当前位置:网站首页>基于onnxruntime的YOLOv5单张图片检测实现
基于onnxruntime的YOLOv5单张图片检测实现
2022-07-02 06:25:00 【wxplol】
接上一篇 基于pytorch的YOLOv5单张图片检测实现,我们实现了pytorch的前向推理,但是这个推理过程需要依赖yolov5本身的模型文件以及结构搭建的过程,所以还是比较麻烦的。这里,有没有一个直接前向推理,然后只处理结果,无需考虑yolov5本身的文件。所以现在介绍的是基于onnx的推理。这个推理过程也很简单,将原模型转化为onnx格式,然后再使用onnxruntime进行就可以了,具体操作可以看我的文章。
一、pt转onnx
这里我们主要参考:https://github.com/ultralytics/yolov5/issues/251中的内容进行转化,进入yolov5安装目录,执行以下:
python models/export.py --weights yolov5s.pt --img 640 --batch 1
二、onnxruntime前向推理
1. 安装依赖
pip install onnxruntime
2. 代码实现
# coding=utf-8
import cv2.cv2 as cv2
import numpy as np
import onnxruntime
import torch
import torchvision
import time
import random
class YOLOV5_ONNX(object):
def __init__(self,onnx_path):
'''初始化onnx'''
self.onnx_session=onnxruntime.InferenceSession(onnx_path)
self.input_name=self.get_input_name()
self.output_name=self.get_output_name()
def get_input_name(self):
'''获取输入节点名称'''
input_name=[]
for node in self.onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_output_name(self):
'''获取输出节点名称'''
output_name=[]
for node in self.onnx_session.get_outputs():
output_name.append(node.name)
return output_name
def get_input_feed(self,image_tensor):
'''获取输入tensor'''
input_feed={
}
for name in self.input_name:
input_feed[name]=image_tensor
return input_feed
def letterbox(self,img, new_shape=(640, 640), color=(114, 114, 114), auto=False, scaleFill=False, scaleup=True,
stride=32):
'''图片归一化'''
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
def xywh2xyxy(self,x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def nms(self,prediction, conf_thres=0.1, iou_thres=0.6, agnostic=False):
if prediction.dtype is torch.float16:
prediction = prediction.float() # to FP32
xc = prediction[..., 4] > conf_thres # candidates
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_det = 300 # maximum number of detections per image
output = [None] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
x = x[xc[xi]] # confidence
if not x.shape[0]:
continue
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
box = self.xywh2xyxy(x[:, :4])
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((torch.tensor(box), conf, j.float()), 1)[conf.view(-1) > conf_thres]
n = x.shape[0] # number of boxes
if not n:
continue
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.boxes.nms(boxes, scores, iou_thres)
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
output[xi] = x[i]
return output
def clip_coords(self,boxes, img_shape):
'''查看是否越界'''
# Clip bounding xyxy bounding boxes to image shape (height, width)
boxes[:, 0].clamp_(0, img_shape[1]) # x1
boxes[:, 1].clamp_(0, img_shape[0]) # y1
boxes[:, 2].clamp_(0, img_shape[1]) # x2
boxes[:, 3].clamp_(0, img_shape[0]) # y2
def scale_coords(self,img1_shape, coords, img0_shape, ratio_pad=None):
''' 坐标对应到原始图像上,反操作:减去pad,除以最小缩放比例 :param img1_shape: 输入尺寸 :param coords: 输入坐标 :param img0_shape: 映射的尺寸 :param ratio_pad: :return: '''
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new,计算缩放比率
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (
img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding ,计算扩充的尺寸
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2]] -= pad[0] # x padding,减去x方向上的扩充
coords[:, [1, 3]] -= pad[1] # y padding,减去y方向上的扩充
coords[:, :4] /= gain # 将box坐标对应到原始图像上
self.clip_coords(coords, img0_shape) # 边界检查
return coords
def sigmoid(self,x):
return 1 / (1 + np.exp(-x))
def infer(self,img_path):
'''执行前向操作预测输出'''
# 超参数设置
img_size=(640,640) #图片缩放大小
conf_thres=0.25 #置信度阈值
iou_thres=0.45 #iou阈值
class_num=1 #类别数
stride=[8,16,32]
anchor_list= [[10,13, 16,30, 33,23],[30,61, 62,45, 59,119], [116,90, 156,198, 373,326]]
anchor = np.array(anchor_list).astype(np.float).reshape(3,-1,2)
area = img_size[0] * img_size[1]
size = [int(area / stride[0] ** 2), int(area / stride[1] ** 2), int(area / stride[2] ** 2)]
feature = [[int(j / stride[i]) for j in img_size] for i in range(3)]
# 读取图片
src_img=cv2.imread(img_path)
src_size=src_img.shape[:2]
# 图片填充并归一化
img=self.letterbox(src_img,img_size,stride=32)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
# 归一化
img=img.astype(dtype=np.float32)
img/=255.0
# # BGR to RGB
# img = img[:, :, ::-1].transpose(2, 0, 1)
# img = np.ascontiguousarray(img)
# 维度扩张
img=np.expand_dims(img,axis=0)
# 前向推理
start=time.time()
input_feed=self.get_input_feed(img)
pred=self.onnx_session.run(output_names=self.output_name,input_feed=input_feed)
#提取出特征
y = []
y.append(torch.tensor(pred[0].reshape(-1,size[0]*3,5+class_num)).sigmoid())
y.append(torch.tensor(pred[1].reshape(-1,size[1]*3,5+class_num)).sigmoid())
y.append(torch.tensor(pred[2].reshape(-1,size[2]*3,5+class_num)).sigmoid())
grid = []
for k, f in enumerate(feature):
grid.append([[i, j] for j in range(f[0]) for i in range(f[1])])
z = []
for i in range(3):
src = y[i]
xy = src[..., 0:2] * 2. - 0.5
wh = (src[..., 2:4] * 2) ** 2
dst_xy = []
dst_wh = []
for j in range(3):
dst_xy.append((xy[:, j * size[i]:(j + 1) * size[i], :] + torch.tensor(grid[i])) * stride[i])
dst_wh.append(wh[:, j * size[i]:(j + 1) * size[i], :] * anchor[i][j])
src[..., 0:2] = torch.from_numpy(np.concatenate((dst_xy[0], dst_xy[1], dst_xy[2]), axis=1))
src[..., 2:4] = torch.from_numpy(np.concatenate((dst_wh[0], dst_wh[1], dst_wh[2]), axis=1))
z.append(src.view(1, -1, 5+class_num))
results = torch.cat(z, 1)
results = self.nms(results, conf_thres, iou_thres)
cast=time.time()-start
print("cast time:{}".format(cast))
#映射到原始图像
img_shape=img.shape[2:]
print(img_size)
for det in results: # detections per image
if det is not None and len(det):
det[:, :4] = self.scale_coords(img_shape, det[:, :4],src_size).round()
if det is not None and len(det):
self.draw(src_img, det)
def plot_one_box(self,x, img, color=None, label=None, line_thickness=None):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def draw(self,img, boxinfo):
colors = [[0, 0, 255]]
for *xyxy, conf, cls in boxinfo:
label = '%s %.2f' % ('image', conf)
print('xyxy: ', xyxy)
self.plot_one_box(xyxy, img, label=label, color=colors[int(cls)], line_thickness=1)
cv2.namedWindow("dst",0)
cv2.imshow("dst", img)
cv2.imwrite("data/res1.jpg",img)
cv2.waitKey(0)
# cv2.imencode('.jpg', img)[1].tofile(os.path.join(dst, id + ".jpg"))
return 0
if __name__=="__main__":
model=YOLOV5_ONNX(onnx_path="./weights/image_detect.onnx")
model.infer(img_path="data/PMC2663376_00004.jpg")
结果:
3、onnxruntime和pytorch比较
- onnxruntime推理时间
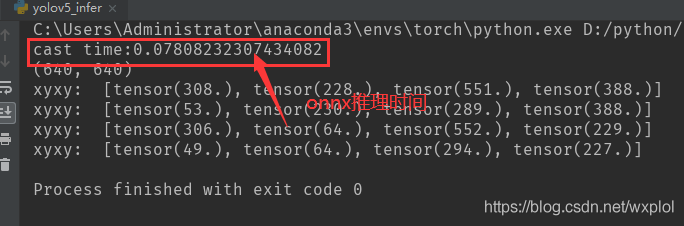
- pytorch推理时间

