当前位置:网站首页>Hash, bitmap and bloom filter for mass data De duplication
Hash, bitmap and bloom filter for mass data De duplication
2022-07-07 18:12:00 【cheems~】
Massive data De duplication hash,bitmap With the bloom filter Bloom Filter
Preface
The main point of this article is bitmap And the bloon filter
The knowledge points of this column are through Zero sound education Online learning , Make a summary and write an article , Yes c/c++linux Readers interested in the course , You can click on the link C/C++ Background advanced server course introduction Check the service of the course in detail .
background
- Making ⽤word⽂ Stall time ,word How to tell if a word is spelled correctly ?
- ⽹ Collateral climbing ⾍ Program , How to keep it from climbing the same url⻚⾯? Error allowed
- spam ( SMS ) How to design the filtering algorithm ? Error allowed
- When the police handle a case , How to judge a suspect ⼈ Whether in ⽹ On the escape list ? Control error False positive rate
- How to solve the cache penetration problem ? Error allowed
demand
Query whether a string exists from massive data
Red and black trees
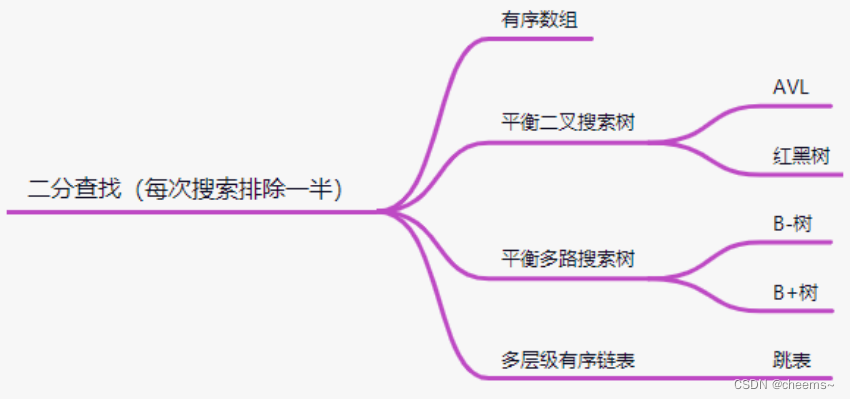
Whether it's AVL Or red and black trees , stay “ Huge amounts of data ” The data is inappropriate , Because red and black trees will key, That is, data is stored , And massive data will lead to insufficient memory . And design to string comparison , Efficiency is also very slow . So in this demand , Using tree related data structures is not appropriate .
expand :
- c++ Standard library (STL) Medium set and map The structure is made of ⽤ red ⿊ Trees achieve , The time complexity of adding, deleting, modifying and checking is O ( l o g 2 N ) O(log_2N) O(log2N).set and map The key difference is set Do not store val Field
- advantage : Storage efficiency ⾼, Access speed ⾼ effect
- shortcoming : For the amount of data ⼤ And query string ⽐ a ⻓ And when the query string is similar, it will be a nightmare
Hash table hashtable
Hash table composition : Array +hash function . It passes a string through hash function ⽣ become ⼀ An integer is then mapped to the array ( So hash table does not need ” Compare strings “, Red and black trees need ), The time complexity of adding, deleting, modifying and checking is o(1).
Be careful : In the node of the hash table kv Is stored together
struct node {
void *key;
void *val;
struct node *next;
};
expand :
- c++ Standard library (STL) Medium unordered_map<string, bool> It's mining ⽤hashtable Realized
- hashtable Nodes in store key and val,hashtable There is no requirement key Of ⼤⼩ The order , We can also modify the code to insert ⼊ Existing data becomes a modification operation
- advantage : Faster access ; There is no need to enter ⾏ character string ⽐ a
- shortcoming : Need to lead ⼊ Strategies to avoid conflict , Inefficient storage ⾼; Space for time
hash function
hash The operation of the function ⽤: Avoid inserting ⼊ String when ⽐ a ,hash The value calculated by the function through the array ⻓ The modulus energy of degree is randomly distributed in the array .
hash Conflict (hash Collision ):hash(key)=addr,hash The function may put two or more different key Map to the same address .hash function ⼀ The general return is 64 An integer , Will be multiple ⼤ Number maps to ⼀ individual ⼩ Array , Must produce ⽣ Conflict .
Load factor : Used to describe the storage density of hash tables . The number of elements stored in the array / Data length ; The smaller the load factor , The less conflict , The greater the load factor , The greater the conflict .
choice hash
How to choose hash function ?
