当前位置:网站首页>The latest NLP game practice summary!
The latest NLP game practice summary!
2022-07-01 15:43:00 【Datawhale】

Introduction to the contest question
In order to improve the competitiveness of products, domestic automobile enterprises 、 Better go to overseas markets , Put forward the demand for intelligent interaction in overseas markets . But countries around the world are “ Data security ” There are strict legal restrictions on , Do a good job in overseas intelligent interaction , The biggest challenge for local enterprises is the lack of data . This competition requires the contestants to pass NLP Relevant artificial intelligence algorithms to achieve multilingual transfer learning in the automotive field .
Event address :https://challenge.xfyun.cn/topic/info?type=car-multilingual&ch=ds22-dw-gzh01
The mission of the event
In this transfer learning task , IFLYTEK smart car BU There will be more in car human-computer interaction Chinese corpus , And a small amount of Chinese and English 、 China and Japan 、 Chinese and Arabic parallel corpora are used as training sets .
Contestants build models from the data provided , Carry out intention classification and key information extraction tasks , The final use of English 、 Japanese 、 Test and judge in Arabic .
1. Preliminaries
- Training set : Chinese corpus 30000 strip , Chinese and English parallel corpora 1000 strip , Chinese and Japanese parallel corpora 1000 strip
- Test set A: English Corpus 500 strip , Japanese Corpus 500 strip
- Test set B: English Corpus 500 strip , Japanese Corpus 500 strip 2. The rematch
- Training set : Chinese corpus is the same as the preliminary contest , Chinese Arabic parallel corpora 1000 strip
- Test set A: Arabic corpus 500 strip
- Test set B: Arabic corpus 500 strip Question data
This competition provides three types of in car interactive function corpus for contestants , This includes command control classes 、 Navigation class 、 Music .
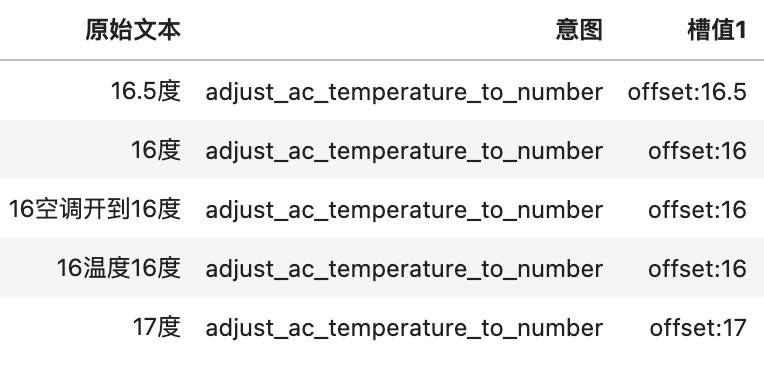
More Chinese corpora and less multilingual parallel corpora contain intention classification and key information , Players need to make full use of the data provided , In Britain 、 Japan 、 Good results have been achieved in the task of intention classification and key information extraction in Arabic corpus . The label types and value types contained in the data are shown in the following table .
| Variable | The numerical format | explain |
|---|---|---|
| intent | string | Whole sentence intention tag |
| device | string | Operation equipment name label |
| mode | string | Operation device mode label |
| offset | string | Operation equipment adjustment label |
| endloc | string | Destination label |
| landmark | string | Search around the reference label |
| singer | string | singer |
| song | string | song |
Evaluation indicators
This model is based on the submitted result document , use accuracy Evaluate .
Intention classification intention correct number total data volume
Key information extraction key information completely correct number total data volume
notes :
It is wrong to draw more or less key information of each data , Finally, we get the average value of intention classification and key information extraction ;
Language conversion is not allowed in the prediction process , The language provided by the test set must be used for intention classification and key information extraction tasks directly .
Their thinking
Intention is classified as a typical text task ;
Information extraction is an entity extraction task ;
The competition task has the following characteristics :
Multilingual text , Need to consider multilingualism BERT;
Short text , You can try keyword matching ;
So let's use TFIDF + The idea of logical regression , In the future, we will continue to share and use BERT The idea of matching keywords .
step 1: Import library
import pandas as pd # Read the file
import numpy as np # Numerical calculation
import nagisa # Japanese word segmentation
from sklearn.feature_extraction.text import TfidfVectorizer # Text feature extraction
from sklearn.linear_model import LogisticRegression # Logical regression
from sklearn.pipeline import make_pipeline # Assembly line step 2: Reading data
# Reading data
train_cn = pd.read_excel(' The preliminary training set of the multilingual transfer learning challenge in the automotive field / chinese _trian.xlsx')
train_ja = pd.read_excel(' The preliminary training set of the multilingual transfer learning challenge in the automotive field / Japanese _train.xlsx')
train_en = pd.read_excel(' The preliminary training set of the multilingual transfer learning challenge in the automotive field / english _train.xlsx')
test_ja = pd.read_excel('testA.xlsx', sheet_name=' Japanese _testA')
test_en = pd.read_excel('testA.xlsx', sheet_name=' english _testA')step 3: Text participle
# Text participle
train_ja['words'] = train_ja[' Original text '].apply(lambda x: ' '.join(nagisa.tagging(x).words))
train_en['words'] = train_en[' Original text '].apply(lambda x: x.lower())
test_ja['words'] = test_ja[' Original text '].apply(lambda x: ' '.join(nagisa.tagging(x).words))
test_en['words'] = test_en[' Original text '].apply(lambda x: x.lower())step 4: Build the model
# Training TFIDF And logical regression
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_ja['words'].tolist() + train_en['words'].tolist(),
train_ja[' Intention '].tolist() + train_en[' Intention '].tolist()
)
# Model to predict
test_ja[' Intention '] = pipline.predict(test_ja['words'])
test_en[' Intention '] = pipline.predict(test_en['words'])
test_en[' Slot value 1'] = np.nan
test_en[' Slot value 2'] = np.nan
test_ja[' Slot value 1'] = np.nan
test_ja[' Slot value 2'] = np.nan
# Write the submission
writer = pd.ExcelWriter('submit.xlsx')
test_en.drop(['words'], axis=1).to_excel(writer, sheet_name=' english _testA', index=None)
test_ja.drop(['words'], axis=1).to_excel(writer, sheet_name=' Japanese _testA', index=None)
writer.save()
writer.close()Focus on Datawhale official account , reply “NLP” Invite in NLP The competition exchange group , You don't need to add any more if you are already there .

