当前位置:网站首页>postgresql之integerset
postgresql之integerset
2022-07-06 18:39:00 【happytree001】
一、简介
1.1 integerset是什么
正如其名,integer set, 整数集合。这里是指存储整数的数据结构。对于数学中集合的定义,集合中的元素是没有重复的。
integerset特点:
能存储64bit整数
内存数据结构,内存操作速度快
使用B-tree结构组织数据,插入、搜索 复杂度O(log2)
使用Simple-8b算法压缩数据,使存储空间更小,还能使用SIMD等指令来加速
1.2 能用来干什么
- 能存储最大64bit的任意正整数
- 快速检索某个整数是否在集合中
1.3 有什么限制
- 插入的值必须是有序的
- 在遍历集合的时候不能插入值
- 不支持删除值
- 不支持负数
1.4 对比redis的intset
| 数据结构 | 可存储最大值 | 组织形式 | 搜索方式 | 存储方式 | 支持负数 | 插入顺序 |
|---|---|---|---|---|---|---|
| integerset | unsigned 64bit | B-tree | 遍历树+折半搜索 | simple-8b编码 | No | 必须有序 |
| intset | signed 64bit | 数组 | 折半搜索 | 直接存值 | Yes | 任意,自动排序 |
1.5 对比redis的listpack变长编码
| 数据结构 | 数值编码方式 | 编码形式 | 编码长度影响因素 |
|---|---|---|---|
| integerset | simple-8b编码 | 批量编码 | 多个连续数值之间的差值大小 |
| listpack | 变长字节编码 | 单数值编码 | 单个数值本身大小 |
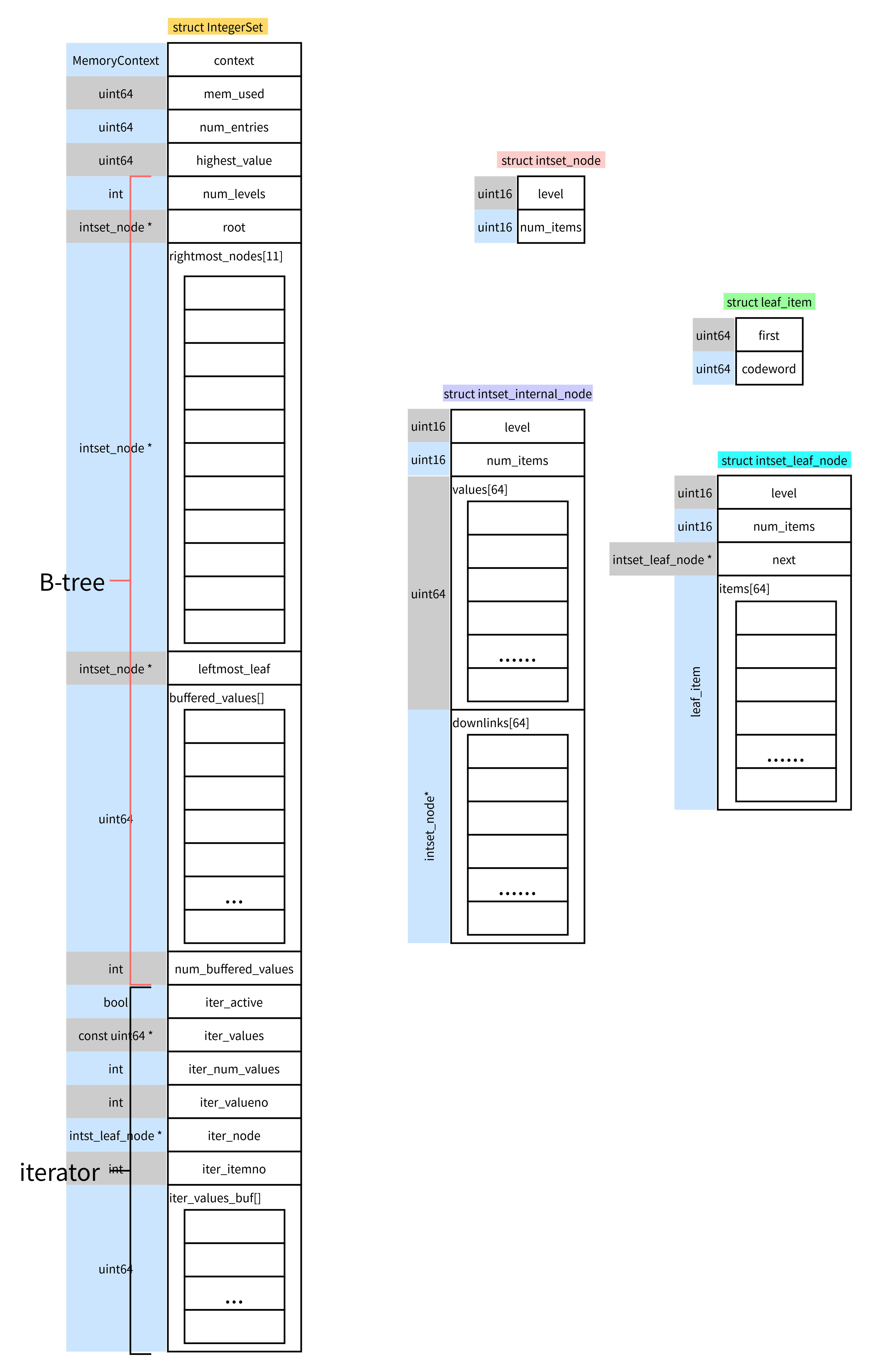
二、 数据结构
2.1 数据结构定义
typedef struct intset_node intset_node;
typedef struct intset_leaf_node intset_leaf_node;
typedef struct intset_internal_node intset_internal_node;
/* Common structure of both leaf and internal nodes. */
struct intset_node
{
uint16 level; /* tree level of this node */
uint16 num_items; /* number of items in this node */
};
/* Internal node */
struct intset_internal_node
{
/* common header, must match intset_node */
uint16 level; /* >= 1 on internal nodes */
uint16 num_items;
/* * 'values' is an array of key values, and 'downlinks' are pointers to * lower-level nodes, corresponding to the key values. */
uint64 values[MAX_INTERNAL_ITEMS];
intset_node *downlinks[MAX_INTERNAL_ITEMS];
};
/* Leaf node */
typedef struct
{
uint64 first; /* first integer in this item */
uint64 codeword; /* simple8b encoded differences from 'first' */
} leaf_item;
#define MAX_VALUES_PER_LEAF_ITEM (1 + SIMPLE8B_MAX_VALUES_PER_CODEWORD)
struct intset_leaf_node
{
/* common header, must match intset_node */
uint16 level; /* 0 on leafs */
uint16 num_items;
intset_leaf_node *next; /* right sibling, if any */
