当前位置:网站首页>Compilation principle: preprocessing of source program and design and implementation of lexical analysis program (including code)
Compilation principle: preprocessing of source program and design and implementation of lexical analysis program (including code)
2022-07-06 12:25:00 【Junfu Xiaotong】
The preprocessing of source program and the design and implementation of lexical analysis program
Let me write it first : The code is written according to your own ideas , It is different from the method mentioned in this blog .
another : My code reads the code that needs to be processed from the document , After processing, print it in the other two documents , Direct replication may not work , You need to create three documents by yourself : Document a ( Source code ); Document 2 ( The source code after preprocessing ); Document three ( Binary ). Remember to check whether the file location and name are correct .
One 、 The experiment purpose
Design and implement a lexical analysis program with preprocessing function , Deepen the understanding of lexical analysis process in compilation .
Two 、 The experimental requirements
1、 Realize the preprocessing function
The source program may contain symbols that are meaningless to program execution , It is required to be removed .
First, compile the input process of a source program , From the keyboard 、 Enter several lines in the file or text box , Store in the input buffer in sequence ( Character data );
Then compile a preprocessing subroutine , Remove the carriage return in the input string 、 Line breaks, tabs and other editorial text ;
Match multiple blanks into one ;
Remove annotations .
2、 Realize lexical analysis function
Input : The source program string of the given grammar .
Output : Binary (syn,token or sum) Sequence of composition .
among ,syn Code for words .Token String for the stored word itself .Sum Is an integer constant .
Concrete implementation , You can handle the word's binary with a structure .
3、 To be analyzed C Morphology of language subset ( It can be expanded by itself , You can also follow C Lexical definition of language )
1) keyword
main if then while do static int double struct break else long switch case typedef char return const float short continue for void default sizeof do
All keywords are lowercase .
2) Operators and delimiters
+ - * / : := < <> <= > >= = ; ( ) #
3) Other marks ID and NUM
Define other tags through the following formal formula :
ID→letter(letter|digit)*
NUM→digit digit*
letter→a|…|z|A|…|Z
digit→0|…|9…
4) The space consists of a blank 、 Tabs and line breaks make up
Spaces are usually used to separate ID、NUM、 Special symbols and keywords , The lexical analysis phase is usually ignored .
4、 The category code corresponding to various word symbols
surface 1 Different codes of various word symbols
| Word symbols | Species code | Word symbols | Species code |
|---|---|---|---|
| main | 1 | ; | 41 |
| if | 2 | ( | 42 |
| then | 3 | ) | 43 |
| while | 4 | int | 7 |
| do | 5 | double | 8 |
| static | 6 | struct | 9 |
| ID | 25 | break | 10 |
| NUM | 26 | else | 11 |
| + | 27 | long | 12 |
| - | 28 | switch | 13 |
| * | 29 | case | 14 |
| / | 30 | typedef | 15 |
| : | 31 | char | 16 |
| := | 32 | return | 17 |
| < | 33 | const | 18 |
| <> | 34 | float | 19 |
| <= | 35 | short | 20 |
| > | 36 | continue | 21 |
| >= | 37 | for | 22 |
| = | 38 | void | 23 |
| default | 39 | sizeof | 24 |
| do | 40 | # | 0 |
5、 The main algorithm idea of lexical analysis program
The basic task of the algorithm is to recognize words and symbols with independent meanings from the source program represented by strings , The basic idea is based on the type of the first character of the scanned word symbol , Spell the corresponding word symbols .
