当前位置:网站首页>Reading notes of Clickhouse principle analysis and Application Practice (7)
Reading notes of Clickhouse principle analysis and Application Practice (7)
2022-07-08 01:51:00 【Aiky WOW】
Begin to learn 《ClickHouse Principle analysis and application practice 》, Write a blog and take reading notes .
The whole content of this article comes from the content of the book , Personal refining .

The first 9 Chapter :
The first 10 Chapter Copy and fragment
10.1 summary
ClickHouse The cluster configuration is very flexible , Users can form all nodes into a single cluster , Or according to the demands of the business , Divide the nodes into several small clusters .
Between each small cluster area , Their nodes 、 The number of partitions and replicas can vary .

The data between slices are different , And the data between copies is exactly the same .
The main purpose of using replicas is to prevent data loss , Increase the redundancy of data storage ; The main purpose of using segmentation is to realize the horizontal segmentation of data .

10.2 Copy of data

stay MergeTree in , A data partition is created from the beginning to the end , Will go through two types of storage areas .
- Memory : The data is first written to the memory buffer .
- Local disk : The data is then written tmp Temporary directory partition , When all are completed, rename the temporary directory to the official partition .
ReplicatedMergeTree On the basis of the above, add ZooKeeper Part of , It will go further in ZooKeeper Create a series of listening nodes , And realize the communication between multiple instances .
In the whole process of communication ,ZooKeeper It does not involve the transmission of table data .
10.2.1 Characteristics of copies
- rely on ZooKeeper: In execution INSERT and ALTER When querying , ReplicatedMergeTree Need help ZooKeeper Distributed collaboration capability , To achieve synchronization between multiple replicas . But when querying the copy , No need to use ZooKeeper.
- Multi master architecture (Multi Master): Can be executed on any copy INSERT and ALTER Inquire about , Their effects are the same . These operations are performed with the help of ZooKeeper The collaboration capability is distributed to each replica and executed locally .
- Block Data blocks : In execution INSERT When the command writes data , Will be based on max_insert_block_size Size ( Default 1048576 That's ok ) Divide the data into several Block Data blocks . therefore Block Data block is the basic unit of data writing , And it has atomicity and uniqueness of writing .
- Atomicity is : On data write , One Block Either all the data in the block is written successfully , All or nothing .
- Uniqueness is : Writing a Block Data block time , Will follow the current Block Data order of data blocks 、 Indicators such as data row and data size , Calculation Hash Information summary and record . after , If a to be written Block The data block is the same as that previously written Block Data blocks have the same Hash Abstract (Block Data sequence in data block 、 The data size and data rows are the same ), Then Block Data blocks are ignored . This design can prevent Caused by abnormal reasons Block The problem of repeated writing of data blocks .
10.2.2 ZooKeeper Configuration mode
Used by each copy Zookeeper The configuration is usually the same , To facilitate copying configuration files between multiple nodes , A more common approach is to put this Some configurations are pulled out , Use a separate file to save .
On the server /etc/clickhouse-server/config.d Create one in the directory be known as metrika.xml Configuration file for :
<?xml version="1.0"?>
<yandex>
<zookeeper-servers> <!—ZooKeeper To configure , Name customization -->
<node index="1"> <!— Node configuration , You can configure multiple addresses -->
<host>hdp1.nauu.com</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
In global configuration config.xml Use in <include_from> Label import the configuration just defined :
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
And reference ZooKeeper Definition of configuration :
<zookeeper incl="zookeeper-servers" optional="false" />ClickHouse A photo named zookeeper Of Proxy table . Through this chart , have access to SQL Read remote data by query ZooKeeper The data in .
Of the query SQL In the sentence , Must specify path Conditions :
SELECT * FROM system.zookeeper where path = '/'
┌─name───────┬─value─┬──────czxid─┬──────mzxid─┬───────────────ctime─┬───────────────mtime─┬─version─┬─cversion─┬─aversion─┬─ephemeralOwner─┬─dataLength─┬─numChildren─┬──────pzxid─┬─path─┐
│ zookeeper │ │ 0 │ 0 │ 1970-01-01 08:00:00 │ 1970-01-01 08:00:00 │ 0 │ -2 │ 0 │ 0 │ 0 │ 2 │ 0 │ / │
│ clickhouse │ │ 4294967299 │ 4294967299 │ 2022-06-20 10:52:21 │ 2022-06-20 10:52:21 │ 0 │ 1 │ 0 │ 0 │ 0 │ 1 │ 4294967301 │ / │
└────────────┴───────┴────────────┴────────────┴─────────────────────┴─────────────────────┴─────────┴──────────┴──────────┴────────────────┴────────────┴─────────────┴────────────┴──────┘
SELECT * FROM system.zookeeper where path = '/clickhouse';
┌─name───────┬─value─┬──────czxid─┬──────mzxid─┬───────────────ctime─┬───────────────mtime─┬─version─┬─cversion─┬─aversion─┬─ephemeralOwner─┬─dataLength─┬─numChildren─┬──────pzxid─┬─path────────┐
│ task_queue │ │ 4294967301 │ 4294967301 │ 2022-06-20 10:52:21 │ 2022-06-20 10:52:21 │ 0 │ 1 │ 0 │ 0 │ 0 │ 1 │ 4294967303 │ /clickhouse │
└────────────┴───────┴────────────┴────────────┴─────────────────────┴─────────────────────┴─────────┴──────────┴──────────┴────────────────┴────────────┴─────────────┴────────────┴─────────────┘10.2.3 Definition form of copy
Using replicas increases the redundant storage of data , So it reduces the risk of data loss .
Each replica instance can be read as data 、 Write the entry , This undoubtedly apportions the load of the node .
ReplicatedMergeTree It's defined in the following way :
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')zk_path Used to specify the ZooKeeper Path to the data table created in , The path name is custom , There are no fixed rules , Users can set any path they want .
ck Configuration template provided :/clickhouse/tables/{shard}/table_name
- /clickhouse/tables/ It is a conventional fixed prefix of path , Indicates the root path where the data table is stored .
- {shard} Indicates the slice number , Usually use numerical values instead of , for example 01、02、03. One A data table can have multiple slices , And each fragment has its own copy .
- table_name Represents the name of the data table , For the convenience of maintenance , Usually the same name as the physical table ( although ClickHouse It is not mandatory that the table name in the path be the same as the physical table name ); and replica_name The role of is defined in ZooKeeper The name of the replica created in , This name is a unique identifier that distinguishes different replica instances . One convention is to use the domain name of the server .
//1 Fragmentation ,1 Copy situation :
// zk_path identical ,replica_name Different
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch5.nauu.com')
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch6.nauu.com')
// Multiple slices 、1 Copy situation :
// Fragmentation 1
// 2 Fragmentation ,1 copy . zk_path identical , among {shard}=01, replica_name Different
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch5.nauu.com')
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch6.nauu.com')
// Fragmentation 2
// 2 Fragmentation ,1 copy . zk_path identical , among {shard}=02, replica_name Different
ReplicatedMergeTree('/clickhouse/tables/02/test_1, 'ch7.nauu.com')
ReplicatedMergeTree('/clickhouse/tables/02/test_1, 'ch8.nauu.com')10.3 ReplicatedMergeTree Principle analysis
10.3.1 data structure
In the core logic , A lot of use of ZooKeeper The ability of , To achieve multiple ReplicatedMergeTree Collaboration between replica instances , Including master copy election 、 Replica state awareness 、 Operation log distribution 、 Task queues and BlockID De judgment, etc .
perform INSERT Data writing 、MERGE Zoning and MUTATION During operation , Will involve ZooKeeper Communication for .
In the process of communication , It does not involve the transmission of any table data , It will not be accessed when querying data ZooKeeper.
from zookeeper The data structure is introduced .
1.ZooKeeper Node structure in
In each ReplicatedMergeTree During the creation of the table , It will be to zk_path Root path , stay Zoo-Keeper Create a group of listening nodes for this table in .
Monitoring nodes can be roughly divided into the following categories :
1) Metadata :
- /metadata: Save metadata information , Include primary key 、 The partitioning key 、 Sampling expression, etc .
- /columns: Save column field information , Including column name and data type .
- /replicas: Save copy name , Corresponding to replica_name.
2) Judgment mark :
- /leader_election: For the election of the master copy , The master copy will dominate MERGE and MUTATION operation (ALTER DELETE and ALTER UPDATE). These tasks can be done with the help of... After the master copy is completed ZooKeeper Distribute message events to other copies .
- /blocks: Record Block The data block Hash The information in this paper, , And corresponding partition_id. adopt Hash The abstract can judge Block Whether the data block is repeated ; adopt partition_id, You can find the data partition that needs to be synchronized .
- /block_numbers: According to the write order of the partition , Record in the same order partition_id. Each copy is made locally MERGE when , Will follow the same block_numbers Proceed in sequence .
- /quorum: Record quorum The number of , When at least quorum After the number of copies is successfully written , The whole write operation is successful .quorum The number of insert_quorum Parameter control , The default value is 0.
3) The operation log :
- /log: General operation log node (INSERT、MERGE and DROP PARTITION), It is the most important part of the whole working mechanism , Save the task instructions to be executed by the copy .log Used ZooKeeper Persistent sequential nodes , The name of each instruction is in log- Increment the prefix , for example log-0000000000、log-0000000001 etc. . Each replica instance will listen /log node , When a new instruction is added , They will add instructions to the respective task queues of the copies , And perform the task . About the execution logic in this regard , It will be further expanded later .
- /mutations:MUTATION Operation log node , The functions and log The log is similar to , When executed ALERT DELETE and ALERT UPDATE When inquiring , Operation instructions will be added to this node .mutations The same is used ZooKeeper Persistent sequential nodes , But its name has no prefix , Each instruction is saved directly as an incremental number , for example 0000000000、0000000001 etc. . About the execution logic in this regard , Also expand later .
- /replicas/{replica_name}/*: A group of listening nodes under the nodes of each replica , It is used to guide the replica to execute specific task instructions locally , The more important nodes are as follows :
- /queue: Task queue node , Used to perform specific operational tasks . When copy from /log or /mutations When the node listens to the operation instruction , The execution task will be added to this node , And execute based on queue .
- /log_pointer:log Log pointer node , The last execution of log Log subscript information , for example log_pointer:4 Corresponding /log/log-0000000003( from 0 Start counting ).
- /mutation_pointer:mutations Log pointer node , The last execution of mutations Log name , for example mutation_pointer:0000000000 Corresponding /mutations/000000000.
2.Entry Data structure of log object
Two sets of parent nodes /log and /mutations It is the information channel for distributing operation instructions , And the way of sending instructions , Add child nodes for these parent nodes .
All copy instances , Will listen to the changes of the parent node , When a child node is added , They can perceive in real time .
These added child nodes are in ClickHouse Is unified and abstracted as Entry object , The specific implementation is by Log-Entry and MutationEntry Object bearing , They correspond to each other /log and /mutations node .
1)LogEntry
LogEntry For encapsulation /log The child node information of .
- source replica: Send this Log Copy source of instruction , Corresponding replica_name.
- type: Operation instruction type , There are mainly get、merge and mutate Three , Corresponding to downloading partitions from remote copies 、 Merge partitions and MUTATION operation .
- block_id: Of the current partition BlockID, Corresponding /blocks The name of the child node of the path .
- partition_name: The name of the current partition directory .
2)MutationEntry
MutationEntry For encapsulation /mutations The child node information of .
- source replica: Send this MUTATION Copy source of instruction , Corresponding replica_name.
- commands: Operating instructions , There are mainly ALTER DELETE and ALTER UPDATE.
- mutation_id:MUTATION Version number of the operation .
- partition_id: Of the current partition directory ID.
10.3.2 The core process of replica collaboration
The core processes of replica collaboration mainly include INSERT、MERGE、MUTATION( Data modification ) and ALTER( Metadata modification ) Four kinds of .
Other queries do not support distributed execution , Include SELECT、CREATE、DROP、RENAME and ATTACH.
1.INSERT The core execution process of