- The selection calculation speed is fast
- Strong random distribution ( Equal probability 、 Evenly distributed throughout the address space )
murmurhash1,murmurhash2,murmurhash3,siphash(redis6.0 Make ⽤,rust And most languages hash Algorithm to achieve hashmap),cityhash All have strong random distribution
The test address is as follows :https://github.com/aappleby/smhasher
siphash It mainly solves the strong random distribution of string proximity , So if you want to hash String words , Priority selection siphash
Conflict handling
- The linked list method
Reference linked list to handle hash conflict , To link elements in a list is to link them together , This is also commonly used to deal with conflicts ⽅ type . But there may be an extreme case , There are many conflict elements , The conflict linked list is too long , At this time, you can convert this linked list into a red black tree . From the time complexity of the original linked list Time complexity of converting to red black tree , So what is the basis for judging that the linked list is too long ? Can pick ⽤ exceed 256( Empirical value ) The linked list structure is transformed into a red black tree structure when there are two nodes .
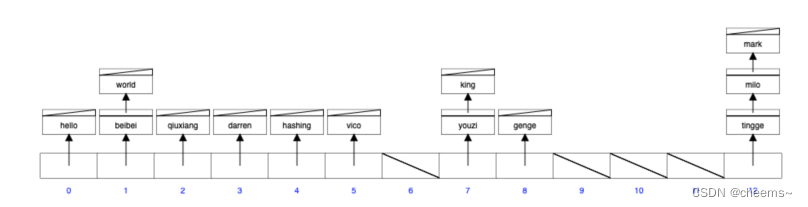
- Open addressing
Store all elements in the array of hash table , No additional data structures ; Generally, the idea of linear exploration is used to solve
- When inserting ⼊ When new elements , send ⽤ The hash function locates the element position in the hash table
- Check whether there is an element in the slot index in the array . If the slot is empty , Then insert ⼊, otherwise 3
- stay 2 Add... To the detected slot index ⼀ Step by step ⻓ Then check 2
Add ⼀ Step by step ⻓ It can be divided into the following categories
- i+1,i+2,i+3,i+4, … ,i+n
- i- 1 2 1^2 12 ,i+ 2 2 2^2 22 ,i- 3 2 3^2 32,1+ 4 2 4^2 42 …
Both will lead to similar hash Gather , That is, the approximate value of its hash The value is also approximate . Then its array slot is also close to , formation hash Gather . The first ⼀ Species of congeners gather and conflict first , The first ⼆ It's just delaying the gathering conflict .
- You can make ⽤ Double hash to solve the problem ⾯ appear hash Aggregation phenomenon
stay .net HashTable Class hash function Hk The definition is as follows :
Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1)))] % hashsize
Here it is (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1))) And hashsize Mutual primes ( Two numbers are prime numbers to each other, which means that they have no common prime factor ⼦)
Of board ⾏ 了 hashsize After exploration , Every... In the hash table ⼀ There are all positions and only ⼀ Visited... Times , in other words , For a given key, Hash table in the same pair ⼀ The position will not make ⽤ Hi and Hj;
Specific principle :https://www.cnblogs.com/organic/p/6283476.html
bitmap
Let's first introduce bitmap, Next, we will introduce the bron filter . Now there is a need : In file 40 One hundred million QQ number , Please design an algorithm for QQ Number de duplication , same QQ Keep only one number , Memory limit 1G.
- If you sort first and then remove the duplicate , Time complexity is too high
- If you use hashmap Natural weight removal , Space complexity is too high
- File cutting to avoid excessive memory , too troublesome , The efficiency is not high
- Use bitmap, It can successfully solve the problems of time and space at the same time
One unsigned int type , share 32 position , It can mark 0 ~ 31 this 32 The existence of integers . Two unsigned int type , share 64 position , It can mark 0 ~ 63 this 64 The existence of integers .
So if we cover the whole integer range , thus 1 On behalf of the first ,2 On behalf of the second ,2 Of 32 The power represents the last bit .40 Of the billion , The existing number is in the corresponding position 1, The other bits are 0. For example, here comes a 1234, Just find the first 1234 position , If it is 1 There is a , yes 0 There is no such thing as .
So as long as we have enough ” position “, You can judge 0~4 100 million 4 Whether 100 million integers exist .2 Of 32 Next is 4,294,967,296. That is to say, we should have 4,294,967,296 bits .