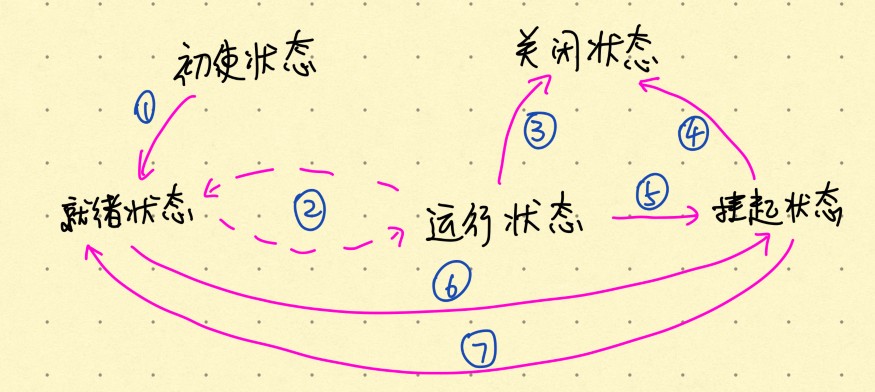
1. Schematic diagram of main program 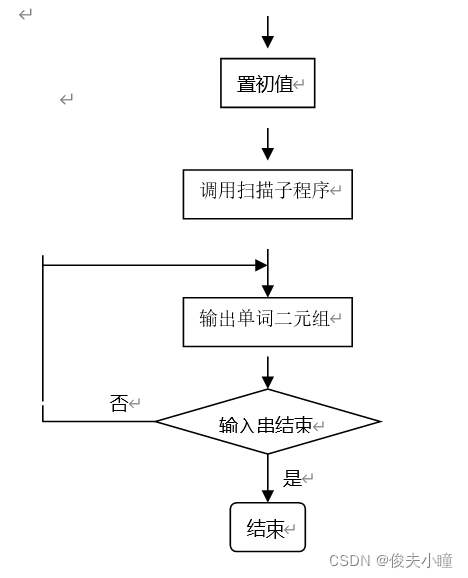
The initial value includes the following two aspects :
(1) Initial value of keyword table
Keywords are treated as special identifiers , Arrange them in a table in advance ( It's called the keyword table ), When the scanner recognizes the identifier , Look up the keyword table .
If you can find a matching word , Then the word is the keyword , Otherwise, it is a general identifier . Turn off
The key word table is an array of strings , Its description is as follows :
char *rwtab[27]={“main”,”if”,”then”,”while”,”do”,” static”,”int”,” double”,”struct”,”break”,”else”,”long”,”switch”,”case”,”typedef”,”char”,”return”,”const”,”float”,”short”,”continue”,”for”,”void”,”default”,”sizeof”,”do”};
(2) The main variables needed in the program :syn,token and sum.
2. Algorithm idea of scanning subroutine
First set three variables :
token Used to store the strings that make up word symbols ;
sum Used to store integer words ;
syn The category code used to store word symbols .
The main flow of the scanning subroutine is shown in the figure 2 Shown .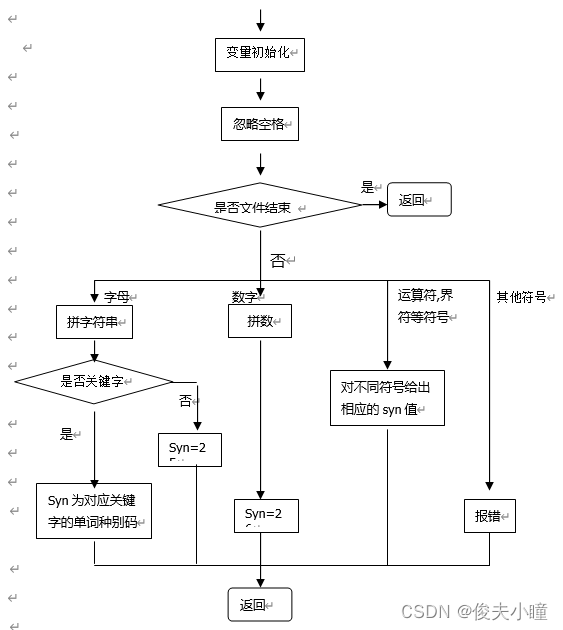
3、 ... and 、 Experimental code
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
char key[26][20] = {
"main","if","then","while","do"," static","int"," double","struct","break","else","long","switch","case","typedef","char",
"return","const","float","short","continue","for","void","sizeof","default","do"};
//da yin
void p(char* str)
{
printf("%s\n",str);
}
//shan chu kong ge
void deblank(char *str)
{
char s[10000];
char s1[10000]={
NULL};
int i=0,j=0,next=0;
strcpy(s,str);
while(s[j]!=EOF)
{
s1[i]=s[j];
i++;
j++;
if(s[j-1]==' ')
{
next=j;
while(s[next]==' ')next++;
j=next;
}
// if(s[j]!=' ')
// {
// str[i]=s[j];
// i++;
// j++;
// }
// else
// {
// str[i]=s[j];
// i++;
// j++;
// next=j;
// while(s[next]==' ')next++;
// j=next;
// }
}
// while(str[i++]!='\0')str[i-1]='\0';
// p(s1);