1) Create the first replica instance
CREATE TABLE replicated_sales_1(
id String,
price Float64,
create_time DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_1','ch5.nauu.com')
PARTITION BY toYYYYMM(create_time)
ORDER BY id
During creation ,ReplicatedMergeTree Some initialization operations will be performed .
- according to zk_path Initialize all ZooKeeper node .
- stay /replicas/ Register your own replica instance under the node ch5.nauu.com.
- Start listening task , monitor /log Log nodes .
- Participate in the replica election , Elect the master copy , The way of election is to /leader_election/ Insert child node , First insert The successful copy is the master copy .
2) Create a second replica instance
Create a second replica instance . Table structure and zk_path It needs to be the same as the first copy , and replica_name It needs to be set to CH6 Domain name of :
CREATE TABLE replicated_sales_1(
// The same structure
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_1','ch6.nauu.com')
// The same structure the second ReplicatedMergeTree Some initialization operations will also be performed .
- stay /replicas/ Register your own replica instance under the node ch6.nauu.com.
- Start listening task , monitor /log Log nodes .
- Participate in the replica election , Elect the master copy . In this case ,CH5 The copy becomes the master copy .
3) Write data to the first replica instance
-- Write data to the first replica instance
INSERT INTO TABLE replicated_sales_1 VALUES('A001',100,'2019-05-10 00:00:00') After the above command is executed , First, the partition directory will be written locally :
Renaming temporary part tmp_insert_201905_1_1_0 to 201905_0_0_0
Then to /blocks The node writes to the data partition block_id:
Wrote block with ID '201905_2955817577822961065_12656761735954722499'
The block_id It will be used as the judgment basis for subsequent weight removal operations . If you execute the previous step again at this time INSERT sentence , Try to write Enter duplicate data , The following prompt will appear :
Block with ID 201905_2955817577822961065_12656761735954722499 already exists; ignoring it.
That is, the copy will be automatically ignored block_id Repeated data to be written . Besides , If set insert_quorum Parameters ( The default is 0), also insert_quorum>=2, be CH5 The number of copies that have completed the write operation will be further monitored , Only when the number of written copies is greater than or equal to insert_quorum when , The whole write operation Success is what you do .
4) Pushed by the first replica instance Log journal
stay 3 After the steps are completed , Will continue to be carried out by INSERT Copy of to /log Node push operation log .
The first copy in the above example CH5 Take the heavy responsibility .
The log number is /log/log-0000000000, and LogEntry The core attributes of :
/log/log-0000000000
source replica: ch5.nauu.com
block_id: 201905_...
type : get
partition_name :201905_0_0_0It can be seen from the contents of the log , The type of operation is get download , The partition that needs to be downloaded is 201905_0_0_0.
All other copies will be based on Log Logs execute commands in the same order .
5) The second instance is pulled Log journal
CH6 The copy will always listen /log Node change , When CH5 Pushed /log/log-0000000000 after ,CH6 The log pull task will be triggered and updated log_pointer, Point it to the latest log subscript :
/replicas/ch6.nauu.com/log_pointer : 0
Yes LogEntry after , It does not directly execute , Instead, turn it into a task object and put it in the queue :
/replicas/ch6.nauu.com/queue/ Pulling 1 entries to queue: log-0000000000 - log-0000000000
Because there may be multiple in the same period LogEntry, So using queue to digest tasks is a more reasonable design .
Be careful , Pulled LogEntry It's an interval , This is also because you may receive multiple in succession LogEntry.
6) The second replica instance initiates a download request to other replicas
CH6 be based on /queue The queue starts executing tasks .
type The type is get,ReplicatedMerge-Tree Know that now you need to synchronize the data partitions in other replicas .
CH6 The second copy instance on will start selecting a remote copy as the data download source .
The selection algorithm is roughly :
- from /replicas The node gets all the replica nodes .
- Traverse these copies , Choose one of them . The selected copy needs to have the largest log_pointer Subscript , also /queue The number of child nodes is the least .log_pointer Subscript max , This means that the copy executes the most logs , The data should be more complete ; and /queue Minimum , It means that the current task execution burden of the copy is small .
If the first download request fails , By default ,CH6 Try again to request 4 Time , I will try 5 Time ( from max_fetch_partition_retries_count Parameter control , The default is 5).
7) The first copy instance responds to data download
CH5 Respond according to parameters , Send local partition data .
8) The second instance downloads data and completes local writing
CH6 Copy received at CH5 After partition data of , First write it to the temporary directory .
After receiving all data , Rename the directory
thus , The whole writing process ends .
stay INSERT During the writing of ,ZooKeeper There will be no substantial data transmission .
In line with the principle of who implements who is responsible , In this case by CH5 First, the partition data is written locally . after , This copy is also responsible for sending Log journal , Notify other copies to download data . If set insert_quorum also insert_quorum>=2, The number of copies written will also be monitored by this copy . Other copies are received Log After the log , Will choose the most appropriate remote copy , Download partition data point-to-point .
2.MERGE The core execution process of
No matter what MERGE The copy from which the operation originated , The merger plan will be made by the master copy .
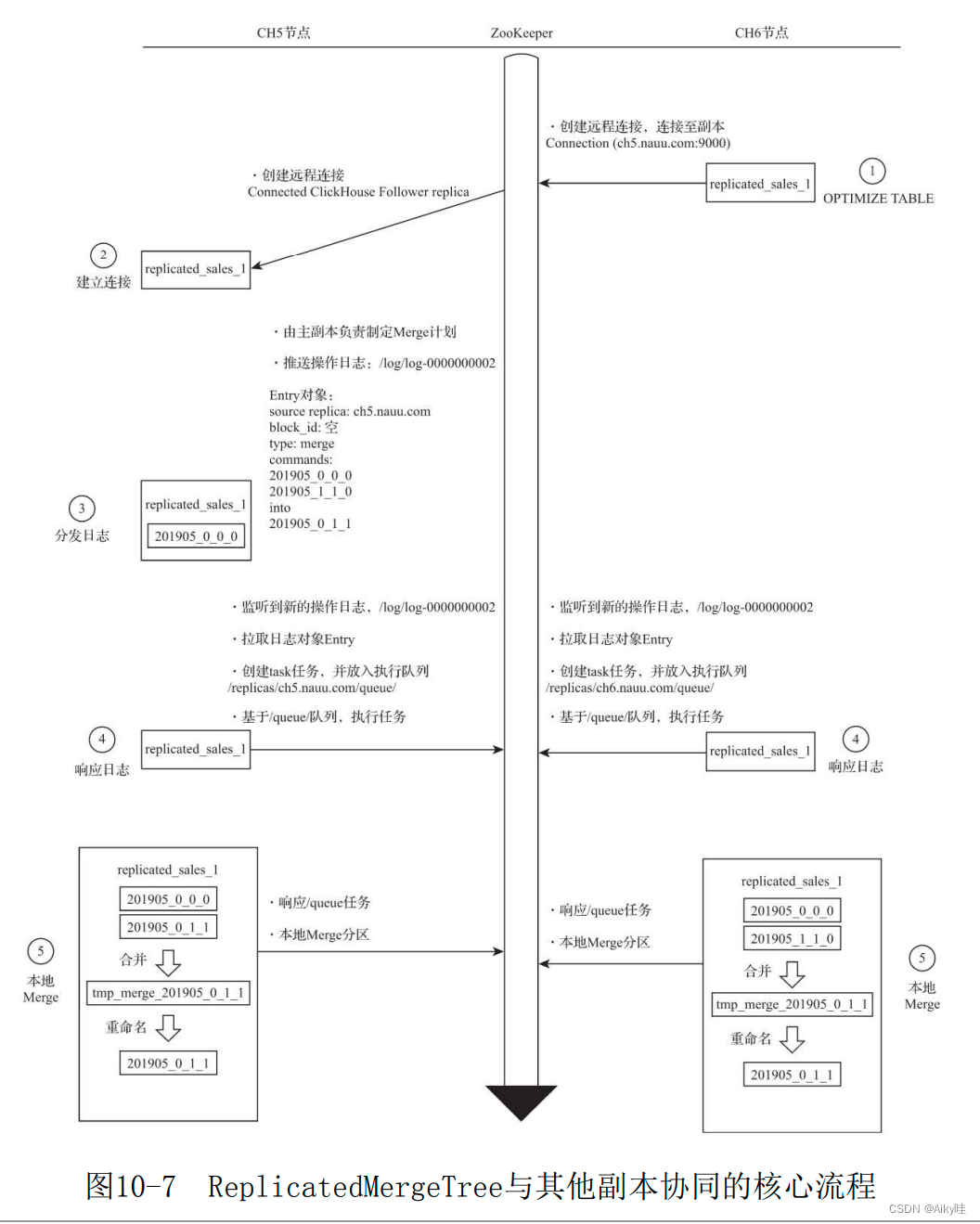
1) Create a remote connection , Try to communicate with the primary replica
stay CH6 Node execution OPTIMIZE, Force trigger MERGE Merge .
CH6 adopt /replicas Find the master and the mate Ben CH5, And try to establish a remote connection with it .
2) The master copy receives communications
Master copy CH5 Receive and establish a copy from the remote CH6 The connection of .
3) Made by the master copy MERGE Plan and push Log journal
By master copy CH5 To develop MERGE plan , And determine which partitions need to be merged . After selection ,CH5 Convert the consolidation plan by Log Log objects and push Log journal , Start merging by notifying all copies .
Log information :
/log/log-0000000002
source replica: ch5.nauu.com
block_id:
type : merge
201905_0_0_0
201905_1_1_0
into
201905_0_1_1The type of operation is Merge Merge , The partition directory to be merged this time is 201905_0_0_0 and 201905_1_1_0.
meanwhile , The master copy will also lock the execution thread , Monitor the reception of logs .
Monitoring behavior is controlled by replication_alter_partitions_sync Parameter control , The default value is 1. When this parameter is 0 when , No waiting ; by 1 when , Just wait for the master copy to complete itself ; by 2 when , Will wait for all copies to be pulled .
4) Each copy is pulled separately Log journal
CH5 and CH6 The two replica instances will listen separately /log/log-0000000002 Log push , They will also pull logs locally , And push them to their respective /queue Task queue
5) Each copy is executed locally MERGE
CH5 and CH6 Based on their own /queue The queue starts executing tasks , Start executing locally MERGE.
thus , The whole consolidation process ends .
stay MERGE In the course of the merger ,ZooKeeper There will be no substantial data transmission , All merge operations , Finally, each copy is completed locally .
No matter which copy the merge action is triggered , Will first be forwarded to the master copy , Then the master copy is responsible for the formulation of the merger plan 、 Push message logs and monitor log reception .
3.MUTATION The core execution process of
perform ALTER DELETE perhaps ALTER UPDATE During operation , You will enter MUTATION Partial logic .
And MERGE similar , Respond by the primary replica .
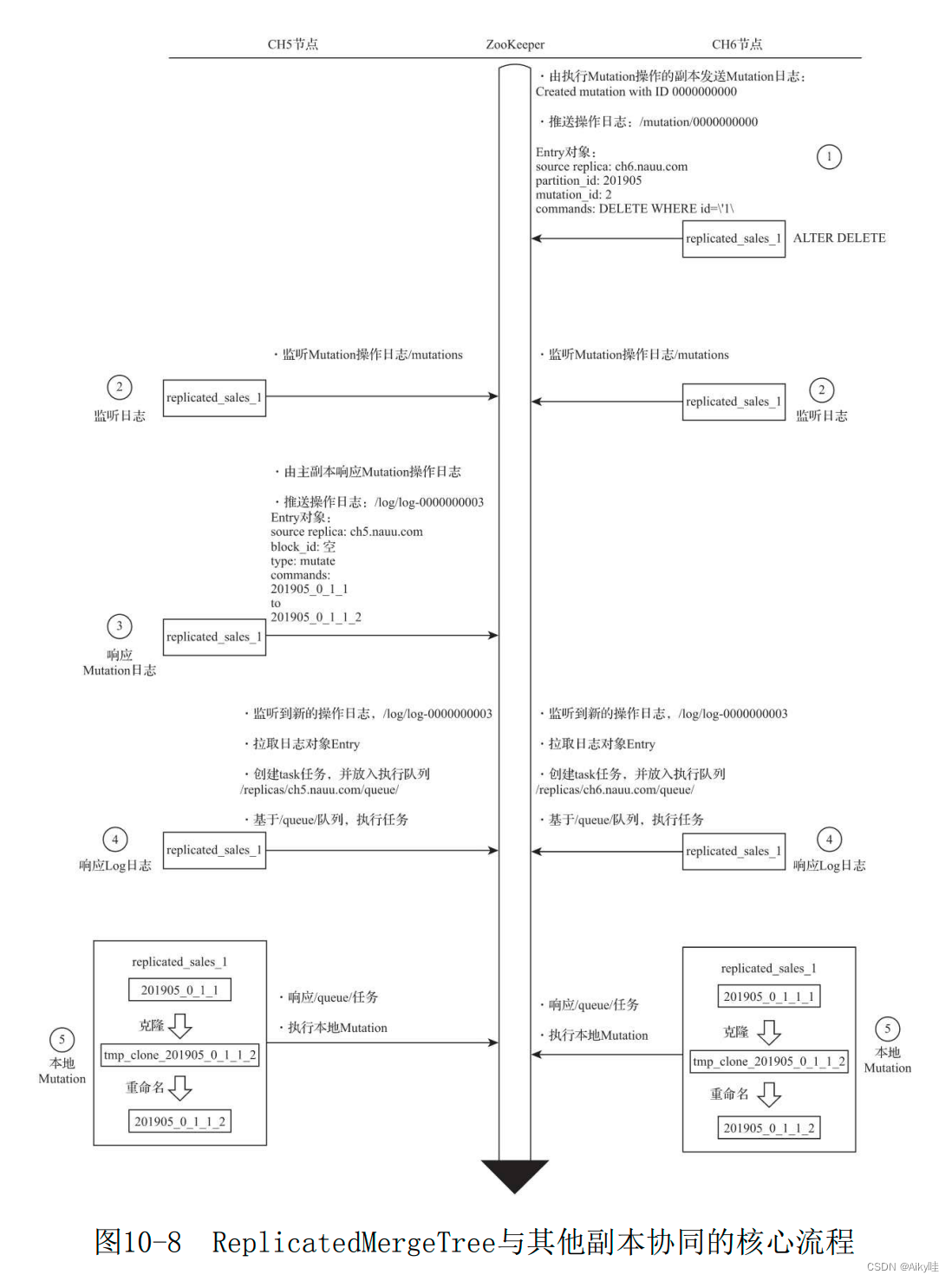
1) push MUTATION journal
stay CH6 Node attempts to pass DELETE To delete data .
After performing , This copy will be followed by two important things :
- establish MUTATION ID
- take MUTATION The operation is converted to MutationEntry journal , And push it to /mutations/0000000000
MutationEntry The core attributes of :
/mutations/0000000000
source replica: ch6.nauu.com
mutation_id: 2
partition_id: 201905
commands: DELETE WHERE id = \'1\'MUTATION The operation log of is via /mutations Nodes are distributed to each replica .
2) All replica instances listen individually MUTATION journal
CH5 and CH6 They're all monitoring /mutations node , When the supervisor hears something new MUTATION When the log is added , Not all copies will respond directly , They will first determine whether they are the master replica .
3) Respond by the primary replica instance MUTATION Log and push Log journal
Only the primary replica will respond MUTATION journal .
CH5 take MUTATION Log transfer Replace with LogEntry Log and push to /log node .
The core information of the log :
/log/log-0000000003
source replica: ch5.nauu.com
block_id:
type : mutate
201905_0_1_1
to
201905_0_1_1_2
The type is mutate, Need to put 201905_0_1_1 The partition is changed to 201905_0_1_1_2(201905_0_1_1 +"_" + mutation_id).
4) Each replica instance is pulled separately Log journal
CH5 and CH6 Two copies listen separately /log/log-0000000003 Log push , Pull logs to this The earth , And push them to their respective /queue Task queue .
5) Each replica instance executes locally MUTATION
CH5 and CH6 Based on their own /queue The queue starts executing tasks , Execute locally MUTATION.
thus , Whole MUTATION End of the process .
be-all MUTATION operation , Finally, each copy is completed locally .
No matter what MUTATION From which copy is the action triggered , After that, it will be forwarded to the master copy , Then the master copy is responsible for pushing Log journal , To notify each copy to execute the final MUTATION Logic . At the same time, the master copy also monitors the receipt of logs .
4.ALTER The core execution process of
Execution increase 、 When deleting table fields and other operations , Get into ALTER Partial logic .
It will not involve /log Distribution of logs . The whole process is carried out in chronological order from top to bottom .

