当前位置:网站首页>flink二開,實現了個 batch lookup join(附源碼)
flink二開,實現了個 batch lookup join(附源碼)
2022-07-02 11:01:00 【Direction_Wind】
本文轉載自:大數據羊說的一篇公眾號文章,這裏只做學習用,沒有任何盈利行為。
flink二開,實現了個 batch lookup join(附源碼)
1.序篇
書接上回,上節說到了博主發現由於在 flink sql 中 lookup join 訪問外部維錶存在的性能問題。
由此誕生了一個想法,以 Redis 維錶為例,Redis 支持 pipeline 批量訪問模式,因此 flink sql lookup join 能不能按照 DataStream 方式一樣,先攢一批數據 ,然後使用 Redis pipeline 批量訪問外部存儲。博主親切的將這個功能稱為 flink sql batch lookup join,本節就是講述博主基於 flink 源碼對此功能的實現。
廢話不多說,咱們先直接上本文的目錄和結論,小夥伴可以先看結論快速了解博主期望本文能給小夥伴們帶來什麼幫助:
直接來一個實戰案例:博主以曝光用戶日志流關聯用戶畫像(年齡、性別)維錶為例介紹 batch lookup join 具有的基本能力(怎麼配置參數,怎麼寫 sql,最終效果咋樣)。
batch lookup join:主要介紹 batch lookup join 的功能是從 flink transformation 出發,確定要 batch lookup join 涉及改動的地方以及其實現思路、原理。也會教給大家一些改動源碼來實現自己想要的一些功能的思路。
總結及展望:目前的 batch lookup join 實現其實不符合 sql 的原始語義,後續大家可以按照 sql 標准自己做一些實現
2.來一個實戰案例
2.1.預期的輸入、輸出數據
來看看在具體場景下,對應輸入值的輸出值應該長啥樣。
需求指標:使用曝光用戶日志流(show_log)關聯用戶畫像維錶(user_profile)關聯到用戶的畫像(性別,年齡段)數據。
來一波輸入數據:
曝光用戶日志流(show_log)數據(數據存儲在 kafka 中):
| log_id | timestamp | user_id |
|---|---|---|
| 1 | 2021-11-01 | |
| 2 | 2021-11-01 | 00:03:00 |
| 3 | 2021-11-01 | 00:05:00 |
| 4 | 2021-11-01 | 00:06:00 |
| 5 | 2021-11-01 | 00:07:00 |
用戶畫像維錶(user_profile)數據(數據存儲在 redis 中):
