当前位置:网站首页>Convert widerperson dataset to Yolo format
Convert widerperson dataset to Yolo format
2022-07-07 02:41:00 【-Brick adding Java】
- First according to train.txt and val.txt The content in , Put all the training set pictures and comments on train Under the folder , The same is true of validation sets .
import os
from pathlib import Path
from PIL import Image
import csv
import shutil
# coding=utf-8
def check_charset(file_path):
import chardet
with open(file_path, "rb") as f:
data = f.read(4)
charset = chardet.detect(data)['encoding']
return charset
def convert(size, box0, box1, box2, box3):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box0 + box2) / 2 * dw
y = (box1 + box3) / 2 * dh
w = (box2 - box0) * dw
h = (box3 - box1) * dh
return (x, y, w, h)
if __name__ == '__main__':
path = 'F:\dataset\WiderPerson/train.txt'
with open(path, 'r') as f:
img_ids = [x for x in f.read().splitlines()]
for img_id in img_ids: # '000040'
img_path = 'F:\dataset\WiderPerson\Images/' + img_id + '.jpg'
with Image.open(img_path) as Img:
img_size = Img.size
ans = ''
label_path = img_path.replace('Images', 'Annotations') + '.txt'
outpath = 'train/' + img_id + '.txt'
with open(label_path, encoding=check_charset(label_path)) as file:
line = file.readline()
count = int(line.split('\n')[0]) # Number of pedestrians inside
line = file.readline()
while line:
cls = int(line.split(' ')[0])
if cls == 1 or cls == 2 or cls == 3:
xmin = float(line.split(' ')[1])
ymin = float(line.split(' ')[2])
xmax = float(line.split(' ')[3])
ymax = float(line.split(' ')[4].split('\n')[0])
print(img_size[0], img_size[1], xmin, ymin, xmax, ymax)
bb = convert(img_size, xmin, ymin, xmax, ymax)
ans = ans + '1' + ' ' + ' '.join(str(a) for a in bb) + '\n'
line = file.readline()
with open(outpath, 'w') as outfile:
outfile.write(ans)
shutil.copy(img_path, 'train/' + img_id + '.jpg')
- Separate the picture from the notes , Put them in their respective folders
import shutil
import os
if __name__ == '__main__':
label_path=r"train/"
imgids = os.listdir(label_path)
print(len(imgids))
n=0
for i in imgids:
n += 1
img_ids_path = label_path.replace('labels', 'images')+ i[0:6] +'.txt'
To_imgpath=r'train\anno/'
print(img_ids_path,To_imgpath,n)
shutil.copy(img_ids_path, To_imgpath)
OK!!!
Reference blog :https://blog.csdn.net/qq_44224801/article/details/123480032
Reference blog :https://blog.csdn.net/wukong168/article/details/122697243
边栏推荐
- 安德鲁斯—-多媒体编程
- Fundamentals of process management
- C # / vb. Net supprime le filigrane d'un document word
- Why am I warned that the 'CMAKE_ TOOLCHAIN_ FILE' variable is not used by the project?
- Linear list --- circular linked list
- [leetcode]Search for a Range
- MES管理系统的应用和好处有哪些
- Detailed explanation of line segment tree (including tested code implementation)
- [paper reading | deep reading] graphsage:inductive representation learning on large graphs
- [C # notes] reading and writing of the contents of text files
猜你喜欢
KYSL 海康摄像头 8247 h9 isapi测试
![[paper reading | deep reading] anrl: attributed network representation learning via deep neural networks](/img/06/17acf9958228cce5d80ada3275ad24.png)
[paper reading | deep reading] anrl: attributed network representation learning via deep neural networks
![[unity notes] screen coordinates to ugui coordinates](/img/e4/fc18dd9b4b0e36ec3e278e5fb3fd23.jpg)
[unity notes] screen coordinates to ugui coordinates

Argo workflows source code analysis

The third season of ape table school is about to launch, opening a new vision for developers under the wave of going to sea

