当前位置:网站首页>ucore lab2 物理内存管理 实验报告
ucore lab2 物理内存管理 实验报告
2022-07-06 09:24:00 【芜湖韩金轮】
实验一过后大家做出来了一个可以启动的系统,实验二主要涉及操作系统的物理内存管理。操作系统为了使用内存,还需高效地管理内存资源。在实验二中大家会了解并且自己动手完成一个简单的物理内存管理系统。、
实验目的
- 理解基于段页式内存地址的转换机制
- 理解页表的建立和使用方法
- 理解物理内存的管理方法
实验内容
本次实验包含三个部分。首先了解如何发现系统中的物理内存;然后了解如何建立对物理内存的初步管理,即了解连续物理内存管理;最后了解页表相关的操作,即如何建立页表来实现虚拟内存到物理内存之间的映射,对段页式内存管理机制有一个比较全面的了解。本实验里面实现的内存管理还是非常基本的,并没有涉及到对实际机器的优化,比如针对 cache 的优化等。如果大家有余力,尝试完成扩展练习。
练习
练习0:填写已有实验
本实验依赖实验1。请把你做的实验1的代码填入本实验中代码中有“LAB1”的注释相应部分。提示:可采用diff和patch工具进行半自动的合并(merge),也可用一些图形化的比较/merge工具来手动合并,比如meld,eclipse中的diff/merge工具,understand中的diff/merge工具等。
如图,打开meld软件
接着将lab1和lab2的目录进行比较
比较的结果为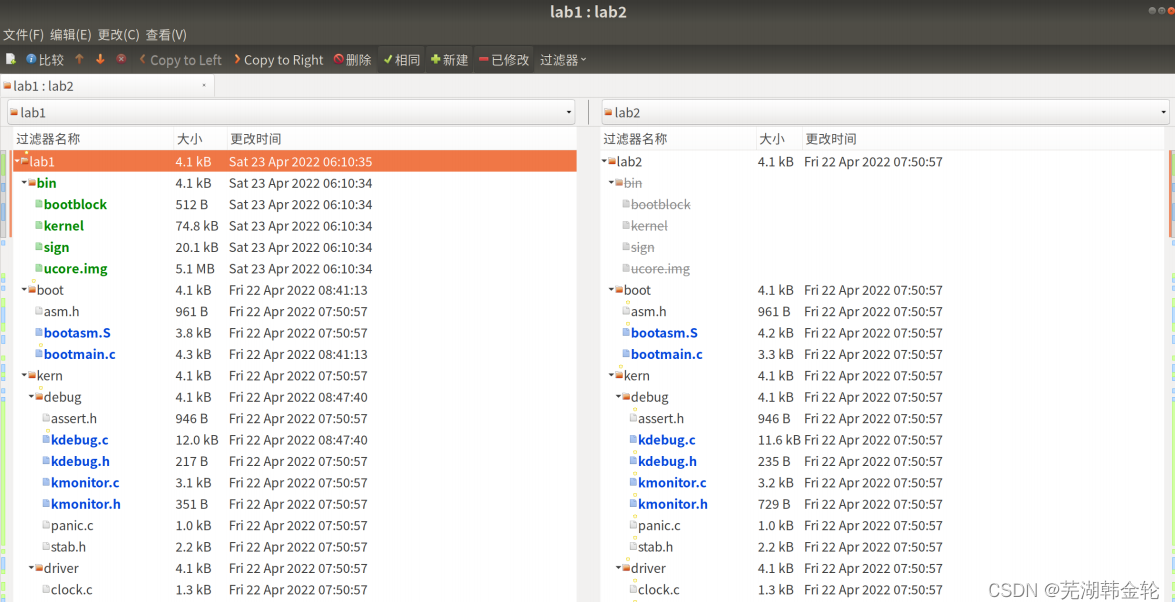
其中找到有*号标注的文件,即为不同的文件,将其复制
到lab2即可。最后将 kern/debug/kdebug.ckern/init/init.c kern/trap/trap.c 三个文件复制到lab2文件夹中,完成练习0。
练习1:实现 first-fit 连续物理内存分配算法(需要编程)
在实现first fit 内存分配算法的回收函数时,要考虑地址连续的空闲块之间的合并操作。提示:在建立空闲页块链表时,需要按照空闲页块起始地址来排序,形成一个有序的链表。可能会修改default_pmm.c中的default_init,default_init_memmap,default_alloc_pages, default_free_pages等相关函数。请仔细查看和理解default_pmm.c中的注释。
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 你的first fit算法是否有进一步的改进空间
准备知识:
First-Fit(首次适应算法):
首次适应算法从空闲分区表的第一个表目起查找该表,把最先能够满足要求的空闲区分配给作业,这种方法目的在于减少查找时间。该算法倾向于优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区,这为以后到达的大作业分配大的内存空间创造了条件。缺点是会造成外部碎片
assert()函数:
assert的作用是先计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。
list.h中
struct list_entry {
struct list_entry *prev, *next;//两个指针,父子节点
};
typedef struct list_entry list_entry_t;//重命名为list_entry_t
list_init初始化一个新的list_entry
list_add , list_add_before和list_add_after 都是添加一个新的条目
list_del是从列表中删除一个条目
list_del_init是从列表中删除─个条目并重定义它
list_empty是判断列表是否为空
list_next和list_prev分别是获取列表的前一项和后一项
le2page的定义:
// 将列表转换成页
#define le2page(le, member)
to_struct((le), struct Page, member)
物理页数据结构Page
struct Page {
int ref;
//ref表示的是,这个页被页表的引用记数,也就是映射此物理页的虚拟页个数。如果这个页被页表引用了,即在某页表中有一个页表项设置了一个虚拟页到这个Page管理的物理页的映射关系,就会把Page的ref加一;反之,若页表项取消,即映射关系解除,就会把Page的ref减一。
uint32_t flags;
//flags表示此物理页的状态标记,有两个标志位状态,为1的时候,代表这一页是free状态,可以被分配,但不能对它进行释放;如果为0,那么说明这个页已经分配了,不能被分配,但是可以被释放掉。
unsigned int property;
//property用来记录某连续空闲页的数量,这里需要注意的是用到此成员
变量的这个Page一定是连续内存块的开始地址(第一页的地址)。
list_entry_t page_link;
//page_link是便于把多个连续内存空闲块链接在一起的双向链表指针,连续内存空闲块利用这个页的成员变量page_link来链接比它地址小和大的其他连续内存空闲块,释放的时候只要将这个空间通过指针放回到双向链表中。
};
修改函数:
default_pmm.c代码中几乎已经实现了first-fit算法,但其中仍然存在一个问题,以至于无法通过检查。因为first-fit算法要求将空闲内存块按照地址从小到大的方式连接起来。但现成的代码还没有实现这一点,所以我们要手动修改相关的代码。
