当前位置:网站首页>Flink parsing (IV): recovery mechanism
Flink parsing (IV): recovery mechanism
2022-07-06 17:28:00 【Stray_ Lambs】
Catalog
Checkpoint What information to save
Checkpoint How to save information
Precision one time (exactly once)
Job After failure , Recover from checkpoint
Apply automatic recovery mechanism
Job After failure , Restore mechanism from savepoint
Flink Recovery mechanism
There is a possibility of error in any framework , Therefore, they will have their own set of recovery mechanisms , for example Spark It is to start from scratch by blood relationship , If there is checkpoint From checkpoint Start execution .Flink Mainly according to each operator And a snapshot of the whole world to restore an error .
The premise is that Flink Of checkpoint The mechanism interacts with persistent storage , Read / write stream and state .
So you need :
- A persistent data source that can playback data over a period of time , For example, persistent message queues ( for example Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub etc. ) Or file system ( for example HDFS、 S3、 GFS、 NFS、 Ceph etc. ).
- Persistent storage of storage state , Usually distributed file system ( such as HDFS、 S3、 GFS、 NFS、 Ceph etc. ).
Checkpoint What is it?
To understand Flink The recovery mechanism , First we need to understand , What is? Checkpoint.Checkpoint yes Flink Check point of , It is based on... Periodically according to the configuration file Stream In each Operator Of state And the Overall SnapShot snapshot . Then it is stored in some peripherals persistently on a regular basis , once Flink The program crashes , You can select these SnapShot Snapshot for rapid recovery , So as to correct the program data interruption caused by the fault . among ,Flink Of CheckPoint The mechanism principle mainly comes from “Chandy-Lamport algorithm”.
Here is a brief introduction to this algorithm , First of all, the goal of this algorithm is to Ensure that the generated snapshots must be consistent , And not stop the world, That is, it cannot affect the normal execution of the program . There are three stages , Initialize snapshot 、 Diffusion snapshot and completion snapshot . You need to look at other documents for specific details , I won't go into details here .
By the way, here is a concept , Namely State And Checkpoint The relationship between .
State Generally refers to a specific Task/Operator The state of (operator The state of represents some intermediate results that some operators will produce in the process of running ). and State By default, the data of is stored in Java Heap memory for /TaskManage In node memory , also State Can be recorded , It can be used to recover data in case of failure . It feels like a local state .
Checkpoint It's a little similar to the overall state . It means a FlinkJob A global snapshot at a particular moment , Save all Task/Operator The state of . It can be understood as all the time State Persistent storage to peripherals .
Savepoint Save it
Savepoint Is based on Flink Application of checkpoint mechanism full snapshot backup mechanism . It is mainly used to save the state of a cluster at a certain time , Make the cluster recover from the saved state . Generally, it is used for application upgrading 、 Cluster migration 、Flink Version update 、A/B Testing, etc. . A savepoint can be understood as a Map( operator ID -> State), The operator is a stateful operator .
Because oneortwo sentences are difficult to explain sp And cp The difference between , I'll go directly to the link ……
Checkpoint Coordinator
Flink in CheckpointCoordinator, Mainly responsible for coordination Flink Operator's State Distributed snapshot of . When triggered to form a snapshot ,CheckpointCoordinator To the input Source Operator injection Barrier news , That is, the fence , Distinguish the data of two batches . Then when all Task After the checkpoints in the task are confirmed , be-all Task Will report State Handle .
Checkpoint
Checkpoint What information to save
Checkpoint In fact, it is mainly Save the first i Times have been consumed offset Information , And each Task The corresponding key value pair information in , That is, some connectors (connectors)、 Window and any user-defined state . A record of the occurrence of Checkpoint Current state , And stored in the opposite state backend ( What exactly is the state backend , Put a flag, Write it in detail later …).
