当前位置:网站首页>Mongodb由浅入深学习
Mongodb由浅入深学习
2022-07-07 18:08:00 【lufei0920】
Mongodb由浅入深学习
Mongodb简介
MongoDB是一种基于分布式文件存储的数据库。它介于关系数据库和非关系数据库之间的产品。
它支持的数据结构非常松散,是类似Json的Bson格式,因此可以存储比较复杂的数据类型。
Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
mongodb 是一个功能最丰富的NoSQL非关系数据库。由 C++ 语言编写。
mongodb 本身提供S端存储数据,即server;也提供C端操作处理(如查询等)数据,即client。
SQL和NoSQL的主要区别:
在SQL中层级关系: 数据库>表>数据
而在NoSQL中则是: 数据库>集合>文档
数据之间无关联性:
SQL中如何需要增加外部关联数据的话,规范化做法是在原表中增加一个外键,关联外部数据表。
NoSQL则可以把外部数据直接放到原数据集中,以提高查询效率。缺点也比较明显,对关联数据做更新时会比较麻烦。
SQL中在一个表中的每条数据的字段是固定的。而NoSQL中的一个集合(表)中的每条文档(数据)的key(字段)可以是互不相同的。
mongodb作为非关系型数据库相较于关系型数据库的优势
易扩展: NoSQL数据库种类繁多, 但是一个共同的特点都是去掉关系数据库的关系型特性。 数据之间无关系, 这样就非常容易扩展大数据量。
高性能: NoSQL数据库都具有非常高的读写性能, 尤其在大数据量下表现优秀。 这得益于它的非关系性,数据库的结构简单灵活的数据模型: NoSQL无需事先为要存储的数据建立字段, 随时可以存储自定义的数据格式。 而在关系数据库中, 增删字段是一件非常麻烦的事情。 如果是非常大数据量的表, 增加字段简直就是一个噩梦
一、MongoDB安装
1、系统命令安装
1)centos 系统安装
yum -y install https://repo.mongodb.org/yum/redhat/7/mongodb-org/4.4/x86_64/RPMS/mongodb-org-mongos-4.4.15-1.el7.x86_64.rpm
yum -y install https://repo.mongodb.org/yum/redhat/7/mongodb-org/4.4/x86_64/RPMS/mongodb-org-shell-4.4.15-1.el7.x86_64.rpm
启动:systemctl start mongod
停止:systemctl stop mongod
重启:systemctl restart mongod
2) ubuntu中使用apt-get工具安装
sudo apt-get install -y mongodb-org
3) 参考官方文档 https://docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/
2、二进制安装
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.15.tgz
tar -xf mongodb-linux-x86_64-rhel70-4.4.15.tgz -C /usr/local
cd /usr/local
mv mongodb-linux-x86_64-rhel70-4.4.15 mongodb
cd ./mongodb
mkdir data
mkdir logs
配置环境变量/etc/profile:
export MONGODB_HOME=/usr/local/mongodb
export PATH=$PATH:$MONGODB_HOME/bin
配置文件:
cd bin
vim mongodb.conf
##编写以下内容:
systemLog:
destination: file
logAppend: true
path: /usr/local/mongodb/logs/mongodb.log
net:
port: 27017
bindIp: 0.0.0.0
maxIncomingConnections: 10000
storage:
dbPath: /usr/local/mongodb/data/db
