当前位置:网站首页>mpf2_线性规划_CAPM_sharpe_Arbitrage Pricin_Inversion Gauss Jordan_Statsmodel_Pulp_pLU_Cholesky_QR_Jacobi
mpf2_线性规划_CAPM_sharpe_Arbitrage Pricin_Inversion Gauss Jordan_Statsmodel_Pulp_pLU_Cholesky_QR_Jacobi
2022-07-06 21:47:00 【LIQING LIN】
Nonlinear dynamics play a vital role in our world. Linear models are often employed in economics due to being easier to study and their easier modeling capabilities. In finance, linear models are widely used to help price securities and perform optimal portfolio allocation, among other useful things. One significant aspect of linearity in financial modeling is its assurance thata problem terminates at a globally-optimal solution.
In order to perform prediction and forecasting, regression analysis is widely used in the field of statistics to estimate relationships among variables. With an extensive mathematics library being one of Python’s greatest strength, Python is frequently used as a scientific scripting language to aid in these problems. Modules such as the SciPy and NumPy packages contain a variety of linear regression functions for data scientists to work with.
In traditional portfolio management, the allocation of assets follows a linear pattern, and investors have individual styles of investing. We can describe the problem of portfolio allocation as a system of linear equations, containing either equalities or inequalities. These linear systems can then be represented in a matrix form as Ax=B, where A is our known coefficient value, B is the observed result, and x is the vector of values that we want to find out. More often than not, x contains the optimal security weights to maximize our utility. Using matrix algebra, we can efficiently solve for x using either direct or indirect methods.
In this chapter, we will cover the following topics:
- Examining the Capital Asset Pricing Model and the security market line
- Solving for the security market line using regression
- Examining the APT(Arbitrage Pricing Theory套利定价理论) model and performing a multivariate linear regression
- Understanding linear optimization in portfolio allocation
- Performing linear optimization using the Pulp package
- Understanding the outcomes of linear programming
- Introduction to integer programming整数规划简介
- Implementing a linear integer programming model with binary conditions
- Solving systems of linear equations with equalities using matrix linear algebra
- Solving systems of linear equations directly with LU, Cholesky, and QR decomposition
- Solving systems of linear equations indirectly with the Jacobi and Gauss-Seidel method
The Capital Asset Pricing Model and the security market line
A lot of the financial literature devotes exclusive discussions to the Capital Asset Pricing Model (CAPM)资本资产定价模型. In this section, we will explore key concepts that highlight the importance of linearity in finance.
In the famous CAPM, the relationship between risk and rates of return in a security is described as follows:![]()
For a security, i, its returns are defined as![]() and its beta as
and its beta as ![]() .
.![]() is the expected market return.
is the expected market return.
- The CAPM defines the return of the security as the sum of
- therisk-free rate,
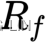 ,
, - and themultiplication of
- the beta
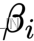 for the security, i,
for the security, i, - withthe risk premium风险溢价.
- The risk premium can be thought of as the market portfolio'sexcess returnsexclusive of the risk-free rate. The following is a visual representation of the CAPM:
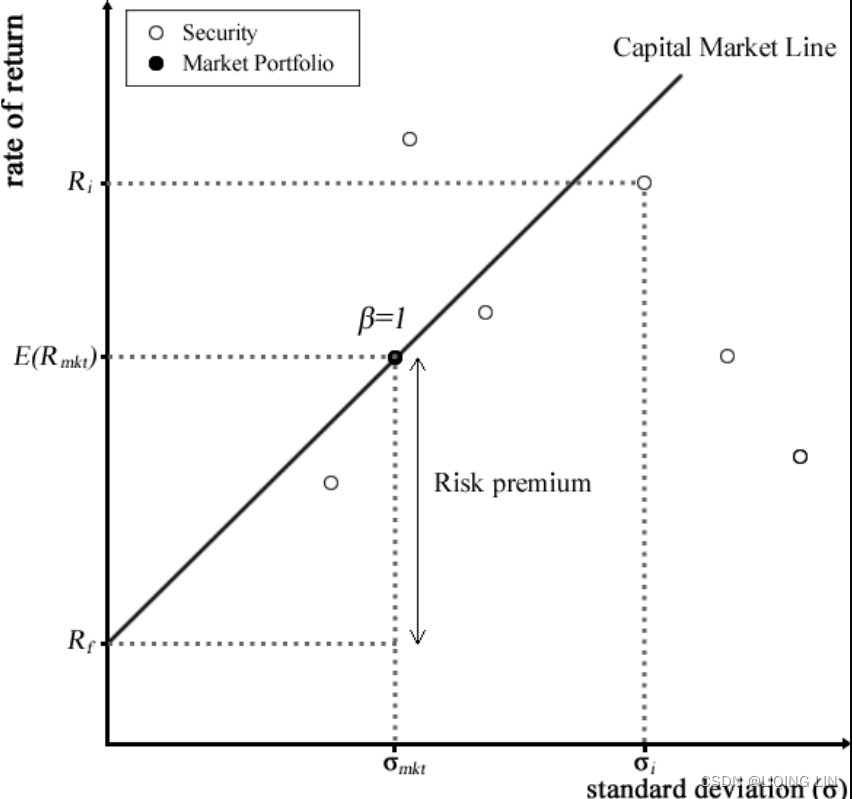
If the stock's beta is 2.0, the risk-free rate is 3%, and the market rate of return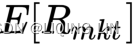 is 7%, the market's excess return is 4% =(7% - 3%). Accordingly, the stock's excess return is 8%= (2 x 4%, multiplying market return by the beta), and the stock's total required return is 11% (8% + 3%, the stock's excess return plus the risk-free rate).
is 7%, the market's excess return is 4% =(7% - 3%). Accordingly, the stock's excess return is 8%= (2 x 4%, multiplying market return by the beta), and the stock's total required return is 11% (8% + 3%, the stock's excess return plus the risk-free rate).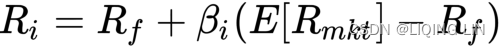
- the beta
- therisk-free rate,
Beta![]() is a measure of thesystematic risk of a stock – a risk that cannot be diversified away. In essence, it describesthe sensitivity of stock returns with respect to movements(sigma)in the market. For example,
is a measure of thesystematic risk of a stock – a risk that cannot be diversified away. In essence, it describesthe sensitivity of stock returns with respect to movements(sigma)in the market. For example,
- a stock with a beta
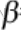 of zero produces no excess returns regardless of the direction the market moves in. It can only grow at a risk-free rate.
of zero produces no excess returns regardless of the direction the market moves in. It can only grow at a risk-free rate. - A stock with a betaof 1 indicates that the stock moves perfectly with the market.
The beta![]() is mathematically derived by dividingthe covariance ofreturns between the stock and the marketbythe variance ofthe market returns.
is mathematically derived by dividingthe covariance ofreturns between the stock and the marketbythe variance ofthe market returns.
The CAPM model(Capital Asset Pricing Model) measuresthe relationship between risk and rates of returnsfor every stock in the portfolio basket. By outlining the sum of this relationship, we obtain combinations or weights of risky securities that produce the lowest portfolio risk for every level of portfolio return. An investor who wishes to receive a particular return would own one such combination of an optimal portfolio that provides the least risk possible. Combinations of optimal portfolios lie along a line called the efficient frontier有效边界.
Along the efficient frontier, there exists a tangent point that denotes the best optimal portfolio available and gives the highest rate of returnin exchange for the lowest risk possible. This optimal portfolio at the tangent point is known as the market portfolio.
There exists a straight line drawn from the market portfolio to the risk-free rate![]() . This line is called the Capital Market Line (CML). The CML can be thought of as the highest Sharpe ratio available among all the other Sharpe ratios of optimal portfolios. The Sharpe ratio
. This line is called the Capital Market Line (CML). The CML can be thought of as the highest Sharpe ratio available among all the other Sharpe ratios of optimal portfolios. The Sharpe ratio![]() is a risk-adjusted performance measure defined as the portfolio's excess returnsover the risk-free rateper unit of its risk in standard deviations. Investors are particularly interested in holding combinations of assets along the CML line. The following diagram illustrates the efficient frontier, the market portfolio, and the CML:
is a risk-adjusted performance measure defined as the portfolio's excess returnsover the risk-free rateper unit of its risk in standard deviations. Investors are particularly interested in holding combinations of assets along the CML line. The following diagram illustrates the efficient frontier, the market portfolio, and the CML:
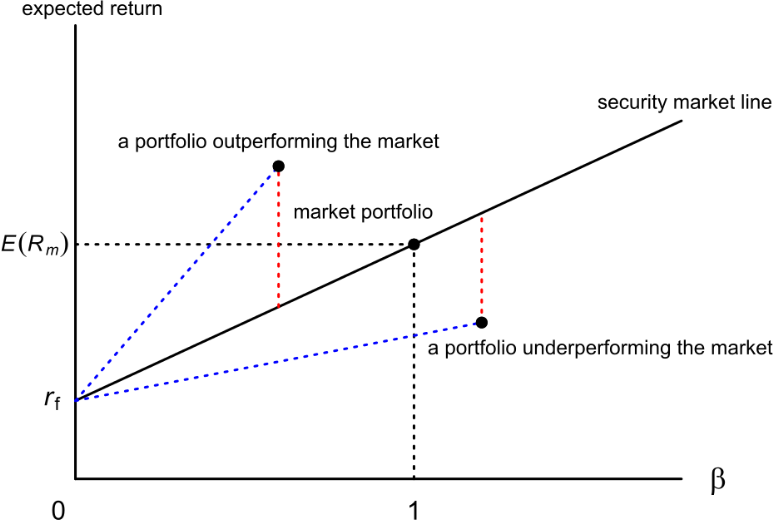 当一个单一资产落在证券市场线的上方,代表在同样风险下有比较高的回报,也就是资产被低估,应该买进;当落于证券市场线下方,代表资产被高估,应该卖出。
当一个单一资产落在证券市场线的上方,代表在同样风险下有比较高的回报,也就是资产被低估,应该买进;当落于证券市场线下方,代表资产被高估,应该卖出。
Another line of interest in CAPM studies is the Security Market Line (SML). The SML plots the asset's expected returnsagainstits beta.{ Beta is a measure of the systematic risk of a stock. In essence, it describes the sensitivity of stock returns with respect to movements(sigma: volatility) in the market.} For a security with a beta value of 1, its returns perfectly match the market's returns. Any security priced被定价 above the SML is deemed to be undervalued since investors expect a higher return given the same amount of risk. Conversely, any security priced below the SML is deemed to be overvalued, as follows: 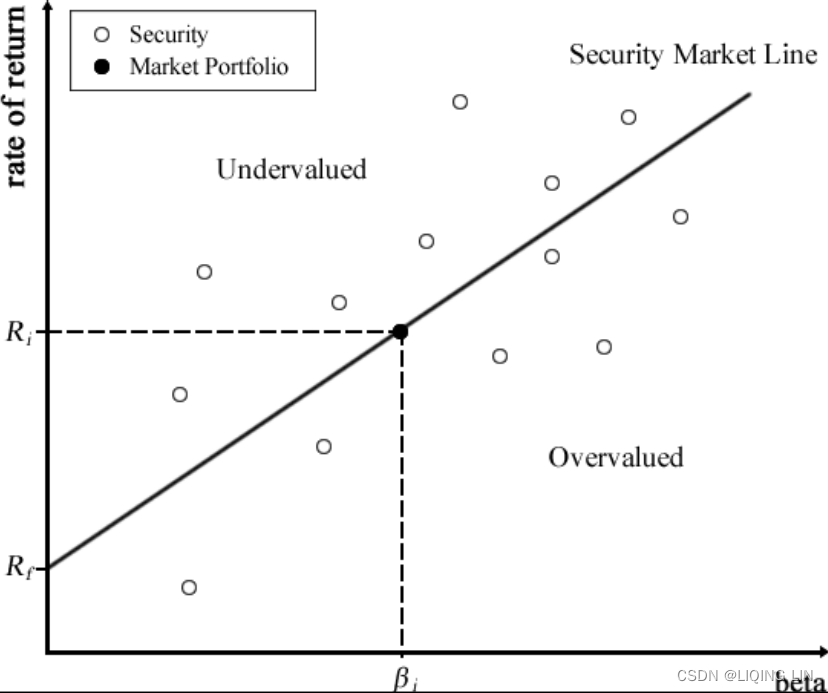
Suppose we are interested in finding the beta,![]() , of a security. We can regress the company's stock returns,
, of a security. We can regress the company's stock returns,![]() , against the market's returns,
, against the market's returns,![]() , along with an intercept, α, in the form of the
, along with an intercept, α, in the form of the![]() equation.
equation.
Consider the following set of stock return and market return data measured over five time periods: 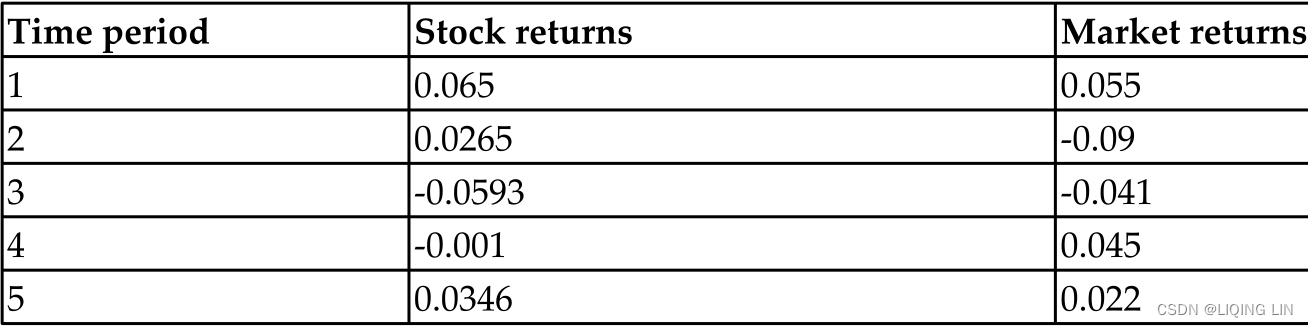
Using the stats module of SciPy, we will perform a least-squares regression on the CAPM model(Capital Asset Pricing Model), and derive the values of α and![]() by running the following code in Python:
by running the following code in Python:
# Linear regression with Scipy
from scipy import stats
stock_returns = [0.065, 0.0265, -0.0593, -0.001, 0.0346]
mkt_returns = [0.055, -0.09, -0.041, 0.045, 0.022]
# beta : slope
# alpha : intercept,
# r_value: The Pearson correlation coefficient,
# The square of rvalue is equal to the coefficient of determination
# pvalue : The p-value for a hypothesis test whose null hypothesis
# is that the slope is zero,
# using Wald Test with t-distribution of the test statistic.
# See alternative above for alternative hypotheses.
# stderr: Standard error of the estimated slope (gradient),
# under the assumption of residual normality
# The square root of the MSE of the full model
beta, alpha, r_value, p_value, std_err = \
stats.linregress(stock_returns, mkt_returns)The scipty.stats.linregress function returns five values:
- the slope(beta) of the regression line,
- the intercept(alpha) of the regression line,
- the correlation coefficient(r_value:https://blog.csdn.net/Linli522362242/article/details/125128240, r_value**2 (or
 ) measure that assesses the ability of a model to predict or explain an outcome in the linear regression setting,
) measure that assesses the ability of a model to predict or explain an outcome in the linear regression setting,
The coefficient of determination shows only association. As with linear regression, it is impossible to use to determine whether one variable causes the other. In addition, the coefficient of determination shows only the magnitude of the association, not whether that association is statistically significant.
In general, a high r_value**2 indicates that the model is a good fit for the data), - the p-value (and lastly P-value explains the significance of the model. A P-value value smaller than 0.05 is considered significant and means there is a 5% chance that the data is following the trend line randomly
) for a hypothesis test with a null hypothesis of a 0 slope(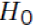 , Alternative Hypothesis
, Alternative Hypothesis 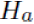 (OR
(OR 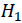 ) is the the opposite of https://blog.csdn.net/Linli522362242/article/details/91037961),
) is the the opposite of https://blog.csdn.net/Linli522362242/article/details/91037961), - and the standard error of the estimate. We are interested in finding the slope and intercept of the line by printing the values of beta and alpha, respectively:

print( beta, alpha ) ![]()
The beta(slope) of the stock is 0.5077 and the alpha(intercept) is nearly zero.
The equation that describes the SML(Security Market Line) can be written as follows: ![]() or
or![]()
The term
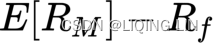 is the market risk premium, and
is the market risk premium, and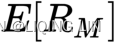 is the expected return on the market portfolio.
is the expected return on the market portfolio.- is the return on the risk-free rate,
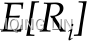 is the expected return on asset, i,
is the expected return on asset, i,- and is the beta of the asset.
Suppose the risk-free rate![]() is 5% and the market risk premium
is 5% and the market risk premium![]() is 8.5%. What is the expected return
is 8.5%. What is the expected return![]() of the stock?
of the stock?
Based on the CAPM, an equity with a beta![]() of 0.5077 would have a risk premium of 0.5077×8.5%,= 4.3%. The risk-free rate
of 0.5077 would have a risk premium of 0.5077×8.5%,= 4.3%. The risk-free rate![]() is 5%, so the expected return
is 5%, so the expected return![]() on the equity is 9.3%.
on the equity is 9.3%.
If the security is observed in the same time period to have a higher return (for example, ![]() =10.5%) thanthe expected stock return(
=10.5%) thanthe expected stock return(![]() =9.3%), the security can be said to be undervalued, since the investor can expect a greater return for the same amount of risk
=9.3%), the security can be said to be undervalued, since the investor can expect a greater return for the same amount of risk
{ Beta is a measure of the systematic risk of a stock. In essence, it describes the sensitivity of stock returns with respect to movements(sigma: volatility) in the market.}. (Any security priced被定价 above the SML is deemed to be undervalued since investors expect a higher return given the same amount of risk. Conversely, any security priced below the SML is deemed to be overvalued, as follows)
Conversely, should the return of the security be observed to have a lower return (for example, ![]() =7%) than the expected return (
=7%) than the expected return (![]() =9.3%) as implied by the SML, the security can be said to be overvalued. The investor receives a reduced return while assuming the same amount of risk.
=9.3%) as implied by the SML, the security can be said to be overvalued. The investor receives a reduced return while assuming the same amount of risk.
The Arbitrage Pricing Theory model套利定价理论模型
The CAPM(Capital Asset Pricing Model) suffers from several limitations, such as the use of a mean-variance framework and the fact that returns are captured by one risk factor – the market risk factor. In a well-diversified portfolio 良好的分散 投资组合, the unsystematic risk of various stocks cancels out and is essentially eliminated.
The Arbitrage Pricing Theory (APT) model was put forward to address these shortcomings and offers a general approach of determining the asset pricesother than the mean and variances.
The APT model assumes that the security returns are generated according to multiple factor models, which consist of a linear combination of several systematic risk factors. Such factors could be
- the inflation rate,
- GDP(Gross Domestic Product) growth rate,

- real interest rates,
- or dividends.
The equilibrium asset pricing equation according to the APT model is as follows: ![]()
Here,
- is the expected rate of return on the isecurity,
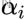 is the expected return on the istock if all factors are negligible如果所有因素都可以忽略不计,
is the expected return on the istock if all factors are negligible如果所有因素都可以忽略不计, is the sensitivity of the ith assetto the jth factor,
is the sensitivity of the ith assetto the jth factor,- and
 is the value of the jth factor that influences the return on the i security.
is the value of the jth factor that influences the return on the i security.
Since our goal is to find all values of ![]() and
and ![]() (all
(all ![]() , we will perform a multivariate linear regression on the APT model.
, we will perform a multivariate linear regression on the APT model.
Multivariate linear regression of factor models
Many Python packages, such as SciPy, come with several variants of regression functions. In particular, the statsmodels package is a complement补充 to SciPy with descriptive statistics and the estimation of statistical models. The official page for Statsmodels is https://www.statsmodels.org/stable/index.html
If Statsmodels is not yet installed in your Python environment, run the following command to do so:
pip install -U statsmodels
If you have an existing package installed, the -U switch tells pip to upgrade the selected package to the newest available version.
In this example, we will use the ols function of the statsmodels module to perform an ordinary least-squares regression and view its summary.
Let's assume that you have implemented an APT model with 7 factors![]() that return the values of Y. Consider the following set of data collected over 9 time periods(or 9 instances), i=1 to i=9.
that return the values of Y. Consider the following set of data collected over 9 time periods(or 9 instances), i=1 to i=9. ![]() to
to ![]() are independent variables observed at each period. The regression problem is therefore structured as follows:
are independent variables observed at each period. The regression problem is therefore structured as follows:![]()
#######https://blog.csdn.net/Linli522362242/article/details/104005906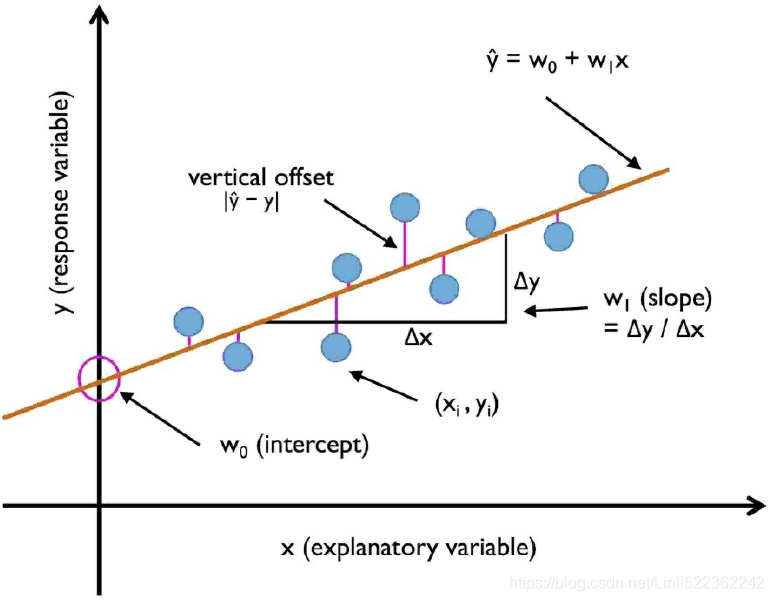
Equation 4-1. Linear Regression model prediction (X0==1, X0 *![]() ==
==![]() )
)
• ŷ is the predicted value.
• n is the number of features.
• xi is the ith feature value. e.g. X1 X2 X3 ... Xn
• θj is the jth model parameter (including the bias term θ0 and the feature weights θ1, θ2, ⋯, θn).
This can be written much more concisely using a vectorized form, as shown in Equation 4-2.