首先查看default_init函数:
//初始化free_area
static void
default_init(void) {
list_init(&free_list); //列表只有一个头指针
nr_free = 0; //空闲页数设为0
}
首先将前面进行了宏定义:
free_area_t free_area;
#define free_list (free_area.free_list) //维护所有空闲的内存块,是一个双向链表,在最开始时它的prev和next都指向自身。
#define nr_free (free_area.nr_free) //空闲页的数目
即将free_area.free_list(全局的空闲链表入口)定义为free_list,将free_area.nr_free(全局空闲页数量)定义为nr_free。
在default_init中,先将free_list进行init初始化,然后将空闲页数量置为0(因为还没开始计算空闲页的数量,所以是0)。
接下来查看 default_init_memmap 函数
//初始化n个空闲页链表并将block加入到free_list中。
static void
default_init_memmap(struct Page *base, size_t n) {
assert(n > 0); //使用assert宏,当为假时中止程序
struct Page *p = base; //声明一个base的页,随后生成起始地址
为base的n个连续页
for (; p != base + n; p ++) {
//初始化n块物理页
assert(PageReserved(p)); //检查是否为保留页,如果是,初始化
p->flags = p->property = 0; //设置标记,flag为0表示可以分配
//property为0表示连续空页为0
set_page_ref(p, 0); //映射到此物理页的虚拟页数量置为0
}
base->property = n;//第一个页表也就是base的property设置为n,因为有n个空闲块
SetPageProperty(base);//设置标志位
nr_free += n; //将空闲页数目设置为n
//list_add(&free_list, &(base->page_link)); 修改前
//后续的连续空页要被设为保留页然后链接成一个双向链表。
list_add_before(&free_list, &(base->page_link));//修改后
}
这一个函数是传入base页的地址和生成物理页的个数n,然后把物理页初始化后设为保留页与base页连接。并将修改base页的property为n,修改nr_free为n,记录空闲页的个数。
分配指定数目的空闲page的代码,即
default_alloc_pages 函数:
//由于是first-fit函数,故把遇到的第一个可以用于分配的连续内存进行分配即可
static struct Page * default_alloc_pages(size_t n) {
//n表示需要分配页的大小
assert(n > 0); //n的值应该大于0
//如果n>nf_free,表示无法分配这么大内存,返回NULL即可
if (n > nr_free)
{
return NULL;
}
//说明够分配,因此找到即可
struct Page *page = NULL;
list_entry_t *le = &free_list;//声明空闲链表的头部
// 查找n个或以上空闲页块,若找到,则判断是否大过n,大于n的话则将其拆分
// 并将拆分后的剩下的空闲页块加回到链表中
while ((le = list_next(le)) != &free_list)
// 如果list_next(le)) == &free_list说明已经遍历完了整个双向链表
{
// 此处le2page就是将le的地址-page_link 在Page的偏移,从而找到 Page 的地址
struct Page *p = le2page(le, page_link);
//说明找到可以满足的连续空闲内存了,让page等于p即可,退出循环
if (p->property >= n) //找到页
{
page = p;
break;
}
}
if (page != NULL)
{
//如果property>n的话,我们需要把多出的内存加到链表里
if (page->property > n)
{
//创建一个新的Page,起始地址为page+n
struct Page *p = page + n;
p->property = page->property - n;
//将其property设置为page->property-n
SetPageProperty(p);
// 将多出来的插入到被分配掉的页块后面
list_add(&(page->page_link), &(p->page_link));
}
// 在空闲页链表中删去刚才分配的空闲页
list_del(&(page->page_link));
//因为分配了n个内存,故nr_free-n即可
nr_free -= n;
ClearPageProperty(page);
}
//返回分配的内存
return page;
}
这个函数用于分配空闲页,根据注释的说明,先判断p->property的大小,如果是>=n,则对标志位进行一些修改,如果是>n,则要分割页块后进行操作,如果都不符合则返回NULL退出。(根据注释一步一步写即可,注释讲的很详细。)