leaf_item items[MAX_LEAF_ITEMS];
};
/* * We buffer insertions in a simple array, before packing and inserting them * into the B-tree. MAX_BUFFERED_VALUES sets the size of the buffer. The * encoder assumes that it is large enough that we can always fill a leaf * item with buffered new items. In other words, MAX_BUFFERED_VALUES must be * larger than MAX_VALUES_PER_LEAF_ITEM. For efficiency, make it much larger. */
#define MAX_BUFFERED_VALUES (MAX_VALUES_PER_LEAF_ITEM * 2)
/* * IntegerSet is the top-level object representing the set. * * The integers are stored in an in-memory B-tree structure, plus an array * for newly-added integers. IntegerSet also tracks information about memory * usage, as well as the current position when iterating the set with * intset_begin_iterate / intset_iterate_next. */
struct IntegerSet
{
/* * 'context' is the memory context holding this integer set and all its * tree nodes. * * 'mem_used' tracks the amount of memory used. We don't do anything with * it in integerset.c itself, but the callers can ask for it with * intset_memory_usage(). */
MemoryContext context;
uint64 mem_used;
uint64 num_entries; /* total # of values in the set */
uint64 highest_value; /* highest value stored in this set */
/* * B-tree to hold the packed values. * * 'rightmost_nodes' hold pointers to the rightmost node on each level. * rightmost_parent[0] is rightmost leaf, rightmost_parent[1] is its * parent, and so forth, all the way up to the root. These are needed when * adding new values. (Currently, we require that new values are added at * the end.) */
int num_levels; /* height of the tree */
intset_node *root; /* root node */
intset_node *rightmost_nodes[MAX_TREE_LEVELS];
intset_leaf_node *leftmost_leaf; /* leftmost leaf node */
/* * Holding area for new items that haven't been inserted to the tree yet. */
uint64 buffered_values[MAX_BUFFERED_VALUES];
int num_buffered_values;
