当前位置:网站首页>IO模型复习
IO模型复习
2022-07-07 07:57:00 【Zong_0915】
IO模型复习
前言
这一块看的冰河老师的文章,做个复习。
一. IO的基础概念
首先来说下什么是IO:涉及计算机核心与其他设备间数据迁移的过程,就是IO。 例如磁盘IO:
- 输入:从磁盘中读取数据到内存。
- 输出:将内存中的数据写入磁盘。
而操作系统发起一次IO操作一般会包含两个阶段:
- IO调用:应用程序进程向操作系统内核发起调用。
- IO执行:操作系统内核完成IO操作。
其中,IO执行阶段又分为两个阶段:
- 准备数据阶段:内核等待I/O设备准备好数据。
- 拷贝数据阶段:将数据从内核缓冲区拷贝到用户进程缓冲区。
如图: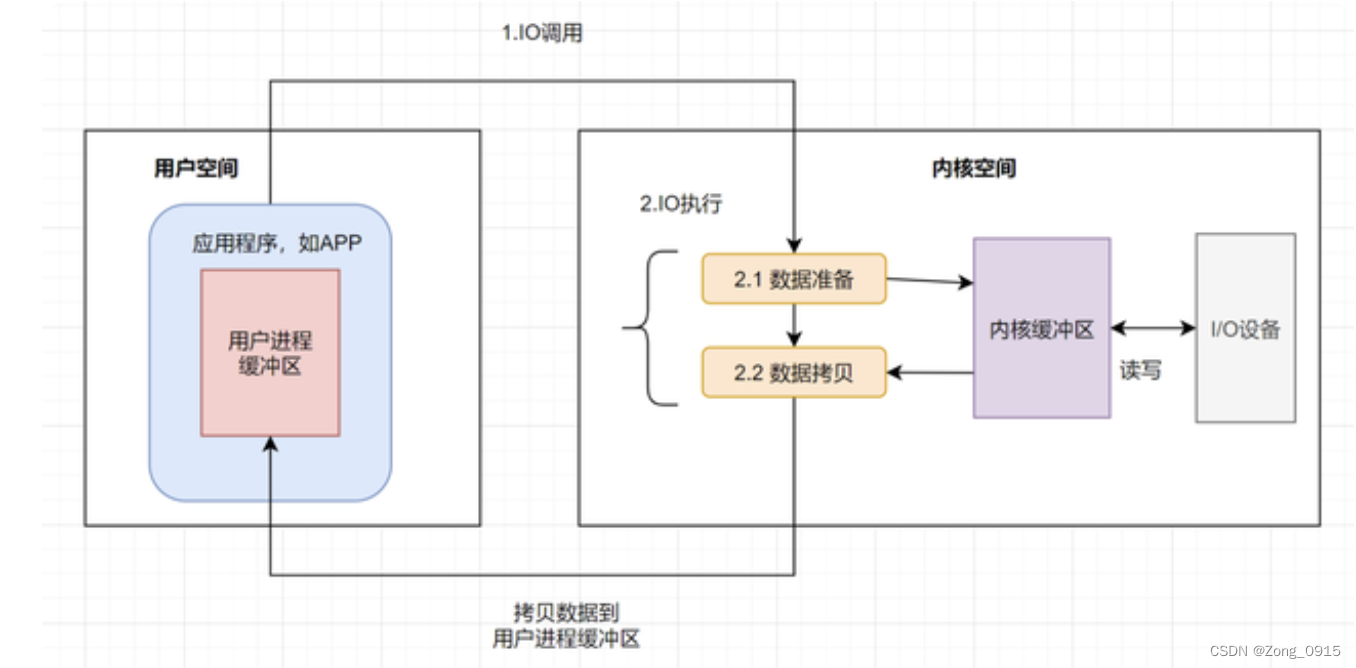
二. IO模型
IO模型主要有五种类型:
2.1 阻塞式IO(BIO)
应用程序进程发起IO调用,但是内核数据还没准备好。因此应用进程一直阻塞等待,直到内核数据准备好。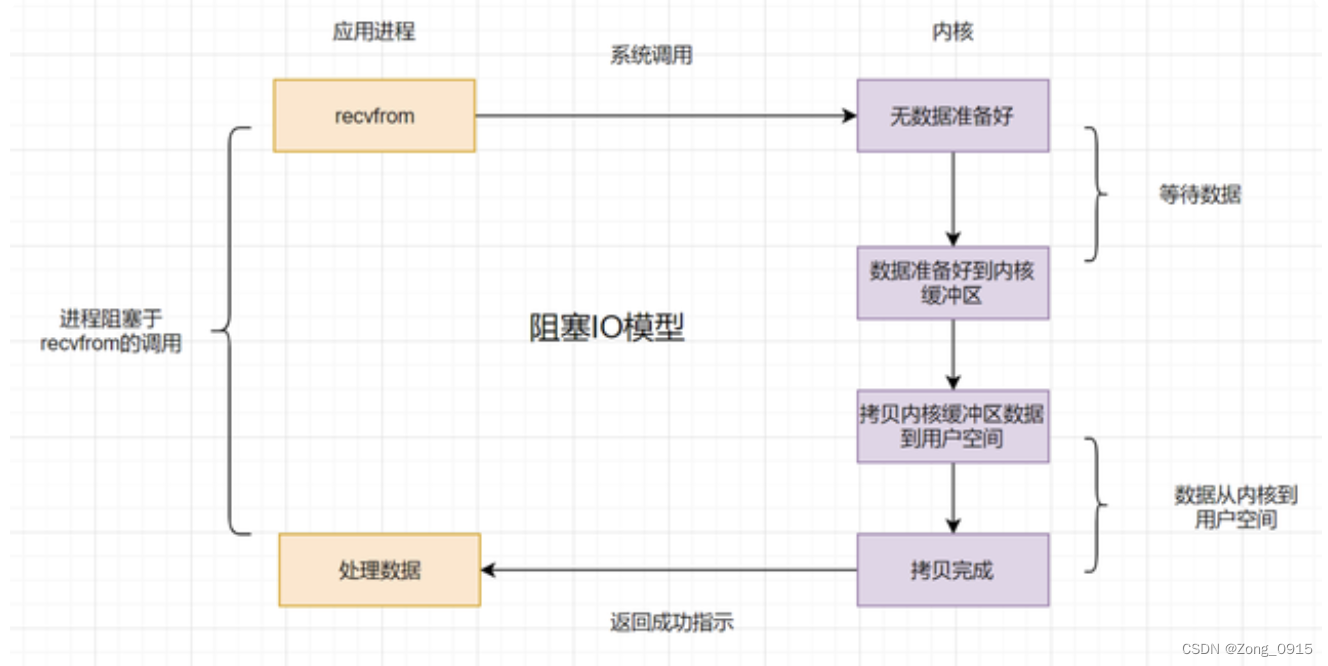
