当前位置:网站首页>将模型的记忆保存下来!Meta&UC Berkeley提出MeMViT,建模时间支持比现有模型长30倍,计算量仅增加4.5%...
将模型的记忆保存下来!Meta&UC Berkeley提出MeMViT,建模时间支持比现有模型长30倍,计算量仅增加4.5%...
2022-07-07 16:34:00 【我爱计算机视觉】
关注公众号,发现CV技术之美
CVPR 2022 论文『MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition』,Facebook&UC Berkeley提出MeMViT,建模时间支持比现有模型长30倍,计算量仅增加4.5%
详细信息如下:

论文链接:https://arxiv.org/abs/2201.08383
01
摘要
虽然今天的视频识别系统准确地解析短片段,但它们还不能在更长的时间范围内进行推理。大多数现有的视频架构只能处理<5秒的视频,而不会遇到计算或内存瓶颈。
在本文中,作者提出了一种新的策略来克服这一挑战。作者提出以在线方式处理视频,并在每次迭代时缓存“记忆”,而不是像大多数现有方法那样一次处理更多帧。通过记忆,模型可以参考先前的上下文进行长期建模,只需边际成本。基于这一思想,作者构建了MeMViT,一种记忆增强的多尺度视觉Transformer,其时间支持比现有模型长30倍,计算量仅增加4.5%;传统方法需要超过3000%的计算量才能完成同样的操作。
在广泛的设置中,MeMViT支持的时间增加带来了一致的识别精度的巨大提高。MeMViT在AVA、EPIC-Kitchens100动作分类和动作预测数据集上获得最先进的结果。
02
Motivation
随着时间的推移,我们的世界不断演变。不同时间点的事件相互影响,共同讲述了视觉世界的故事。计算机视觉有望理解这个故事,但今天的系统仍然相当有限。它们可以在独立快照或短时间片段(例如5秒)内准确解析视觉内容,但不能超过该时间段。那么,如何才能实现准确的长期视觉理解呢?当然,前面还有很多挑战,但拥有一个可以在长视频上运行的模型可以说是重要的第一步。
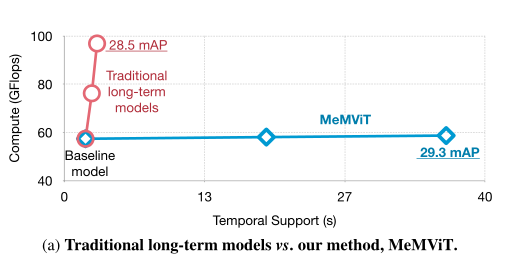
在本文中,作者提出了一种基于记忆的方法来构建有效的长期模型。中心思想是不共同处理或训练整个长视频,而是在以在线方式处理视频时保持“记忆”。在任何时候,模型都可以访问长期上下文的先前记忆。由于记忆是从过去“重用”的,因此该模型非常高效。为了实现这个想法,作者构建了一个名为MeMViT的具体模型,MeMViT是一个记忆增强的多尺度视觉Transformer。MeMViT处理的输入时间比现有模型长30倍,计算量仅增加4.5%。相比之下,通过增加帧数量建立的长期模型将会需要超过3000%的计算。上图显示了计算/持续时间的权衡比较。
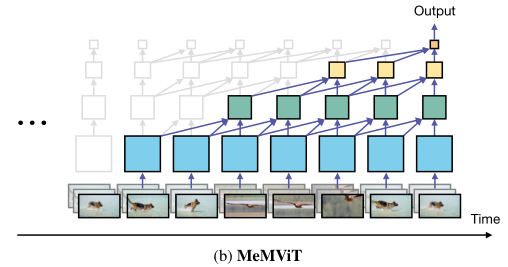
具体地说,MeMViT使用Transformer的“键”和“值”作为记忆。当模型在一个片段上运行时,“查询”涉及一组扩展的“键”和“值”,它们来自当前时间和过去。当在多个层上执行此操作时,每一层都会深入到过去,从而产生显著更长的感受野,如上图所示。
为了进一步提高效率,作者联合训练了一个记忆压缩模块,以减少内存占用。直觉上,这允许模型了解哪些线索对未来的识别很重要,并只保留这些线索。
本文的设计灵感来源于人类如何解析长期视觉信号。人类不会在很长一段时间内同时处理所有信号。相反,人类以在线方式处理信号,将我们所看到的与过去的记忆联系起来以理解过去的记忆,并记忆重要信息以备将来使用。