journal:
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
systemLog:
destination: file
logAppend: true
path: /usr/local/mongodb/logs/mongodb.log
processManagement:
fork: true
security:
authorization: enabled
net:
port: 27017
bindIp: 0.0.0.0
maxIncomingConnections: 10000
启动停止:
./mongod -f ./mongo.conf
sudo ./mongod -f ./mongodb.conf --shutdown
二、MongoDB的简单使用
1、mongodb客户端链接数据库
mongo [options] [db address] [file names (ending in .js)]
2、mongodb的常用简单命令
查看当前的数据库:db(没有切换数据库的情况下默认使用test数据库)
查看所有的数据库:show dbs /show databases
切换数据库:use db_name
db_name为show dbs后返回的数据库名 ,如果数据库不在,则自动创建。
删除当前的数据库:db.dropDatabase()
show dbs 查看数据库名称
show collections 查看已有数据库里面的文档,collections存放文档的表
show users 查看用户
show logs 查看全局日志
help
db.help
db.stats(): 数据库状态
db.serverStatus(): mongodb数据库服务器状态
db.getCollectionName(): 查看所有collections的文档。
db.collections.help
db.students.insert({name:"tom",age:23}) 插入一个students的文档。
show collections 查看这个文档集合
show dbs 查看数据库
db.students.stats() 查看students表的状态
db.students.insert({name:"jerry",age:40,gender:"M"}) 再插入一个文档数据
db.students.find() 查看这个文档集
db.students.count() 统计students中有多少个文档
3、mongodb集合的命令
手动创建集合:
db.createCollection(name,options)
db.createCollection("stu")
db.createCollection("sub", { capped : true, size : 10 } )
参数capped:默认值为false表示不设置上限,值为true表示设置上限
参数size:集合所占用的字节数。 当capped值为true时,需要指定此参数,表示上限大小,当文档达到上限时, 会将之前的数据覆盖,单位为字节
查看集合:show collections
删除集合:db.集合名称.drop()
检查集合是否设定上限: db.集合名.isCapped()
4、mongodb常见数据类型
Object ID: 文档ID/数据的ID,数据的主键
String: 字符串,最常用,必须是有效的UTF-8
Boolean: 存储一个布尔值,true或false
Integer: 整数可以是32位或64位,这取决于服务器
Double: 浮点数
Arrays: 数组/列表
Object: mongodb中的一条数据/文档,即文档嵌套文档
Null: 存储null值
Timestamp: 时间戳,表示从1970-1-1到现在的总秒数
Date: 存储当前日期或时间的UNIX时间格式
注意点
每个文档都有一个属性,为_id,保证每个文档的唯一性,mongodb默认使用_id作为主键
可以手动设置_id的值,如果没有提供,那么MongoDB为每个文档提供了一个独特的_id, 类型为objectID
objectID是一个12字节的十六进制数,每个字节两位,一共是24位的字符串:
前4个字节为当前时间戳
接下来3个字节的机器ID
