当前位置:网站首页>【分布式理论】(二)分布式存储
【分布式理论】(二)分布式存储
2022-07-07 15:40:00 【林立可】
分布式存储
先有分布式还是先有大数据呢?这是个值得思考的问题。因为大数据所以才会数据分布式存储,因为单机无法存储,所以需要分布式存储嘛。但是,另一方面,我们的数据产生天然就是分布式的,只不过我们一般的思路是集中存储,便于管理。
分布式存储的一般思路,就是将大数据切片,按照某种策略存储在多个节点之间,这种策略要确保数据的分布是均匀的,以保证节点负载的均匀;同时数据的分布也要有一定的稳定性,不能因为节点的变动产生较大规模的数据迁移现象。同时数据分散后要具备可靠性,采用冗余机制,保证数据不会异常丢失。最后,数据的分布式存储,需要保证数据获取的方便性,以及拆开之后还能聚合起来。
总之,分布式存储需要解决的问题:数据分布的稳定性,数据节点的异构性,数据的可用性和可靠性。
- 数据分布的稳定性:当节点故障时,不会存在大规模的数据迁移,这意味着我们需要良好的数据分布算法。
- 数据节点的异构性:数据节点性能不一,我们的数据分布算法应该考虑数据分布节点的偏向;
- 数据的可用性和可靠性:意味着我们数据的存储应该具备一定的容错能力,比如副本机制、持久化机制。
1,数据分区机制
数据分布的稳定,依赖于我们的数据分区策略,几种常见的数据分区算法:
- 基于范围的分区:比如按照年龄范围,地区范围;
- 基于列表的分区:比如按照国家、省市分区;
- 基于循环的分区:比如 mod 一个循环值;
- 基于散列的分区:最常见最常用的分区,比如 hash;
- 基于组合的分区:上述方式的组合。
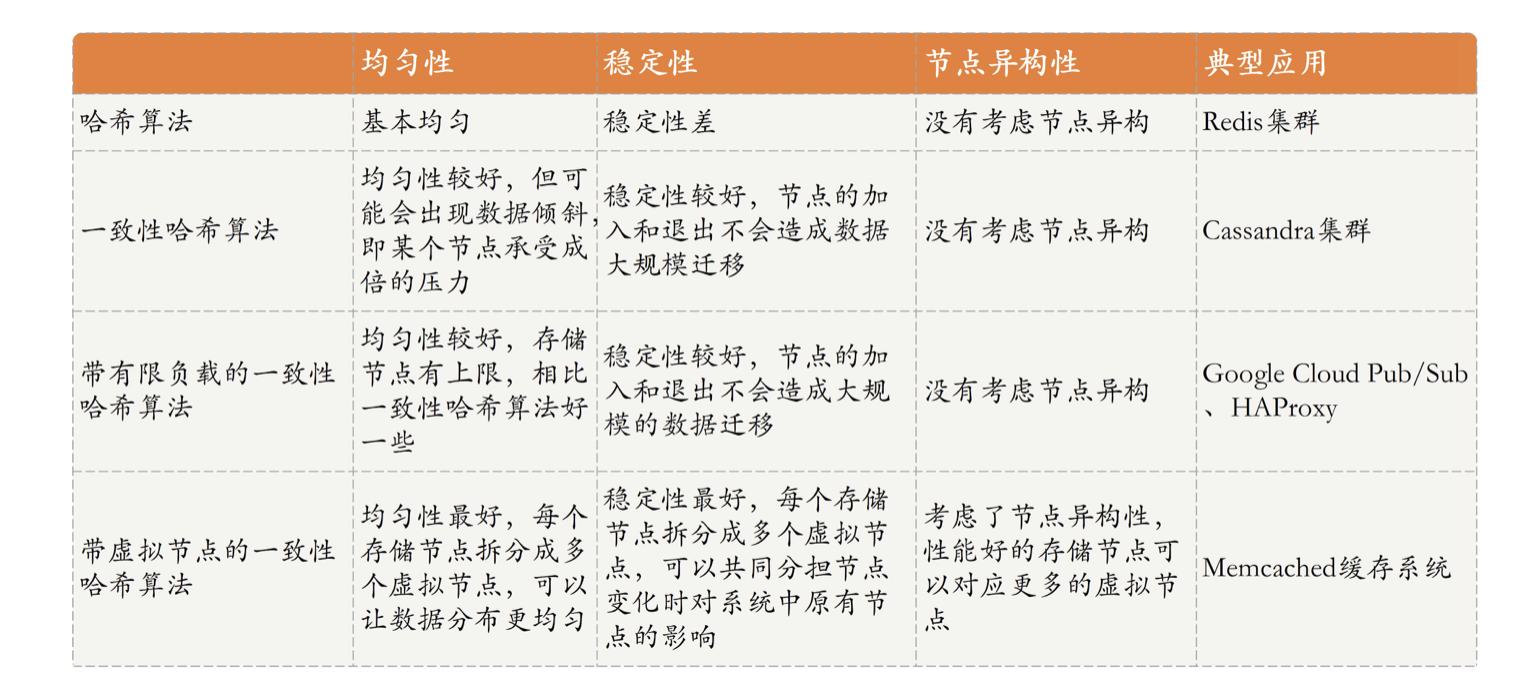
基于散列的分区,是大型分布式系统中最为常见的分区策略,所以这里我们主要讨论该算法的几种实现形式:
1,普通哈希,比如按照数据的某一字段进行哈希,然后分区;但存在着节点变动,数据大范围迁移的 rehash 现象;
2,一致性哈希,即按照顺时针顺序将数据存储到 hash 环中,当节点变动时,只需迁移相邻节点的数据即可。有个细节就是,一致性 hash 做数据查询时需要在节点内维护一个索引表,以定位节点内部数据的实际存储位置。但是这种方式,会导致部分节点承担较多的数据存储任务,节点的数据负载较高。
3,带有限负载的一致性 hash,即每个节点有固定的存储上限,当达到上限时会继续顺时针遍历下一个节点,存储数据;但是这种方式也没有考虑到节点异构带来的存储性能差异;
4,带虚拟头节点的一致性 hash,虚拟节点时按照节点性能差异分配的虚拟节点,也即节点性能好的,虚拟节点数量就会更多,数据就会尽可能地存储在该节点内。性能较为稳定。
