当前位置:网站首页>机器学习和深度学习中的梯度下降及其类型
机器学习和深度学习中的梯度下降及其类型
2022-08-02 14:08:00 【vcsir】
机器学习和深度学习中的梯度下降及其类型
介绍
梯度下降算法是一种最常用于机器学习和深度学习的优化算法。梯度下降调整参数以将特定函数最小化到局部最小值。在线性回归中,它找到权重和偏差,深度学习反向传播使用该方法。
该算法的目标是识别模型参数,如权重和偏差,以减少训练数据上的模型误差。
在本文中,我们将探索不同类型的梯度下降。因此,让我们开始阅读这篇文章吧!
什么是梯度?
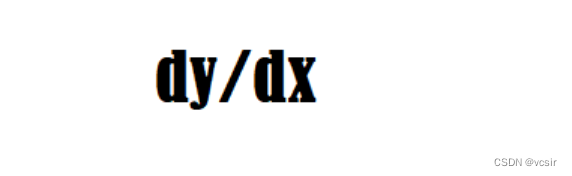
- 如果稍微改变输入,梯度会测量函数输出的变化量。
- 在机器学习中,梯度是具有多个输入变量的函数的导数。在数学术语中称为函数的斜率,梯度只是衡量关于误差变化的所有权重的变化。
学习率:
算法设计者可以设置学习率。如果我们使用的学习率太小,会导致我们更新非常慢,需要更多的迭代才能得到更好的解决方案。
梯度下降的类型
三种流行类型的主要区别在于它们使用的数据量: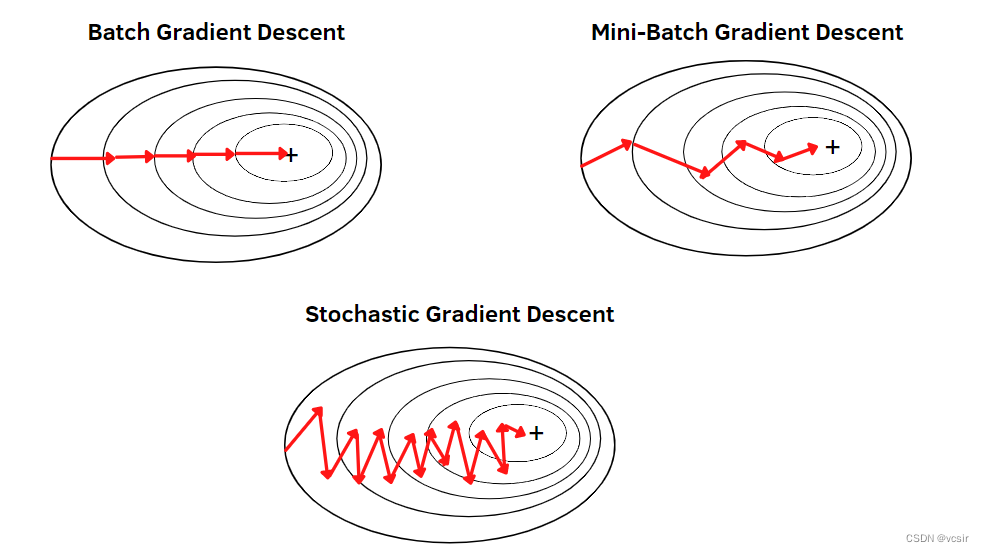
1、批量梯度下降
批量梯度下降,也称为普通梯度下降,计算训练数据集中每个样本的误差。尽管如此,在对每个训练样本进行评估之前,模型都不会改变。整个过程称为一个周期和一个训练时期。批处理的一些好处是它的计算效率,它产生稳定的误差梯度和稳定的收敛。一些缺点是稳定的误差梯度有时会导致收敛状态不是模型所能达到的最佳状态。它还要求整个训练数据集都在内存中并且可供算法使用。
代码实现
class GDRegressor:
def __init__(self,learning_rate=0.01,epochs=100):
self.coef_ = None
self.intercept_ = None
self.lr = learning_rate
self.epochs = epochs
def fit(self,X_train,y_train):
# init your coefs
self.intercept_ = 0
self.coef_ = np.ones(X_train.shape[1])
for i in range(self.epochs):
# update all the coef and the intercept
y_hat = np.dot(X_train,self.coef_) + self.intercept_
#print("Shape of y_hat",y_hat.shape)
intercept_der = -2 * np.mean(y_train - y_hat)
self.intercept_ = self.intercept_ - (self.lr * intercept_der)
coef_der = -2 * np.dot((y_train - y_hat),X_train)/X_train.shape[0]
self.coef_ = self.coef_ - (self.lr * coef_der)
print(self.intercept_,self.coef_)
def predict(self,X_test):
return np.dot(X_test,self.coef_) + self.intercept_
优点
1、更少的模型更新意味着最速下降法的这种变体比随机梯度下降法的计算效率更高。
2、降低更新频率可以为一些问题提供更稳定的误差梯度和更稳定的收敛。
3、分离预测误差计算和模型更新提供了基于并行处理的算法实现。
缺点
1、更稳定的误差梯度会导致模型过早收敛到一组次优的参数。
2、训练结束时期的更新需要在所有训练示例中累积预测误差的额外复杂性。
3、批量梯度下降法通常需要将整个训练数据集保存在内存中,并在算法中使用。
4、大型数据集可能导致模型更新或训练速度非常慢。
5、速度慢并且需要更多的计算能力。
2、随机梯度下降
相比之下,随机梯度下降 (SGD) 为数据集中的每个训练样本一次更改每个训练样本的参数。根据问题,这可以使 SGD 比批量梯度下降更快。一个好处是,定期更新可以让我们对改进率有一个相当准确的认识。但是,批处理方法的计算成本低于频繁更新。这种更新的频率也会产生噪声梯度,这可能导致错误率波动而不是逐渐下降。
优点
1、您可以通过频繁更新立即查看模型的性能和改进率。
2、这种最速下降法的变体可能是最容易理解和实施的,尤其是对于初学者。
3、增加模型更新的频率将使您能够更快地了解有关某些问题的更多信息。
4、嘈杂的更新过程允许模型避免局部最小值(例如,过早收敛)。
5、更快,需要更少的计算能力。
6、适用于较大的数据集。
缺点
1、与其他最速下降配置相比,频繁的模型更新计算量更大,并且使用大型数据集训练模型需要相当长的时间。
2、频繁更新会导致噪声梯度信号。这可能会导致模型参数并导致错误飞来飞去(整个训练时期的差异更大)。
3、沿着误差梯度的嘈杂学习过程也可能使算法难以承诺模型的最小误差。
在sklearn中sgd分类器的实现
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=5)
clf.fit(X, y)
SGDClassifier(max_iter=5)
