当前位置:网站首页>[tricks] whiteningbert: an easy unsupervised sentence embedding approach
[tricks] whiteningbert: an easy unsupervised sentence embedding approach
2022-07-02 07:22:00 【lwgkzl】
executive summary
This article mainly introduces three uses BERT do Sentence Embedding Small Trick, Respectively :
- You should use all token embedding Of average As a sentence, it means , Instead of just using [CLS] Representation of corresponding position .
- stay BERT Multi level sentence vector superposition should be used in , Instead of just using the last layer .
- When judging sentence similarity through cosine similarity , have access to Whitening Operation to unify sentence embedding Vector distribution of , So we can get better sentence expression .
Model
The first two points introduced in this paper do not involve models , Only the third point Whitening The operation can be briefly introduced .
starting point : Cosine similarity as a measure of vector similarity is based on “ Orthonormal basis ” On the basis of , The basis vectors are different , The meaning of each value in the vector also changes . And then pass by BERT The coordinate system of the extracted sentence vector may not be based on the same “ Orthonormal basis ” The coordinate system of .
Solution : Normalize each vector into the coordinate system of the same standard orthogonal basis . A guess is , Each sentence vector generated by the pre training language model should be relatively uniform at each position in the coordinate system , That is, show all kinds of homosexuality . Based on this guess , We can normalize all sentence vectors , Make it isotropic . A feasible solution is to reduce the distribution of sentence vectors to normal distribution , Because the normal distribution satisfies the isotropy ( Mathematical theorems ).
practice :
Content screenshot from Su Shen's blog : link
Experiment and conclusion
- You should use all token embedding Of average As a sentence, it means , Instead of just using [CLS] Representation of corresponding position .
- superposition BERT Of 1,2,12 The vector effect of these three layers is the best .
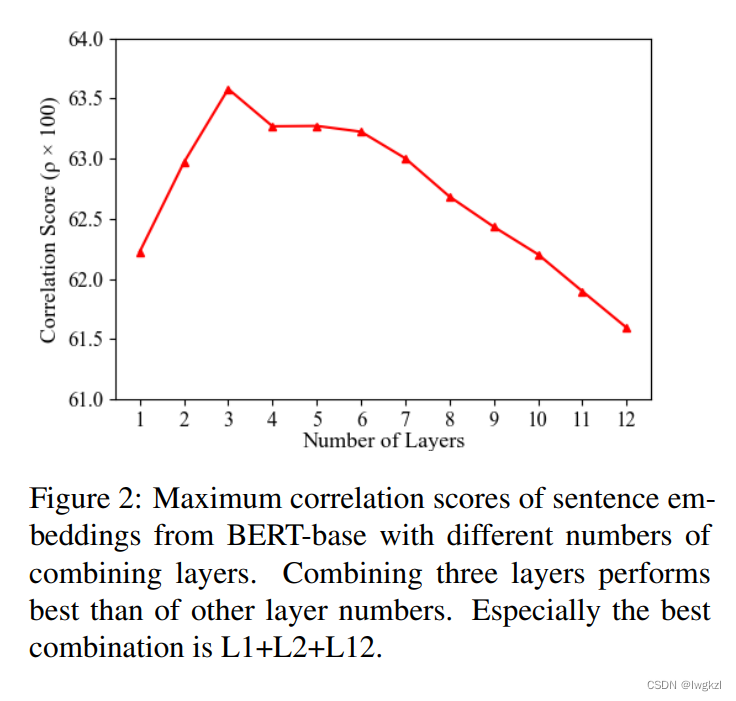

