当前位置:网站首页>[le plus complet du réseau] | interprétation complète de MySQL explicite
[le plus complet du réseau] | interprétation complète de MySQL explicite
2022-07-06 01:23:00 【Le bleu est le grand Dieu.】
TIPS
Cet article est basé surMySQL 8.0Compilation,Soutien théoriqueMySQL 5.0Et plus.
EXPLAINUtiliser
explainPeut être utilisé pour analyserSQLPlan de mise en œuvre.Le format est le suivant::
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | {EXPLAIN | DESCRIBE | DESC}
tbl_name [col_name | wild]
{EXPLAIN | DESCRIBE | DESC}
[explain_type]
{explainable_stmt | FOR CONNECTION connection_id}
{EXPLAIN | DESCRIBE | DESC} ANALYZE select_statement
explain_type: {
FORMAT = format_name
}
format_name: {
TRADITIONAL
| JSON
| TREE
}
explainable_stmt: {
SELECT statement
| TABLE statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement
}
|
Exemple:
1 2 3 4 5 6 7 8 9 10 11 12 | EXPLAIN format = TRADITIONAL json SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
|
Présentation des résultats :
| Champ | format=json Nom de l'heure | Sens |
|---|---|---|
| id | select_id | Identification unique de l'instruction |
| select_type | Aucune | Type de requête |
| table | table_name | Nom du tableau |
| partitions | partitions | Partitions correspondantes |
| type | access_type | Type de connexion |
| possible_keys | possible_keys | Sélection possible de l'index |
| key | key | Index effectivement sélectionné |
| key_len | key_length | Longueur de l'index |
| ref | ref | Quelle colonne de l'index est référencée |
| rows | rows | Estimer les lignes à numériser |
| filtered | filtered | Indique le pourcentage de données qui répondent aux critères de requête |
| Extra | Non. | Informations complémentaires |
Interprétation des résultats
id
Identification unique de l'instruction .Siexplain Les résultats pour idValeur, Plus le nombre est grand, plus il est exécuté en premier. ;Et pour le mêmeidOui., Cela signifie exécuter de haut en bas .
select_type
Type de requête,Il y a plusieurs valeurs:
| Type de requête | Action |
|---|---|
| SIMPLE | Simple requête(Non utiliséUNIONOu sous - Requête) |
| PRIMARY | Requête externe |
| UNION | InUNIONLa deuxième et la suivanteSELECTMarqué commeUNION.SiUNIONParFROM La Sous - requête dans la clause contient , Le premier SELECTSera marqué commeDERIVED. |
| DEPENDENT UNION | UNION La deuxième requête ou plus tard dans , Dépend des requêtes externes |
| UNION RESULT | UNIONLes résultats de |
| SUBQUERY | Première Sous - Requête SELECT |
| DEPENDENT SUBQUERY | Première Sous - Requête SELECT, Dépend des requêtes externes |
| DERIVED | Utilisé pour représenter l'inclusion dansFROM Dans la Sous - requête d'une clause SELECT,MySQLLes résultats sont exécutés Récursivement et placés dans une table temporaire.MySQL En interne, on l'appelle Derived table(Tableau dérivé), Parce que la table temporaire est dérivée de la Sous - Requête |
| DEPENDENT DERIVED | Tableau dérivé, Dépend d'autres tableaux |
| MATERIALIZED | Sous - Requête matérialisée |
| UNCACHEABLE SUBQUERY | Sous - Requête, Les résultats ne peuvent pas être mis en cache , Chaque ligne de la requête externe doit être réévaluée |
| UNCACHEABLE UNION | UNIONDeUNCACHEABLE SUBQUERY Deuxième ou dernière requête de |
table
Indique le tableau auquel cette ligne accède actuellement ,SiSQLAlias défini,Afficher l'alias de la table
partitions
La requête actuelle correspond à la partition de l'enregistrement.Pour les tables non partitionnées,Retournull
type
Type de connexion,Il y a plusieurs valeurs,Classement des performances du bon au mauvais Comme suit:
system:Le tableau n'a qu'une seule ligne(Équivalent à la table du système),system- Oui.constCas particuliers de type
const:Numérisation équivalente des requêtes pour les clés primaires ou les index uniques, Renvoie au plus une ligne de données. const La requête est très rapide, Parce qu'il ne peut être lu qu'une seule fois
eq_ref:Lorsque toutes les composantes de l'index sont utilisées,Et l'index estPRIMARY KEYOuUNIQUE NOT NULL Pour utiliser ce type,Après la performancesystemEtconst.