#######
A simple ordinary least-squares regression on values of X and Y can be performed with the following code:
# Least squares regression with statmodels
import numpy as np
import statsmodels.api as sm
# Generate some sample data
num_periods = 9 # i=1 ~i=9
all_values = np.array([np.random.random(8)
for i in range(num_periods)
])
all_values 
# Filter the data
y_values = all_values[:,0] # 1st column values as Y
x_values = all_values[:,1:] # all other values as X
# add_constant : Add a column of ones to an array.
x_values = sm.add_constant(x_values) # Include the intercept
x_values
results = sm.OLS( y_values, x_values ).fit() # Regress and fit the model
print(results.summary()) The OLS regression results will output a pretty long table of statistical information. However, our interest lies in one particular section that gives us the coefficients of our APT model: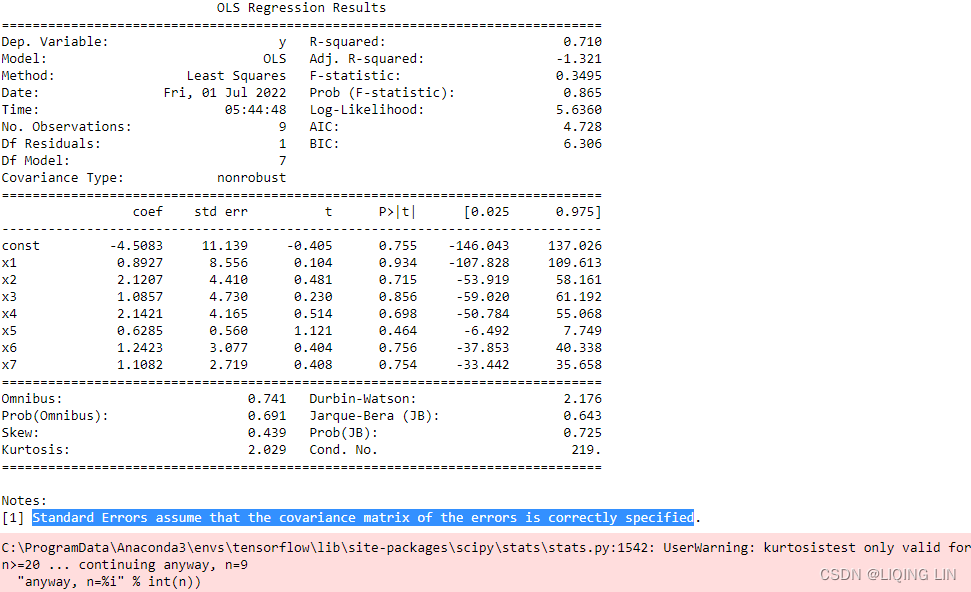
The coef column gives us the coefficient values of our regression for the c constant (intercept), and![]() until
until![]() . Similarly, we can use the params property to display these coefficients of interest:
. Similarly, we can use the params property to display these coefficients of interest:
print(results.params) ![]()
Both the function calls produce the same coefficient values for the APT model in the same order.
Linear optimization
In the CAPM and APT pricing theories, we assumed linearity in the models and solved for expected security prices using regressions in Python.
As the number of securities in our portfolio increases, certain limitations are introduced as well. Portfolio managers would find themselves constrained by these rules in pursuing certain objectives mandated/ ˈmændeɪtɪd /被委托的 by investors.
Linear optimization helps overcome the problem of portfolio allocation. Optimization focuses on minimizing or maximizing the value of objective functions. Some examples include maximizing returns and minimizing volatility. These objectives are usually governed by certain regulations, such as a no short-selling rule, or limits on the number of securities to be invested禁止卖空规则或投资证券数量的限制.
Unfortunately, in Python, there is no single official package that supports this solution. However, there are third-party packages available with an implementation of the simplex algorithm for linear programming. For the purpose of this demonstration, we will use Pulp, an open source linear programming modeler, to assist us in this particular linear programming problem.
Getting Pulp
You can obtain Pulp from https://coin-or.github.io/pulp/main/installing_pulp_at_home.html. The project page contains a comprehensive list of documentation to help you get started with your optimization process.
You may also obtain the Pulp package with the pip package manager:
pip install pulp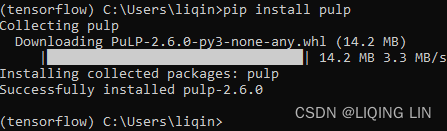
A maximization example with linear programming Pulp库求解线性规划问题
Suppose that we are interested in investing in 2 securities, X and Y. We would like to find out the actual number of units to invest for every 3 units of the security X and 2 units of the security Y, such that the total number of units invested is maximized![]() , where possible. However, there are certain constraints on our investment strategy:
, where possible. However, there are certain constraints on our investment strategy:
- For every 2 units of the security X invested and 1 unit of the security Y invested, the total volume must not exceed 100
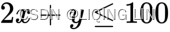
- For every unit of the securities X and Y invested, the total volume must not exceed 80
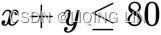
- The total volume allowed to invest in the security X must not exceed 40
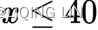
- Short-selling is not allowed for securities证券不允许卖空
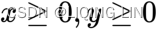
The maximization problem can be mathematically represented as follows:![]()
subject to: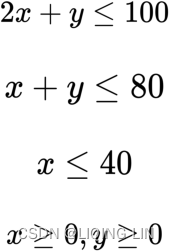
By plotting the constraints on an x by y graph, a set of feasible solutions can be seen, given by the shaded area: 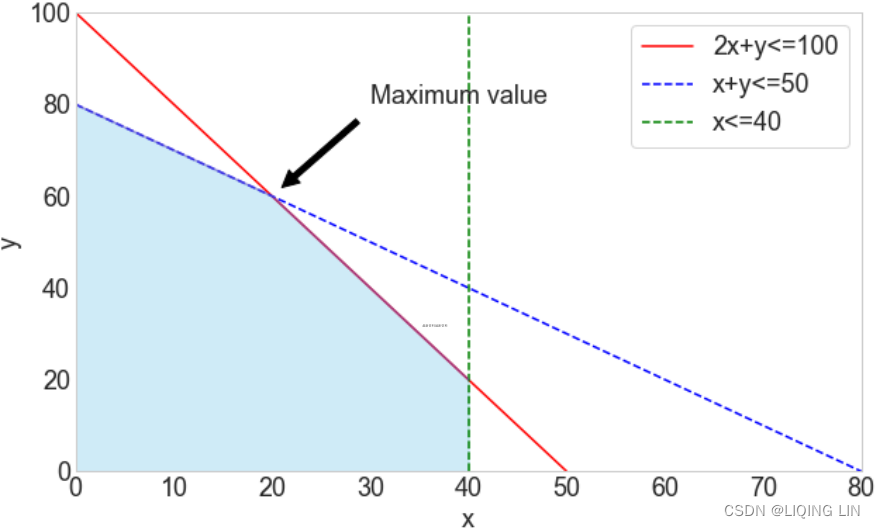
The problem can be translated into Python with the pulp package, as follows:
# A linear optimization problem with 2 variables
import pulp
# https://coin-or.github.io/pulp/technical/pulp.html#pulp.LpVariable
# pulp.LpVariable(name, lowBound=None, upBound=None, cat='Continuous', e=None)
x = pulp.LpVariable('x', lowBound=0) # x>0, Continuous
y = pulp.LpVariable('y', lowBound=0)
# classpulp.LpProblem(name='NoName', sense=1)
# name – name of the problem used in the output .lp file
# sense – of the LP problem objective. Either LpMinimize (default) or LpMaximize.
problem = pulp.LpProblem( 'A simple maximization objective', pulp.LpMaximize)
problem += 3*x + 2*y,'The objective fuction'
problem += 2*x + y <= 100,'1st constraint'
problem += x+y <= 80,'2nd constant'
problem += x<= 40,'3rd constant'
problem.solve() ![]()
- The LpVariable function declares a variable to be solved.
- The LpProblem function initializes the problem with a text description of the problem and the type of optimization, which in this case is the maximization method.
- The += operation allows an arbitrary number of constraints to be added, along with a text description.
- Finally, the .solve() method is called to begin performing linear optimization.
- To show the values solved by the optimizer, use the .variables() method to loop through each variable and print out its varValue .
The following output is generated when the code runs:
print("Maximization Results:")
for variable in problem.variables():
print( variable.name, "=", variable.varValue) 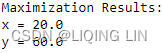
The results show that obtaining the maximum value of 180![]() is possible when the value of x is 20 and y is 60 while fulfilling the given set of constraints.
is possible when the value of x is 20 and y is 60 while fulfilling the given set of constraints.
Outcomes of linear programs
There are three outcomes in linear optimization, as follows:
- A local optimal solution to a linear program is a feasible solution with a closer objective function value than all other feasible solutions close to it. It may or may not be the global optimal solution, a solution that is better than every feasible solution.
- A linear program is infeasible不可行的 if a solution cannot be found.
- A linear program is unbounded if the optimal solution is unbounded or is infinite无界或无限的无界或无限的.
Integer programming
In the simple optimization problem we investigated earlier, A maximization example with linear programming, the variables were allowed to be continuous or fractional. What if the use of fractional values or results is not realistic? This problem is called the linear integer programming problem, where all the variables are restricted as integers. A special case of an integer variable is a binary variable that can either be 0 or 1. Binary variables are especially useful in model decision-making when given a set of choices.
Integer programming models are frequently used in operational researchto model real-world working problems. More often than not, stating nonlinear problems in a linear or even binary fashion requires more art than science.
A minimization example with integer programming
Suppose we must go for 150 contracts in a particular over-the-counter exotic security from three dealers.
- Dealer X quoted $500 per contract plus handling fees of $4,000, regardless of the number of contracts sold.
- Dealer Y charges $350 per contract plus a transaction fee of $2,000.
- Dealer Z charges $450 per contract plus a fee of $6,000.
- Dealer X will sell at most 100 contracts,
dealer Y at most 90,
and dealer Z at most 70. - The minimum transaction volume from any dealer is 30 contracts if any are transacted with that dealer. How should we minimize the cost of purchasing 150 contracts?
Using the pulp package, let's set up the required variables:
# An example of implementing an integer programming model with binary conditions
import pulp
dealers = ['X', 'Y', 'Z']
variable_costs = {'X': 500, 'Y': 350, 'Z': 450}
fixed_costs = {'X':4000, 'Y':2000, 'Z':6000}
# Define Pulp variables to solve
# dicts(name, indexs, lowBound=None, upBound=None, cat=0, indexStart=[])
# indexs – A list of strings of the 'keys' to the dictionary of LP variables,
# and the main part of the variable name itself
quantities = pulp.LpVariable.dicts('quantity', dealers, lowBound=0,
cat=pulp.LpInteger)
is_orders = pulp.LpVariable.dicts('orders', dealers,
cat=pulp.LpBinary
)The dealersvariable simply contains the dictionary identifiers that are used to reference lists and dictionaries later on. The variable_costs and fixed_costsvariables are dictionary objects that contain the respective contract cost and fees charged by each dealer. The Pulp solver solves for the values of quantities and is_orders , which are defined by the LpVariable function. The dicts() method tells Pulp to treat the assigned variable as a dictionary object, using the dealers variable for referencing. Note that the quantities variable has a lower boundary (0) that prevents us from entering a short position in any securities. The is_orders values are treated as binary objects, indicating whether we should enter into a transaction with any of the dealers.
What is the best approach to modeling this integer programming problem? At first glance, it seems fairly straightforward by applying this equation:
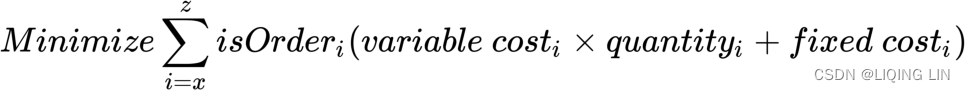
Where the following is true:
The equation simply states that we want to minimize the total costs with the binary variable, ![]() , to determinewhether to account for the costs associated with buying from a specific dealer.
, to determinewhether to account for the costs associated with buying from a specific dealer.
Let's implement this model in Python:
# classpulp.LpProblem(name='NoName', sense=1)
# name – name of the problem used in the output .lp file
# sense – of the LP problem objective. Either LpMinimize (default) or LpMaximize.
model = pulp.LpProblem('A cost minimization problem', pulp.LpMinimize)
# This is an example of implementing an integer programming model
# with binary variables the wrong way.
model += sum( [ (variable_costs[i]*quantities[i] + fixed_costs[i]) * is_orders[i]
for i in dealers
] ),'Minimize portfolio cost'
model += sum( [ quantities[i]
for i in dealers
] )==150,'Total contracts required'
model += 30 <= quantities['X'] <= 100,'Boundary of total volume of X'
model += 30 <= quantities['Y'] <= 90,'Boundary of total volume of Y'
model += 30 <= quantities['Z'] <= 70,'Boundary of total volume of Z'
model.solve() # You will get an error running this code!What happens when we run the solver? Check it out:
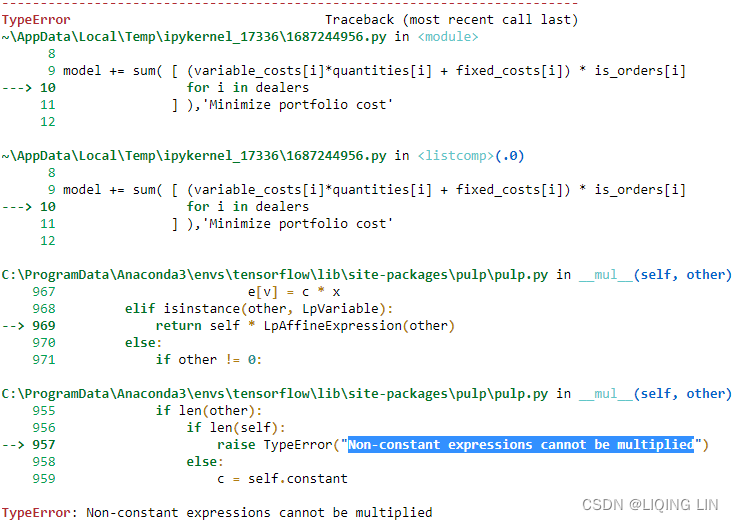
As it turned out, we were trying to perform multiplication on two unknown variables, quantities and is_order, which unknowingly led us to perform nonlinear programming. (This error is a nonlinear problem caused by multiplying 2 unknown variables) Such are the pitfalls陷阱 encountered when performing integer programming.
How should we solve this problem? We can consider using binary variables, as shown in the next section.
Integer programming with binary conditions
Another method for formulating the minimization objective is to place all unknown variables in a linear fashion such that they are additive:
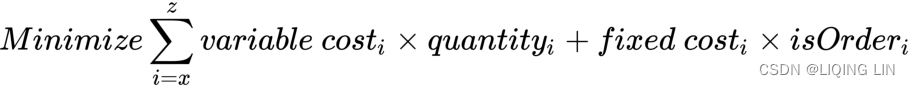
Comparing with the previous objective equation, we would obtain the same fixed cost values. However, the unknown variable, ![]() , remains in the first term of the equation. Hence, the
, remains in the first term of the equation. Hence, the ![]() variable is required to be solved as a function of
variable is required to be solved as a function of ![]() , such that the constraints are stated as follows:
, such that the constraints are stated as follows: 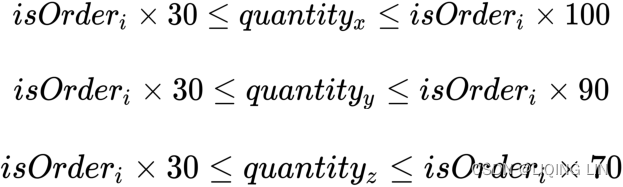
Let’s apply these formulas in Python:
# classpulp.LpProblem(name='NoName', sense=1)
# name – name of the problem used in the output .lp file
# sense – of the LP problem objective. Either LpMinimize (default) or LpMaximize.
model = pulp.LpProblem('A cost minimization problem', pulp.LpMinimize)
# This is an example of implementing an integer programming model
# with binary variables the correct way.
model += sum( [variable_costs[i]*quantities[i] + fixed_costs[i]*is_orders[i]
for i in dealers
] ),'Minimize portfolio cost'
# s.t.
model += sum( [ quantities[i]
for i in dealers
] )==150,'Total contracts required'
model += is_orders['X']*30 <= quantities['X'] <= is_orders['X']*100,'Boundary of total volume of X'
model += is_orders['Y']*30 <= quantities['Y'] <= is_orders['Y']*90,'Boundary of total volume of Y'
model += is_orders['Z']*30 <= quantities['Z'] <= is_orders['Z']*70,'Boundary of total volume of Z'
model.solve() ![]() # There is no multiplication of 2 unknown variables here
# There is no multiplication of 2 unknown variables here
What happens when we try to run the solver? Let's see:
print('Minimization Results:')
for variable in model.variables():
print(variable, '=', variable.varValue)
print( 'Total cost:', pulp.value(model.objective) ) 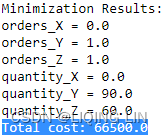 The output tells us that
The output tells us that
- buying 90 contracts from dealer Y
- and 60 contracts from dealer Z
- gives us the lowest possible cost of $66,500 while fulfilling all other constraints.
As we can see, careful planning is required in the design of integer programming models to arrive at an accurate solution in order for them to be useful in decision-making.
Direct Methods for Solving Linear Systems of Equations
This section covers direct methods for solving linear systems of equations. Later, we'll also cover iterative methods; the distinction will be obvious once both types of methods are discussed.
Solving systems of linear equations求解线性方程组
Recall the three basic rules for matrix manipulation from linear algebra:
- Switching two rows or columns does not change the solution of the linear system.
切换两行或两列不会改变线性系统的解。 - Any row can be multiplied by a constant without changing the solution of the linear system.
任何行都可以乘以常数而不改变线性系统的解。 - Any row or linear multiple of a row can be added/subtracted to/from another row without changing the solution of the linear system.
任何行或行的线性倍数都可以添加到另一行/从另一行减去,而不会改变线性系统的解。
Consider the system of equations:
We can write in augmented matrix form: 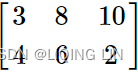
We can multiply the 1st row (![]() ) by
) by![]() and add it to the 2nd row (
and add it to the 2nd row (![]() ), etc...
), etc... 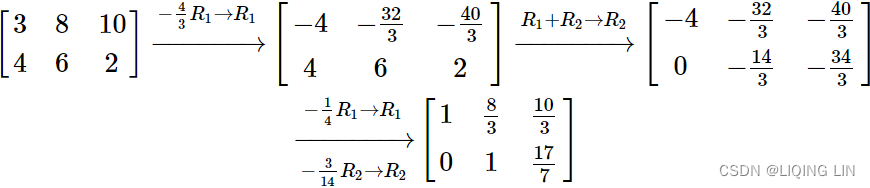
By inspection we can see that ![]() we can then substitute this solution into a modified first equation
we can then substitute this solution into a modified first equation ![]()
and solve for ![]() . The final solution is
. The final solution is ![]() .
.
This procedure is called Gaussian elimination.
Stability of Gaussian elimination
Recall that another way of writing a linear system of equations in matrix form is![]() where
where
- A is the coefficient matrix,
 is the vector of unknowns,
is the vector of unknowns,- and
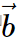 is the right-hand side vector.
is the right-hand side vector.
One method of determining if a linear system has a solution is to take the determinate of the A matrix(A 矩阵的行列式). If the determinate ofA =0(如果A 的行列式=0) then the matrix is said to be singular奇异的 and the system either has no solution or an infinite number of solutions.
A matrix that is near-singular接近奇异 is said to be ill-conditioned病态的 whereas one that is far from singular远离奇异 is said to be well-conditioned良态的. There is a notion of condition number条件数 that mathematically quantifies a matrix's amenability to numeric computations with matrices having high condition numbers高条件数 being well-conditioned and matrices with low condition numbers低条件数 being ill-conditioned. We will return to condition numbers in more detail when we discuss singular value decomposition. Below is an example of two matrices A and B. A is an ill-conditioned matrix, B is well-conditioned.
The determinant行列式 of a 2-D array  is a*d - b*c:
is a*d - b*c:
A = np.array([[1, 1],
[1, 1.0001]
])
# Compute the determinant of an array.
np.linalg.det(A) # return Determinant of A ![]() <==
<== ![]() <== a*d - b*c
<== a*d - b*c
If we were to change the last entry of A to d=1, it would be singular since a*d - b*c =1*1-1*1 =0.
A is an ill-conditioned matrix since the determinate ofA is close to 0
B = np.array([[0.0001, 1],
[1 , 1]
])
# Compute the determinant of an array.
np.linalg.det(B) # return Determinant of A ![]() <==
<==![]() <== a*d - b*c
<== a*d - b*c
B is well-conditioned matrix since the determinate ofB is far from 0
To illustrate the ill-conditioning of A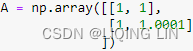 in another way let's consider two very close right-hand side vectors,
in another way let's consider two very close right-hand side vectors, ![]() :
:
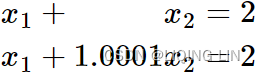 (1)
(1)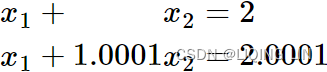 (2)
(2)
The system of equations (1) has the solution ![]() , and the system of equations (2) has the solution
, and the system of equations (2) has the solution ![]() . Notice that a change in the fifth digit of
. Notice that a change in the fifth digit of ![]() (2.0001)→ was amplified to a change in the first digit of the solution
(2.0001)→ was amplified to a change in the first digit of the solution![]() . Even the most robust numerical method will have trouble with this sensitivity to small perturbations(/ ˌpɜːrtərˈbeɪʃns /扰动).
. Even the most robust numerical method will have trouble with this sensitivity to small perturbations(/ ˌpɜːrtərˈbeɪʃns /扰动).
Now I would like to illustrate that even a well-conditioned matrix like B![]() can be ruined by a poor algorithm. Consider the matrix B with the right-hand side vector,
can be ruined by a poor algorithm. Consider the matrix B with the right-hand side vector, ![]() =[1,2] and let's proceed with Gaussian elimination.
=[1,2] and let's proceed with Gaussian elimination. 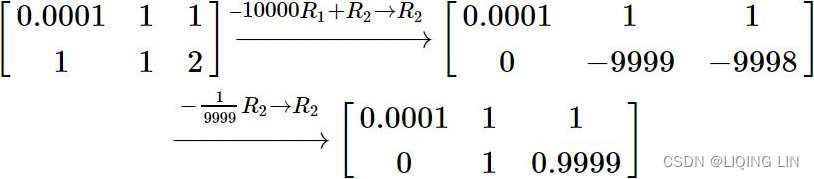 <==
<==![]()
by inspection we see that ![]() , now we can back substitute into the first equation
, now we can back substitute into the first equation
![]()
and solve for ![]() . The final solution is
. The final solution is ![]() .the exact solution
.the exact solution
Now let us do the same computation, this time on a computer that rounds the results of the computations to 3 decimal places (a machine epsilon of 0.0001 :机械误差极小值0.0001), the resulting matrix after manipulations would be
 The leadingnon-zero entryof the row you are using to eliminate entries below is called the pivot. 0.0001 is thepivot in this example.
The leadingnon-zero entryof the row you are using to eliminate entries below is called the pivot. 0.0001 is thepivot in this example.
by inspection we see that ![]() and back substitution yields
and back substitution yields ![]() . This is the incorrect solution brought on by the small pivot 0.0001. For this matrix Gaussian elimination is a poor algorithm. Fortunately there is an easy solution: exchange rows.
. This is the incorrect solution brought on by the small pivot 0.0001. For this matrix Gaussian elimination is a poor algorithm. Fortunately there is an easy solution: exchange rows.
Now lets do the same computation on the same computer that rounds off the computation to 3 decimal places. This time we will exchange the rows before proceeding with the Gaussian elimination. Eliminating some detail we can see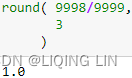
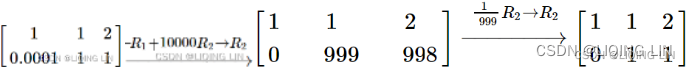
by inspection we see that ![]() , and back substitution yields
, and back substitution yields ![]() =1. We can see that this solution differs from the exact solution
=1. We can see that this solution differs from the exact solution![]() only by the roundoff error of the computer. Exchanging rows to obtain the largest possible pivot is called partial pivoting. Exchanging both rows and columns to obtain the largest possible pivot is called full pivoting. Full pivoting will result in the most stable algorithm but requires more computations and the requirement of tracking column permutations置换. For most matrices partial pivoting is sufficient enough for stability.
only by the roundoff error of the computer. Exchanging rows to obtain the largest possible pivot is called partial pivoting. Exchanging both rows and columns to obtain the largest possible pivot is called full pivoting. Full pivoting will result in the most stable algorithm but requires more computations and the requirement of tracking column permutations置换. For most matrices partial pivoting is sufficient enough for stability.
Gaussian elimination高斯消元 with back substitution and partial pivoting
Pseudocode is a human readable computer algorithm description. It omits any language specific syntax in favor of clarity using general programming flow control and conditional statements.
Consider a linear system with n equations and n unknowns: 

