当前位置:网站首页>Self made dataset in pytoch for dataset rewriting
Self made dataset in pytoch for dataset rewriting
2022-07-07 17:41:00 【AI cannon fodder】
Through the last blog post , We can get the data of the file as follows :
So the process of self-made dataset is as follows :
(1) Generate csv perhaps txt file
See my last blog : Deep learning - Make your own dataset _AI Cannon fodder blog -CSDN Blog
(2) rewrite Dataset
(3) Generate DataLoader()
(4) Iterative data
(2)(3)(4) The complete code of step is as follows ;
import pandas as pd
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
import cv2 as cv
class diff_motion_dataset(Dataset):
def __init__(self, dataset_dir, csv_path, resize_shape): # After initialization, the initialization function will call itself
# init Methods generally need to write data transformer、 Basic parameters of data
self.dataset_dir = dataset_dir
self.csv_path = csv_path
self.shape = resize_shape
# Read our generated csv file
self.df = pd.read_csv(self.csv_path, encoding='utf-8')
self.transformer = transforms.Compose([
transforms.Resize(self.shape),
transforms.ToTensor(), # hold PIL nucleus np.array Convert images in format to Tensor
])
def __len__(self): # Return data size
return len(self.df)
def __getitem__(self, idx): # getitem, idx = index Is the subscript of the data sample . Special reminder: first list filename and label Take it out and proceed idx Read in sequence, otherwise an error will be reported
x_train = cv.imread(self.df['filepath'][idx]) # Read idx That's ok ,filename Columns of data ( That is, all images ), And then into transformer Inside , It will process the image resize and toTensor
y_train = self.df['label'][idx] # traindataLoader It will automatically turn label Turn into tensor
return x_train, y_train # A single piece of data is returned, not df All the data in it
data_ds = diff_motion_dataset("F:/reshape_images", "F:/reshape_images/motion_data.csv", (256, 256))
# print(len(data_ds))
# Data partitioning
num_sample = len(data_ds)
train_percent = 0.8
train_num = int(train_percent*num_sample)
test_num = num_sample - train_num
train_ds, test_ds = random_split(data_ds, [train_num, test_num])
# print(len(train_ds))
# 3. Generate DataLoader(). Make the data iteratable , Secondly, the data can be divided into many batch as well as shuffer、nun_worker Multithreading
train_dl = DataLoader(train_ds, batch_size=4, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=4, shuffle=True)
# # Iterative data
for x_train, y_train in iter(train_dl):
print(x_train.shape)
print(y_train.shape)
break
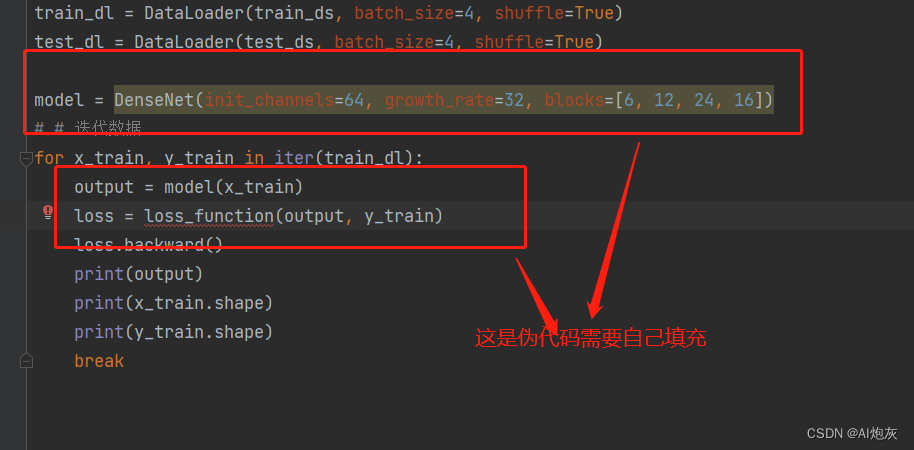
If you need self-defined model for self-made data set training , Call the defined model as follows :
Different formats are the production and loading of data sets, as shown in :
边栏推荐
- 基于PyTorch利用CNN对自己的数据集进行分类
- TaffyDB开源的JS数据库
- Share the latest high-frequency Android interview questions, and take you to explore the Android event distribution mechanism
- 【可信计算】第十次课:TPM密码资源管理(二)
- 本周小贴士#140:常量:安全习语
- Define menus using XML resource files
- 深入浅出图解CNN-卷积神经网络
- 麒麟信安携异构融合云金融信创解决方案亮相第十五届湖南地区金融科技交流会
- 大笨钟(Lua)
- 使用OneDNS完美解决办公网络优化问题
猜你喜欢




随机推荐
Functions and usage of serachview
如何在软件研发阶段落地安全实践
LeetCode 497(C#)
【可信计算】第十次课:TPM密码资源管理(二)
企业即时通讯软件是什么?它有哪些优势呢?
策略模式 - Unity
Toast will display a simple prompt message on the program interface
Functions and usage of imageswitch
Cartoon | who is the first ide in the universe?
L1-023 输出GPLT(Lua)
Face recognition attendance system based on Baidu flying plasma platform (easydl)
面试官:页面很卡的原因分析及解决方案?【测试面试题分享】
数字化转型的主要工作
Supplementary instructions to relevant rules of online competition
【信息安全法律法规】复习篇
Biped robot controlled by Arduino
<代码随想录二刷>链表
手机app外卖订餐个人中心页面
网络攻防复习篇
本周小贴士#136:无序容器