当前位置:网站首页>[introduction to information retrieval] Chapter 3 fault tolerant retrieval
[introduction to information retrieval] Chapter 3 fault tolerant retrieval
2022-07-02 07:21:00 【lwgkzl】
The overview
This chapter mainly solves the following problems :
- According to the user's inquiry , How to find the inverted list corresponding to the words in the user's query ?
- If the user doesn't remember how to spell a word , How to realize fuzzy query ( Wildcard query )?
- If the user writes a word incorrectly , How to help him correct , So as to return the word that the user really wants to query ?
The above questions correspond to the following three sections .
3.1 Search term dictionary
Preface : In the first two chapters , We perform Boolean queries directly by default according to the word items queried by the user , Directly get his inverted list . But actually , We need to find the corresponding term in the term dictionary first , Can return the inverted table corresponding to the word item . For users query After participle , Get the word item to be queried , We must first look it up in the lexicon , Of course, the simplest method is linear search , However, the time complexity of this method O ( n ) O(n) O(n) Too high . Of course, we can sort the word dictionary according to the dictionary order , In this way, we can happily use binary search O ( l o g n ) O(logn) O(logn) 了 , But things are not so simple , If it is web Search words , The vocabulary needs to be constantly updated , And if you need to ensure that the word list is orderly , Every time the thesaurus is updated, it will also cause a huge waste of performance . So next we will introduce two solutions , Help us locate quickly in the dictionary of words !
String hash : Mengde once said :“ Why melancholy , Only hash ”, The function of string hash is to define a function , Map a string to a number that uniquely corresponds to it , Here we can map directly to the memory address , So every query term , We go through the hash function “ Shua ” You can find the memory address corresponding to the word item at a glance , The time complexity is O ( 1 ) O(1) O(1), It has nothing to do with the size of the lexicon , But too fast is not a good thing , Especially for some friends , Hash functions have the following limitations .
Limitations of string hashing :
- With the dynamic increase of word dictionary , conflict ( Multiple strings are mapped to the same number by this function ) The possibility of
- String hashes cannot handle the following *“ Prefix query ”*, It cannot be adapted to the following “ Wildcard search ”
Then people expect a perfect algorithm to solve this problem , He should be able to query quickly , Also support fast dynamic insertion . He is ------- Binary search tree :
Each leaf node of the binary search tree is a string , Non leaf nodes are used as partition nodes , Divide the string smaller than this node into the left subtree , Divide strings larger than this node into right subtrees ( See Introduction to algorithm for details ). Binary search tree can also be regarded as prefix tree of string , It can be used for prefix retrieval of strings . To make a long story short , Binary search tree can achieve dynamic increase , And the retrieval efficiency is O ( l o g n ) O(logn) O(logn), Then there are some improvements based on the simple binary search tree , among Balanced binary trees Dynamically maintain the balance of binary search tree , Ensure that the time complexity of each retrieval is O ( l o g n ) O(logn) O(logn) about ,B- Trees Expand the binary tree to multi fork , Each branch represents a string of an interval , In order to reduce the cost of maintaining balance every time of balanced binary tree . Please check the saint level magic guide book for specific algorithm introduction —《 Introduction to algorithms 》.
3.2 Wildcard query
When Xiao Ming slowly typed out in the input box heavily “ Horse * mei ” When , What he wants to know is the heroic deeds of a great hero , Unfortunately, Xiao Ming forgot his full name , I remember his name is Ma Yimei . At this time, fuzzy retrieval is needed , The middle one entered by Xiao Ming * It stands for replacing any character . This kind of query is called wildcard query .
a. Single wildcard query
If the user's query contains only one wildcard , It can be easily solved in the existing term retrieval technology , Such as “ Horse * mei ”, Then I can construct two binary search trees , A word item that stores positive (A), Another word item stored after inversion (B). Then I just need to be in the tree A Retrieved in “ Horse ” A set of words prefixed as well as In the tree B Retrieved in “ mei ” A set of words prefixed , Then take the union of the two , It's all the word items corresponding to Ma Hemei .
b. Multiple Wildcard Queries
If the user's query contains multiple wildcards , Such as “ Horse * mei * Skey ”, At this time, we need to use some other means .
Wheel index : Add special characters at the end of a single word $, And add all the forms of its rotation to the lexicon , Then construct a binary search tree based on the rotation word dictionary . The example is shown in the following figure :
What are the benefits of doing so , At this time, we can query “ Horse * mei * Skey ” 了 , First, transform it into Skey $\ Horse * mei *, Then search the binary search tree for the information containing " Skey $\ Horse " The term of ( Prefix search ), Finally, in the retrieved words , By measuring whether the retrieved words contain “ mei ” Use this keyword to filter , After screening, we get the final word list .
Defects of wheel index : Multiply the original large number of words , Because he saved all the results of the original rotation of each word item , Make the computer storage that is not rich even worse .
k-gram Indexes :
This method is more native, It's a single word k-gram Draw out the word items , Constitute the k-gram The dictionary , For example, consider words “ Ma Dongmei autosky ” Of 2-gram, It is 【‘$ Horse ’,‘ Ma Dong ’,‘ Wintersweet ’…‘ Skey ’,‘ The base $’】 To identify the start and end position , Mark him with special characters at the beginning and end $, Then the dictionary contains so many . Then according to the 2-gram Just search the corresponding words : Such as “ Horse * mei ”, It becomes Boolean search “ Horse ” A N D “ mei Horse ” AND “ mei Horse ”AND“ mei ”, Then find the corresponding word .
3.3 Spelling correction
Finally came the spelling correction , Obviously, when users query, due to input method or memory deviation and other reasons , He may lose by mistake . For example, Xiao Ming inquired about a name “ Ma Ximei ”, Obviously, there is no “ Ma Ximei ” The name of this hero . This leads to Spelling correction technology .
Principles and steps :
- When the user retrieves too little information about keywords , We can think that he entered the wrong information , So correct his spelling , And provide the search results of the corrected words as “ Spelling suggestions ”.
- For a misspelled word , We need to find the nearest word in the correct spelling .
- If there are multiple correctly spelled words closest to the wrong spelling , Choose the word with the most frequent occurrence as the final spelling result
According to the above principles and steps , We need to define a concept as the relationship between wrong words and correct words *“ distance ”* What determines .
a. Word independent correction method
This method is aimed at the user entering the wrong word , As shown above , We need to define a standard to measure the gap between the wrong words and the correct words , Here are two ways .
Edit distance : The first measure is edit distance , This one is direct leetcode Understand , link 
The minimum number of operations in the topic , That is the distance between two words .
k-gram Coincidence :
ditto , Disassemble the word items into k-gram after , Compare the common of correct words and wrong words k-gram The number of , The more public , The closer the distance between the two words . For example, consider words “ Ma Dongmei ” Of 2-gram, It is 【‘$ Horse ’,‘ Ma Dong ’,‘ Wintersweet ’,‘ mei $’】, And the wrong word “ Ma Ximei ” Of 2-gram by 【‘$ Horse ’,‘ Ma Dong ’,‘ Ximei ’,‘ mei $’】, obviously , The distance between the two is relatively close . But another problem is , If the length of the word item is very long , There may be some deviation, for example, a word item is “ Ma Dongmei - Robertsberg - Ostrovsky ”, Then he and the wrong words “ Ma Ximei ” Of 2-gram Public quantity and “ Ma Dongmei ” It's the same , Obviously, from the perspective of users “ Ma Dongmei ” And “ Ma Ximei ” It's closer . To take this into account , We use an index called the jackard coefficient .
Jacobian coefficient :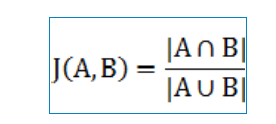
among A,B They are the wrong words and the correct words k-gram Set .
b. Context sensitive correction method
This method is applicable to , The words entered by the user are all right , But the combined phrase is not what the user wants to express . If the user enters “ Excavator of flying technology ”, Of course, there are not many results after searching , But among them “ flight ”,“ Technology ” And other words are correct words . At this time, we need to specify it as “ Lanxiang Technology ”. At present, there is no particularly suitable method among the traditional methods , The more violent way is , Try to replace every word in the phrase with a word close to it , Then combine them into new phrases , Then choose the phrase with the highest frequency .
c. Speech based correction method
One method of voice hashing is ** soundex Algorithm **, Words with similar pronunciation can be grouped into the same category .
summary
problem 1. According to the user's inquiry , How to find the inverted list corresponding to the words in the user's query ?
answer 1: Binary search tree perhaps String hash is ok
problem 2. If the user doesn't remember how to spell a word , How to realize fuzzy query ( Wildcard query )?
answer 2: Use wheel index or k-gram Indexes
problem 3. If the user writes a word incorrectly , How to help him correct , So as to return the word that the user really wants to query ?
answer 3: Use algorithms such as editing distance to correct word level errors , Correct phrase level errors based on word level errors .
Knowledge map in this chapter

