当前位置:网站首页>45 lectures on MySQL [index]
45 lectures on MySQL [index]
2022-07-03 03:00:00 【Little fish 2020】
List of articles
04 | Index in simple terms ( On )
Index is to improve the efficiency of data query , It's like a book catalog .
The ways to implement the index are Hashtable 、 Ordered arrays and search trees
Hashtable
Hash table is a kind of key - value (key-value) Structure of stored data , We just input the value to be searched key, You can find the corresponding value, that is Value. The idea of hash is very simple , Put values in an array , Use a hash function to put key Convert to a certain location , And then put value In this position of the array .
inevitably , Multiple key Value is converted by hash function , There will be the same value . One way to deal with this is to , Pull out a list .

User2 and User4 The value calculated according to the ID number is N, But never mind. , Followed by a chain
surface . hypothesis , At this time, you need to check ID_card_n2 What is the corresponding name , The processing steps are : First , take
ID_card_n2 It is calculated by hash function N; then , Traverse in order , find User2.
If you want to find the ID number now, [ID_card_X, ID_card_Y] All uses of this interval
Household , You have to scan it all . therefore , This structure of hash table is applicable to the scenario with only equivalent query
Ordered array 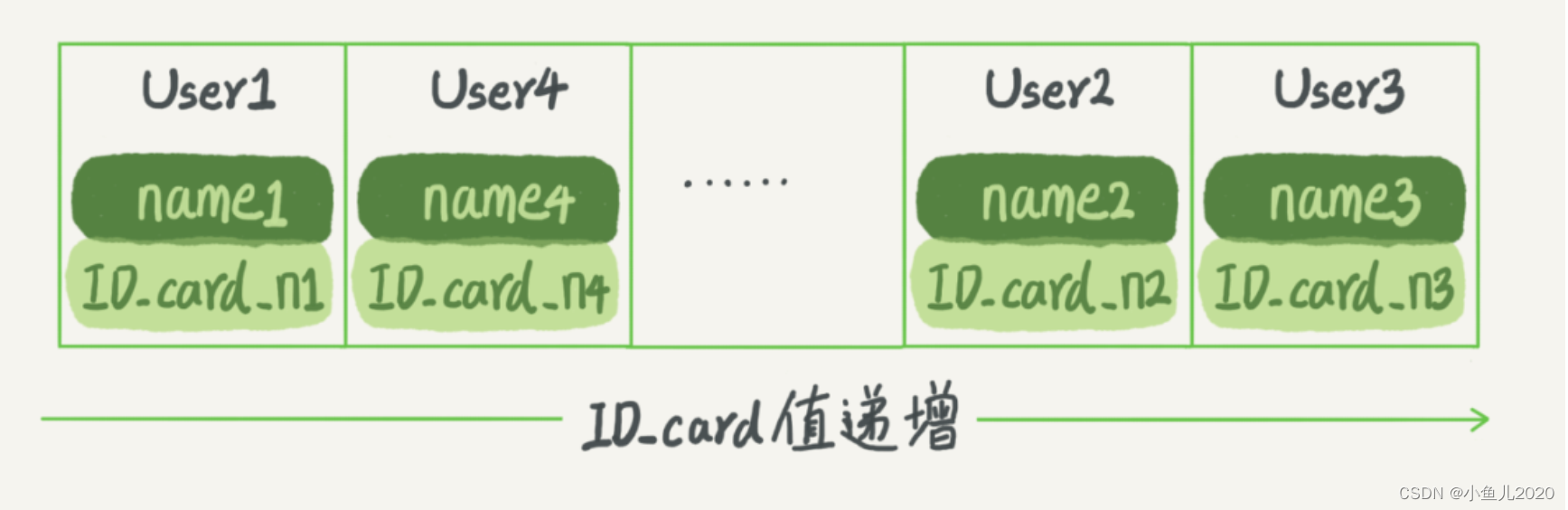
Here we assume that the ID number is not repeated. , This array is kept in the order of increasing the ID number . Now , If you want to check ID_card_n2 The corresponding name , With dichotomy, you can get , This time complexity is O(log(N))
This index structure supports range queries . You need to check the ID number. [ID_card_X, ID_card_Y] District
Between the User, You can find it by dichotomy ID_card_X( If it doesn't exist ID_card_X, We find that it is greater than
ID_card_X One of the first User), And then go right , Until we find the first one greater than ID_card_Y Identity card number , Exit loop .
however , When you need to update the data, it's troublesome , If you insert a record in the middle, you have to move all the records behind you , The cost is too high , therefore , Ordered array indexes are only available for static storage engines