1) Modify shared metadata
stay CH6 The node tries to add a column field , After performing ,CH6 Will modify ZooKeeper Shared metadata node in .
After data modification , The version number of the node will also be increased .
meanwhile ,CH6 It will also be responsible for monitoring the modification completion of all copies
2) Listen for shared metadata changes and perform local modifications respectively
CH5 and CH6 The two replicas listen for changes in shared metadata .
after , They will compare the local metadata version number with Compare the shared version number .
It is found that the local version number is lower than the shared version number , Start updating locally .
3) Confirm that all copies have been modified
CH6 Confirm that all copies have been modified .
thus , Whole ALTER End of the process .
In line with the principle of who implements who is responsible , In this case by CH6 Responsible for the modification of shared metadata and the monitoring of the modification progress of each copy .
10.4 Data fragmentation
Data copy cannot solve the capacity problem of data table .
ClickHouse Data fragmentation needs to be combined Distributed Use with table engine .
Distributed The table engine itself does not store any data , It can be used as a distributed table A layer of transparent proxy , Automatically write data in the cluster 、 distribution 、 Inquire about 、 Routing and so on .
10.4.1 How to configure the cluster
1 Fragmentation 、0 The configuration of replica semantics is as follows
<shard> <!-- Fragmentation -->
<replica><!— copy -->
</replica>
</shard>
in 1 Fragmentation 、1 Configuration of replica semantics
<shard> <!-- Fragmentation -->
<replica><!— copy -->
</replica>
<replica>
</replica>
</shard>
There are two configurations of clusters :
1. Fragments that do not contain copies
【 Use here node Configuration of is really uncommon , All the manufacturers I see use shard To define the , Skip this 】
2. Custom shards and copies
<!-- 2 A shard 、0 Copies -->
<sharding_simple> <!-- Custom cluster name -->
<shard> <!-- Fragmentation -->
<replica> <!-- copy -->
<host>ch5.nauu.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>ch6.nauu.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_simple>
<!-- 1 A shard 1 Copies -->
<sharding_simple_1>
<shard>
<replica>
<host>ch5.nauu.com</host>
<port>9000</port>
</replica>
<replica>
<host>ch6.nauu.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_simple_1>
<!-- 2 A shard 1 Copies -->
<sharding_ha>
<shard>
<replica>
<host>ch5.nauu.com</host>
<port>9000</port>
</replica>
<replica>
<host>ch6.nauu.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>ch7.nauu.com</host>
<port>9000</port>
</replica>
<replica>
<host>ch8.nauu.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_ha>
10.4.2 Cluster based distributed DDL
By default ,CREATE、DROP、RENAME and ALTER etc. DDL Statement does not support distributed execution .
After joining the cluster configuration , You can use the new grammar Implement distributed DDL Yes :
CREATE/DROP/RENAME/ALTER TABLE ON CLUSTER cluster_name
cluster_name Corresponds to the cluster name in the configuration file , You can query through the system table :
SELECT cluster, host_name FROM system.clusters-- Create a table to illustrate :
-- ClickHouse According to the cluster shard_2 Configuration information , Respectively in CH5 and CH6 Nodes are created locally test_1_local.
CREATE TABLE test_1_local ON CLUSTER shard_2(
id UInt64
-- Any other table engine can be used here ,
-- use {shard} and {replica} Two dynamic macro variables replace hard coding .
)ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_1', '{replica}')
ORDER BY id
-- Delete :
DROP TABLE test_1_local ON CLUSTER shard_2
-- Execute the following statement to query the system table , Be able to see the present ClickHouse Macro variables that already exist in the node :
--ch5 node
SELECT * FROM system.macros
┌─macro───┬─substitution─┐
│ replica │ ch5.nauu.com │
│ shard │ 01 │
└───────┴─────────┘
--ch6 node
SELECT * FROM remote('ch6.nauu.com:9000', 'system', 'macros', 'default')
┌─macro───┬─substitution─┐
│ replica │ ch6.nauu.com │
│ shard │ 02 │
└───────┴─────────┘
Macro variables are pre-defined in the configuration files of each node in the form of configuration files :
<macros>
<shard>01</shard>
<replica>ch5.nauu.com</replica>
</macros>
<macros>
<shard>02</shard>
<replica>ch6.nauu.com</replica>
</macros>1. data structure
1)ZooKeeper Node structure in
By default , Distributed DDL stay ZooKeeper The root path used in is :/clickhouse/task_queue/ddl
The path is made by config.xml Internal distributed_ddl Configuration assignment :
<distributed_ddl>
<!-- Path in ZooKeeper to queue with DDL queries -->
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>Under this root path , There are other listening nodes , These include /query- [seq], It is DDL The operation log , Every time you execute distributed DDL Inquire about , An operation log will be added under this node , To record the corresponding operation instructions . When each node listens to the addition of a new log , Will respond to execution .DDL The operation log uses ZooKeeper Persistent sequential nodes , The name of each instruction is in query- The prefix , The subsequent sequence number is incremented , for example query0000000000、query-0000000001 etc. .
Every one of them query-[seq] Under the operation log , also There are two state nodes :
- /query-[seq]/active: Used for condition monitoring and other purposes , During the execution of the task , Under this node, the current status in the cluster will be temporarily saved as active The node of .
- /query-[seq]/finished: Used to check the completion of tasks , During the execution of the task , Whenever a host After the node is executed , Records will be written under this node . For example, the following statement .
/query-000000001/finished ch5.nauu.com:9000 : 0 ch6.nauu.com:9000 : 0Indicates CH5 and CH6 Two nodes have completed the task .
2)DDLLogEntry Data structure of log object
stay /query-[seq] The log information recorded below is provided by DDLLogEntry bearing , Core content :
- query Recorded DDL The execution statement of the query
query: DROP TABLE default.test_1_local ON CLUSTER shard_2 - hosts Records the of the specified cluster hosts Host list , The cluster consists of distributed DDL Statement ON CLUSTER Appoint
hosts: ['ch5.nauu.com:9000','ch6.nauu.com:9000'] - initiator Record initialization host The name of the host
initiator: ch5.nauu.com:9000 hosts The value source of the host list is the same as : -- from initiator Node query cluster Information SELECT host_name FROM remote('ch5.nauu.com:9000', 'system', 'clusters', 'default') WHERE cluster = 'shard_2'
2. Distributed DDL The core execution process of
Explain distributed DDL The core execution process of .