缺点:如果内核数据一直没准备好,那用户进程将一直阻塞,浪费性能。
2.2 非阻塞式IO(NIO)
鉴于阻塞式IO的缺点,在其基础上,倘若内核数据还没准备好,非阻塞式IO会先将错误信息返回给用户进程,让其无需等待,再通过轮询的方式来请求。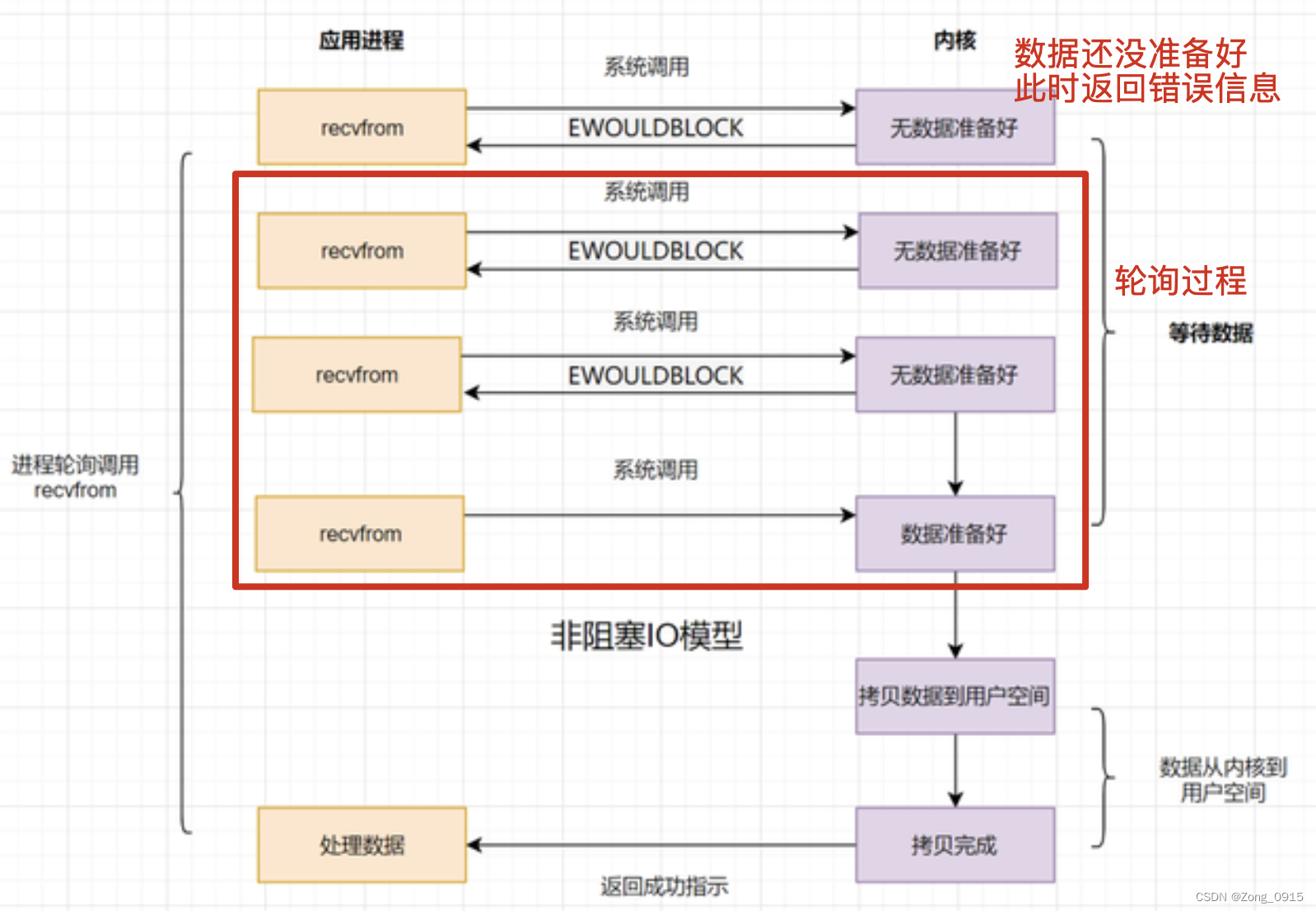 优点:相对于阻塞式IO,用户可以无需等待,不会因为内核数据没准备好而进入阻塞状态。
优点:相对于阻塞式IO,用户可以无需等待,不会因为内核数据没准备好而进入阻塞状态。
缺点:频繁的轮询,导致频繁的进行系统调用,消耗大量的CPU资源。
2.3 IO多路复用(BIO)
既然频繁的轮询导致CPU消耗很大。那就让内核数据准备好的时候,主动通知应用程序进行系统调用即可。也就是IO多路复用。
概念:文件描述符(File Descriptor)
文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
IO复用模型核心思路:系统给我们提供一类函数,它们可以同时监控多个fd的操作,任何一个返回内核数据就绪,应用进程再发起系统调用。注意,这里依旧是需要应用进程去发起系统调用的。