4,294,967,296 bits =2 Of 32 The second place =2 Of 29 Sub bytes =512MB. original 32 An integer , Transformed into 1 Bit Boolean , So the data space is the original 32 One of the points .
You can see , Use bitmap Not only automatic weight removal , Even this demand is in order , Traverse positive integers from small to large , When bitmap The value of bit is 1 when , Just output the value , The output positive integer sequence is the sorted result .
m% 2 n 2^n 2n = m & ( 2 n 2^n 2n-1) ------ In order to calculate more efficiently , Generally will Modulus operation become And operation

Massive data De duplication bloom filter
red ⿊ Trees and hashtable Can't solve the problem of massive data , They all need to store specific strings , If the amount of data ⼤, Can't provide ⼏ hundred G Of memory ; Therefore, we need to try to explore non storage key Of ⽅ case , And have hashtable The advantages of ( Unwanted ⽐ Compare string ). And bloom filter just meets this demand , It does not need to store specific strings , There's no need to compare . Time and space complexity are low .
Introduction to bloon filter
Bloom filter definition : The bloon filter is ⼀ Kind of Probability type data structure , It is characterized by ⾼ Effective insertion ⼊ And query , Can clearly tell a string ⼀ Must not exist perhaps Possible ;
Advantages and disadvantages : Bloom filter phase ⽐ Traditional query structure ( for example :hash,set,map And so on ) more ⾼ effect , Occupy ⽤ More space ⼩, But it is certain that the result it returns is probabilistic , result There is a certain error , Error controllable , meanwhile Delete operation not supported
constitute : Bitmap (bit Array )+ n individual hash function .
Principle of bloon filter
When an element is added to a bitmap : adopt K individual hash The function operation maps this element to the bitmap K A little bit , And set them to 1
When retrieving an element : through K individual hash Function operation to detect the of bitmap K Whether all points are 1, If it's all for 1, There may be ; If there is one not for 1, It must not exist .
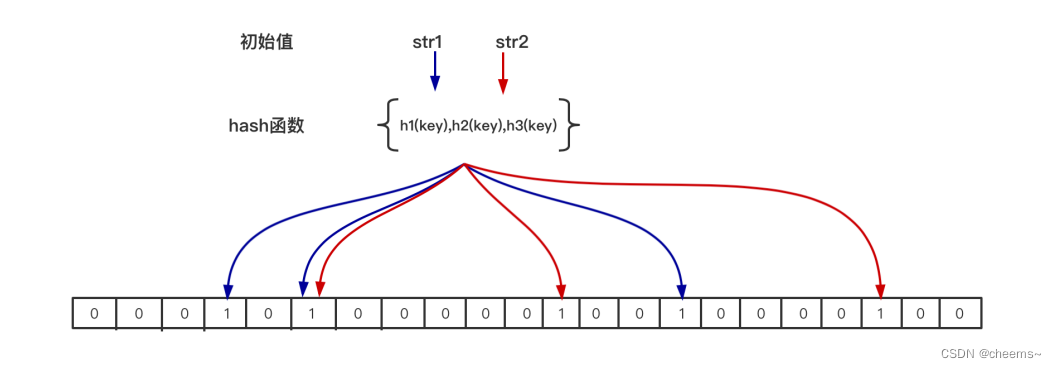
Why is deletion not supported ? Because there are only two states for each slot in the bitmap (0 perhaps 1), A slot is set to 1 state , But I'm not sure how many times it's set ; I don't know how many key From hash mapping and by which hash Function mapping , Therefore, deletion is not supported .
If you want to delete , You can use two Bloom filters , Elements to be deleted , Put it into the second bloom filter , Then, when querying, go to the second one , If you can find the description in the second one, it may be deleted ( Note that there are also errors ).
How to apply bloom filtering
Variable relationships
In practice, we should ⽤ In the process , How the bloom filter makes ⽤? How many hash function , Bitmap of how much space to allocate , How many elements are stored ? In addition, how to control the false positive rate ( The bloan filter can define ⼀ Must not exist , Not clear ⼀ There must be , Then there is an error in the judgment of existence , False positive rate is the probability of wrong judgment )?