(1) push DDL journal
First, in the CH5 Node execution CREATE TABLE ON CLUSTER, In line with the principle of who implements who is responsible , In this case, there will be CH5 The node is responsible for creating DDLLogEntry Log and push the log to ZooKeeper, At the same time, this node will also be responsible for monitoring the implementation progress of tasks .
(2) Pull log and execute
CH5 and CH6 The two nodes listen separately /ddl/query0000000064 Log push , So they pull logs locally . First , They will judge their own host Whether it is included in DDLLog-Entry Of hosts In the list .
If included , Then enter the execution process , Write the status to finished node ; If not , Then ignore this log push .
(3) Confirm the implementation progress
Steps in 1 perform DDL After statement , The client will block waiting 180 second , To expect all host completion of enforcement . If the waiting time is greater than 180 second , Then it will go to the background thread and continue to wait ( Waiting time by distributed_ddl_task_timeout Parameter assignment , The default is 180 second ).
10.5 Distributed Principle analysis
No data stored by itself , But as a transparent proxy for data fragmentation , It can automatically route data to each node in the cluster , therefore Distributed The table engine needs to work with other data table engines .
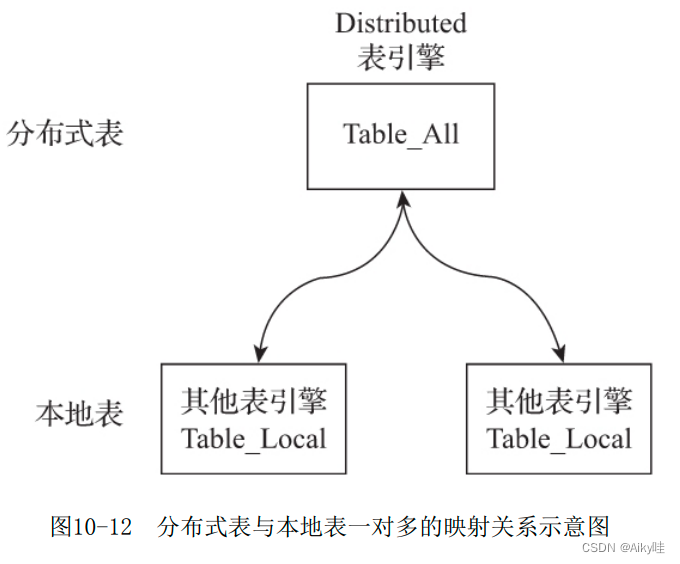
From the entity table level , A slice table consists of two parts :
- Local table : Usually, the _local Name the suffix . Local table is the carrier of data , You can use non Distributed Any table engine , A local table corresponds to a data fragment .
- Distributed table : Usually, the _all Name the suffix . Only distributed tables can be used Distributed Watch engine , It forms a one to many mapping relationship with the local table , In the future, multiple local tables will be operated through distributed table agents .
Consistency is not checked when creating tables ,Distributed The table engine adopts the mechanism of read-time checking , This means that if their table structures are incompatible , only An error will be thrown when querying .
10.5.1 Definition form
Distributed The definition form of the table engine is as follows :
ENGINE = Distributed(cluster, database, table [,sharding_key])- cluster: Cluster name , Corresponds to the custom name in the cluster configuration . In the process of writing and querying distributed tables , It will use the configuration information of the cluster to find the corresponding host node .
- database and table: Corresponding to the names of database and table respectively , Distributed tables use this set of configurations to map to local tables .
- sharding_key: Patch key , Optional parameters . During data writing , Distributed tables will be based on the rules of sharding keys , Distribute the data to various areas host The local table of the node .
-- In clusters sharding_simple Create a distributed table
-- according to rand() The value of the random function determines which partition the data is written into .
CREATE TABLE test_shard_2_all ON CLUSTER sharding_simple (
id UInt64
)ENGINE = Distributed(sharding_simple, default, test_shard_2_local,rand())
-- In clusters sharding_simple Create local table
CREATE TABLE test_shard_2_local ON CLUSTER sharding_simple (
id UInt64
)ENGINE = MergeTree()
ORDER BY id
PARTITION BY id