本文的结果表明,使用记忆增强视频模型并实现远程注意力是简单且非常有益的。在AVA时空动作定位、EPIC-Kitchens-1001动作分类和EPIC-Kitchens-100动作预测数据集上,MeMViT取得了比其他模型更大的性能收益,并取得了最先进的结果。
03
Preliminaries
Vision Transformers (ViT)
视觉Transformer(ViT)首先将图像嵌入到N个不重叠的patch中(使用跨步卷积),并将其embed到张量。然后,一堆Transformer层对这些patch之间的相互作用进行建模。Transformer层的中心组件是注意操作,它首先将输入张量X线性投影为查询Q、键K和值V:
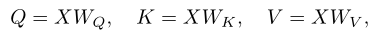
并执行自注意力操作,获得输出张量。
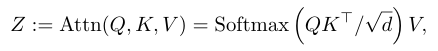
Multiscale Vision Transformers (MViT)
多尺度视觉Transformer(MViT)基于两个简单的想法改进了ViT。首先,MViT在整个网络中没有固定的分辨率N,而是通过多个阶段学习多尺度表示,从较小patch的细粒度建模(大N和小d)开始,到后期较大patch的高级建模(小N和大d)。阶段之间的过渡是通过跨阶段的池化来完成的。其次,MViT使用池化注意力(P),池化Q、K和V的时空维度,以大幅降低注意力层的计算成本,即:
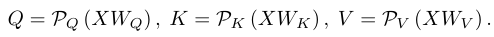
这两个更改显著提高了模型的性能和效率。在本文中,作者基于略微修改的MViT构建了本文的方法,其中作者交换了线性层和池化的顺序:
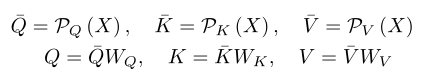
这允许线性层在较小的张量上操作,减少计算成本,而不影响精度。
04
方法
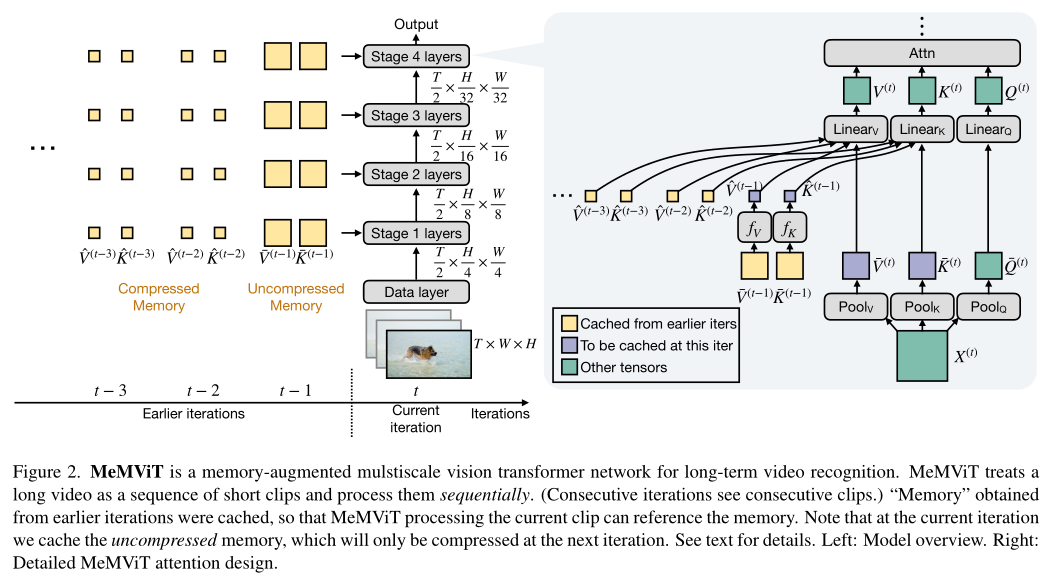
本文的方法很简单。作者将视频分割成一系列短的T×H×W个片段,并按顺序进行处理(用于训练和推理)。作者在每次迭代时缓存“记忆”,即已处理片段的一些表示。当在时间步t处理当前片段时,模型可以访问早期迭代
用于长期的上下文。上图展示了本文方法的overview。
4.1. Memory Attention and Caching
The Basic MeMViT Attention
实现此想法的一种简单方法是将transformer结构中的“键”和“值”视为一种记忆形式,并在当前迭代t中扩展和,以包括从和的早期迭代的和:
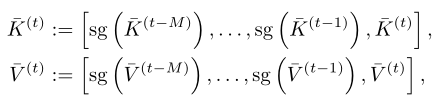
其中,方括号表示沿标记维度的concat。使用此公式,查询Q不仅涉及当前时间步t的信息,而且还涉及之前多达M步的信息。这里,“停止梯度”操作符(sg)在反向传播中进一步打破了对过去的依赖。记忆是随时间分层构建的(参见上图b),以前的键和值内存保存了以前时间步中存储的信息。
训练和推理的额外成本仅包括用于记忆缓存的GPU内存和扩展注意力层中的额外计算。网络的所有其他部分(MLP等)保持不变。成本随着时间的支持而增长,复杂度为。作者缓存了完整的键和值张量,这些张量可能包含对将来的识别不有用的冗余信息。
4.2. Memory Compression
Naive Memory Compression
有许多潜在的压缩内存的方法,但一种直观的设计尝试联合训练压缩模块(例如,可学习的池化操作符)和,以分别减小K和V张量的时空大小:
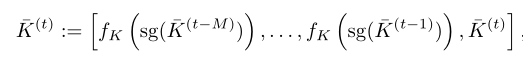
对于也是如此。使用这种设计,在推理时只需要缓存和处理“压缩”记忆和,从而减少内存占用和计算成本。然而,在训练时,它需要联合训练所有“完整”的记忆张量,因此这实际上可能会增加记忆的计算和成本,使获得这样的模型变得昂贵。对于长期建模的M更大的模型,成本更高。
Pipelined Memory Compression
为了解决这个问题,作者提出了一种pipelined压缩方法。虽然压缩模块和需要在未压缩的记忆上运行并进行联合优化,以便模型学习需要保留的重要内容,但学习的模块可以在所有过去的记忆中共享。因此,作者提出训练一步只压缩一次记忆,即:
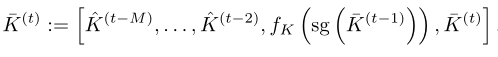
对于也是如此。上图的右侧示出了这种设计。注意这里缓存中只有从上一步的记忆为未压缩的,并用于在当前迭代中训练。从到的
402 Payment Required
在之前的迭代中已经压缩过了。下图展示了这一步的伪代码。
这样,MeMViT只比基础MeMViT增加了“固定”压缩成本,因为它一次只在一个步骤上运行压缩。但是,它大大降低了所有其他步骤的缓存和注意力成本。本文设计的一个吸引人的特性是,视频模型的感受野不仅随着M的增加而增加,而且随着层的数量L的增加而增加,因为每一层都会进一步深入到过去,因此,时间感受野会随着深度的增加而分层增加。
4.3. Implementation Details
Data Loading
在训练和推理过程中,对连续的帧块(片段)进行顺序读取,以在线方式处理视频。在本文的实现中,只需concat所有视频并按顺序读取它们。在缓存记忆来自前一个视频的情况下(即,在视频边界处),作者将记忆mask为零。
Compression Module Design
压缩模块可以是减少token数量但保持维度d的任何函数。在本文的实例化中,作者选择了一个可学习的池化,因为它简单且性能强,但也有其他选择。
Positional Embedding
在原始MViT中,绝对位置嵌入被添加到网络的输入中,每个片段使用相同的位置嵌入。因此,位置嵌入只能指示片段内的位置,而不能指示多个片段之间的顺序。因此,作者采用了“改进的MViT”中使用的相对位置嵌入,因此不同时间点的记忆与查询具有不同的相对距离。
05
实验
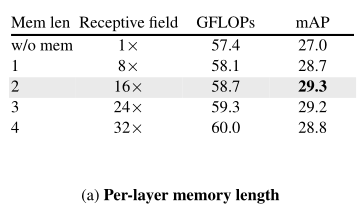
上表比较了具有不同每层记忆长度(M)的模型。作者发现,与baseline短期模型相比,所有增加记忆的模型都有明显的改善(mAP中的绝对增益为1.7-2.3%)。有趣的是,这种行为对记忆长度的选择不是很敏感。使用每层记忆长度为2,对应于16×更大(36秒)的感受野,可以获得AVA的最佳性能。在下面的A V A实验中,作者使用M=2作为默认值。
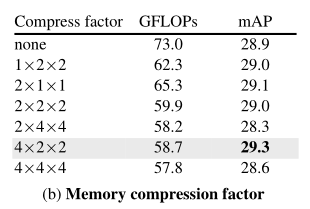
上表比较了具有不同下采样因子的压缩模块。作者发现,在实现强大性能的同时,时间下采样(4×)比空间下采样(2×)程度更大。有趣的是,与没有压缩的模型相比,本文的压缩方法实际上提高了精度。这支持了本文的假设,即学习记忆中的“要保留什么”可能会抑制不相关的噪音并有助于学习。由于其强大的性能,作者默认使用4×2×2的降采样因子(分别用于时间、高度和宽度)。
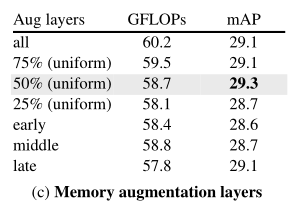