def gauss_solve(A, b):
# Concontanate the matrix A and right hand side column vector b
# into one matrix
temp_mat = np.c_[A,b]
# Get the number of rows
n = temp_mat.shape[0]
# Loop over rows
for r in range(n):
# Find the pivot index
# by looking down the rth column 'from the rth row' to find
# the maximum (in magnitude) entry.
p_index = np.abs( temp_mat[r:,r] ).argmax()
# We have to reindex the pivot index to be
# the appropriate entry in the entire matrix,
# not just from the ith row down.
p_index += r # since 'from the rth row'
# 'Swapping rows' to make the maximal entry the pivot (if needed).
if p_index != r:
temp_mat[ [p_index, r] ] = temp_mat[ [r, p_index] ]
# Eliminate all entries below the pivot
factors_vertical = temp_mat[r+1:,r] / temp_mat[r,r]
temp_mat[r+1:] -= factors_vertical[:, np.newaxis]*temp_mat[r]
# Allocating space for the solution vector
x = np.zeros_like(b, dtype=np.double)
# Here we perform the 'back-substitution'.
# Initializing with the last row.
x[-1] = temp_mat[-1,-1] / temp_mat[-1,-2]
# Looping over rows in 'reverse' (from the bottom up),
# starting with the second to last row,
# because the last row solve was completed in the last step.
for r in range(n-2, -1, -1):
# a[r,n+1] - sum( a[r,r:n+1] )
x[r] = ( temp_mat[r,-1] - np.dot( temp_mat[r,r+1:-1],
x[r+1:]
)
) /temp_mat[r,r]
#OR x[r] = ( temp_mat[r,-1] - temp_mat[r,r:].dot(x[r:]) ) / temp_mat[r,r]
# since x[r]==0 and 3*0 == 0
return x 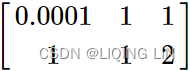
A = np.array([[0.0001, 1],
[1, 1]
])
b = np.array([1,
2
])
np.round( gauss_solve(A, b),
3 ) ![]()
Gauss-Jordan elimination
Gauss-Jordan elimination simply adds steps to the simple Gauss elimination procedure to produce a matrix that is in reduced row echelon(/ ˈeʃəlɑːn /梯形) form. This is done by eliminating values both above and below the pivots and ensuring that each pivot has the value 1.
Starting where we ended on the exact solution of matrix B earlier we can simply add two steps to produce a reduced row echelon matrix. 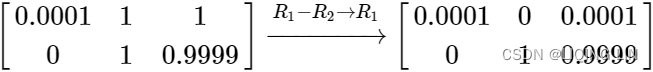
then we normalize the first equation to produce a 1 on the pivot: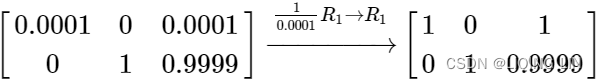
now by inspection (and without the use of back substitution) we can see that the solution is ![]() just as before.
just as before.
For a linear system with n equations and m unknowns (Xs).
- The innermost loops (one subtraction and one multiplication) of a Gauss-Jordan elimination routine are executed
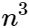 and
and 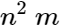 times.
times. - The corresponding loops in a Gaussian scheme are executed
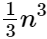 and
and 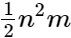 times, followed by a back substitution for a similar loop (one subtraction and one multiplication) that occurs
times, followed by a back substitution for a similar loop (one subtraction and one multiplication) that occurs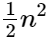 times.
times. - If there are far more equations that unknowns the Gaussian scheme with back substitution enjoys roughly a factor of 3 advantage over the Gauss-Jordan,
for n=mGaussian elimination with back substitution enjoys a factor of 6 advantage over Gauss-Jordan. For matrix inversion矩阵求逆 (discussed later) the two methods have identical efficiencies.
Gauss-Jordan elimination with partial pivoting
Consider a linear system with n equations and n unknowns: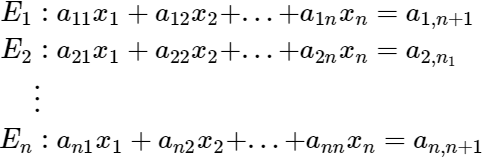