1 2 3 4 5 6 7 8
-- Requête associée à plusieurs tables,Une seule ligne correspond SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; -- Requête associée à plusieurs tables,Index commun,Correspondance multiligne SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
ref:Lorsque la règle du préfixe le plus à gauche de l'index est remplie,Se produit lorsque l'index n'est pas une clé primaire ou un index unique.Si vous utilisez un index qui ne correspond qu'à un petit nombre de lignes,La performance est également bonne.
1 2 3 4 5 6 7 8 9 10 11
-- Selon l'index(Clé non primaire,Index non unique),Correspond à plusieurs lignes SELECT * FROM ref_table WHERE key_column=expr; -- Requête associée à plusieurs tables,Index unique,Correspondance multiligne SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; -- Requête associée à plusieurs tables,Index commun,Correspondance multiligne SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
TIPS
Principe du préfixe le plus à gauche,Indique que l'index correspond à l'index de la manière la plus à gauche.Comme créer un index composite(column1, column2, column3),Alors,Si les critères de requête sont:
- WHERE column1 = 1、WHERE column1= 1 AND column2 = 2、WHERE column1= 1 AND column2 = 2 AND column3 = 3 Vous pouvez utiliser cet index;
- WHERE column1 = 2、WHERE column1 = 1 AND column3 = 3Impossible de faire correspondre l'index.
fulltext:Index texte complet
ref_or_null:Ce type est similaire àref,MaisMySQLRecherche supplémentaire de lignes contenantNULL. Ce type est courant pour résoudre les sous - requêtes
1 2
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;
index_merge:Ce type indique que l'optimisation de la fusion d'index est utilisée,Indique que plusieurs index sont utilisés dans une requête
unique_subquery:Ce type eteq_refSimilaire,Mais en utilisantINRequête,Et la Sous - requête est une clé primaire ou un index unique.Par exemple:
1
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery:Etunique_subquerySimilaire,Seule la Sous - requête utilise un index non unique
1
value IN (SELECT key_column FROM single_table WHERE some_expr)
range:Balayage de la portée,Une ligne indiquant que la plage spécifiée a été récupérée,Principalement utilisé pour les scans d'index limités. Les scans de portée les plus courants sont ceux avec BETWEENClause ouWHEREDans la clause>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()Opérateur égal.
1 2 3 4 5
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20; SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
index:Numérisation complète de l'index,EtALLSimilaire,C'est juste queindexC'est un balayage complet des données indexées.Lorsque la requête n'utilise qu'une partie des colonnes de l'index,Ce type de.Il y a deux scénarios qui déclenchent:
- Si l'index est l'index de superposition de la requête,Et les données de la requête d'index peuvent satisfaire toutes les données requises dans la requête,Ne scannez que l'arbre d'index.En ce moment,explainDeExtra Le résultat de la colonne estUsing index.indexGénéralement plus queALLAllez,Parce que la taille de l'index est généralement inférieure aux données du tableau.
- Rechercher les lignes de données dans l'ordre de l'index,Un balayage complet de la table a été effectué.En ce moment,explainDeExtraLe résultat de la colonne n'apparaît pasUses index.
ALL:Balayage complet de la table,Les pires performances.
possible_keys
Affiche les index disponibles pour la requête courante,Les données de cette colonne ont été créées au début du processus d'optimisation.,Par conséquent, certains index peuvent ne pas être utiles pour les processus d'optimisation ultérieurs.
key
ReprésentationMySQLIndex effectivement sélectionné
key_len
Nombre d'octets utilisés par l'index.En raison du format de stockage,Lorsque le champ est autorisé àNULLHeure,key_lenPlus grand qu'un espace non autorisé1Octets.
key_lenFormule de calcul: explainDekey_lenCalcul - yayun - La blogosphère
ref
Indique quel champ ou constante sera combiné aveckeyLes champs utilisés dans les colonnes sont comparés.
