当前位置:网站首页>Crawler series (9): item+pipeline data storage
Crawler series (9): item+pipeline data storage
2022-07-06 15:20:00 【Jane said Python】

One 、 Write it at the front
It hasn't been updated for a long time , Almost half a month , Few readers rush to update , So I dragged myself , Try every means to find a way out for official account , It's really a little lost , No more nonsense .
Today is the third day of the reptile series 9 piece , Last one Scrapy System crawl Bole online We have used Scrapy Get the basic data of all articles on Bole online website , But we didn't do the storage operation , This article , Let's talk about how to use Scrapy Framework knowledge is stored –Item Do data structure +Pipeline Operating the database .
Two 、 You have to know Knowledge
1. English words involved in this article
1. item
Britain [ˈaɪtəm] beautiful [ˈaɪtəm]
n. project ; strip , Clause ; a ; A commodity ( Or something )
adv. also , ditto
2.crawl
Britain [krɔ:l] beautiful [krɔl]
vi. crawl ; Move slowly ; Fawn on
n. Crawl slowly ;〈 Beautiful slang 〉 dance , Freestyle swimming ; fish culture ( turtle ) pool
3.pipeline
Britain [ˈpaɪplaɪn] beautiful [ˈpaɪpˌlaɪn]
n. The Conduit ; petroleum pipeline ; channel , Delivery route
vt.( Through pipes ) transport , Pass on ; by … Install piping
4.meta
Britain ['metə] beautiful ['metə]
abbr.(Greek=after or beyond) ( Greek ) stay … After or beyond ;[ dialectics ] Metalanguage
