当前位置:网站首页>Easy to understand [linear regression of machine learning]
Easy to understand [linear regression of machine learning]
2022-07-07 17:42:00 【SmartBrain】
Linear regression :
1. Take bank credit as an example , Popular speaking , Classification is based on your X( Qualifications such as salary and age ), To decide Y( Whether to give you a loan ), Return is to decide how much money you can borrow ;
2. The goal is : The loan data model is trained through various characteristics of loan data , A simple example , Is through input X( Age and salary ) To predict the Y( Whether to give you a loan );
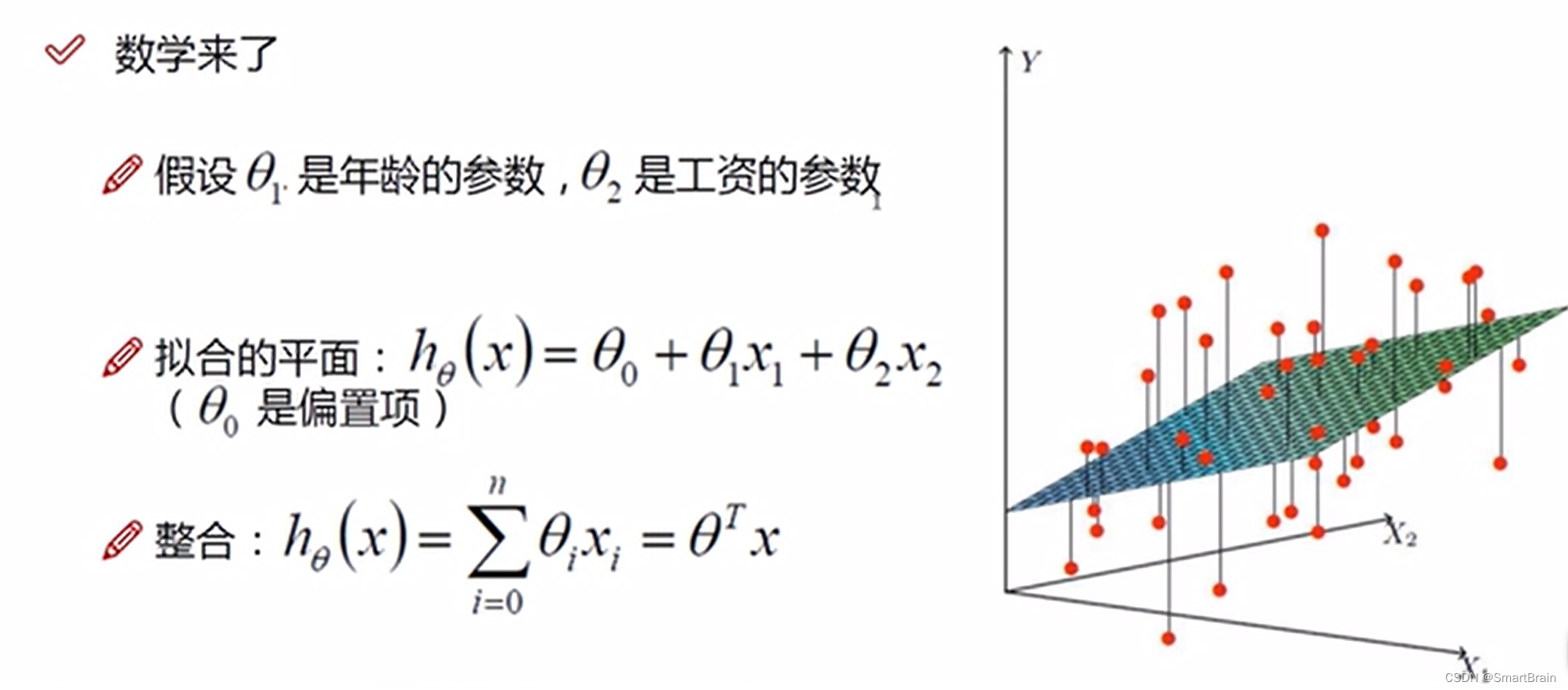