| user_id(主鍵) | age | sex |
|---|---|---|
| a | 12-18 | 男 |
| b | 18-24 | 女 |
| c | 18-24 | 男 |
注意:redis 中的數據結構存儲是按照 key,value 去存儲的。其中 key 為 user_id,value 為 age,sex 的 json。如下圖所示:

預期輸出數據如下:
| log_id | timestamp | user_id | age | sex |
|---|---|---|---|---|
| 1 | 2021-11-01 00:01:03 | a | 12-18 | 男 |
| 2 | 2021-11-01 00:03:00 | b | 18-24 | 女 |
| 3 | 2021-11-01 00:05:00 | c | 18-24 | 男 |
| 4 | 2021-11-01 00:06:00 | b | 18-24 | 女 |
| 5 | 2021-11-01 00:07:00 | c | 18-24 | 男 |
2.2.batch lookup join sql 代碼
batch lookup join sql 代碼和原來的 lookup join sql 代碼一模一樣。如下 sql。
CREATE TABLE show_log (
log_id BIGINT,
`timestamp` as cast(CURRENT_TIMESTAMP as timestamp(3)),
user_id STRING,
proctime AS PROCTIME()
)
WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.user_id.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE user_profile (
user_id STRING,
age STRING,
sex STRING
) WITH (
'connector' = 'redis',
'hostname' = '127.0.0.1',
'port' = '6379',
'format' = 'json',
'lookup.cache.max-rows' = '500',
'lookup.cache.ttl' = '3600',
'lookup.max-retries' = '1'
);
CREATE TABLE sink_table (
log_id BIGINT,
`timestamp` TIMESTAMP(3),
user_id STRING,
proctime TIMESTAMP(3),
