当前位置:网站首页>【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
2022-07-02 07:44:00 【bryant_ meng】


CVPR-2013
List of articles
1 Background and Motivation
face keypoint detection advantageous to face recognition and analysis
face keypoint detection The difficulty lies in extreme poses, lightings, expressions, and occlusions Scene
Existing methods :
- classifying(component detector) search windows, want scanning, Using local features
- directly predicting keypoint positions (or shape parameters)
The author designed a cascade CNN structure ——a cascaded regression approach for facial point detection with three levels of convolutional networks,significantly improves the prediction accuracy of SOTA and latest commercial software
2 Related Work
- Many used Adaboost, SVM, or random forest classifiers as component detectors and detection was based on local image features.
- regression-based approaches
- Convolutional networks
3 Advantages / Contributions
- Put forward cascade Of CNN Structure is used to accurately locate the key points of the face , The effect on some data is better than SOTA And commercial software
- use locally sharing weights Carry out more targeted training on different key points of the face
4 Method
The cascade network structure is as follows 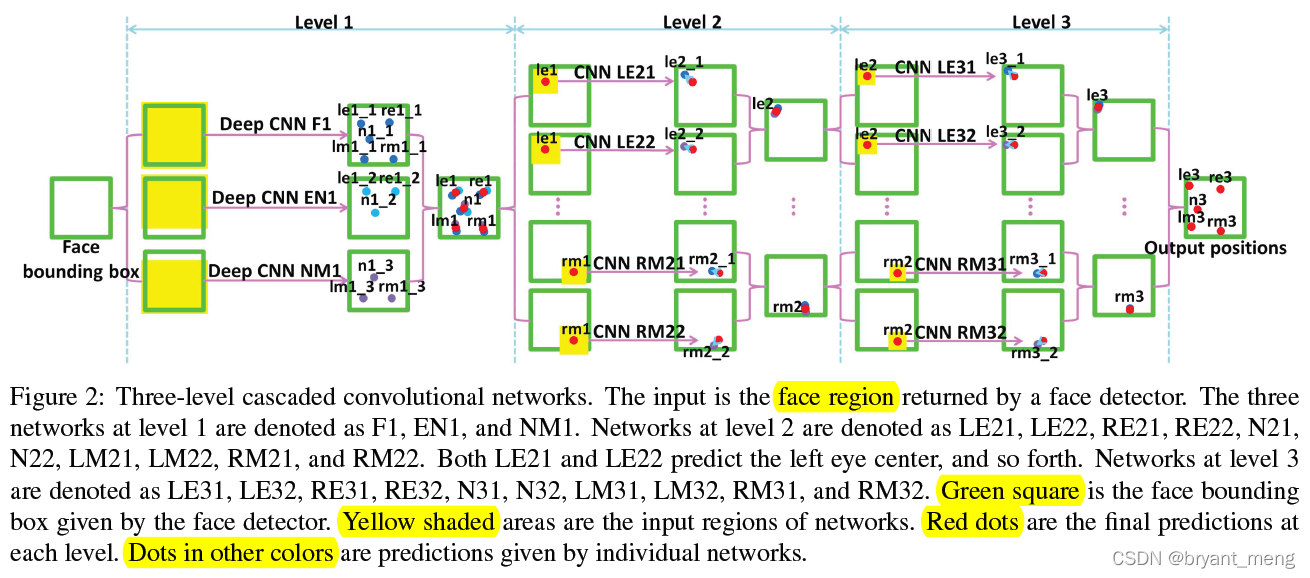
cascade three levels of convolutional networks to make coarse-to-fine prediction
Five key points :
- left eye center (LE)
- right eye center (RE)
- nose tip (N)
- left mouth corner (LM)
- right mouth corner (RM)
1)level 1
The input is the whole face , The three networks predict
- whole face (F)—— It refers to the five key points on the face
- eyes and nose (EN)
