当前位置:网站首页>高斯推断推导
高斯推断推导
2022-08-03 23:58:00 【威士忌燕麦拿铁】
设有一对服从多元正态分布的变量 ( x , y ) (\boldsymbol{x}, \boldsymbol{y}) (x,y),可以写出他们的联合概率密度函数:
p ( x , y ) = N ( [ μ x μ y ] , [ Σ x x Σ x y Σ y x Σ y y ] ) p(\boldsymbol{x}, \boldsymbol{y})=\mathcal{N}\left(\left[\begin{array}{l}\boldsymbol{\mu}_{x} \\\boldsymbol{\mu}_{y}\end{array}\right],\left[\begin{array}{ll}\boldsymbol{\Sigma}_{x x} & \boldsymbol{\Sigma}_{x y} \\\boldsymbol{\Sigma}_{y x} & \boldsymbol{\Sigma}_{y y}\end{array}\right]\right) p(x,y)=N([μxμy],[ΣxxΣyxΣxyΣyy])
其中, Σ y x = Σ x y T \boldsymbol{\Sigma}_{y x}=\boldsymbol{\Sigma}_{x y}^{\mathrm{T}} Σyx=ΣxyT。
由舒尔补有:
[ Σ x x Σ x y Σ y x Σ y y ] = [ 1 Σ x y Σ y y − 1 0 1 ] [ Σ x x − Σ x y Σ y y − 1 Σ y x 0 0 Σ y y ] [ 1 0 Σ y y − 1 Σ y x 1 ] \left[\begin{array}{cc}\boldsymbol{\Sigma}_{x x} & \boldsymbol{\Sigma}_{x y} \\\boldsymbol{\Sigma}_{y x} & \boldsymbol{\Sigma}_{y y}\end{array}\right]=\left[\begin{array}{cc}\mathbf{1} & \boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \\\mathbf{0} & \mathbf{1}\end{array}\right]\left[\begin{array}{cc}\boldsymbol{\Sigma}_{x x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x} & \mathbf{0} \\\mathbf{0} & \boldsymbol{\Sigma}_{y y}\end{array}\right]\left[\begin{array}{cc}\mathbf{1} & \mathbf{0} \\\boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x} & \mathbf{1}\end{array}\right] [ΣxxΣyxΣxyΣyy]=[10ΣxyΣyy−11][Σxx−ΣxyΣyy−1Σyx00Σyy][1Σyy−1Σyx01]
对两边同时求逆有:
[ Σ x x Σ x y Σ y x Σ y y ] − 1 = [ 1 0 − Σ y y − 1 Σ y x 1 ] [ ( Σ x x − Σ x y Σ y y − 1 Σ y x ) − 1 0 0 Σ y y − 1 ] [ 1 − Σ x y Σ y y − 1 0 1 ] {\left[\begin{array}{cc}\boldsymbol{\Sigma}_{x x} & \boldsymbol{\Sigma}_{x y} \\\boldsymbol{\Sigma}_{y x} & \boldsymbol{\Sigma}_{y y}\end{array}\right]^{-1}= \left[\begin{array}{cc}\mathbf{1} & \mathbf{0} \\-\boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x} & \mathbf{1}\end{array}\right]} \left[\begin{array}{cc}\left(\boldsymbol{\Sigma}_{x x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x}\right)^{-1} & \boldsymbol{0} \\\boldsymbol{0} & \boldsymbol{\Sigma}_{y y}^{-1}\end{array}\right]\left[\begin{array}{cc}\mathbf{1} & -\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \\\mathbf{0} & \mathbf{1}\end{array}\right] [ΣxxΣyxΣxyΣyy]−1=[1−Σyy−1Σyx01][(Σxx−ΣxyΣyy−1Σyx)−100Σyy−1][10−ΣxyΣyy−11]