age STRING,
sex STRING
) WITH (
'connector' = 'print'
);
-- lookup join 的 query 邏輯
INSERT INTO sink_table
SELECT
s.log_id as log_id
, s.`timestamp` as `timestamp`
, s.user_id as user_id
, s.proctime as proctime
, u.sex as sex
, u.age as age
FROM show_log AS s
LEFT JOIN user_profile FOR SYSTEM_TIME AS OF s.proctime AS u
ON s.user_id = u.user_id
可以看到 lookup join 和 batch lookup join 的代碼是完全相同的,唯一的不同之處在於,batch lookup join 需要設置 table config 參數,如下圖所示:
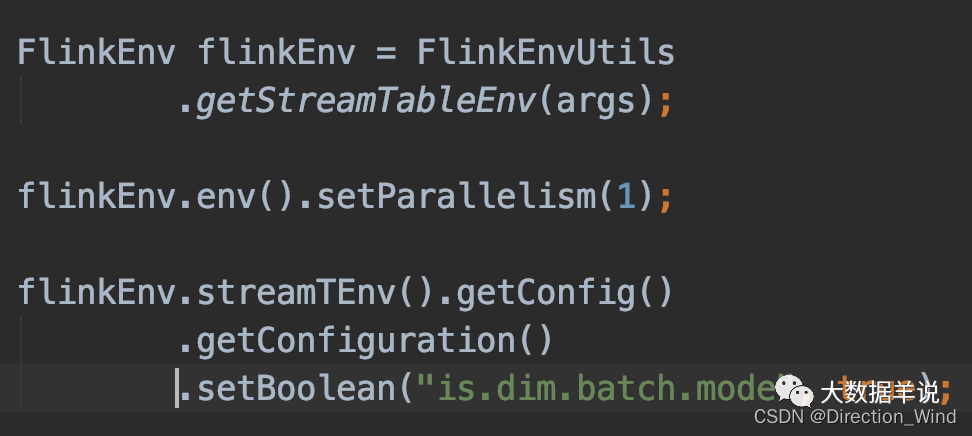
2.3.batch lookup join 效果
將原生 lookup join 和 batch lookup join 的效果做個對比:
原生的 lookup join:每輸入一條數據,訪問外部維錶獲取到結果輸出一條數據,如下圖所示。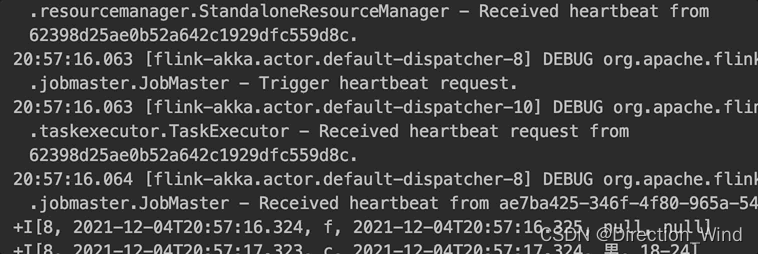
博主實現的 batch lookup join:是每攢够 30 條數據或者每 5s(防止數據量少的情况下,長時間不輸出數據) 就利用 redis pipeline 能力訪問外部存儲一次。然後批量輸出結果,如下圖所示。大大提高了吞吐。
3.batch lookup join 實現
3.1.怎麼知道應該改哪部分源碼?
博主將通過下面幾個問題去交給大家怎麼改源碼去實現自己的功能。
- 改源碼的有哪些比較好的思路?
- 結論:首先就是參考類似模塊的實現(不會寫,但是我會抄啊!),比如本文要實現 batch lookup join,必然要參考原生的 lookup join 去實現。
- 大家在改 flink 源碼時,因為 flink 源碼的模塊太多了,項目非常龐大,往往第一步碰到的問題不是怎麼去實現這個功能,而是應該在什麼地方去改才能實現!
- 結論:一個 flink 的任務(DataStream\Table\SQL)所有的精華精華精華都集中在 transformation 中!!!只要是涉及到算子實現的東西,小夥伴萌就可以到 transformation 中去尋找。可以將斷點打在每一個 operator 的構造器或者 open 方法中就可以看到其實在哪一步構造和初始化的。這樣就能順著調用棧往前回溯而確定要改哪部分代碼了。