- Whiten Operation is effective for most pre training language models .
Code
def whitening_torch_final(embeddings):
# For torch < 1.10
mu = torch.mean(embeddings, dim=0, keepdim=True)
cov = torch.mm((embeddings - mu).t(), (embeddings - mu))
# For torch >= 1.10
cov = torch.cov(embedding)
u, s, vt = torch.svd(cov)
W = torch.mm(u, torch.diag(1/torch.sqrt(s)))
embeddings = torch.mm(embeddings - mu, W)
return embeddings
after bert encoder The vector after that , Send in whitening_torch_final Function whitening The operation of .
Optimize
According to Su Shen's blog , Only keep SVD Extracted before N Eigenvalues can improve further effect . also , Because only the former N Features , So PCA The principle is similar , It is equivalent to doing a step of dimensionality reduction on the sentence vector .
Change the code to :
def whitening_torch_final(embeddings, keep_dim=256):
# For torch >= 1.10
cov = torch.cov(embedding) # emb_dim * emb_dim
u, s, vt = torch.svd(cov)
# u : emb_dim * emb_dim, s: emb_dim
W = torch.mm(u, torch.diag(1/torch.sqrt(s))) # W: emb_dim * emb_dim
embeddings = torch.mm(embeddings - mu, W[:,:keep_dim]) # truncation
return embeddings # bs * keep_dim
边栏推荐
- 【Torch】解决tensor参数有梯度,weight不更新的若干思路
- 优化方法:常用数学符号的含义
- Two table Association of pyspark in idea2020 (field names are the same)
- 【Torch】最简洁logging使用指南
- How to efficiently develop a wechat applet
- oracle EBS标准表的后缀解释说明
- view的绘制机制(一)
- 腾讯机试题
- Oracle RMAN semi automatic recovery script restore phase
- 使用Matlab实现:Jacobi、Gauss-Seidel迭代
猜你喜欢

Three principles of architecture design

SSM supermarket order management system
CAD secondary development object
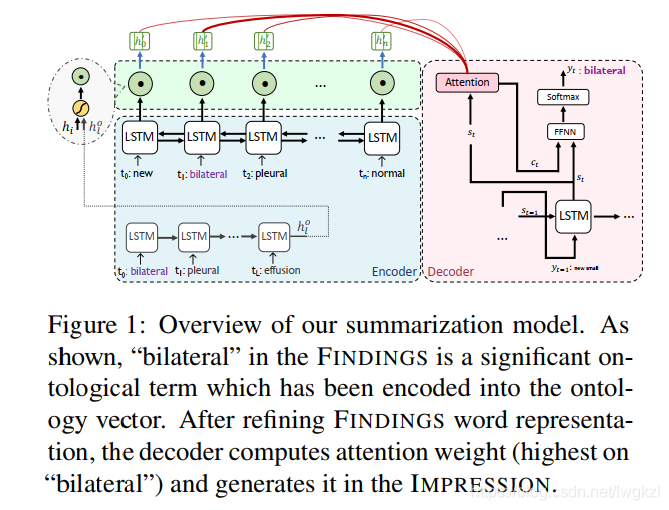
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
中年人的认知科普

一份Slide两张表格带你快速了解目标检测
Cognitive science popularization of middle-aged people

ORACLE EBS中消息队列fnd_msg_pub、fnd_message在PL/SQL中的应用
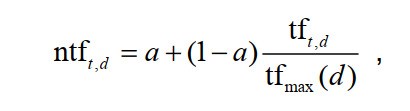
【信息检索导论】第六章 词项权重及向量空间模型
Illustration of etcd access in kubernetes
随机推荐
Ding Dong, here comes the redis om object mapping framework
类加载器及双亲委派机制
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
图解Kubernetes中的etcd的访问
PHP uses the method of collecting to insert a value into the specified position in the array
Cloud picture says | distributed transaction management DTM: the little helper behind "buy buy buy"
外币记账及重估总账余额表变化(下)
Changes in foreign currency bookkeeping and revaluation general ledger balance table (Part 2)
CAD secondary development object
Oracle rman半自动恢复脚本-restore阶段
ORACLE EBS中消息队列fnd_msg_pub、fnd_message在PL/SQL中的应用
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization
Oracle general ledger balance table GL for foreign currency bookkeeping_ Balance change (Part 1)
SSM学生成绩信息管理系统
The first quickapp demo
Oracle段顾问、怎么处理行链接行迁移、降低高水位
DNS攻击详解
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
Sqli-labs customs clearance (less1)