SirefC'est une fonction,La valeur utilisée est le résultat de la fonction.Pour voir quelle fonction est,Oui.EXPLAINLa déclaration est suivie d'unSHOW WARNINGDéclarations.
rows
MySQL Estimer le nombre de lignes à numériser ,Plus la valeur est petite, mieux c'est.
filtered
Indique le pourcentage de données qui répondent aux critères de requête ,Max.100.Avecrows × filteredNombre de lignes disponibles pour se connecter au tableau suivant.Par exemplerows = 1000,filtered = 50%,Le nombre de lignes connectées au tableau suivant est500.
TIPS
InMySQL 5.7Avant,Pour afficher ce champ, utilisezexplain extendedLes ordres;
MySQL.5.7Et plus,explainLa valeur par défaut affichefiltered
Extra
Afficher des informations supplémentaires sur cette requête,Les valeurs sont les suivantes::
Child of ‘table’ pushed [email protected]
Cette valeur ne sera disponible qu'àNDB ClusterEn bas..
const row not found
Par exemple, une instruction de requête SELECT … FROM tbl_name,Et la table est vide
Deleting all rows
PourDELETEDéclarations,Certains moteurs(Par exempleMyISAM)Prend en charge la suppression de toutes les données d'une manière simple et rapide,Si cette optimisation est utilisée,Cette valeur est affichée
Distinct
TrouverdistinctValeur,Après avoir trouvé la première ligne correspondante,La recherche de lignes supplémentaires pour la combinaison de lignes courante s'arrêtera
FirstMatch(tbl_name)
Demi - connexion actuellement utiliséeFirstMatchStratégie,Voir détails FirstMatch Strategy - MariaDB Knowledge Base ,Traduction semi-joinOptimisation des sous - requêtes -- FirstMatchStratégie - abce - La blogosphère
Full scan on NULL key
Une façon d'optimiser les sous - requêtes,Impossible d'accéder à l'indexnullPour les valeurs, utilisez
Impossible HAVING
HAVINGLa clause est toujoursfalse,Ne touche à aucune ligne
Impossible WHERE
WHERELa clause est toujoursfalse,Ne touche à aucune ligne
Impossible WHERE noticed after reading const tables
MySQLJ'ai lu tous lesconst(Ousystem)Tableau,Et découvrirWHERELa clause est toujoursfalse
LooseScan(m..n)
Demi - connexion actuellement utiliséeLooseScanStratégie,Voir détails LooseScan Strategy - MariaDB Knowledge Base ,Traduction MySQL5.6 Semi join Stratégie d'optimisation LooseScan Stratégie |
No matching min/max row
Il n'y a rien qui puisse satisfaire, par exemple, SELECT MIN(…) FROM … WHERE condition DansconditionOui.