3.2.lookup join 原理
3.2.1.transformation
在實現 batch lookup join 之前,當然要從原生的 lookup join 的實現開始入手,看看 flink 官方大大是怎麼實現的,具體 transformation 如下圖所示:
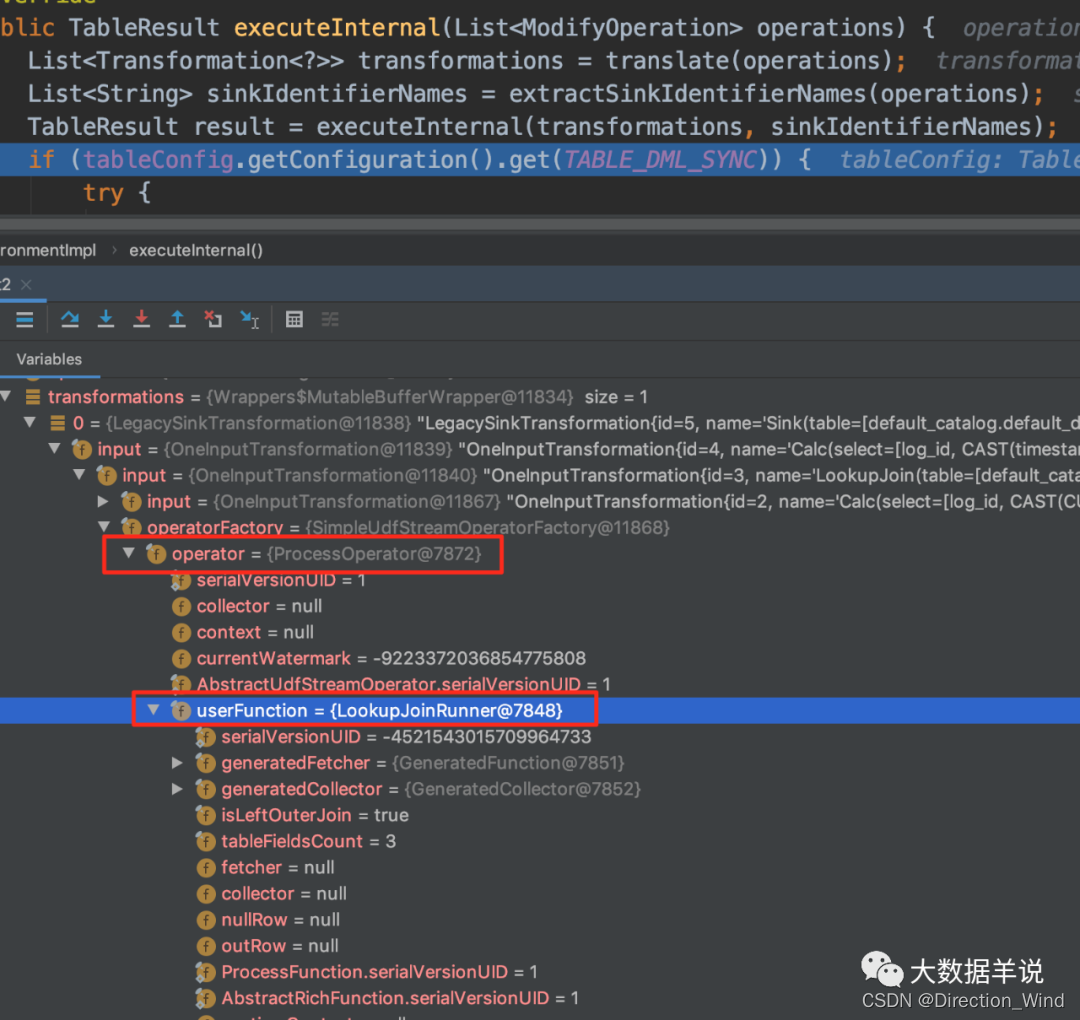
具體的實現邏輯承載在 org.apache.flink.streaming.api.operators.ProcessOperator,org.apache.flink.table.runtime.operators.join.lookup.LookupJoinRunner 中。
3.2.2.LookupJoinRunner
LookupJoinRunner 中的數據處理邏輯集中在 processElement 中。
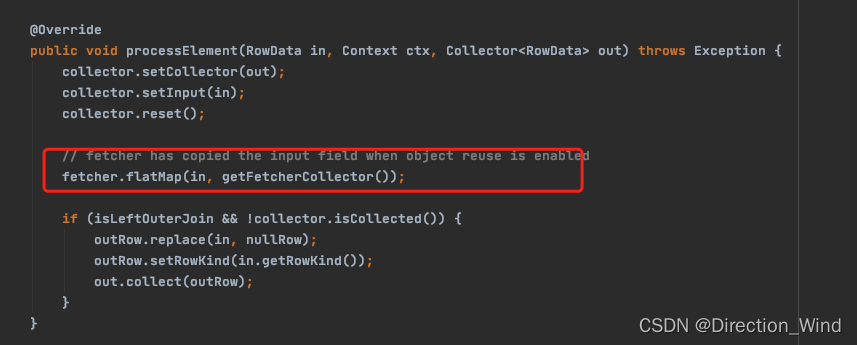
可以看到上圖,LookupJoinRunner 又內嵌了一層 fetcher 來實現具體的 lookup 邏輯。
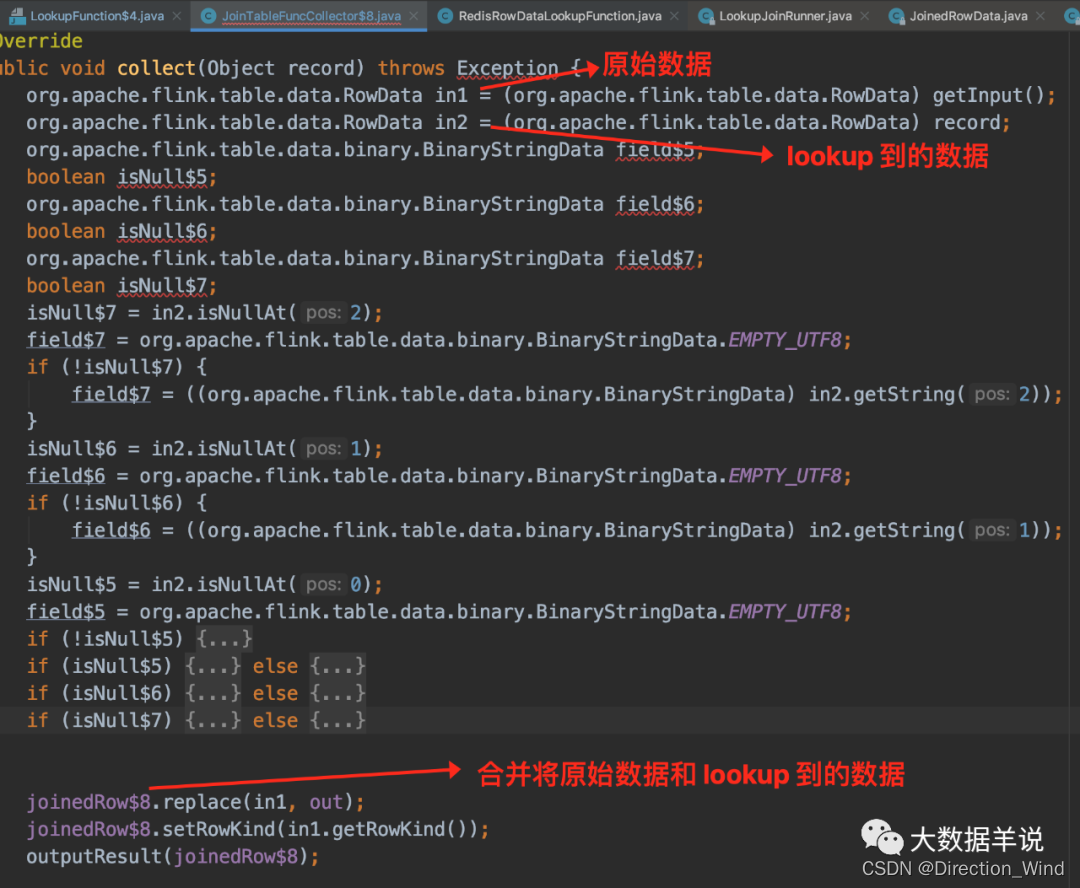
- 其中 fetcher:就是根據 flink sql lookup join 邏輯生成的 lookup join 的代碼實例;
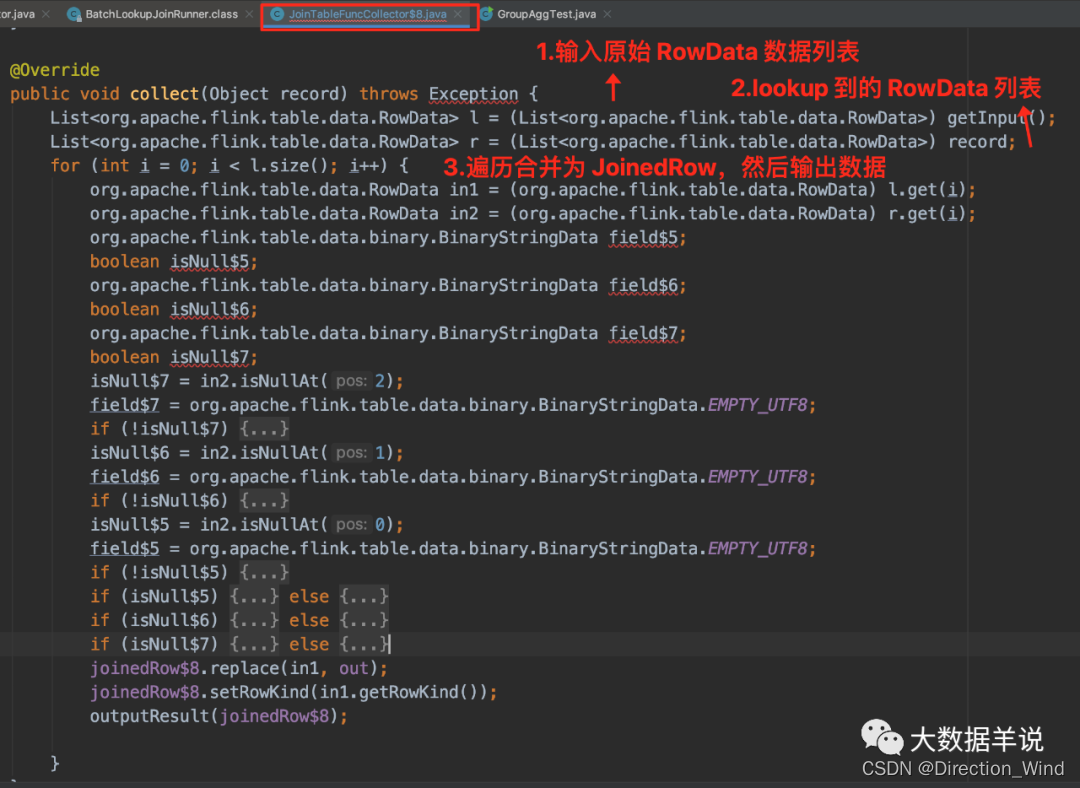
- 其中 collector:collector 的主要功能就是將原始數據 RowData 和 lookup 到的 RowData 的數據合並為 JoinedRowData 結果,然後輸出。
接下來詳細看看 fetcher 和 collector。
3.2.3.fetcher
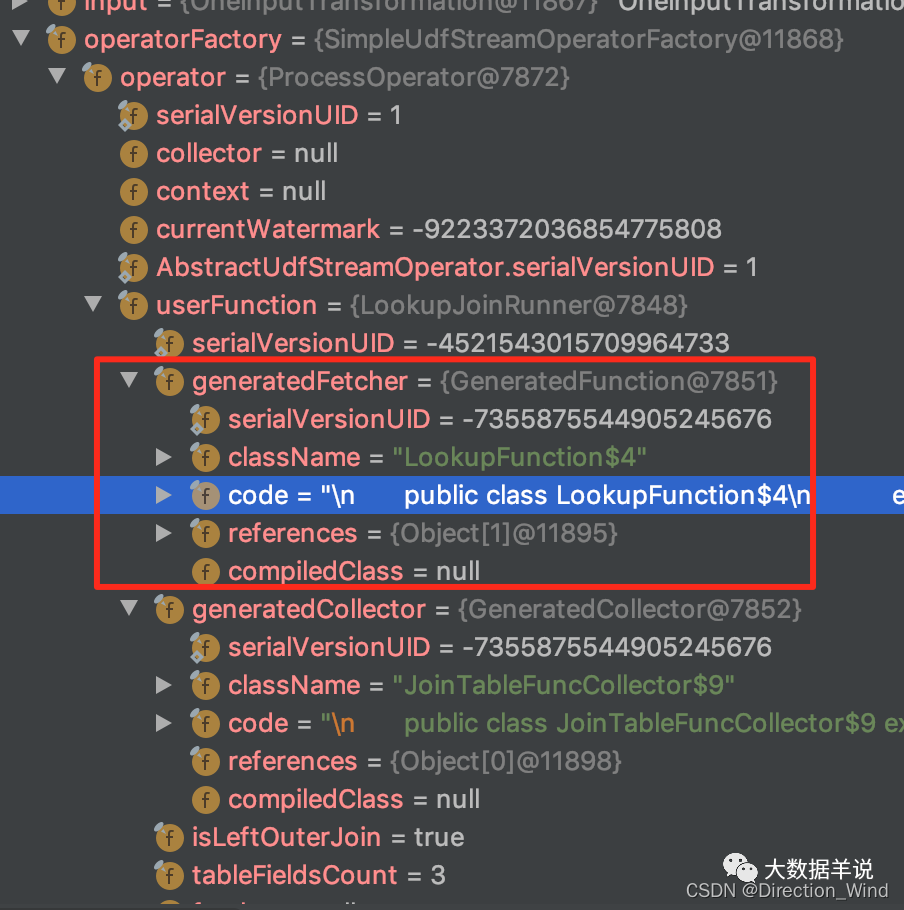
把這個 fetcher 的代碼 copy 出來瞅瞅。

fetcher 內嵌了 RedisRowDataLookupFunction 來作為最終訪問外部維錶的函數。
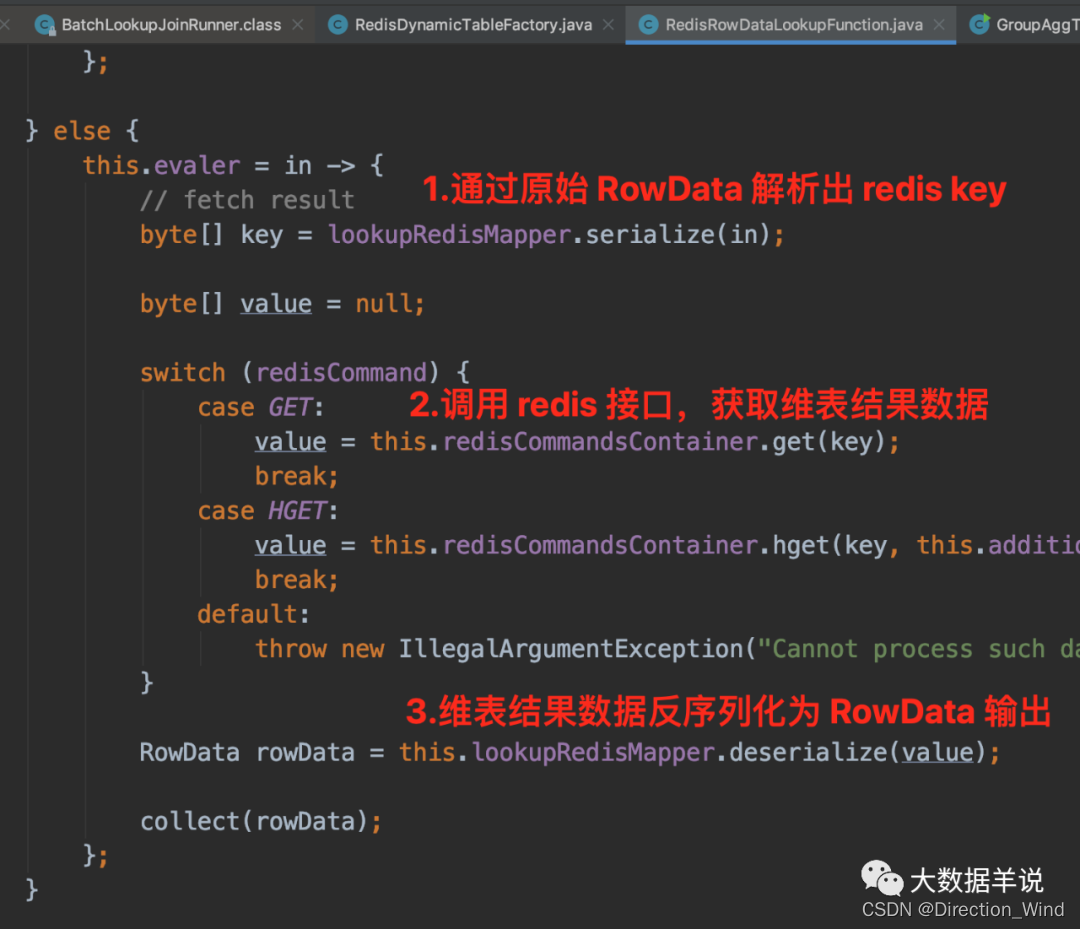
3.2.4.RedisRowDataLookupFunction
訪問 redis 獲取到數據。
3.2.5.collector
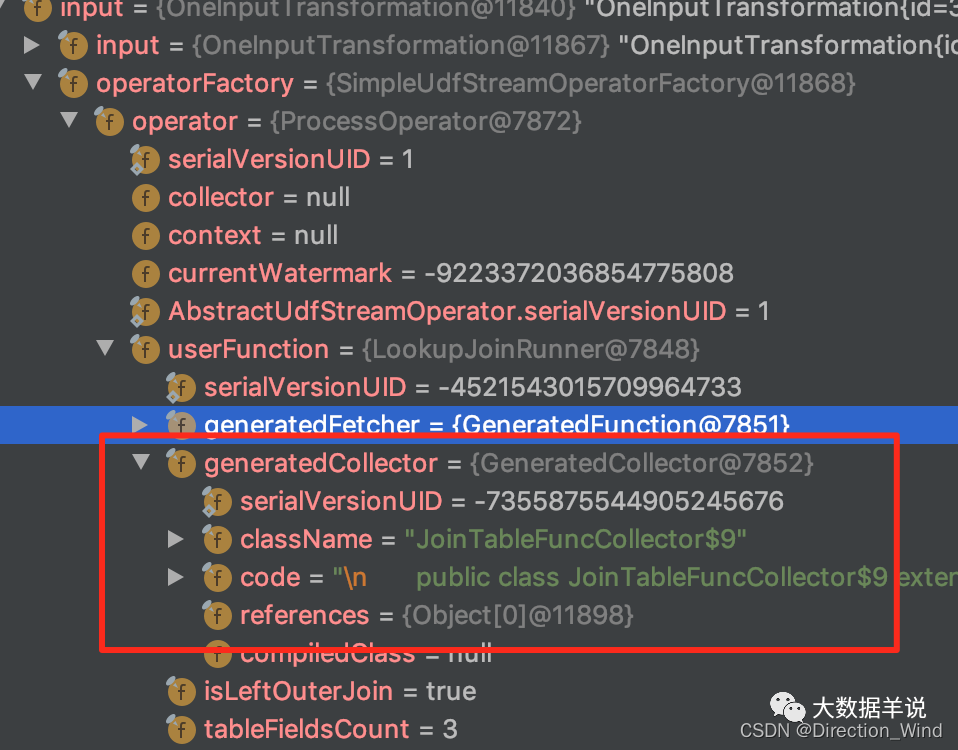
把這個 collector 的代碼 copy 出來瞅瞅。
3.3.lookup join 算子實現調用鏈
是不是感覺一個 lookup join 的調用鏈賊複雜。
