当前位置:网站首页>四、机器学习基础
四、机器学习基础
2022-07-07 06:37:00 【Dragon Fly】
文章目录
1、训练集(training),交叉验证集(dev)和测试集(test)
\qquad 在拿到原始数据之后,需要将数据进行划分成为三部分:训练集,交叉验证集合测试集。其中,当数据量比较小时,可以采用60/20/20的比例进行划分;当数据量比较大时,可以将交叉验证集合测试集的占比调小,如使用98/1/1的比例进行分配。需要保证交叉验证集和测试集的分布规律和训练集的分布规律相同。
2、偏差(bias)和方差(variance)的处理
\qquad 当不能通过绘制图像来直观表现bias和variance时,可以通过训练集和偏差率和交叉验证集和偏差率来判断模型是过拟合还是欠拟合,判断方法如下所示: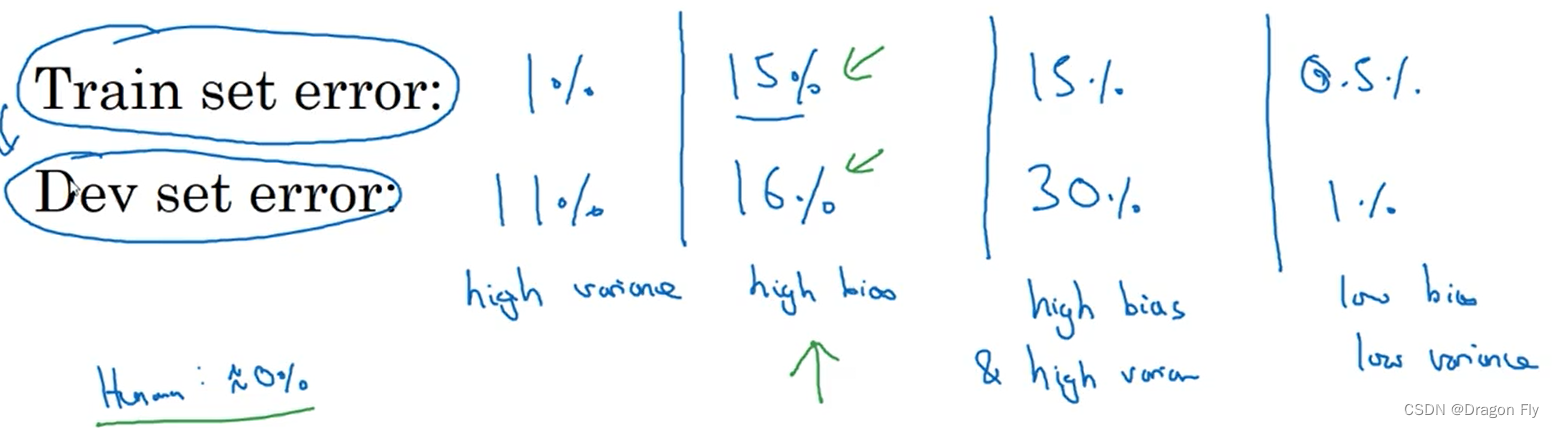
3、Basic recipe for machine learning
\qquad 在设计一个神经网络模型时,首先可以通过bias值和variance值来迅速判断网络设计的是否合理,当出现较高的bias时,可以通过加深网络的层数,训练更多的次数来进行网络的改进,直到bias比较小为止;之后再判断当前的variance是否也比较小,若出现variance比较大的情况,则可以通过获取更多的数据,归一化处理来进行模型的改进。