Binary search tree 
The characteristics of binary search tree are : The left son of each node is smaller than the parent node , The parent node is smaller than the right son . So if you want to check ID_card_n2 Words , According to the search sequence in the figure is according to UserA -> UserC -> UserF ->User2 This path leads to . This time complexity is O(log(N)).
Trees can have two forks , It can also have many forks . A multi tree means that each node has multiple sons , The size between sons is guaranteed to increase from left to right . Binary tree is the most efficient , But in fact, most database storage does not use binary tree . The reason is , Indexes don't just exist in memory , And write it to disk .
To make a query read as little disk as possible , The query process must access as few data blocks as possible . that , We shouldn't use binary trees , But to use “N fork ” Trees . here ,“N fork ” In the tree “N” Depending on the data block
Size
With InnoDB An integer field index for example , This N Is almost 1200. The height of this tree is 4 When , You can save 1200 Of 3 The value of the power , This has been 17 The hundred million . Considering that the data block of the tree root is always in memory , One 10 Index of an integer field on a 100 million row table , To find a value, you only need to access at most 3 Secondary disk . Actually , The second layer of the tree also has a high probability of being in memory , So the average number of disk accesses is less .
N Due to the performance advantages of the fork tree in reading and writing , And the access mode of the adapter disk , It has been widely used in database engine .
InnoDB The index model of
stay InnoDB in , Tables are stored in the form of indexes according to the primary key order , The tables in this way of storage are called index organization tables . Because of what we mentioned earlier ,InnoDB Used B+ Tree index model , So the data is stored in B+ In the tree .
Every index is in InnoDB It corresponds to a B+ Trees .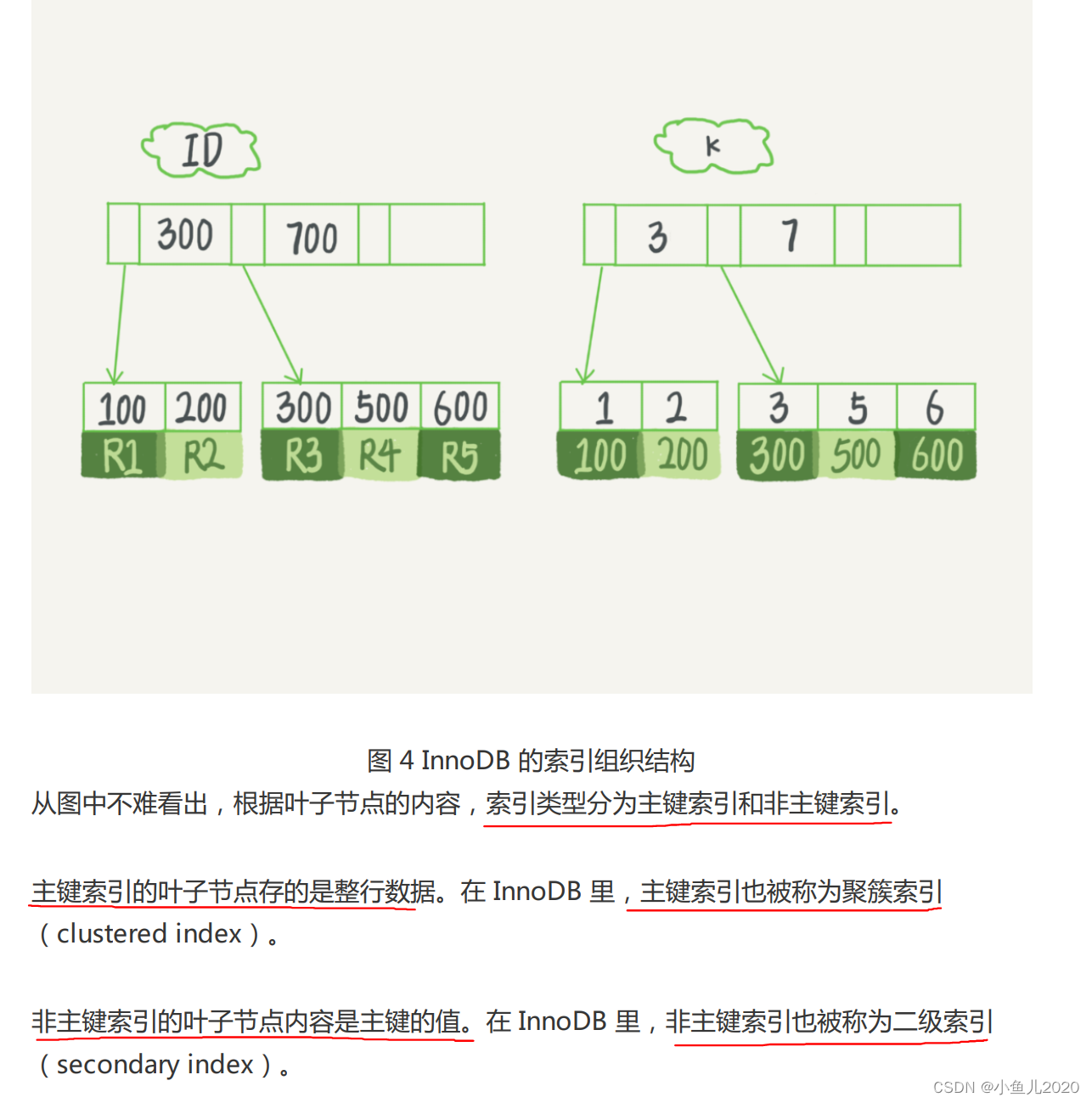

