当前位置:网站首页>4种常见的缓存模式,你都知道吗?
4种常见的缓存模式,你都知道吗?
2022-07-07 15:47:00 【Java中文社群】
概述
在系统架构中,缓存可谓提供系统性能的最简单方法之一,稍微有点开发经验的同学必然会与缓存打过交道,最起码也实践过。
如果使用得当,缓存可以减少响应时间、减少数据库负载以及节省成本。但如果缓存使用不当,则可能出现一些莫名其妙的问题。
在不同的场景下,所使用的缓存策略也是有变化的。如果在你的印象和经验中,缓存还只是简单的查询、更新操作,那么这篇文章真的值得你学习一下。
在这里,为大家系统地讲解4种缓存模式以及它们的使用场景、流程以及优缺点。
缓存策略的选择
本质上来讲,缓存策略取决于数据和数据访问模式。换句话说,数据是如何写和读的。
例如:
系统是写多读少的吗?(例如,基于时间的日志)
数据是否是只写入一次并被读取多次?(例如,用户配置文件)
返回的数据总是唯一的吗?(例如,搜索查询)
选择正确的缓存策略才是提高性能的关键。
常用的缓存策略有以下五种:
Cache-Aside Pattern:旁路缓存模式
Read Through Cache Pattern:读穿透模式
Write Through Cache Pattern:写穿透模式
Write Behind Pattern:又叫Write Back,异步缓存写入模式
上述缓存策略的划分是基于对数据的读写流程来区分的,有的缓存策略下是应用程序仅和缓存交互,有的缓存策略下应用程序同时与缓存和数据库进行交互。因为这个是策略划分比较重要的一个维度,所以在后续流程学习时大家需要特别留意一下。
Cache Aside
Cache Aside是最常见的缓存模式,应用程序可直接与缓存和数据库对话。Cache Aside可用来读操作和写操作。
读操作的流程图:
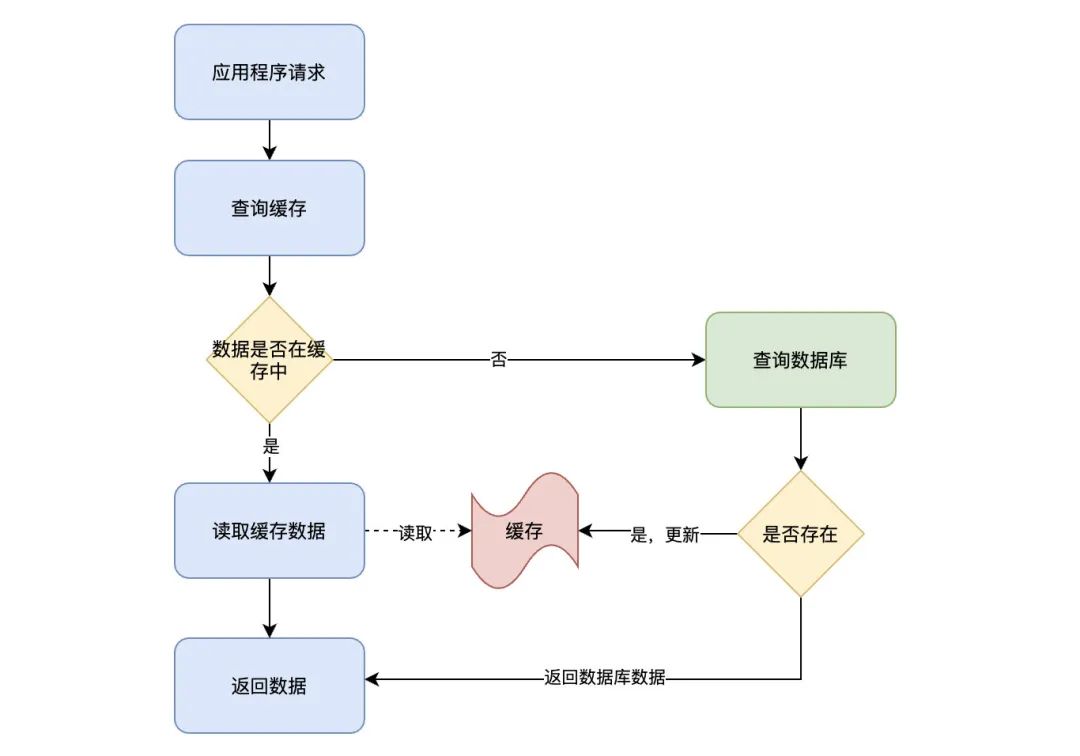
读操作的流程:
应用程序接收到数据查询(读)请求;
应用程序所需查询的数据是否在缓存上:
如果存在(Cache hit),从缓存上查询出数据,直接返回;
如果不存在(Cache miss),则从数据库中检索数据,并存入缓存中,返回结果数据;
这里我们需要留意一个操作的边界,也就是数据库和缓存的操作均由应用程序直接进行操作。