之后再去判断bias,如此循环,一直到bias和variance 均比较小为止。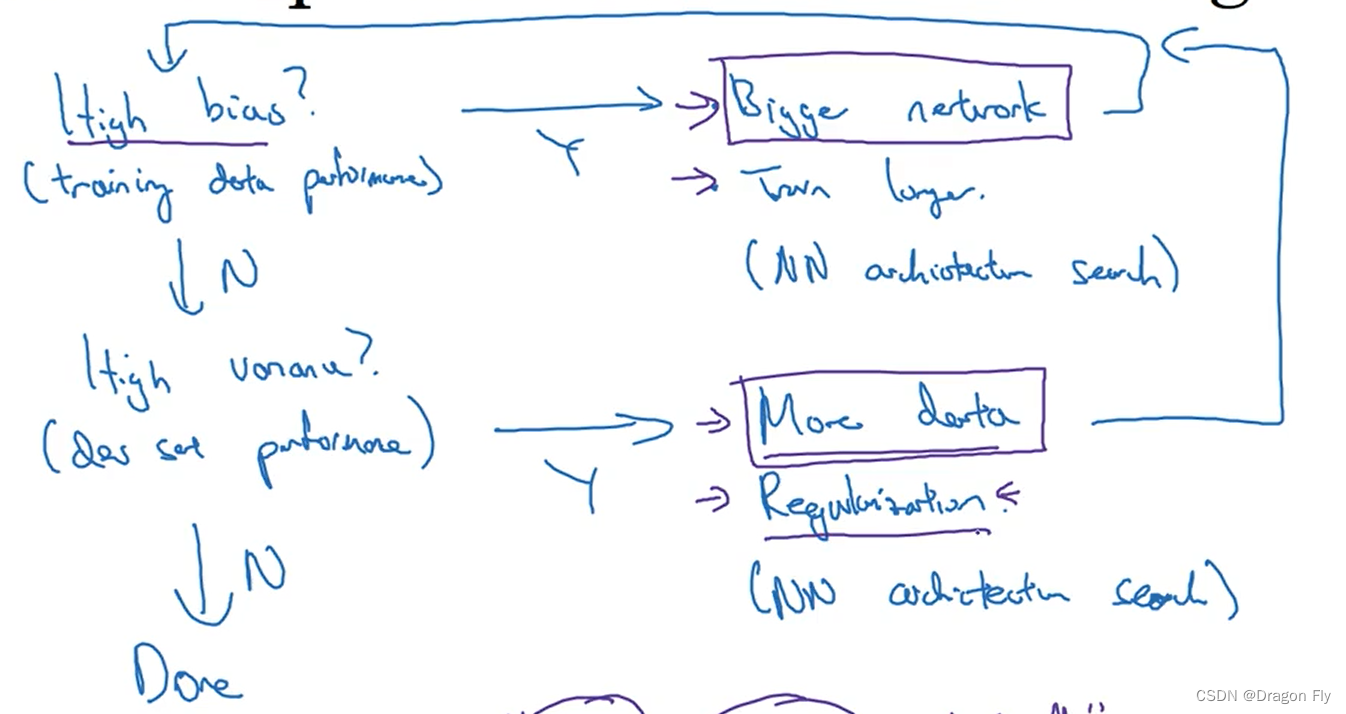
4、神经网络的归一化/正则化
\qquad 当训练神经网络时出现了过拟合的现象,第一个应该尝试的手段就是归一化处理(regularization)。如下例,对于逻辑回归问题的正则化处理如下所示: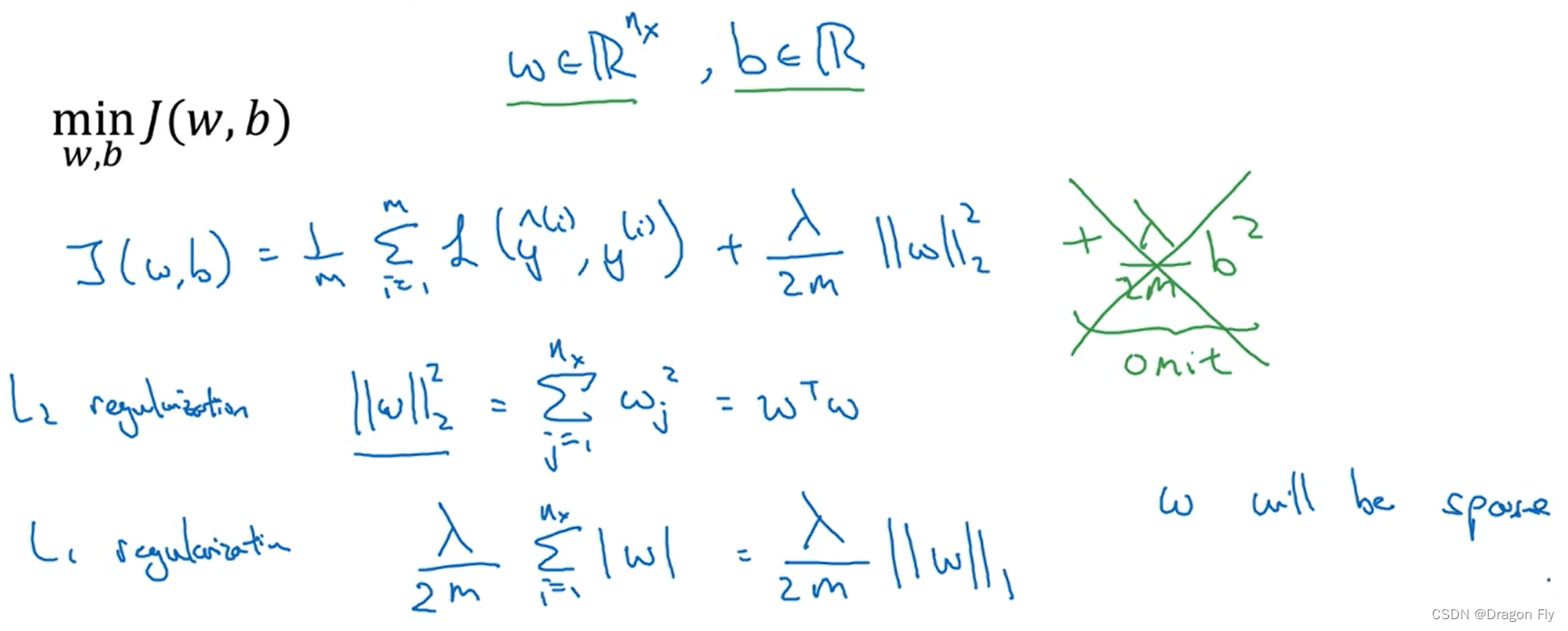
\qquad 使用 L 2 L_2 L2正则化处理之后,在反向传播时,更新参数W的值的时候,会有一个系数折减,使得W的值相对于不使用正则化时更小,这叫做weight decay。添加了正则化项之后的 d w [ l ] = ( f r o m b a c k p r o p ) + λ m w [ l ] d\ w^{[l]}=(from \ backprop) +\frac{\lambda}{m}w^{[l]} d w[l]=(from backprop)+mλw[l],recall参数更新规则为: w [ l ] = w [ l ] − α ( d w [ l ] ) w^{[l]}=w^{[l]}-\alpha\ (d\ w^{[l]}) w[l]=w[l]−α (d w[l]),可以推出 w [ l ] = w [ l ] − α λ m w [ l ] − α ( f r o m b a c k p r o p ) w^{[l]}=w^{[l]}-\frac{\alpha \lambda}{m}w^{[l]}-\alpha(from \ backprop) w[l]=w[l]−mαλw[l]−α(from backprop)
4.1 正则化可以减少过拟合风险的原因
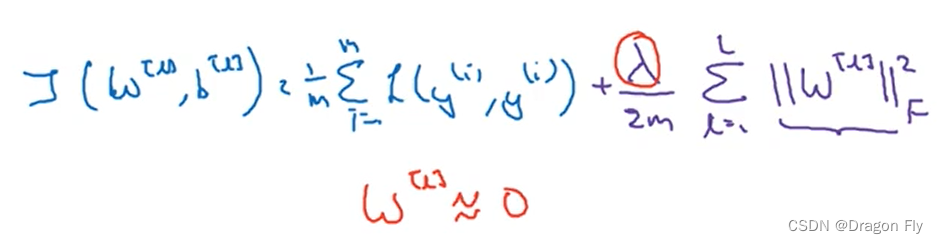
\qquad 首先从直观上理解,当正则化参数 λ \lambda λ设置较大时,权重项 W W W会相应减小,因为目标是最小化损失函数 J J J,可以近似理解为削减了某些神经网络层的影响,从而减小过拟合的风险。从深层次理解,如下图所示,若使用tanh作为激活函数,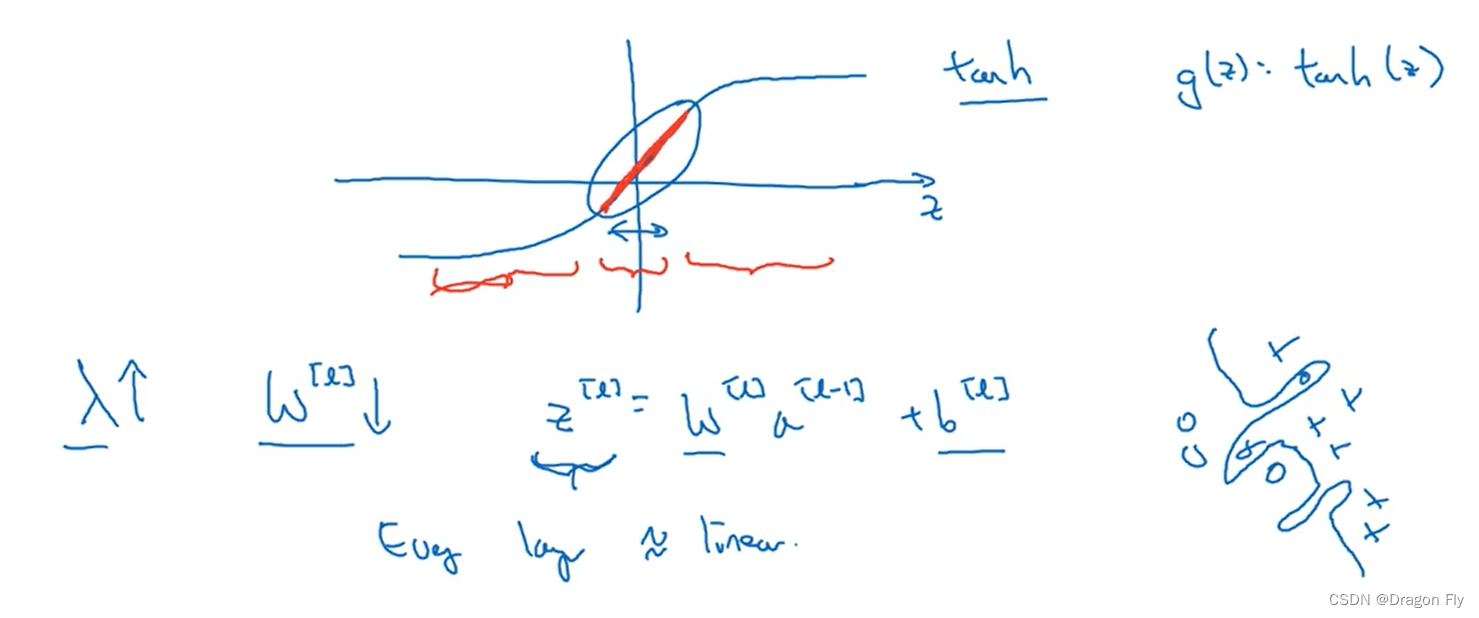