由上可得,操作系统分配内存的思路为: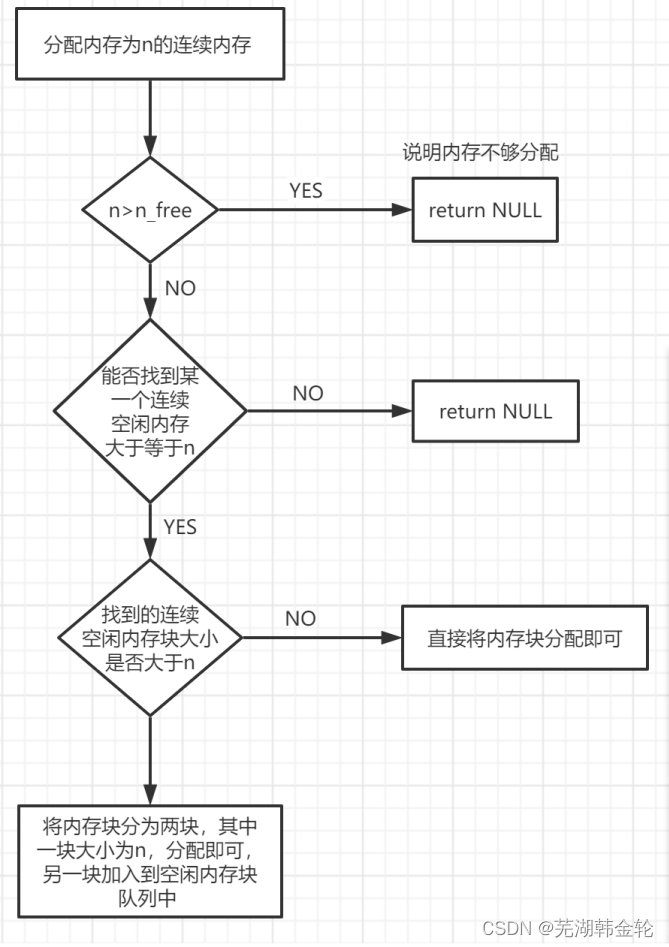
释放内存代码,即 default_free_pages 函数
//释放掉n个页块,释放后也要考虑释放的块是否和已有的空闲块是紧挨着的,也就是可以合并的
//如果可以合并,则合并,否则直接加入双向链表
static void default_free_pages(struct Page *base, size_t n)
{
assert(n > 0); //n必须大于0
struct Page *p = base;
//首先将base-->base+n之间的内存的标记以及ref初始化
for (; p != base + n; p ++)
{
assert(!PageReserved(p) && !PageProperty(p));
//将flags和ref设为0
p->flags = 0;
set_page_ref(p, 0);
}
//释放完毕后先将这一块的property改为n
base->property = n;
SetPageProperty(base);
list_entry_t *le = list_next(&free_list);
// 检查能否将其合并到合适的页块中
while (le != &free_list)
{
p = le2page(le, page_link);
le = list_next(le);
//如果这个块在下一个空闲块前面,二者可以合并
if (base + base->property == p)
{
//让base的property等于两个块的大小之和
base->property += p->property;
//将另一个空闲块删除即可
ClearPageProperty(p);
list_del(&(p->page_link));
}
//如果这个块在上一个空闲块的后面,二者可以合并
else if (p + p->property == base)
{
//将p的property设置为二者之和
p->property += base->property;
//将后面的空闲块删除即可
ClearPageProperty(base);
base = p;
//注意这里需要把p删除,因为之后再次去确认插入的位置
list_del(&(p->page_link));
}
}
//整体上空闲空间增大了n
nr_free += n;
le = list_next(&free_list);
// 将合并好的合适的页块添加回空闲页块链表
//因为需要按照内存从小到大的顺序排列列表,故需要找到应该插入的位置
while (le != &free_list)
{
p = le2page(le, page_link);
//找到正确的位置:
if (base + base->property <= p)
{
break;
}
//否则链表项向后,继续查找
le = list_next(le);
}
//将base插入到刚才找到的正确位置即可
list_add_before(le, &(base->page_link));
}
此函数用于将释放的页重新加入到页链表中,本实验中的做法为遍历链表,找到第一个页地址大于所释放的第一页的地址,首先判断所释放的页的基地址加上所释放的页的数目是否刚好等于找到的地址,如果是则进行合并,同理找到这个页之前的第一个property不为0的页,判断所释放的页和上一个页是否是连续的,如果连续则进行合并操作。
释放内存的思路: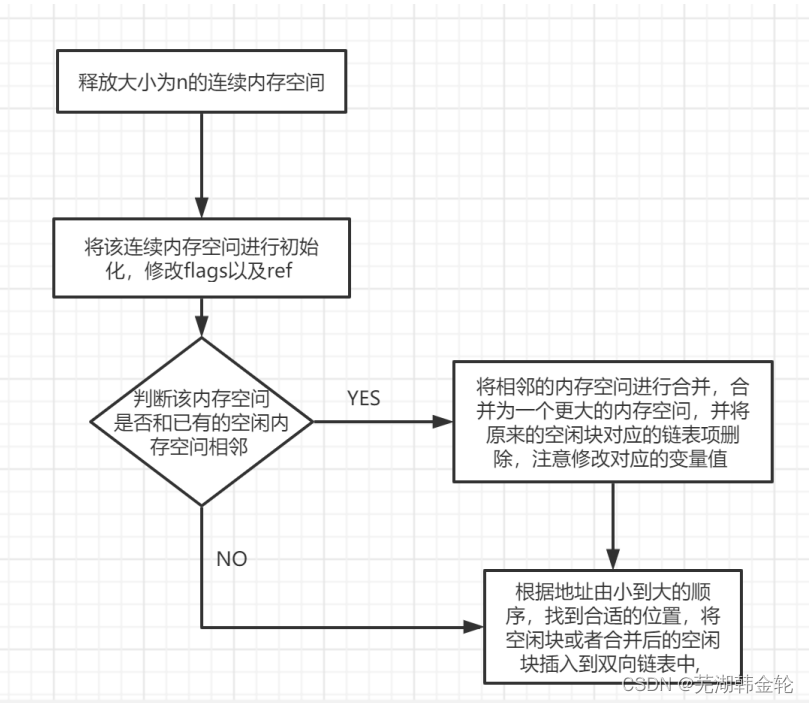
完成相关函数后,进行make qemu指令,可以看到 :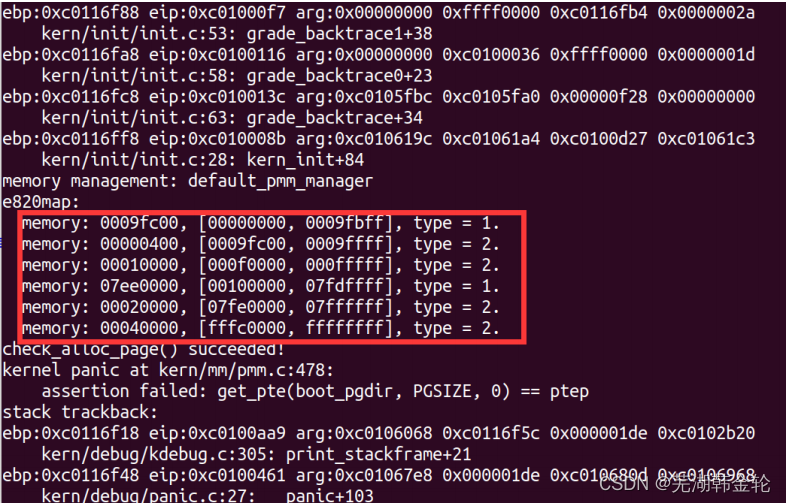
可以看到,内存成功分配,算法通过测试。
回答问题
- 你的first fit算法是否有进一步的改进空间
首先我们知道该算法在分配以及释放内存时复杂度均为O(n),因为需要访问链表,故复杂度不可避免地为O(n);
我们可以用二叉搜索树来对内存进行管理。用二叉搜索树主要是通过对地址排序,使得在使用free时候可以在O(logn)时间内完成链表项位置的查找,从而实现时间上的优化。具体如下:
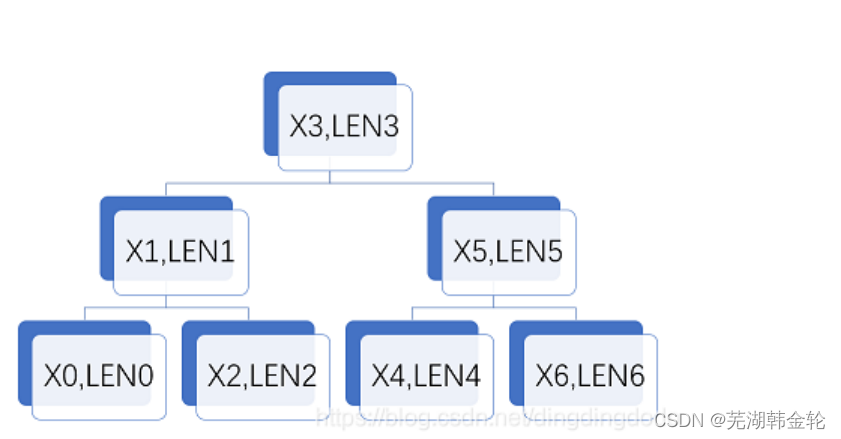
按照地址排序,也就是保证二叉树的任意节点的左节点的地址值小于自身地址值,右节点的地址值大于自身地址值,通过此方法优化,我们可以实现O(n)的复杂度进行内存的分配,但是可以O(logn)的复杂度进行内存的释放,因为判断合并的过程得到了优化。在这里,我们对LEN无要求,但必须保证X0<X1<X2<X3<X4<X5<X6,且地址之间无交集且不相邻。通过这个方法使得算法的复杂度得到了优化。
练习2:实现寻找虚拟地址对应的页表项(需要编程)
通过设置页表和对应的页表项,可建立虚拟内存地址和物理内存地址的对应关系。其中的get_pte函数是设置页表项环节中的一个重要步骤。此函数找到一个虚地址对应的二级页表项的内核虚地址,如果此二级页表项不存在,则分配一个包含此项的二级页表。本练习需要补全get_pte函数 in kern/mm/pmm.c,实现其功能。请仔细查看和理解get_pte函数中的注释。get_pte函数的调用关系图如下所示: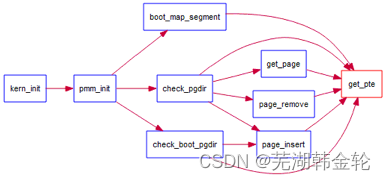
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中每个组成部分的含义以及对ucore而言的潜在用处。