在上表中,作者探讨了是否需要在所有注意力层增加记忆,如果不需要,在哪一层增加记忆最有效。有趣的是,作者发现在所有的层上处理记忆是不必要的。此外,在整个网络中均匀地放置它们比将它们集中在早期(阶段1和2)层、中期(阶段3)层或晚期(阶段4)层效果稍好。
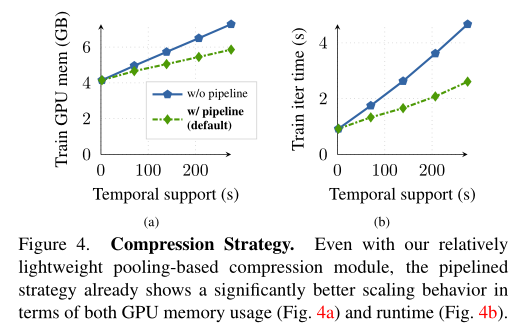
最后,作者比较了Pipelined 压缩策略与没Pipelined 的基本版本的缩放行为。可以看到,即使使用相对轻量级的基于池化的压缩模块,Pipelined 策略在GPU内存使用(上图a)和运行时间(上图b)方面已经显示出明显更好的缩放行为。因此,作者在MeMViT中默认使用它。
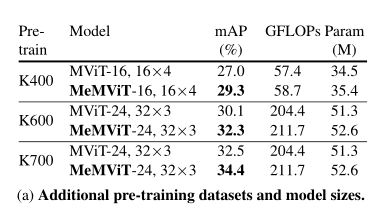
上表显示,尽管预训练数据集和模型大小设置不同,MeMViT提供了比原始短期模型(MViT)一致的性能增益,这表明本文的方法具有良好的通用性。
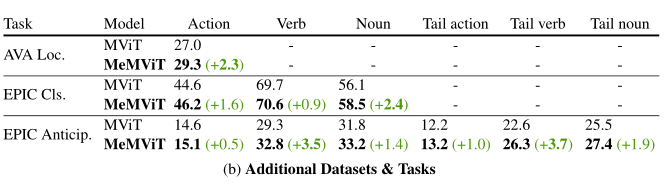
上表给出了EPIC-Kitchens-100动作分类和EPIC-Kitchens-100行动预测的结果。这里使用的模型与AVA使用的默认模型“MeMViT-16,16×4”相同,只是对于EPIC Kitchens,作者发现使用M=4(32×长期,或70.4秒感受野)的长期模型效果最好。
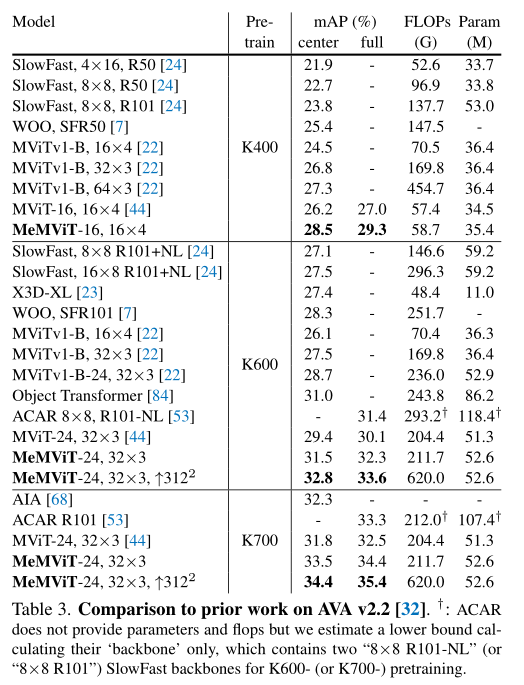
上表比较了MeMViT与AVA v2.2数据集上之前工作的性。可以发现,在所有预训练设置下,MeMViT获得了比之前工作更高的准确性,同时具有可比甚至更少的FLOPs和参数量。
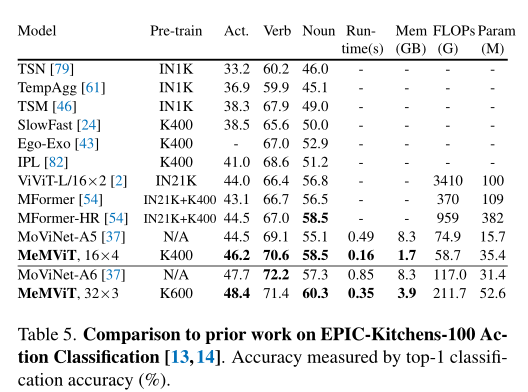
上表展示了EPIC-Kitchens-100动作分类任务的结果,可以看出,MeMViT再次优于所有之前的工作,包括基于CNN的方法和基于ViT的方法。
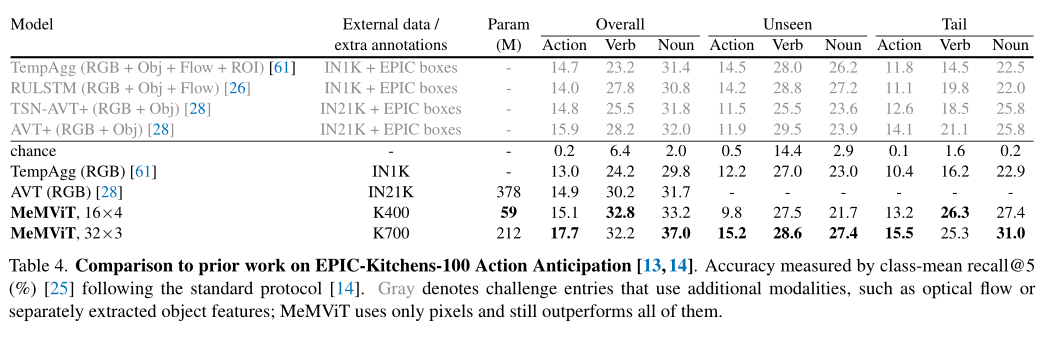
上表展示了EPIC-Kitchens-100动作预测任务的结果,可以看出,MeMViT优于所有先前的工作,包括使用多种模态的工作,如光流、单独训练的对象特征提取器和大规模预训练。
06
总结
长期视频理解是计算机视觉的一个重要目标。要做到这一点,拥有一个用于长期视觉建模的实用模型是一个基本前提。在本文中,作者表明,扩展现有最先进的模型以包含更多的输入帧并不能很好地扩展。本文提出的基于记忆的方法MeMViT可更高效地扩展,并获得更好的准确性。本文提出的技术是通用的,适用于其他基于Transformer的视频模型。
参考资料
[1]https://arxiv.org/abs/2201.08383

END
加入「Transformer」交流群备注:TFM

边栏推荐
- [4500 word summary] a complete set of skills that a software testing engineer needs to master
- Skills of embedded C language program debugging and macro use
- 现在网上期货开户安全吗?国内有多少家正规的期货公司?
- 上市十天就下线过万台,欧尚Z6产品实力备受点赞
- [trusted computing] Lesson 11: TPM password resource management (III) NV index and PCR
- Chapter 1 Introduction to CRM core business