2.Item effect
Item It is mainly used to define the data structure of crawling , Specify your own fields to store data , Unified treatment , establish Item Need to inherit scrapy.Item class , And the definition type is scrapy.Field, Do not distinguish between data types , The data type depends on the data type of the original data at the time of assignment , Its usage is similar to that of a dictionary .
3.Pipeline effect
When Item stay Spider After being collected in , It will be delivered to Item Pipeline,Pipeline The main function is to return Of items Write to the database 、 File and other persistence modules .
4.Scrapy in Request Functional mate Parameter function
Request in meta The function of parameters is to pass information to the next function , The use process can be understood as assigning the information that needs to be transferred to this is called meta The variable of , but meta Only accept assignments of dictionary types , Therefore, the information to be transmitted should be changed into " Dictionaries ” In the form of , If you want to take out... In the next function value, Just get the of the last function meta[key] that will do .
3、 ... and 、 Look at the code , Learn while knocking and remember Scrapy Item and Pipeline application
1. Current project directory
2. Previous review
It's really the last article in this series (Scrapy System crawl Bole online ) It's too far away from now , Simply remind you what we did in the last article :
1. Batch 、 Turn the page and crawl
2. The basic introduction of data has been crawled , See the data sheet below
| Chinese name of variable | Variable name | Value type |
|---|---|---|
| Article title | title | str |
| Release date | create_time | str |
| The article classification | article_type | str |
| Number of likes | praise_number | int |
| Number of collections | collection_number | int |
| comments | comment_number | int |
3. stay Item.py Create a new one in JobboleArticleItem class , Used to store article information
class JobboleArticleItem(scrapy.Item): front_img = scrapy.Field() # Cover image title = scrapy.Field() # title create_time = scrapy.Field() # Release time url = scrapy.Field() # The current page url article_type =scrapy.Field() # The article classification praise_number = scrapy.Field() # Number of likes collection_number = scrapy.Field() # Number of collections comment_number = scrapy.Field() # comments 4. Add article cover image to get
(1) Page analysis 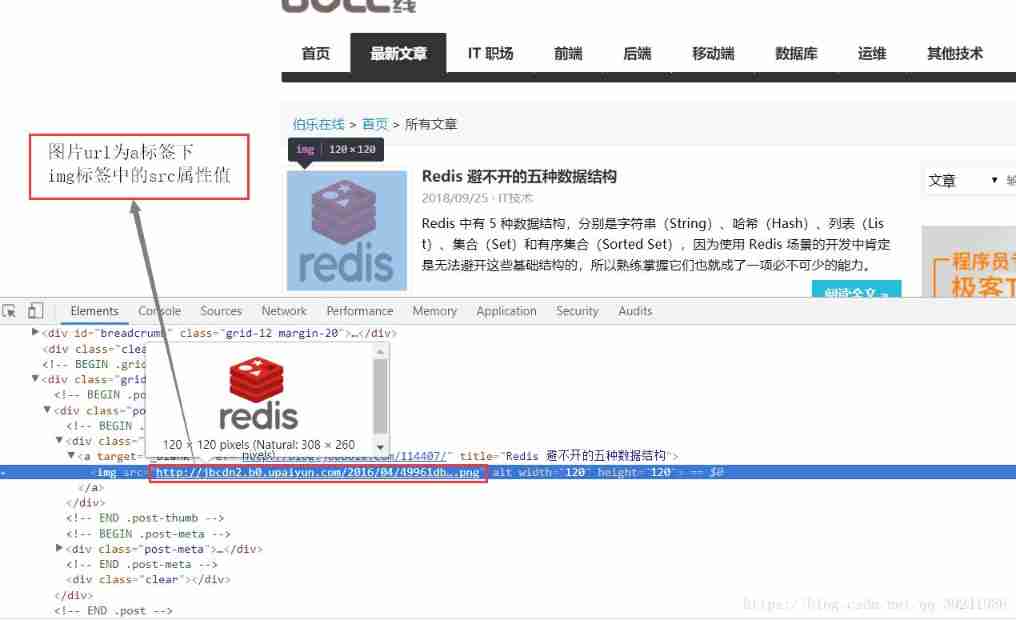
(2)jobbole.py Revision in China parse function
We go through Request Functional mate Parameter passed to image_url,