Checkpoint How to save information
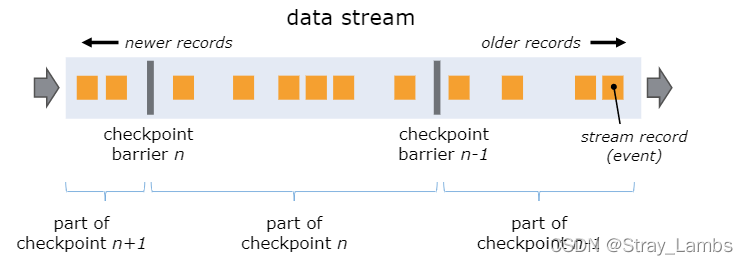
Flink Asynchronous barrier Snapshot mode to generate snapshot information . When JobManager Medium Checkpoint coordinator Give Way taskManager To begin checkpoint When , It will make all the source End record their offset , And an incrementally numbered checkpoint barriers Insert into source In the stream . these barriers The fence is mainly to distinguish each checkpoint Forward and backward flow , And each barrier Will carry a snapshot of its own ID Number . such as ,Checkpoint n Will contain each operator Of state, And the corresponding opertor operator It must mean consumption checkpoint barrier n All previous events , And does not contain n The state of any subsequent event .
When Barrier After being injected into the parallel data stream from the data stream source ,Barrier It will be transmitted downstream , After encountering non data source operators , Snapshots are received in all input streams n Of Barrier when , The operator will be on its own State Snapshot save , And to their downstream Broadcast transmission snapshot n Of Barrier. until Sink The operator receives Barrier after , There will be two situations .
(1) If It is a strict one-time processing guarantee in the engine , When Sink Operator has received all upstream Barrie n when , Sink Operators on their own State Take a snapshot , Then notify the checkpoint coordinator ( CheckpointCoordinator) . When all operators report success to the checkpoint coordinator , The checkpoint coordinator confirms the completion of this snapshot to all operators .
(2) In case of end-to-end strict one-time processing guarantee , When Sink Operator has received all upstream Barrie n when , Sink Operators on their own State Take a snapshot , And pre commit transactions ( The first phase of a two-phase submission ), Then notify the checkpoint coordinator ( CheckpointCoordinator) , The checkpoint coordinator confirms the completion of this snapshot to all operators ,Sink operator Commit transaction ( The second phase of a two-phase submission ), This transaction is completed .
When job graph Each of the operator All received barriers When the data is , It will record its current state . If an operator has two or more input streams ( for example CoProcessFunction) Will execute barrier alignment , In order to determine that the current snapshot can contain the consumption input stream check barrier n Before ( But not more than ) The state resulting from all events .
Barrier alignment
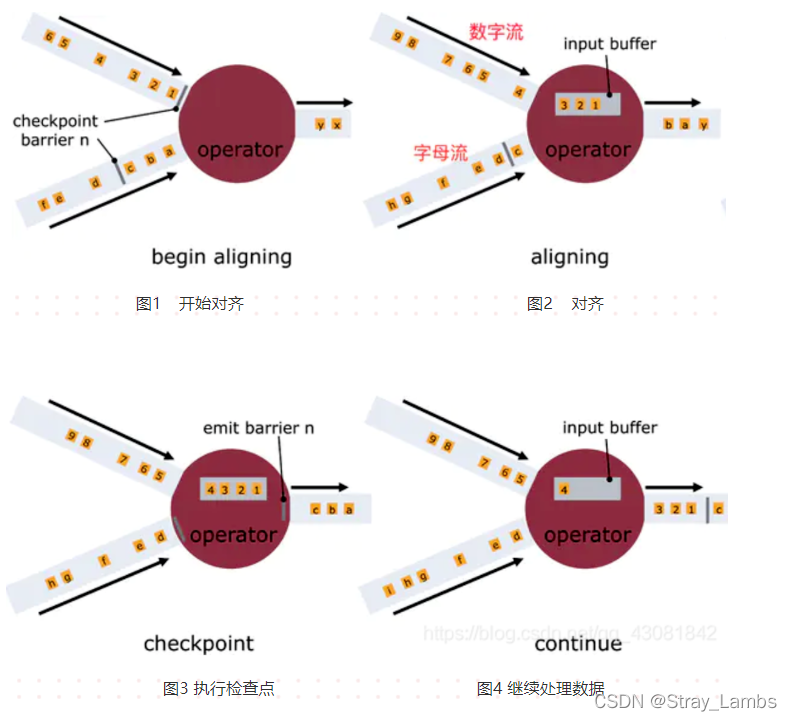