IO多路复用的方式有三种:select、poll、epoll。
2.3.1 select
应用进程可以通过select函数,来同时监控多个fd,在select函数监控fd的过程中,只要任何一个数据状态准备就绪了。select就会返回可读状态,这时候应用进程就会发起请求读取内核数据。 如图: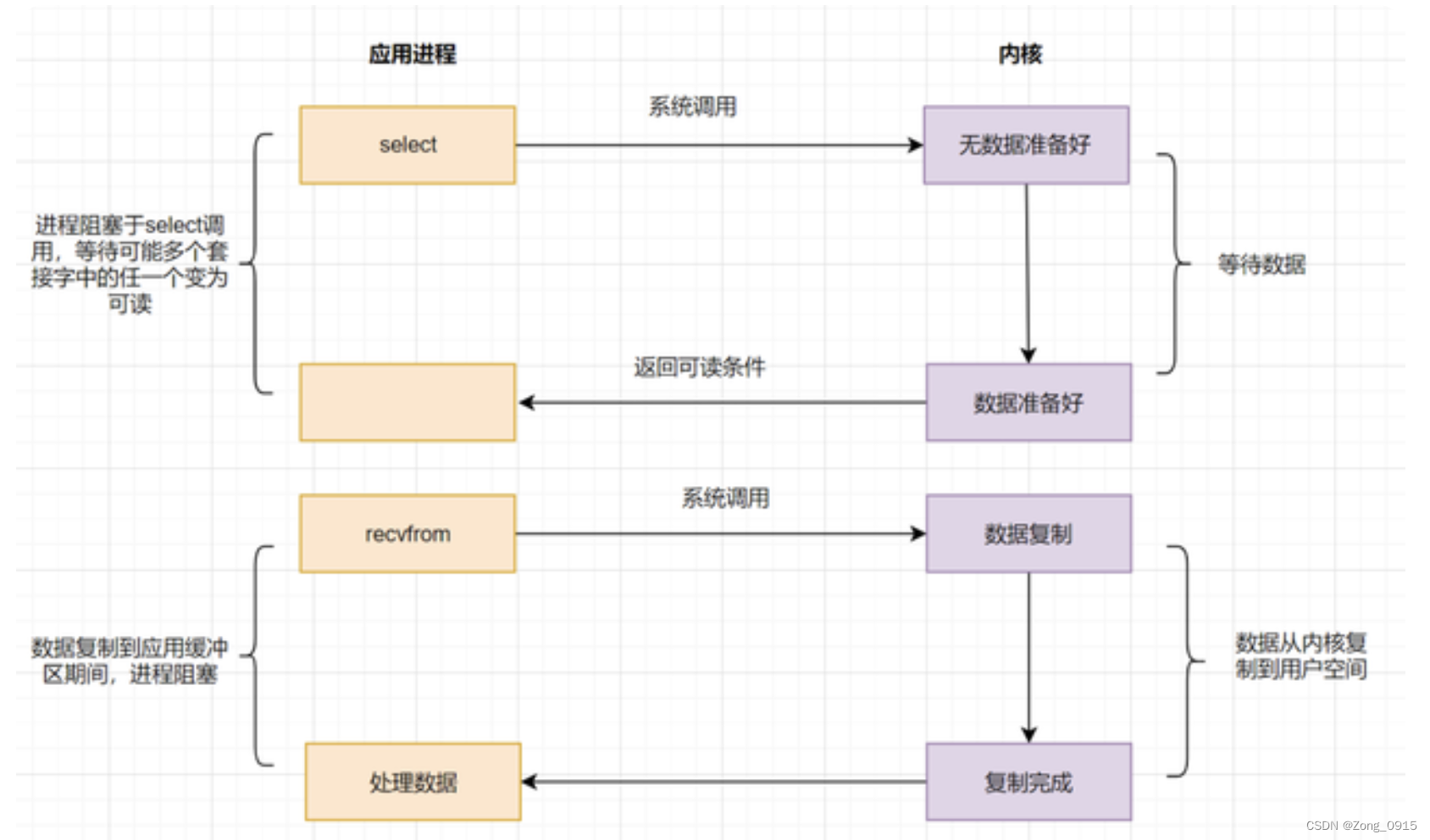
缺点如下:
- 监听的IO最大连接数有上限。
select函数返回后,是通过遍历fd集合,找到就绪的描述符fd。(即遍历所有的流)
2.3.2 poll
鉴于select方式的缺点,就提出了poll。与前者相比,poll解决了连接数量限制的问题。但是poll还是需要通过遍历文件描述符来获取已经就绪的socket。
2.3.3 epoll
那么为了解决select和poll存在的问题,就有了IO多路复用(epoll)模型,采用事件驱动来实现: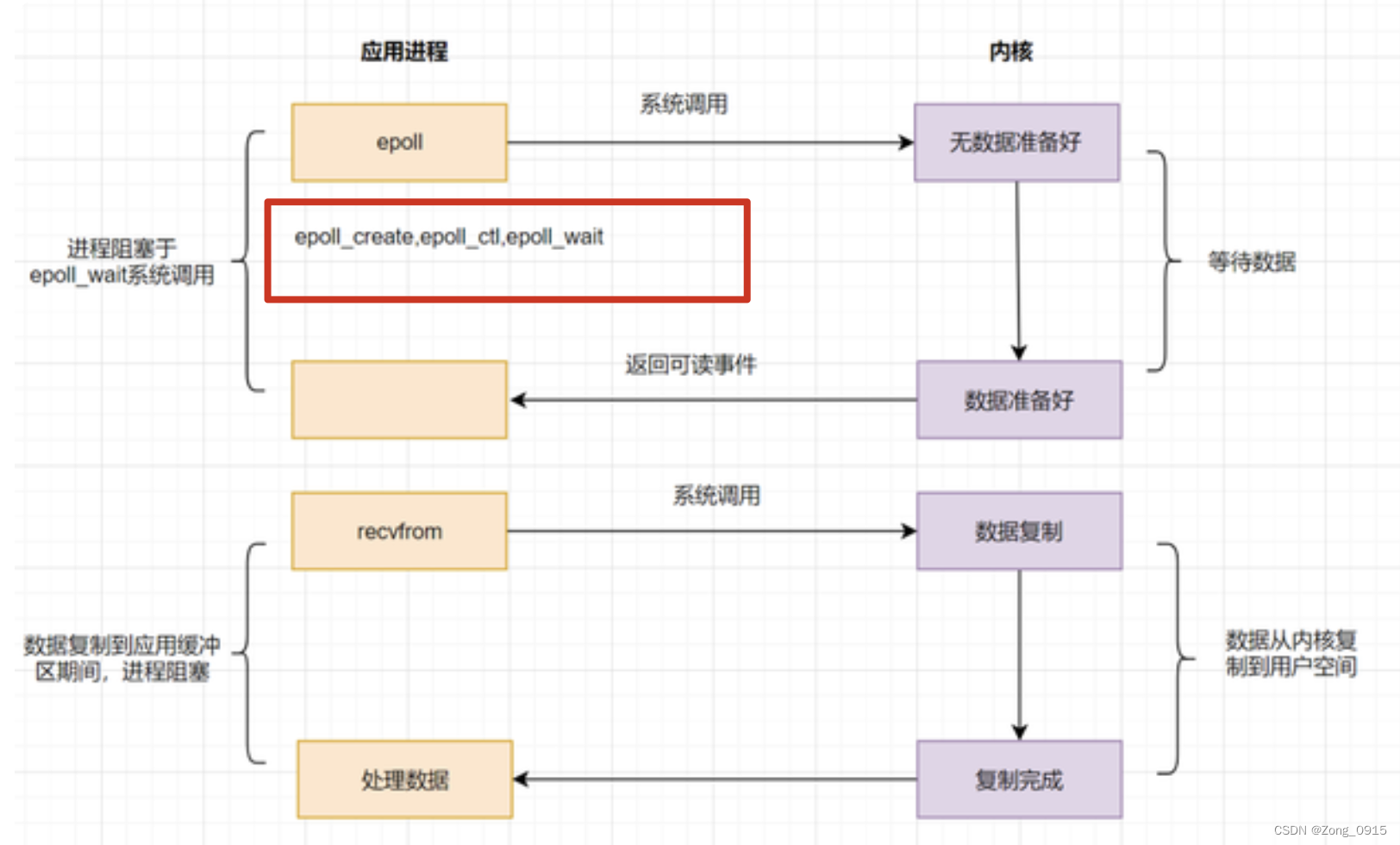
看起来和select的流程图没啥区别,这里加点文字描述:
epoll首先通过epoll_ctl()函数来注册一个文件描述符。- 一旦基于某个
fd就绪时,内核会采用回调机制,迅速激活这个fd。 - 当进程调用
epoll_wait()时便得到通知。通过采用监听事件回调的机制来避免遍历所有的文字描述符。
虽然IO多路复用这种方式对于非阻塞式IO,不需要进行频繁的调用,而是通过回调的方式来进行。但是当进程调用epoll_wait()时,仍然可能被阻塞。
重要的事情说三遍,多路复用IO它依旧是:同步阻塞的!同步阻塞的!同步阻塞的!
因此从设计上希望有这么个功能(这里我觉得应该这么理解会更好):
- 多路复用IO,虽然可以指定对应的IO流。避免遍历所有的IO。
- 虽然是通过回调的方式来获取结果的,但是这个等待结果的这个过程,是需要阻塞去等待的。
- 因此设计上希望用户进程可以无需等待,先去做别的事情。等回调结果有了,我再去感应即可。
随之而来的也就是信号驱动IO模型。
2.4 信号驱动IO(NIO)
在多路复用的基础上。向内核发送一个信号。此时应用进程不用阻塞,可以去做其他事情。当内核数据准备好后,再通过SIGIO信号通知应用进程。进程一旦获取到信号,就立即调用获取内核数据。如图: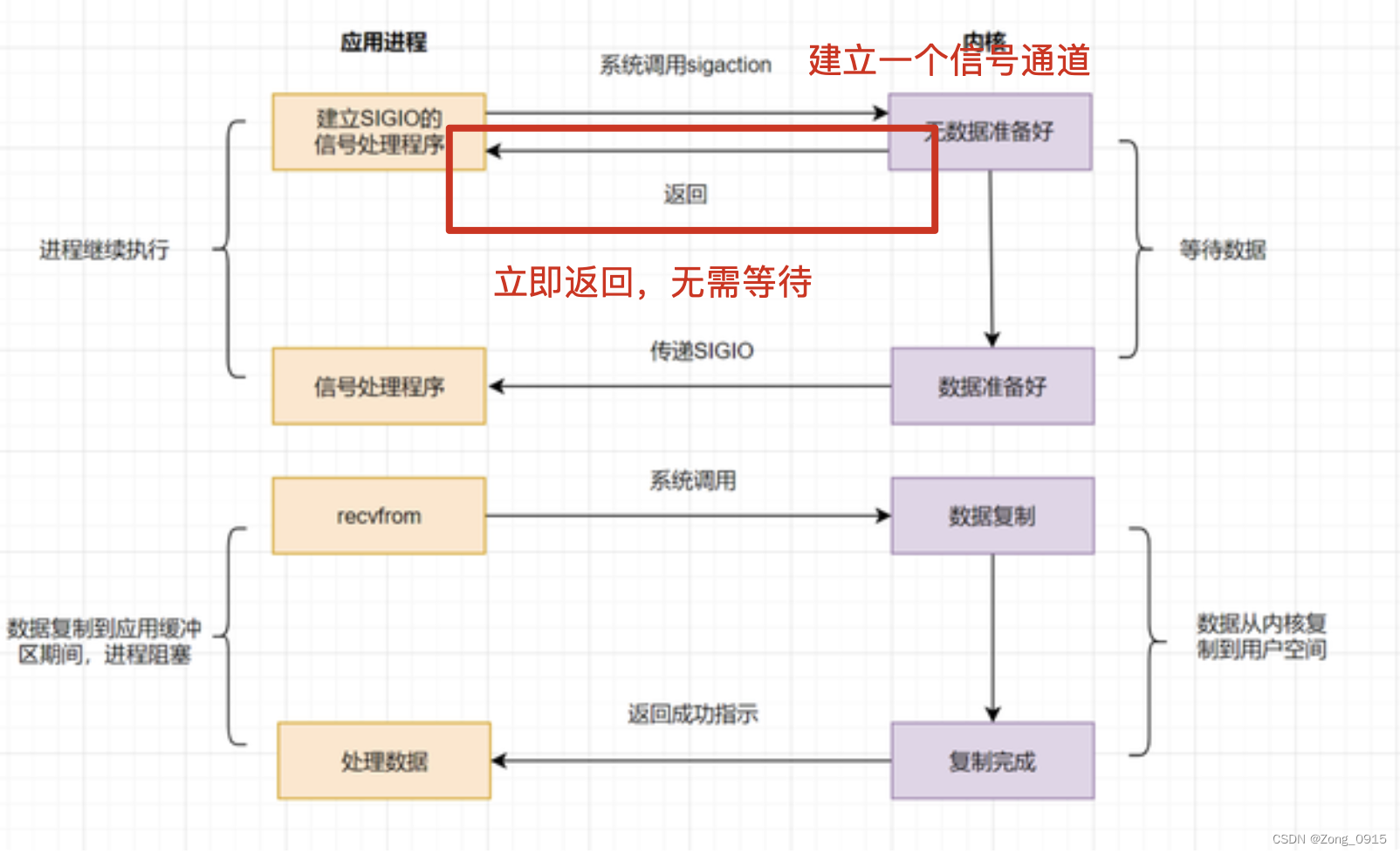