no matching row in const table
Pour les requêtes associées,Il y a une table vide,Ou aucune ligne ne peut satisfaire aux critères d'index uniques
No matching rows after partition pruning
PourDELETEOuUPDATEDéclarations,L'optimiseur estpartition pruning(Taille de la zone)Après,Impossible de trouverdeleteOuupdateLe contenu de
No tables used
Quand cette requête n'a pasFROMClause ou avoirFROM DUALApparaît dans la clause.Par exemple:explain select 1
Not exists
MySQLOui.LEFT JOINOptimisation,Après avoir trouvé la correspondanceLEFT JOINAprès la ligne,Plus de lignes dans ce tableau ne seront pas vérifiées pour la combinaison de lignes précédente.Par exemple:
1 2
SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
Hypothèsest2.idDéfini comme
NOT NULL,En ce moment,MySQLVa scannert1,Et utilisert1.idRecherche de valeur pourt2Lignes en. SiMySQLInt2 Une ligne correspondante a été trouvée dans ,Il saurat2.idJamais pourNULL,Et ne scanne past2A le mêmeidLes autres lignes de la valeur.C'est - à - dire,Pourt1Chaque ligne,MySQLIl suffit det2Effectuer une seule recherche dans,Sans penser àt2Nombre de lignes effectivement appariées dans.InMySQL 8.0.17Et plus,Si cette invite apparaît,Peut également être représenté comme NOT IN (subquery) Ou NOT EXISTS (subquery) DeWHERELa condition a été convertie en anti - connexion à l'intérieur.Ceci supprime la Sous - requête et place sa table dans le plan de requête de haut niveau,Pour améliorer les frais généraux de la requête.En combinant les demi - Connexions et les anti - Connexions,L'optimiseur est plus libre de réorganiser les tables dans le plan d'exécution,Dans certains cas,Pour accélérer la requête.Vous pouvez le faire enEXPLAINLa déclaration est suivie d'unSHOW WARNINGDéclarations, Et analyser les résultats MessageColonnes, Pour voir quand une transformation anti - join a été effectuée sur la requête .
Note
L'Association de deux tableaux ne renvoie que les données du tableau principal,Et ne renvoie que les données de la table primaire et de la table enfant qui ne sont pas associées, Cette connexion est appelée connexion inverse
Plan isn’t ready yet
UtiliséEXPLAIN FOR CONNECTION,Lorsque l'optimiseur n'a pas terminé la création d'un plan d'exécution pour une instruction exécutée dans la connexion spécifiée, Cette valeur apparaîtra.
Range checked for each record (index map: N)
MySQLAucun index approprié n'a été trouvé pour être utilisé,Mais vérifiez si vous pouvez utiliserrangeOuindex_mergePour récupérer les lignes,Cette invite apparaîtra.index map NNuméro de l'index de1C'est parti.,Selon le tableauSHOW INDEXLe même ordre est indiqué. Valeur de cartographie de l'indexN Est une valeur de masque de bits indiquant quels index sont candidats . Par exemple0x19(Binaire11001)La valeur de signifie que l'index sera considéré1、4Et5.
Exemple:Dans l'exemple suivant,name- Oui.varcharType, Mais la condition donne le type entier , Impliquant une transformation implicite .
Dans la figuret2Et l'index n'est pas utilisé, C'est parce que je vais t2Moyennename Trier les champs à la place utf8_bin La collation des champs liés qui en résulte ne correspond pas .1 2 3
explain select a.* from t1 a left join t2 b on t1.name = t2.name where t2.name = 2;
Résultats:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t2 | NULL | ALL | idx_name | NULL | NULL | NULL | 9 | 11.11 | Using where |
| 1 | SIMPLE | t1 | NULL | ALL | idx_name | NULL | NULL | NULL | 5 | 11.11 | Range checked for each record (index map: 0x8) |
Recursive
Une requête récursive apparaît .Voir détails “WITH (Common Table Expressions)”
Rematerialize
Très peu utilisé, Utiliser comme suit: SQLHeure,Il montreraRematerialize
1 2 3 4 5 6
SELECT ... FROM t, LATERAL (derived table that refers to t) AS dt ...
Scanned N databases
Indique qu'il est en cours de traitement INFORMATION_SCHEMA Lors de la requête du tableau , Plusieurs répertoires ont été scannés ,NLa valeur peut être0,1Ouall.Voir détails “Optimizing INFORMATION_SCHEMA Queries”
Select tables optimized away
Optimizer OK :①Retour maximum1D'accord;② Données à produire pour cette ligne , Pour lire un ensemble déterminé de lignes , Cette invite apparaît lorsque . En général, lorsque certaines fonctions d'agrégation sont utilisées pour accéder à un champ où un index existe , L'optimiseur est affiché directement à la ligne de données désirée par index une fois que la requête complète est terminée ,Par exemple:SQL.