once Operator Received... From input stream CheckPoint barrier n, It cannot process any data records from the stream , Until it receives... From all other inputs barrier n until . otherwise , It will be mixed to belong to the snapshot n Records and belong to snapshots n + 1 The record of ;
As shown in the figure above :
chart 1, The operator receives the Barrier, The letter stream corresponds to barrier It hasn't arrived yet
chart 2, The operator receives the Barrier, Will continue to receive data from the digital stream , But these flows can only be shelved , Records cannot be processed , Instead, put it in the cache , Wait for the letter stream Barrier arrive . Before the letter stream arrives , 1,2,3 The data has been cached .
chart 3, The letter stream arrives , The operator begins to align State Take asynchronous snapshots , And will Barrier Broadcast downstream , Do not wait for the snapshot to complete .
chart 4, Operators take asynchronous snapshots , First, deal with the backlog data in the cache , Then get the data from the input channel .
So when do I need Barrier alignment , When not needed .
barrier Not aligned : It means when there are other streams barrier Before they arrive , In order not to affect performance , Don't pay attention to , Deal directly with barrier Later data . Wait until all the streams barrier When all arrive , Then you can do it Operator do CheckPoint 了 ;
As mentioned above ,barrier Misalignment will lead to repeated consumption , Because there is no need to wait for backward data , This may lead to repeated consumption of some data . if necessary Exactly once Scene , Then it has to be barrier alignment , If possible at least once You don't need barrier alignment .
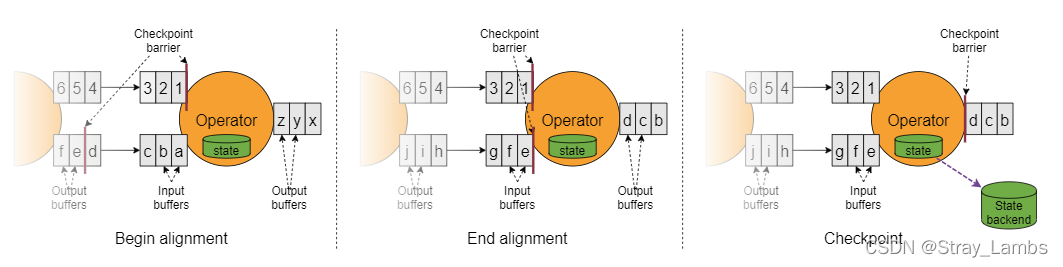
Flink in The state backend adopts write time replication (copy-on-write) The mechanism allows when a state snapshot of an older version is generated asynchronously , Ability to continue stream processing unaffected . Only after the snapshot is persisted , The status of the old version will be garbage collected .
Precision one time (exactly once)
When an error occurs in the stream processing application , The result may be loss or duplication .Flink Configure your application according to , The following results can be produced :
- Flink No recovery from snapshot (at most once)
- Nothing is missing , But you may get redundant results (at least once)
- No loss or redundancy (exactly once)
Flink By fallback and resend source Data flow recovers from failure , When the ideal situation is described as Exactly once when , This also No It means that every event will be handled exactly once . contrary , It means Every event affects Flink The state of management is accurate once .
