当前位置:网站首页>漫谈Map Reduce 参数优化
漫谈Map Reduce 参数优化
2022-08-03 05:22:00 【大数据队长】
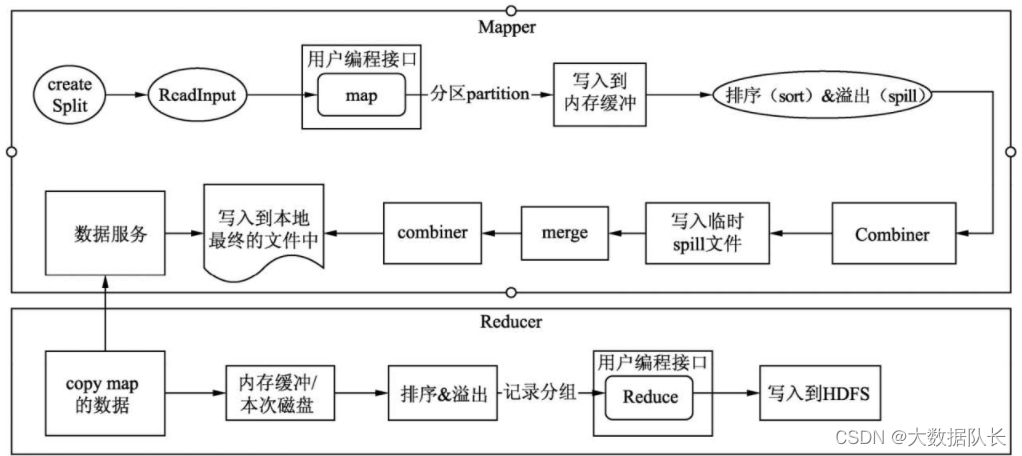
优化点:
1.map个数设置:
默认map个数
default_num=total_size/block_size;
期望大小
goal_num=mapred.map.tasks;
设置处理的文件大小
split_size=max(mapred.min.split.size,block_size);
split_num=total_size/split_size;
计算的map个数
compute_map_num=min(split_num,max(default_num,goal_num))
1)如果想增加map个数,则设置mapred.map.tasks为一个较大的值。
2)如果想减小map个数,则设置mapred.min.split.size为一个较大的值。有如下两种情况:
情况1:输入文件size巨大,但不是小文件增大mapred.min.split.size的值。
情况2:输入文件数量巨大,且都是小文件,就是单个文件的size小于blockSize。这种情况通过增大mapred.min.spllt.size不可行,需要使用CombineFileInputFormat将多个input path合并成一个(合并小文件输入)InputSplit送给mapper处理,从而减少mapper的数量。
set mapred.max.split.size=256000000; -- 决定每个map处理的最大的文件大小,单位为B
set mapred.min.split.size.per.node=128000000; -- 节点中可以处理的最小的文件大小
set mapred.min.split.size.per.rack=128000000; -- 机架中可以处理的最小的文件大小
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;2.mapper 向量化模式
在关系型数据库里可以采用批量的操作方式避免单行处理数据导致系统处理性能的降低,Hive也提供了类似的功能使用向量的模式,将一次处理一条数据变为一次处理1万条数据,来提高程序的性能。开启向量模式的方法如下:
set hive.vectorized.execution.enabled = true目前MapReduce计算引擎只支持Map端的向量化执行模式,Tez和Spark计算引擎可以支持Map和Reduce端的向量化执行模式
3.开启map join
hive.auto.convert.join:是否开启MapJoin自动优化,hive 0.11版本以前默认关闭
hive.smalltable.filesize or hive.mapjoin.smalltable.filesize:默认值2500000(25MB)如果大小表在进行表连接时的小表数据量小于这个默认值,则自动开启MapJoin优化。在Hive 0.8.1以前使用hive.smalltable.filesize,之后的版本使用hive.mapjoin.smalltable.filesize参数。Hive 0.11版本及以后的版本,可以使用hive.auto.convert.join.noconditionaltask.size和hive.auto.convert.join.noconditionaltask两个配置参数。hive.auto.convert.join.noconditionaltask.size的默认值为1000000(100MB)。hive.auto.convert.join.noconditionaltask的默认值是true,表示Hive会把输入文件的大小小于hive.auto.convert.join.noconditionaltask.size指定值的普通表连接操作自动转化为MapJoin的形式
4.hive.map.aggr:是否开启Map任务的聚合,combiner,默认值是true
hive.map.aggr.hash.percentmemory:默认值是0.5,表示开启Map任务的聚合,聚合所用的哈希表,所能占用到整个Map被分配的内存50%。例如,Map任务被分配2GB内存,那么哈希表最多只能用1GB