- nose and mouth (NM)
The results of the three networks will be averaged as a follow-up level Part of the input
2)level2 and level3
The input is the previous level Predict the coordinates of the key points of the face as a benchmark patch
level2 and level3 Yes 10 A network , Predict separately 5 Horizontal and vertical coordinates of key points
Predictions at the last two levels are strictly restricted because local appearance is sometimes ambiguous and unreliable.
3) Final forecast
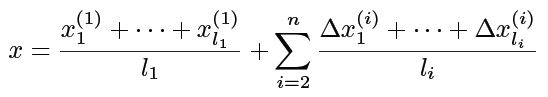
Also in level1 Based on the predicted results refine( Δ \Delta Δ)
4) Specific network structure
level1 Three networks ,level2 and level3 Each has 10 A network , What does it look like ?
Have a look first level1 Of F1
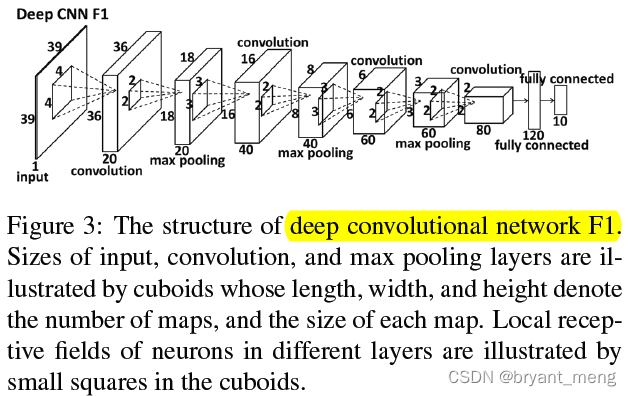
Look at other structures 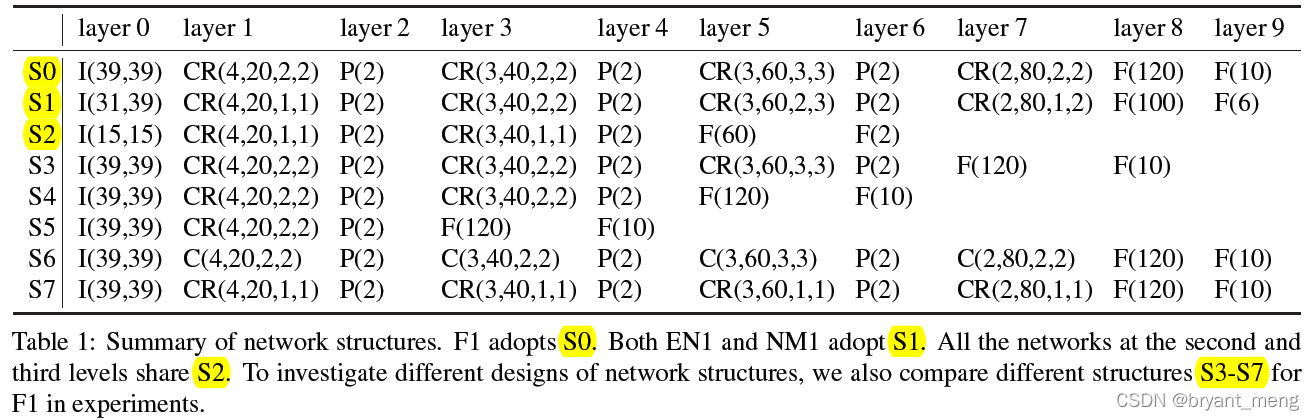
level1 Yes S0 and S1,level2 and level3 They all use S2
5)locally sharing weights
globally sharing weights does not work well on images with fixed spatial layout, such as faces
For example, while eyes and mouth may share low-level features (e.g. edges), they are very different at high-level.
Let's first look at the formula of convolution 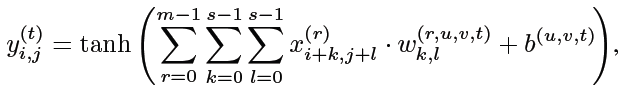
Abbreviation C ( s , n , p , q ) C(s, n, p, q) C(s,n,p,q)
C R ( s , n , p , q ) CR(s, n, p, q) CR(s,n,p,q) It means in tanh Then an absolute value is added
except w w w and b b b More on u u u and v v v Outer and normal convolution ( No, locally shared weight) It's the same
Input feature map ( h , w , m ) (h, w, m) (h,w,m)
- m m m Enter the number of channels
- n n n Number of output channels , t t t The number of output channels , t = 0 , . . . , n − 1 t = 0,...,n-1 t=0,...,n−1