因為 batch lookup join 是完全參考 lookup join 去實現的,所以接下來博主介紹一下整體的調用鏈關系,這就會方便後續設計 batch lookup join 實現方案的時候去確定具體修改哪一部分代碼。
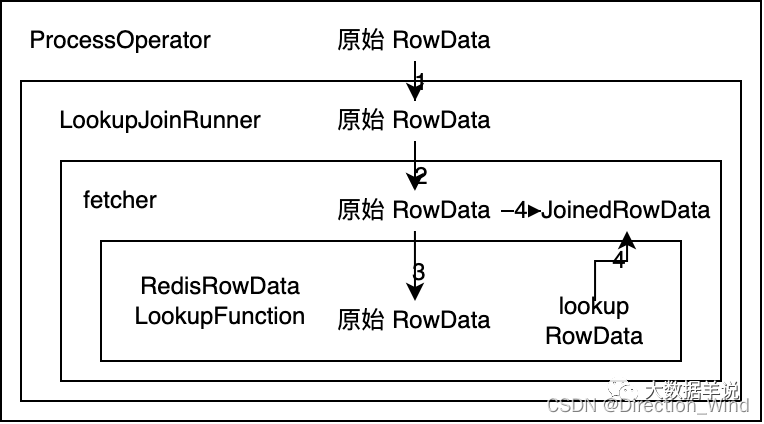
整體的調用邏輯如下:
- ProcessOpeartor 把 原始 RowData 傳給 LookupJoinRunner
- LookupJoinRunner 把 原始 RowData 傳給根據 sql 代碼生成的 fetcher
- fetcher 中把 原始 RowData 傳給 RedisRowDataLookupFunction 然後去 lookup 維錶,lookup 到的結果數據為 lookup RowData
- collector 把 原始 RowData 和 lookup RowData 數據合並為 JoinedRowData 然後輸出。
3.4.batch lookup join 設計思路
還是一樣,先看看設計思路最終的結論,batch lookup join 算子調用鏈設計如下:
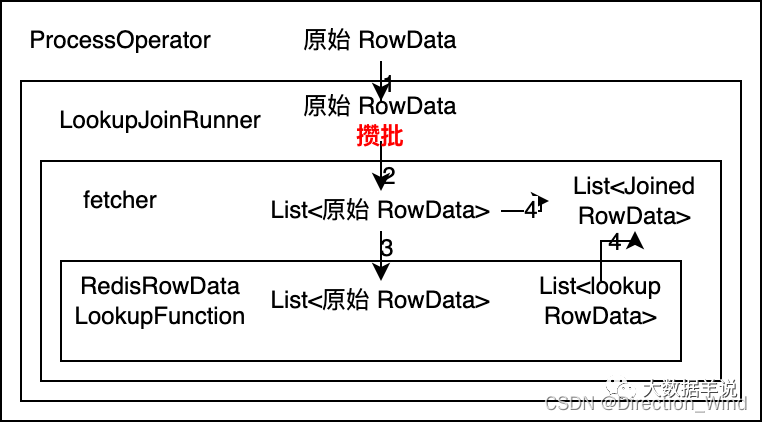
詳細說明一下設計思路:
- 如果想做到批量訪問外部存儲(Redis)的數據。可以推斷出 RedisRowDataLookupFunction 的輸入需要是 List<原始 RowData> ,輸出需要是 List。其中輸入數據輸入到 RedisRowDataLookupFunction 中後,使用 Redis pipeline 去批量訪問外部存儲,然後把結果 List 輸出。
- 由 RedisRowDataLookupFunction 的輸出數據為 List 推斷出 collector 輸入數據格式必然是 List<原始 RowData>。由於在 lookup join 中 collector 的邏輯就是將 原始 RowData 和 lookup RowData 合並為 JoinedRowData,將結果輸出。因此 collector 這裏就是將 List<原始 RowData> 和 List 進行遍曆合並,一條一條的輸出 JoinedRowData。
- 同樣 RedisRowDataLookupFunction 的輸入數據是 fetcher 傳入的,則推斷出 fetcher 輸入數據格式必然是 List<原始 RowData>。
- 由於 fetcher 輸入是 List<原始 RowData>,則 LookupJoinRunner 輸出到 fetcher 的數據也需要是 List<原始 RowData>。但是 ProcessOpeartor 只能傳給 LookupJoinRunner 原始 RowData,因此可以得出我們的每攢 30 條數據或者每隔 5s 的邏輯就能確定需要在 LookupJoinRunner 中做了。