写操作的流程图:
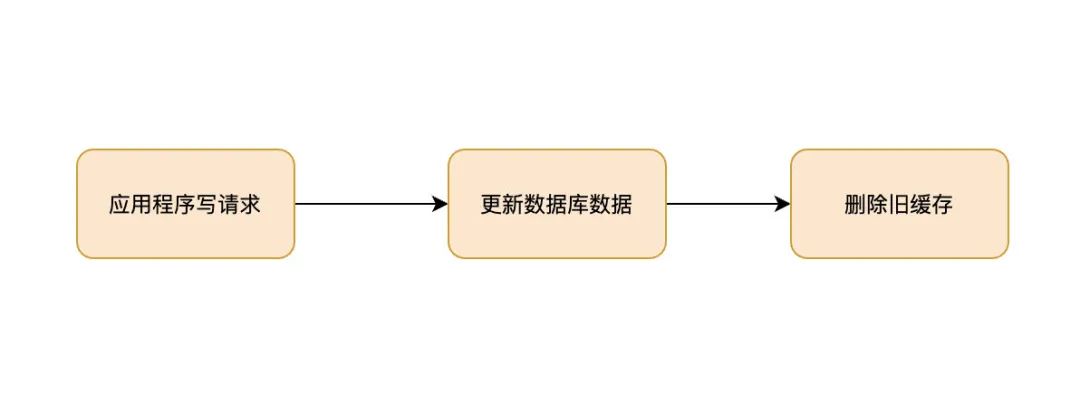
这里的写操作,包括创建、更新和删除。在写操作的时候,Cache Aside模式是先更新数据库(增、删、改),然后直接删除缓存。
Cache Aside模式可以说适用于大多数的场景,通常为了应对不同类型的数据,还可以有两种策略来加载缓存:
使用时加载缓存:当需要使用缓存数据时,从数据库中查询出来,第一次查询之后,后续请求从缓存中获得数据;
预加载缓存:在项目启动时或启动后通过程序预加载缓存信息,比如”国家信息、货币信息、用户信息,新闻信息“等不是经常变更的数据。
Cache Aside适用于读多写少的场景,比如用户信息、新闻报道等,一旦写入缓存,几乎不会进行修改。该模式的缺点是可能会出现缓存和数据库双写不一致的情况。
Cache Aside也是一个标准的模式,像Facebook便是采用的这种模式。
Read Through
Read-Through和Cache-Aside很相似,不同点在于程序不需要关注从哪里读取数据(缓存还是数据库),它只需要从缓存中读数据。而缓存中的数据从哪里来是由缓存决定的。
Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。Read-Through的优势是让程序代码变得更简洁。
这里就涉及到我们上面所说的应用程序操作边界问题了,直接来看流程图:
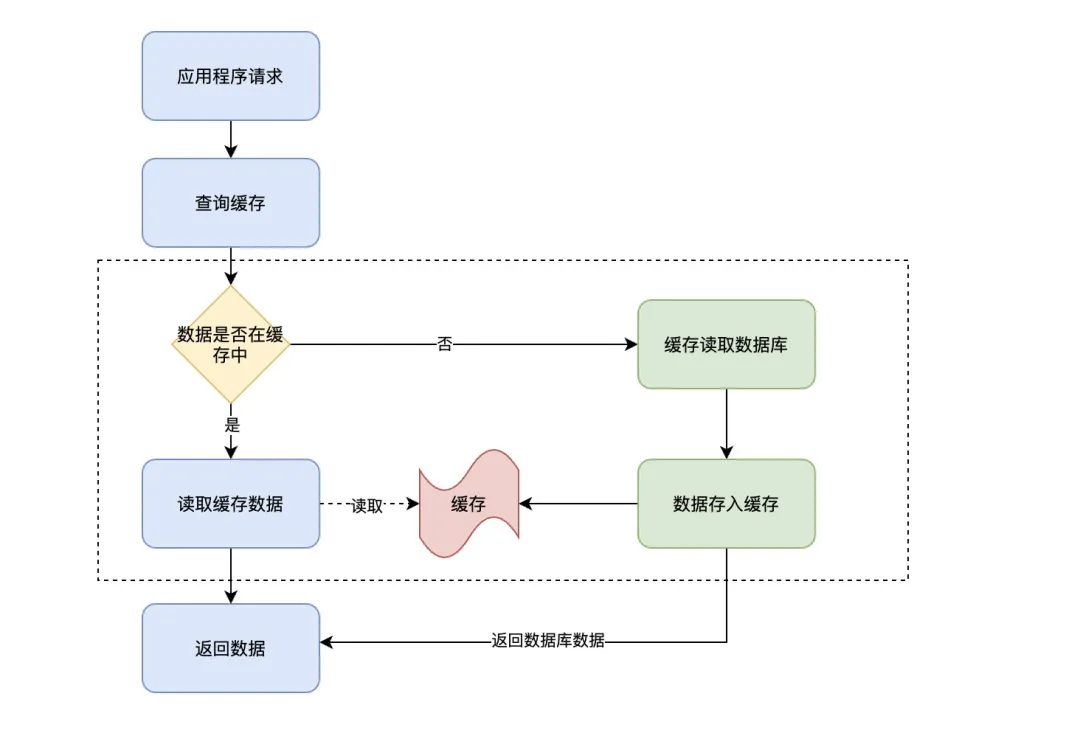
在上述流程图中,重点关注一下虚线框内的操作,这部分操作不再由应用程序来处理,而是由缓存自己来处理。也就是说,当应用从缓存中查询某条数据时,如果数据不存在则由缓存来完成数据的加载,最后再由缓存返回数据结果给应用程序。
Write Through
在Cache Aside中,应用程序需要维护两个数据存储:一个缓存,一个数据库。这对于应用程序来说,有一些繁琐。
Write-Through模式下,所有的写操作都经过缓存,每次向缓存中写数据时,缓存会把数据持久化到对应的数据库中去,且这两个操作在一个事务中完成。因此,只有两次都写成功了才是最终写成功了。坏处是有写延迟,好处是保证了数据的一致性。
可以理解为,应用程序认为后端就是一个单一的存储,而存储自身维护自己的Cache。