接下来的2个字节中MongoDB的服务进程id
最后3个字节是简单的增量值
5、mongodb的增删改查
01)插入数据
命令:db.集合名称.insert(document)
db.stu.insert({name:'gj', gender:1})
db.stu.insert({_id:"20220704", name:'gj', gender:1})
02)mongodb保存
命令:db.集合名称.save(document)
db.stu.save({_id:'20220704', name:'gj', gender:2})
db.stu.save({name:'gj', gender:2})
db.stu.find()
03)mongodb的查询
命令:db.集合名称.find()
方法find(): 查询
db.集合名称.find({条件文档})
方法findOne():查询,只返回第一个
db.集合名称.findOne({条件文档})
方法pretty(): 将结果格式化;不能和findOne()一起使用!
db.集合名称.find({条件文档}).pretty()
04)比较运算符
等于: 默认是等于判断, 没有运算符
小于:$lt (less than)
小于等于:$lte (less than equal)
大于:$gt (greater than)
大于等于:$gte
不等于:$ne
05)逻辑运算
and:在json中写多个条件即可
查询年龄大于或等于18, 并且性别为true的学生
db.stu.find({age:{$gte:18},gender:true})
or:使用$or, 值为数组, 数组中每个元素为json
查询年龄大于18, 或性别为false的学生
db.stu.find({$or:[{age:{$gt:18}},{gender:false}]})
查询年龄大于18或性别为男生, 并且姓名是郭靖
db.stu.find({$or:[{age:{$gte:18}},{gender:true}],name:'gj'})
06)范围运算
使用$in, $nin 判断数据是否在某个数组内
查询年龄为18、 28的学生
db.stu.find({age:{$in:[18,28,38]}})
07)支持正则表达式
使用$regex编写正则表达式
查询name以'黄'开头的数据
db.stu.find({name:{$regex:'^黄'}})
08)自定义查询
mongo shell 是一个js的执行环境
使用$where 写一个函数, 返回满足条件的数据
查询年龄大于30的学生
db.stu.find({
$where:function() {
return this.age>30;}
})
09)ship和limit
方法limit(): 用于读取指定数量的文档
db.集合名称.find().limit(NUMBER)
查询2条学生信息
db.stu.find().limit(2)
方法skip(): 用于跳过指定数量的文档
db.集合名称.find().skip(NUMBER)
db.stu.find().skip(2)
同时使用
db.stu.find().limit(4).skip(5)
db.stu.find().skip(5).limit(4)
这两条效果相同,都是先ship后limit。
注意:先使用skip在使用limit的效率要高于前者
10)投影
在查询到的返回结果中, 只选择必要的字段
命令:db.集合名称.find({},{字段名称:1,...})
参数为字段与值, 值为1表示显示, 值为0不显
特别注意:
对于_id列默认是显示的, 如果不显示需要明确设置为0
对于其他不显示的字段不能设置为0
db.stu.find({},{_id:0,name:1,gender:1})
11)排序
方法sort(), 用于对查询结果按照指定的字段进行排序
命令:db.集合名称.find().sort({字段:1,...})
参数1为升序排列
参数-1为降序排列
根据性别降序, 再根据年龄升序
db.stu.find().sort({gender:-1,age:1})
12)统计个数
方法count()用于统计结果集中文档条数
命令:db.集合名称.find({条件}).count()
命令:db.集合名称.count({条件})