10.5.2 Classification of queries
Distributed Table query operations can be divided into :
- Queries that will act on local tables : about INSERT and SELECT Inquire about , Distributed It will act on local Local table . The specific execution logic of these queries , It will be introduced in the following sections .
- Will only affect Distributed Oneself , Queries that do not work on local tables : Distributed Support some metadata operations , Include CREATE、DROP、RENAME and ALTER, among ALTER It does not include partition operations (ATTACH PARTITION、REPLACE PARTITION etc. ). These queries will only be modified Distributed Table itself , It doesn't change local Local table .( To completely delete a distributed table , You need to delete the distributed Tables and local tables )
-- Delete distributed tables DROP TABLE test_shard_2_all ON CLUSTER sharding_simple -- Delete local table DROP TABLE test_shard_2_local ON CLUSTER sharding_simple Unsupported query :Distributed Table does not support any MUTATION Type of operation , Include ALTER DELETE and ALTER UPDATE.
10.5.3 Fragmentation rule
Fragment key requires to return an integer value , Include Int Series and UInt series .
-- According to the user id Remainder division of
Distributed(cluster, database, table ,userid)
-- Divide according to random numbers
Distributed(cluster, database, table ,rand())
-- According to the user id Hash value partition of
Distributed(cluster, database, table , intHash64(userid))
-- If you do not declare the fragment key , Then the distributed table can only contain one fragment , This means that only one local table can be mapped , otherwise ,
When writing data, you will get the following exception :
Method write is not supported by storage Distributed with more than one shard and no sharding key provided
How the data is divided ?
1. Slice weight (weight)
Cluster configuration , There is one weight( Slice weight ) Set up :
<sharding_simple><!-- Custom cluster name -->
<shard><!-- Fragmentation -->
<weight>10</weight><!-- Slice weight -->
……
</shard>
<shard>
<weight>20</weight>
……
</shard>
…
weight The default is 1, Although it can be set to any integer , But the official suggestion should be set to a smaller value as far as possible . The slice weight will affect the inclination of the data in the slice , The larger the weight value of a slice is , Then the more data it will be written .
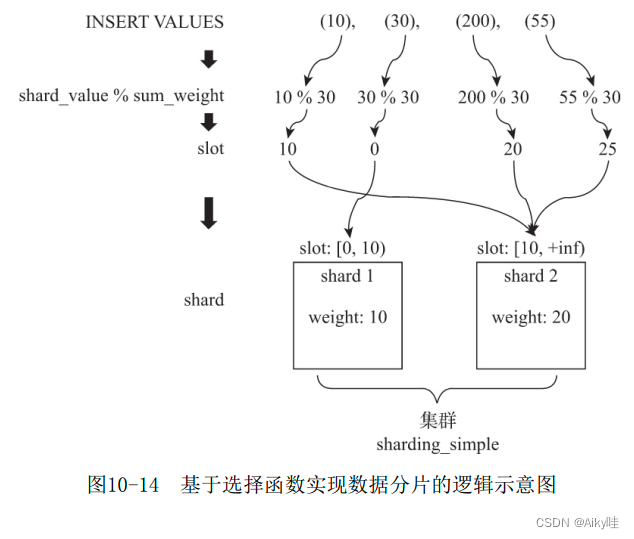
2.slot( Slot )
slot The number of is equal to the sum of the weights of all slices .
Suppose the cluster sharding_simple There are two Shard branch slice , The first piece weight by 10, The second piece weight by 20, that slot The quantity of is equal to 30.
slot According to the value range of weight elements , Form a mapping relationship with the corresponding partition . In this example , If slot The value falls on [0,10) Section , Then it corresponds to the first partition ; If slot The value falls on [10,20] Section , Then it corresponds to the second partition .
3. Selection function
The number is used to determine which partition a row of data to be written should be written into .
The steps are :
- find slot The value of ,slot = shard_value % sum_weight.shard_value Is the value of the slice key ;sum_weight Is the sum of the weights of all the tiles ;slot be equal to shard_value and sum_weight The remainder of . Suppose a row of data shard_value yes 10,sum_weight yes 30( Two pieces , The weight of the first partition is 10, The weight of the second partition is 20), that slot The value is equal to 10(10%30=10).
- be based on slot Value to find the corresponding data fragment . When slot The value is equal to 10 When , It belongs to [10,20) Section , So this line of data will correspond to the second Shard Fragmentation .
10.5.4 The core process of distributed writing
Two ways of thinking :
- Write data directly to ClickHouse Each local table of the cluster , Better write performance 【 It's also ck Officially recommended method 】
- adopt Distributed The table engine agent writes fragment data .( Emphasis on the )
1. The core process of writing data into slices
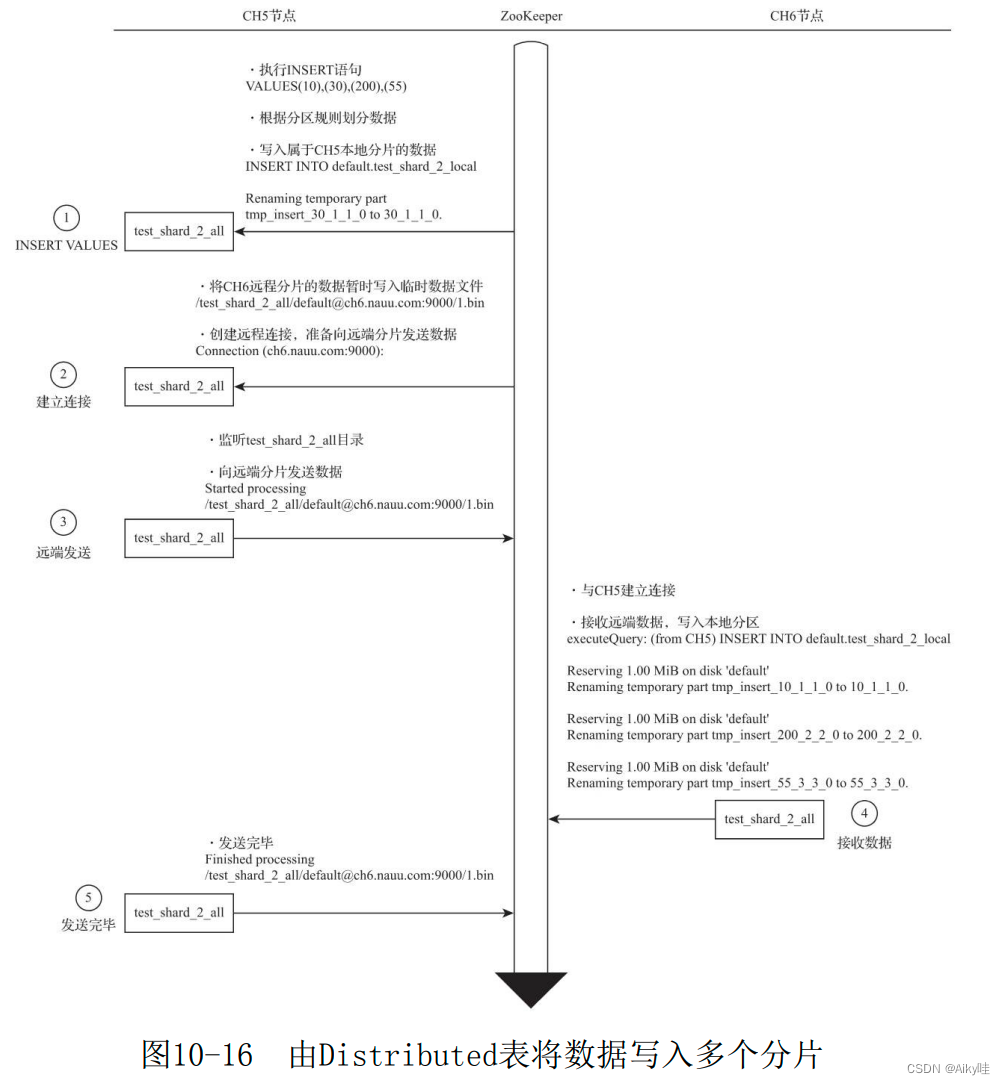
1) Write local partition data in the first partition node
stay CH5 node , For distributed tables test_shard_2_all perform INSERT Inquire about , write in 10、30、200 and 55 Four lines of data .
Distributed tables divide data according to fragmentation rules ,30 To slice 1;10,200,55 To slice 2.
The data belonging to the current partition is directly written to the local table test_shard_2_local.
2) The first partition establishes a remote connection , Prepare to send remote partition data
The data to be classified into remote partitions is divided into partitions , Write separately test_shard_2_all Store the temporary under the directory bin file .
The naming rules of data files are as follows :
/[email protected]:port/[increase_num].bin
In the example is :/test_shard_2_all/[email protected]:9000/1.bin
10、200 and 55 Three lines of data will be written into the above temporary data file .
Then start trying to communicate with the far end CH6 Establish connection in pieces .
3) The first partition sends data to the remote partition
Listen to the /test_shard_2_all The files in the directory change , Start sending data .
Each directory will be sent by an independent thread , Data will be compressed before transmission .
4) The second slice receives data and writes it locally
CH6 Confirm the establishment and CH5 The connection of , Receive from CH5 After sending the data , Write them to the local table
5) The first slice confirms the completion of writing
from CH5 Slice and confirm that all data is sent .
thus , The whole process is over .
Distributed Table is responsible for writing all slices . In line with the principle of who implements who is responsible , In this example , from CH5 The distributed table of nodes is responsible for data segmentation , And send data to all other sharding nodes .