Sorting is not easy to , spot Fabulous Three even ↓
边栏推荐
- Implementation of wechat web page subscription message
- Qt+pcl Chapter 9 point cloud reconstruction Series 2
- 求求你们,别再刷 Star 了!这跟“爱国”没关系!
- Wechat applet 02 - Implementation of rotation map and picture click jump
- 华为发布HCSP-Solution-5G Security人才认证,助力5G安全人才生态建设
- 药品溯源夯实安全大堤
- 七夕表白攻略:教你用自己的专业说情话,成功率100%,我只能帮你们到这里了啊~(程序员系列)
- Microservice tracking SQL (support Gorm query tracking under isto control)
- 重回榜首的大众,ID依然乏力
- 【一天学awk】条件与循环
猜你喜欢

An intrusion detection model

【300+精选大厂面试题持续分享】大数据运维尖刀面试题专栏(三)
Detailed explanation of stm32adc analog / digital conversion
![[target tracking] |stark](/img/e2/83e9d97cfb8c49cfb8d912cfe2f858.png)
[target tracking] |stark
新出生的机器狗,打滚1小时后自己掌握走路,吴恩达开山大弟子最新成果
Some abilities can't be learned from work. Look at this article, more than 90% of peers

工厂高精度定位管理系统,数字化安全生产管理

Deep operator overloading (2)
MySQL backup and restore single database and single table
Pnas: brain and behavior changes of social anxiety patients with empathic embarrassment
随机推荐
Don't ask me again why MySQL hasn't left the index? For these reasons, I'll tell you all
Hardware design guide for s32k1xx microcontroller
SAP s/4hana: one code line, many choices
Go语学习笔记 - gorm使用 - 表增删改查 | Web框架Gin(八)
STM32F4-TFT-SPI时序逻辑分析仪调试记录
[target tracking] |stark
【STM32学习】 基于STM32 USB存储设备的w25qxx自动判断容量检测
STM32ADC模拟/数字转换详解
Summary of week 22-06-26
Crypto Daily:孙宇晨在MC12上倡议用数字化技术解决全球问题
SAP S/4HANA: 一条代码线,许多种选择
Équipe tensflow: Nous ne sommes pas abandonnés
如何写出好代码 - 防御式编程指南
【OpenCV 例程200篇】216. 绘制多段线和多边形
Is JPMorgan futures safe to open an account? What is the account opening method of JPMorgan futures company?
Task.Run(), Task.Factory.StartNew() 和 New Task() 的行为不一致分析
Deep operator overloading (2)
TensorFlow團隊:我們沒被拋弃
u本位合约和币本位合约有区别,u本位合约会爆仓吗
MySQL backup and restore single database and single table