- 如果ucore执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
准备知识:
x86体系结构将内存地址分成三种:逻辑地址(也称虚
地址)、线性地址和 物理地址。
- 逻辑地址即是程序指令中使用的地址。
- 物理地址是实际访问内存的地址。
- 逻辑地址通过段式管理的地址映射可以得到线性地址, 线性地址通过页式 管理的地址映射得到物理地址。
get_pte函数给出了线性地址,即linear address。三者的关系是:线性地址(Linear Address)是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,或说是段中的偏移地址,加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址能再经变换以产生一个物理地址。
地址的转换如图示 :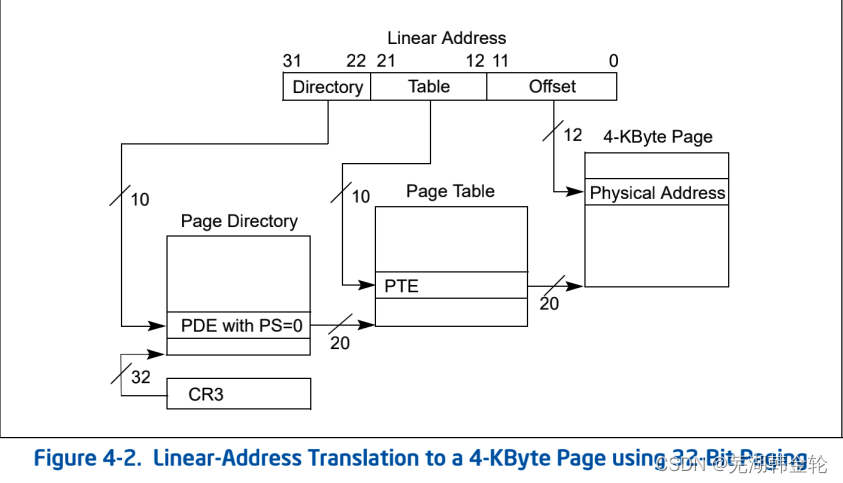
Ucore的页式管理通过一个二级的页表实现。一级页表存放在高10位中,二级页表存放于中间10位中,最后的12位表示偏移量,据此可以证明,页大小为4KB(2的12次方,4096)。
- Directory为一级页表
- PDX(la)可以获取Directory(获取一级页表)
- Table为二级页表
- PTX(la)可以获取Table(获取二级页表)
get_pte的注释中给出了一些宏和定义:
- PDX(la): 返回虚拟地址la的页目录索引
- KADDR(pa): 返回物理地址pa对应的虚拟地址
- set_page_ref(page,1): 设置此页被引用一次
- page2pa(page): 得到page管理的那一页的物理地址
- struct Page * alloc_page() : 分配一页出来
- memset(void * s, char c, size_t n) : 设置s指向地址的前面n个字节为‘c’
- PTE_P 0x001 表示物理内存页存在
- PTE_W 0x002 表示物理内存页内容可写
- PTE_U 0x004 表示可以读取对应地址的物理内存页内容
代码如下:
//此函数找到一个虚地址对应的二级页表项的内核虚地址,如果此二级页表项不存在,则分配一个包含此项的二级页表
// pgdir:PDT的内核虚拟地址 la:需要映射的线性地址 creat:决定是否为PT分配页面的逻辑值
//return vaule:这个pte的内核虚拟地址
pte_t *get_pte(pde_t *pgdir, uintptr_t la, bool create)
{
//找一级页表PDE
pde_t *pdep = pgdir + PDX(la);
//如果存在的话,返回对应的PTE即可
if (*pdep & PTE_P) {
pte_t *ptep = (pte_t *)KADDR(*pdep & ~0x0fff) + PTX(la);
return ptep;
}
//如果不存在的话分配给它page
struct Page *page;
if (!create || ((page = alloc_page()) == NULL))
{
return NULL;
}
//要查找该页表,则引用次数+1
set_page_ref(page, 1);
//得到page的线性地址
uintptr_t pa = page2pa(page) & ~0x0fff;
//转成虚拟地址并初始化为0,因为还没有开始映射
memset((void *)KADDR(pa), 0, PGSIZE);
//设置控制位,同时设置PTE_U,PTE_W和PTE_P,分别代表用户态的软件可以读取对应地址的物理内存页内容、物理内存页内容可写、物理内存页存在。
*pdep = pa | PTE_P | PTE_W | PTE_U;
//返回PTE
pte_t *ptep = (pte_t *)KADDR(pa) + PTX(la);
//返回对应页项地址
return ptep;
}
需要注意的地方:
通过 default_alloc_pages() 分配的页的地址并不是真正的页分配的地址,实际上只是 Page 这个结构体所在的地址,故而需要通过使用 page2pa() 将 Page 这个结构体的地址转换成真正的物理页地址的线性地址,需要注意的是:无论是 * 或是 memset 都是对虚拟地址进行操作的所以需要将真正的物理页地址再转换成内核虚拟地址。
回答问题:
- 请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中每个组成部分的含义以及对ucore而言的潜在用处。
页目录项(Page Directory Entry)组成以及对ucore
而言的潜在作用: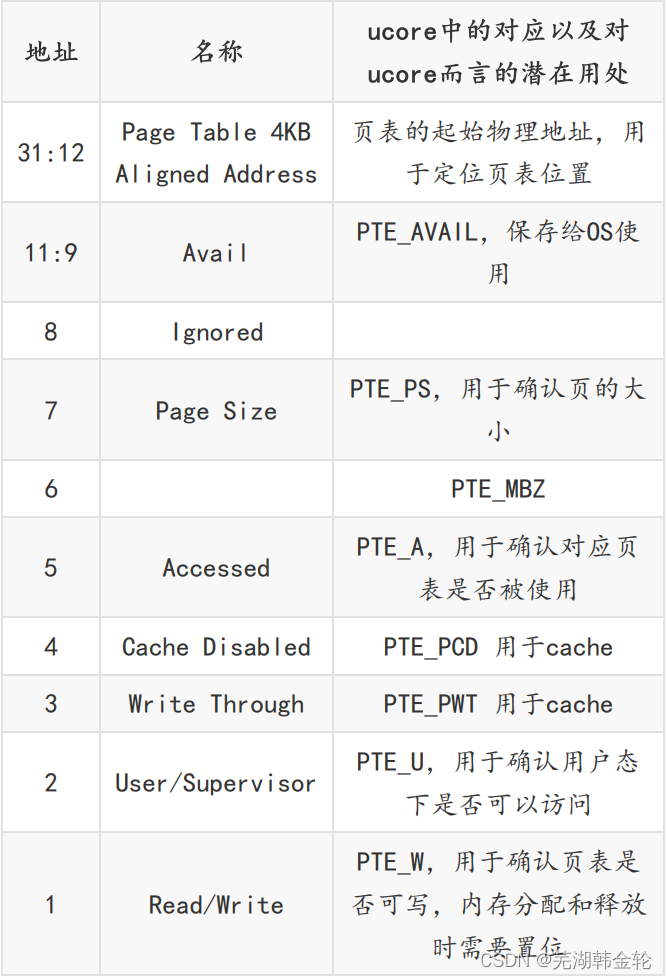

页表项(Page Table Entry)的组成以及对ucore而言的
潜在作用: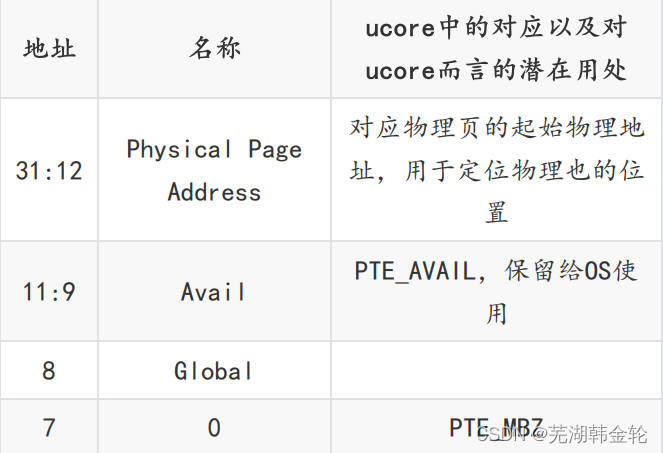
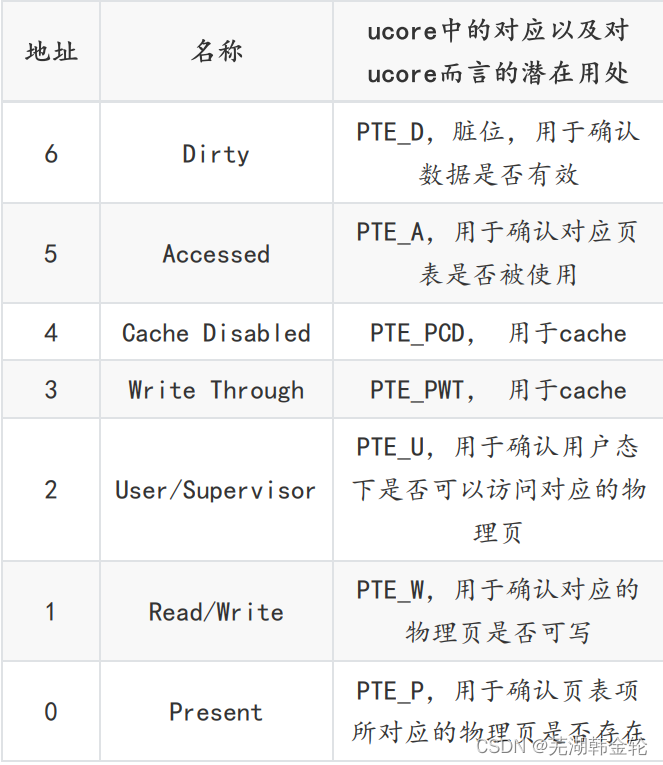
总而言之,页目录项是一级页表,存储了各二级页表的起始地址,页表是二级页表,存储了各个页的起始地址。一个虚拟地址(线性地址)通过页机制翻译得到最终的物理地址。
页表的主要作用是:假如在系统里面,物理内存和虚拟内存是一一对应的,那么在进程空间里面就会存在很多的页表,同时也会占据很多的空间,那么,为了解决这个问题就出现了多级页表。