Distributed When the table is responsible for sending data to the remote partition , There are two modes of asynchronous write and synchronous write :
- Asynchronous writing , It's in Distributed After the table is written and divided locally ,INSERT The query will return the information written successfully ;
- Write synchronously , It's executing INSERT After the query , Will wait for all points Chip finish writing .
insert_distributed_sync Parameter control , The default is false, Asynchronous write .
2. The core process of copying data
Data is between multiple copies , There are two ways to implement replication :
- One is to continue to use Distributed Watch engine , It writes the data to the copy ;
- The other is with the help of ReplicatedMergeTree The table engine realizes the distribution of copy data .
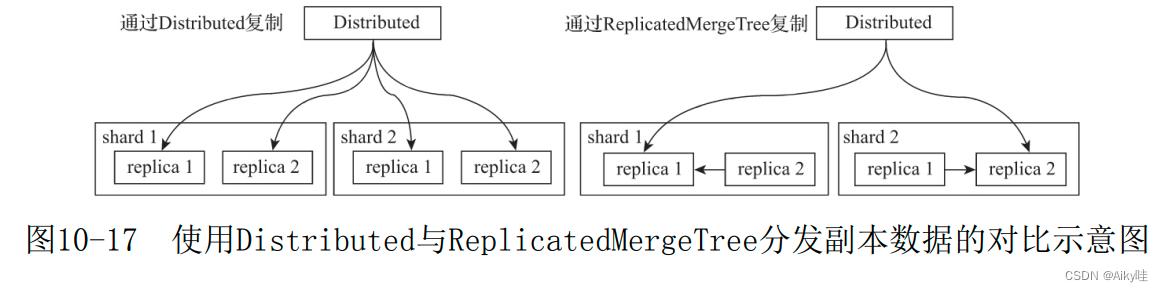
1) adopt Distributed Copy the data
Distributed I will be responsible for the data writing of shards and replicas at the same time , The writing process of replica data is the same as the slicing logic .
In this implementation scheme ,Distributed The node needs to be responsible for the data writing of shards and replicas at the same time , It is likely to become a single point bottleneck for writing .
2) adopt ReplicatedMergeTree Copy the data
In the cluster shard Add... To the configuration internal_replication Parameter and set it to true( The default is false), that Distributed The table is in this shard Will only choose a suitable replica And write data to it .
At this point, multiple replica Data replication between replicas will be handed over to ReplicatedMergeTree Do it yourself .
stay shard Choose from replica The algorithm is roughly as follows :
- stay ClickHouse In the service node of , Have a global counter errors_count, When there is any exception in the service , This count adds cumulatively 1;
- next , When one shard There are multiple replica when , choice errors_count The one with the least mistakes .
10.5.5 The core process of distributed query
The cluster can only query data through Distributed Table engine implementation .
Distributed The table will query the data of each partition in turn , Then merge and summarize to return .
1. Routing rules for multiple copies
If one of the clusters shard, Has more than replica,Distributed The table will use the load balancing algorithm from many replica Choose one of them . What kind of load balancing algorithm is used , be from load_balancing Parameter control :
load_balancing = random/nearest_hostname/in_order/first_or_random1)random
The default load balancing algorithm ,random The algorithm will choose errors_count The number of errors is the most Less replica, If more than one replica Of errors_count The count is the same , Then choose one of them at random .
2)nearest_hostname
random Variations of the algorithm , Will choose errors_count The one with the least number of errors replica, If more than one replica Of errors_count The count is the same , Then select cluster configuration host Name and current host The most similar one .
The rule is based on the current host The name is used as the benchmark to compare byte by byte , Find the one with the least number of different bytes .
3)in_order
random Variations of the algorithm , Will choose errors_count The one with the least number of errors replica, If more than one replica Of errors_count The count is the same , In the cluster configuration replica Select one by one in the order of definition .
4)first_or_random
do in_order Variations of the algorithm , First, it will choose errors_count The one with the least number of errors replica, If more than one replica Of errors_count The count is the same , It will first select the first one defined in the cluster configuration replica, If it's time to replica Unavailable , Then choose another one at random replica.
2. The core process of multi slice query
In line with the principle of who implements who is responsible , It will be received by SELECT Of the query Distributed surface , And be responsible for connecting the whole process .
-- Query distributed tables :
SELECT * FROM distributed_table
--sql After conversion, it is sent to the remote partition node :
SELECT * FROM local_table Distributed The table engine will convert the query plan into multiple shards UNION The joint query .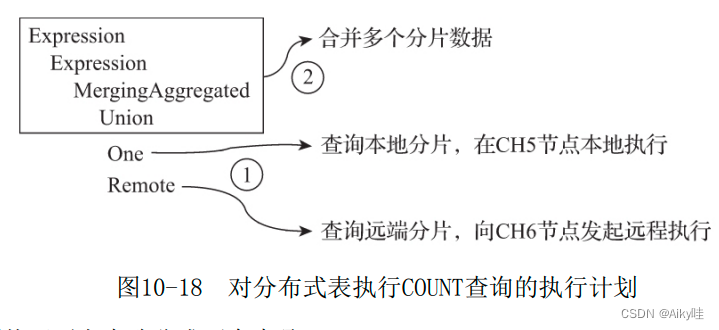
1) Query the fragment data
In the figure 10-18 In the execution plan shown ,One and Remote The steps are executed in parallel . Responsible for local and remote partition query respectively action .
2) Merge return results
After multiple fragment data are queried and returned , Data consolidation .
3. Use Global Optimize distributed subqueries
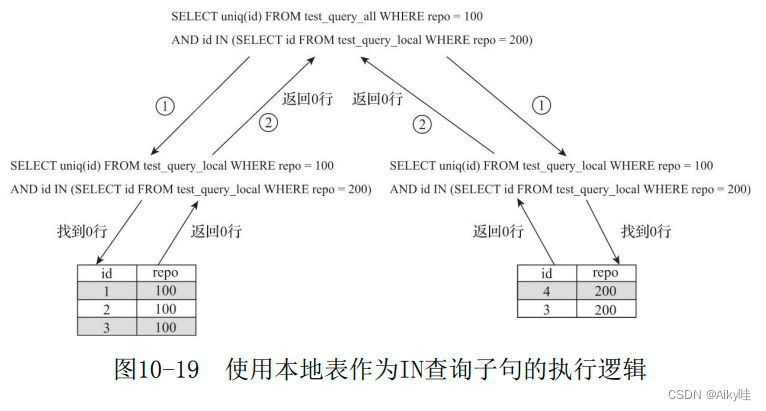
1) The problem of using local tables
-- consider in Use local tables in :
SELECT uniq(id) FROM test_query_all WHERE repo = 100
AND id IN (SELECT id FROM test_query_local WHERE repo = 200)
-- ck Will SQL Replace with the form of local table , Then send it to each partition for execution .
-- Be careful IN The clauses of the query use local tables :
SELECT uniq(id) FROM test_query_local WHERE repo = 100
AND id IN (SELECT id FROM test_query_local WHERE repo = 200)
Because only part of the data is saved on a single slice , So the SQL The statement result is problematic .
2) The problem of using distributed tables
-- Try to IN Use distributed tables in query clauses :
SELECT uniq(id) FROM test_query_all WHERE repo = 100
AND id IN (SELECT id FROM test_query_all WHERE repo = 200)Although the result is correct , But because of in Distributed tables are also used in , Launch remote query to other partitions again , At this time, the query will be enlarged .