因为程序只和缓存交互,编码会变得更加简单和整洁,当需要在多处复用相同逻辑时这点就变得格外明显。
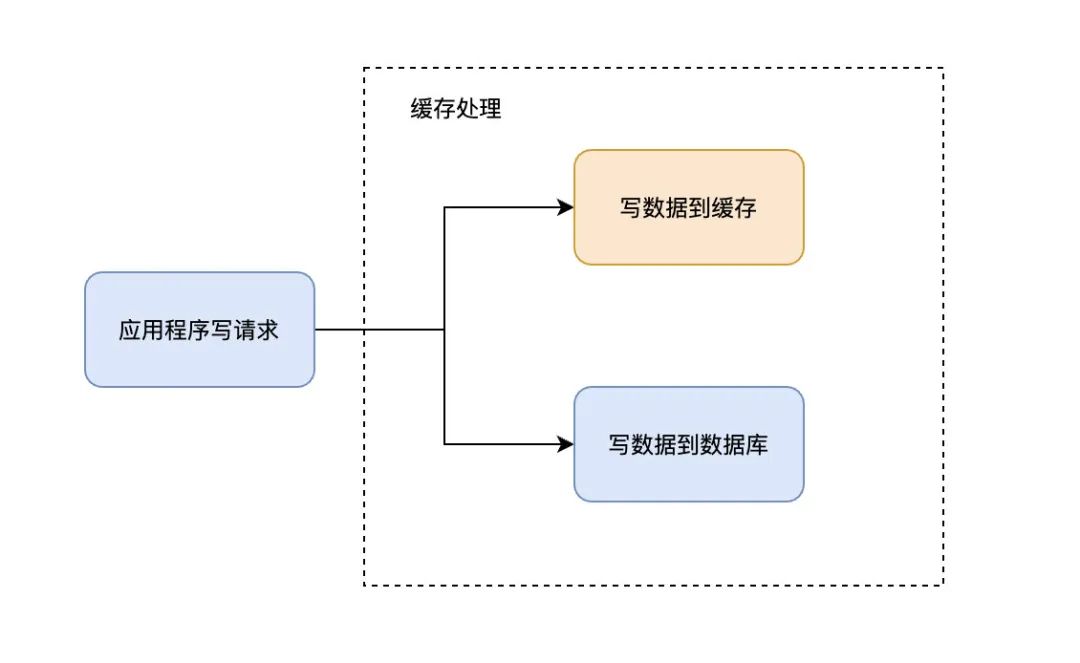
当使用Write-Through时,一般都配合使用Read-Through来使用。Write-Through的潜在使用场景是银行系统。
Write-Through适用情况有:
需要频繁读取相同数据
不能忍受数据丢失(相对Write-Behind而言)和数据不一致
在使用Write-Through时要特别注意的是缓存的有效性管理,否则会导致大量的缓存占用内存资源。甚至有效的缓存数据被无效的缓存数据给清除掉。
Write-Behind
Write-Behind和Write-Through在”程序只和缓存交互且只能通过缓存写数据“这方面很相似。不同点在于Write-Through会把数据立即写入数据库中,而Write-Behind会在一段时间之后(或是被其他方式触发)把数据一起写入数据库,这个异步写操作是Write-Behind的最大特点。
数据库写操作可以用不同的方式完成,其中一个方式就是收集所有的写操作并在某一时间点(比如数据库负载低的时候)批量写入。另一种方式就是合并几个写操作成为一个小批次操作,接着缓存收集写操作一起批量写入。
异步写操作极大地降低了请求延迟并减轻了数据库的负担。同时也放大了数据不一致的。比如有人此时直接从数据库中查询数据,但是更新的数据还未被写入数据库,此时查询到的数据就不是最新的数据。
小结
不同的缓存模式有不同的考量点和特征,根据应用程序需求场景的不同,需要灵活的选择适配的缓存模式。在实践的过程中往往也是多种模式相结合来使用。

往期推荐

边栏推荐
- Mysql 索引命中级别分析
- Self made dataset in pytoch for dataset rewriting
- Introduction to OTA technology of Internet of things
- 本周小贴士#134:make_unique与私有构造函数
- Use onedns to perfectly solve the optimization problem of office network
- 请将磁盘插入“U盘(H)“的情况&无法访问 磁盘结构损坏且无法读取