思路有了,那麼 batch lookup join 涉及到的改動項也就能確認了。
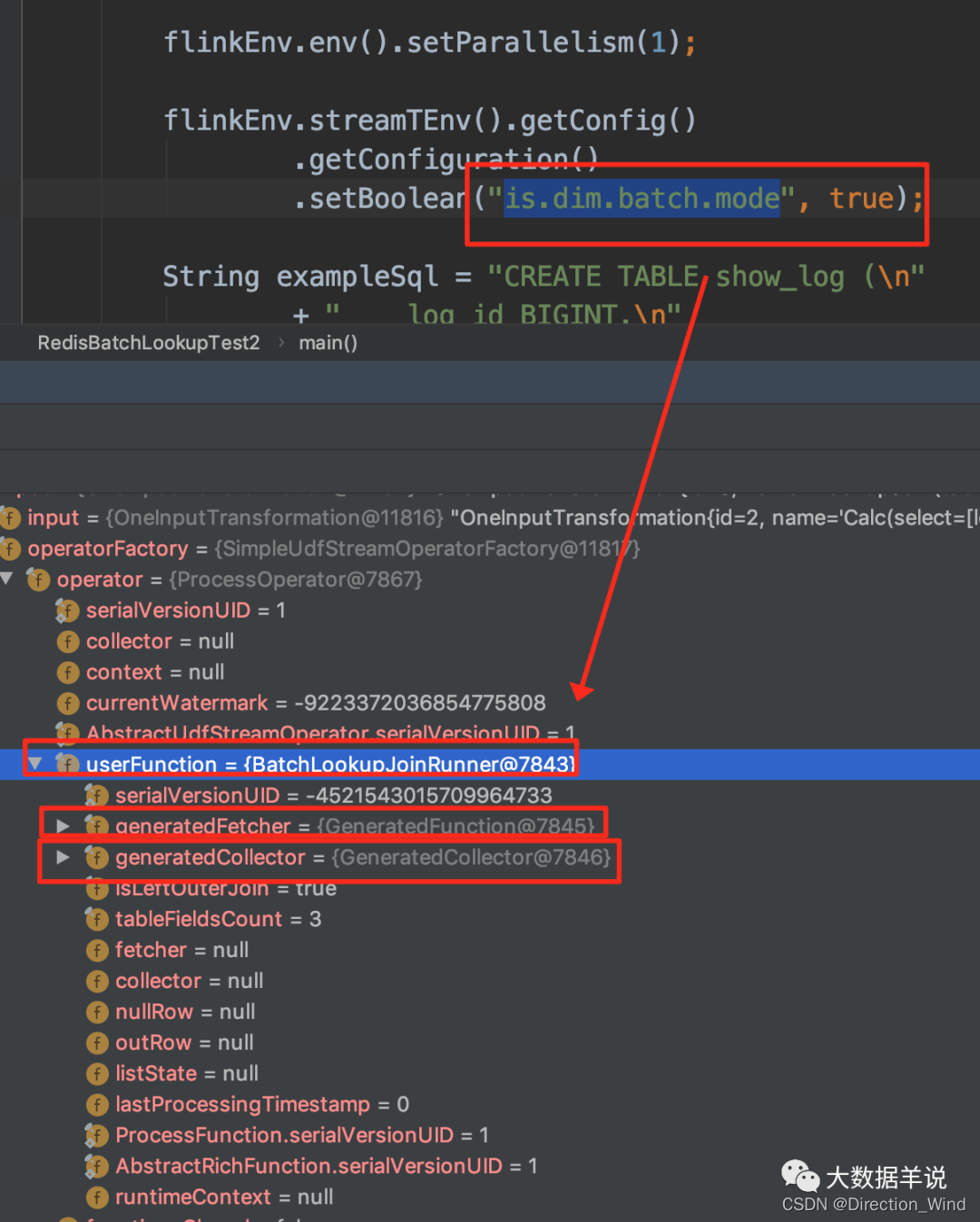
- 新建一個 BatchLookupJoinRunner:實現攢批邏輯(每攢 30 條數據或者每隔 5s),其中攢批的數據放在 ListState 中,以防止丟失,在 table config 中的 is.dim.batch.mode 設置為 true 時使用此 BatchLookupJoinRunner。
- 代碼生成的 fetcher:將原來輸入的 原始 RowData 改為 List<原始 RowData>。
- 新建一個 RedisRowDataBatchLookupFunction:實現將輸入的批量數據 List<原始 RowData> 拿到之後使用 redis pipeline 批量訪問外部存儲,獲取到 List 結果數據給 collector。
- 代碼生成的 collector:將原來 lookup join 中的輸入 原始 RowData,lookup RowData 改為 List<原始 RowData>,List,添加遍曆循環 List<原始 RowData>,List,按順序合並 List 中的每一項 原始 RowData,lookup RowData 輸出 JoinedRowData 的邏輯。
3.5.batch lookup join 的最終效果
3.5.1.transformation
可以看到 is.dim.batch.mode 設置為 true 時,transformation 如下。transformation 中的重點處理邏輯就是 BatchLookupJoinRunner
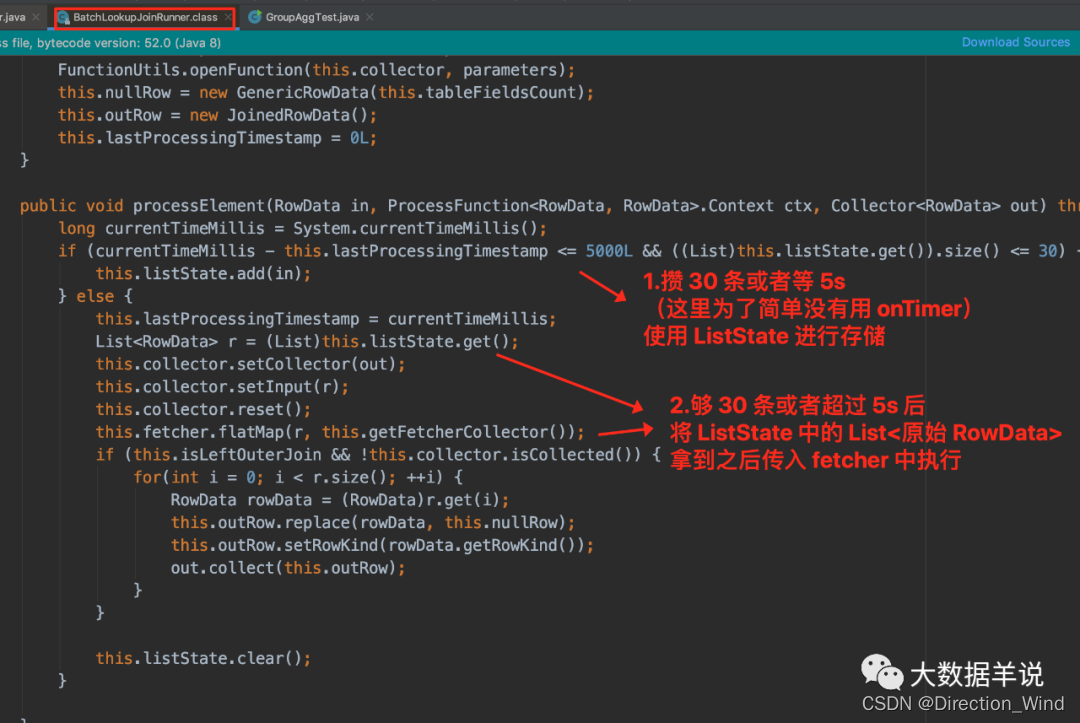
3.5.2.BatchLookupJoinRunner
3.5.3.fetcher

3.5.4.RedisRowDataBatchLookupFunction
RedisRowDataBatchLookupFunction 拿到輸入的 List 數據,調用 Redis pipeline 批量訪問外部存儲。

3.5.5.collector
sql 生成的 collector 代碼如下:
3.6.待改進項
目前上述方案實現的不足之處如下:
- batch 的執行邏輯與 sql 原始的語義不一致。因為從 sql 上看是完全沒有這種 batch lookup join 的語義的。
