昨日内容回顾
闭包函数
1.定义:定义在函数内部的函数,并且使用外部函数局部名称空间中的名字
2.传参方式之一:在同级别的上面加一些东西然后再用一个函数包起来缩进去
3.从返回值方向研究了从全局用局部名称空间的值
4.实际应用中局部名称空间套局部名称空间,原来所说的局部空间在函数代码体执行结束后就立即关闭,但是在闭包函数的这种情况下会有所不同,只有在内部局部名称空间结束的时候它才会关闭
装饰器
1.本质: 在不改变被装函数的原来的调用方式和内部代码去给被装函数添加新的功能
2.原则:对修改封闭,对扩展开发
装饰器重要推导流程
1.统计某个函数的运行时间
2.将统计函数运行时间的代码封装成了函数
3.直接分装成函数会改变调用方式
4.利用闭包函数传参尝试
5.利用重名替换原来函数的功能
6.函数的参数
7.函数返回值
装饰器模板
def outer(被装饰的函数的函数名):
def inner(*args, **kwargs):
print('执行被装饰对象之前可以做的操作')
res = func(*args, **kwargs)
print('执行被装饰对象之后可以做的操作')
return res
return 内部函数名
'''针对两个地方的*args和**kwargs的作用'''
def index(*args,**kwargs):
pass
def func(*args,**kwargs):
index(*args,**kwargs)
'''
args = ([1,2,3,4],)
kwargs = {'name':'jason','age':18}
index(*([1,2,3,4],),**{'name':'jason','age':18})
index([1,2,3,4],name='jason',age=18)
转换来转换去其实就是给func穿什么相当于给index传什么
'''
func([1,2,3,4],name='jason',age=18)
'''
[1,2,3,4],是多余的位置参数给了args以一个数据值,以元组的形式
name='jason',age=18,是多余的关键字参数给了kwargs,以字典的形式
'''
装饰器语法糖
@outer # 相当于这个,index = outer(index)
def index():
pass
装饰器修复技术
from functools import wraps
def outer(func_name):
@wraps(func_name) # 是为了让装饰器不容易被别人发现,做到真正的以假乱真,不会影响代码,写不写都可以
def inner(*args, **kwargs):
print('执行被装饰对象之前可以做的额外操作')
res = func_name(*args, **kwargs)
print('执行被装饰对象之后可以做的额外操作')
return res
return inner
今日内容
作业讲解
1.编写一个用户认证装饰器
基本要求
执行每个函数的时候必须先校验身份 eg: jason 123
拔高练习(有点难度)
执行被装饰的函数 只要有一次认证成功 那么后续的校验都通过
函数:register login transfer withdraw
提示:全局变量 记录当前用户是否认证
is_login = {'is_login': False, } # 可变类型在局部名称空间中更改的话是不需要去创建一个新的名字
# 编写装饰器
def lonin_auth(func_name):
def inner(*args, **kwargs):
# 判断全局字典is_login对应的值是否True
if is_login.get('is_login'):
# 如果是True,说明用户已经登陆过了,直接叫他执行要执行的操作
res = func_name(*args, **kwargs)
return res
# 校验用户身份
username = input('输入用户名:').strip()
password = input('输入密码:').strip()
if username == 'jason' and password == '123':
res = func_name(*args, **kwargs)
# 登录成功后,执行用户想要执行的操作
is_login['is_login'] = True # 用户登录过后的记录
return res
else:
print('用户名权限不够')
return inner
@lonin_auth
def register():
print('注册功能')
@lonin_auth
def login():
print('登录功能')
@lonin_auth
def transfer():
print('转账功能')
@lonin_auth
def withdraw():
print('体现功能')
register()
login()
transfer()
withdraw()
多层装饰器
def outter1(func1): # func1等于wrapper2
print('加载了outter1')
def wrapper1(*args, **kwargs):
print('执行了wrapper1')
res1 = func1(*args, **kwargs)
return res1
return wrapper1
def outter2(func2): # func2等于wrapper3
print('加载了outter2')
def wrapper2(*args, **kwargs):
print('执行了wrapper2')
res2 = func2(*args, **kwargs)
return res2
return wrapper2
def outter3(func3): # func3等于真正的index函数
print('加载了outter3')
def wrapper3(*args, **kwargs):
print('执行了wrapper3')
res3 = func3(*args, **kwargs)
return res3
return wrapper3
@outter1 # index = outter1(wrapper2)
@outter2 # wrapper2 = outter2(wrapper3)
@outter3 # rapper3 = outter3(正真的index函数名)
def index():
print('from index')
index()
'''
语法糖的功能:
1.会自动将下面紧挨着的函数当作参数传递给@符号后面的函数名(加括号调用)
2.如果语法糖上面还有语法糖那么他的返回值不是函数名,要看他调用函数后的返回值
3.wrapper3 = outter3(正真的index函数名)中的wrapper3是一个函数名,然后上面又是一个语法糖,然后又触发了1的条件
....
