当前位置:网站首页>MongoDB优化的几点原则
MongoDB优化的几点原则
2022-07-07 11:17:00 【cui_yonghua】
基础篇(能解决工作中80%的问题):
进阶篇:
其它:
1.查询优化
确认你的查询是否充分利用到了索引,用explain命令查看一下查询执行的情况,添加必要的索引,避免扫表操作。
2.搞清热数据大小
可能你的数据集非常大,但是这并不那么重要,重要的是你的热数据集有多大,你经常访问的数据有多大(包括经常访问的数据和所有索引数据)。
使用MongoDB,你最好保证你的热数据在你机器的内存大小之下,保证内存能容纳所有热数据。
3.选择正确的文件系统
MongoDB的数据文件是采用的预分配模式,并且在Replication里面,Master和Replica Sets的非Arbiter节点都是会预先创建足够的空文件用以存储操作日志。
这些文件分配操作在一些文件系统上可能会非常慢,导致进程被Block。所以我们应该选择那些空间分配快速的文件系统。这里的结论是尽量不要用ext3,用ext4或者xfs。
4.选择合适的硬盘
这里的选择包括了对磁盘RAID的选择,也包括了磁盘与SSD的对比选择。
5.尽量少用in的方式查询
尤其是在shard上,他会让你的查询去被一个shand上跑一次, 如果逼不得已要用的话再每个shard上建索引。
优化in的方式是把in分解成一个一个的单一查询。速度会提高40-50倍
6.合理设计sharding key
增量sharding-key:适合于可划分范围的字段,比如integer、float、date类型的,查询时比较快
随机sharding-key: 适用于写操作频繁的场景,而这种情况下如果在一个shard上进行会使得这个shard负载比其他高,不够均衡,故而希望能hash查询key,将写分布在多个shard上进行,考虑复合key作为sharding key, 总的原则是查询快,尽量减少跨shard查询,balance均衡次数少。
mongodb默认是单条记录16M,尤其在使用GFS的时候,一定要注意shrading-key的设计。
不合理的sharding-key会出现,多个文档,在一个chunks上,同时,因为GFS中存贮的往往是大文件,导致mongodb在做balance的时候无法通过sharding-key来把这多个文档分开到不同的shard上, 这时候mongodb会不断报错 [conn27669] Uncaught std::exception: St9bad_alloc, terminating。最后导致mongodb倒掉。
解决办法:加大chunks大小(治标),设计合理的sharding-key(治本)。
7.mongodb可以通过profile来监控数据,进行优化。
查看当前是否开启profile功能 用命令db.getProfilingLevel() 返回level等级,值为0|1|2,
分别代表意思:0代表关闭,1代表记录慢命令,2代表全部
开启profile功能命令为 db.setProfilingLevel(level); #level等级,值同上 level为1的时候,慢命令默认值为100ms,更改为db.setProfilingLevel(level,slowms)如db.setProfilingLevel(1,50)这样就更改为50毫秒
通过db.system.profile.find() 查看当前的监控日志。
边栏推荐
- 关于 appium 如何关闭 app (已解决)
- HZOJ #235. Recursive implementation of exponential enumeration
- 学习突围2 - 关于高效学习的方法
- Pay close attention to the work of safety production and make every effort to ensure the safety of people's lives and property
- What are the benefits of ip2long?
- RecyclerView的数据刷新
- 高瓴投的澳斯康生物冲刺科创板:年营收4.5亿 丢掉与康希诺合作
- Awk of three swordsmen in text processing
- Adopt a cow to sprint A shares: it plans to raise 1.85 billion yuan, and Xu Xiaobo holds nearly 40%
- 关于 appium 启动 app 后闪退的问题 - (已解决)
猜你喜欢
高瓴投的澳斯康生物冲刺科创板:年营收4.5亿 丢掉与康希诺合作
Sed of three swordsmen in text processing
Blog recommendation | Apache pulsar cross regional replication scheme selection practice

Cinnamon Applet 入门

单片机原理期末复习笔记
Leetcode skimming: binary tree 23 (mode in binary search tree)
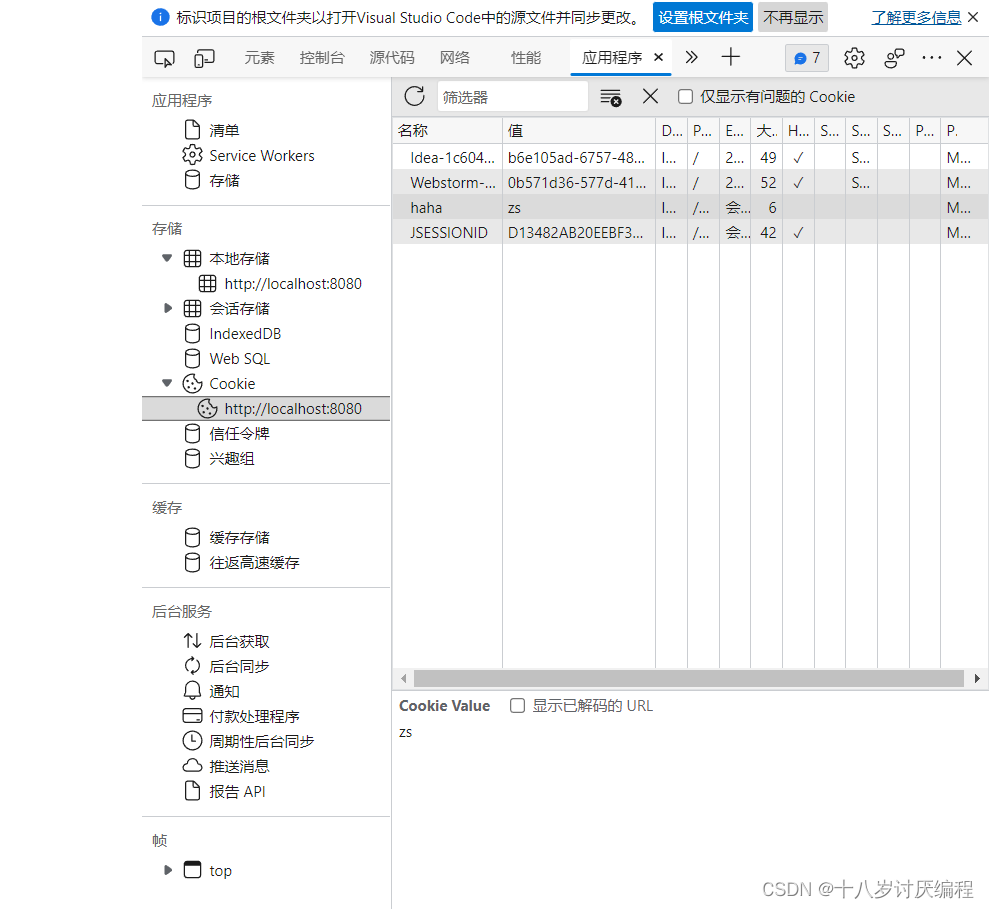
Cookie