2,数据复制机制
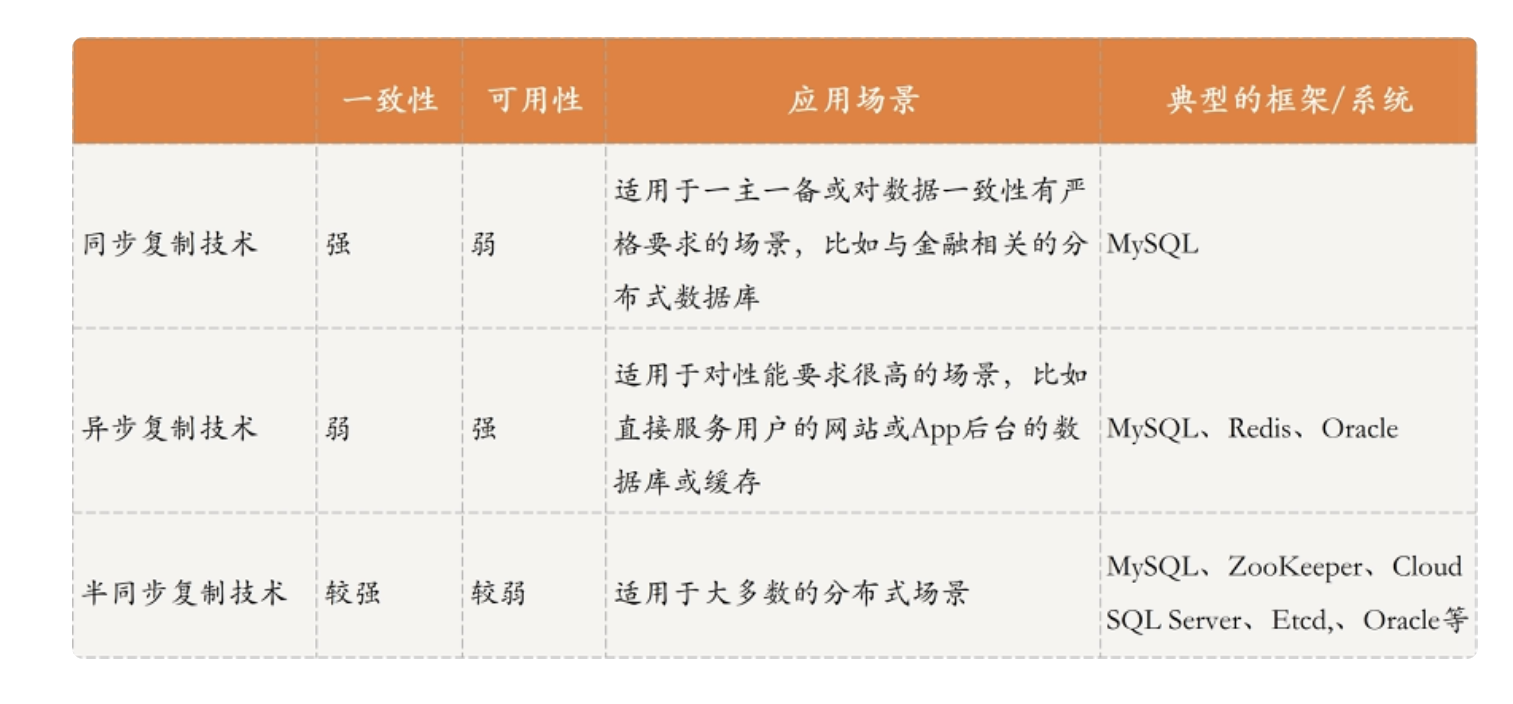
分布式场景下,如何实现数据复制的一致性?下面来看看几种数据复制策略:
同步复制:客户端在向主节点写入消息,然后主节点再向其它从节点同步完成,才会向客户端返回操作成功消息。这样的机制保证了数据的强一致性,但如果从节点较多,同步复制的时延较长,势必会影响可用性。在某些金融场合,交易场合适用。比如我们的 mysql 的主备集群方案,包括我们的 kafka 集群的副本的 ack 机制都是采用了类似的思想。
异步复制:客户端在向主节点写入消息,主节点立马返回操作成功的信息,然后再将数据异步复制到其他从节点。可以看到,这种机制保证了可用性,但牺牲了一致性,会出现客户端在主节点和从节点查询数据不一致的情况。该方案适用于对数据要求不高的情况,我们的 mysql 主备模式默认就是采用此方案。还有我们的 redis 集群,也是采用了这种方案保证了高性能。
半同步复制:即平衡了上面两种方式,兼顾了一致性和可用性。半同步复制包括两种,一种是收到一个从节点的响应即认为同步成功,一种是半数从节点响应后即认为成功。此种方案涉及到同步后数据不一致问题,即我们的数据同步因该以哪个节点为准的问题。一种思路是,以 leader 节点的数据为准,根据索引记录匹配,将从节点数据开始不一致的位置之后的数据,强行同步与 leader 一致。
我们的 mysql 集群方案,可以通过配置支持三种复制方式。
参考链接:
极客时间《分布式原理与算法解析》
边栏推荐
- 【黄啊码】为什么我建议您选择go,而不选择php?
- Biped robot controlled by Arduino
- 服务器彻底坏了,无法修复,如何利用备份无损恢复成虚拟机?
- 【TPM2.0原理及应用指南】 12、13、14章
- DNS series (I): why does the updated DNS record not take effect?
- Smart logistics platform: make overseas warehouses smarter
- 策略模式 - Unity
- The mail server is listed in the blacklist. How to unblock it quickly?
- 99% 用户在 Power BI 云端报表常犯错误
- [image sensor] correlated double sampling CDs
猜你喜欢