3、小批量梯度下降
由于小批量梯度下降结合了批量梯度下降和 SGD 的思想,因此它是首选技术。它将训练数据集划分为可管理的组,并分别更新每个组。这在批量梯度下降的有效性和随机梯度下降的持久性之间取得了平衡。小批量大小通常在 50 到 256 之间,但与其他机器学习技术一样,没有固定标准,因为它取决于应用程序。深度学习中最流行的一种,在训练神经网络时使用这种方法。
代码实现
class MBGDRegressor:
def __init__(self,batch_size,learning_rate=0.01,epochs=100):
self.coef_ = None
self.intercept_ = None
self.lr = learning_rate
self.epochs = epochs
self.batch_size = batch_size
def fit(self,X_train,y_train):
# init your coefs
self.intercept_ = 0
self.coef_ = np.ones(X_train.shape[1])
for i in range(self.epochs):
for j in range(int(X_train.shape[0]/self.batch_size)):
idx = random.sample(range(X_train.shape[0]),self.batch_size)
y_hat = np.dot(X_train[idx],self.coef_) + self.intercept_
#print("Shape of y_hat",y_hat.shape)
intercept_der = -2 * np.mean(y_train[idx] - y_hat)
self.intercept_ = self.intercept_ - (self.lr * intercept_der)
coef_der = -2 * np.dot((y_train[idx] - y_hat),X_train[idx])
self.coef_ = self.coef_ - (self.lr * coef_der)
print(self.intercept_,self.coef_)
def predict(self,X_test):
return np.dot(X_test,self.coef_) + self.intercept_
优点
1、该模型比堆栈梯度下降法更新得更频繁,允许更稳健的收敛并避免局部最小值。
2、批量更新提供了比随机梯度下降更高效的计算过程。
3、批处理既可以提高内存中没有所有训练数据的效率,又可以实现算法。
缺点
1、小批量需要为学习算法设置额外的超参数“小批量大小”。
2、错误信息应该在小批量训练样本上累积,例如批量梯度下降。
3、它将产生复杂的功能。
配置小批量梯度下降
小批量最速下降法是推荐用于大多数应用的最速下降法的变体,即强化学习。为简洁起见,通常称为“批量大小”的小批量大小,需要针对运行实现的计算架构的某些方面进行定制。例如,与 GPU 或 CPU 硬件的内存要求相匹配的 2 的幂,例如 32、64、128 和 256。堆栈大小是学习过程的滑块。较小的值可以让学习过程以牺牲训练过程中的噪声为代价快速收敛。较大的值会导致学习过程缓慢收敛到对误差梯度的准确估计。
结论
在本文中,我们了解了不同类型的梯度下降。这篇文章的主要内容是:
1、小批量最速下降法是推荐的方法,因为它结合了批量最速下降的概念和 SGD。只需将您的训练数据集划分为可管理的组并单独更新每个组,这平衡了批量梯度下降的有效性和随机梯度下降的持久性。
2、使用批量梯度下降时,在计算某个批次的误差后进行调整。批量梯度下降法的一个优点是它的计算效率,它产生稳定的误差梯度和稳定的收敛。
3、随机梯度下降(SGD)顺序修改数据集中每个训练样本中每个训练样本的参数,这使得 SGD 比批量梯度下降更快。一个好处是,定期更新可以让我们对改进率有一个相当准确的认识。
4、一般来说,学习率越高,模型学习的速度越快,代价是非最优的最终权重集。在学习率较低的情况下,该模型可以学习到一组更优或全局最优的权重,但训练可能需要相当长的时间。
边栏推荐
猜你喜欢

随机推荐
LLVM系列第二十八章:写一个JIT Hello World
深度学习之文本分类总结
boost库智能指针
Ehcache基础学习
加强版Apktool堪称逆向神器
自定义UDF函数
In the Visual studio code solutions have red wavy lines
The problem that UIWindow's makeKeyAndVisible does not call viewDidLoad of rootviewController
使用预训练语言模型进行文本生成的常用微调策略
PyTorch⑥---卷积神经网络_池化层
深度学习之 卷积网络(textCNN)
1.RecyclerView是什么
Redis数据库相关指令
kotlin Android序列化
使用flutter小记
flutter中App签名
LLVM系列第三章:函数Function
针对多轮推理分类问题的软标签构造方法
神经网络可以解决一切问题吗:一场知乎辩论的整理
Visual studio代码中有红色波浪线解决办法