- n - - The number of elements in the bloom filter , Pictured above Only str1 and str2 Two elements that n=2. How many values are stored in prefetching
- p - - False positive rate , stay 0-1 Between 0.0000001. Acceptable false positive rate
- m - - Space occupied by bitmap
- k - - hash Number of functions
The formula is as follows :
n = ceil(m / (-k / log(1 - exp(log(p) / k))))
p = pow(1 - exp(-k / (m / n)), k)
m = ceil((n * log(p)) / log(1 / pow(2, log(2))))
k = round((m / n) * log(2))
determine n and p
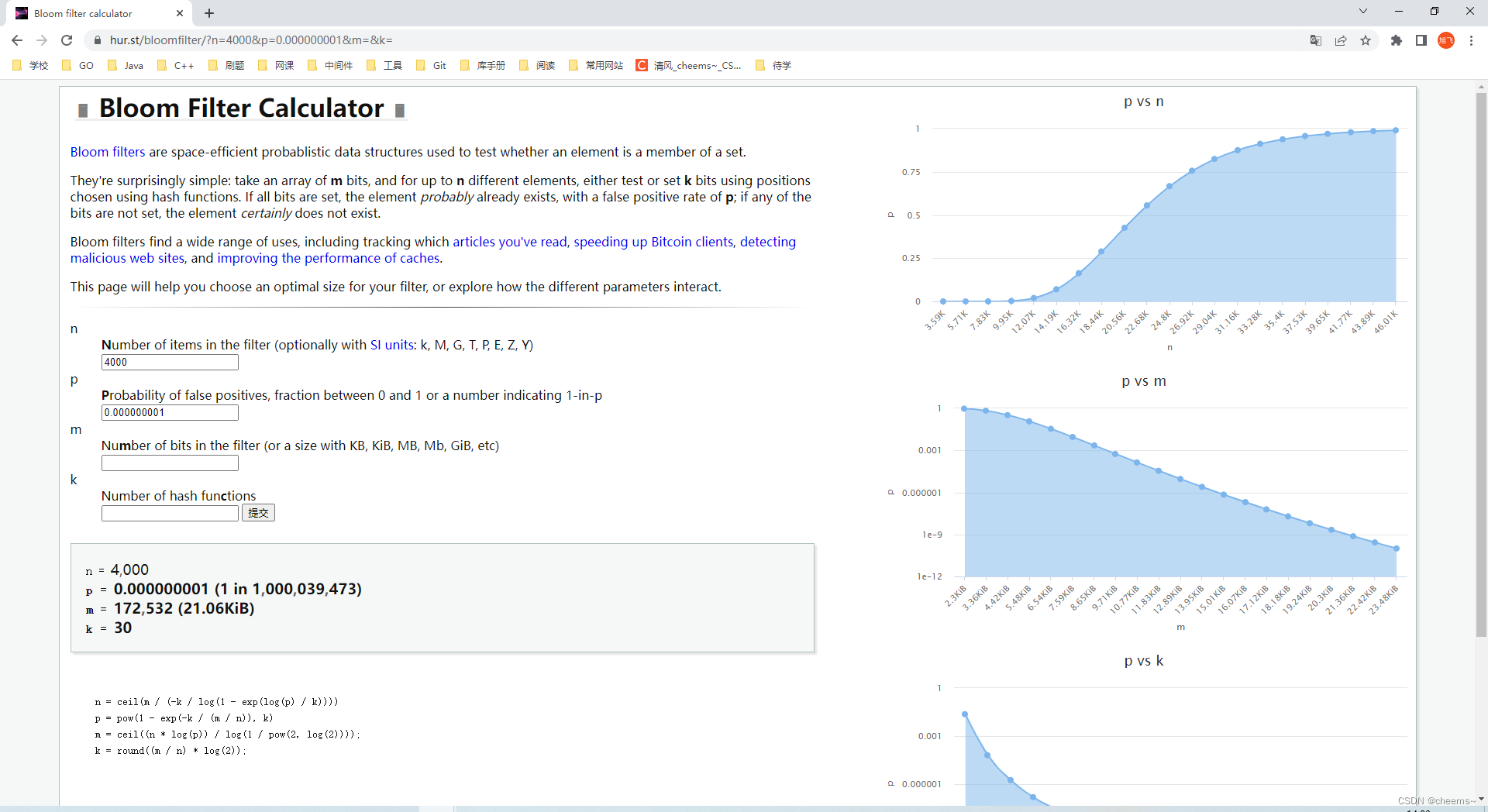
When actually using Bloom filter , The first thing to do is to determine n and p, Through the above calculation, we can get m and k; You can usually choose the appropriate value on the following website
https://hur.st/bloomfilter/
Now suppose n = 4000,p = 0.000000001. We can bring in the formula calculation by ourselves m and k, You can also bring it into the website to calculate the variable value , And the thumbnail on the right can observe different values .
n = 4000
p = 0.000000001 (1 in 1000039473)
m = 172532 (21.06KiB)
k = 30
choice k individual hash function
We found that the above calculation requires 30 individual hash function , Are we going to find 30 Different hash Function , Obviously, it shouldn't be like this . We should choose one hash function , By giving hash Pass different seed offset values , The linear search method is used to construct multiple hash function .