3) Use GLOBAL Optimized query
Use GLOBAL IN or JOIN To optimize .
SELECT uniq(id) FROM test_query_all WHERE repo = 100
AND id GLOBAL IN (SELECT id FROM test_query_all WHERE repo = 200)The whole process is roughly divided into 5 A step :
- take IN Clause proposed separately , Launched a distributed query .
- Transfer the distributed table to local After the local table , Execute the query locally and remotely .
- take IN Clause to summarize the results of the query , And put a temporary memory table to save .
- Send the memory table to the remote partition node .
- After converting a distributed table to a local table , Start executing the complete SQL sentence ,IN Clause directly uses the data of the temporary memory table .
Avoid the problem of query amplification .
【 But memory table data will cause network overhead ,IN perhaps JOIN The data returned by clause should not be too large .】

10.6 Summary of this chapter
Introduced the copy 、 The usage of sharding and clustering and the core workflow .
ReplicatedMergeTree Table engine and Distributed The core functions and workflow of the table engine .
The next chapter will introduce and ClickHouse Manage the content related to operation and maintenance .
边栏推荐
- 剑指 Offer II 041. 滑动窗口的平均值
- Coordinate conversion of one-dimensional array and two-dimensional matrix (storage of matrix)
- common commands
- 软件测试笔试题你会吗?
- 用户之声 | 对于GBase 8a数据库学习的感悟
- Plot function drawing of MATLAB
- What kind of MES system is a good system
- 滑环在直驱电机转子的应用领域
- 由排行榜实时更新想到的数状数值
- Introduction to natural language processing (NLP) based on transformers
猜你喜欢
pb9.0 insert ole control 错误的修复工具