strcpy(str,s1);
}
//shan chu zhu shi
void zhushi(char *str)
{
int i,j;
char s[10000];
strcpy(s,str);
for(i=0,j=0;s[i]!=EOF;i++,j++)
{
if(s[i]=='/'&&s[i+1]=='/')
{
str[j]=' ';
while(s[i]!='\n')i++;
}
else
{
str[j]=s[i];
}
}
strcpy(s,str);
for(i=0,j=0;s[i]!=EOF;i++,j++)
{
if(s[i]=='/'&&s[i+1]=='*')
{
str[j]=' ';
while(s[i]!='*'||s[i+1]!='/')
{
i++;
if(s[i]==EOF)
{
printf(" Incorrect comments .\n");
system("pause");
exit(0);
}
}
i=i+1;
}
else
{
str[j]=s[i];
}
}
deblank(str);
// p(str);
}
//shan chu hui che haun hang
void enter(char *str)
{
int i,j=0;
char s[10000];
strcpy(s,str);
for(i=0;s[i]!=EOF;i++,j++)
{
if(s[i]=='\n'||s[i]=='\r'||s[i]=='\t')
{
s[i]=' ';
str[j]=s[i];
}
else
{
str[j]=s[i];
}
}
// p(str);
}
int zm(char a)
{
if(a>='a'&&a<='z'||a>='A'&&a<='Z')
{
return 1;
}
else
{
return 0;
}
}
int sz(char a)
{
if(a>='0'&&a<='9')
{
return 1;
}
else
{
return 0;
}
}
void xr(char *a,int b)
{
FILE *fp;
fp=fopen("D:\\app\\vscode\\codes\\compilation\\exp1-3.txt","a");
if(fp==NULL)
{
printf("fail to open the file!\n");
system("pause");
exit(0);
}
if(b>=0)
{
fprintf(fp, "<%s,%d>\n", a, b);
}
else
{
fprintf(fp, " Can't recognize \"%c\"\n",a[0]);
}
fclose(fp);
}
void id(char *a)
{
int i,b;
for(i = 0; i<26;i++)
{
if(strcmp(a,key[i]) == 0)
{
if(i<24)
{
b=i+1;
}
else
{
if(i==24) b=39;
if(i==25) b=40;
}
xr(key[i],b);
return;
}
}
xr(a,25);
}
void cffx()
{
FILE *fp;
char ch;
char str[10000];
char word[50];
char numb[50];
int i,j,k;
fp=fopen("D:\\app\\vscode\\codes\\compilation\\exp1-2.txt","r");
if(fp==NULL)
{
printf("fail to open the file!\n");
exit(0);
}
i=0;
while((ch=fgetc(fp))!=EOF)
{
str[i]=ch;
i++;
}
for(i=0,j=0,k=0;str[i]!=NULL;i++)
{
int a,b;
a=zm(str[i]);
if(a==1)
{
word[j]=str[i];
j++;
for(;;)
{
i++;
a=zm(str[i]);
b=sz(str[i]);
if(a==1||b==1)
{
word[j]=str[i];
j++;
}
else
{
id(word);
memset(word,0,sizeof(word));
j=0;
break;
}
}
i--;
continue;
}
a=sz(str[i]);
if(a==1)
{
numb[k]=str[i];
k++;
for(;;)
{
i++;
a=sz(str[i]);
if(a==1||str[i]=='e'||str[i]=='E'||str[i]=='.')