当然,这里数据状态询问流程是异步的没错,但是数据复制部分,依旧是同步阻塞的,也因此这整个信号驱动IO的流程并不是异步的。
2.5 异步IO(AIO)
只需要向内核发送一次请求,就可以完成数据状态询问和数据拷贝的所有操作,并且不用阻塞等待结果。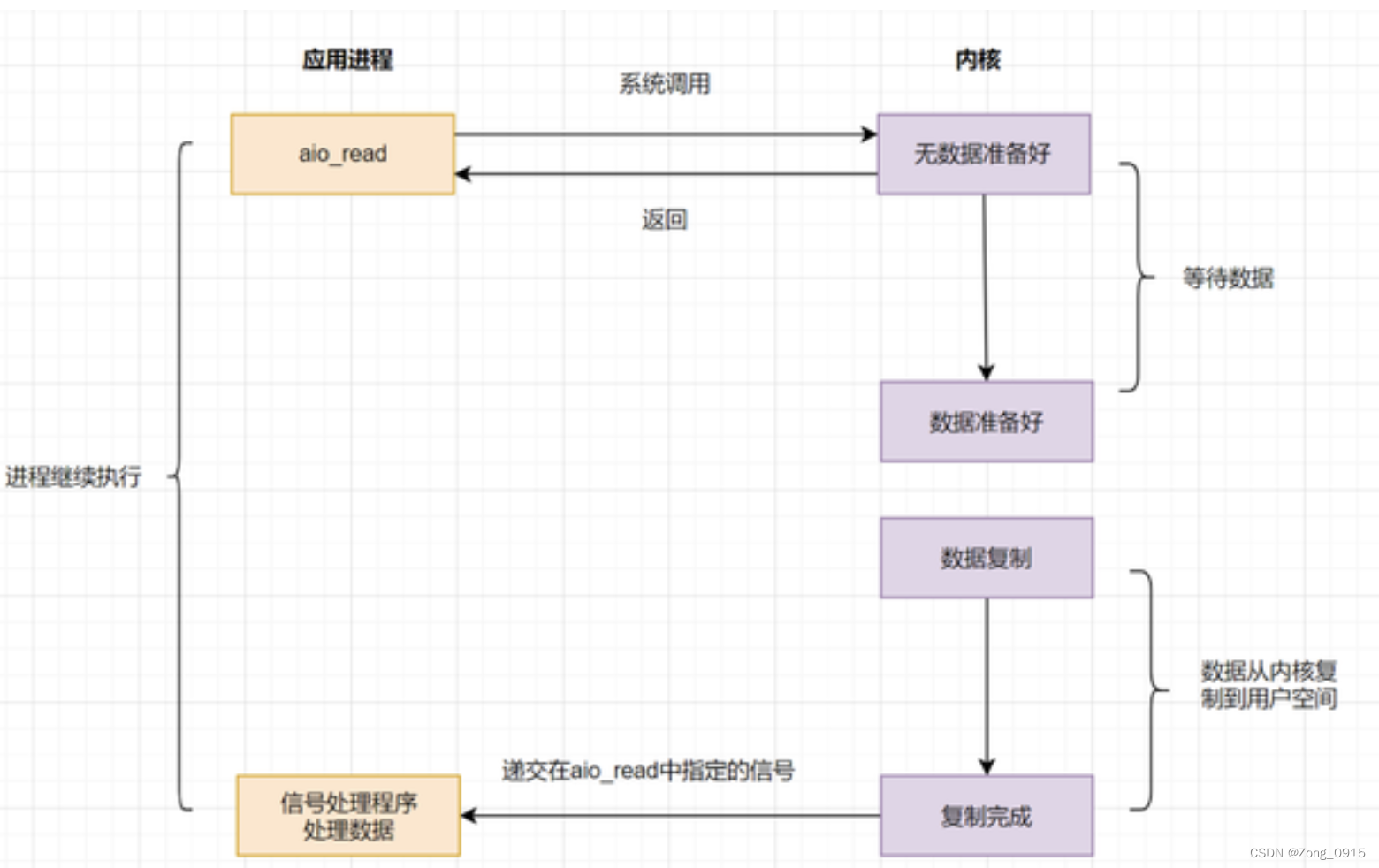
这里解释下BIO、NIO、AIO:
- 同步阻塞(
blocking-IO)简称BIO。 - 同步非阻塞(
non-blocking-IO)简称NIO。 - 异步非阻塞(
asynchronous-non-blocking-IO)简称AIO。
三. 总结
3.1 select、poll、epoll三者区别*
| 比较项 | select | poll | epoll |
|---|---|---|---|
| 底层数据结构 | 数组 | 链表 | 红黑树+双链表 |
| 获取就绪的fd方式 | 遍历所有 | 遍历所有 | 事件回调 |