边栏推荐
- php中删除指定文件夹下的内容
- How to call WebService in PHP development environment?
- Spark SQL task performance optimization (basic)
- SSM garbage classification management system
- Oracle RMAN semi automatic recovery script restore phase
- 腾讯机试题
- 类加载器及双亲委派机制
- Alpha Beta Pruning in Adversarial Search
- php中获取汉字拼音大写首字母
- RMAN incremental recovery example (1) - without unbacked archive logs
猜你喜欢
【信息检索导论】第二章 词项词典与倒排记录表

Cloud picture says | distributed transaction management DTM: the little helper behind "buy buy buy"
Practice and thinking of offline data warehouse and Bi development
中年人的认知科普

view的绘制机制(一)
SSM second hand trading website
spark sql任务性能优化(基础)

Two table Association of pyspark in idea2020 (field names are the same)

Oracle 11g uses ords+pljson to implement JSON_ Table effect

SSM student achievement information management system
随机推荐
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
MySQL无order by的排序规则因素
Error in running test pyspark in idea2020
php中判断版本号是否连续
oracle apex ajax process + dy 校验
叮咚,Redis OM对象映射框架来了
ARP攻击
ARP attack
php中删除指定文件夹下的内容
Oracle 11g uses ords+pljson to implement JSON_ Table effect
Pratique et réflexion sur l'entrepôt de données hors ligne et le développement Bi
优化方法:常用数学符号的含义
ORACLE APEX 21.2安装及一键部署
【论文介绍】R-Drop: Regularized Dropout for Neural Networks
Agile development of software development pattern (scrum)
Feeling after reading "agile and tidy way: return to origin"
Sqli-labs customs clearance (less2-less5)
【信息检索导论】第二章 词项词典与倒排记录表
Pyspark build temporary report error
离线数仓和bi开发的实践和思考