- s s s Yes kernel size
- i , j i, j i,j Is the spatial location index ( Not pixel space , It is the local shared space divided by the author , The specific division rules are shown in the following formula )
i = Δ h ⋅ u + 0 , . . . , Δ h ⋅ u + Δ h − 1 i = \Delta h \cdot u + 0, ... , \Delta h \cdot u + \Delta h -1 i=Δh⋅u+0,...,Δh⋅u+Δh−1, among Δ h = h − s + 1 p \Delta h = \frac{h-s+1}{p} Δh=ph−s+1, u = 0 , . . . , p − 1 u = 0, ... , p-1 u=0,...,p−1
j = Δ w ⋅ v + 0 , . . . , Δ w ⋅ v + Δ w − 1 j = \Delta w \cdot v + 0, ... , \Delta w \cdot v + \Delta w -1 j=Δw⋅v+0,...,Δw⋅v+Δw−1, among Δ w = w − s + 1 q \Delta w = \frac{w-s+1}{q} Δw=qw−s+1, v = 0 , . . . , q − 1 v = 0, ... , q-1 v=0,...,q−1
Put the whole picture ( h , w ) (h, w) (h,w) Roughly divided into p p p x q q q area ( use u u u and v v v To index ), The size of each area is approximately Δ h \Delta h Δh x Δ w \Delta w Δw, Weight sharing in each area , Not the whole picture ( Normal convolution weight sharing in the whole graph ——kernel size Of course, it is not shared in the scope )
Let's look at the formula of pool layer 
gain coefficient g g g and shifted by a bias b b b, s s s is the side length of square pooling regions
FC layer 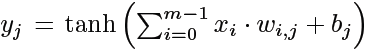
- n n n Output vector dimension , m m m The dimension of the input vector
- j = 0 , . . . , n − 1 j = 0, . . . , n − 1 j=0,...,n−1
tanh function 
6) Specific input size 
You can see F1 Our network is also expanded on the basis of human faces
level2 and level3 stay level1 Output point position Expand up and out
5 Experiments
5.1 Datasets
13, 466 face images,5, 590 images are from LFW + 7, 876 from the web