| 事件复杂度 | O(n) | O(n) | O(1) |
| 最大连接数 | 1024(Linux) | 无限制 | 无限制 |
fd数据拷贝方式 | 每次调用select,都需要将fd从用户空间拷贝到内核空间 | 每次调用poll,都需要将fd从用户空间拷贝到内核空间 | 通过内存映射(mmap),不需要进行频繁的拷贝fd,一次即可。 |
3.2 五种IO模型
| IO模型 | 阻塞状态 | 同步状态 |
|---|---|---|
| 阻塞式IO | 阻塞 | 同步 |
| 非阻塞式IO | 非阻塞 | 同步 |
| IO多路复用 | 阻塞 | 同步 |
| 信号驱动IO | 非阻塞 | 同步 |
| 异步IO | 非阻塞 | 异步 |
阻塞,非阻塞的概念区分:可以简单理解为需要做一件事能不能立即得到返回应答,如果不能立即获得返回,需要等待,那就阻塞。更倾向于是否立即应答。
同步,异步的概念区分:你总是做完一件再去做另一件,不管是否需要时间等待,这就是同步。否则就是异步。更倾向于是否可以并行做两件事。
那回过头再看上面的表格:
非阻塞式IO方面的解释:
- 非阻塞:因为用户进程能够立刻获得结果(可能是最终用户想要的数据,也可能是错误信息)。
- 同步:因为数据复制阶段总是在数据询问阶段完成后执行。
IO多路复用方面的解释:
- 阻塞:用户进程需要等待回调结果的返回。这一过程是阻塞的。
- 同步:因为数据复制阶段总是在数据询问阶段完成后执行。
信号驱动IO方面的解释:
- 非阻塞:用户进程在数据询问阶段就能够立即获得返回。
- 同步:需要等待内核发送信号,表示
fd找到了。让用户进程得到fd,再由用户进程发起请求进行数据拷贝。
异步IO方面的解释:
- 非阻塞:用户也可以立刻获得结果。
- 异步:整个数据的等待和拷贝操作都交给操作系统来完成,并不是用户,用户无需阻塞等待。
最终可以发现,针对这五种IO模型,关于异步和同步的区别无非就是:
- 同步:数据等待和拷贝过程分为两个阶段,由应用进程发起。需要发起两次。
- 异步:数据等待和拷贝操作都交给操作系统完成。应用进程发起一次请求即可。
边栏推荐
- Weekly recommended short videos: what are the functions of L2 that we often use in daily life?