- Mrs offline data analysis: process OBS data through Flink job
- Based on pytorch, we use CNN to classify our own data sets
- [OKR target management] value analysis
- 使用 xml资源文件定义菜单
猜你喜欢
![[OKR target management] case analysis](/img/73/d28cdf40206408be6e2ca696b8e37f.jpg)



![Easy to understand [linear regression of machine learning]](/img/db/f300457165de7ab12aefac8842330f.jpg)

随机推荐
Management by objectives [14 of management]
深度学习机器学习各种数据集汇总地址
Examen des lois et règlements sur la sécurité de l'information
什么是敏捷测试
【解惑】App处于前台,Activity就不会被回收了?
Actionbar navigation bar learning
百度地图自定义样式向右拖拽导致全球地图经度0度无法正常显示
基于百度飞浆平台(EasyDL)设计的人脸识别考勤系统
第3章业务功能开发(用户访问项目)
测试3个月,成功入职 “字节”,我的面试心得总结
Native JS verification code
漫画 | 宇宙第一 IDE 到底是谁?
原生js验证码
利用七种方法对一个文件夹里面的所有图像进行图像增强实战
viewflipper的功能和用法
[4500 word summary] a complete set of skills that a software testing engineer needs to master
开发一个小程序商城需要多少钱?
USB通信协议深入理解
SD_DATA_SEND_SHIFT_REGISTER
Function and usage of calendar view component