Barrier Alignment is only required when it is necessary to provide accurate semantic guarantee once (Barrier alignment). If you don't need this semantics , Can be configured by CheckpointingMode.AT_LEAST_ONCE close Barrier Alignment to improve performance .
End to end precision once
In order to achieve end-to-end accuracy, one time , In order to sources Each event in is accurate only once sinks take effect , The following conditions must be met :
- Yours sources Must be reproducible
- Yours sinks Must be transactional ( Or idempotent )
Job After failure , Recover from checkpoint
Flink Provides Apply automatic recovery mechanism as well as Manual job recovery mechanism .
Apply automatic recovery mechanism
Flink Set the restart policy for job failure , There are three
- Periodic recovery strategy :fixed-delay. The fixed delay restart policy will try to restart a given number of times Job, If the maximum number of restarts is exceeded ,Job It will eventually fail , Between two consecutive restart attempts , The restart strategy will wait for a fixed time , Default Integer.MAX_VALUE Time
- Failure ratio strategy :failure-rate. Failure rate restart strategy in job Restart after failure , But beyond the failure rate ,Job Will eventually be judged as a failure , Between two consecutive restart attempts , The restart policy will wait for a fixed time .
- Direct failure strategy :None Failure does not restart .
Manual job recovery mechanism
because Flink The checkpoint directories correspond to JobId, Every time I pass flink run The way / When the page submission method is restored, it will be regenerated jobId,Flink Provides a way to start up by setting -s . Parameter specifies the function of the checkpoint directory , Let the new jobld Read the checkpoint meta file information and status information , So as to achieve the purpose of starting the job at the specified time node .
Job After failure , Restore mechanism from savepoint
Restoring jobs from savepoints is not easy , Especially when the operation changes ( Such as modifying logic 、 Repair bug) Under the circumstances , The following points need to be considered :
(1) The order of operators changes
If the corresponding UID It hasn't changed , You can restore , If the corresponding UID The recovery failed .
(2) A new operator has been added to the job
If it's a stateless operator , No impact , Can recover normally , If it's a stateful operator , With stateless operators Handle it the same way .
(3) Removed a stateful operator from the job
By default, you need to restore the state of all operators recorded in the savepoint , If you delete a stateful operator , Deleted when replying from savepoint OperatorID Can't find , So there's an error You can add... To the command
-- allowNonReStoredSlale (short: -n ) Skip unrecoverable operators .
(4) Add and delete stateless operators
If you set it manually UID You can restore , Stateless operators are not recorded in the savepoint If it is automatically assigned UID , Then the state operator may change ( Flink A monotonically increasing counter is generated UID,DAG Revision , The counter is likely to change ) It is likely that the recovery will fail .
Reference resources
边栏推荐
猜你喜欢
04个人研发的产品及推广-数据推送工具
Flink 解析(三):内存管理
Instructions for Redux
JVM class loading subsystem
02 personal developed products and promotion - SMS platform
应用服务配置器(定时,数据库备份,文件备份,异地备份)
CTF reverse entry question - dice

Wu Jun's trilogy insight (V) refusing fake workers
Set up the flutter environment pit collection
C# WinForm系列-Button简单使用
随机推荐
vscode
connection reset by peer
Flink 解析(七):时间窗口
Wu Jun's trilogy insight (V) refusing fake workers
Compile homework after class
MySQL advanced (index, view, stored procedure, function, password modification)
PySpark算子处理空间数据全解析(4): 先说说空间运算
Flink 解析(三):内存管理
06个人研发的产品及推广-代码统计工具
JVM 垃圾回收器之Garbage First
[mmdetection] solves the installation problem
Application service configurator (regular, database backup, file backup, remote backup)
Koa Middleware
Assembly language addressing mode
04个人研发的产品及推广-数据推送工具
Some feelings of brushing leetcode 300+ questions
MySQL date function
复盘网鼎杯Re-Signal Writeup
Flink parsing (VI): savepoints
[reverse] repair IAT and close ASLR after shelling