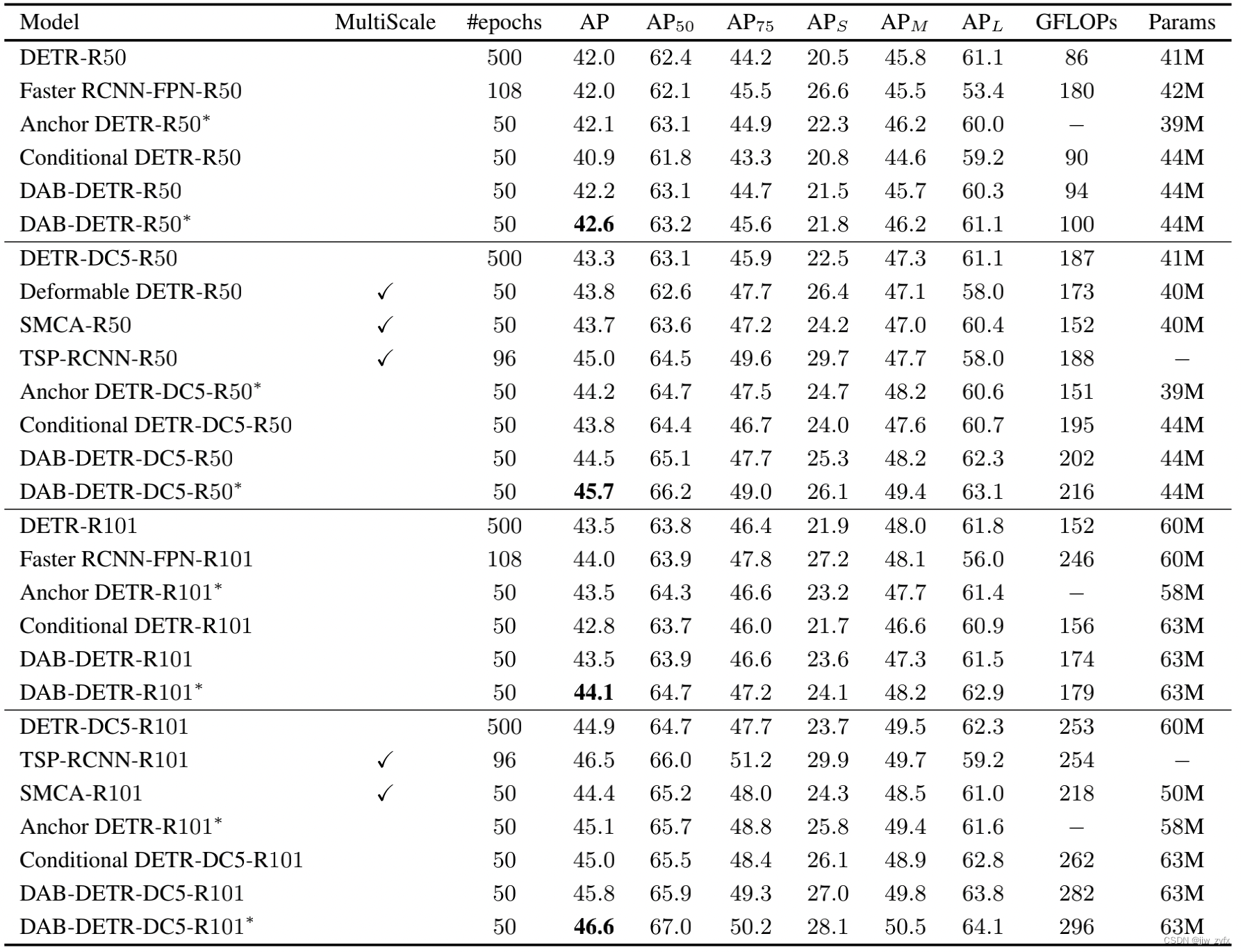
Table 2:DAB-DETR和其他检测模型的结果。除DETR外,所有类似DETR的模型都使用300个查询,而DETR使用100个查询。带∗的模型使用3种模式嵌入,如Anchor DETR(王等人,2021)。我们还在附录G和附录C中提供了更有力的DAB-DETR结果。
表2显示了我们在COCO 2017验证集上的主要结果。我们将我们提出的DAB DETR与DETR(Carion等人,2020)、Faster RCNN(Ren等人,2017)、Anchor DETR(Wang等人,2021)、SMCA(Gao等人,2021)、Deformable DETR(Zhu等人,2021)、TSP(Sun等人,2020)和Conditional DETR(Meng等人,2021)进行了比较。我们展示了模型的两种变体:标准模型和带∗的模型其中带∗的模型有三种模式嵌入(王等人,2021)。我们的标准模型比Conditional DETR有很大的优势。我们注意到,我们的模型引入了略微增加的GFLOP。GFLOP可能因计算脚本而异,我们使用了作者在表2中报告的结果。实际上,我们在测试中发现,我们的标准模型的GFLOP与基于我们的GFLOP计算脚本的相应ConditionalDETR模型几乎相同,因此我们的模型在相同设置下仍然比以前的工作具有优势。当使用模式嵌入时,我们的带∗的DAB-DETR 在所有四个骨干上都比以前的类似DETR的方法有很大的优势,甚至比多尺度架构更好。验证了分析的正确性和设计的有效性。
5.2、消融实验

