当前位置:网站首页>Hands on deep learning -- implementation of multi-layer perceptron from scratch and its concise implementation
Hands on deep learning -- implementation of multi-layer perceptron from scratch and its concise implementation
2022-06-12 08:14:00 【Orange acridine 21】
Multi layer perceptron is realized from scratch
# First, you need to import the required packages
import torch
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
"""
1、 get data
Use FashionMNIST Data sets , Use a multi-layer perceptron to start classifying images
"""
batch_size=256 # The batch size is set to 256, That is, every time you read 256 A picture
train_iter,test_iter =d2l.load_data_fashion_mnist(batch_size)
# Set up an iterator for training set and test set
"""
2、 Define model parameters
stay softmax Regression starts from zero , mention Fashion-MNIST The image shape in the dataset is 28x28, The number of categories is 10.
This section still uses a length of 28x28=784 The vector of represents each image .
"""
num_inputs,num_outputs,num_hiddens=784,10,256
# Enter the number 784, Number of outputs 10 individual , Number of hyperparameter hidden cells 256
W1=torch.tensor(np.random.normal(0,0.01,(num_inputs,num_hiddens)),dtype=torch.float)
# The weight W1 Initialize to a value of Gaussian random distribution , The mean for 0, The variance of 0.01, Input layer
b1=torch.zeros(num_hiddens,dtype=torch.float)
# deviation b1 Is the number of hidden layers , Define data types
W2=torch.tensor(np.random.normal(0,0.1,(num_hiddens,num_outputs)),dtype=torch.float)
# The weight W2 Initialize to a value of Gaussian random distribution , The mean for 0, The variance of 0.01, Output layer
b2=torch.zeros(num_outputs,dtype=torch.float)
# deviation b2 Is to grow into 10 A vector of , Define data types
# The following is the gradient of model parameters , Represents each weight w And deviation b You need to find the gradient
params=[W1,b1,W2,b2]
for param in params:
param.requires_grad_(requires_grad=True)
"""
3、 Define activation function
Use here ReLU Activation function , Use basic max Function implementation ReLU, Instead of calling directly
"""
def relu(X):
return torch.max(input=X,other=torch.tensor(0.0))
# Input to X
"""
4、 Defining models
Implement the calculation expression of multi-layer perceptron in the previous section
"""
def net(X):
X=X.view((-1,num_inputs))
# Use view Function to change the length of each original image to NUM_inputs Vector
H=relu(torch.matmul(X,W1)+b1) # Multiply first Enter times W1 On the plus b1
return torch.matmul(H,W2)+b2
# The output of the first layer is multiplied by the weight of the second layer, plus the deviation of the second layer
"""
5、 Define the loss function
"""
loss =torch.nn.CrossEntropyLoss()
"""
6、 Training models
The training process and softmax The training process for returning is the same
Let's go straight ⽤ d2lzh_pytorch In bag train_ch3 function ,
"""
num_epochs,lr=5,100.0 # Set the super parameter iteration period to 5, The learning rate is 100.0
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,batch_size,params,lr)

Simple implementation of multi-layer perceptron
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
#1、 Defining models
# and softmax Return to Wei ⼀ The difference is , We added more ⼀ A fully connected layer acts as a hidden layer
num_inputs, num_outputs, num_hiddens = 784, 10, 256
net = nn.Sequential(
d2l.FlattenLayer(),# Hidden layer
nn.Linear(num_inputs, num_hiddens), # Linear layer
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
for params in net.parameters():
init.normal_(params, mean=0, std=0.01)
#2、 Read the data and train the model
batch_size = 256 # Batch size 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
# Because of this ⾥ send ⽤ Yes. PyTorch Of SGD⽽ No d2lzh_pytorch⾥⾯ Of sgd, So there is no such thing as the learning rate looks very ⼤ The problem.
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,batch_size, None, None, optimizer)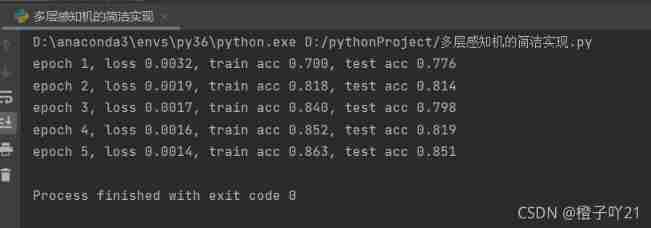
边栏推荐
- FPGA to flip video up and down (SRAM is61wv102416bll)
- You get download the installation and use of artifact
- (P17-P18)通过using定义基础类型和函数指针别名,使用using和typedef给模板定义别名
- StrVec类 移动拷贝
- APS软件有哪些排程规则?有何异常处理方案?
- How SQLite limits the total number of data in a table
- OpenMP task 原理与实例
- (P14)overrid关键字的使用
- vm虛擬機中使用NAT模式特別說明
- call方法和apply方法
猜你喜欢

Derivation of Poisson distribution

Clarify the division of IPv4 addresses

vm虚拟机中使用NAT模式特别说明
Servlet advanced

如何理解APS系统的生产排程?

Hands on learning and deep learning -- Realization of linear regression from scratch

Vision Transformer | CVPR 2022 - Vision Transformer with Deformable Attention

(P19-P20)委托构造函数(代理构造函数)和继承构造函数(使用using)

Installation series of ROS system (I): installation steps

(p25-p26) three details of non range based for loop and range based for loop
随机推荐
千万别把MES只当做工具,不然会错过最重要的东西
FPGA generates 720p video clock
Vins technical route and code explanation
Model Trick | CVPR 2022 Oral - Stochastic Backpropagation A Memory Efficient Strategy
In depth interpretation of 5g key technologies
Face recognition using BP neural network of NNET in R language
Model Trick | CVPR 2022 Oral - Stochastic Backpropagation A Memory Efficient Strategy
MYSQL中的调用存储过程,变量的定义,
Bean的作用域
Summary of 3D point cloud construction plane method
Vision Transformer | CVPR 2022 - Vision Transformer with Deformable Attention
(P17-P18)通过using定义基础类型和函数指针别名,使用using和typedef给模板定义别名
vscode 下载慢解决办法
Literature reading: deep neural networks for YouTube recommendations
MES系统是什么?MES系统的操作流程是怎样?
企业上线MES软件的费用真的很贵?
Leetcode notes: Weekly contest 279
GTEST/GMOCK介绍与实战
uni-app用canvas截屏并且分享好友
Learning notes (1): live broadcast by Dr. Lu Qi - face up to challenges and grasp entrepreneurial innovation opportunities - face up to challenges and grasp entrepreneurial innovation opportunities -1