BioID has 1, 521 images of 23 subjects

LFPW contains 1, 432 face images from the web

The evaluation index 
- ( x , y ) (x,y) (x,y) Is the key point of prediction
- ( x ′ , y ′ ) ({x}',{y}') (x′,y′) yes GT
- l l l is the width of the bounding box returned by our face detector
The error is greater than %5 Think failure
l l l by bi-ocular distance( Binocular distance ) More common ,but it has problem on faces with large pose variations, since bi-ocular distance of near-profile faces is much shorter than that of frontal faces, That is, it will magnify the error of the side face , The above will be relatively better
5.2 Investigate network and cascade structures
1)Network structure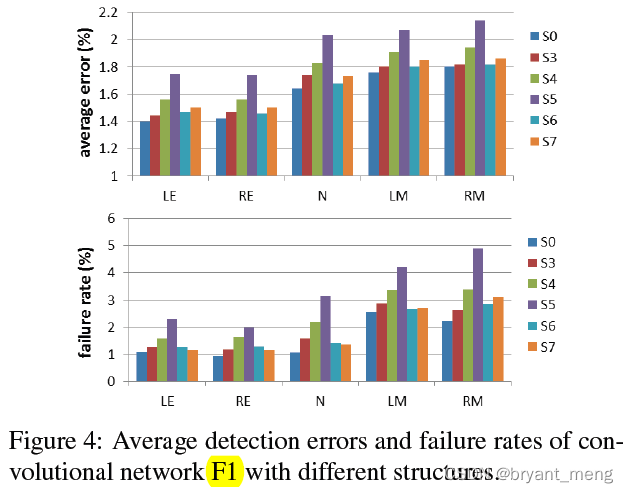
F1 Explore the effects of different networks ,S0 good
the performance can be significantly improved by including more layers
S6 and S7 The structure is the same as S0, but S6 Convolution C No CR,S7 It's using globally shares weights instead of locally sharing weights
We also find that locally sharing weights in higher layers is more important
2)Multi-level prediction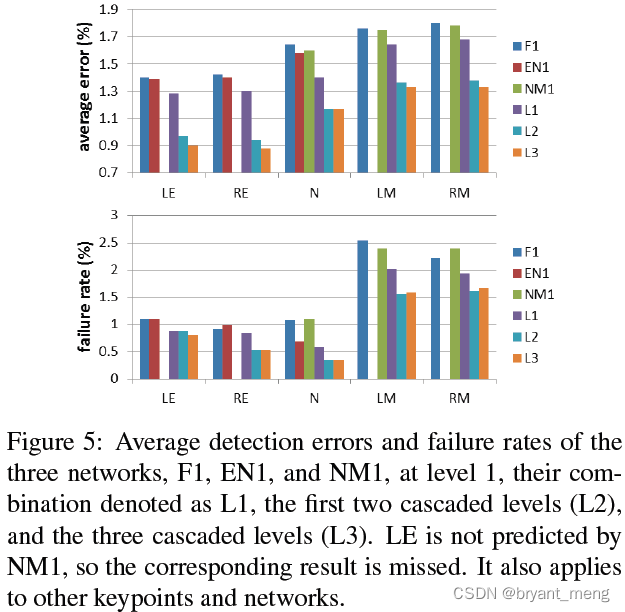
cascade Come down ,error It's reducing
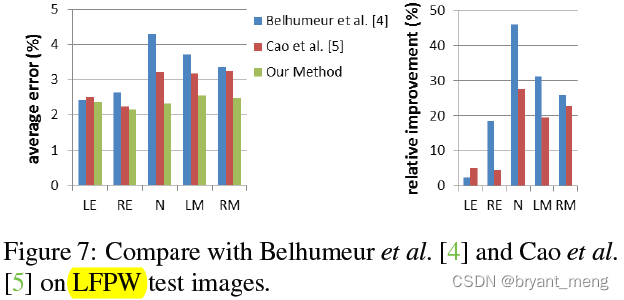
5.3 Comparison with other methods

6 Conclusion(own) / Future work
Code :https://github.com/luoyetx/deep-landmark
Recommended blog :
- Deep Convolutional Network Cascade for Facial Point Detection practice
- Deep Convolutional Network Cascade for Facial Point Detection Reading notes
cascade
locally sharing weights
边栏推荐
- The difference and understanding between generative model and discriminant model
- Sorting out dialectics of nature
- Determine whether the version number is continuous in PHP
- TimeCLR: A self-supervised contrastive learning framework for univariate time series representation
- Drawing mechanism of view (3)
- 【Ranking】Pre-trained Language Model based Ranking in Baidu Search
- label propagation 标签传播
- 超时停靠视频生成
- Comparison of chat Chinese corpus (attach links to various resources)
- iOD及Detectron2搭建过程问题记录
猜你喜欢
Implementation of yolov5 single image detection based on onnxruntime
![[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video](/img/bc/c54f1f12867dc22592cadd5a43df60.png)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
程序的内存模型

ModuleNotFoundError: No module named ‘pytest‘

label propagation 标签传播

What if a new window always pops up when opening a folder on a laptop
【Mixed Pooling】《Mixed Pooling for Convolutional Neural Networks》
点云数据理解(PointNet实现第3步)

Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered

【Paper Reading】
随机推荐
Point cloud data understanding (step 3 of pointnet Implementation)
ABM thesis translation
Generate random 6-bit invitation code in PHP
【Hide-and-Seek】《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization xxx》
Faster-ILOD、maskrcnn_benchmark训练自己的voc数据集及问题汇总
Drawing mechanism of view (II)
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
论文写作tip2
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
What if the laptop task manager is gray and unavailable
基于pytorch的YOLOv5单张图片检测实现
@Transitional step pit
PointNet理解(PointNet实现第4步)
ABM论文翻译
Faster-ILOD、maskrcnn_ Benchmark training coco data set and problem summary
Deep learning classification Optimization Practice
Conversion of numerical amount into capital figures in PHP
How to efficiently develop a wechat applet
【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》