因此,联合概率密度函数 p ( x , y ) p(\boldsymbol{x}, \boldsymbol{y}) p(x,y) 指数部分的二次项为:
( [ x y ] − [ μ x μ y ] ) T [ Σ x x Σ x y Σ y x Σ y y ] − 1 ( [ x y ] − [ μ x μ y ] ) = ( [ x y ] − [ μ x μ y ] ) T [ 1 0 − Σ y y − 1 Σ y x 1 ] [ ( Σ x x − Σ x y Σ y y − 1 Σ y x ) − 1 0 0 Σ y y − 1 ] × [ 1 − Σ x y Σ y y − 1 0 1 ] ( [ x y ] − [ μ x μ y ] ) = ( x − μ x − Σ x y Σ y y − 1 ( y − μ y ) ) T ( Σ x x − Σ x y Σ y y − 1 Σ y x ) − 1 × ( x − μ x − Σ x y Σ y y − 1 ( y − μ y ) ) + ( y − μ y ) T Σ y y − 1 ( y − μ y ) \begin{aligned}&\left(\left[\begin{array}{l}\boldsymbol{x} \\\boldsymbol{y}\end{array}\right]-\left[\begin{array}{l}\boldsymbol{\mu}_{x} \\\boldsymbol{\mu}_{y}\end{array}\right]\right)^{\mathrm{T}}\left[\begin{array}{ll}\boldsymbol{\Sigma}_{x x} & \boldsymbol{\Sigma}_{x y} \\\boldsymbol{\Sigma}_{y x} & \boldsymbol{\Sigma}_{y y}\end{array}\right]^{-1}\left(\left[\begin{array}{l}\boldsymbol{x} \\\boldsymbol{y}\end{array}\right]-\left[\begin{array}{l}\boldsymbol{\mu}_{x} \\\boldsymbol{\mu}_{y}\end{array}\right]\right) \\=&\left(\left[\begin{array}{l}\boldsymbol{x} \\\boldsymbol{y}\end{array}\right]-\left[\begin{array}{l}\boldsymbol{\mu}_{x} \\\boldsymbol{\mu}_{y}\end{array}\right]\right)^{\mathrm{T}}\left[\begin{array}{cc}\boldsymbol{1} & \boldsymbol{0} \\-\boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x} & \boldsymbol{1}\end{array}\right]\left[\begin{array}{cc}\left(\boldsymbol{\Sigma}_{x x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x}\right)^{-1} & \boldsymbol{0} \\\mathbf{0} & \boldsymbol{\Sigma}_{y y}^{-1}\end{array}\right] \\& \times\left[\begin{array}{cc}\mathbf{1} & -\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \\\mathbf{0} & \mathbf{1}\end{array}\right]\left(\left[\begin{array}{l}\boldsymbol{x} \\\boldsymbol{y}\end{array}\right]-\left[\begin{array}{l}\boldsymbol{\mu}_{x} \\\boldsymbol{\mu}_{y}\end{array}\right]\right) \\=&\left(\boldsymbol{x}-\boldsymbol{\mu}_{x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1}\left(\boldsymbol{y}-\boldsymbol{\mu}_{y}\right)\right)^{\mathrm{T}}\left(\boldsymbol{\Sigma}_{x