def gauss_jordan_solve(A,b):
# Concontanate the matrix A and right hand side column vector b
# into one matrix
temp_mat = np.c_[A,b]
# Get the number of rows
n = temp_mat.shape[0]
# Loop over rows
for r in range(n):
# Find the pivot index
# by 'looking down' the rth column 'from the rth row' to find
# the maximum (in magnitude) entry.
p_index = np.abs( temp_mat[r:,r] ).argmax()
# We have to reindex the pivot index to be
# the appropriate entry in the entire matrix,
# not just from the ith row down.
p_index += r # since 'from the rth row'
# 'Swapping rows' to make the maximal entry the pivot (if needed).
if p_index != r:
temp_mat[ [p_index, r] ] = temp_mat[ [r, p_index] ]
# Make the diagonal entires 1
# Divide each row by the diagonal elements in its respective row
temp_mat = temp_mat/np.diagonal( temp_mat )[:, np.newaxis]
# Eliminate all entries(are multiples of 1) above the pivot
factors_above = temp_mat[:r, r]
temp_mat[:r] -= factors_above[:,np.newaxis] * temp_mat[r]
# Eliminate all entries below the pivot
factors_vertical = temp_mat[r+1:,r]
temp_mat[r+1:] -= factors_vertical[:, np.newaxis]*temp_mat[r]
# now, all diagonal entries are 1s, the rest entries are 0s except last column
# If solution is a column vector, flatten it into a 1D array
###print('temp_mat:\n',temp_mat)
if temp_mat[:,n:].shape[1] == 1:
return temp_mat[:,n:].flatten()
else:
return temp_mat[:,n:]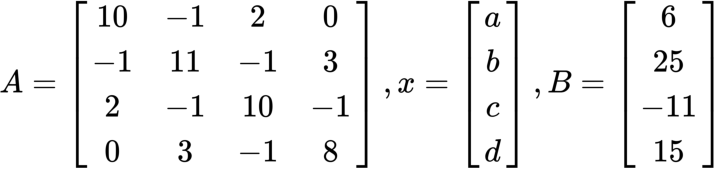
A = np. array([ [10. , -1. , 2. , 0. ] ,
[-1. , 11. , -1. , 3. ] ,
[2. , -1. , 10. , -1. ] ,
[0. , 3. , -1. , 8. ]
], dtype=np.double )
b = np.array([6., 25., -11, 15.])
np.round( gauss_jordan_solve(A, b),
3
) 
Matrix Inversion矩阵求逆 with Gauss-Jordan scheme
For matrix inversion, both the Gauss elimination with back-substitution and Gauss-Jordan schemes described previously have identical efficiencies. For this reason we will, for simplicities sake, only consider the process for matrix inversion using the Gauss-Jordan scheme.
All we have to do is augment an A matrix with an identity matrixof the same dimensions and proceed with Gauss-Jordan elimination exactly as we have done previously. Consider the following A matrix: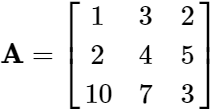
we augment it with a 3×3 identity matrix ![]() and proceed with Gauss-Jordan Elimination.
and proceed with Gauss-Jordan Elimination.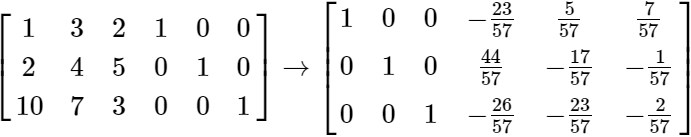
We can see by inspection the right side 3×3 submatrix on the right is the inverse of A.
def gauss_jordan_inverse(A):
# initialize b as an identity matrix the same size as A,
# and call gauss_jordan_solve as before.
return gauss_jordan_solve( A, np.eye(A.shape[0]) )A = np. array([ [1. , 3. , 2. ] ,
[2. , 4. , 5. ] ,
[10., 7. , 3. ] ,
] )
gauss_jordan_inverse(A) the inverse of A :![]()

A = np. array([ [10. , -1. , 2. , 0. ] ,
[-1. , 11. , -1. , 3. ] ,
[2. , -1. , 10. , -1. ] ,
[0. , 3. , -1. , 8. ]
], dtype=np.double )
gauss_jordan_inverse(A)the inverse of A : ![]()

Solving linear equations using matrices
In the previous section, we looked at solving a system of linear equations with inequality constraints. If a set of systematic linear equations has constraints that are deterministic, we can represent the problem as matrices and apply matrix algebra. Matrix methods represent multiple linear equations in a compact manner while using existing matrix library functions.
Suppose we would like to build a portfolio that consists of 3 securities: a, b, and c. The allocation of the portfolio must meet certain constraints:
- it must consist of 6 units of a long position in the security a.
- With every two units of the security a,
one unit of the security b,
and one unit of the security c invested,
the net position must be long four units. - With every one unit of the security a,
three units of the security b,
and two units of the security c invested,
the net position must be long five units.
To find out the number of securities to invest in, we can frame the problem mathematically, as follows: 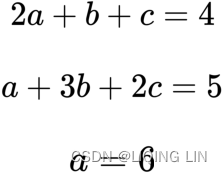
With all of the coefficients visible, the equations are as follows: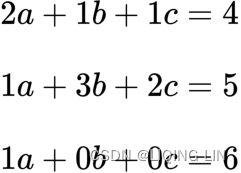
Let's take the coefficients of the equations and represent them in a matrix form: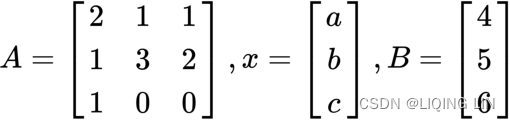
The linear equations can now be stated as follows:![]()
To solve for the x vector that contains the number of securities to invest in, the inverse of the A matrix is taken and the equation is written as follows:![]()
Using NumPy arrays, the A and B matrices are assigned as follows:
# Linear algebra with NumPy matrices
import numpy as np
A = np.array([ [2,1,1],
[1,3,2],
[1,0,0]
])
B = np.array([4,5,6])We can use the linalg.solve function of NumPy to solve a system of linear scalar equations:
# Solution to the system a x = b. Returned shape is identical to b.
print( np.linalg.solve(A,B) ) ![]() The portfolio would require
The portfolio would require
- along position of 6 units of the security a,
- 15 units of the security b,
- and a short position of 23 units of the security c.
In portfolio management, we can use the matrix system of equations to solve for optimal weight allocations of securities, given a set of constraints. As the number of securities in the portfolio increases, the size of the A matrix increases and it becomes computationally expensive to compute the matrix inversion of A. Thus, one may consider methods such as the Cholesky decomposition, LU decomposition, QR decomposition, the Jacobi method, or the Gauss-Seidel method to break down the A matrix into simpler matrices for factorization.
The LU decomposition
################## https://www.sciencedirect.com/topics/engineering/nonsingular-matrix
(Nonsingular matrix). An n × n matrix A is called nonsingular or invertible if there exists an n × n matrix B such that ![]()
If A does not have an inverse, A is called singular.
A matrix B such that ![]() is called an inverse of A. There can only be one inverse.
is called an inverse of A. There can only be one inverse. and
and![]()
![]() and
and![]()


##################
The LU decomposition, or also known as lower-upper factorization, is one of the methods that solve square systems of linear equations. As its name implies, the LU factorization decomposes the non-singular A matrix into a product of two matrices: a lower triangular matrix, L, and an upper triangular matrix, U. The decomposition can be represented as follows: 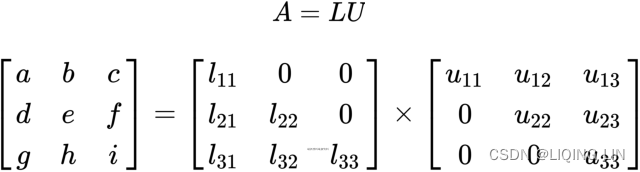
Here, we can see ![]() and so on.
and so on.
- A lower triangular matrix, L is a matrix that contains values in its lower triangle with the remaining upper triangle populated with zeros.
- The converse is true for an upper triangular matrix, U.
#########https://johnfoster.pge.utexas.edu/numerical-methods-book/LinearAlgebra_LU.html
LU
We will look at a simple example and write out the row operations.
row_index+1=2 row_index+1=3

L : row operation and constraint : column_index= row_index
row_index+1=3 row_index+1=2
![]() ==>
==>  Psuedocode for a simple LU factorization
Psuedocode for a simple LU factorization
Consider the matricies: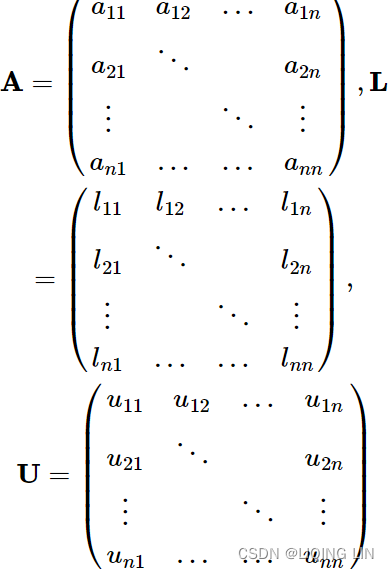

def lu(A):
# Get the number of rows
n = A.shape[0]
U = A.copy()
# https://numpy.org/devdocs/reference/generated/numpy.eye.html
# numpy.eye(N, M=None, k=0, dtype=<class 'float'>, order='C', *, like=None)
# Return a 2-D array with ones on the diagonal and zeros elsewhere.
L = np.eye(n, dtype=np.double)
# Loop over rows
for r in range(n):
# Eliminate entries below r with row operations on U
# and reverse the row operations to manipulate L
factor = U[r+1:, r]/U[r,r] #==> [2. 3.], then [4], then []
L[r+1:,r] = factor
#L: [[1. 0. 0.] then [[1. 0. 0.]
# [2. 1. 0.] [2. 1. 0.]
# [3. 0. 1.]] [3. 4. 1.]]
# E_2 - 2E_1 and E3 - 3E_1
# https://numpy.org/devdocs/reference/constants.html?highlight=numpy%20newaxis#numpy.newaxis
# [[2.]
# [3.]] * [1. 1. 0.]
U[r+1:] -= factor[:, np.newaxis] * U[r]
#U: [[ 1. 1. 0.] then U: [[ 1. 1. 0.]
# [ 0. -1. -1.] [ 0. -1. -1.]
# [ 0. -4. -1.]] [ 0. 0. 3.]]
return L,UA = np.array([ [ 1, 1, 0],
[ 2, 1, -1],
[ 3, -1, -1]
], dtype=np.double)
L,U= lu(A)
print("L:", L)
print("U:", U)
print("[email protected]", [email protected])
A = np.array([ [ 2, 1, 1],
[ 1, 3, 2],
[ 1, 0, 0]
], dtype=np.double)
L,U= lu(A)
print("L:", L)
print("U:", U)
print("[email protected]", [email protected]) <==
<==
PLU factorization
If we observe the pseudocode presented previously we can see that something as simple as![]() will cause our algorithm to fail. We can prevent this from happening by doing a row exchange with a row that has a nonzero value in the
will cause our algorithm to fail. We can prevent this from happening by doing a row exchange with a row that has a nonzero value in the![]() column. Like Gauss elimination there are several pivot strategies that can be utilized. For simplicity, we will exchange any row that has a zero on the diagonalwith the first row below it that hasa nonzero number in that column. Here we have to keep track of the row exchanges by creating a 置换矩阵permutation matrix, P by performing the same row exchanges to an identity matrix. This gives a matrix with precisely one nonzero entry in each row and in each column and each nonzero entry is 1. We will need P later, when we use the LU factorization to solve the permuted system of equations,
column. Like Gauss elimination there are several pivot strategies that can be utilized. For simplicity, we will exchange any row that has a zero on the diagonalwith the first row below it that hasa nonzero number in that column. Here we have to keep track of the row exchanges by creating a 置换矩阵permutation matrix, P by performing the same row exchanges to an identity matrix. This gives a matrix with precisely one nonzero entry in each row and in each column and each nonzero entry is 1. We will need P later, when we use the LU factorization to solve the permuted system of equations, ![]() .
.
Consider the matrices: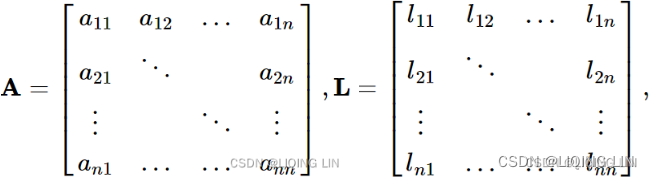