1 2 3
explain select min(id) from t1;
Skip_open_table, Open_frm_only, Open_full_table
Ces valeurs représentent les valeurs applicables INFORMATION_SCHEMA Optimisation de l'ouverture des fichiers pour les requêtes de table ;
- Skip_open_table: Pas besoin d'ouvrir le fichier table , L'information a été obtenue en scannant le dictionnaire de données
- Open_frm_only: Il suffit de lire le dictionnaire de données pour obtenir les informations du tableau
- Open_full_table: Recherche d'information non optimisée . Les informations du tableau doivent être lues à partir du dictionnaire de données et du fichier du tableau
Start temporary, End temporary
Indique l'utilisation temporaire de la table Duplicate WeedoutStratégie,Voir détails DuplicateWeedout Strategy - MariaDB Knowledge Base ,Traduction semi-joinOptimisation des sous - requêtes -- Duplicate WeedoutStratégie - abce - La blogosphère
unique row not found
Pour la forme SELECT … FROM tbl_name Demandes de renseignements,Mais aucune ligne ne répond aux critères d'un index unique ou d'une requête de clé primaire
Using filesort
QuandQuery Inclus dans ORDER BY Fonctionnement,Et quand l'opération de tri ne peut pas être effectuée avec l'index,MySQL Query Optimizer Il faut choisir l'algorithme de tri approprié pour réaliser.Trier à partir de la mémoire lorsque les données sont faibles, Sinon, triez à partir du disque .Explain Ne s'affichera pas pour dire au client quel tri utiliser .Explication officielle:“MySQLUne livraison supplémentaire est nécessaire,Pour trouver comment récupérer les lignes dans l'ordre de tri.En parcourant toutes les lignes par type de jointure et en faisant correspondre toutes les lignesWHERELa ligne de la clause enregistre le mot - clé de tri et le pointeur de ligne pour compléter le tri.Puis les mots clés sont triés,Et récupère les lignes dans l'ordre de tri”
Using index
Extraire les informations de colonne du tableau en utilisant uniquement les informations de l'arbre d'index,Sans avoir à faire d'autres recherches pour lire les lignes réelles.Lorsque la requête n'utilise que des colonnes appartenant à un seul Index,Cette politique peut être utilisée.Par exemple:
1
explain SELECT id FROM t
Using index condition
Indique que l'index est d'abord filtré par Condition,Trouver toutes les lignes de données qui répondent aux critères d'indexation après avoir filtré l'index,Ensuite, utilisez WHERE D'autres conditions dans la clause filtrent ces lignes de données.De cette façon,Sauf si c'est nécessaire,Sinon, les informations de l'index peuvent être retardées“Poussez.”Lire les données pour toute la ligne.Voir détails “Index Condition Pushdown Optimization” .Par exemple:
TIPS
MySQLDivisé.ServerCouche et couche moteur,La poussée vers le bas signifie que la demande est envoyée au niveau du moteur pour traitement.
Comprendre cette fonctionnalité , Peut être créé INDEX (zipcode, lastname, firstname), Et les instructions suivantes sont utilisées respectivement: ,
1 2
SET optimizer_switch = 'index_condition_pushdown=off'; SET optimizer_switch = 'index_condition_pushdown=on';
Pousser avec ou sans index ,Et comparer:
1 2 3 4
explain SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%etrunia%' AND address LIKE '%Main Street%';
Résultats de la mise en œuvre.
index condition pushdownDeMySQL 5.6Soutien initial,- Oui.MySQL Mécanismes d'optimisation pour des scénarios spécifiques ,Si ça vous intéresse, regardez. MySQL Pousser vers le bas dans l'état de l'index Index Condition Pushdown_ Le blog technique de Li rulei _51CTOBlogs
Using index for group-by
Accès aux données et Using index C'est pareil,Il suffit de lire l'index,QuandQuery Utilisé dansGROUP BYOuDISTINCT Clause,Si les champs groupés sont également dans l'index,ExtraLe message sera Using index for group-by.Voir détails “GROUP BY Optimization”
1 2
-- nameLes champs sont indexés explain SELECT name FROM t1 group by name
Using index for skip scan
Indique l'utilisationSkip Scan.Voir détails Skip Scan Range Access Method
Using join buffer (Block Nested Loop), Using join buffer (Batched Key Access)
UtiliserBlock Nested LoopOuBatched Key AccessAmélioration de l'algorithmejoinPerformance.Voir détails 【mysql】À propos deICP、MRR、BKACaractéristiques équivalentes - Pas de traces sur la neigeSS - La blogosphère
Using MRR
UtiliséMulti-Range ReadOptimiser la stratégie.Voir détails “Multi-Range Read Optimization”
Using sort_union(…), Using union(…), Using intersect(…)
Ces instructions indiquent comment la numérisation de l'index est fusionnée enindex_mergeType de connexion.Voir détails “Index Merge Optimization” .