// Mining ⽤⼀ individual hash function , to hash Pass on different species ⼦ Offset value
// #define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
uint64_t hash1 = MurmurHash2_x64(key, len, Seed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
// k yes hash Number of functions
for (i = 0; i < k; i++) {
Pos[i] = (hash1 + i*hash2) % m; // m It's a bitmap ⼤⼩
}
// Through this kind of ⽅ To simulate k individual hash function Before us ⾯ Open addressing double hash yes ⼀ What kind of thinking
Digression , Interview Baidu :hash In the process of function implementation Why? There will be i * 31?
- i * 31 = i * (32-1) = i * (1<<5 -1) = i << 5 - i;
- 31 Prime number ,hash Random distribution is very good
Blum filter application scenario
The bloom filter is usually used to determine a certain key A scene that must not exist , At the same time, it is allowed to judge the existence of errors
Common processing scenarios :① Solution of cache penetration ;② heat key Current limiting
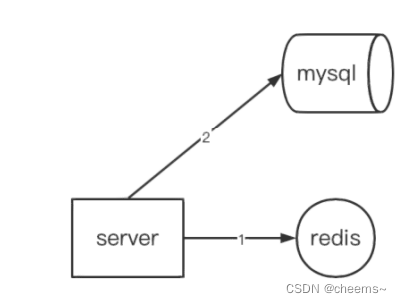
Caching scenarios : In order to reduce the pressure of database access , stay server and mysql Add cache between to store hotspot data
Cache penetration :server When requesting data , Neither the cache nor the database has this data , Eventually, all the pressure is given to the database
Read step :
- First visit redis, Return if present , Nonexistence 2
- visit mysql, If it doesn't exist, it returns , There are 3
- take mysql Of key Write back to redis
Solution :
- stay redis Set up <key,null> To avoid access mysql, But if <key,null> Too much will occupy memory ( You can set the expiration time to solve this problem )
- stay server A bloom filter is stored at the end , take mysql Contains key Put them into the bloom filter , Bloom filter can filter data that must not exist
边栏推荐
- USB通信协议深入理解
- 机器人工程终身学习和工作计划-2022-
- Using stored procedures, timers, triggers to solve data analysis problems
- 机器视觉(1)——概述
- Ten thousand words nanny level long article -- offline installation guide for datahub of LinkedIn metadata management platform
- TaffyDB开源的JS数据库
- swiper左右切换滑块插件
- Mui side navigation anchor positioning JS special effect
- 五种网络IO模型
- 深度学习-制作自己的数据集
猜你喜欢
手机app外卖订餐个人中心页面

MRS离线数据分析:通过Flink作业处理OBS数据
磁盘存储链式的B树与B+树

Deep learning - make your own dataset
Dragging the custom style of Baidu map to the right makes the global map longitude 0 unable to be displayed normally

机器人工程终身学习和工作计划-2022-

原生js验证码
万字保姆级长文——Linkedin元数据管理平台Datahub离线安装指南

The report of the state of world food security and nutrition was released: the number of hungry people in the world increased to 828million in 2021
Tips of the week 136: unordered containers
随机推荐
漫画 | 宇宙第一 IDE 到底是谁?
自动化测试:Robot FrameWork框架大家都想知道的实用技巧
原生js验证码
In depth understanding of USB communication protocol
Chapter 2 building CRM project development environment (building development environment)
[principle and technology of network attack and Defense] Chapter 1: Introduction
debian10编译安装mysql
Tips of this week 141: pay attention to implicit conversion to bool
2022年理财有哪些产品?哪些适合新手?
测试3个月,成功入职 “字节”,我的面试心得总结
性能测试过程和计划
[principles and technologies of network attack and Defense] Chapter 5: denial of service attack
What is agile testing
Supplementary instructions to relevant rules of online competition
< code random recording two brushes> linked list
Run Yolo v5-5.0 and report an error. If the sppf error cannot be found, solve it
基于RGB图像阈值分割并利用滑动调节阈值
三仙归洞js小游戏源码
手机app外卖订餐个人中心页面
Machine vision (1) - Overview