- Appx code signing Guide
- Pdf document signature Guide
- .NET配置系统
- Guide de signature du Code Appx
- Enterprise practice | construction of banking operation and maintenance index system under complex business relations
- IPv4套接字地址结构
- 【学习笔记-李宏毅】GAN(生成对抗网络)全系列(一)
- 搭建物联网硬件通信技术几种方案
- Some test points about coupon test
猜你喜欢
HAL库配置通用定时器TIM触发ADC采样,然后DMA搬运到内存空间。
ORM模型--关联字段,抽象模型类
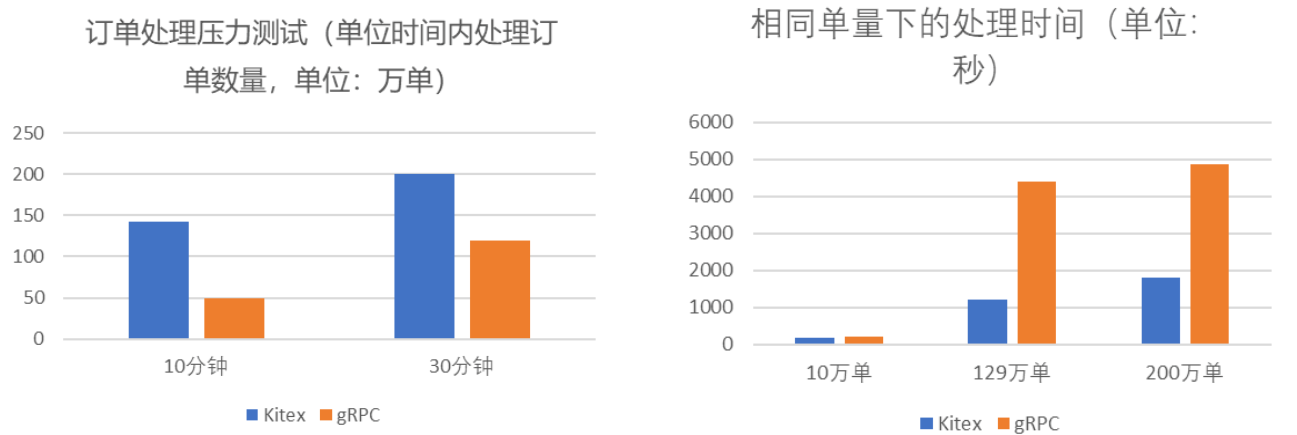
The landing practice of ByteDance kitex in SEMA e-commerce scene

Chris Lattner, père de llvm: Pourquoi reconstruire le logiciel d'infrastructure ai
mysql插入数据创建触发器填充uuid字段值
arcgis操作:dwg数据转为shp数据

Use of JSON extractor originals in JMeter
Agile course training
ORM--分组查询,聚合查询,查询集QuerySet对象特性
【acwing】789. Range of numbers (binary basis)
随机推荐
Future development blueprint of agriculture and animal husbandry -- vertical agriculture + artificial meat
request对象对请求体,请求头参数的解析
STM32产品介绍
Advanced function learning in ES6
Bean 作⽤域和⽣命周期
Introduction to uboot
Web3.0 series distributed storage IPFs
ISP、IAP、ICP、JTAG、SWD的编程特点
Apprentissage avancé des fonctions en es6
2022.7.3DAY595
conda离线创建虚拟环境
Internship log - day04
串口通讯继电器-modbus通信上位机调试软件工具项目开发案例
搭建物联网硬件通信技术几种方案
Introduction to automated testing framework
Some thoughts on the testing work in the process of R & D
Word自动生成目录的方法
CONDA creates virtual environment offline
C#记录日志方法
Weekly recommended short videos: what are the functions of L2 that we often use in daily life?