\qquad 增大 λ \lambda λ的值会使得权重的值 w w w减小,从而使得神经网络的计算值 z z z减小,对于tanh激活函数, z z z值减小意味这激活函数近似为线性函数,所以不会使得神经网络学习出非常复杂的高次函数,从而减少过拟合的风险。
4.2 Drop out 归一化
\qquad Drop的基本思想是将每一层的神经网络中的神经元个数进行随机或者规定缩减一定的数量,从而减少过拟合的风险。Inverted dropout的执行过程如下所示:
\qquad 其中, d 3 d_3 d3表示需要进行去除的神经元的比例为20%,之后计算当前神经网络层的新的神经元输入值 a 3 a_3 a3,最后为了使得dropout前后,当前层的神经网络计算值大致保持不变,需要将dropout的神经元输入值进行除以 0.8 0.8 0.8。在训练数据的时候通常使用dropout,但是在测试数据的时候,通常不使用dropout,因为会引入随机因素,使得测试的结果波动较大。
4.3 其他归一化方法
\qquad data argument可以作为一种防止过拟合的方法,如在图像识别领域,通过将input data的各种图片进行简单的水平变换操作,增加数据集的数量,来防止过拟合的出现。
\qquad early stopping时另一种防止过拟合的方法,当训练集的训练误差不断减小的过程,交叉验证集的误差可以会增大,这种情况下,可以在交叉验证集误差最小的地方终止训练,从而放置过拟合。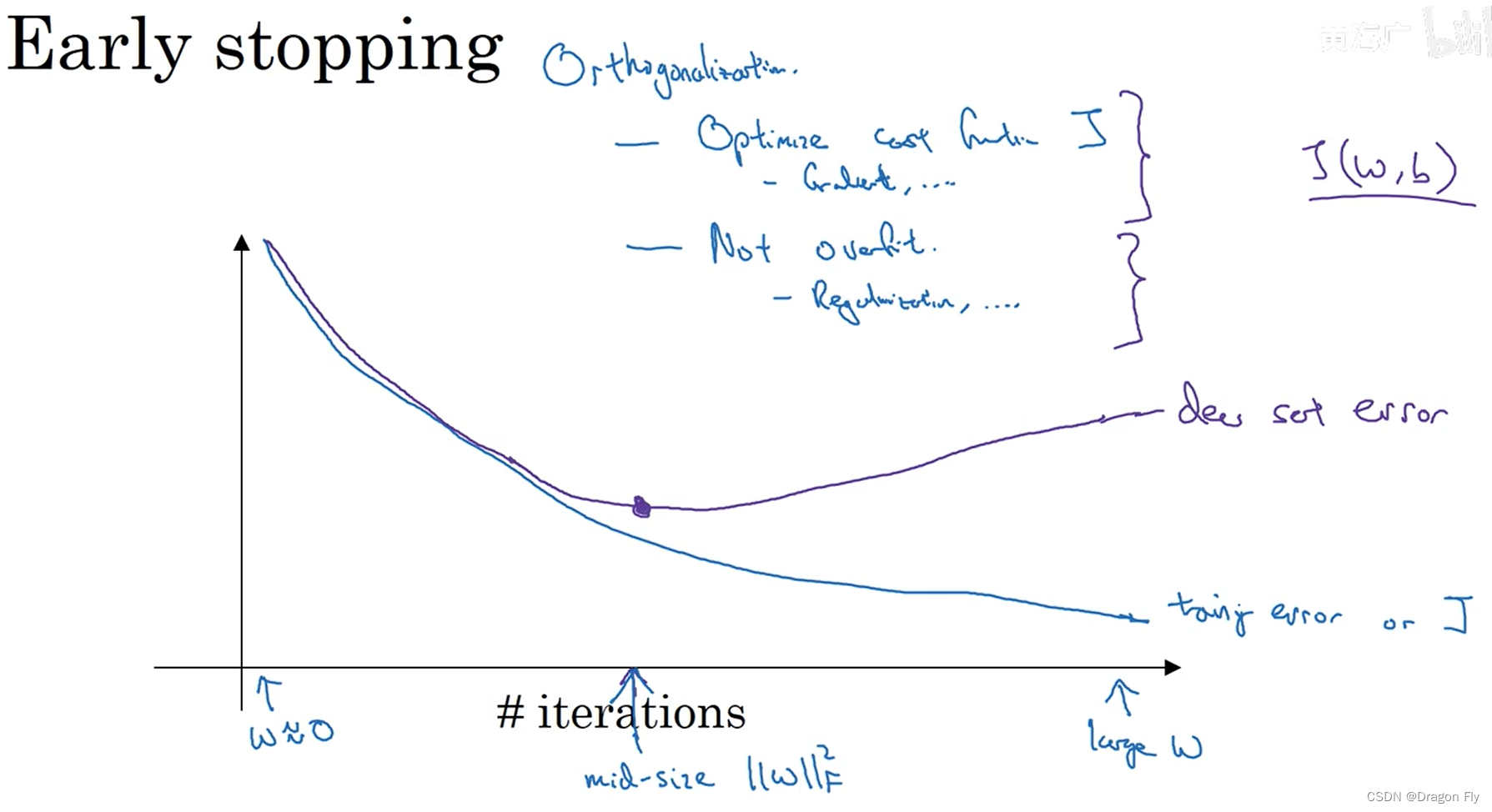
5、设置问题来加速模型训练
5.1归一化数据集
\qquad 归一化数据集features的方法可以将输入数据首先减去均值(mean),之后再归一化方差(various)。
μ = 1 m ∑ i = 1 m x i x : = x − μ σ 2 = 1 m ∑ i = 1 m ( x i ) 2 x : = x / σ \mu = \frac{1}{m} \sum_{i=1}^{m}x^{i} \\ x:=x-\mu \\ \sigma^2=\frac{1}{m}\sum_{i=1}^{m}(x^{i})^2 \\ x:=x/ \sigma μ=m1i=1∑mxix:=x−μσ2=m1i=1∑m(xi)2x:=x/σ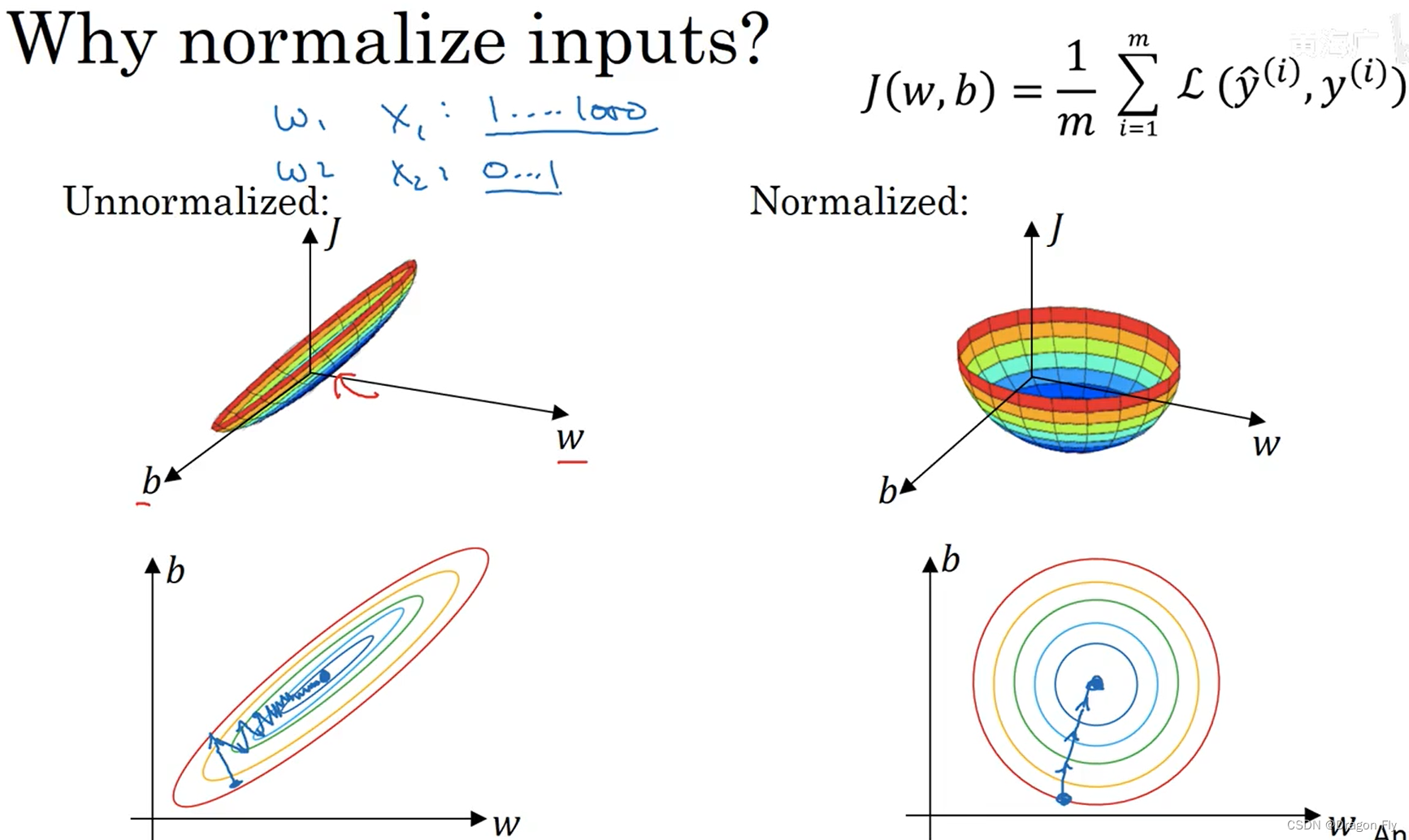
\qquad 当训练数据的特征取值区间差别很大时,有必要对features进行归一化,从而使得梯队下降执行的次数更少,同时可以增大学习率来提高学习效率。
5.2 梯度消失和梯度爆炸