- 其中每 5s博主簡單實現了下,完全基於數據驅動的每 5s 攢一批,不是基於 onTimer 驅動的。可能會出現來了一條數據之後,5 min 內都沒有來數據,則數據就不輸出了。
- 沒有考慮實現代碼的抽象,以實現功能為主,所以很多基於源碼的改動都是直接 copy 出來了另一個方法實現。
4.xdm 怎麼使用這個功能?
打包項目 重新把下面兩個模塊 install (mvn clean install) 到本地倉庫中。
然後在你的項目中引用兩個 blink 包即可使用。使用方法就是只需要把 table config 的 is.dim.batch.mode 設置為 true,代碼還按照 lookup join 的方式寫即可。
边栏推荐
- In the face of uncertainty, the role of supply chain
- HDU1234 开门人和关门人(水题)
- Special topic of binary tree -- Logu p1229 traversal problem (the number of traversals in the middle order is calculated when the pre and post order traversals of the multiplication principle are know
- 如何用list组件实现tabbar标题栏
- 长投学堂上面的账户安全吗?
- 【快应用】text组件里的文字很多,旁边的div样式会被拉伸如何解决
- 2022-06-17
- Binary tree topic -- Luogu p3884 [jloi2009] binary tree problem (DFS for binary tree depth BFS for binary tree width Dijkstra for shortest path)
- 2. Hacking lab script off [detailed writeup]
- Overview of integrated learning
猜你喜欢

如何使用IDE自动签名调试鸿蒙应用
JSP webshell免杀——JSP的基础

MySQL数据库远程访问权限设置
二叉树专题--AcWing 3384. 二叉树遍历(已知先序遍历 边建树 边输出中序遍历)

【深入浅出玩转FPGA学习3-----基本语法】

HDU1228 A + B(map映射)

洛谷 P5536 【XR-3】核心城市(贪心 + 树形 dp 寻找树的中心)

Analysis of hot spots in AI technology industry

Introduction to MySQL 8 DBA foundation tutorial