3. Method : Establish a regression equation ,Y=W1*X1( Wages )+W2*X2( Age );W Is the weight or parameter , Determine contribution ;
4. difficulty : It is impossible to fit all data points with one plane , Only try to find a plane that best fits the data ;
5. Mathematical expression : The data company is used to express the fitting plane as follows
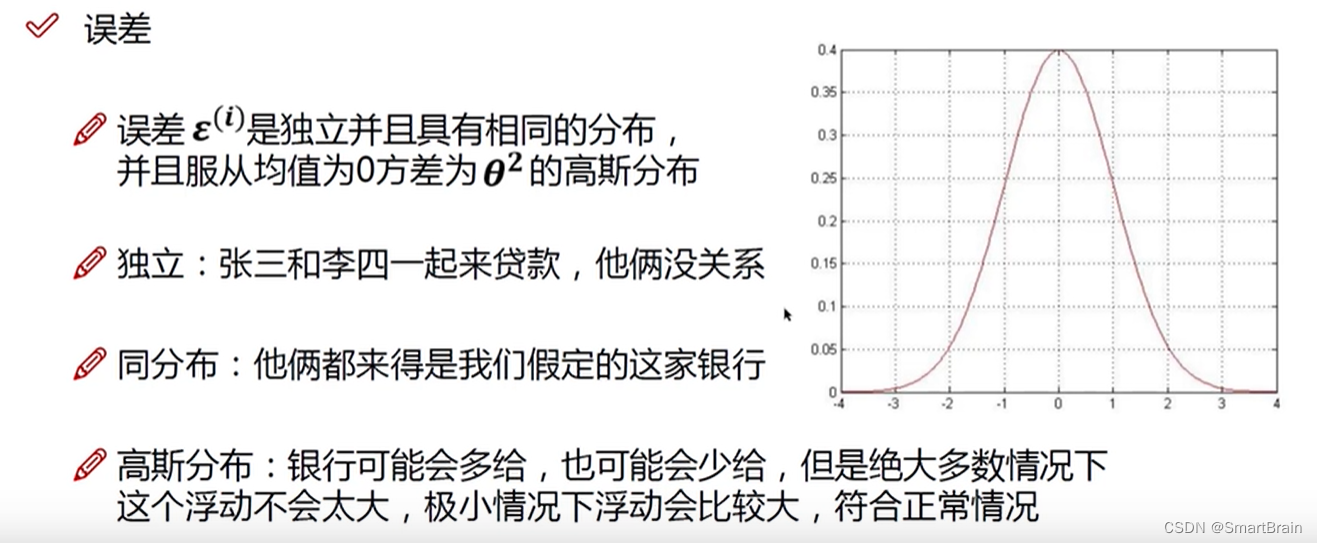
 6. Mainly to reduce the error , And the error must be for the equation of independent identically distributed , Obey Gaussian distribution , The details are as follows :
6. Mainly to reduce the error , And the error must be for the equation of independent identically distributed , Obey Gaussian distribution , The details are as follows :