TPG x AIDU|AI领军人才招募计划进行中!
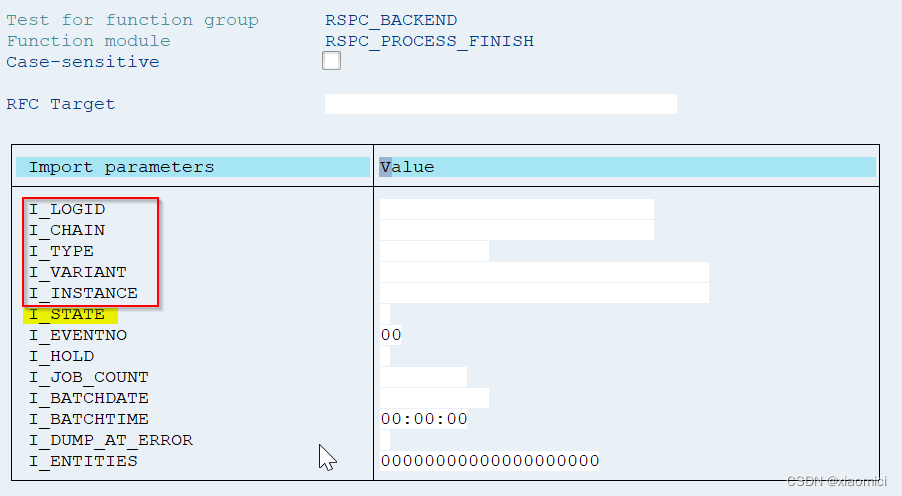
处理链中断后如何继续/子链出错removed from scheduling
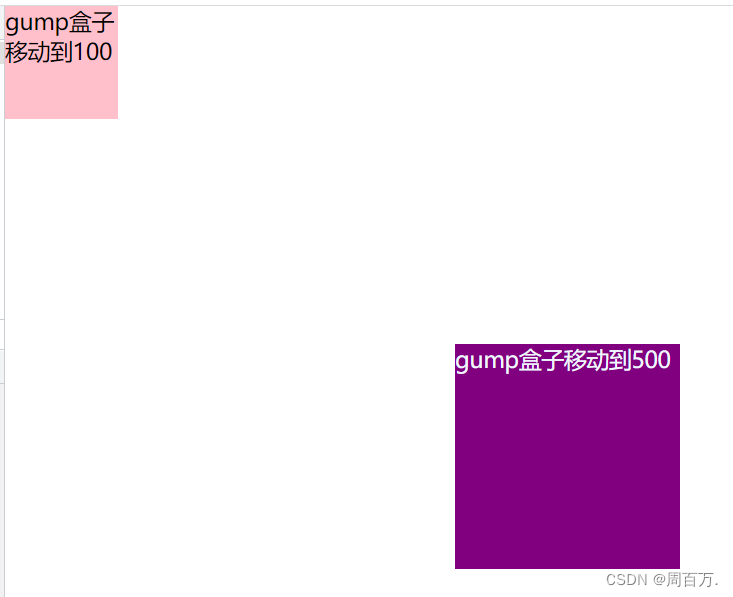
JS缓动动画原理教学(超细节)
随机推荐
【学习笔记】AGC010
[untitled]
DHCP 动态主机设置协议 分析
工具箱之 IKVM.NET 项目新进展
Lingyunguang of Dachen and Xiaomi investment is listed: the market value is 15.3 billion, and the machine is implanted into the eyes and brain
php——laravel缓存cache
.Net下极限生产力之efcore分表分库全自动化迁移CodeFirst
File operation command
Find ID value MySQL in string
Differences between MySQL storage engine MyISAM and InnoDB
服务器到服务器 (S2S) 事件 (Adjust)
PACP学习笔记三:PCAP方法说明
2022-07-07 Daily: Ian Goodfellow, the inventor of Gan, officially joined deepmind
Ogre入门尝鲜
Leetcode skimming: binary tree 27 (delete nodes in the binary search tree)
Go language learning notes - structure
【无标题】
共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf
Sample chapter of "uncover the secrets of asp.net core 6 framework" [200 pages /5 chapters]
Initialization script