This article is originated from the official account :TechFlow, Originality is not easy. , Ask for attention
Today's article with you to learn a big data field often used algorithm —— The bloon filter . If seen 《 The beauty of Mathematics 》 Our classmates should be familiar with it , It is often used in the judgment of sets , It is used to quickly judge whether an element is in a large set in the massive data scenario . Its principle is not difficult , But the design is very clever , To be honest, I'm looking at 《 The beauty of Mathematics 》 Before , I've never heard of this data structure , So this article is also my own study notes .
principle
In my previous understanding , If you want to determine whether an element is in a collection , The classic structure should be a balanced tree and hash table. But either way , Can't escape a little , All need to store the original value .
For example, in the reptile scene , We need to record the websites we've crawled before . We're going to store all the previous URLs in containers , And then in the face of a new website to determine whether it has climbed . In this question , We don't care what websites we've crawled before , We only care if the current website has appeared before . That is to say, it doesn't matter what happened before , It's important to see if there's ever been one .
We use balance trees or Trie Or is it AC Automata and other data structures and algorithms can achieve efficient search , But they can't do without storing all the strings . Imagine , A web address is about a hundred characters , about 0.1KB, If it's 100 million websites , Need 10GB 了 , If it's ten billion and one hundred billion ? Obviously, such a large scale would be troublesome , The Blum filter introduced today can solve this problem , And there's no need to store the original value , This is a very clever way , Let's take a look at how it works .
The structure of the bloon filter itself is very simple , It's a one-dimensional bool Array of type , That is to say, everyone has only 0 perhaps 1, It's a bit, The length of this array is m. For each new item , We use K Different species hash The algorithm calculates hash value . So we can get K individual hash value , We use it hash It's worth it m modulus , The assumption is x. At the beginning, the array was full of 0, We put all x The corresponding position is marked 1.
for instance , Let's say we start with m yes 10,K yes 3. The first value we encounter to insert is ” linear algebra “, We treat it hash And then get 1,3,5, So we mark the corresponding position as 1.
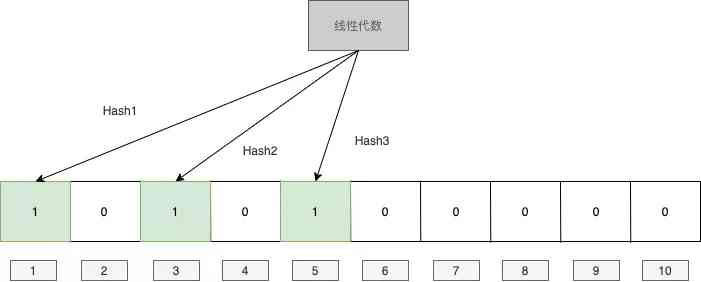
Then we came across another value that was ” Advanced mathematics “,hash And then get 1,8,9, We still assign the corresponding position to 1, Will find 1 The value for this position is already 1 了 , We just ignore it .
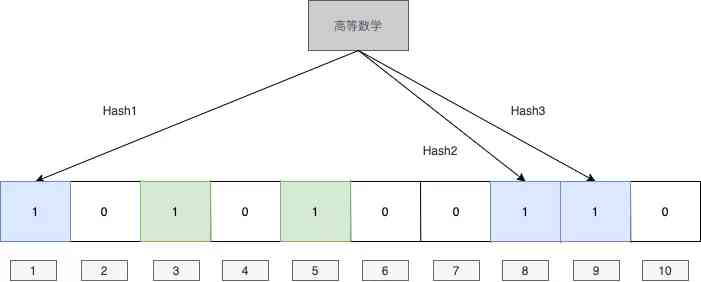
If at this time we want to judge ” probability statistics ” Have you ever seen , What do I do ? It's simple , We are right. “ probability statistics ” Calculate again hash value . Suppose we get 1,4,5, Let's go through the corresponding positions , Find out 4 This position is 0, The description has not been added before “ probability statistics ”, obviously “ probability statistics ” There is no such thing as .