/* * Iterator support. * * 'iter_values' is an array of integers ready to be returned to the * caller; 'iter_num_values' is the length of that array, and * 'iter_valueno' is the next index. 'iter_node' and 'iter_itemno' point * to the leaf node, and item within the leaf node, to get the next batch * of values from. * * Normally, 'iter_values' points to 'iter_values_buf', which holds items * decoded from a leaf item. But after we have scanned the whole B-tree, * we iterate through all the unbuffered values, too, by pointing * iter_values to 'buffered_values'. */
bool iter_active; /* is iteration in progress? */
const uint64 *iter_values;
int iter_num_values; /* number of elements in 'iter_values' */
int iter_valueno; /* next index into 'iter_values' */
intset_leaf_node *iter_node; /* current leaf node */
int iter_itemno; /* next item in 'iter_node' to decode */
uint64 iter_values_buf[MAX_VALUES_PER_LEAF_ITEM];
};
其中 intset_node可以看作是基类,其他继承它。
class intset_node {
};
class intset_internal_node : intset_node {
};
class intset_leaf_node : intset_node {
};
2.2 结构图
三、 相关API
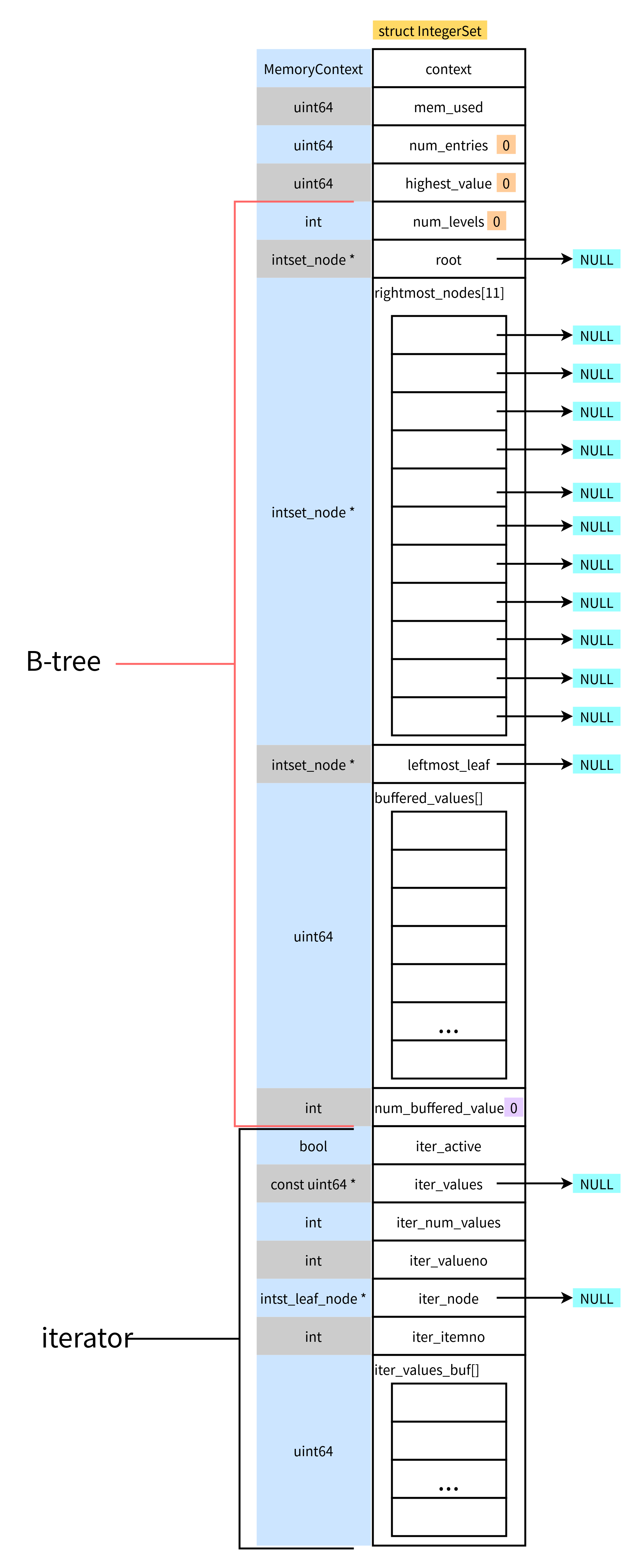
3.1 创建integerset
/* * Create a new, initially empty, integer set. * * The integer set is created in the current memory context. * We will do all subsequent allocations in the same context, too, regardless * of which memory context is current when new integers are added to the set. */
IntegerSet *
intset_create(void)
{
IntegerSet *intset;
intset = (IntegerSet *) palloc(sizeof(IntegerSet));
intset->context = CurrentMemoryContext;
intset->mem_used = GetMemoryChunkSpace(intset);
intset->num_entries = 0;
intset->highest_value = 0;
intset->num_levels = 0;
intset->root = NULL;
memset(intset->rightmost_nodes, 0, sizeof(intset->rightmost_nodes));
intset->leftmost_leaf = NULL;
intset->num_buffered_values = 0;
intset->iter_active = false;
intset->iter_node = NULL;
intset->iter_itemno = 0;
intset->iter_valueno = 0;
intset->iter_num_values = 0;
intset->iter_values = NULL;
return intset;
}