x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x}\right)^{-1} \\& \times\left(\boldsymbol{x}-\boldsymbol{\mu}_{x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1}\left(\boldsymbol{y}-\boldsymbol{\mu}_{y}\right)\right)+\left(\boldsymbol{y}-\boldsymbol{\mu}_{y}\right)^{\mathrm{T}} \boldsymbol{\Sigma}_{y y}^{-1}\left(\boldsymbol{y}-\boldsymbol{\mu}_{y}\right)\end{aligned} ==([xy]−[μxμy])T[ΣxxΣyxΣxyΣyy]−1([xy]−[μxμy])([xy]−[μxμy])T[1−Σyy−1Σyx01][(Σxx−ΣxyΣyy−1Σyx)−100Σyy−1]×[10−ΣxyΣyy−11]([xy]−[μxμy])(x−μx−ΣxyΣyy−1(y−μy))T(Σxx−ΣxyΣyy−1Σyx)−1×(x−μx−ΣxyΣyy−1(y−μy))+(y−μy)TΣyy−1(y−μy)
很明显可以看出,这是两个二次项的和。
又由贝叶斯公式有:
p ( x , y ) = p ( x ∣ y ) p ( y ) p(\boldsymbol{x}, \boldsymbol{y})=p(\boldsymbol{x} \mid \boldsymbol{y}) p(\boldsymbol{y}) p(x,y)=p(x∣y)p(y)
并且:
p ( y ) = N ( μ y , Σ y y ) p(\boldsymbol{y}) =\mathcal{N}\left(\boldsymbol{\mu}_{y}, \boldsymbol{\Sigma}_{y y}\right) p(y)=N(μy,Σyy)
因此,由幂运算中同底数幂相乘,底数不变、指数相加的性质,可以得到:
p ( x ∣ y ) = N ( μ x + Σ x y Σ y y − 1 ( y − μ y ) , Σ x x − Σ x y Σ y y − 1 Σ y x ) p(\boldsymbol{x} \mid \boldsymbol{y}) =\mathcal{N}\left(\boldsymbol{\mu}_{x}+\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1}\left(\boldsymbol{y}-\boldsymbol{\mu}_{y}\right), \boldsymbol{\Sigma}_{x x}-\boldsymbol{\Sigma}_{x y} \boldsymbol{\Sigma}_{y y}^{-1} \boldsymbol{\Sigma}_{y x}\right) p(x∣y)=N(μx+ΣxyΣyy−1(y−μy),Σxx−ΣxyΣyy−1Σyx)
这便是高斯推断中最重要的部分:从状态的先验概率分布出发,然后基于一些观测值来缩小这个范围。
边栏推荐
猜你喜欢
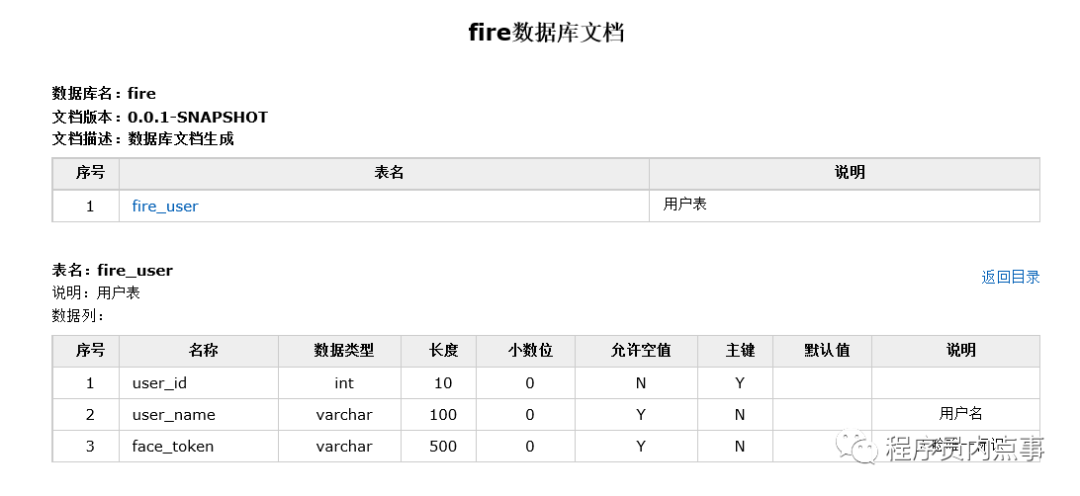
jav一键生成数据库文档
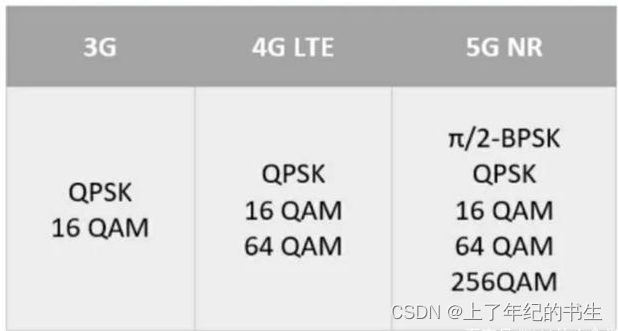
射频芯片(RFIC)的协议之5G及其调制
![[Miscellaneous] How to install the specified font into the computer and then use the font in the Office software?](/img/15/23b0724f9c9672c61b91320f1b84d8.png)
[Miscellaneous] How to install the specified font into the computer and then use the font in the Office software?