- 持续测试(CT)实战经验分享
- 4种常见的缓存模式,你都知道吗?
- 卖空、加印、保库存,东方甄选居然一个月在抖音卖了266万单书
- Download, installation and development environment construction of "harmonyos" deveco
猜你喜欢
小程序中实现付款功能

通过 Play Integrity API 的 nonce 字段提高应用安全性

Deep learning - make your own dataset

低代码助力企业数字化转型会让程序员失业?

元宇宙带来的创意性改变
Chapter 2 building CRM project development environment (building development environment)
JS pull down the curtain JS special effect display layer
Run Yolo v5-5.0 and report an error. If the sppf error cannot be found, solve it
Hash, bitmap and bloom filter for mass data De duplication
Mobile app takeout ordering personal center page
随机推荐
What are the financial products in 2022? What are suitable for beginners?
Tips for this week 131: special member functions and ` = Default`
Debian10 compile and install MySQL
< code random recording two brushes> linked list
[principle and technology of network attack and Defense] Chapter 6: Trojan horse
Tips of the week 136: unordered containers
Learn to make dynamic line chart in 3 minutes!
数学分析_笔记_第11章:Fourier级数
回归测试的分类
Using stored procedures, timers, triggers to solve data analysis problems
Chapter 3 business function development (safe exit)
低代码助力企业数字化转型会让程序员失业?
Chapter 3 business function development (user login)
Run Yolo v5-5.0 and report an error. If the sppf error cannot be found, solve it
debian10编译安装mysql
用存储过程、定时器、触发器来解决数据分析问题
How to clean when win11 C disk is full? Win11 method of cleaning C disk
现货白银分析中的一些要点
[trusted computing] Lesson 10: TPM password resource management (II)
元宇宙带来的创意性改变