3.2 插入元素
/* * Add a value to the set. * * Values must be added in order. */
void
intset_add_member(IntegerSet *intset, uint64 x)
{
if (intset->iter_active)
elog(ERROR, "cannot add new values to integer set while iteration is in progress");
if (x <= intset->highest_value && intset->num_entries > 0)
elog(ERROR, "cannot add value to integer set out of order");
if (intset->num_buffered_values >= MAX_BUFFERED_VALUES)
{
/* Time to flush our buffer */
intset_flush_buffered_values(intset);
Assert(intset->num_buffered_values < MAX_BUFFERED_VALUES);
}
/* Add it to the buffer of newly-added values */
intset->buffered_values[intset->num_buffered_values] = x;
intset->num_buffered_values++;
intset->num_entries++;
intset->highest_value = x;
}
- 首先会加入到缓存区中
- 等缓冲区满后,再插入B树中
(1) 为啥先插入缓冲区,而不是直接插入B-tree
simple-8b编码方式决定的
B-tree中叶子节点中存储的是通过simple-8b编码后的值, 而不是原始值。
(2) 什么是simple-8b编码
simple-8b, 其中b是byte, 使用8字节编码,每次编码后的结果都是8字节。
8byte, 64bit, 其中开始4bit用于选择使用编码模式,不同的编码模式,决定了后面的60bit的如何分配来存储数据。
static const struct simple8b_mode
{
uint8 bits_per_int;
uint8 num_ints;
} simple8b_modes[17] =
{
{
0, 240}, /* mode 0: 240 zeroes */
{
0, 120}, /* mode 1: 120 zeroes */
{
1, 60}, /* mode 2: sixty 1-bit integers */
{
2, 30}, /* mode 3: thirty 2-bit integers */
{
3, 20}, /* mode 4: twenty 3-bit integers */
{
4, 15}, /* mode 5: fifteen 4-bit integers */
{
5, 12}, /* mode 6: twelve 5-bit integers */
{
6, 10}, /* mode 7: ten 6-bit integers */
{
7, 8}, /* mode 8: eight 7-bit integers (four bits * are wasted) */
{
8, 7}, /* mode 9: seven 8-bit integers (four bits * are wasted) */
{
10, 6}, /* mode 10: six 10-bit integers */
{
12, 5}, /* mode 11: five 12-bit integers */
{
15, 4}, /* mode 12: four 15-bit integers */
{
20, 3}, /* mode 13: three 20-bit integers */
{
30, 2}, /* mode 14: two 30-bit integers */
{
60, 1}, /* mode 15: one 60-bit integer */
{
0, 0} /* sentinel value */
};
根据编码模式可以看出,数值越小,能编码的个数就越多,越节省空间。
那如何将需要编码的数值变小呢
对相邻两数差值进行编码,因此数据集越集中,差值越小,能编码的个数越多
只存储差值,如何恢复原始值呢?