- 如果ucore执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
- 硬件陷入内核,在堆栈中保存程序计数器。大多数机器将当前指令的各种状态信息保存在特殊的CPU寄存器中。
- 启动一个汇编代码例程保存通用寄存器和其他易失的信息,以免被操作系统破坏。这个例程将操作系统作为一个函数来调用。
- 当操作系统发现一个缺页中断时,尝试发现需要哪个虚拟页面。通常一个硬件寄存器包含了这一信息,如果没有的话,操作系统必须检索程序计数器,取出这条指令,用软件分析这条指令,看看它在缺页中断时正在做什么。
- 一旦知道了发生缺页中断的虚拟地址,操作系统检查这个地址是否有效,并检查存取与保护是否一致。如果不一致,向进程发出一个信号或杀掉该进程。如果地址有效且没有保护错误发生,系统则检查是否有空闲页框。如果没有空闲页框,执行页面置换算法寻找一个页面来淘汰。
- 如果选择的页框“脏”了,安排该页写回磁盘,并发生一次上下文切换,挂起产生缺页中断的进程,让其他进程运行直至磁盘传输结束。无论如何,该页框被标记为忙,以免因为其他原因而被其他进程占用。
- 一旦页框“干净”后(无论是立刻还是在写回磁盘后),操作系统查找所需页面在磁盘上的地址,通过磁盘操作将其装入。该页面被装入后,产生缺页中断的进程仍然被挂起,并且如果有其他可运行的用户进程,则选择另一个用户进程运行。
- 当磁盘中断发生时,表明该页已经被装入,页表已经更新可以反映它的位置,页框也被标记为正常状态。
- 恢复发生缺页中断指令以前的状态,程序计数器重新指向这条指令。
- 调度引发缺页中断的进程,操作系统返回调用它的汇编语言例程。
- 该例程恢复寄存器和其他状态信息
练习3:释放某虚地址所在的页并取消对应二级页表项的映射(需要编程)
当释放一个包含某虚地址的物理内存页时,需要让对应此物理内存页的管理数据结构Page做相关的清除处理,使得此物理内存页成为空闲;另外还需把表示虚地址与物理地址对应关系的二级页表项清除。请仔细查看和理解page_remove_pte函数中的注释。为此,需要补全在 kern/mm/pmm.c中的page_remove_pte函数。page_remove_pte函数的调用关系图如下所示: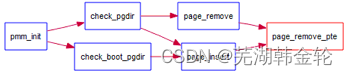
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 数据结构Page的全局变量(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?
- 如果希望虚拟地址与物理地址相等,则需要如何修改lab2,完成此事? 鼓励通过编程来具体完成这个问题
思路:检查页表项是否存在,如果存在,将其对应的映
射关系取消,并将PTE清除,之后刷新tlb即可。
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep)
{
//检查page directory是否存在
//练习二我们已经学到 PTE_P用于表示page dir是否存在
if (*ptep & PTE_P)
{
struct Page *page = pte2page(*ptep);
// (page_ref_dec(page)将page的ref减1,并返回减1之后的ref
if (page_ref_dec(page) == 0) //如果ref为0,则free即可
{
free_page(page);
}
//清除第二个页表 PTE
*ptep = 0;
//刷新 tlb,去除那些清除关系的二级页表,更新页目录项
tlb_invalidate(pgdir, la);
}
}
完成代码书写后,可以执行make qemu,检测练习二和
练习三的代码是否正确,运行结果如下:
[email protected]:~/os_kernel_lab/labcodes/lab2$ make qemu
+ cc kern/mm/pmm.c
kern/mm/pmm.c:266:1: warning: ‘boot_alloc_page’ defined but not
used [-Wunused-function]
boot_alloc_page(void) {
^~~~~~~~~~~~~~~
+ ld bin/kernel
+ ld bin/kernel_nopage
记录了10000+0 的读入
记录了10000+0 的写出
5120000 bytes (5.1 MB, 4.9 MiB) copied, 0.0208672 s, 245 MB/s
记录了1+0 的读入
记录了1+0 的写出
512 bytes copied, 0.000204289 s, 2.5 MB/s
记录了265+1 的读入
记录了265+1 的写出
135832 bytes (136 kB, 133 KiB) copied, 0.000493457 s, 275 MB/s
WARNING: Image format was not specified for 'bin/ucore.img' and
probing guessed raw.
Automatically detecting the format is dangerous for raw
images, write operations on block 0 will be restricted.
Specify the 'raw' format explicitly to remove the
restrictions.
(THU.CST) os is loading ...