def parse(self, response): # 1. Get a single page a Label content , return Selector object post_urls = response.xpath('//*[@id="archive"]/div/div[1]/a') # 2. Access to the article url、 Cover image url、 Download page content and pictures for post_node in post_urls: # 2.1 Get a single page article url image_url = post_node.css("img::attr(src)").extract_first("") # 2.2 Get a single page article url post_url = post_node.css("::attr(href)").extract_first("") # 2.3 Submit for download yield Request(url= parse.urljoin(response.url,post_url),meta={
"front_img":image_url},callback= self.parse_detail) # 3. Get flip page url And turn the page to download next_url = response.css(".next::attr(href)").extract() if next_url != []: next_url = next_url[0] yield Request(url= parse.urljoin(response.url,next_url),callback= self.parse) (3)Debug debugging 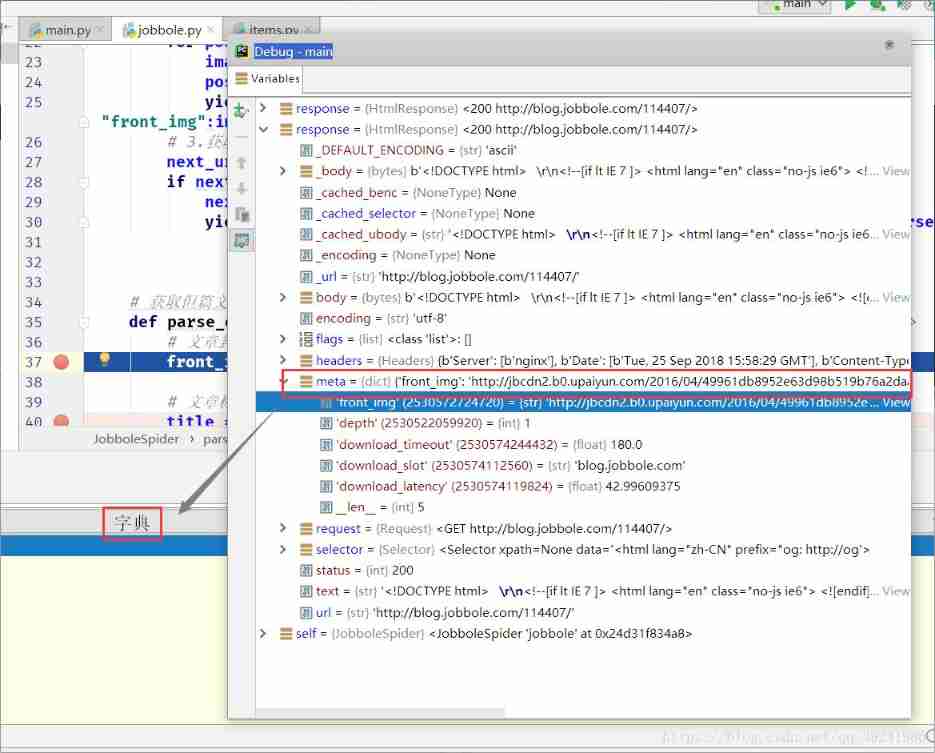
Debug As a result, we can see ,mate The value of succeeds with response The incoming to parse_detail Function , Then we can be in parse_detail Function to obtain front_img.
(4) completion parse_detail function code
# Initialize a item object article_item = JobboleArticleItem() # Article cover front_img = response.mate.get("front_img","") · · · # Data stored in Item in article_item['title'] = title article_item['create_time'] = create_time article_item['article_type'] = article_type article_item['praise_number'] = praise_number article_item['collection_number'] = collection_number article_item['comment_number'] = comment_number article_item['front_img'] = front_img article_item['url'] = response.url # take item Pass on to Pipeline in yield article_item thus Item Relevant code functions are written , We are right behind Pipeline To store actual data .