\qquad 在训练深度网络时,比较容易出现梯度消失和梯度爆炸的问题,如下图所示: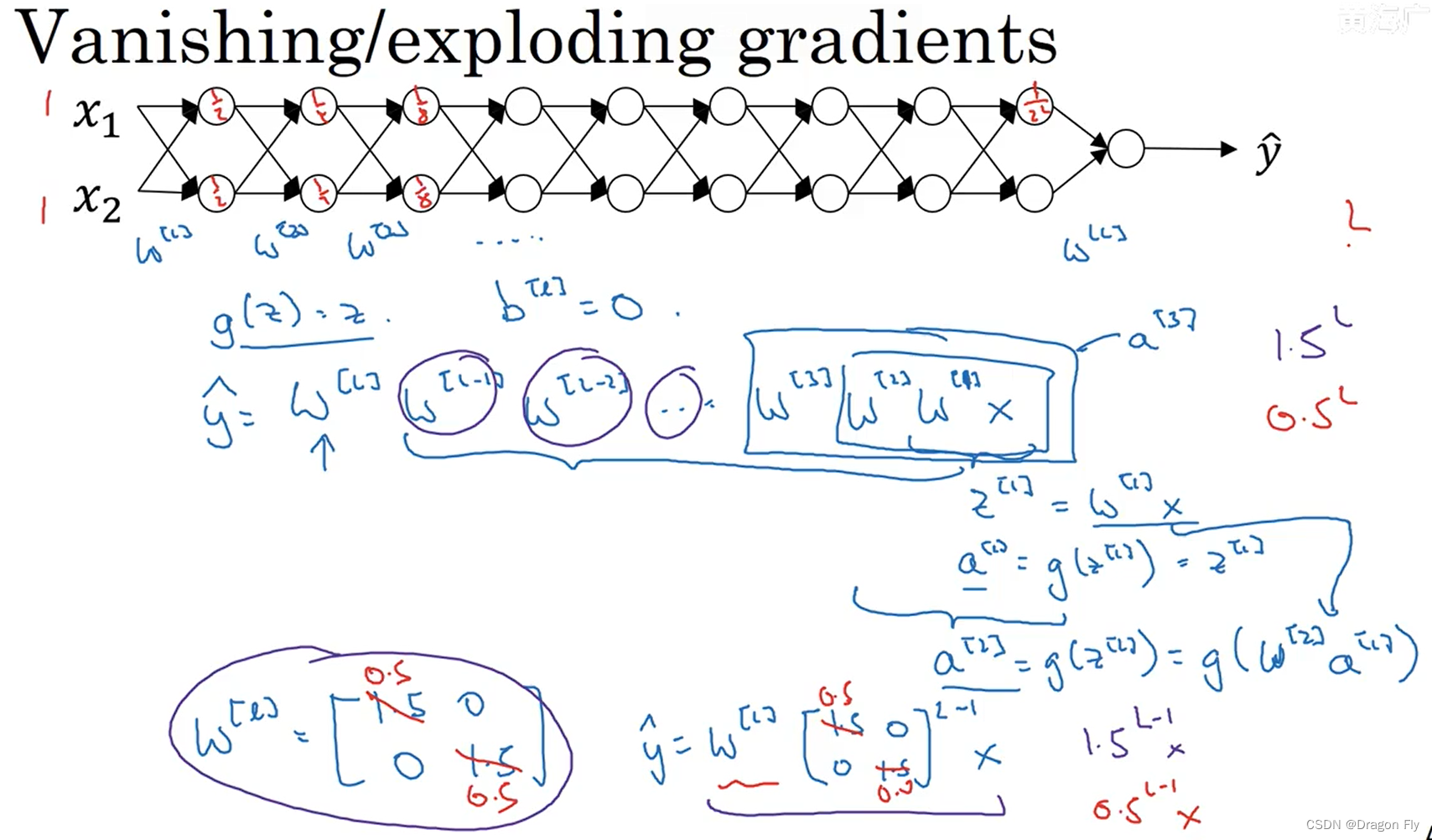
\qquad 梯度消失和梯度爆炸的问题可以通过carefully 初始化权重来得到缓解。若使用ReLU作为激活函数,通常将网络权重初始化为 2 n l − 1 \frac{2}{n^{l-1}} nl−12,当使用tanh作为激活函数时,通常使用 1 n l − 1 \sqrt{\frac{1}{n^{l-1}}} nl−11作为网络权重的初始值。
5.3 梯度检验
\qquad 在使用梯度检验时,双侧检验的精度相对于单侧检验的精度要更高。
\qquad 进行梯度检验的方法如下所示,通过计算近似数值梯度的值和反向传播计算的梯度值之间的“欧式距离”来观察梯度是否被正确进行了计算。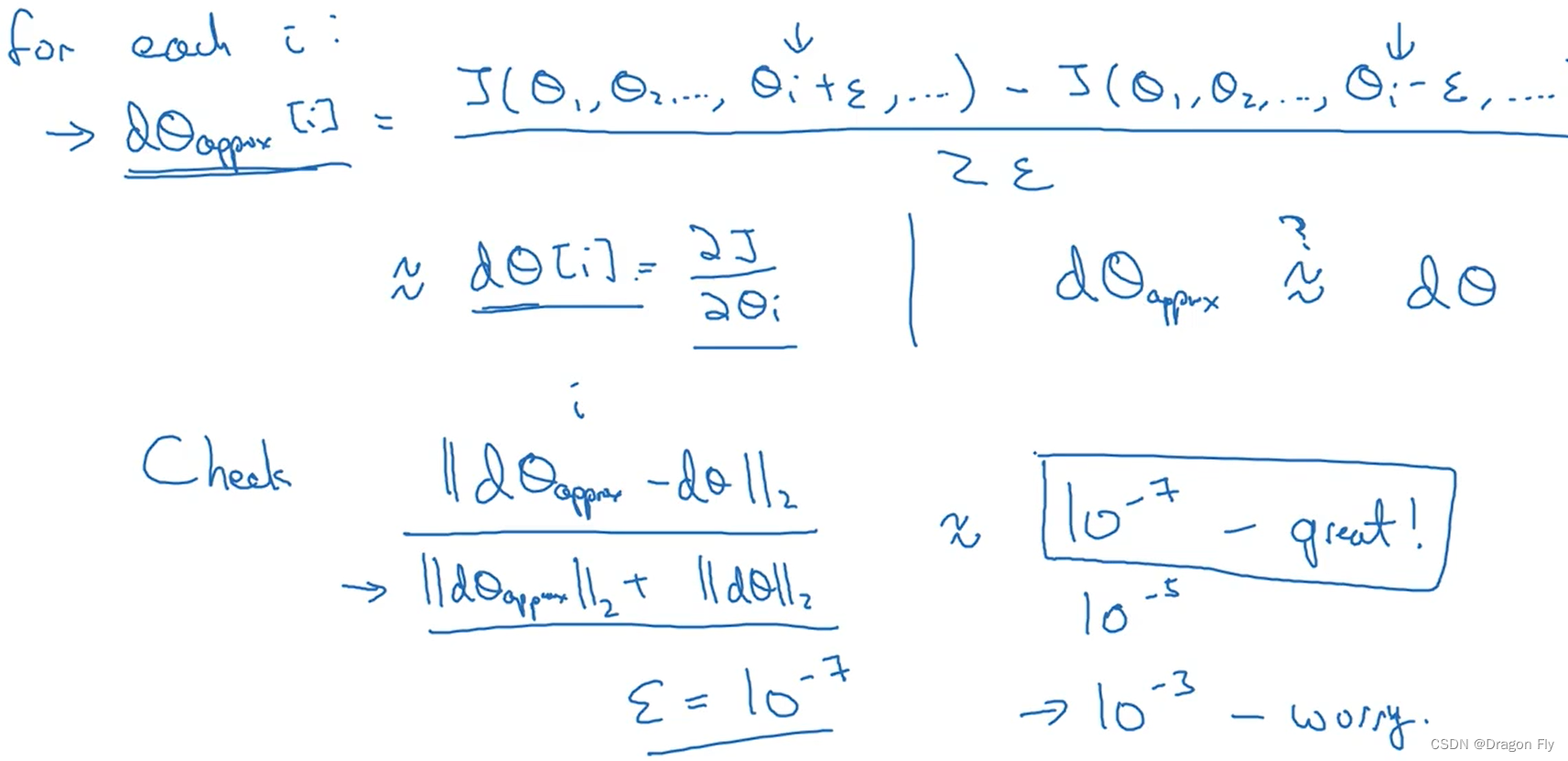
THE END
边栏推荐
- Unity Shader入门精要初级篇(一)-- 基础光照笔记
- Why is access to the external network prohibited for internal services of the company?