Special kernel symbols:
entry 0xc0100036 (phys)
etext 0xc0106f2e (phys)
edata 0xc011d000 (phys)
end 0xc02a4960 (phys)
Kernel executable memory footprint: 1683KB
ebp:0xc0119f38 eip:0xc0100aa9 arg:0x00010094 0x00010094
0xc0119f68 0xc01000cd
kern/debug/kdebug.c:305: print_stackframe+21
ebp:0xc0119f48 eip:0xc0100d9f arg:0x00000000 0x00000000
0x00000000 0xc0119fb8
kern/debug/kmonitor.c:129: mon_backtrace+10
ebp:0xc0119f68 eip:0xc01000cd arg:0x00000000 0xc0119f90
0xffff0000 0xc0119f94
kern/init/init.c:48: grade_backtrace2+33
ebp:0xc0119f88 eip:0xc01000f7 arg:0x00000000 0xffff0000
0xc0119fb4 0x0000002b
kern/init/init.c:53: grade_backtrace1+38
ebp:0xc0119fa8 eip:0xc0100116 arg:0x00000000 0xc0100036
0xffff0000 0x0000001d
kern/init/init.c:58: grade_backtrace0+23
ebp:0xc0119fc8 eip:0xc010013c arg:0xc0106f5c 0xc0106f40
0x00187960 0x00000000
kern/init/init.c:63: grade_backtrace+34
ebp:0xc0119ff8 eip:0xc010008b arg:0xc010713c 0xc0107144
0xc0100d27 0xc0107163
kern/init/init.c:28: kern_init+84
memory management: default_pmm_manager
e820map:
memory: 0009fc00, [00000000, 0009fbff], type = 1.
memory: 00000400, [0009fc00, 0009ffff], type = 2.
memory: 00010000, [000f0000, 000fffff], type = 2.
memory: 07ee0000, [00100000, 07fdffff], type = 1.
memory: 00020000, [07fe0000, 07ffffff], type = 2.
memory: 00040000, [fffc0000, ffffffff], type = 2.
check_alloc_page() succeeded!
check_pgdir() succeeded!
check_boot_pgdir() succeeded!
-------------------- BEGIN --------------------
PDE(0e0) c0000000-f8000000 38000000 urw
|-- PTE(38000) c0000000-f8000000 38000000 -rw
PDE(001) fac00000-fb000000 00400000 -rw
|-- PTE(000e0) faf00000-fafe0000 000e0000 urw
|-- PTE(00001) fafeb000-fafec000 00001000 -rw
--------------------- END ---------------------
++ setup timer interrupts
0: @ring 0
0: cs = 8
0: ds = 10
0: es = 10
0: ss = 10
+++ switch to user mode +++
100 ticks
100 ticks
100 ticks
通过运行结果,我们可以看到ucore在显示其entry(入口地址)、etext(代码段截止处地址)、edata(数据段截止处地址)、和end(ucore截止处地址)的值后,探测出计算机系统中的物理内存的布局(e820map下的显示内容)。接下来ucore会以页为最小分配单位实现一个简单的内存分配管理,完成二级页表的建立,进入分页模式,执行各种我们设置的检查,最后显示ucore建立好的二级页表内容,并在分页模式下响应时钟中断。
同时运行make grade查看分数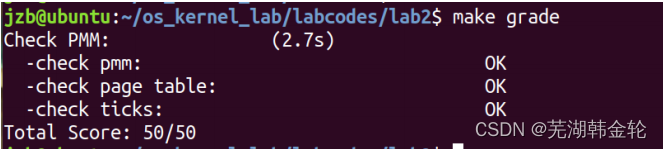
说明练习2和练习3的代码均正确。
回答问题
- 数据结构Page的全局变量(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?
pages的每一项与页表中的页目录项和页表项有对应,pages每一项对应一个物理页的信息。一个页目录项对应一个页表,一个页表项对应一个物理页。假设有N个物理页,pages的长度为N,而页目录项、页表项的前20位对应物理页编号。
如下图所示: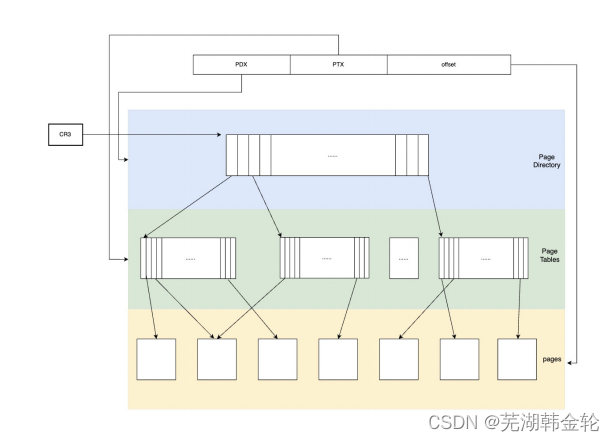
一个PDE对应1024个PTE,一个PTE对应1024个page。
- 如果希望虚拟地址与物理地址相等,则需要如何修改
lab2,完成此事? 鼓励通过编程来具体完成这个问题
物理地址和虚拟地址之间存在offset:
phy addr + KERNBASE = virtual addr
所以,KERNBASE = 0时,phy addr = virtual addr
所以把memlayout.h中的
/* All physical memory mapped at this address */
#define KERNBASE 0x00000000
将KERNBASE改为0即可。
扩展练习Challenge:buddy system(伙伴系统)分配算法(需要编程)
Buddy System算法把系统中的可用存储空间划分为存储块(Block)来进行管理, 每个存储块的大小必须是2的n次幂(Pow(2, n)), 即1, 2, 4, 8, 16, 32, 64, 128…
- 参考伙伴分配器的一个极简实现, 在ucore中实现buddy system分配算法,要求有比较充分的测试用例说明实现的正确性,需要有设计文档。
准备知识
buddy system: 伙伴分配的实质就是一种特殊的“分离适配”,即将内存按2的幂进行划分,相当于分离出若干个块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。
算法大体上是:
分配内存:
- 寻找大小合适的内存块(大于等于所需大小并且最接近2的幂,比如需要27,实际分配32):
- 如果找到了,分配给应用程序
- 如果没找到,分出合适的内存块
- 对半分离出高于所需大小的空闲内存块
- 如果分到最低限度,分配这个大小。
- 回溯到步骤1(寻找合适大小的块)
- 重复该步骤直到一个合适的块
释放内存:
- 释放该内存块
- 寻找相邻的块,看其是否释放了。
- 如果相邻块也释放了,合并这两个块,重复上述步骤直 到遇上未释放的相邻块,或者达到最高上限(即所有内存 都释放了)。
分配器的整体思想:
通过一个数组形式的完全二叉树来监控管理内存,二叉树的节点用于标记相应内存块的使用状态,高层节点对应大的块,低层节点对应小的块,在分配和释放中我们就通过这些节点的标记属性来进行块的分离合并。如图所示,假设总大小为16单位的内存,我们就建立一个深度为5的满二叉树, 根节点从数组下标[0]开始,监控大小16的块;它的左右孩子节点下标[1~ 2],监控大小8的块;第三层节点下标[3~6]监控大小4的块……依此类推。
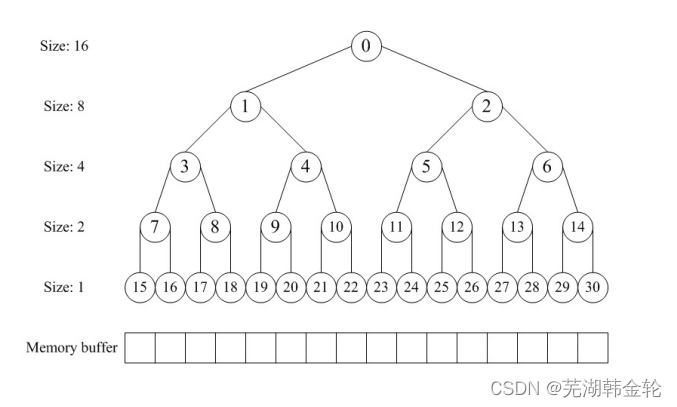
实现buddy system分配算法
先分析ucore的执行过程:
从练习1中可知,内存的分配函数是在default_pmm.c中
实现的, 并在pmm.c中调用,因此 模仿default_pmm.h和pmm.c创建完成buddy.h和buddy.c。
buddy.h的实现:
#ifndef __KERN_MM_BUDDY_PMM_H__
#define __KERN_MM_BUDDY_PMM_H__
#include <pmm.h>
extern const struct pmm_manager buddy_pmm_manager;
#endif /* ! __KERN_MM_DEFAULT_PMM_H__ */
将pmm.c中的 init_pmm_manager 函数中的pmm_manager
值修改为 buddy_pmm_manager ,即:
static void
init_pmm_manager(void) {
pmm_manager = &buddy_pmm_manager;
cprintf("memory management: %s\n", pmm_manager->name);
pmm_manager->init();
}
同时完成buddy.c代码:
#include <pmm.h>
#include <list.h>
#include <string.h>
#include <default_pmm.h>
#include <buddy.h>
//来自参考资料的一些宏定义
#define LEFT_LEAF(index) ((index) * 2 + 1)//左子树节点的值
#define RIGHT_LEAF(index) ((index) * 2 + 2)//右子树节点的值
#define PARENT(index) ( ((index) + 1) / 2 - 1)//父节点的值