db.stu.find({gender:true}).count()
db.stu.count({age:{$gt:20},gender:true})
14)mongodb的更新
db.集合名称.update({query}, {update}, {multi: boolean})
参数query:查询条件
参数update:更新操作符
参数multi:可选,默认是false,表示只更新找到的第一条数据,值为true表示把满足条件的数据全部更新
db.stu.update({name:'hr'},{name:'mnc'}) # 全文档进行覆盖更新
db.stu.update({name:'hr'},{$set:{name:'hys'}}) # 指定键值更新操作
db.stu.update({},{$set:{gender:0}},{multi:true}) # 更新全部
注意:"multi update only works with $ operators"
multi参数必须和$set一起使用!
15) mongodb的删除
db.集合名称.remove({query}, {justOne: boolean})
- 参数query:可选,删除的?档的条件
- 参数justOne:可选, 如果设为true或1,则只删除一条,默认false,表示删除全部
三、MongoDB的聚合操作
1、mongodb的聚合是什么
聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
语法:db.集合名称.aggregate({管道:{表达式}})
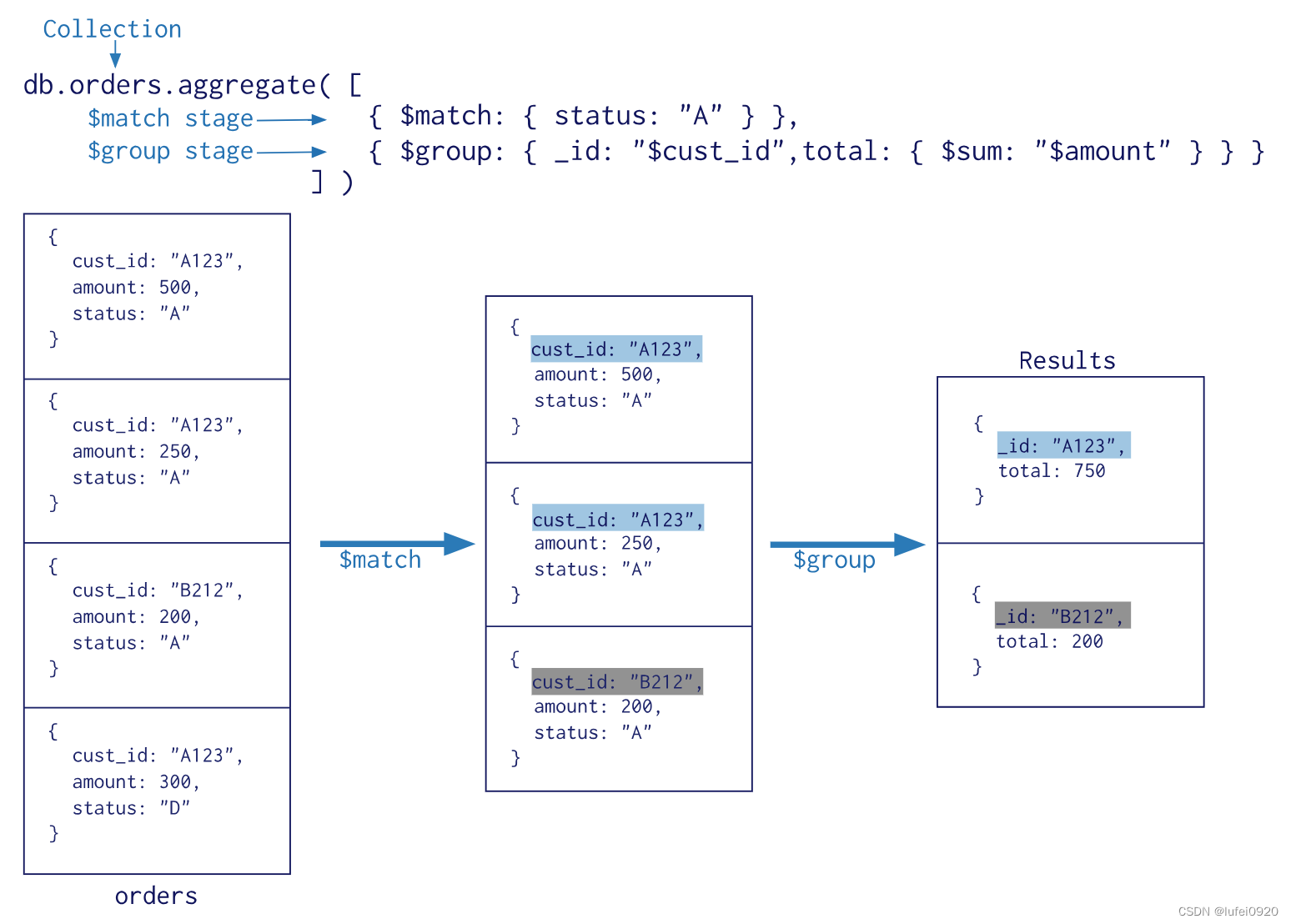
2、mongodb的管道和表达式
1)常用管道命令
常用管道命令如下:
$group: 将集合中的文档分组, 可用于统计结果
$match: 过滤数据, 只输出符合条件的文档
$project: 修改输入文档的结构, 如重命名、 增加、 删除字段、 创建计算结果
$sort: 将输出文档排序后输出
$limit: 限制聚合管道返回的文档数
$skip: 跳过指定数量的文档, 并返回余下的?档
2)常用表达式
语法:表达式:'$列名'
常用表达式:
$sum: 计算总和, $sum:1 表示以1倍计数
$avg: 计算平均值
$min: 获取最小值
$max: 获取最大值
$push: 在结果文档中插入值到一个数组中
3、管道命令之$group
3.1)按照某个字段进行分组
$group是所有聚合命令中用的最多的一个命令,用来将集合中的文档分组,可用于统计结果
使用示例如下:
db.stu.aggregate(
{$group:
{
_id:"$gender",
counter:{$sum:1}
}
}
)
其中注意点:
db.db_name.aggregate是语法,所有的管道命令都需要写在其中
_id 表示分组的依据,按照哪个字段进行分组,需要使用$gender表示选择这个字段进行分组
$sum:1 表示把每条数据作为1进行统计,统计的是该分组下面数据的条数
3.2)group by null
当我们需要统计整个文档的时候,$group 的另一种用途就是把整个文档分为一组进行统计
使用实例如下:
db.stu.aggregate(
{$group:
{
_id:null,
counter:{$sum:1}
}
}
)
其中注意点:
_id:null 表示不指定分组的字段,即统计整个文档,此时获取的counter表示整个文档的个数
3.3) 数据透视
正常情况在统计的不同性别的数据的时候,需要知道所有的name,需要逐条观察,如果通过某种方式把所有的name放到一起,那么此时就可以理解为数据透视。
01、统计不同性别的学生
db.stu.aggregate(
{$group:
{
_id:null,
name:{$push:"$name"}
}
}
)
02、使用$$ROOT可以将整个文档放入数组中
db.stu.aggregate(
{$group:
{
_id:null,
name:{$push:"$$ROOT"}
}
}
)
4、管道命令之$match
$match用于进行数据的过滤,是在能够在聚合操作中使用的命令,和find区别在于$match 操作可以把结果交给下一个管道处理,而find不行.