{
if(str[i]=='.'&&sz(str[i+1])==0)
{
printf(" Decimal point error .\n");
system("pause");
exit(0);
}
numb[k]=str[i];
k++;
}
else
{
xr(numb,26);
memset(numb,0,sizeof(numb));
k=0;
break;
}
}
i--;
continue;
}
if(str[i]==' ')
{
continue;
}
switch(str[i])
{
case '+': xr((char*)"+",27);break;
case '-': xr((char*)"-",28);break;
case '*': xr((char*)"*",29);break;
case '/': xr((char*)"/",29);break;
case '=': xr((char*)"=",38);break;
case ';': xr((char*)";",41);break;
case '(': xr((char*)"(",42);break;
case ')': xr((char*)")",43);break;
case '#': xr((char*)"#",0);break;
case '.': xr((char*)".",-1);break;
case '{': xr((char*)"{",-1);break;
case '}': xr((char*)"}",-1);break;
case '%': xr((char*)"%",-1);break;
case '\"': xr((char*)"\"",-1);break;
case '\\': xr((char*)"\\",-1);break;
case ',': xr((char*)",",-1);break;
case '|':
if(str[i+1] == '|')
{
i++;
xr((char*)"||",-1);
}
else
{
xr((char*)"|",-1);
}
break;
case '&':
if(str[i+1] == '&')
{
i++;
xr((char*)"&&",-1);
}
else
{
xr((char*)"&",-1);
}
break;
case ':':
if(str[i+1] == '=')
{
i++;
xr((char*)":=",32);
}
else
{
xr((char*)":",31);
}
break;
case '<':
if(str[i+1] == '>')
{
i++;
xr((char*)"<>",34);
}
else if(str[i+1] == '=')
{
i++;
xr((char*)"<=",35);
}
else
{
xr((char*)"<",33);
}
break;
case '>':
if(str[i+1] == '=')
{
i++;
xr((char*)">=",37);
}
else
{
xr((char*)">",36);
}
break;
// default : xr(&str[i],-1);break;
}
}
}
int main()
{
FILE *fp;
char ch;
char str[10000];
int i=0;
fp=fopen("D:\\app\\vscode\\codes\\compilation\\exp1-1.txt","r");
if(fp==NULL)
{
printf("fail to open the file!\n");
exit(0);
}
else
{
// printf("The file is open!\n");
while((ch=fgetc(fp))!=EOF)
{
str[i]=ch;
i++;
// putchar(ch);
}
// printf("%s\n",str);
// Read file contents :
// 1.
// while((ch=fgetc(fp))!=EOF)putchar(ch);
// 2.
// ch=fgetc(fp);
// while(ch!=EOF)
// {
// putchar(ch);
// ch=fgetc(fp);
// }
// 3.
// while(!feof(fp))printf("%c",fgetc(fp));
// while((ch=getchar())!='#')
// {
// fputc(ch,fp);
// }
zhushi(str);
enter(str);
deblank(str);
// fclose(fp);
}
FILE *fpp;
fpp=fopen("D:\\app\\vscode\\codes\\compilation\\exp1-2.txt","w");
if(fpp==NULL)
{
printf("fail to open the file!\n");
exit(0);
}
else
{
// printf("The file is open!\n");
fputs(str,fpp);
fclose(fpp);
fclose(fp);
}
FILE *file;
file = fopen("D:\\app\\vscode\\codes\\compilation\\exp1-3.txt","w");
fclose(file);
cffx();
printf(" Processing is complete \n");
system("pause");
return 0;
}
Running results :
Example :
/main/
if(a>3)
{
a–;//a>3
}
Console :
Document a ( Source code ):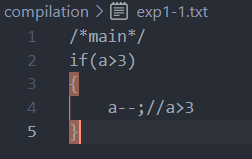
Document 2 ( Code after preprocessing ):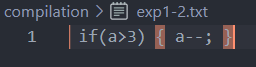
Document three ( Binary ):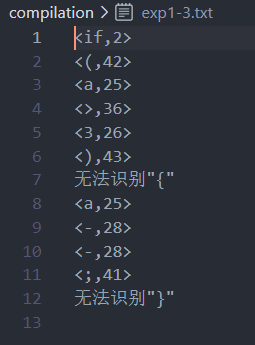
Okay , end , If intermediate result document 2 is not required , You can comment out .