(5) Activate Pipeline
modify setting.py, Activate Pipeline
stay setting.py Found under file No 67-69 That's ok , Just remove the comment .( Or directly Ctrl+F Search for ITEM_PIPELINES, Find the appropriate location , Just remove the comment )
ITEM_PIPELINES = {
key : value } key : Express pipeline Classpath defined in value : Express this pipeline Priority of execution , value The smaller the value. , from jobbole.py Passed To the Item The more you enter this Pipeline. 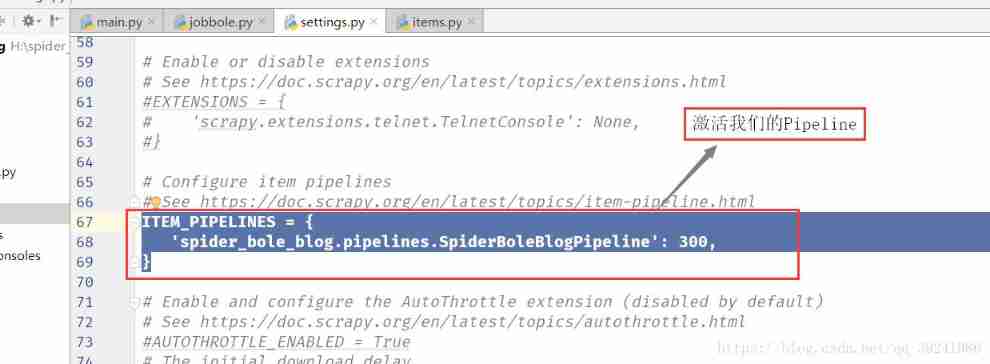
We activate the above operation Pipeline, Next we can Debug once , Look at the effect :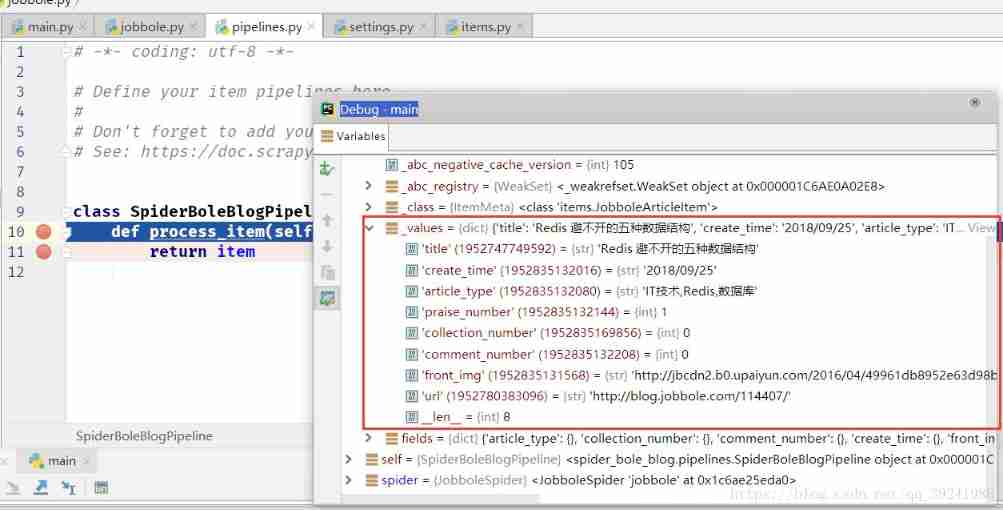
Sure enough ,Debug after Item Into Pipeline, Later we can process the data 、 Store the data .
(6) stay Pipeline Data storage operation in (MySql)
- Create a table
CREATE TABLE `bole_db`.`article` ( `id` INT UNSIGNED NOT NULL AUTO_INCREMENT, `title` VARCHAR(100) NULL, `create_time` VARCHAR(45) NULL, `article_type` VARCHAR(50) NULL, `praise_number` INT NULL, `collection_number` INT NULL, `comment_number` INT NULL, `url` VARCHAR(100) NULL, `front_img` VARCHAR(150) NULL, PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 COMMENT = ' Bole online article information '; - Store the data