7. At present , How to solve my parameters ?
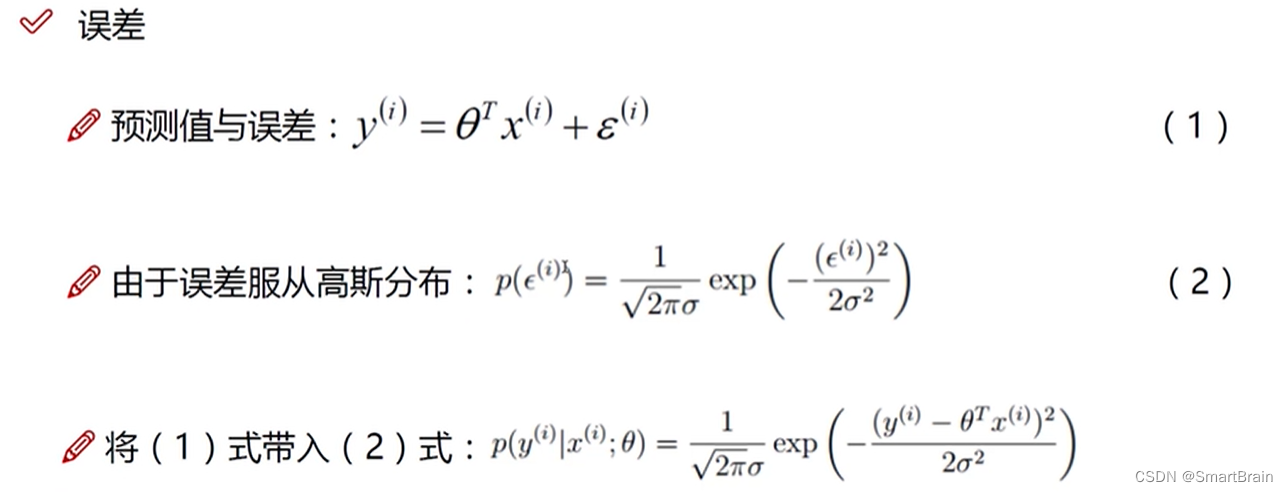 8. The goal is : Is to find the error is 0 In the equation of , The best parameter is that the predicted value is close to the real value , Therefore, a large amount of data is needed ( I'm going to set it to m) Find the right parameters , So it's the way of tiring , But multiplication is too complicated , We need to turn logarithm into addition problem .
8. The goal is : Is to find the error is 0 In the equation of , The best parameter is that the predicted value is close to the real value , Therefore, a large amount of data is needed ( I'm going to set it to m) Find the right parameters , So it's the way of tiring , But multiplication is too complicated , We need to turn logarithm into addition problem .

9. Into the extreme point of the parameter , bring Y Maximum , That is o J The minimum value of , It's the least square method
 10 , Find the current parameter , bring J Minimum , That is, the partial derivative is 0 yes , Is the extreme point of the parameter .
10 , Find the current parameter , bring J Minimum , That is, the partial derivative is 0 yes , Is the extreme point of the parameter .
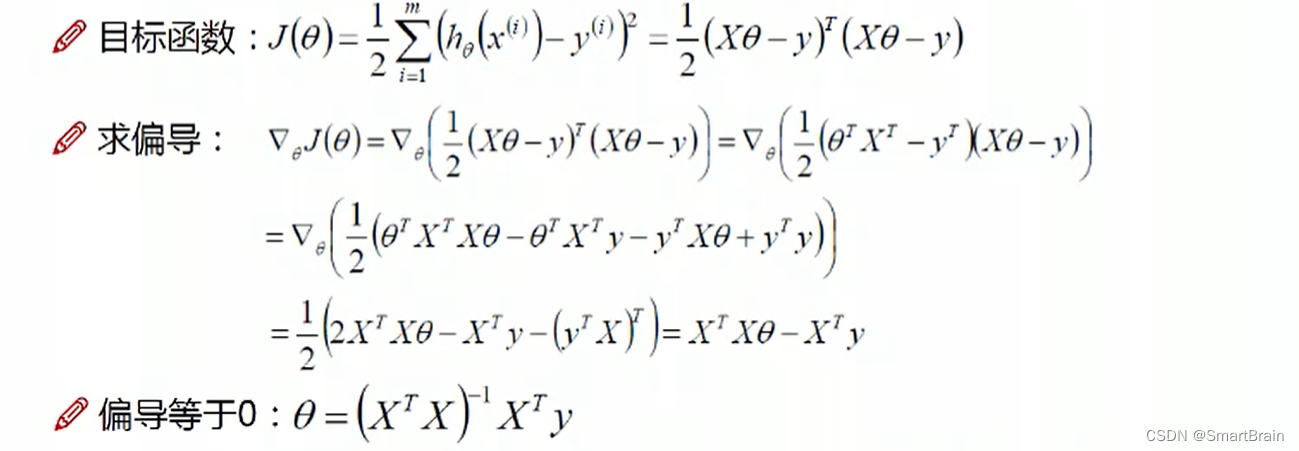
Summarized below :
1. deviation ( Distance ): It describes the gap between the expected value of the predicted value and the real value , The bigger the deviation , The more deviated from the real data . 2. variance ( Whether to gather ): Variance of predicted value , It describes the range of changes in the predicted values , discrete Degree of , That is, the distance from the predicted value to the expected value , The greater the variance , The more data is distributed , Conceptual understanding is more abstract , Now let's understand the deviation and variance through diagrams .