def plu(A):
# Get the number of rows
n = A.shape[0]
# Initialize L=P=I of dimension n×n and U=A
U = A.copy()
L = np.eye( n, dtype=np.double )
P = np.eye( n, dtype=np.double )
# Loop over rows
for r in range(n):
# Permute rows if needed
for k in range(r,n):
if ~np.isclose( U[r,r], 0.0 ): # if U[r,r] !=0
break
# elif U[r,r] ==0
# row swap
# U:
# [ [ 0, 1]
# [ 2, 1] ]
# U[ [k+1, k] ]:
# [ [2. 1.]
# [0. 1.] ]
U[ [r, k+1] ] = U[ [k+1, r] ]
# U:
# [ [2. 1.]
# [0. 1.] ]
P[ [r, k+1] ] = P[ [k+1, r] ]
# Eliminate entries below r with row operations on U
# and reverse the row operations to manipulate L
factor = U[r+1:, r] / U[r, r]
L[r+1:, r] = factor
U[r+1:] -= factor[:, np.newaxis] * U[r]
return P,L,U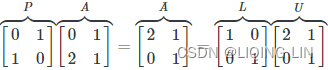
A = np.array([ [ 0, 1],
[ 2, 1],
], dtype=np.double)
P,L,U= plu(A)
print("P:", P)
print("L:", L)
print("U:", U) <==<==
<==<==![]()
A = np.array([ [ 0, 1],
[ 2, 1],
], dtype=np.double)
# Perform LU decomposition
LU, piv = scipy.linalg.lu_factor(A)
print('LU:', LU)
print('Piv:', piv)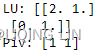
LU : Matrix containing U in itsupper triangle, and L in its lower triangle.
The unit diagonal elements of L are not stored.
piv : Pivot indices representing the permutation matrix P: row i of matrix was interchanged with rowpiv[i]. ![]() ==>row i =0, P[0]=[1,0], piv[0] =1, P[1]=[0,1] ==> swap ==>
==>row i =0, P[0]=[1,0], piv[0] =1, P[1]=[0,1] ==> swap ==> 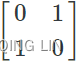 ==>next, if piv[i] ==i, not swap
==>next, if piv[i] ==i, not swap
A = np.array([ [ 0, -4, -6],
[ 0, -2, -4],
[ 1, 2, 2],
], dtype=np.double)
P,L,U= plu(A)
print("P:", P)
print("L:", L)
print("U:", U) 
A = np.array([ [ 0, -4, -6],
[ 0, -2, -4],
[ 1, 2, 2],
], dtype=np.double)
# Perform LU decomposition
LU, piv = scipy.linalg.lu_factor(A)
print('LU:', LU)
print('Piv:', piv) 
LU : Matrix containing U in itsupper triangle, and L in its lower triangle.
The unit diagonal elements of L are not stored.
piv : Pivot indices representing the permutation matrix P: row i of matrix was interchanged with rowpiv[i]. P= ==>row i =0, P[0]=[1,0,0], piv[0] =2, P[2]=[0,0,1] ==> swap ==> P=
==>row i =0, P[0]=[1,0,0], piv[0] =2, P[2]=[0,0,1] ==> swap ==> P=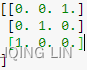 ==>row i =1, P[1]=[0,1,0], piv[0] =2, P[2]=[1,0,0] ==> swap ==>
==>row i =1, P[1]=[0,1,0], piv[0] =2, P[2]=[1,0,0] ==> swap ==>
P=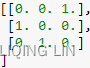 ==> if piv[i] ==row i, not swap ==>
==> if piv[i] ==row i, not swap ==>
A = np.array([ [ 2, 1, 1],
[ 1, 3, 2],
[ 1, 0, 0]
], dtype=np.double)
P,L,U= plu(A)
print("P:", P)
print("L:", L)
print("U:", U) 
We can display the LU decomposition of the A matrix using the lu() method of scipy.linalg. The lu() method returns three variables—
- the permutation matrix, P,
- the lower triangular matrix, L,
- and the upper triangular matrix, U – individually:
import scipy
A = np.array([ [ 2, 1, 1],
[ 1, 3, 2],
[ 1, 0, 0]
], dtype=np.double)
P, L, U = scipy.linalg.lu(A)
print(' P:' , P)
print(' L:' , L)
print(' U:' , U)When we print out these variables, we can conclude the relationship between the LU factorization and A matrix, as follows:
<==
# Perform LU decomposition
LU, piv = scipy.linalg.lu_factor(A)
print('LU:', LU)
print('Piv:', piv) 
LU : Matrix containing U in itsupper triangle, and L in its lower triangle.
The unit diagonal elements of L are not stored.
piv : Pivot indices representing the permutation matrix P: row i of matrix was interchanged with rowpiv[i]. ==> if piv[i] ==row i, not swap ==>
######### https://johnfoster.pge.utexas.edu/numerical-methods-book/LinearAlgebra_LU.html
The LU decomposition, or also known as lower-upper factorization, is one of the methods that solve square systems of linear equations. As its name implies, the LU factorization decomposes the non-singular A matrix into a product of two matrices: a lower triangular matrix, L, and an upper triangular matrix, U. The decomposition can be represented as follows:
Here, we can see ![]() and so on.
and so on.
- A lower triangular matrix, L is a matrix that contains values in its lower triangle with the remaining upper triangle populated with zeros.
- The converse is true for an upper triangular matrix, U.
The definite advantage of the LU decomposition method over the Cholesky decomposition method is that it works for any square matrices. The latter only works for symmetric and positive definite matrices.
Think back to the previous example in Solving linear equations using matrices of a 3 x 3 A matrix. This time, we will use the linalg package of the SciPy module to perform the LU decomposition with the following code:
==>==>![]()
"""
LU decomposition with SciPy
"""
import numpy as np
import scipy.linalg as linalg
# Define A and B
A = np.array([ [2. , 1. , 1. ] ,
[1. , 3. , 2. ] ,
[1. , 0. , 0. ]
])
B = np.array([4. , 5. , 6. ] )
# Perform LU decomposition
LU_Piv = linalg.lu_factor(A)
x = linalg.lu_solve(LU_Piv, B)
# To view the values of x , execute the following command:
print(x) ![]()
We get the same values of 6 , 15 , and -23 for a, b, and c, respectively.
Note that we used the lu_factor() method of scipy.linalg here, which gives the LU_Piv variable as the pivotedLU decomposition of the A matrix. We used the lu_solve() method, which takes in the pivotedLU decomposition and the B vector, to solve the equation system.
##########https://johnfoster.pge.utexas.edu/numerical-methods-book/LinearAlgebra_LU.html
Solving equations![]() ==>
==>![]() after LU factorization
after LU factorization
Once we have L and U we can solve for as many right-hand side vectors ![]() (OR
(OR ![]() )as desired very quickly using the following two step process.
)as desired very quickly using the following two step process.
forward substitution
First we let ![]() and then solve for
and then solve for ![]() (d1, d2,d3,d4) by using forward substitution. The pseudocode for this is as follows
(d1, d2,d3,d4) by using forward substitution. The pseudocode for this is as follows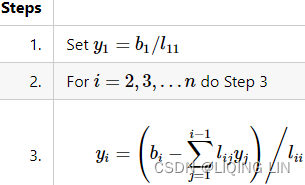

![]()
def forward_substitution(L, b):
#Get number of rows
n = L.shape[0]
# Allocating space for the solution vector
y = np.zeros_like(b, dtype=np.double);
#Here we perform the forward-substitution.
#Initializing with the first row.
y[0] = b[0] / L[0, 0]
#Looping over rows in reverse (from the bottom up),
#starting with the second to last row, because the
#last row solve was completed in the last step.
for r in range(1, n):
y[r] = ( b[r] - (L[r,:r]).dot(y[:r]) ) / L[r,r]
return yimport scipy
A = np.array([ [ 2, 1, 1],
[ 1, 3, 2],
[ 1, 0, 0]
], dtype=np.double)
B = np.array([4. , 5. , 6. ] )
P, L, U = scipy.linalg.lu(A)
y = forward_substitution(L,B)
y![]()
back substitution
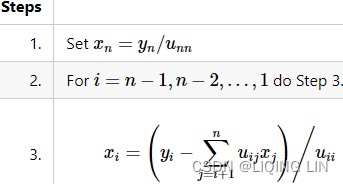

