当前位置:网站首页>Lightweight AlphaPose
Lightweight AlphaPose
2022-08-02 15:26:00 【Hongyao】
目录
前言
AlphaPose介绍
AlphaPose是一个精确的多人姿态估计器,是第一个在COCO数据集上实现70+ mAP (75 mAP),在MPII数据集上实现80+ mAP (82.1 mAP)的开源系统.为了匹配跨帧对应于同一个人的姿势,我们还提供了一个名为“姿势流”的高效在线姿势跟踪器.它是首个在PoseTrack Challenge数据集上同时实现60+ mAP (66.5 mAP)和50+ MOTA (58.3 MOTA)的开源在线姿势跟踪器.
这里强调一下
大部分Alphapose的文章都会介绍Alphapose和RMPE等论文有关.但事实上发展到今天,Alphapose其实更接近一个纯粹的基于自上而下的多人姿态估计项目,里面的模型也是集众家之所长,像RMPE论文里提到的SSTN在新版的项目里甚至都被去除了.
轻量化什么
目前的Alphapose实际上是yolov3-spp行人检测+姿态关键点检测+行人重识别算法的组合,对应多目标检测、单人姿态估计、行人重识别三个任务,本文主要介绍的是在Alphapose原项目中轻量化单人姿态估计模型的方法.
yolo目标检测的轻量化
Alphapose里使用的yolov3实际上是yolov4项目下的一个版本,加入了空间金字塔池化(Spatial Pyramid Pooling, SPP),目标检测效果会比原版的yolov3好一点.
这里有大佬使用Yolov4优化了一下目标检测部分:https://github.com/WildflowerSchools/pytorch-YOLOv4
csdn里的另一个大佬完成了使用任意yolo替换Alphapose的目标检测网络的项目:https://blog.csdn.net/qq_35975447/article/details/114940943
本人的做法是将所有模型转换成torchscript模型,然后自己重写中间的衔接(主要是中间的图像处理和多线程流水线),有兴趣的可以关注一下我的项目,里面能找到相应的处理:https://github.com/hongyaohongyao/smart_classroom_demo
- 我在项目里用的是yolov5s模型,姑且算是使用了比较轻量的目标检测模型吧.
单人姿态估计网络的轻量化
Alphapose的自上而下的多人姿态估计的步骤
- 先做多人目标检测
- 将检测到的目标裁剪下来,通过仿射变换转换成大小为固定大小的图像
- 使用单人姿态估计网络预测所有图像中的关键点,关键点回归用的是热图法
- 将检测到的关键点通过仿射变换的逆变换还原成原图像中的坐标.
Alphapose的单人姿态估计网络主要有三种输出格式:coco 17关键点,Halpe 26关键点和Halpe 136关键点.
coco17关键点比较常见,其实可以用其他单人姿态估计模型替代,比如这个南京大学做的SimpleBaseline的轻量化:https://github.com/zhang943/lpn-pytorch
Halpe是Alphapose自己的数据集,需要自己重新训练模型.
训练轻量化的单人姿态估计模型
下载数据集
到Alphapose的这个子项目Fang-Haoshu/Halpe-FullBody下载数据集
在data文件夹下按照下面的目录结构进行组织,这里我应该改过一些文件名称,需要和下面创建的训练文件进行对应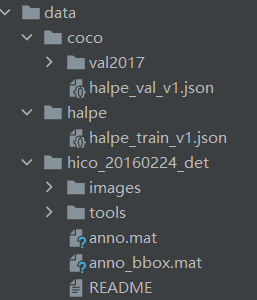
- 其实完整的模型应该要在:300wLP(脸部)、Halpe数据集(全身)和frei(手部)三个数据集训练,否则至训练Halpe数据集的化手部和脸部的效果会比较差,不过因为设备和时间的问题,我只训练了Halpe数据集的136个关键点,虽然map有下降,不过实际效果也基本能满足项目需求.
创建FastPoseMobile
在alphapose/models目录下创建自己的轻量化模型.我命名叫FastPoseMobile
这里使用torchvision的mobilenetv3轻量化了fastpose的骨干网络
- 这里提一嘴,貌似Alphapose里的Alphapose和fastpose的论文没啥关系,可能就是个模型结构吧.
- 创建好的模型需要添加`@SPPE.registe在这里插入图片描述
r_module`注解
- 在
alphapose/models/__init__.py文件的__all__字典里添加FastPoseMobile - mobilenet_v3是我从torchvision里面改的,内容比较多,这里就不放出来了
# -----------------------------------------------------
# Copyright (c) Shanghai Jiao Tong University. All rights reserved.
# Written by Jiefeng Li (jeff.lee.sjtu@gmail.com)
# -----------------------------------------------------
import torch.nn as nn
from .builder import SPPE
from .layers.DUC import DUC
from .layers.mobilenet_v3 import mobilenet_v3
@SPPE.register_module
class FastPoseMobile(nn.Module):
def __init__(self, norm_layer=nn.BatchNorm2d, **cfg):
super(FastPoseMobile, self).__init__()
self._preset_cfg = cfg['PRESET']
if 'CONV_DIM' in cfg.keys():
self.conv_dim = cfg['CONV_DIM']
else:
self.conv_dim = 128
assert cfg['MODEL_SIZE'] in ['large', 'small']
self.preact = mobilenet_v3(cfg['MODEL_SIZE'])
output_num = 960 // 4 if cfg['MODEL_SIZE'] == 'large' else 576 // 4
self.suffle1 = nn.PixelShuffle(2)
self.duc1 = DUC(output_num, 1024, upscale_factor=2, norm_layer=norm_layer)
if self.conv_dim == 256:
self.duc2 = DUC(256, 1024, upscale_factor=2, norm_layer=norm_layer)
else:
self.duc2 = DUC(256, self.conv_dim * 4, upscale_factor=2, norm_layer=norm_layer)
self.conv_out = nn.Conv2d(
self.conv_dim, self._preset_cfg['NUM_JOINTS'], kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.preact(x)
out = self.suffle1(out)
out = self.duc1(out)
out = self.duc2(out)
out = self.conv_out(out)
return out
def _initialize(self):
for m in self.conv_out.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# logger.info('=> init {}.weight as normal(0, 0.001)'.format(name))
# logger.info('=> init {}.bias as 0'.format(name))
nn.init.normal_(m.weight, std=0.001)
nn.init.constant_(m.bias, 0)
创建训练文件
创建训练文件configs/halpe_136/mobilenet/256x192_mobilenet_lr1e-3_2x-regression.yaml
- 要训练其他数据集可以参考这个格式编写一下其他训练文件,主要是改一下DATASET下面的文件地址.