5.hive.vectorized.execution.mapjoin.native.enabled:是否使用原生的向量化执行模式执行MapJoin,它会比普通MapJoin速度快。默认值为False
6.reduce 个数设置
方法1.调整hive.exec.reducers.bytes.per.reducer和hive.exec.reducers.maxhive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1G)hive.exec.reducers.max(每个任务最大的reduce数,默认为999)计算reducer数的公式:
reduce_number=min(hive.exec.reducers.maxinput_size/hive.exec.reducers.bytes.per.reducer,hive.exec.reducers.max)
推荐使用本方法控制reduce数量,因为数据量往往会变化,如果采用固定的reduce数量可能导致资源浪费或者oom等问题。在设置reduce个数的时候需要考虑这两个原则:使大数据量利用合适的reduce数;使单个reduce任务处理合适的数据量;
方法2:
调整mapreduce.job.reduces该参数会直接生效,hive不再根据数据量估算reduce数量。
set mapred.reduce.tasks = 30;
reduce个数并不是越多越好;启动和初始化reduce也会消耗时间和资源;另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题
7. hive.multigroupby.singlereducer:表示如果一个SQL 语句中有多个分组聚合操作,且分组是使用相同的字段,那么这些分组聚合操作可以用一个作业的Reduce完成,而不是分解成多个作业、多个Reduce完成。这可以减少作业重复读取和Shuffle的操作
8.hive.mapred.reduce.tasks.speculative.execution:表示是否开启Reduce任务的推测执行。即系统在一个Reduce 任务中执行进度远低于其他任务的执行进度,会尝试在另外的机器上启动一个相同的Reduce任务
9. hive.optimize.reducededuplication:表示当数据需要按相同的键再次聚合时,则开启这个配置,可以减少重复的聚合操
10. hive.vectorized.execution.reduce.enabled:表示是否启用Reduce任务的向量化执行模式,默认是true。MapReduce计算引擎并不支持对Reduce阶段的向量化处理。
11.设置hive.merge.smallfiles.avgsize参数,默认16MB,当输出的文件小于该值时,启用一个MapReduce任务合并小文件;
设置hive.merge.size.per.task参数,默认256MB,是每个任务合并后文件的大小。一般设置为和HDFS集群的文件块大小一致。
12.hive.optimize.countdistinct:默认值为true, Hive 3.0新增的配置项。当开启该配置项时,去重并计数的作业会分成两个作业来处理这类SQL,以达到减缓SQL的数据倾斜作用。
13.hive.exec.parallel:默认值是False,是否开启作业的并行。默认情况下,如果一个SQL被拆分成两个阶段,如stage1、stage2,假设这两个stage没有直接的依赖关系,还是会采用窜行的方式依次执行两个阶段。如果开启该配置,则会同时执行两个阶段。在资源较为充足的情况下开启该配置可以有效节省作业的运行时间。
边栏推荐
猜你喜欢
Ansible installation and deployment detailed process, basic operation of configuration inventory
Leetcode刷题——128. 最长连续序列
![7.24[C语言零基础 知识点总结]](/img/b8/3abcee495e70c9ffffc671f2b7d9b1.png)
7.24[C语言零基础 知识点总结]

运行 npm run xxx 如何触发构建命令以及启动Node服务等功能?