Sator launched Web3 game "satorspace" and launched hoobi

What is cloud computing?
【信息安全法律法規】複習篇
Skimage learning (2) -- RGB to grayscale, RGB to HSV, histogram matching
命令模式 - Unity

第3章业务功能开发(安全退出)

Test case management tool recommendation

SlashData开发者工具榜首等你而定!!!

《世界粮食安全和营养状况》报告发布:2021年全球饥饿人口增至8.28亿

麒麟信安中标国网新一代调度项目!
随机推荐
Reflections on "product managers must read: five classic innovative thinking models"
[fan Tan] those stories that seem to be thinking of the company but are actually very selfish (I: building wheels)
[Seaborn] combination chart: facetgrid, jointgrid, pairgrid
PLC:自动纠正数据集噪声,来洗洗数据集吧 | ICLR 2021 Spotlight
国内首创!Todesk将RTC技术融入远程桌面,画质更清晰操作更流畅
What is cloud computing?
网络攻防复习篇
LeetCode 403. Frog crossing the river daily
LeetCode 1031. Maximum sum of two non overlapping subarrays
redis主从、哨兵主备切换搭建一步一步图解实现
LeetCode 1477. Find two subarrays with sum as the target value and no overlap
【可信计算】第十二次课:TPM授权与会话
99% 用户在 Power BI 云端报表常犯错误
Flash build API Service - generate API documents
【视频/音频数据处理】上海道宁为您带来Elecard下载、试用、教程
rpcms获取指定分类下的文章的方法
本周小贴士#134:make_unique与私有构造函数
LeetCode 535(C#)
How to add aplayer music player in blog
字符串 - string(Lua)