Using temporary
Pour résoudre la requête,MySQLVous devez créer une table temporaire pour enregistrer les résultats.Si la requête contient des colonnes différentesGROUP BYEt ORDER BYClause,Ça arrive souvent.
1 2
-- namePas d'index explain SELECT name FROM t1 group by name
Using where
Si on ne lit pas toutes les données du tableau,Ou peut - être qu'il n'est pas possible d'obtenir toutes les données nécessaires simplement par index,Et il y aurausing whereInformation
1
explain SELECT * FROM t1 where id > 5
Using where with pushed condition
Uniquement pourNDB
Zero limit
La requête a unlimit 0Clause,Aucune ligne ne peut être sélectionnée
1
explain SELECT name FROM resource_template limit 0
ExtensibleEXPLAIN
EXPLAINDes informations supplémentaires peuvent être générées,Disponible enEXPLAINSuivi d'une déclarationSHOW WARNINGInstruction afficher les informations étendues.
TIPS
- InMySQL 8.0.12Et plus,Les informations étendues sont disponibles pourSELECT、DELETE、INSERT、REPLACE、UPDATEDéclarations;InMySQL 8.0.12Avant,Les informations étendues ne s'appliquent qu'àSELECTDéclarations;
- InMySQL 5.6Et plus tôt,À utiliserEXPLAIN EXTENDED xxxDéclarations;Et deMySQL 5.7C'est parti.,Pas besoin d'ajouterEXTENDEDMots clés.
Exemple d'utilisation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | mysql> EXPLAIN
SELECT t1.a, t1.a IN (SELECT t2.a FROM t2) FROM t1\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t1
type: index
possible_keys: NULL
key: PRIMARY
key_len: 4
ref: NULL
rows: 4
filtered: 100.00
Extra: Using index
*************************** 2. row ***************************
id: 2
select_type: SUBQUERY
table: t2
type: index
possible_keys: a
key: a
key_len: 5
ref: NULL
rows: 3
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `test`.`t1`.`a` AS `a`,
<in_optimizer>(`test`.`t1`.`a`,`test`.`t1`.`a` in
( <materialize> (/* select#2 */ select `test`.`t2`.`a`
from `test`.`t2` where 1 having 1 ),
<primary_index_lookup>(`test`.`t1`.`a` in
<temporary table> on <auto_key>
where ((`test`.`t1`.`a` = `materialized-subquery`.`a`))))) AS `t1.a
IN (SELECT t2.a FROM t2)` from `test`.`t1`
1 row in set (0.00 sec)
|
Parce queSHOW WARNINGLe résultat n'est pas nécessairement valableSQL,Et pas nécessairement capable d'exécuter(Parce qu'il contient beaucoup de marques spéciales). Les valeurs des étiquettes spéciales sont les suivantes: :
<auto_key>Tableau temporaire généré automatiquementkey
<cache>(expr)Expression(Par exemple, sous - Requête scalaire)Une fois.,Et les valeurs sont stockées en mémoire pour une utilisation ultérieure.Pour les résultats avec plusieurs valeurs, Des tables temporaires peuvent être créées ,Vous verrez
<temporary table>Les mots de<exists>(query fragment)Sous - Requête convertie en
EXISTS<in_optimizer>(query fragment)C'est un objet d'optimisation interne,Ça n'a aucun sens pour l'utilisateur
<index_lookup>(query fragment)Utiliser la recherche d'index pour traiter les fragments de requête,Pour trouver des lignes qualifiées
<if>(condition, expr1, expr2)Si la condition esttrue,Prends - le.expr1,Sinon, prenez - le.expr2
<is_not_null_test>(expr)L'expression de validation n'est pasNULLTest
<materialize>(query fragment)Mise en œuvre avec des sous - Requêtes
materialized-subquery.col_nameDans le tableau provisoire physico - chimique internecol_nameRéférences,Pour enregistrer les résultats des sous - Requêtes