stay Pipelien Create a database operation class in , And configure to setting in .pipeline.pyin :
class MysqlPipeline(object): def __init__(self): # Database connection self.conn = pymysql.connect(host="localhost", port=3306, user="root", password="root", charset="utf8", database="bole_db") self.cur = self.conn.cursor() # insert data def sql_insert(self,sql): self.cur.execute(sql) self.conn.commit() def process_item(self, item, spider): # Deposit in mysql database sql_word = "insert into article (title,create_time,article_type,praise_number,collection_number,comment_number,url,front_img) values ('{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}')".format(item["title"],item["create_time"],item["article_type"],item["praise_number"],item["collection_number"],item["comment_number"],item["url"],item["front_img"]) self.sql_insert(sql_word) return item setting.py in :
# The first 67 OK, let's start ITEM_PIPELINES = {
'spider_bole_blog.pipelines.SpiderBoleBlogPipeline': 300, 'spider_bole_blog.pipelines.MysqlPipeline':100 } - Running results
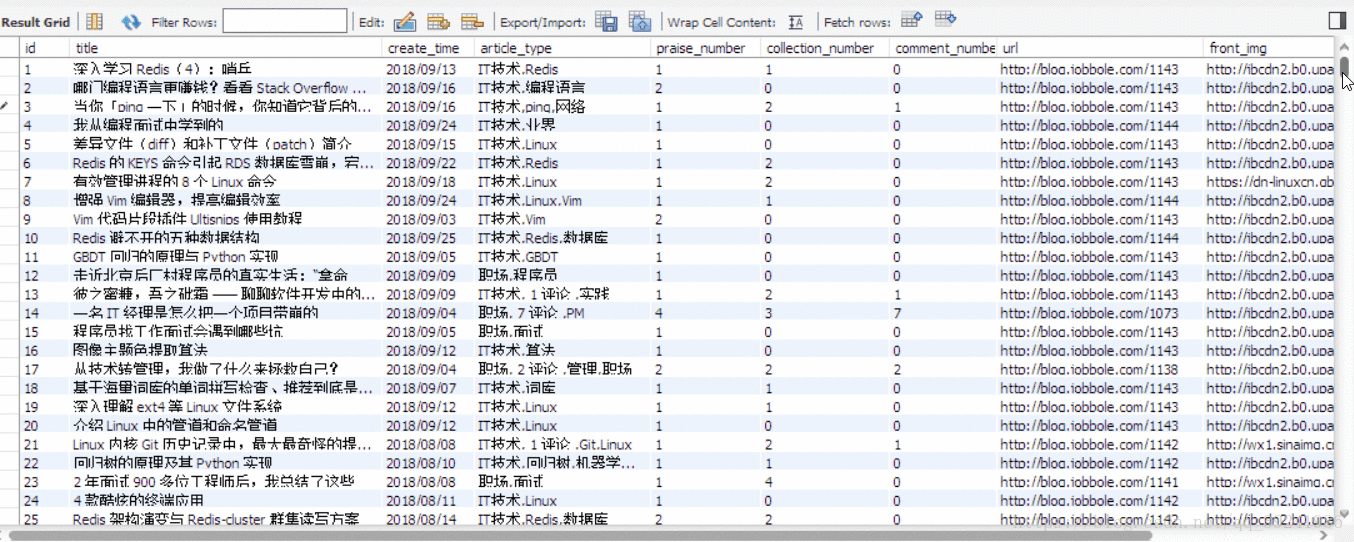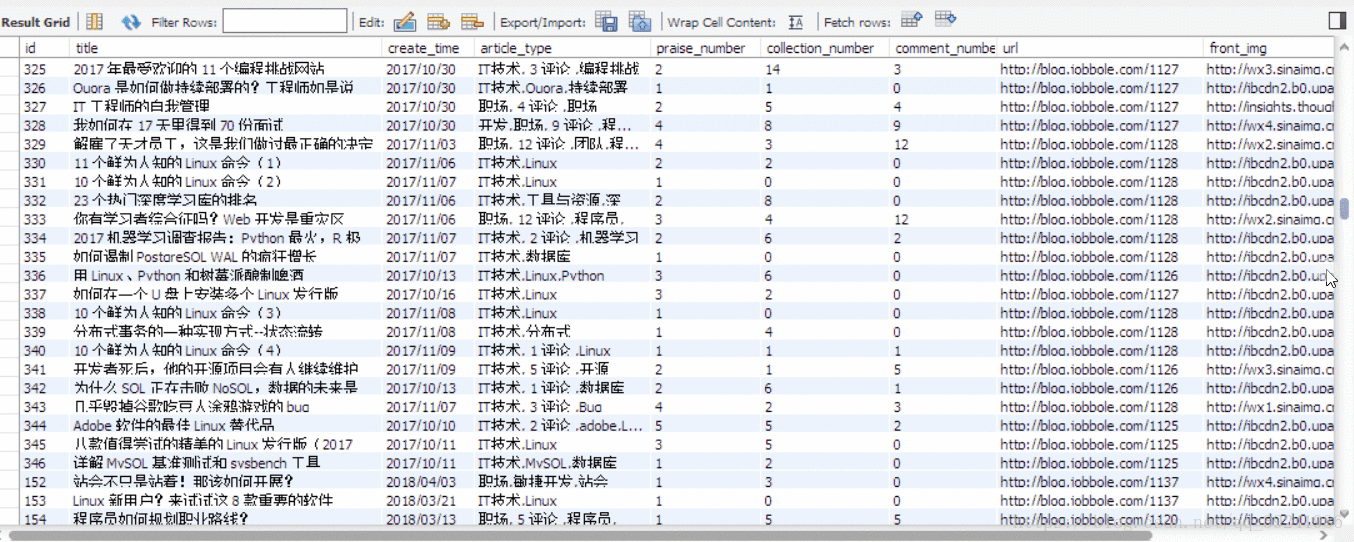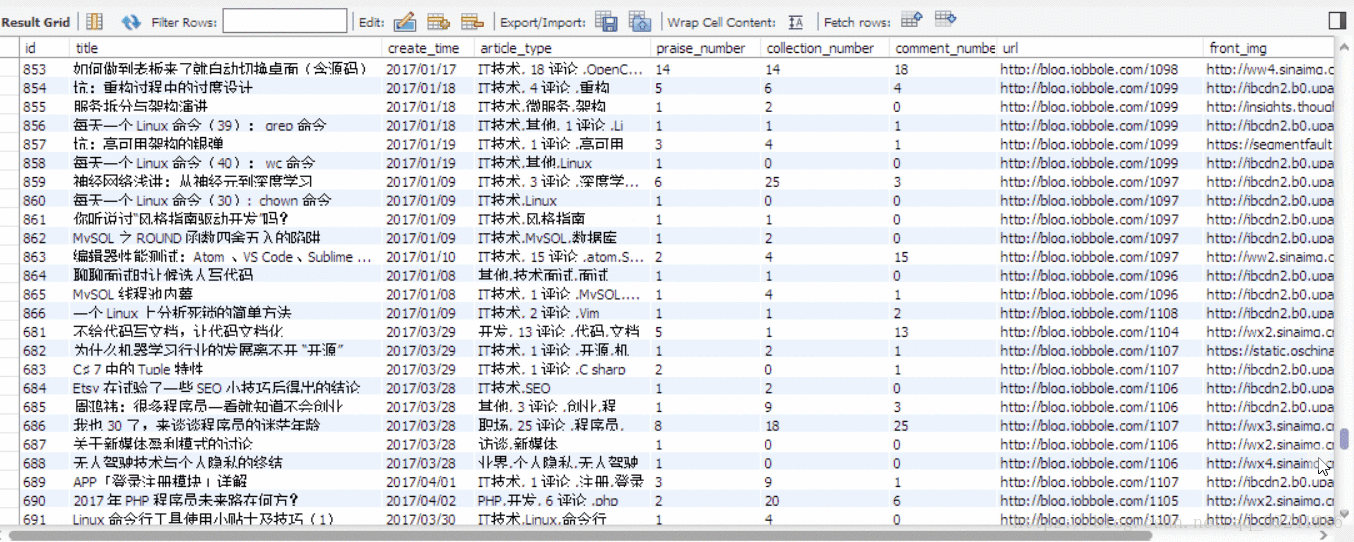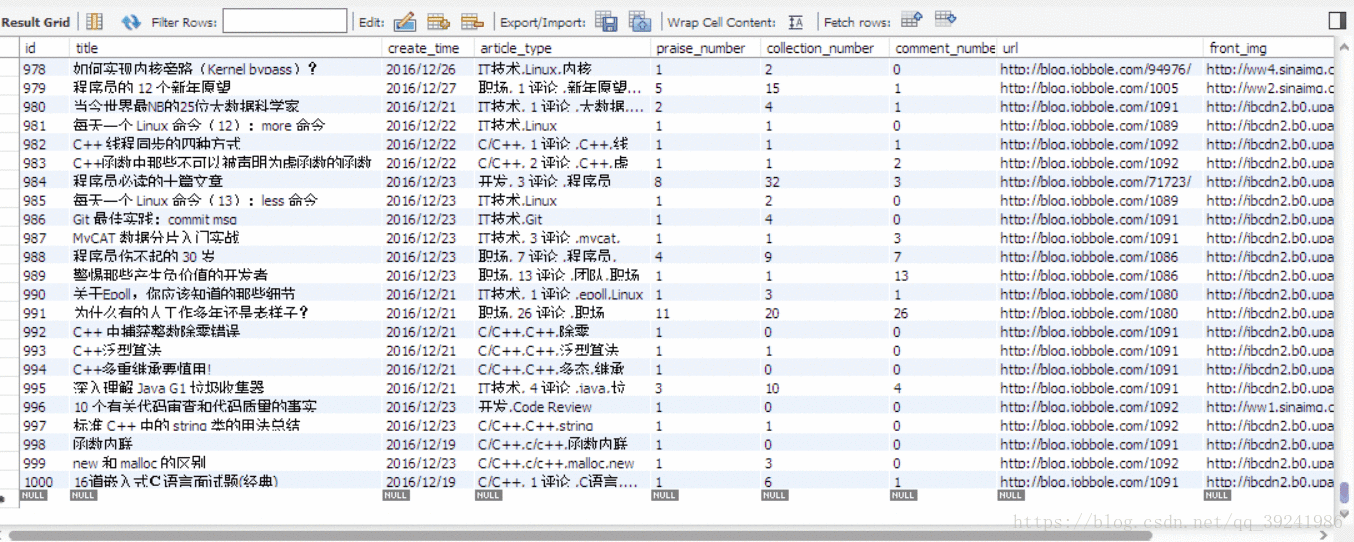
I just ran 1 minute , Just climb down and store 1000 Data , And it hasn't been crawled back , It can be seen that Scrapy The power of the framework .