Query based on non primary key index needs to scan an index tree . therefore , We should try our best to
Use the primary key to query
ID number as primary key , Or use auto increment fields as primary keys ?
Because each leaf node of a non primary key index has a primary key value . If the ID card number is used as the primary key , Then the leaf nodes of each secondary index occupy about 20 Bytes , And if you use an integer as the primary key , Then as long as 4 Bytes , If it's a long form (bigint) It is 8 Bytes
obviously , The smaller the primary key length , The smaller the leaf node of a normal index is , The less space a normal index takes
Try to use primary key query ” principle , Set this index as the primary key directly , You can avoid having to search two trees at a time ,
05 | Index in simple terms ( Next )
create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT ''
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff')
If I execute select * from T where k between 3 and 5, You need to perform several tree searches , How many lines will be scanned ?
Because the data needed for query results is only on the primary key index , So I have to go back to my watch
Overlay index
If the executed statement is select ID from T where k between 3 and 5, At this time, we just need to check ID Of
value , and ID The value of is already in k On the index tree , So you can directly provide query results , There is no need to return the form . That is to say
say , In this query , Indexes k already “ covers ” Our query needs , We call it coverage index .
Tree searches can be reduced by overwriting the index , Significantly improve query performance , So using overlay index is a common
Performance optimization means of .
It should be noted that , Use the overlay index inside the engine to index k I actually read three records ,R3~R5( Corresponding
Indexes k Record item on ), But for MySQL Of Server Layer , It just found the engine and got two records
record , therefore MySQL Think the number of scan lines is 2
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB
If there is a high frequency request now , He should check his name according to the ID number of the citizen. , This joint index makes sense
了 . It can use overlay index on this high frequency request , There is no need to go back to the table to look up the whole record , Reduce the execution of statements
Time
Leftmost prefix principle
B+ Tree is an index structure , Available with index “ Left most prefix ”, To locate records .