But if “ probability statistics ”hash The result is 1,3,8 Well ? We are wrong to judge that it has appeared , The answer is simple , Because though 1,3,8 This hash The combination never appeared before , But the corresponding positions have appeared in other elements , So there's an error . So we can know , The bloon filter is accurate for non-existent , But the judgment of existence may be wrong .
Code
The principle of the bloon filter is very simple , When I understand , It's easy for us to write code :
# Insert elements
def BloomFilter(filter, value, hash_functions):
m = len(filter)
for func in hash_functions:
idx = func(value) % m
filter[idx] = True
return filter
# Element of judgement
def MemberInFilter(filter, value, hash_functions):
m = len(filter)
for func in hash_functions:
idx = func(value) % m
if not filter[idx]:
return False
return True
Error rate calculation
The previous examples should show clearly , Although the bloom filter is easy to use , But there will be bad case, That is to say, misjudgment . that , What's the probability of this kind of misjudgment ?
The calculation of this probability is not difficult : Because the array length is \(m\), So insert a bit It's set to 1 Is the probability that \(\frac{1}{m}\), Inserting an element requires inserting k individual hash value , So insert an element , Someone is not set to 1 Is the probability that \((1-\frac{1}{m})^k\). Insert n After elements , Someone is still 0 Is the probability that \((1-\frac{1}{m})^{nk}\), It becomes 1 Is the probability that \(1-(1-\frac{1}{m})^{nk}\).
If in some judgment , There's an element that hasn't been seen in the collection , So that means it hash All positions obtained have been previously set to 1 了 , The probability of this time is :
There's a limit here :
Let's find out when the conflict rate is the lowest k The value of , For the sake of calculation , We make \(b=e^{\frac{n}{m}}\), Plug in :
Seek guidance on both sides :
We make the derivative equal to 0, To find its extreme value :
We will \(b^{-k}=\frac{1}{2}\) Plug in , When we can find the maximum value \(k=\ln2\cdot\frac{m}{n} \approx 0.7\frac{m}{n}\)
Empathy , We can also preset the set elements n And miscarriage of justice p, To solve the corresponding n, Also use the above formula to calculate , You can get \(m=-\frac{n\ln p}{(\ln2)^2}\)
If we allow some tolerance , And can roughly estimate the number of elements that will appear , So we can use the bloom filter instead of the traditional method of container weight determination . This is not only very efficient , And the storage requirements are very small .
Soul torture
The principle is clear , The code also understands , Now let's think about a question : Can the bloom filter delete elements ?
unfortunately , The bloon filter does not support deletion .
Because every one of the bloon filters bit It's not exclusive , It's possible that multiple elements share a certain bit . If we delete this one directly , Will affect other elements .
Use the example above : We delete linear algebra , The corresponding position of linear algebra is 1,3,5, Although we did not delete Advanced Mathematics , But because we've removed the places that advanced mathematics also uses 1, If we judge the existence of higher mathematics, we will get the wrong result , Although we didn't delete it .
Of course , In some scenarios where deletion is necessary , There is also a way . And it's very simple , Is to modify the data structure , Will be original each one bit Change to a int, When we insert elements , No longer will bit Set to true, But let the corresponding position increase , When it is deleted, it is the corresponding bit minus one . such , We can delete a single result without affecting other elements .
This method is not perfect , Due to the misjudgment of the bloon filter , It's possible that we'll delete values that don't exist , It also affects other elements .
Bloom filter is a data structure with obvious advantages and disadvantages , The advantages are excellent : Fast enough , Low memory consumption , Simple code implementation . But the disadvantages are obvious : Deleting elements... Is not supported , There will be miscalculations . This distinctive data structure is really attractive .
Today's article is all about , If you think you've got something , Please pay attention to it , Your help is very important to me .