为了能恢复原始值,因此编码分为两部分
- 基数base
- 后续数据差值编码
typedef struct
{
uint64 first; // base
uint64 codeword; //编码结果
} leaf_item;
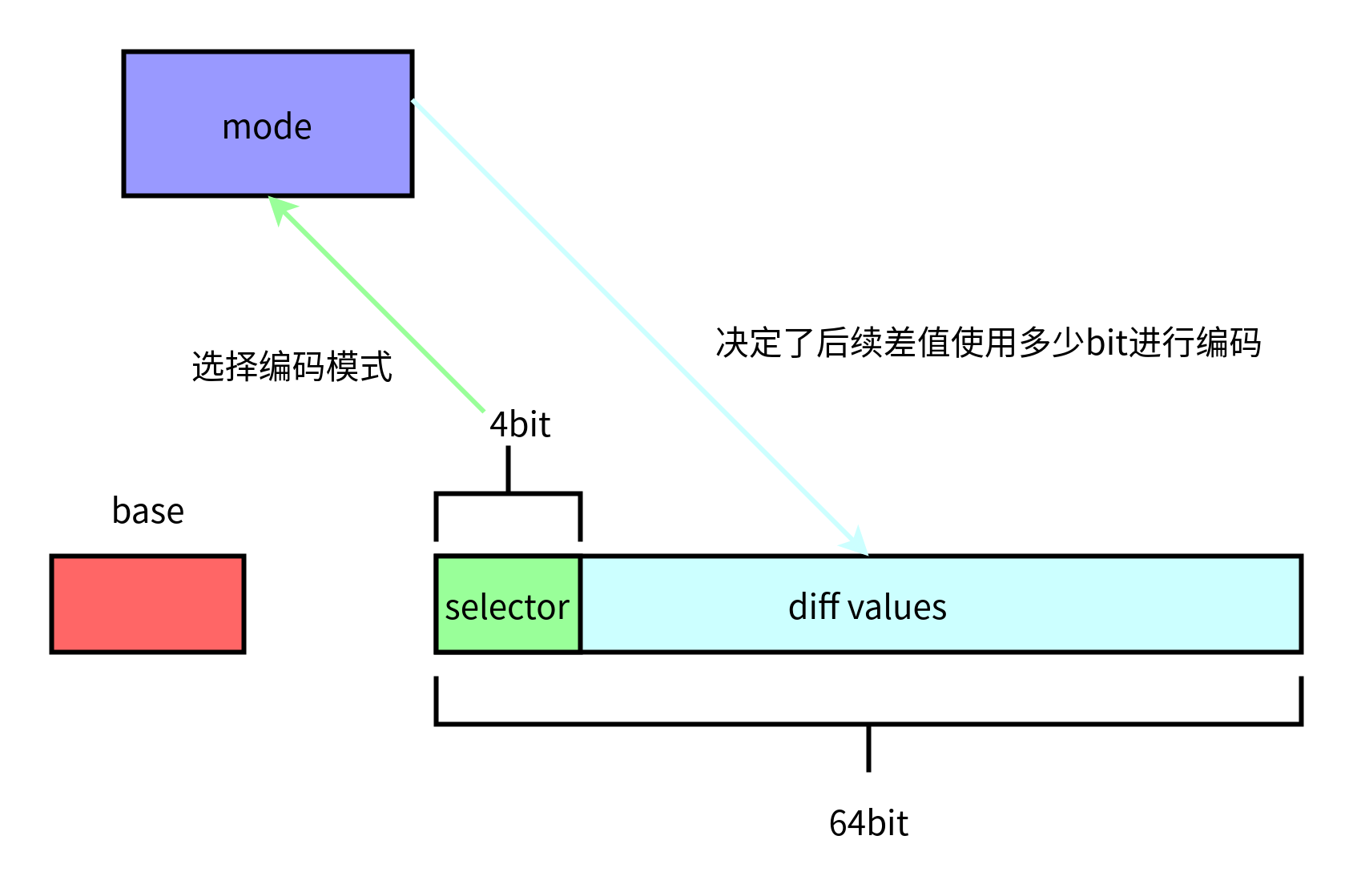
比如使用mode10, 则每个数值使用10bit,总共可以编码6个数值
1010 xxxxxxxxxx xxxxxxxxxx xxxxxxxxxx xxxxxxxxxx xxxxxxxxxx xxxxxxxxxx
只有60 bit用来编码数据,那大于60bit的数值如何编码的呢?