Four 、 an account of happenings after the event being told
This series has not been updated for a long time , Let me review what I said before
Scrapy Learning column
边栏推荐
- How to change XML attribute - how to change XML attribute
- UCORE lab1 system software startup process experimental report
- MySQL数据库(一)
- Brief introduction to libevent
- Cc36 different subsequences
- Threads et pools de threads
- Introduction to safety testing
- Thinking about three cups of tea
- Interface test interview questions and reference answers, easy to grasp the interviewer
- The minimum sum of the last four digits of the split digit of leetcode simple problem
猜你喜欢

Stc-b learning board buzzer plays music

Sorting odd and even subscripts respectively for leetcode simple problem
ucore lab5
ucore Lab 1 系统软件启动过程
What are the software testing methods? Show you something different
软件测试工作太忙没时间学习怎么办?
想跳槽?面试软件测试需要掌握的7个技能你知道吗
CSAPP Shell Lab 实验报告
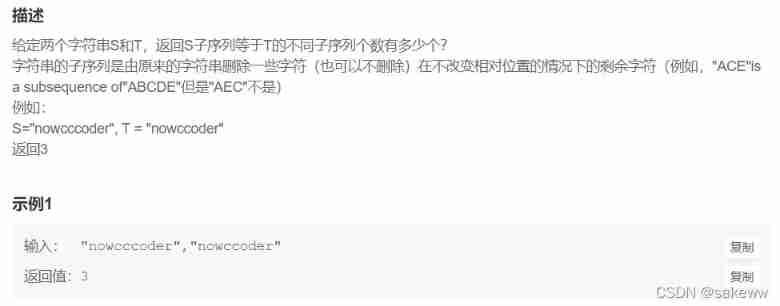
Cc36 different subsequences

Threads et pools de threads


随机推荐
Cc36 different subsequences
Global and Chinese markets for complex programmable logic devices 2022-2028: Research Report on technology, participants, trends, market size and share
Public key box
Global and Chinese market of pinhole glossmeter 2022-2028: Research Report on technology, participants, trends, market size and share
Description of Vos storage space, bandwidth occupation and PPS requirements
Capitalize the title of leetcode simple question
Heap, stack, queue
[oiclass] maximum formula
C4D quick start tutorial - Introduction to software interface
ucore lab 2
Investment should be calm
Jupyter installation and use tutorial
Pedestrian re identification (Reid) - data set description market-1501
UCORE lab5 user process management experiment report
Want to change jobs? Do you know the seven skills you need to master in the interview software test
UCORE lab2 physical memory management experiment report
The minimum number of operations to convert strings in leetcode simple problem
The most detailed postman interface test tutorial in the whole network. An article meets your needs
ucore lab5用户进程管理 实验报告
ucore Lab 1 系统软件启动过程