Sword finger offer II 041 Average value of sliding window

滑环使用如何固定

Why does the updated DNS record not take effect?

微信小程序uniapp页面无法跳转:“navigateTo:fail can not navigateTo a tabbar page“

ANSI / NEMA- MW- 1000-2020 磁铁线标准。. 最新原版
Nacos microservice gateway component +swagger2 interface generation

从Starfish OS持续对SFO的通缩消耗,长远看SFO的价值

第七章 行为级建模
break net
随机推荐
ClickHouse原理解析与应用实践》读书笔记(8)
Kafka connect synchronizes Kafka data to MySQL
Cross modal semantic association alignment retrieval - image text matching
Remote Sensing投稿經驗分享
生态 | 湖仓一体的优选:GBase 8a MPP + XEOS
日志特征选择汇总(基于天池比赛)
剑指 Offer II 041. 滑动窗口的平均值
Partage d'expériences de contribution à distance
微软 AD 超基础入门
Apache多个组件漏洞公开(CVE-2022-32533/CVE-2022-33980/CVE-2021-37839)
用户之声 | 对于GBase 8a数据库学习的感悟
regular expression
Graphic network: uncover the principle behind TCP's four waves, combined with the example of boyfriend and girlfriend breaking up, which is easy to understand
Tencent game client development interview (unity + cocos) double bombing social recruitment 6 rounds of interviews
Uniapp one click Copy function effect demo (finishing)
Version 2.0 de tapdata, Open Source Live Data Platform est maintenant disponible
图解网络:揭开TCP四次挥手背后的原理,结合男女朋友分手的例子,通俗易懂
ArrayList源码深度剖析,从最基本的扩容原理,到魔幻的迭代器和fast-fail机制,你想要的这都有!!!
如果时间是条河
2、TD+Learning