4.最后用index去接收
结果
加载了outter3
加载了outter2
加载了outter1
执行了wrapper1
执行了wrapper2
执行了wrapper3
from index
'''
有参装饰器
1.在里加入参数

2.在inner里加入参数

3.正确思路
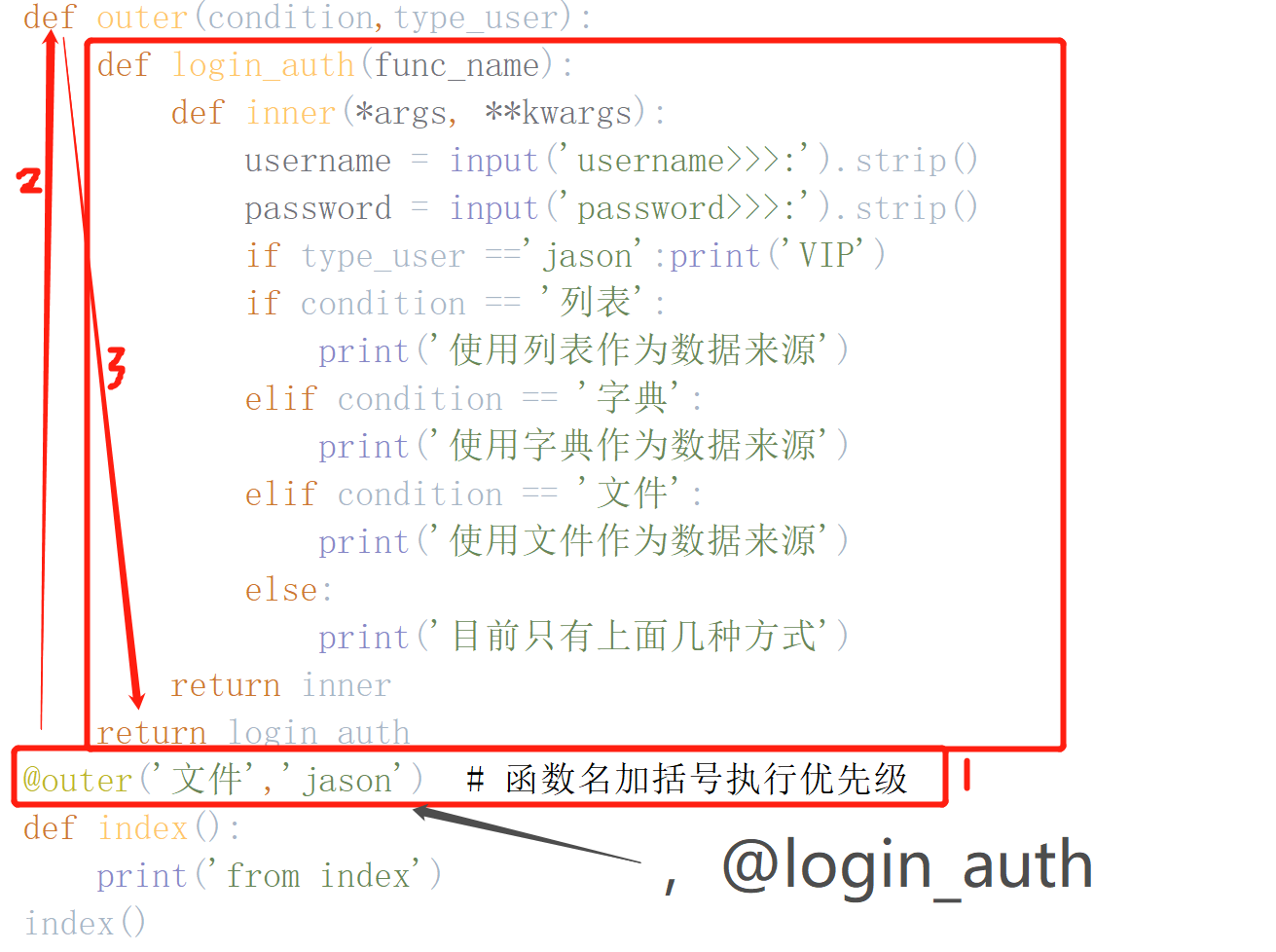
def outer(condition,type_user):
def login_auth(func_name): # 这里不能再填写其他形参
def inner(*args, **kwargs): # 这里不能再填写非被装饰对象所需的参数
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 应该根据用户的需求情况执行不同的代码
if type_user =='jason':print('VIP')
if condition == '列表':
print('使用列表作为数据来源')
elif condition == '字典':
print('使用字典作为数据来源')
elif condition == '文件':
print('使用文件作为数据来源')
else:
print('目前只有上面几种方式')
return inner
return login_auth
@outer('文件','jason') # 函数名加括号执行优先级 @login_auth
def index():
print('from index')
index()
'''
举例说明
在装饰器内部可以切换多种数据来源
1.原本装饰器按照是一步一步向下执行
2.现在是在获取用户名之后有多种情况不再是直接的向下执行,言外之意就是在某个地方需要用到分支情况了
3. if condition == '列表':
print('使用列表作为数据来源')
elif condition == '字典':
print('使用字典作为数据来源')
elif condition == '文件':
print('使用文件作为数据来源')
else:
print('目前只有上面几种方式')
这个时候condition是一个不固定的值,它可以是列表、字典或者文件,而这个值是我们传进来的,那么函数里的传值方式有俩种,这个时候就要看是哪一种的传值
4.在最外面加一层函数
总结:如果我们再写一个装饰器的时候,它的内部需要传入额外的数据来控制代码的分支,这种情况下可以在原有的基础上再套一个函数,并且可以传入多个值,不需要再套函数
'''
递归函数
1.递归函数简介
# 直接调用:自己调用自己
def index():
print('from index')
index()
index()
# 间接调用:俩个函数直接互相调用
def index():
print('from index')
func()
def func():
print('from func')
index()
'''
在python中自己调用自己是有次数限制的,官方给出的限制是1000 有时候可能会有些许偏差(997 998...)
'''
import sys
print(sys.getrecursionlimit()) # 1000 获取递归最大次数