示例:
1、查询年龄大于20的学生
db.stu.aggregate(
{$match:{age:{$gt:20}}}
)
2、查询年龄大于20的男女学生的人数
db.stu.aggregate(
{$match:{age:{$gt:20}}},
{$group:{_id:"$gender",counter:{$sum:1}}}
)
5 管道命令之$project
$project用于修改文档的输入输出结构,例如重命名,增加,删除字段
使用示例如下:
1、查询学生的年龄、姓名,仅输出年龄姓名
db.stu.aggregate(
{$project:{_id:0,name:1,age:1}}
)
2、查询男女生人生,输出人数
db.stu.aggregate(
{$group:{_id:"$gender",counter:{$sum:1}}},
{$project:{_id:0,counter:1}}
)
6、 管道命令之$sort
$sort用于将输入的文档排序后输出
使用示例如下:
1、查询学生信息,按照年龄升序
db.stu.aggregate({$sort:{age:1}})
2、查询男女人数,按照人数降序
db.stu.aggregate(
{$group:{_id:"$gender",counter:{$sum:1}}},
{$sort:{counter:-1}}
)
7、 管道命令之$skip 和 $limit
$limit限制返回数据的条数
$skip 跳过指定的文档数,并返回剩下的文档数
注意:同时使用时先使用skip在使用limit
使用示例如下:
1、查询2条学生信息
db.stu.aggregate(
{$limit:2}
)
2、查询从第三条开始的学生信息
db.stu.aggregate(
{$skip:3}
)
3、统计男女生人数,按照人数升序,返回第二条数据
db.stu.aggregate(
{$group:{_id:"$gender",counter:{$sum:1}}},
{$sort:{counter:-1}},
{$skip:1},
{$limit:1}
)
四、MongoDB的索引操作
1、mongodb创建简单的索引方法
语法:db.集合名.ensureIndex({属性:1}),1表示升序, -1表示降序
2、创建索引前后查询速度对比
测试:插入100万条数据到数据库中
插入数据:
for(i=0;i<1000000;i++){db.t1.insert({name:'test'+i,age:i})}
创建索引前:
db.t1.find({name:'test955342'})
db.t1.find({name:'test955342'}).explain('executionStats') # 显示查询操作的详细信息
创建索引:
db.t1.ensureIndex({name:1})
创建索引后:
db.t1.find({name:'test955342'}).explain('executionStats')
前后速度对比:
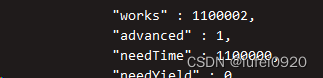

3、索引查看
查看方式:db.集合名.getIndexes()

4、删除索引
语法:db.集合名.dropIndex({'索引名称':1})
db.t1.dropIndex({name:1})
db.t1.getIndexes()

5、mongodb创建唯一索引
在默认情况下mongdb的索引域的值是可以相同的,创建唯一索引之后,数据库会在插入数据的时候检查创建索引域的值是否存在,如果存在则不会插入该条数据,但是创建索引仅仅能够提高查询速度,同时降低数据库的插入速度。
语法:db.集合名.ensureIndex({"字段名":1}, {"unique":true})
利用唯一索引进行数据去重:
根据唯一索引指定的字段的值,如果相同,则无法插入数据
db.t1.ensureIndex({"name":1}, {"unique":true})
db.t1.insert({name: 'test10000'})
6、建立复合索引
在进行数据去重的时候,可能用一个域来保证数据的唯一性,这个时候可以考虑建立复合索引来实现。
例如:抓全贴吧信息,如果把帖子的名字作为唯一索引对数据进行去重是不可取的,因为可能有很多帖子名字相同