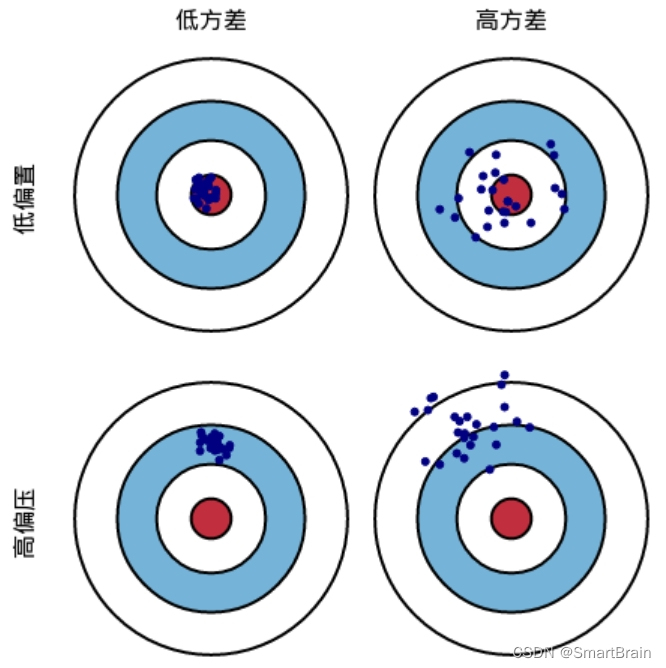
Pictured above , We assume that a shot is a machine learning model to predict a sample , Hitting the red bull's-eye position means the prediction is accurate , The farther away from the bull's-eye, the greater the prediction error . Deviation is a measure of how far the blue dot of the shot is from the red circle , The closer the blue dot is to the red bull's-eye, the smaller the deviation is , The farther the blue dot is from the red bull's-eye, the greater the deviation ; Variance measures whether the hand is stable when shooting, that is, whether the blue dots gather at the shooting position , The more concentrated the blue dots, the smaller the variance , The more scattered the blue dots, the greater the variance .
The generalization ability of the model ( The generalization error ) It is caused by deviation 、 Sum of variance and data noise
Deviation measures the degree of deviation between the prediction error and the real error of the learning algorithm , The learning ability of the instant drawing learning algorithm itself , Variance measures the change of learning performance caused by the change of training data of the same size , Immediately draw the impact caused by data disturbance , Noise expresses the lower bound of the expected prediction error that any learning algorithm can achieve in the current task , Immediately draw the difficulty of the learning problem itself , Therefore, the generalization error is determined by the ability of the learning algorithm 、 The adequacy of the data and the difficulty of the problem itself determine When learning algorithm is just trained , Insufficient training and insufficient fitting , At this time, the deviation is large ; When the training is deepened , The disturbance of training data is also learned by the algorithm , At this time, the algorithm is over fitted , Over variance , Slight disturbance of training data will make the learning model change significantly ,
So we come to the conclusion that : The deviation is too large when the model is under fitted , The variance is too large when the model is over fitted .