sys.setrecursionlimit(2000) # 可以修改最大次数
print(sys.getrecursionlimit())
2.递归函数的应用场景
递推:一层层往下寻找答案
回溯:根据已知的条件推导最终答案
条件:每次调用都距离答案跟近一点,一次比一次简单,最终必须要有一个结束条件
例题说明:
l1 = [1, [2, [3, [4, [5, [6, [7, [8, [9, [10, ]]]]]]]]]]
# 循环打印出列表中所有的数字
'''
分析过程:
1.for循环l1里面所有的数据值
2.判断当前数据值是否是数字 如果是则打印
3.如果不是则继续for循环里面所有数据值
4.判断当前数据值是否是数字 如果是则打印
5.如果不是则继续for循环里面所有数据值
6.判断当前数据值是否是数字 如果是则打印
....
由此可见,总有一段代码会重复
'''

def get_num(l1):
for i in l1:
if isinstance(i,int):
print(i)
else:
get_num(i)
get_num(l1)
算法之二分法
1.什么是算法?
算法是解决问题的方法,算法永远都在精进,但是很少有最完美的算法。
2.二分法
是算法里面最简单的算法,主要应用于有序序列中,原理是每次查找都将原序列折半,逐渐缩小查找范围的一种算法
每次取中值,如果高了则继续取下半部分的中值,如果低了则取上半部分的中值,以此类推,最后找到正确猜测值。
存在的缺陷:查找的数如果在开头或者结尾 那么二分法效率更低,只能查找有序序列。
例题展示:
l1 = [2, 4, 6, 8, 10, 15, 18, 23, 34, 56, 78, 90, 101, 120]
def get_num(l1, target_num):
# 添加递归函数的结束条件
if len(l1) == 0:
print('找不到')
return
# 1.获取中间那个数,总的长度去整除2,就是中间的那个值
middle_index = len(l1) // 2
middle_value = l1[middle_index]
# 2.判断取到的中间值与我们要找的目标数字谁打谁小,然后分情况讨论,利用if..elif
if target_num > middle_value:
# 3.如果目标函数大于中间数,说明目标函数在右边,既然大一的话那么就说明比它本身大就可以在缩小一点范围
right_l1 = l1[middle_index + 1:]
# 3. 同样在右边在进行同样的操作,查找中间值然后进行比较
# 经过分析得知 应该使用递归函数
print(right_l1)
get_num(right_l1, target_num)
elif target_num < middle_value:
# 4.说明要查找的数在数据集左半边 如何截取左半边
left_l1 = l1[:middle_index] # 左边不需要-1,索引是顾头不顾尾的
# 4.同样在左边在进行同样的操作,查找中间值然后进行比较
# 经过分析得知 应该使用递归函数
print(left_l1)
get_num(left_l1, target_num)
else:
print(target_num)
get_num(l1, 18)