对于大于60bit的数值,将数据存入base, 编码8byte就写UINT64CONST(0x0FFFFFFFFFFFFFFF),编码数据长度0,相当于浪费了8byte。
a. simple-8b编码实现
/* * EMPTY_CODEWORD is a special value, used to indicate "no values". * It is used if the next value is too large to be encoded with Simple-8b. * * This value looks like a mode-0 codeword, but we can distinguish it * because a regular mode-0 codeword would have zeroes in the unused bits. */
#define EMPTY_CODEWORD UINT64CONST(0x0FFFFFFFFFFFFFFF)
/* * Encode a number of integers into a Simple-8b codeword. * * (What we actually encode are deltas between successive integers. * "base" is the value before ints[0].) * * The input array must contain at least SIMPLE8B_MAX_VALUES_PER_CODEWORD * elements, ensuring that we can produce a full codeword. * * Returns the encoded codeword, and sets *num_encoded to the number of * input integers that were encoded. That can be zero, if the first delta * is too large to be encoded. */
static uint64
simple8b_encode(const uint64 *ints, int *num_encoded, uint64 base)
{
int selector;
int nints;
int bits;
uint64 diff;
uint64 last_val;
uint64 codeword;
int i;
Assert(ints[0] > base);
/* * Select the "mode" to use for this codeword. * * In each iteration, check if the next value can be represented in the * current mode we're considering. If it's too large, then step up the * mode to a wider one, and repeat. If it fits, move on to the next * integer. Repeat until the codeword is full, given the current mode. * * Note that we don't have any way to represent unused slots in the * codeword, so we require each codeword to be "full". It is always * possible to produce a full codeword unless the very first delta is too * large to be encoded. For example, if the first delta is small but the * second is too large to be encoded, we'll end up using the last "mode", * which has nints == 1. */
selector = 0;
nints = simple8b_modes[0].num_ints;
bits = simple8b_modes[0].bits_per_int;
diff = ints[0] - base - 1;
last_val = ints[0];
i = 0; /* number of deltas we have accepted */