DATASET:
TRAIN:
TYPE: 'Halpe_136'
ROOT: './data/halpe/'
IMG_PREFIX: 'train2017'
ANN: 'halpe_train_v1.json'
AUG:
FLIP: true
ROT_FACTOR: 45
SCALE_FACTOR: 0.35
NUM_JOINTS_HALF_BODY: 8
PROB_HALF_BODY: 0.3
VAL:
TYPE: 'Halpe_136'
ROOT: './data/coco/'
IMG_PREFIX: 'val2017'
ANN: 'halpe_val_v1.json'
TEST:
TYPE: 'Halpe_136_det'
ROOT: './data/coco/'
IMG_PREFIX: 'val2017'
DET_FILE: './exp/json/test_det_yolo.json'
ANN: 'halpe_val_v1.json'
DATA_PRESET:
TYPE: 'simple'
LOSS_TYPE: 'L1JointRegression'
SIGMA: 2
NUM_JOINTS: 136
IMAGE_SIZE:
- 256
- 192
HEATMAP_SIZE:
- 64
- 48
MODEL:
TYPE: 'FastPoseMobile'
PRETRAINED: ''
TRY_LOAD: ''
NUM_DECONV_FILTERS:
- 256
- 256
- 256
MODEL_SIZE: 'large'
CONV_DIM: 256
LOSS:
TYPE: 'L1JointRegression'
NORM_TYPE: 'sigmoid'
OUTPUT_3D: False
DETECTOR:
NAME: 'yolo'
CONFIG: 'detector/yolo/cfg/yolov3-spp.cfg'
WEIGHTS: 'detector/yolo/data/yolov3-spp.weights'
NMS_THRES: 0.6
CONFIDENCE: 0.05
TRAIN:
WORLD_SIZE: 4
BATCH_SIZE: 48
BEGIN_EPOCH: 0
END_EPOCH: 270
OPTIMIZER: 'adam'
LR: 0.001
LR_FACTOR: 0.1
LR_STEP:
- 170
- 200
DPG_MILESTONE: 210
DPG_STEP:
- 230
- 250
开始训练
修改train.py文件的配置,将–cfg的默认值修改成刚才的训练文件.
parser.add_argument('--cfg', default="configs/halpe_136/mobilenet/256x192_mobilenet_lr1e-3_2x-regression.yaml",
help='experiment configure file name',
type=str)
然后就可以把项目部署到gpu服务器上训练了.
训练结果
用八张卡的rtx3090训练了大概6天,模型在209轮达到了最好的效果,准确率大概90%多,之后就过拟合了.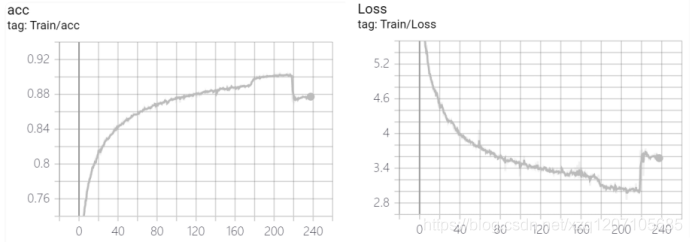
识别效果其实还是不错的,面部的关键点回归会稍微有点扭曲,勉强可以使用,手部的基本没法用,需要用另外两个数据集进一步训练,不过这边也用不上.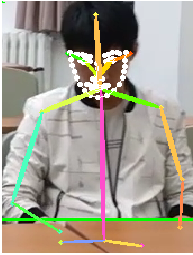
训练项目和数据集
- 在
.tensorboard文件夹里包含我之前训练好的权重
边栏推荐
猜你喜欢


随机推荐
win10怎么设置不睡眠熄屏?win10设置永不睡眠的方法
The SSE instructions into ARM NEON
Use tencent cloud builds a personal blog
General code for pytorch model to libtorch and onnx format
Mysql的锁
win10无法直接用照片查看器打开图片怎么办
mysql的索引结构为什么选用B+树?
发布模块到npm应该怎么操作?及错误问题解决方案
镜像法求解接地导体空腔电势分布问题
Win7遇到错误无法正常开机进桌面怎么解决?
Mysql connection error solution
arm ldr系列指令
LORA芯片ASR6601支持M4内核的远距离传输芯片
PyTorch①---加载数据、tensorboard的使用
HAL框架
FP6195耐压60V电流降压3.3V5V模块供电方案
FP6296锂电池升压 5V9V12V内置 MOS 大功率方案原理图
win10 system update error code 0x80244022 how to do
Win11 computer off for a period of time without operating network how to solve
【使用Pytorch实现VGG16网络模型】