<primary_index_lookup>(query fragment)Utilisez la clé primaire pour traiter les fragments de requête,Pour trouver des lignes qualifiées
<ref_null_helper>(expr)C'est un objet d'optimisation interne,Ça n'a aucun sens pour l'utilisateur
/* select#N */ select_stmtSELECTAvec desEXPLAINProduits en coursid=NLa ligne associée à
outer_tables semi join (inner_tables)Opération de demi - connexion.inner_tables Afficher les tableaux non tirés .Voir détails “Optimizing Subqueries, Derived Tables, and View References with Semijoin Transformations”
<temporary table>Indique qu'une table temporaire interne a été créée et que les résultats intermédiaires ont été mis en cache
Quand certaines tables sont constOusystemType, Les expressions impliquées dans les colonnes de ces tableaux seront évaluées par l'optimiseur le plus tôt possible , Et ne fait pas partie de l'énoncé affiché .Mais,Lorsqu'il est utiliséFORMAT=JSONHeure,Certainsconst L'accès au tableau sera affiché comme suit: ref.
Estimer la performance de la requête
Dans la plupart des cas,Vous pouvez estimer la performance de la requête en calculant le nombre de recherches sur le disque.Pour les tableaux plus petits,Les lignes se trouvent généralement dans une recherche sur disque(Parce que l'index peut déjà être mis en cache),Et pour les tables plus grandes,Vous pouvez utiliserB-treeIndex pour l'estimation:Combien de recherches avez - vous besoin pour trouver la ligne:log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1
InMySQLMoyenne,index_block_lengthEn général.1024Octets,Les pointeurs de données sont généralement4Octets.Par exemple,,Il y a un500,000Tableau,key- Oui.3Octets,Donc, selon la formule, log(500,000)/log(1024/3*2/(3+4)) + 1 = 4 Recherche.
Cet index nécessitera500,000 * 7 * 3/2 = 5.2MBEspace de stockage pour(Supposons que le taux de remplissage d'un cache d'index typique soit2/3),Pour que vous puissiez stocker plus d'index en mémoire,.Peut - être qu'il suffit d'un ou deux appels pour trouver la ligne désirée.
Mais,Pour les opérations d'écriture,Vous avez besoin de quatre demandes de recherche pour trouver où placer les nouvelles valeurs d'index,Et il faut souvent2Recherche pour mettre à jour l'index et l'écrire en ligne.
La discussion précédente ne signifie pas que votre performance d'application sera due àlog NEt la descente lente.Tant que le contenu estOSOuMySQLCache du serveur,Au fur et à mesure que la table grandit,Ça ralentit un peu..Après que la quantité de données est devenue trop grande pour être mise en cache,Ça va ralentir.,Jusqu'à ce que votre application soit limitée par la recherche sur disque(Selonlog NCroissance).Pour éviter cela,Peut augmenter en fonction de la croissance des donnéeskeyDe.PourMyISAMTableau,keyLa taille du cache pourkey_buffer_sizeContrôle des variables du système pour,
边栏推荐
- Logstash clear sincedb_ Path upload records and retransmit log data
- ORA-00030
- 037 PHP login, registration, message, personal Center Design
- Interview must brush algorithm top101 backtracking article top34
- 2022 Guangxi Autonomous Region secondary vocational group "Cyberspace Security" competition and its analysis (super detailed)
- Modify the ssh server access port number
- MATLB|实时机会约束决策及其在电力系统中的应用
- Yii console method call, Yii console scheduled task
- internship:项目代码所涉及陌生注解及其作用
- Dedecms plug-in free SEO plug-in summary
猜你喜欢

一图看懂!为什么学校教了你Coding但还是不会的原因...