1、 High deviation ( Model underfit ) Time model optimization method
(1) Add feature number When the feature is insufficient or the correlation between the selected feature and the tag is not strong , The model is prone to under fitting , By mining context features 、ID Class characteristics 、 Combined features and other new features , It can often achieve the effect of preventing under fitting , In deep learning , There are many models that can help with Feature Engineering , Such as factorizer 、 Gradient lift decision tree 、Deep-crossing And so on can be called the method of enriching features
(2) Increase model complexity If the model is too simple, the learning ability will be poor , By increasing the complexity of the model, the model can have stronger you and ability , For example, add high in the linear model , Increase the number of hidden layers or neurons in the neural network model
(3) Extend the training time In decision tree 、 Neural network , The generalization ability of the model can be enhanced by increasing the training time , Make the model have enough time to learn the characteristics of the data , Can achieve better results
(4) Reduce the regularization coefficient Regularization is used to over fit , However, when the model is under fitted, a targeted small regularization coefficient is needed , Such as xgboost Algorithm
(5) Integrated learning methods Boosting Boosting The algorithm is to concatenate multiple weak classifications , Such as Boosting During algorithm training , We calculate the errors and residuals of weak classifiers , As input to the next classifier , This process itself is constantly reducing the loss function , Reduce the deviation of the model
(6) Choose a more appropriate model Sometimes the reason for under fitting is that the model is not selected correctly , For example, linear models are used for nonlinear data , The fitting effect is certainly not good enough , Therefore, it is sometimes necessary to consider whether the model is inappropriate
2、 High variance ( The model is over fitted ) Time model optimization method
(1) Add data set Adding data sets is the most effective means to solve the over fitting problem , Because more data can make the model learn more and more effective features , Reduce the impact of noise . Of course, data is very valuable , Sometimes there is not so much data available or the acquisition cost is too high , But we can also expand the training data through certain rules , For example, on the problem of image classification , It can be translated through the image , rotate , The zoom 、 Blur and add noise to expand the data set , In my article, I introduce , Take another step , The generative countermeasure network can be used to synthesize a large amount of new data
(2) Reduce the complexity of the model When data sets are small , The complexity of the model is the main factor of over fitting , Appropriately reducing the complexity of the model can avoid excessive sampling noise in model fitting , For example, reduce the depth of the tree in the decision tree algorithm 、 Pruning ; Reduce the number of network layers in deep Networks 、 Number of neurons, etc
(3) Regularization prevents over fitting Regularization idea : Because the model is over fitted, it is likely that the training model is too complex , So in training , While minimizing the loss function , We need to limit the number of model parameters , That is, add the regular term , That is, it is not supposed to reduce the loss function , At the same time, the complexity of the model is also considered
边栏推荐
猜你喜欢




随机推荐
L1-028 判断素数(Lua)
Audio device strategy audio device output and input selection is based on 7.0 code
目标管理【管理学之十四】
【可信计算】第十一次课:TPM密码资源管理(三) NV索引与PCR
notification是显示在手机状态栏的通知
Lex & yacc of Pisa proxy SQL parsing
面试官:页面很卡的原因分析及解决方案?【测试面试题分享】
【网络攻防原理与技术】第3章:网络侦察技术
【网络攻防原理与技术】第4章:网络扫描技术
Establishment of solid development environment
在窗口上面显示进度条
手机版像素小鸟游js戏代码
actionBar 导航栏学习
With the latest Alibaba P7 technology system, mom doesn't have to worry about me looking for a job anymore
Functions and usage of viewswitch
【可信计算】第十三次课:TPM扩展授权与密钥管理
Problems encountered in Jenkins' release of H5 developed by uniapp
Function and usage of calendar view component
mysql官网下载:Linux的mysql8.x版本(图文详解)
【分布式理论】(二)分布式存储