Table 3::DAB-DETR的消融结果。所有模型均在ResNet-50-DC5骨干上测试,其他参数与我们的默认设置相同。
表3显示了我们模型中每个组件的有效性。我们发现,我们提出的所有模块都对我们的最终结果做出了显著贡献。与锚点公式(比较第3行和第4行)相比,锚框公式将性能从44.0%AP提高到45.0%AP,锚框更新的引入了使得有1.7%AP提升(比较第1行和第2行),这证明了动态锚框设计的有效性。
在去除调制注意力和温度微调后,模型性能分别下降到45.0%(比较第1行和第3行)和44.4%(比较第1行和第5行)。因此,位置注意的细粒度调整对于提高检测性能也非常重要。
6、结论
本文提出了一种新的查询公式,在DETR中使用动态锚盒,并对查询在DETR中的作用有了更深入的理解。使用锚盒作为查询具有以下优点,包括温度调整后拥有更好的位置先验,可调整大小的注意力以考虑不同尺度的目标,以及迭代锚框更新以逐步改进锚框估计。这样的设计清楚地表明,DETR中的查询可以实现为以级联方式逐层执行软ROI池。进行了大量实验,有效地验证了我们的分析,并验证了我们的算法设计。
边栏推荐
- 手机号国际区号JSON格式另附PHP获取
- golang 根据生日计算星座和属相
- The JSON format of the international area code of the mobile phone number is obtained with PHP
- UltraEdit-32 温馨提示:右协会,取消 bak文件[通俗易懂]
- 机器学习笔记 - 使用机器学习进行鸟类物种分类
- 【写给初发论文的人】撰写综述性科技论文常见问题
- 用头像模仿天狗食月
- List interview common questions
- 红米k40s root玩机笔记
- Confirm the future development route! Digital economy, digital transformation, data This meeting is very important
猜你喜欢
2022年电工杯B 题 5G 网络环境下应急物资配送问题思路分析
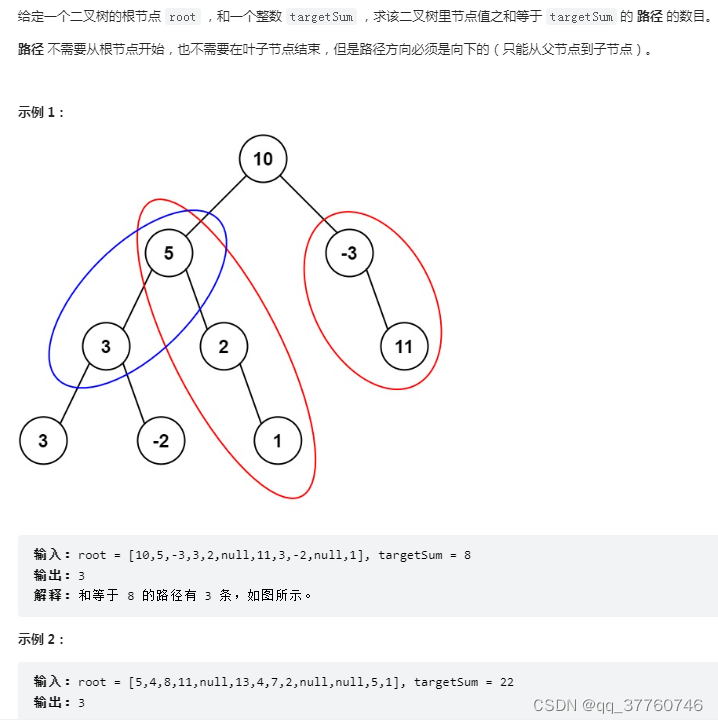
力扣------路径总和 III

ABAP dynamic inner table grouping cycle
Web service performance monitoring scheme
Force buckle ----- path sum III

Probability formula

Create commonly used shortcut icons at the top of the ad interface (menu bar)
【knife-4j 快速搭建swagger】
web服务性能监控方案
接口数据安全保证的10种方式
随机推荐
Collection of idea gradle Lombok errors
手机号国际区号JSON格式另附PHP获取
Operational amplifier application summary 1
Imitate Tengu eating the moon with Avatar
QT opens a file and uses QFileDialog to obtain the file name, content, etc
【写给初发论文的人】撰写综述性科技论文常见问题
Que savez - vous de la sérialisation et de l'anti - séquence?
[MySQL] row sorting in MySQL
opencv第三方库
如何编写一个程序猿另一个面试官眼前一亮的简历[通俗易懂]
Implementation of map and set
Termux set up the computer to connect to the mobile phone. (knock the command quickly), mobile phone termux port 8022
Leetcode: interview question 17.24 Maximum cumulative sum of submatrix (to be studied)
本机mysql
On file uploading of network security
【安全攻防】序列化與反序列,你了解多少?
10 ways of interface data security assurance
Hisilicon 3559 universal platform construction: RTSP real-time playback support
leetcode:面试题 17.24. 子矩阵最大累加和(待研究)
1.19.11.SQL客户端、启动SQL客户端、执行SQL查询、环境配置文件、重启策略、自定义函数(User-defined Functions)、构造函数参数