建立复合索引的语法:db.collection_name.ensureIndex({字段1:1,字段2:1})
注意:
根据需要选择是否需要建立唯一索引
索引字段是升序还是降序在单个索引的情况下不影响查询效率,但是带复合索引的条件下会有影响
数据量巨大并且数据库的读出操作非常频繁的时候才需要创建索引,如果写入操作非常频繁,创建索引会影响写入速度
例如:在进行查询的时候如果字段1需要升序的方式排序输出,字段2需要降序的方式排序输出,那么此时复合索引的建立需要把字段1设置为1,字段2设置为-1
五、MongoDB的权限管理
1、为什么要进行权限管理的设置
刚安装完毕的mongodb默认不使用权限认证方式启动,与MySQL不同,mongodb在安装的时候并没有设置权限,然而公网运行系统需要设置权限以保证数据安全,所以我们要学习mongodb的权限管理。
2、mongodb的权限管理方案
MongoDB是没有默认管理员账号,所以要先添加管理员账号,并且mongodb服务器需要在运行的时候开启验证模式
用户只能在用户所在数据库登录(创建用户的数据库),包括管理员账号。
管理员可以管理所有数据库,但是不能直接管理其他数据库,要先认证后才可以。
3、mongodb超级管理员账号的创建
3.1 创建超级用户
使用admin数据库(超级管理员账号必须创建在该数据库上)
use admin
创建超级用户
db.createUser({"user":"pytest","pwd":"python","roles":["root"]})

通过超级用户登录
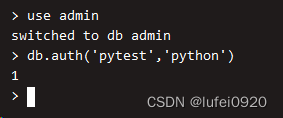
说明:python用户是创建在admin数据库上的所以必须来到admin数据库上进行认证
认证成功会返回1,失败返回0
如果不切换用户且登录账号密码,则操作没有任何显示。
4、创建普通用户
4.1 选着需要创建用户的数据库
use test
4.2 创建用户
db.createUser({"user":"user1", "pwd":"pwd1", roles:["read"]}) # 创建普通用户user1,该用户在test1上的权限是只读
db.createUser({"user":"user2", "pwd":"pwd1", roles:["readWrite"]}) # 创建普通用户user1,该用户在test1上的权限是读写
4.3 在admin用户数据库上创建普通用户
use admin
db.createUser({"user":"python1", "pwd":"python1", roles:[{"role":"read","db":"dbname1"},{"role":"readWrite","db":"dbname2"}]})
在admin上创建python1用户,python1用户的权限有两个,一个再dbname1上的只读,另一个是在dbname2上的读写
5、查看创建的用户
show users
6、删除用户
use db_name # 进入账号所在的数据库
db.dropUser('python') # 删除对应想删除的账号
边栏推荐
- Gorilla official: sample code for golang to open websocket client
- vulnhub之Funfox2
- Machine learning notes - explore object detection datasets using streamlit
- R language ggplot2 visualization: use the ggstripchart function of ggpubr package to visualize the dot strip plot, set the position parameter, and configure the separation degree of different grouped
- Openeuler prize catching activities, to participate in?
- 力扣 989. 数组形式的整数加法
- Some arrangements about oneself
- c语言如何判定是32位系统还是64位系统