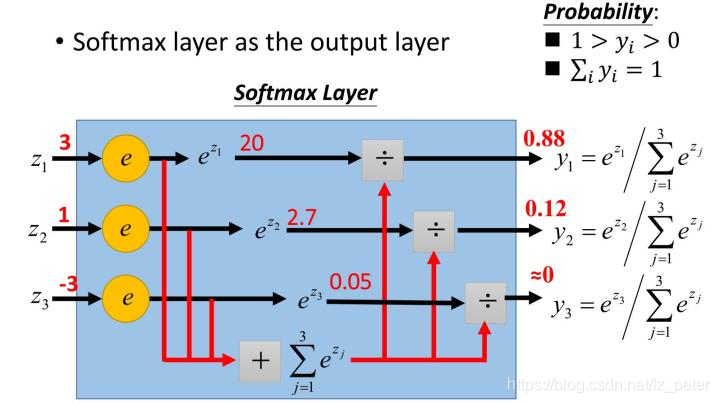
Opinions on softmax function
Four dimensional matrix, flip (including mirror image), rotation, world coordinates and local coordinates

激动人心,2022开放原子全球开源峰会报名火热开启
![Cf:h. maximum and [bit operation practice + K operations + maximum and]](/img/c2/9e58f18eec2ff92e164d8d156629cf.png)
Cf:h. maximum and [bit operation practice + K operations + maximum and]

282. Stone consolidation (interval DP)
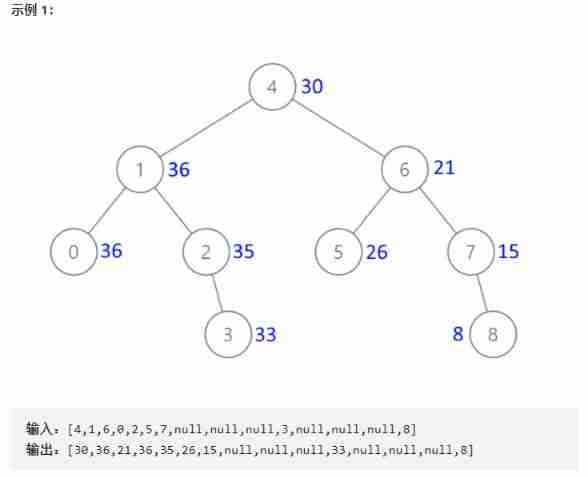
Convert binary search tree into cumulative tree (reverse middle order traversal)
Who knows how to modify the data type accuracy of the columns in the database table of Damon
Finding the nearest common ancestor of binary search tree by recursion
JVM_ 15_ Concepts related to garbage collection
随机推荐
IP storage and query in MySQL
Dedecms plug-in free SEO plug-in summary
Logstash clear sincedb_ Path upload records and retransmit log data
Idea sets the default line break for global newly created files
DOM introduction
About error 2003 (HY000): can't connect to MySQL server on 'localhost' (10061)
2022年广西自治区中职组“网络空间安全”赛题及赛题解析(超详细)
Paging of a scratch (page turning processing)
记一个 @nestjs/typeorm^8.1.4 版本不能获取.env选项问题
ThreeDPoseTracker项目解析
3D模型格式汇总
Leetcode 剑指 Offer 59 - II. 队列的最大值
Ubantu check cudnn and CUDA versions
Unity VR resource flash surface in scene
Mathematical modeling learning from scratch (2): Tools
MATLB|实时机会约束决策及其在电力系统中的应用
What is weak reference? What are the weak reference data types in ES6? What are weak references in JS?
MATLB | real time opportunity constrained decision making and its application in power system
2022 Guangxi Autonomous Region secondary vocational group "Cyberspace Security" competition and its analysis (super detailed)
What is the most suitable book for programmers to engage in open source?