- Self awakening from a 30-year-old female programmer
- Upgrade Alibaba cloud RDS (relational database service) instance to com mysql. jdbc. exceptions. Troubleshooting of jdbc4.communicationsexception
- H3C VXLAN配置
- Some pit avoidance guidelines for using Huawei ECS
- [chaosblade: node CPU load, node network delay, node network packet loss, node domain name access exception]
- STM32 clock system
- 【ChaosBlade:节点 CPU 负载、节点网络延迟、节点网络丢包、节点域名访问异常】
- Leetcode question brushing record (array) combination sum, combination sum II
猜你喜欢
Entity of cesium data visualization (Part 1)

C language pointer (Part 1)
stm32和电机开发(从单机版到网络化)
Several stages of PMP preparation study
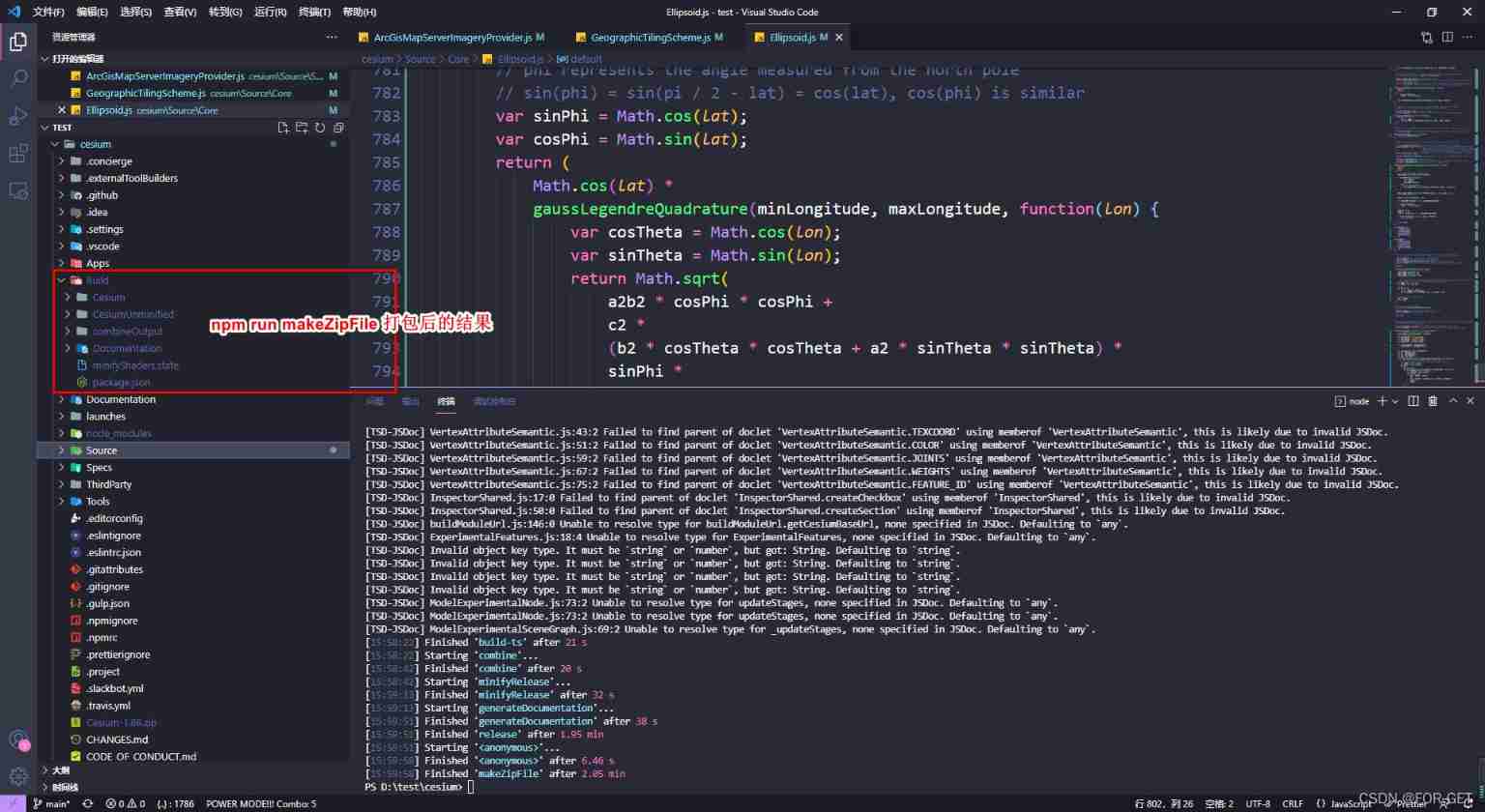
Cesium does not support 4490 problem solution and cesium modified source code packaging scheme

The essence of high availability
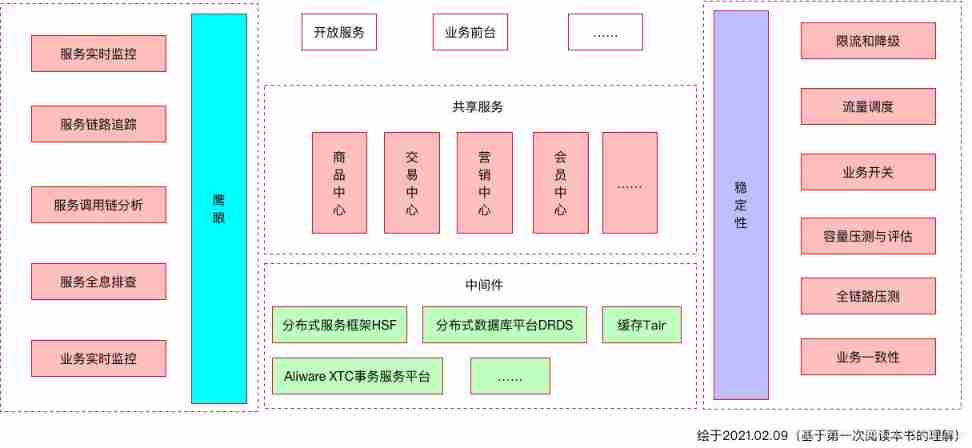