Index push down
MySQL 5.6 Index push down optimization introduced (index condition pushdown), Can be traversed in the index
Cheng Zhong , Judge the fields included in the index first , Filter out unqualified records directly , Reduce the number of times to return to the table .
Index differentiation
Before talking about the above problems , Let's first look at another concept , It's discrimination .
Degree of differentiation : Refers to the non repetition ratio of fields in the database
Discrimination has a very important reference value when creating an index , stay MySQL in , The calculation rules of discrimination are as follows :
Quotient between the total number of fields after de duplication and the total number of records in the whole table .
for example :
select count(distinct(name))/count(*) from t_base_user;
give the result as follows :
The maximum value of discrimination is 1.000, The minimum is 0.0000, The greater the value of discrimination , That is, the greater the data non repetition rate , The better the new index , The distinction between primary key and unique key is the highest , by 1.0000. In state , The discrimination value above fields such as gender is the smallest . ( This depends on the amount of data , If there are only a few pieces of data , At this time, the discrimination is quite high , If there's a lot of data , The discrimination is basically 0.0000. That is, after adding indexes to these fields , The reason for the poor effect .)
It is worth noting that : If there is no record in the table , The result of calculating the discrimination is null , In other cases , The discrimination values are distributed in 0.0000-1.0000 Between .
How to index
( One ) : Degree of differentiation
I strongly recommend , When building index , Be sure to calculate the discrimination of this field first , Here's why :
Single index
You can view the discrimination of this field , According to the size of the discrimination , You can also roughly know whether the new index on this field is valid , And how it works . The more distinguishable , The more obvious the indexing effect .
Multi column index ( Joint index )
In fact, there is a problem of field order in multi column index , Generally, the one with higher discrimination is placed in front , In this way, joint indexing is more effective , for example :
select * from t_base_user where name="" and status=1;
Like the above sentence , If you build a joint index , It should be :
alter table t_base_user add index idx_name_status(name,status);
instead of :
alter table t_base_user add index idx_status_name(status,name);
( Two ) Leftmost prefix matching principle
MySQL It will keep matching to the right until it encounters a range query (>、<、between、like) Just stop matching , such as
select * from t_base_user where type="10" and created_at<"2017-11-03" and status=1, ( This statement is only for demonstration )
In the above statement ,status You won't go through the index , Because I met < when ,MySQL Matching has stopped , At this time, the index is :(type,created_at), Its order can be adjusted , And can't walk status Indexes , At this time, you need to modify the statement to :
select * from t_base_user where type=10 and status=1 and created_at<"2017-11-03"
You can go status Indexes .
( 3、 ... and ) Function operation
Don't put it on the index column , Do function operations , Otherwise, the index will fail . because b+ All the data stored in the tree are the field values in the data table , But when searching , You need to apply functions to all elements to compare , Obviously it costs too much .
( Four ) Expansion first
Expansion first , Don't create a new index , Try to modify in the existing index . as follows :
select * from t_base_user where name="andyqian" and email="andytohome"
In the table t_base_user It already exists in the table idx_name Indexes , If you need to join idx_name_email The index of , It should be a modification idx_name Indexes , Instead of creating an index .
Reference resources
边栏推荐
- [principles of multithreading and high concurrency: 1_cpu multi-level cache model]
- 基于can总线的A2L文件解析(2)
- Classes and objects - initialization and cleanup of objects - constructor call rules
- 用docker 连接mysql的过程
- [Fuhan 6630 encodes and stores videos, and uses RTSP server and timestamp synchronization to realize VLC viewing videos]
- 销毁Session和清空指定的属性
- 敏捷认证(Professional Scrum Master)模拟练习题-2
- 迅雷chrome扩展插件造成服务器返回的数据js解析页面数据异常
- Parameter index out of range (1 > number of parameters, which is 0)
- Can netstat still play like this?
猜你喜欢

docker安装redis
Segmentation fault occurs during VFORK execution

Kubernetes family container housekeeper pod online Q & A?

Xiaodi notes

超好用的日志库 logzero

Kubernetes cluster log and efk architecture log scheme
从C到Capable-----利用指针作为函数参数求字符串是否为回文字符

Add automatic model generation function to hade
HTB-Devel
Pytest (6) -fixture (Firmware)
随机推荐
How to select the minimum and maximum values of columns in the data table- How to select min and max values of a column in a datatable?
The left value and the right finger explain better
I2C 子系统(四):I2C debug
I2C 子系统(二):I3C spec
Privatization lightweight continuous integration deployment scheme -- 01 environment configuration (Part 2)
C language beginner level - pointer explanation - paoding jieniu chapter
Getting started | jetpack hilt dependency injection framework
ASP. Net core 6 framework unveiling example demonstration [02]: application development based on routing, MVC and grpc
The solution of "the required function is not supported" in win10 remote desktop connection is to modify the Registry [easy to understand]
Add automatic model generation function to hade
C语言初阶-指针详解-庖丁解牛篇
Three. JS local environment setup
sql server 查詢指定錶的錶結構
从C到Capable-----利用指针作为函数参数求字符串是否为回文字符
ComponentScan和ComponentScans的区别
分布式事务
超好用的日志库 logzero
Random Shuffle attention
How to implement append in tensor
Super easy to use logzero