本周 火火火火 的开源项目!
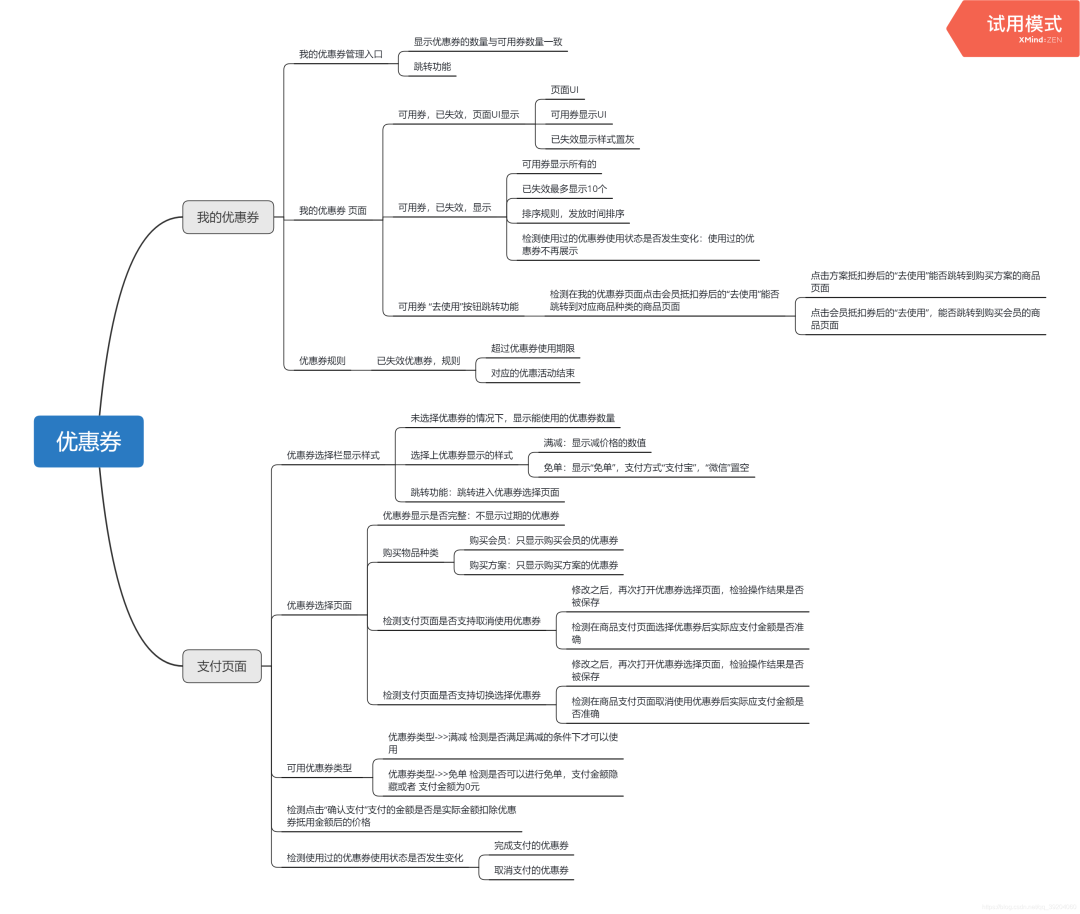
测试优惠券要怎么写测试用例?

Station B's June ranking list - feigua data up main growth ranking list (BiliBili platform) is released!
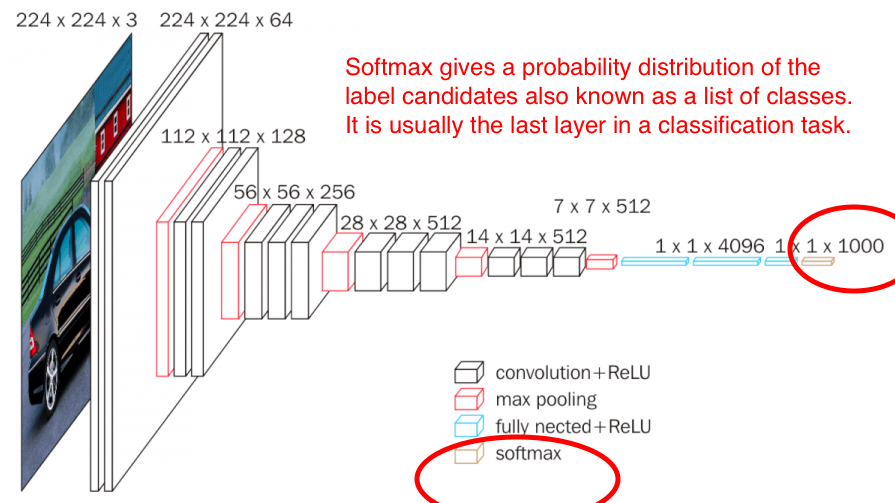
Classify the features of pictures with full connection +softmax
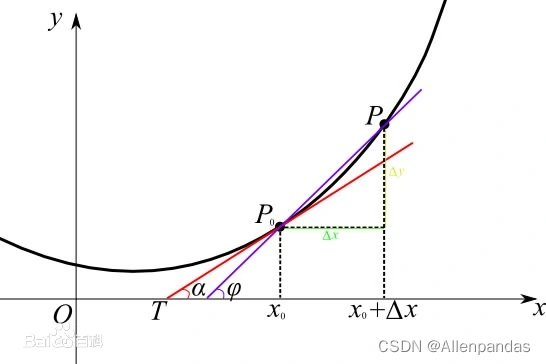
导数、偏导数、方向导数
随机推荐
The so-called consumer Internet only matches and connects industry information, and does not change the industry itself
MySQL - common functions - string functions
3--新唐nuc980 kernel支持jffs2, Jffs2文件系统制作, 内核挂载jffs2, uboot网口设置,uboot支持tftp
Hash table and full comments
[server data recovery] data recovery case of a Dell server crash caused by raid damage
QT常见概念-1
[C # notes] use file stream to copy files
Cloud Mail .NET Edition
Web3's need for law
unity 自定义webgl打包模板
[paper reading | deep reading] graphsage:inductive representation learning on large graphs
Huitong programming introductory course - 2A breakthrough
STM32项目 -- 选题分享(部分)
1 -- Xintang nuc980 nuc980 porting uboot, starting from external mx25l
MySQL
安全交付工程师
Detailed explanation of line segment tree (including tested code implementation)
fiddler的使用
QPushButton-》函数精解
Web3对法律的需求