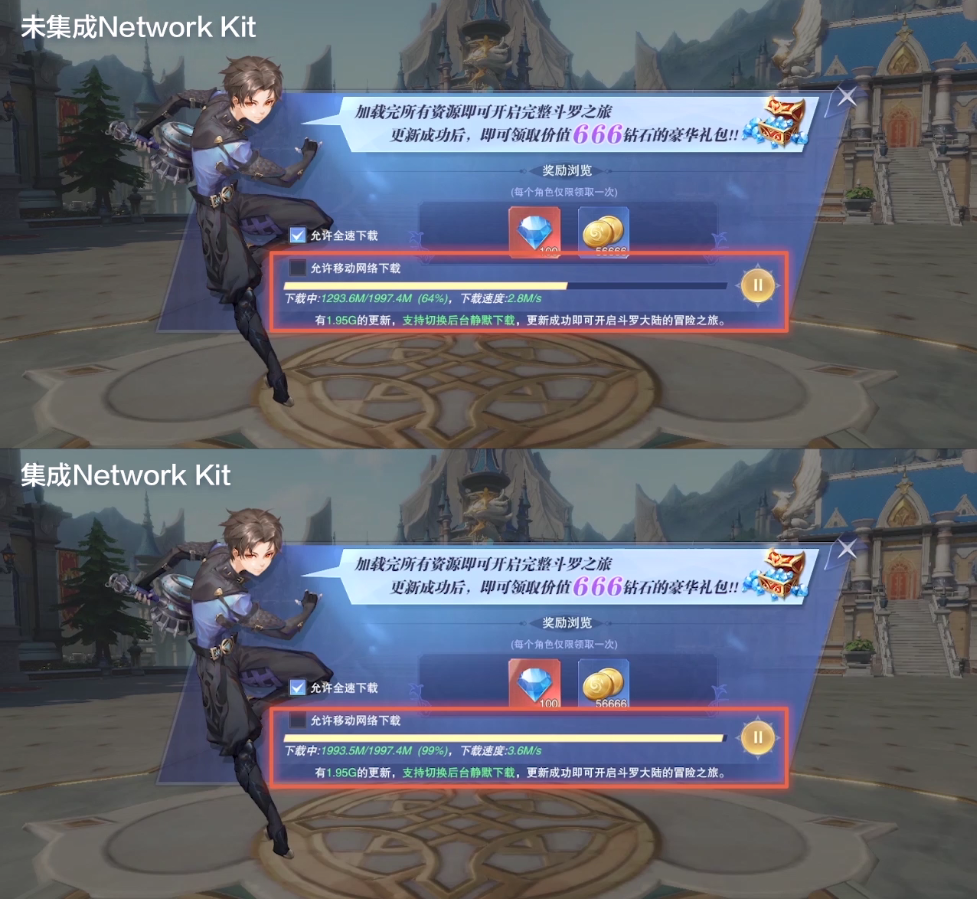
The Chinese Valentine's Day event is romantically launched, don't let the Internet slow down and miss the dark time
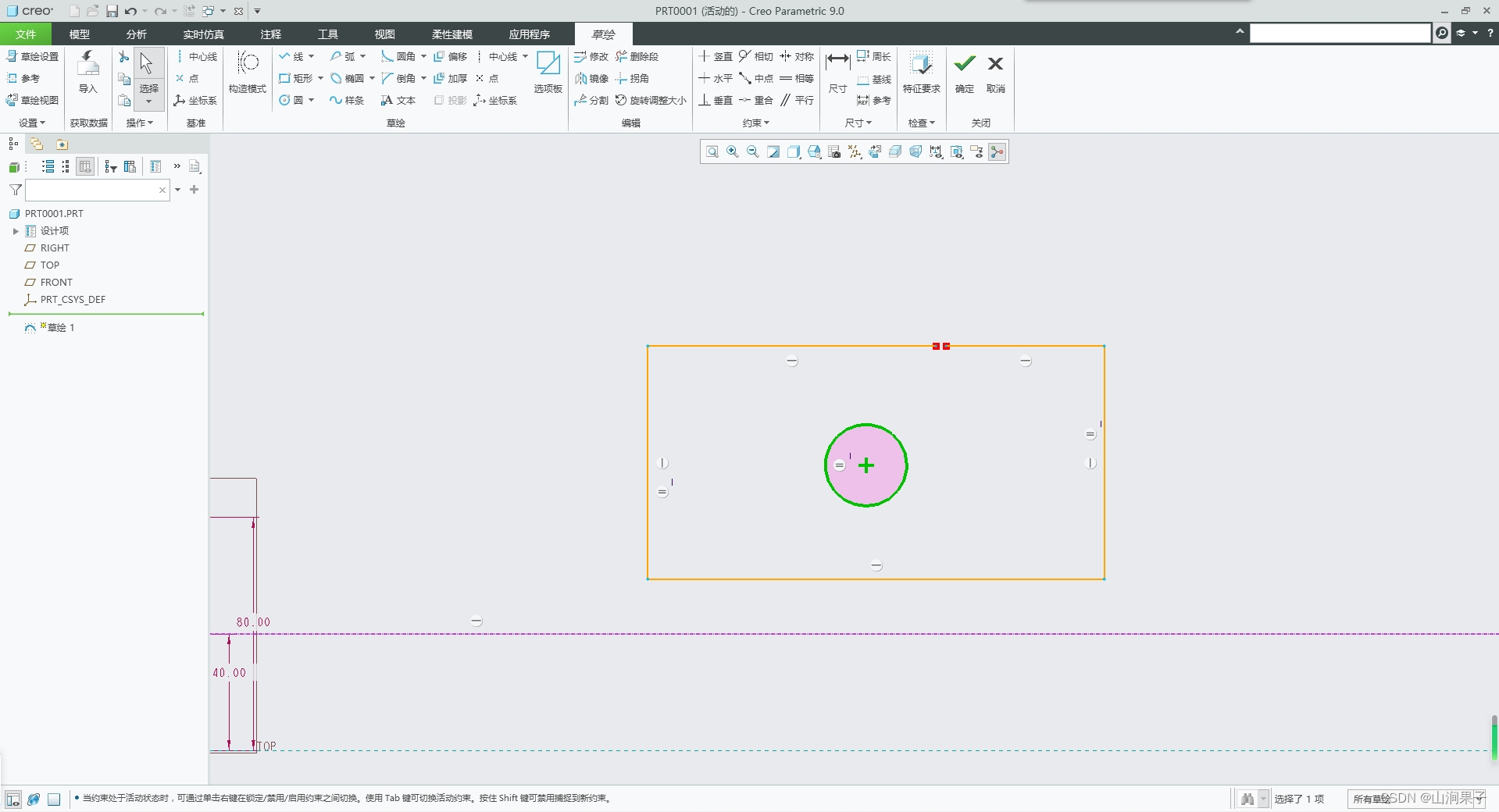
Creo 9.0二维草图的诊断:加亮开放端点

小身材有大作用——光模块基础知识(一)

Apple told Qualcomm: I bought a new campus for $445 million and may plan to speed up self-development of baseband chips
In V8 how arrays (with source code, picture and text easier to understand)

XSLT – 服务器端概述
分布式事务框架 seata
随机推荐
SolidEdge ST8安装教程
The problem of disorganized data output by mnn model
汉字风格迁移---结合本地和全局特征学习的中文字体迁移
rsync 基础用法
响应式织梦模板除尘器类网站
并查集详解
1067 Sort with Swap(0, i)
状态机实验
Creo 9.0创建几何点
密码学基础以及完整加密通讯过程解析
禾匠编译错误记录
浅谈我国产业园区未来的发展方向
LeetCode 0155. 最小栈
伦敦银最新均线分析系统怎么操作?
BPF 可移植性和 CO-RE(一次编译,到处运行)
"Miscellaneous" barcode by Excel as a string
689. 三个无重叠子数组的最大和
Salesforce's China business may see new changes, rumors may be closing
Go编译原理系列7(Go源码调试)
Read FastDFS in one article