From Read and save in bag file Jpg pictures and PCD point cloud
随机推荐
Special topic of binary tree -- Logu p1229 traversal problem (the number of traversals in the middle order is calculated when the pre and post order traversals of the multiplication principle are know
JSP webshell免杀——webshell免杀
Special topic of binary tree -- acwing 3384 Binary tree traversal (known preorder traversal, while building a tree, while outputting middle order traversal)
Read H264 parameters from mediarecord recording
华为联机对战服务玩家掉线重连案例总结
快应用中实现自定义抽屉组件
PCL eigen introduction and simple use
Luogu p4281 [ahoi2008] emergency gathering / gathering (tree doubling LCA)
JSP webshell免殺——JSP的基礎
2. Hacking lab script off [detailed writeup]
2022爱分析· 国央企数字化厂商全景报告
洛谷 P4281 [AHOI2008]紧急集合 / 聚会(树上倍增 LCA)
UVM——Callback
P1055 [noip2008 popularization group] ISBN number
二叉树专题--AcWing 3540. 二叉搜索树建树(实用板子 构建二叉搜索树 并输出前、中、后序遍历)
Dialogue Wu Gang: why do I believe in the rise of "big country brands"?
MySQL environment configuration
Point cloud projection picture
UWA report uses tips. Did you get it? (the fourth bullet)
How to transfer event objects and user-defined parameters simultaneously in Huawei express applications