![]() ==> x
==> x
def back_substitution(U, y):
# Number of rows
n = U.shape[0]
# Allocating space for the solution vector
x = np.zeros_like(y, dtype=np.double);
# Here we perform the back-substitution.
# Initializing with the last row.
x[-1] = y[-1] / U[-1, -1]
# Looping over rows in reverse (from the bottom up),
# starting with the second to last row, because the
# last row solve was completed in the last step.
for i in range(n-2, -1, -1): # n-2 ==> n==0
# print(x)
x[i] = ( y[i] - U[i,i+1:].dot(x[i+1:]) ) / U[i,i]
#OR== x[i] = ( y[i] - U[i,i:].dot(x[i:]) ) / U[i,i]
# since x[i]==0 and 3*0 == 0
return x
x=back_substitution(U,y)
x
# Putting everything together for a solution process
def lu_solve(A, b):
L, U = lu(A)
y = forward_substitution(L, b)
return back_substitution(U, y)
lu_solve(A,B)![]()
########## https://johnfoster.pge.utexas.edu/numerical-methods-book/LinearAlgebra_LU.html
We can display the LU decomposition of the A matrix using the lu() method of scipy.linalg. The lu() method returns three variables—
- the permutation matrix, P,
- the lower triangular matrix, L,
- and the upper triangular matrix, U – individually:
import scipy
A = np.array([ [ 2, 1, 1],
[ 1, 3, 2],
[ 1, 0, 0]
], dtype=np.double)
B = np.array([4. , 5. , 6. ] )
P, L, U = scipy.linalg.lu(A)
print(' P=\n' , P)
print(' L=\n' , L)
print(' U=\n' , U) 
When we print out these variables, we can conclude the relationship between the LU
factorization and A matrix, as follows:
The LU decomposition can be viewed as the matrix form of Gaussian elimination高斯消元 performed on two simpler matrices: the upper triangular and lower triangular matrices.
The Cholesky decomposition
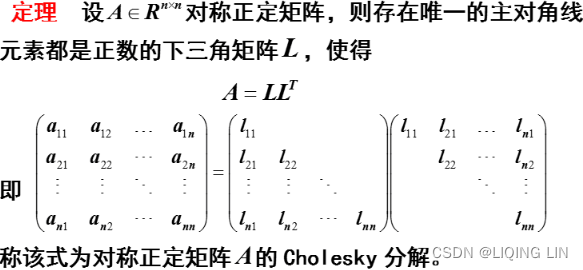
The Cholesky decomposition is another way of solving systems of linear equations. It can be significantly faster and uses a lot less memory than the LU decomposition, by exploiting the property of symmetric matrices. However, the matrix being decomposed must beHermitian (or real-valued symmetric![]() and thus square) and positive definite
and thus square) and positive definite . This means that the A matrix is decomposed as
. This means that the A matrix is decomposed as ![]() ,
, where
where
- L is a lower triangular matrix with real and positive numbers on the diagonals,
- and
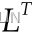 is the conjugate transpose共轭转置 of L.
is the conjugate transpose共轭转置 of L. 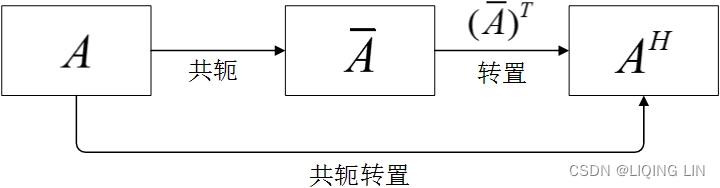
 共轭就是矩阵每个元素都取共轭(实部不变,虚部取反,正变负,虚变正).
共轭就是矩阵每个元素都取共轭(实部不变,虚部取反,正变负,虚变正).
######
Suppose we want to calculate the conjugate transpose of the following matrix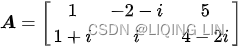
We first transpose the matrix:
Then we conjugate every entry of the matrix: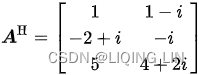
n阶复方阵A的对称单元互为共轭,即A的共轭转置矩阵等于它本身,则A是厄米特矩阵(Hermitian Matrix)。
######
If matrix A is symmetric![]() and positive definite, then there exists a lower triangular matrix L such that
and positive definite, then there exists a lower triangular matrix L such that ![]() . This is just a special case of the LU decomposition,
. This is just a special case of the LU decomposition,![]() . The algorithm is slightly simpler than the Doolittle or Crout methods.
. The algorithm is slightly simpler than the Doolittle or Crout methods.
Consider the matrices
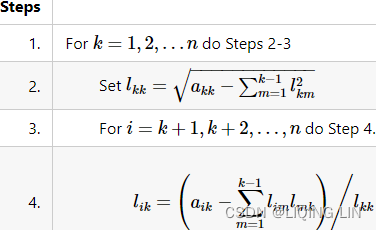
def cholesky(A):
n = A.shape[0]
# Allocating space for the L (lower triangular matrix)
L = np.zeros( (n,n), dtype=np.double )
for k in range(n): # L[k,k:]==[0...]
# A对角线一个值A[k,k] - sum( L对角线一个值L[k,k]所有左边值的平方)
L[k,k] = np.sqrt( A[k,k] - np.sum( L[k,:k]**2 ) )
# L[k+1,:k] @ L[:k,k] : sum(L[k,k]下一行左边值 *对角线 L[k,k]垂直上方值)
L[(k+1):, k] = ( A[(k+1):, k] - L[(k+1):, :k] @ L[:k,k] ) / L[k,k]
return LA = np. array([ [10. , -1. , 2. , 0. ] ,
[-1. , 11. , -1. , 3. ] ,
[2. , -1. , 10. , -1. ] ,
[0. , 3. , -1. , 8. ]
] )
L = cholesky(A)
Larray([[ 3.16227766, 0. , 0. , 0. ],
[-0.31622777, 3.3015148 , 0. , 0. ],
[ 0.63245553, -0.30289127, 3.08354615, 0. ],
[ 0. , 0.9086738 ,-0.32430194, 2.65878547]])
def cholesky(A):
n = A.shape[0]
# Allocating space for the L (lower triangular matrix)
L = np.zeros( (n,n), dtype=np.double )
for k in range(n): # L[k,k:]==[0...]
# A对角线一个值A[k,k] - sum( L对角线一个值L[k,k]左边的值的平方)
# L[k,k] = np.sqrt( A[k,k] - np.sum( L[k,:k]**2 ) )
# 考虑到L对角线右边的值都为0以及当前L[k,k]=0
L[k,k] = np.sqrt( A[k,k] - np.sum( L[k,:]**2 ) )
# # L[k+1,:k] @ L[:k,k] : sum(L[k,k]下一行左边值 *对角线 L[k,k]垂直上方值)
# L[(k+1):, k] = ( A[(k+1):, k] - L[(k+1):, :k] @ L[:k,k] ) / L[k,k]
# 考虑到L对角线右边和下边的值都为0以及当前L[k+1,k+1]=0
# broadcasting
L[(k+1):, k] = ( A[(k+1):, k] - L[(k+1):, :] @ L[:, k]) / L[k, k]
return LA = np. array([ [10. , -1. , 2. , 0. ] ,
[-1. , 11. , -1. , 3. ] ,
[2. , -1. , 10. , -1. ] ,
[0. , 3. , -1. , 8. ]
], dtype=np.double )
L = cholesky(A)
Larray([[ 3.16227766, 0. , 0. , 0. ],
[-0.31622777, 3.3015148 , 0. , 0. ],
[ 0.63245553, -0.30289127, 3.08354615, 0. ],
[ 0. , 0.9086738 ,-0.32430194, 2.65878547]])
A = np.array([[2, -1, 0],
[-1, 2, -1.],
[0, -1, 2.]
], dtype=np.double)
L = cholesky(A)
L 
np.linalg.cholesky(A)
L @ (L.T.conj()) 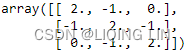 ==A
==A
Let's consider another example of a system of linear equations where the A matrix is both Hermitian(![]() ) and positive definite. Again, the equation is in the form of Ax=B, where A and B take the following values:
) and positive definite. Again, the equation is in the form of Ax=B, where A and B take the following values:
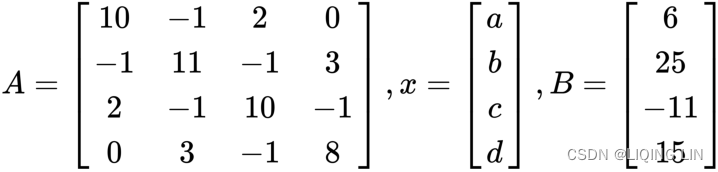
Let's represent these matrices as NumPy arrays:
# Cholesky decomposition with NumPy
import numpy as np
A = np. array([ [10. , -1. , 2. , 0. ] ,
[-1. , 11. , -1. , 3. ] ,
[2. , -1. , 10. , -1. ] ,
[0. , 3. , -1. , 8. ]
], dtype=np.double )
B = np.array([6., 25., -11, 15.])
L = np.linalg.cholesky(A)
LThe cholesky() function of numpy.linalg would compute the lower triangular factor L of the A matrix. Let's view the lower triangular matrix:
 #different with the result from our algrithm(accuracy problem)
#different with the result from our algrithm(accuracy problem)
Return the Cholesky decomposition, L * L.H, of the square matrix A, where L is lower-triangular and .H is the conjugate transpose operator (which is the ordinary transpose普通转置 if A is real-valued). a must be Hermitian (symmetric if real-valued) and positive-definite. No checking is performed to verify whether A is Hermitian or not. In addition, only the lower-triangular and diagonal elements of A are used. Only L is actually returned
To verify that the Cholesky decomposition results are correct, we can use the definition of the Cholesky factorization by multiplying L by its conjugate transpose, which will lead us back to the values of the A matrix:
print( np.dot(L, L.T.conj() ) ) # A = L @ L* 
Before solving for x (![]() and
and ![]() ), we need to solve for
), we need to solve for ![]() as y. Let's use the solve() method of numpy.linalg:
as y. Let's use the solve() method of numpy.linalg:![]() and
and ![]() (note:
(note: ![]() )
)
==> applying ![]() ==>
==>![]()
==> ![]() (from
(from ![]() ) ==>
) ==>![]() (from
(from ![]() )
)
# A .x=B U.x=y, then L.y=B
y = np.linalg.solve(L, B) # L.L*.x=B; When L*.x=y, then L.y=B
y ![]()
To solve for x, we need to solve again using the conjugate transpose of L and y:
x = np.linalg.solve( L.T.conj(), y ) # x=L*'.y
x![]() The output gives us our values of x for a, b, c, and d.
The output gives us our values of x for a, b, c, and d.
To show that the Cholesky factorization gives us the correct values, we can verify the answer by multiplying the A matrix by the transpose of x to return the values of B:
print( np.mat(A)*np.mat(x).T ) 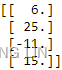
print( A @ x.T ) ![]()
This shows that the values of x by the Cholesky decomposition would lead to the same values given by B.
The QR decomposition
The QR decomposition, also known as the QR factorization, is another method of solving linear systems of equations using matrices, very much like the LU decomposition. The equation to solve is in the form of Ax=B, where matrix A=QR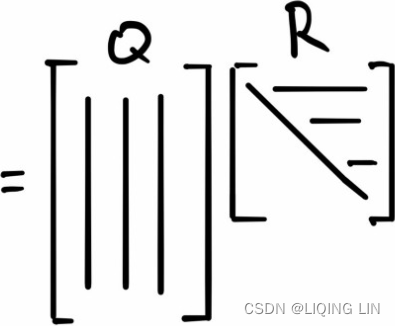 . However, in this case, A is a product of an orthogonal matrix, Q, and upper triangular matrix, R. A 是 正交矩阵Q 和 上三角矩阵R 的乘积。 The QR algorithm is commonly used to solve the linear least-squares problem.
. However, in this case, A is a product of an orthogonal matrix, Q, and upper triangular matrix, R. A 是 正交矩阵Q 和 上三角矩阵R 的乘积。 The QR algorithm is commonly used to solve the linear least-squares problem.
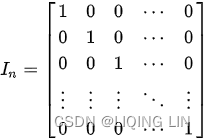
An orthogonal matrix, Q, exhibits the following properties:
- It is a square matrix.
- Multiplying an orthogonal matrix by its transpose returns the identity matrix
 :
: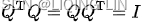
- The inverse of an orthogonal matrix equals its transpose:
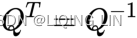
(In linear algebra, an n-by-n square matrix A is called invertible (also nonsingular or nondegenerate), if there exists an n-by-n square matrix B such that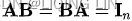 , the matrix B is uniquely determined by A, and is called the (multiplicative) inverse of A)
, the matrix B is uniquely determined by A, and is called the (multiplicative) inverse of A)
An identity matrix is also a square matrix, with its main diagonal containing 1s and 0s elsewhere.
The problem of Ax=B ==>QRx=B can now be restated as follows: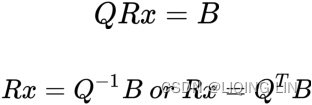
Using the same variables in the LU decomposition example, we will use the qr() method of scipy.linalg to compute our values of Q and R, and let the y variable represent our value of ![]() with the following code:
with the following code:
# QR decomposition with scipy
import numpy as np
import scipy.linalg as linalg
A = np.array([ [ 2, 1, 1],
[ 1, 3, 2],
[ 1, 0, 0]
], dtype=np.double)
B = np.array([4. , 5. , 6.])
Q,R = linalg.qr(A) # QR decomposition
y = np.dot( Q.T, B ) # Let y=Q'.B ==> Rx
x = linalg.solve(R,y) # Solve Rx=y ==> x
print( 'Rx :', y ) ![]()
Note that Q.T is simply the transpose of Q , which is also the sameas the inverse of Q:
print( x ) ![]()
We get the same answers as those in the LU decomposition example.
Solving with other matrix algebra methods
So far, we've looked at the use of matrix inversion, the LU decomposition, the Cholesky decomposition, and QR decomposition to solve for systems of linear equations. Should the size of our financial data in the A matrix be large, it can be broken down by a number of schemes so that the solution can converge more quickly using matrix algebra. Quantitative portfolio analysts should be familiar with these methods.
In some circumstances, the solution that we are looking for might not converge. Therefore, you might consider the use of iterative methods. Common methods to solve systems of linear equations iteratively are the Jacobi method, the Gauss-Seidel method, and the SOR method. We will take a brief look at examples of implementing the Jacobi and Gauss-Seidel methods.
Iterative Methods for Solving Linear Systems of Equations
Iterative techniques are rarely used for solving linear systems of small dimension because the computation time required for convergence usually exceeds that required for direct methods such as Gaussian elimination高斯消元. However, for very large systems, especially sparse systems (systems with a high percentage of 0 entries in the matrix), these iterative techniques can be very efficient in terms of computational run times and memory usage.
An iterative technique starts to solve the matrix equation![]() starts with an initial approximation
starts with an initial approximation![]() and generates a sequence of vectors
and generates a sequence of vectors![]() that converges to
that converges to![]() as N→∞. These techniques involve a process that converts the system
as N→∞. These techniques involve a process that converts the system ![]() to an equivalent system of the form
to an equivalent system of the form ![]() . The process then follows, for an initial guess
. The process then follows, for an initial guess ![]() .
.

We will stop the iteration when some convergence criterion has been reached. A popular convergence criterion uses the![]() norm. The
norm. The![]() norm is a metric that represents the greatest length or size of a vector or matrix component. Expressed mathematically,
norm is a metric that represents the greatest length or size of a vector or matrix component. Expressed mathematically,
The Jacobi method雅克比迭代算法
Consider the system:![]()
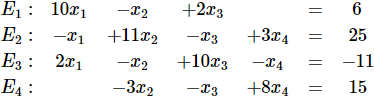 <=>
<=>
Let us solve each equation,![]() , for the variable
, for the variable![]() .
. 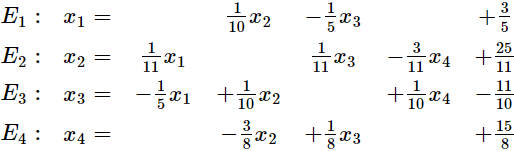 <=
<=
using the notation introduced previously we have![]()

for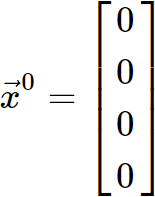 ==>
==>![]() ==>
==>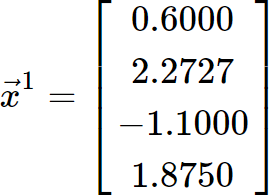 ==>
==>![]() ==>
==>![]()
we repeat this process until the desired convergence has been reached. This technique is called the Jacobi iterative method.
For the matrix equation![]() with an initial guess
with an initial guess![]() .
. 

def jacobi( A,b,tolerance=1e-10, max_iterations=10000 ):
# Allocating space for the solution vector
x = np.zeros_like(b, dtype=np.double)
# A=([[0, 1, 2], ([[0, 0, 0],
# [3, 4, 5], ==>np.diagnoal(A)==>([0, 4, 8])==>np.diag()==> [0, 4, 0],
# [6, 7, 8] [0, 0, 8]
# ]) ])
# Make the elements of the main diagonal all 0
T = A - np.diag( np.diagonal(A) )
for k in range( max_iterations ):
x_previous = x.copy()
# x[:] = ( -T.dot(x) + b ) / np.diagonal(A)
x[:] = ( b - T.dot(x) ) / np.diagonal(A)
if np.linalg.norm( x - x_previous,
ord=np.inf
) / np.linalg.norm(x, ord=np.inf) < tolerance:
break
return x
A = np.array([ [10., -1., 2., 0.],
[-1., 11., -1., 3.],
[ 2., -1., 10., -1.],
[0.0, 3., -1., 8.]
])
B = np.array([6., 25., -11., 15.])
n = 25
x = jacobi( A, B, max_iterations=n )
print('x', '=', np.round(x) ) ![]()
Observations on the Jacobi iterative method
Let's consider a matrix A, in which we split into three matrices, D, U, L, where these matrices are diagonal, upper triangular, and lower triangular respectively. 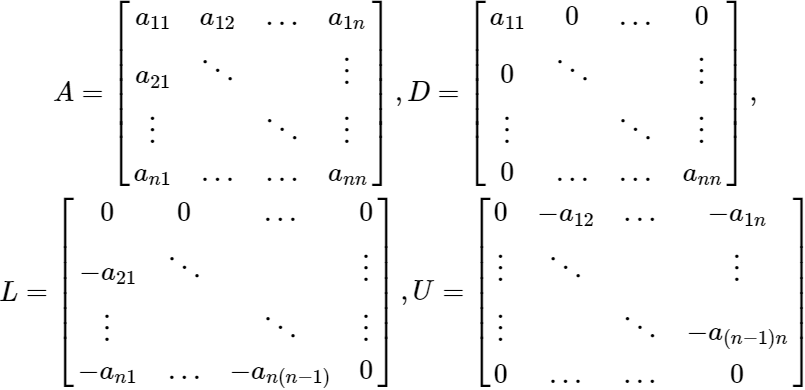
If we let A=D−L−U, then the matrix equation![]() becomes
becomes![]()
if ![]() exists, that implies
exists, that implies ![]() ,
,
then![]()
The results in the matrix form of the Jacobi iteration method ![]()
We can see that one requirement for the Jacobi iteration to work is for![]() . This may involve row exchanges before iterating for some linear systems.
. This may involve row exchanges before iterating for some linear systems.
The Jacobi method solves a system of linear equations iteratively along its diagonal elements. The iteration procedure terminates when the solution converges. Again, the equation to solve is in the form of Ax=B or ![]() , where the matrix A can be decomposed into two matrices of the same size such that A=D+R. The matrix D consists of only the diagonal componentsof A, and the other matrix R (=−L−U)consists of the remaining components. Let's take a look at the example of a 4 x 4 A matrix:
, where the matrix A can be decomposed into two matrices of the same size such that A=D+R. The matrix D consists of only the diagonal componentsof A, and the other matrix R (=−L−U)consists of the remaining components. Let's take a look at the example of a 4 x 4 A matrix: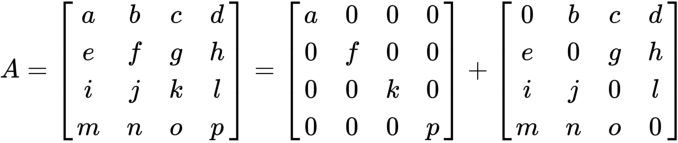
The solution is then obtained iteratively, as follows: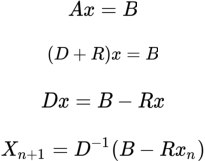
As opposed to the Gauss-Siedel method, the value of ![]() in the Jacobi method is needed during each iteration in order to compute
in the Jacobi method is needed during each iteration in order to compute![]() and cannot be overwritten. This would take up twice the amount of storage. However, the computations for each element can be done in parallel, which is useful for faster computations.
and cannot be overwritten. This would take up twice the amount of storage. However, the computations for each element can be done in parallel, which is useful for faster computations.
If the A matrix is strictly irreducibly( /ˌɪrɪˈduːsəbli / 不能减少地,不能简化地) diagonally dominant严格不可约 对角占优矩阵, this method is guaranteed to converge. A strictly irreducibly diagonally dominant matrix is one where the absolute diagonal elementin every row is greater than the sum of the absolute values of other terms.
In some circumstances, the Jacobi method can converge even if these conditions are not met. The Python code is given as follows:
"""
Solve Ax=B with the Jacobi method
"""
import numpy as np
def jacobi2(A, B, tolerance=1e-10, max_iterations=10000):
# Allocating space for the solution vector with same shape and type as B
x = np.zeros_like(B)
for iter_count in range( max_iterations ):
x_new = np.zeros_like(x)
for r in range( A.shape[0] ):
# T.dot(x)
s1 = np.dot( A[r, :r], x[:r] )
s2 = np.dot( A[r, r+1:], x[r+1:])
# -T.dot(x) + B ==> B - T.dot(x)
x_new[r] = (B[r] - s1 - s2) / A[r, r]
if np.allclose(x, x_new, tolerance):
break
x = x_new
return x Consider the same matrix values in the Cholesky decomposition example. We will use 25 iterations in our jacobi function to find the values of x:
A = np.array([ [10., -1., 2., 0.],
[-1., 11., -1., 3.],
[ 2., -1., 10., -1.],
[0.0, 3., -1., 8.]
])
B = np.array([6., 25., -11., 15.])
n = 25
x = jacobi2( A, B, max_iterations=n )
print('x', '=', np.round(x) )![]() We solved for the values of x, which are similar to the answers from the Cholesky decomposition.
We solved for the values of x, which are similar to the answers from the Cholesky decomposition.
The Gauss-Seidel method
During the Jacobi iteration we always use the components of![]() to compute
to compute![]() but for row_index i>1,
but for row_index i>1,![]() are already computed and are most likely the best approximations of the real solution. Therefore, we can calculate
are already computed and are most likely the best approximations of the real solution. Therefore, we can calculate![]() using the most recently calculated values when available. This technique is called Gauss-Seideliteration. The pseudocode is as follows
using the most recently calculated values when available. This technique is called Gauss-Seideliteration. The pseudocode is as follows
For the matrix equation![]() with an initial guess
with an initial guess![]() .
. 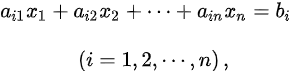