Reflections on the way of enterprise IT architecture transformation (Alibaba's China Taiwan strategic thought and architecture practice)
Jemter operation

面试题:高速PCB一般布局、布线原则
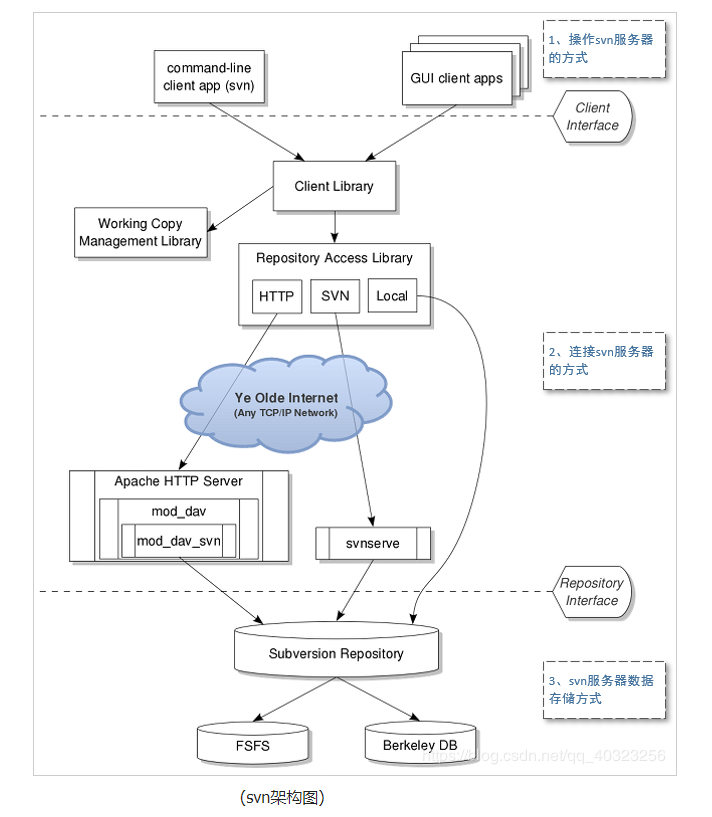
【SVN】SVN是什么?怎么使用?
随机推荐
C语言指针(习题篇)
[istio introduction, architecture, components]
【SVN】SVN是什么?怎么使用?
Interpretation of MySQL optimization principle
Mysql database lock learning notes
Unity Shader入门精要初级篇(一)-- 基础光照笔记
C语言指针(下篇)
PMP Exam Preparation experience, seek common ground while reserving differences, and successfully pass the exam
Jemter operation
How to pass the PMP Exam in a short time?
Common operating commands of Linux
正则匹配以XXX开头的,XXX结束的
硬核分享:硬件工程师常用工具包
【ChaosBlade:节点磁盘填充、杀节点上指定进程、挂起节点上指定进程】
The essence of high availability
JWT certification used in DRF
MySql数据库-索引-学习笔记
JVM garbage collection detailed learning notes (II)
NVIC interrupt priority management
[chaosblade: node disk filling, killing the specified process on the node, suspending the specified process on the node]