我们在归一化到640x640图像上进行比较,onnx推理比纯pytorch时间提升了1倍。说明onnx推理还是可以的,后续会在其他加速框架上进行测试,期待后续吧。。。
github链接:yolov5前向推理实现
边栏推荐
- @Transational踩坑
- ssm超市订单管理系统
- Analysis of MapReduce and yarn principles
- 叮咚,Redis OM对象映射框架来了
- allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
- sparksql数据倾斜那些事儿
- ERNIE1.0 与 ERNIE2.0 论文解读
- 【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
- 【论文介绍】R-Drop: Regularized Dropout for Neural Networks
- Oracle EBS interface development - quick generation of JSON format data
猜你喜欢
![[introduction to information retrieval] Chapter 7 scoring calculation in search system](/img/cc/a5437cd36956e4c239889114b783c4.png)
[introduction to information retrieval] Chapter 7 scoring calculation in search system
![[introduction to information retrieval] Chapter 3 fault tolerant retrieval](/img/75/ac2fdcd256f5c2336ca53c7a2744b8.png)
[introduction to information retrieval] Chapter 3 fault tolerant retrieval

ORACLE EBS 和 APEX 集成登录及原理分析

@Transational踩坑
Practice and thinking of offline data warehouse and Bi development

类加载器及双亲委派机制
PointNet理解(PointNet实现第4步)
【信息检索导论】第三章 容错式检索

第一个快应用(quickapp)demo

Two table Association of pyspark in idea2020 (field names are the same)
随机推荐
SSM laboratory equipment management
【调参Tricks】WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach
如何高效开发一款微信小程序
读《敏捷整洁之道:回归本源》后感
Pyspark build temporary report error
SSM二手交易网站
Conda 创建,复制,分享虚拟环境
腾讯机试题
[tricks] whiteningbert: an easy unsupervised sentence embedding approach
Jordan decomposition example of matrix
Check log4j problems using stain analysis
Optimization method: meaning of common mathematical symbols
SSM personnel management system
Oracle 11.2.0.3 handles the problem of continuous growth of sysaux table space without downtime
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
Cognitive science popularization of middle-aged people
[introduction to information retrieval] Chapter 1 Boolean retrieval
SSM学生成绩信息管理系统
view的绘制机制(三)
Yaml file of ingress controller 0.47.0