#define IS_POWER_OF_2(x) (!((x)&((x)-1)))//x是不是2的幂
#define MAX(a, b) ((a) > (b) ? (a) : (b))//判断a,b大小
#define UINT32_SHR_OR(a,n) ((a)|((a)>>(n)))//右移n位
#define UINT32_MASK(a)
(UINT32_SHR_OR(UINT32_SHR_OR(UINT32_SHR_OR(UINT32_SHR_OR(UINT32_
SHR_OR(a,1),2),4),8),16))
//大于a的一个最小的2^k
#define UINT32_REMAINDER(a) ((a)&(UINT32_MASK(a)>>1))
#define UINT32_ROUND_DOWN(a) (UINT32_REMAINDER(a)?((a)-
UINT32_REMAINDER(a)):(a))//小于a的最大的2^k
static unsigned fixsize(unsigned size) {
//找到大于等于所需内存的2
的倍数
size |= size >> 1;
size |= size >> 2;
size |= size >> 4;
size |= size >> 8;
size |= size >> 16;
return size+1;
}
struct buddy2 {
unsigned size;//表明管理内存的总单元数
unsigned longest; //二叉树的节点标记,表明对应内存块的空闲单位
};
struct buddy2 root[80000];//存放二叉树的数组,用于内存分配
free_area_t free_area;
#define free_list (free_area.free_list)
#define nr_free (free_area.nr_free)
struct allocRecord//记录分配块的信息
{
struct Page* base;
int offset;
size_t nr;//块大小
};
struct allocRecord rec[80000];//存放偏移量的数组
int nr_block;//已分配的块数
static void buddy_init()
{
list_init(&free_list);
nr_free=0;
}
//初始化二叉树上的节点
void buddy2_new( int size ) {
unsigned node_size;
int i;
nr_block=0;
if (size < 1 || !IS_POWER_OF_2(size))
return;
root[0].size = size;
node_size = size * 2;
for (i = 0; i < 2 * size - 1; ++i) {
if (IS_POWER_OF_2(i+1))
node_size /= 2;
root[i].longest = node_size;
}
return;
}
//初始化内存映射关系
static void
buddy_init_memmap(struct Page *base, size_t n)
{
assert(n>0);
struct Page* p=base;
for(;p!=base + n;p++)
{
assert(PageReserved(p));
p->flags = 0;
p->property = 1;
set_page_ref(p, 0);
SetPageProperty(p);
list_add_before(&free_list,&(p->page_link));
}
nr_free += n;
int allocpages=UINT32_ROUND_DOWN(n);
buddy2_new(allocpages);
}
//内存分配
int buddy2_alloc(struct buddy2* self, int size) {
unsigned index = 0;//节点的标号(数组下标)
unsigned node_size;
unsigned offset = 0;//偏移量
if (self==NULL)//无法分配
return -1;
if (size <= 0)//分配不合理
size = 1;
else if (!IS_POWER_OF_2(size))//不为2的幂时,取比size更大的2的n
次幂
size = fixsize(size);
if (self[index].longest < size)//可分配内存不足
return -1;
for(node_size = self->size; node_size != size; node_size /= 2
) {
//从最大根节点开始向下寻找合适的节点
//左子树优先
if (self[LEFT_LEAF(index)].longest >= size)
{
if(self[RIGHT_LEAF(index)].longest>=size)
{
index=self[LEFT_LEAF(index)].longest <=
self[RIGHT_LEAF(index)].longest?
LEFT_LEAF(index):RIGHT_LEAF(index);
//找到两个相符合的节点中内存较小的结点
}
else
{
index=LEFT_LEAF(index);
}
}
else
index = RIGHT_LEAF(index);
}
self[index].longest = 0;//标记节点为已使用
offset = (index + 1) * node_size - self->size;//计算偏移量
//向上刷新
while (index) {
index = PARENT(index);
self[index].longest =
MAX(self[LEFT_LEAF(index)].longest,
self[RIGHT_LEAF(index)].longest);
//刷新父节点
}
return offset;
}
static struct Page*
buddy_alloc_pages(size_t n){
assert(n>0);
if(n>nr_free)
return NULL;
struct Page* page=NULL;
struct Page* p;
list_entry_t *le=&free_list,*len;
rec[nr_block].offset=buddy2_alloc(root,n);//记录偏移量
int i;
for(i=0;i<rec[nr_block].offset+1;i++)
le=list_next(le);
page=le2page(le,page_link);
int allocpages;
if(!IS_POWER_OF_2(n))
allocpages=fixsize(n);
else
{
allocpages=n;
}
//根据需求n得到块大小
rec[nr_block].base=page;//记录分配块首页
rec[nr_block].nr=allocpages;//记录分配的页数
nr_block++;
for(i=0;i<allocpages;i++)
{
len=list_next(le);
p=le2page(le,page_link);
ClearPageProperty(p);
le=len;
}//修改每一页的状态
nr_free-=allocpages;//减去已被分配的页数
page->property=n;
return page;
}
void buddy_free_pages(struct Page* base, size_t n) {
unsigned node_size, index = 0;
unsigned left_longest, right_longest;
struct buddy2* self=root;
list_entry_t *le=list_next(&free_list);
int i=0;
for(i=0;i<nr_block;i++)//找到块
{
if(rec[i].base==base)
break;
}
int offset=rec[i].offset;
int pos=i;//暂存i
i=0;
while(i<offset)
{
le=list_next(le);
i++;
}
int allocpages;
if(!IS_POWER_OF_2(n))
allocpages=fixsize(n);
else
{
allocpages=n;
}
assert(self && offset >= 0 && offset < self->size);//是否合法
node_size = 1;
index = offset + self->size - 1;
nr_free+=allocpages;//更新空闲页的数量
struct Page* p;
self[index].longest = allocpages;
for(i=0;i<allocpages;i++)//回收已分配的页
{
p=le2page(le,page_link);
p->flags=0;
p->property=1;
SetPageProperty(p);
le=list_next(le);
}
while (index) {
//向上合并,修改先祖节点的记录值
index = PARENT(index);
node_size *= 2;
left_longest = self[LEFT_LEAF(index)].longest;
right_longest = self[RIGHT_LEAF(index)].longest;
if (left_longest + right_longest == node_size)
self[index].longest = node_size;
else
self[index].longest = MAX(left_longest, right_longest);