当然,此处假定![]() ,在很多情况下,它比简单迭代法收敛快,它和简单迭代法的不同点在于计算
,在很多情况下,它比简单迭代法收敛快,它和简单迭代法的不同点在于计算![]() 时,利用了刚刚迭代出的
时,利用了刚刚迭代出的![]() 的值,当系数矩阵 A 严格对角占优(A strictly irreducibly diagonally dominant matrix is one where the absolute diagonal elementin every row is greater than the sum of the absolute values of other terms)或对称正定时,高斯-赛德尔迭代法必收敛
的值,当系数矩阵 A 严格对角占优(A strictly irreducibly diagonally dominant matrix is one where the absolute diagonal elementin every row is greater than the sum of the absolute values of other terms)或对称正定时,高斯-赛德尔迭代法必收敛
def gauss_seidel( A, b, tolerance=1e-10, max_iterations=10000):
# Allocating space for the solution vector with same shape and type as b
# iterate
for k in range( max_iterations ):
x_previous = x.copy()
# loop over rows
for r in range( A.shape[0] ):
x[r] = (b[r] - np.dot( A[r, :r], x[:r] )\
- np.dot( A[r, r+1:], x_previous[r+1:] )
) / A[r,r]
if np.linalg.norm( x - x_previous,
ord=np.inf
) / np.linalg.norm(x, ord=np.inf) < tolerance:
break
return x
A = np.array([ [10., -1., 2., 0.],
[-1., 11., -1., 3.],
[ 2., -1., 10., -1.],
[0.0, 3., -1., 8.]
])
B = np.array([6., 25., -11., 15.])
n = 100
x = gauss_seidel( A, B, max_iterations=n )
print('x', '=', np.round(x) )![]()
Observations on the Gauss-Seidel iterative method
Let's consider a matrix A, in which we split into three matrices, D, U, L, where these matrices are diagonal, upper triangular, and lower triangular respectively.
We will leave, as an exercise for the student, the derivation, but the matrix equation for the Gauss-Seidel iteration method is as follows:
If we let A=D−L−U, then the matrix equation![]() becomes
becomes![]() ==> (D-L) x = Ux+b
==> (D-L) x = Ux+b ![]()
In order for the lower triangular matrix D−L to be invertible it is necessary and sufficient for ![]() . As before, this may involve row exchanges before iterating for some linear systems.
. As before, this may involve row exchanges before iterating for some linear systems.
The Gauss-Seidel method works very much like the Jacobi method. It is another way to solve a square system of linear equations using an iterative procedure with the equation in the form of Ax=B(![]() ). Here, the A matrix is decomposed as A=L+U, where the A matrix is a sum of a lower triangular matrix, L (=D-L), and an upper triangular matrix, U. Let's take a look at the example of a 4 x 4 A matrix:
). Here, the A matrix is decomposed as A=L+U, where the A matrix is a sum of a lower triangular matrix, L (=D-L), and an upper triangular matrix, U. Let's take a look at the example of a 4 x 4 A matrix: 
The solution is then obtained iteratively, as follows:
Using a lower triangular matrix, L, where zeroes fill up the upper triangle, the elements of ![]() can be overwrittenin each iteration in order to compute
can be overwrittenin each iteration in order to compute ![]() . This results in the advantage of needing half the storage required when using the Jacobi method.
. This results in the advantage of needing half the storage required when using the Jacobi method.
The rate of convergence in the Gauss-Seidel method largely lies in the properties of the A matrix, especially if the A matrix is needed to be strictly-diagonally dominant or symmetric positive definite. Even if these conditions are not met, the Gauss-Seidel method may converge.
"""
Solve Ax=B with the Gauss-Seidel method
"""
import numpy as np
def gauss_seidel2( A, b, tolerance=1e-10, max_iterations=10000):
L = np.tril(A) # returns the lower triangular matrix(including np.diagonal(A)) of A
U = A-L # decompose A = L + U
L_inv = np.linalg.inv(L)
# Allocating space for the solution vector with same shape and type as B
x = np.zeros_like(B)
for k in range( max_iterations ):
Ux = np.dot(U, x)
x_new = np.dot(L_inv, B - Ux)
if np.allclose(x, x_new, tolerance):
break
x = x_new
return xHere, the tril() method of NumPy returns the lower triangular A matrix, from which we can find the upper triangular U matrix. Plugging the remaining values into x iteratively would lead us to the following solution, with some tolerance defined by tolerance.
Let's consider the same matrix values in the Jacobi method and Cholesky decomposition example. We will use a maximum of 100 iterations in our gauss_seidel2 function to find the values of x, as follows:
A = np.array([ [10., -1., 2., 0.],
[-1., 11., -1., 3.],
[ 2., -1., 10., -1.],
[0.0, 3., -1., 8.]
])
B = np.array([6., 25., -11., 15.])
n = 100
x = gauss_seidel2( A, B, max_iterations=n )
print('x', '=', np.round(x) ) ![]() We solved for the values of x, which are similar to the answers from the Jacobi method and Cholesky decomposition.
We solved for the values of x, which are similar to the answers from the Jacobi method and Cholesky decomposition.
Summary
In this chapter, we took a brief look at the use of the CAPM(Capital Asset Pricing Model 资本资产定价模型) model and APT(Arbitrage Pricing Theory套利定价理论) model in finance. In the CAPM model, we visited the efficient frontier with the CML(Capital Market Line) to determine the optimal portfolio and the market portfolio. Then, we solved for the SML(Securities Market Line) using regression, which helped us to determine whether an asset is undervalued or overvalued. In the APT model, we explored how various factors affect security returns other than using the mean-variance framework. We performed a multivariate linear regression to help us determine the coefficients of the factors that led to the valuation of our security price. ![]()
subject to:
In portfolio allocation, portfolio managers are typically mandated by investors toachieve a set of objectives while following certain constraints. We can model this problem using linear programming. Using the Pulp Python package, we can define a minimization or maximization objective function, and add inequality constraints to our problems to solve for unknown variables. The three outcomes in linear optimization can be an unbounded solution, only one solution, or no solution at all.
Where the following is true:
Another form of linear optimization is integer programming, where all the variables are restricted to being integers instead of fractional values. A special case of an integer variable is a binary variable, which can either be 0 or 1, and it is especially useful to model decision-making when given a set of choices. We worked on a simple integer programming model that contains binary conditions and saw how easy it is to run into a pitfall陷阱(we were trying to perform multiplication on two unknown variables, quantities and is_order, which unknowingly led us to perform nonlinear programming. (This error is a nonlinear problem caused by multiplying 2 unknown variables)). Careful planning on the design of integer programming models is required for them to be useful in decision-making.
The portfolio-allocation problem may also be represented as a system of linear equations with equalities, which can be solved using matrices in the form of Ax=B. To find the values ofx, we solved for ![]() using various types of decomposition of the A matrix. The two types of matrix decomposition method are the direct and indirect methods. The direct method performs matrix algebra in a fixed number of iterations, and includes the LU decomposition(
using various types of decomposition of the A matrix. The two types of matrix decomposition method are the direct and indirect methods. The direct method performs matrix algebra in a fixed number of iterations, and includes the LU decomposition(![]() ==>y==>
==>y==>![]() ==>x), Cholesky decomposition(
==>x), Cholesky decomposition(![]() and
and![]() ), and QR decomposition methods. The indirect or iterative method iteratively computes the next values of x until a certain tolerance of accuracy is reached. This method is particularly useful for computing large matrices, but it also faces the risk of not having the solution converge. The indirect methods we used are the Jacobi method
), and QR decomposition methods. The indirect or iterative method iteratively computes the next values of x until a certain tolerance of accuracy is reached. This method is particularly useful for computing large matrices, but it also faces the risk of not having the solution converge. The indirect methods we used are the Jacobi method![]() and the Gauss-Seidel method.
and the Gauss-Seidel method.
In the next chapter, we will look at nonlinear modeling in finance.
边栏推荐
- Unity3D在一建筑GL材料可以改变颜色和显示样本
- 機器人(自動化)課程的持續學習-2022-
- vim —- 自己主动的按钮indent该命令「建议收藏」
- Nanopineo use development process record
- Collection of idea gradle Lombok errors
- EasyUI export excel cannot download the method that the box pops up
- Use br to back up tidb cluster to GCS
- 2022 middle school Youth Cup mathematical modeling question B fertility policy research ideas under the background of open three children
- See Gardenia minor
- EasyCVR平台接入RTMP协议,接口调用提示获取录像错误该如何解决?
猜你喜欢
Hardware development notes (10): basic process of hardware development, making a USB to RS232 module (9): create ch340g/max232 package library sop-16 and associate principle primitive devices

The root file system of buildreoot prompts "depmod:applt not found"
SSM+JSP实现企业管理系统(OA管理系统源码+数据库+文档+PPT)
这项15年前的「超前」技术设计,让CPU在AI推理中大放光彩
機器人(自動化)課程的持續學習-2022-

见到小叶栀子

各路行业大佬称赞的跨架构开发“神器”,你get同款了吗?
【编码字体系列】OpenDyslexic字体
Operational amplifier application summary 1

The most complete security certification of mongodb in history
随机推荐
AI 落地新题型 RPA + AI =?
MySQL data loss, analyze binlog log file
See Gardenia minor
Win11玩绝地求生(PUBG)崩溃怎么办?Win11玩绝地求生崩溃解决方法
Highly paid programmers & interview questions. Are you familiar with the redis cluster principle of series 120? How to ensure the high availability of redis (Part 1)?
[team learning] [34 sessions] Alibaba cloud Tianchi online programming training camp
英特尔与信步科技共同打造机器视觉开发套件,协力推动工业智能化转型
深耕开发者生态,加速AI产业创新发展 英特尔携众多合作伙伴共聚
机器人(自动化)课程的持续学习-2022-
Continuous learning of Robotics (Automation) - 2022-
What is CGI, IIS, and VPS "suggested collection"
手机号国际区号JSON格式另附PHP获取
The first introduction of the most complete mongodb in history
ABAP dynamic inner table grouping cycle
这项15年前的「超前」技术设计,让CPU在AI推理中大放光彩
How to solve the problem of adding RTSP device to easycvr cluster version and prompting server ID error?
VIM - own active button indent this command "suggestions collection"
Kotlin compose text supports two colors
【OA】Excel 文档生成器: Openpyxl 模块
NanopiNEO使用开发过程记录