Django从入门到放弃三 -- cookie,session,cbv加装饰器,ajax,django中间件,redis缓存等

【 Nmap and Metasploit common commands 】

pta a.1003 的收获
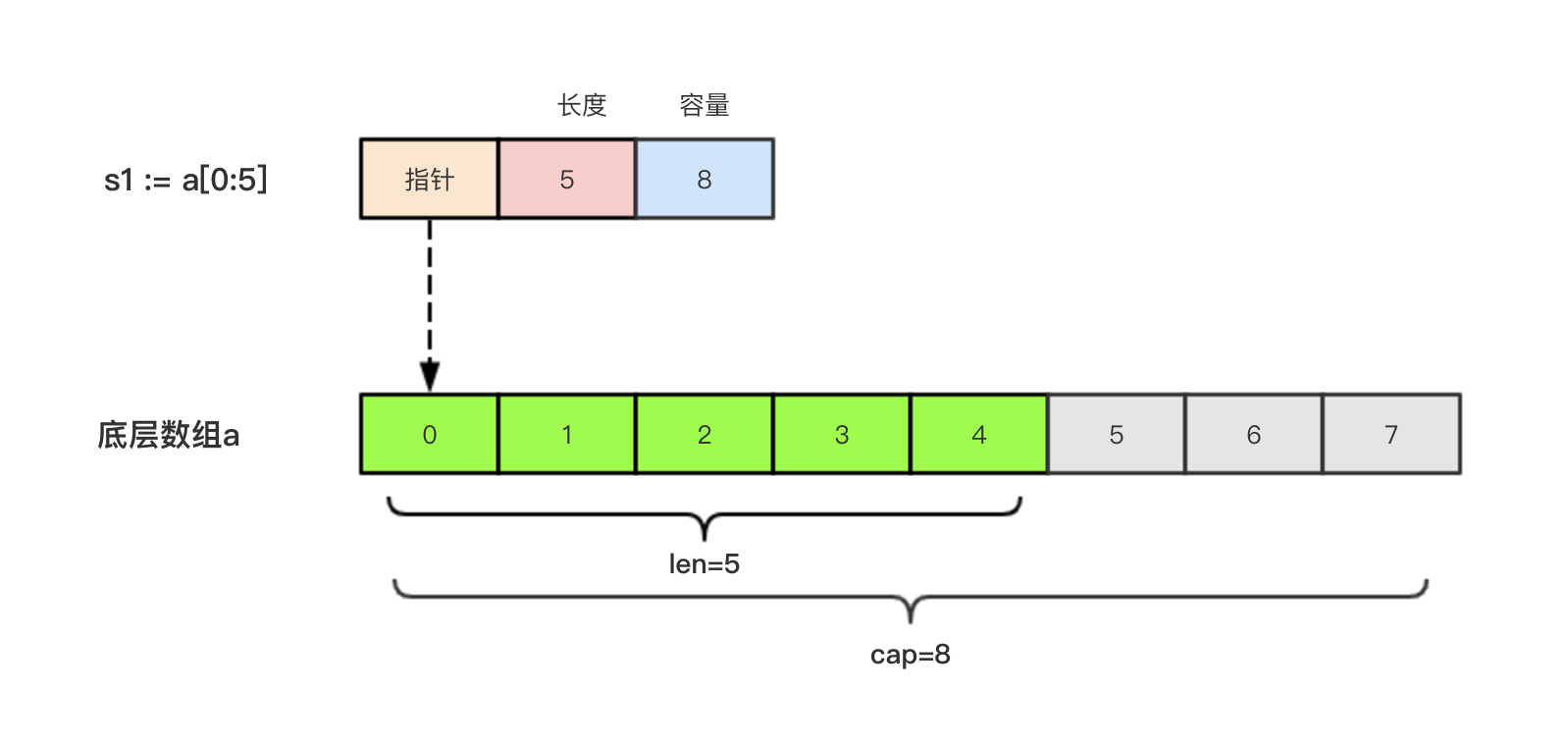
Go (一) 基础部分3 -- 数组,切片(append,copy),map,指针
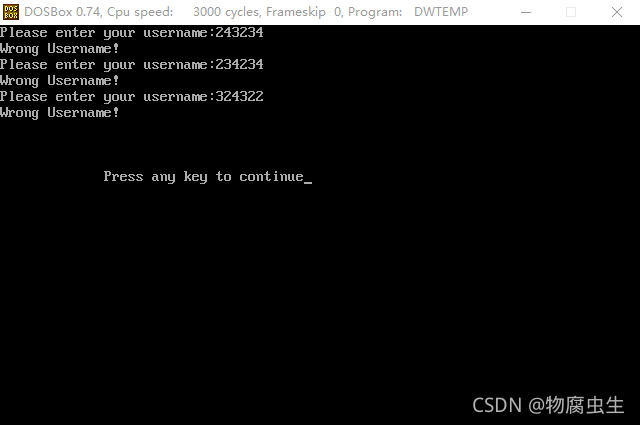
用户登录验证程序的实现
jsp通过form表单提交数据到servlet报404
随机推荐
NFT租赁提案EIP-5006步入最后审核!让海外大型游戏的链改成为可能
7.8(6)
用C语言来实现五子棋小游戏
中国磷化铟晶圆行业发展前景与投资规划分析报告2022~2028年
中国生活垃圾处理行业十四五规划与投融资模式分析报告2022~2028年
controller层到底能不能用@Transactional注解?
Navicat 解决隔一段时间不操作出现延时卡顿问题
7.24[C语言零基础 知识点总结]
7.15(6)
处理异步事件的三种方式
小码农的第一篇博客
嵌入式-I2C-物理电路图
阿凡提的难题
【DC-4 Range Penetration】
D-PHY
7.7(5)
Greetings(状压DP,枚举子集转移)
MySQL EXPLAIN 性能分析工具详解
动态调整web系统主题? 看这一篇就够了
中国水产养殖行业市场投资分析及未来风险预测报告2022~2028年