- R language ggplot2 visualization: use the ggqqplot function of ggpubr package to visualize the QQ graph (Quantitative quantitative plot)
- Implement secondary index with Gaussian redis
猜你喜欢
Sword finger offer II 013 Sum of two-dimensional submatrix
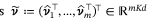
Automatic classification of defective photovoltaic module cells in electroluminescence images-论文阅读笔记
vulnhub之tre1
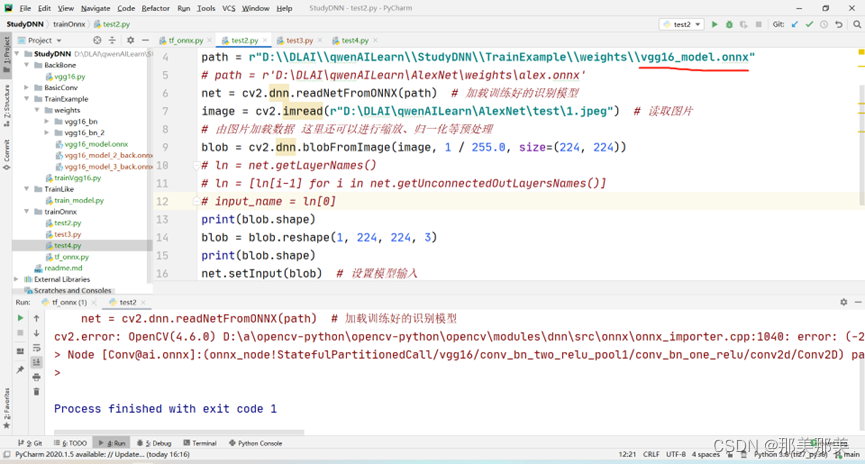
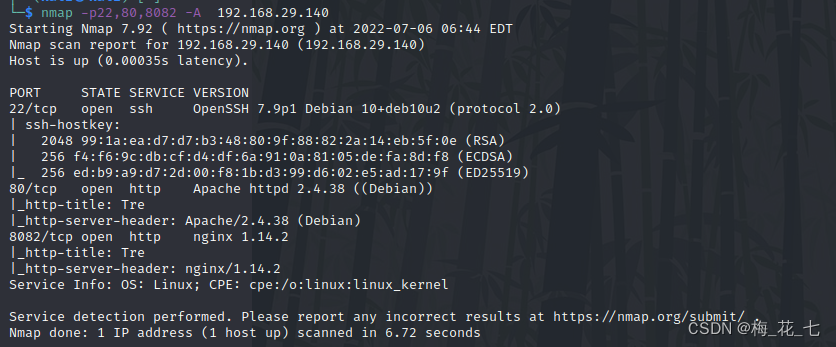
关于cv2.dnn.readNetFromONNX(path)就报ERROR during processing node with 3 inputs and 1 outputs的解决过程【独家发布】
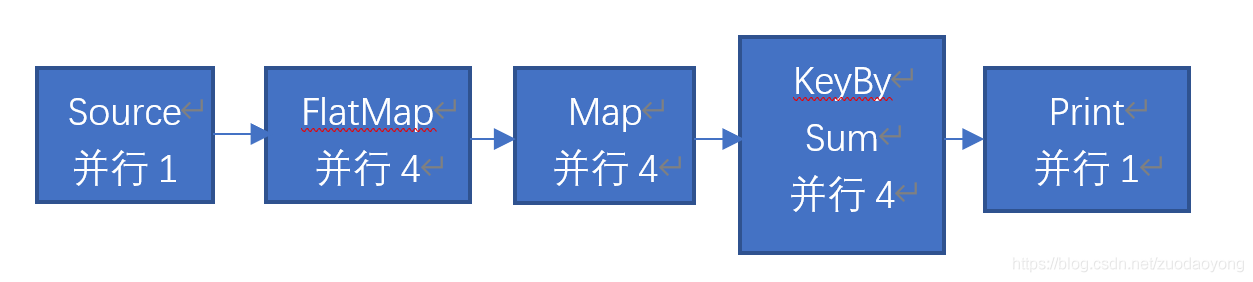
Flink并行度和Slot详解
BI的边界:BI不适合做什么?主数据、MarTech?该如何扩展?

干货分享|DevExpress v22.1原版帮助文档下载集合
ASP.NET学习& asp‘s one word

CSDN语法说明
Interpretation of transpose convolution theory (input-output size analysis)
随机推荐
JVM class loading mechanism
力扣 1790. 仅执行一次字符串交换能否使两个字符串相等
Version selection of boot and cloud
PHP method of obtaining image information
vulnhub之school 1
微信公众号OAuth2.0授权登录并显示用户信息
一文读懂数仓中的pg_stat
MSE API学习
Force buckle 1790 Can two strings be equal by performing string exchange only once
论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
The DBSCAN function of FPC package of R language performs density clustering analysis on data, checks the clustering labels of all samples, and the table function calculates the two-dimensional contin
Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記
rk3128投影仪lcd显示四周显示不完整解决
Chapter 9 Yunji datacanvas company won the highest honor of the "fifth digital finance innovation competition"!
关于cv2.dnn.readNetFromONNX(path)就报ERROR during processing node with 3 inputs and 1 outputs的解决过程【独家发布】
How to cooperate among multiple threads
力扣674. 最长连续递增序列
九章云极DataCanvas公司获评36氪「最受投资人关注的硬核科技企业」
Automatic classification of defective photovoltaic module cells in electroluminescence images-论文阅读笔记
ASP. Net gymnasium integrated member management system source code, free sharing