}
for(i=pos;i<nr_block-1;i++)//清除此次的分配记录
{
rec[i]=rec[i+1];
}
nr_block--;//更新分配块数的值
}
static size_t
buddy_nr_free_pages(void) {
return nr_free;
}
//以下是一个测试函数
static void
buddy_check(void) {
struct Page *p0, *A, *B,*C,*D;
p0 = A = B = C = D =NULL;
assert((p0 = alloc_page()) != NULL);
assert((A = alloc_page()) != NULL);
assert((B = alloc_page()) != NULL);
assert(p0 != A && p0 != B && A != B);
assert(page_ref(p0) == 0 && page_ref(A) == 0 && page_ref(B)
== 0);
free_page(p0);
free_page(A);
free_page(B);
A=alloc_pages(500);
B=alloc_pages(500);
cprintf("A %p\n",A);
cprintf("B %p\n",B);
free_pages(A,250);
free_pages(B,500);
free_pages(A+250,250);
p0=alloc_pages(1024);
cprintf("p0 %p\n",p0);
assert(p0 == A);
//以下是根据链接中的样例测试编写的
A=alloc_pages(70);
B=alloc_pages(35);
assert(A+128==B);//检查是否相邻
cprintf("A %p\n",A);
cprintf("B %p\n",B);
C=alloc_pages(80);
assert(A+256==C);//检查C有没有和A重叠
cprintf("C %p\n",C);
free_pages(A,70);//释放A
cprintf("B %p\n",B);
D=alloc_pages(60);
cprintf("D %p\n",D);
assert(B+64==D);//检查B,D是否相邻
free_pages(B,35);
cprintf("D %p\n",D);
free_pages(D,60);
cprintf("C %p\n",C);
free_pages(C,80);
free_pages(p0,1000);//全部释放
}
const struct pmm_manager buddy_pmm_manager = {
.name = "buddy_pmm_manager",
.init = buddy_init,
.init_memmap = buddy_init_memmap,
.alloc_pages = buddy_alloc_pages,
.free_pages = buddy_free_pages,
.nr_free_pages = buddy_nr_free_pages,
.check = buddy_check,
};
运行make qemu,得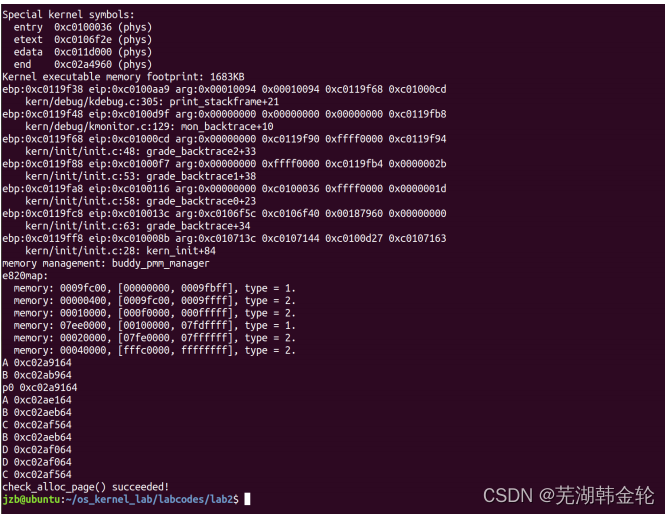
运行正常,且经过检验正确,可以实现challenge的要
求。
扩展练习Challenge:任意大小的内存单元slub分配算法(需要编程)
slub算法,实现两层架构的高效内存单元分配,第一层是基于页大小的内存分配,第二层是在第一层基础上实现基于任意大小的内存分配。可简化实现,能够体现其主体思想即可。
- 参考linux的slub分配算法/,在ucore中实现slub分配算法。要求有比较充分的测试用例说明实现的正确性,需要有设计文档。
实验总结
前面的练习1~3让我对操作系统的内存管理等机制有了深刻的理解,比如不同内存分配算法和页表等。
challenge我认为是比较有挑战性的,但和练习1有一定的联系,都是要完成内存的分配和释放。看了指导书中给的伙伴算法的参考链接,该文作者看起来很喜欢这个算法,但这个算法还是有一定的缺点的,比起练习中实现的First-Fit,它的内部碎片反而变大了,而且它浪费严重,比如需要9K,必需分配16K的空间导致7K被浪费。合并的要求太过严格,只能是满足伙伴关系的块才能合并。优点则是可以较好的解决外部碎片问题,而且查询相关资料有提到伙伴算法针对大内存分配设计。
总的来说,lab2的收获还是很大,而且正如实验指导书最开始说的,lab1和lab2比较困难,但通过lab1和lab2后,对计算机原理中的中断、段页表机制、特权级等的理解会更深入。对后面的学习有很大的帮助。
边栏推荐
- 移植蜂鸟E203内核至达芬奇pro35T【集创芯来RISC-V杯】(一)
- Numpy Quick Start Guide
- 函数:求方程的根
- 数字电路基础(三)编码器和译码器
- Database monitoring SQL execution
- Login the system in the background, connect the database with JDBC, and do small case exercises
- Don't you even look at such a detailed and comprehensive written software test question?
- 《統計學》第八版賈俊平第七章知識點總結及課後習題答案
- 线程的实现方式总结
- Function: string storage in reverse order
猜你喜欢
Statistics, 8th Edition, Jia Junping, Chapter VIII, summary of knowledge points of hypothesis test and answers to exercises after class
数字电路基础(四) 数据分配器、数据选择器和数值比较器
Don't you even look at such a detailed and comprehensive written software test question?

Intranet information collection of Intranet penetration (3)
servlet中 servlet context与 session与 request三个对象的常用方法和存放数据的作用域。

What is the transaction of MySQL? What is dirty reading and what is unreal reading? Not repeatable?
Opencv recognition of face in image
. Net6: develop modern 3D industrial software based on WPF (2)
MySQL中什么是索引?常用的索引有哪些种类?索引在什么情况下会失效?

《统计学》第八版贾俊平第七章知识点总结及课后习题答案
随机推荐
C language do while loop classic Level 2 questions
Database monitoring SQL execution
Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
Keil5 MDK's formatting code tool and adding shortcuts
Statistics 8th Edition Jia Junping Chapter 12 summary of knowledge points of multiple linear regression and answers to exercises after class
我的第一篇博客
Fundamentals of digital circuit (V) arithmetic operation circuit
Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
Function: string storage in reverse order
[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases
What level do 18K test engineers want? Take a look at the interview experience of a 26 year old test engineer
Login the system in the background, connect the database with JDBC, and do small case exercises
servlet中 servlet context与 session与 request三个对象的常用方法和存放数据的作用域。
Using flask_ Whooshalchemyplus Jieba realizes global search of flask
Statistics, 8th Edition, Jia Junping, Chapter 11 summary of knowledge points of univariate linear regression and answers to exercises after class
“Hello IC World”
Statistics 8th Edition Jia Junping Chapter 4 Summary and after class exercise answers
数字电路基础(二)逻辑代数
DVWA exercise 05 file upload file upload
【指针】使用插入排序法将n个数从小到大进行排列