边栏推荐
- [Offer29] 排序的循环链表
- Pytorch four commonly used optimizer tests
- . elf . map . list . Hex file
- JS variable types and common type conversions
- [leetcode15] sum of three numbers
- Imgcat usage experience
- [offer78] merge multiple ordered linked lists
- PT OSC deadlock analysis
- [offer18] delete the node of the linked list
- ES6 grammar summary -- Part I (basic)
猜你喜欢
ESP学习问题记录

记一次云服务器被密码爆破的经历——关小黑屋、改密码、改端口
ORA-02030: can only select from fixed tables/views
First use of dosbox
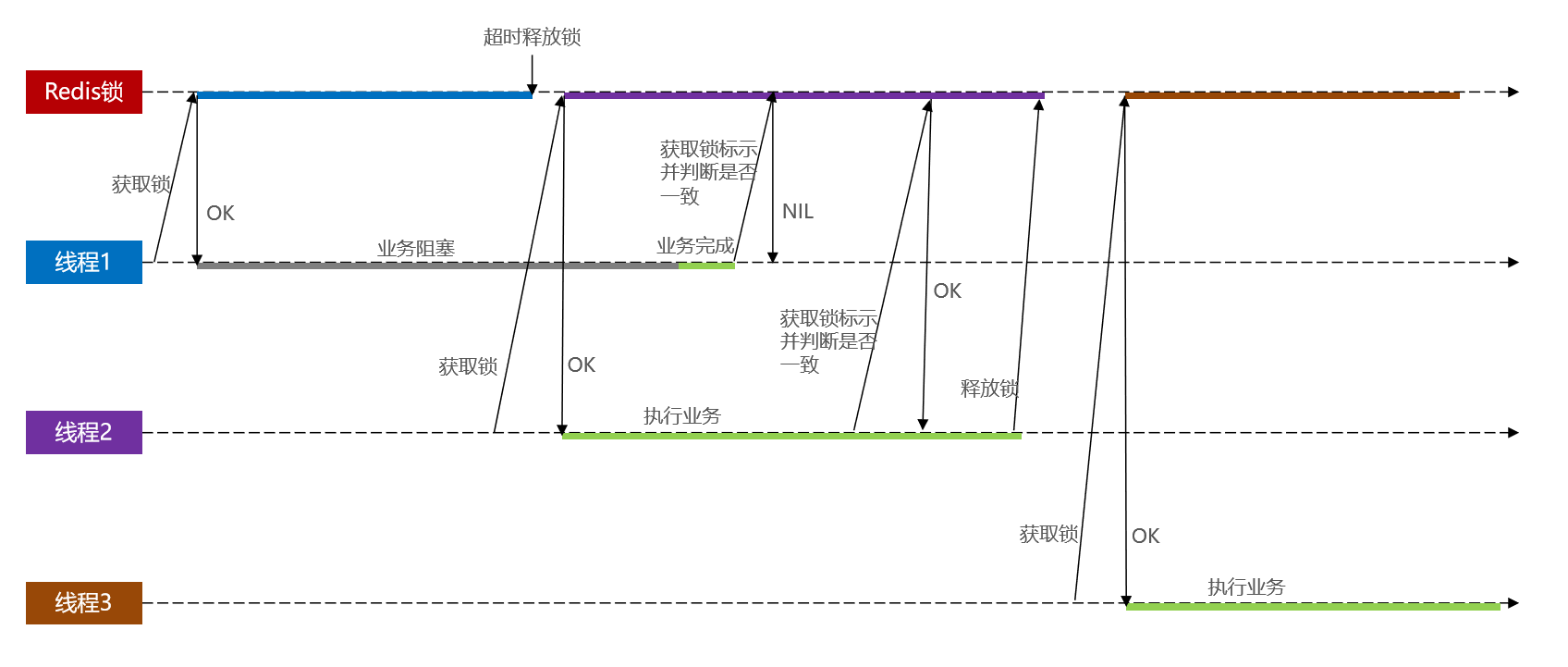
基于Redis的分布式锁 以及 超详细的改进思路
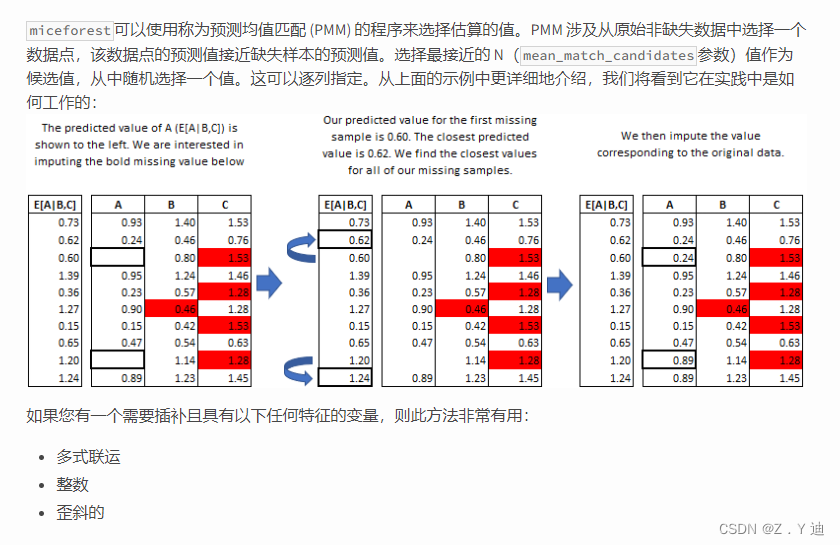
Missing value filling in data analysis (focus on multiple interpolation method, miseforest)
dosbox第一次使用
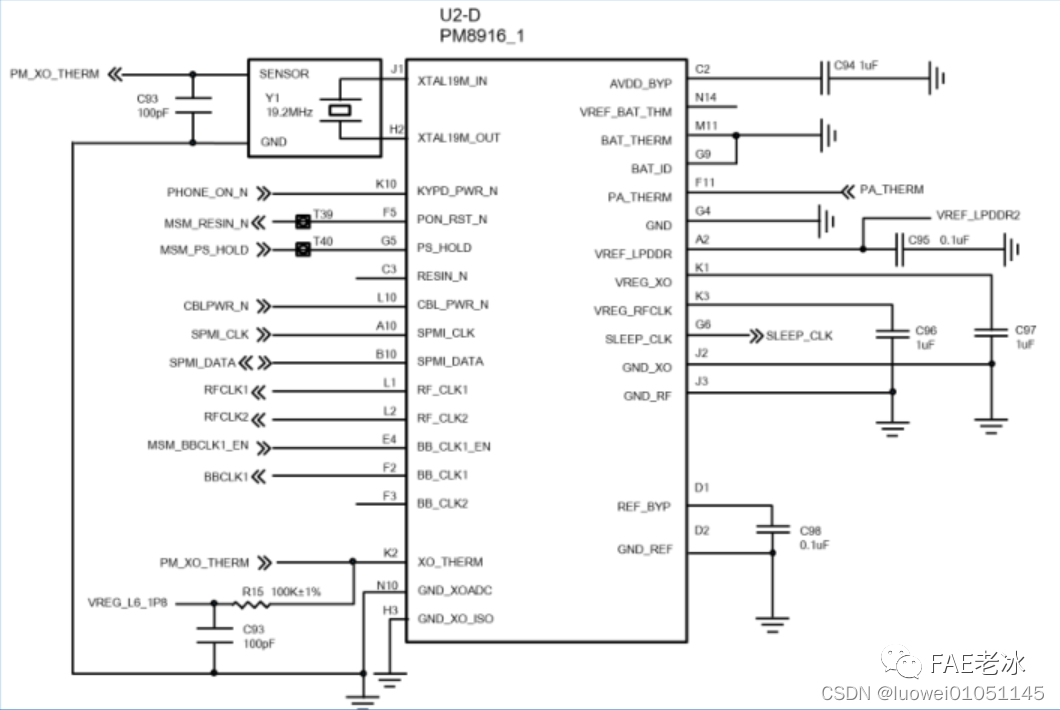
Working principle of genius telephone watch Z3
A possible cause and solution of "stuck" main thread of RT thread

基於Redis的分布式ID生成器
随机推荐
Pytoch temperature prediction
[leetcode19]删除链表中倒数第n个结点
Esp8266 uses Arduino to connect Alibaba cloud Internet of things
Page performance optimization of video scene
记一次云服务器被密码爆破的经历——关小黑屋、改密码、改端口
Rough analysis of map file
JS regular expression basic knowledge learning
Arduino get random number
Intermediate use tutorial of postman [environment variables, test scripts, assertions, interface documents, etc.]
[Leetcode15]三数之和
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
A possible cause and solution of "stuck" main thread of RT thread
By v$rman_ backup_ job_ Oracle "bug" caused by details
[Offer29] 排序的循环链表
ES6语法总结--下篇(进阶篇 ES6~ES11)
AMBA、AHB、APB、AXI的理解
Arduino gets the length of the array
Learning notes of JS variable scope and function
Générateur d'identification distribué basé sur redis
MySQL時間、時區、自動填充0的問題