for (;;)
{
if (diff >= (UINT64CONST(1) << bits))
{
/* too large, step up to next mode */
selector++;
nints = simple8b_modes[selector].num_ints;
bits = simple8b_modes[selector].bits_per_int;
/* we might already have accepted enough deltas for this mode */
if (i >= nints)
break;
}
else
{
/* accept this delta; then done if codeword is full */
i++;
if (i >= nints)
break;
/* examine next delta */
Assert(ints[i] > last_val);
diff = ints[i] - last_val - 1;
last_val = ints[i];
}
}
if (nints == 0)
{
/* * The first delta is too large to be encoded with Simple-8b. * * If there is at least one not-too-large integer in the input, we * will encode it using mode 15 (or a more compact mode). Hence, we * can only get here if the *first* delta is >= 2^60. */
Assert(i == 0);
*num_encoded = 0;
return EMPTY_CODEWORD;
}
/* * Encode the integers using the selected mode. Note that we shift them * into the codeword in reverse order, so that they will come out in the * correct order in the decoder. */
codeword = 0;
if (bits > 0)
{
for (i = nints - 1; i > 0; i--)
{
diff = ints[i] - ints[i - 1] - 1;
codeword |= diff;
codeword <<= bits;
}
diff = ints[0] - base - 1;
codeword |= diff;
}
/* add selector to the codeword, and return */
codeword |= (uint64) selector << 60;
*num_encoded = nints;
return codeword;
}
b. simple-8b解码实现
将8byte的编码数据,恢复到一个数组中。
/* * Decode a codeword into an array of integers. * Returns the number of integers decoded. */
static int
simple8b_decode(uint64 codeword, uint64 *decoded, uint64 base)
{
int selector = (codeword >> 60);
int nints = simple8b_modes[selector].num_ints;
int bits = simple8b_modes[selector].bits_per_int;
uint64 mask = (UINT64CONST(1) << bits) - 1;
uint64 curr_value;
if (codeword == EMPTY_CODEWORD)
return 0;
curr_value = base;
for (int i = 0; i < nints; i++)
{
uint64 diff = codeword & mask;
curr_value += 1 + diff;
decoded[i] = curr_value;
codeword >>= bits;
}
return nints;
}
(3) 比如插入1-600
- 首先是插入缓冲区
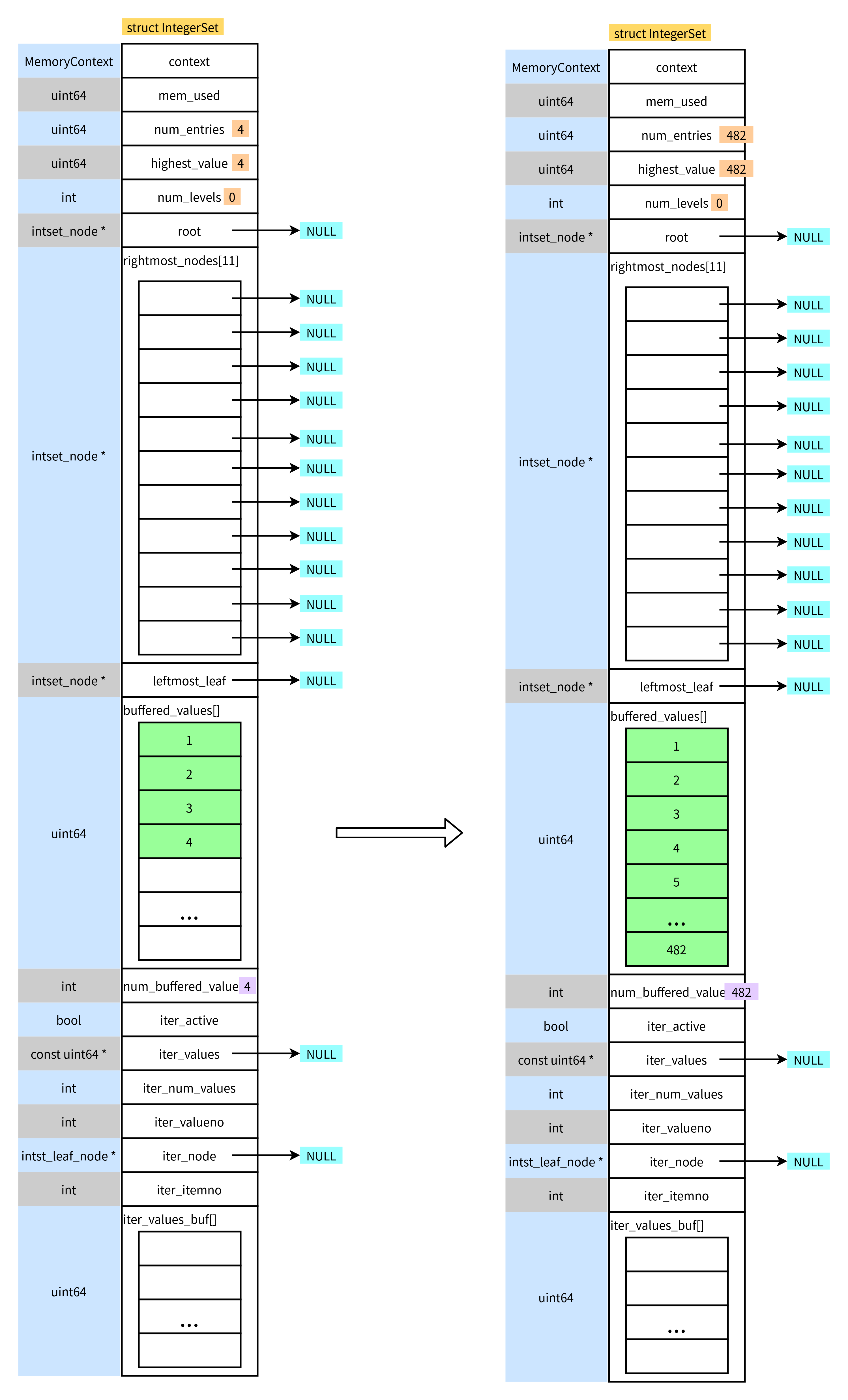
- 当缓冲区写满后,将进行编码以及插入B-tree
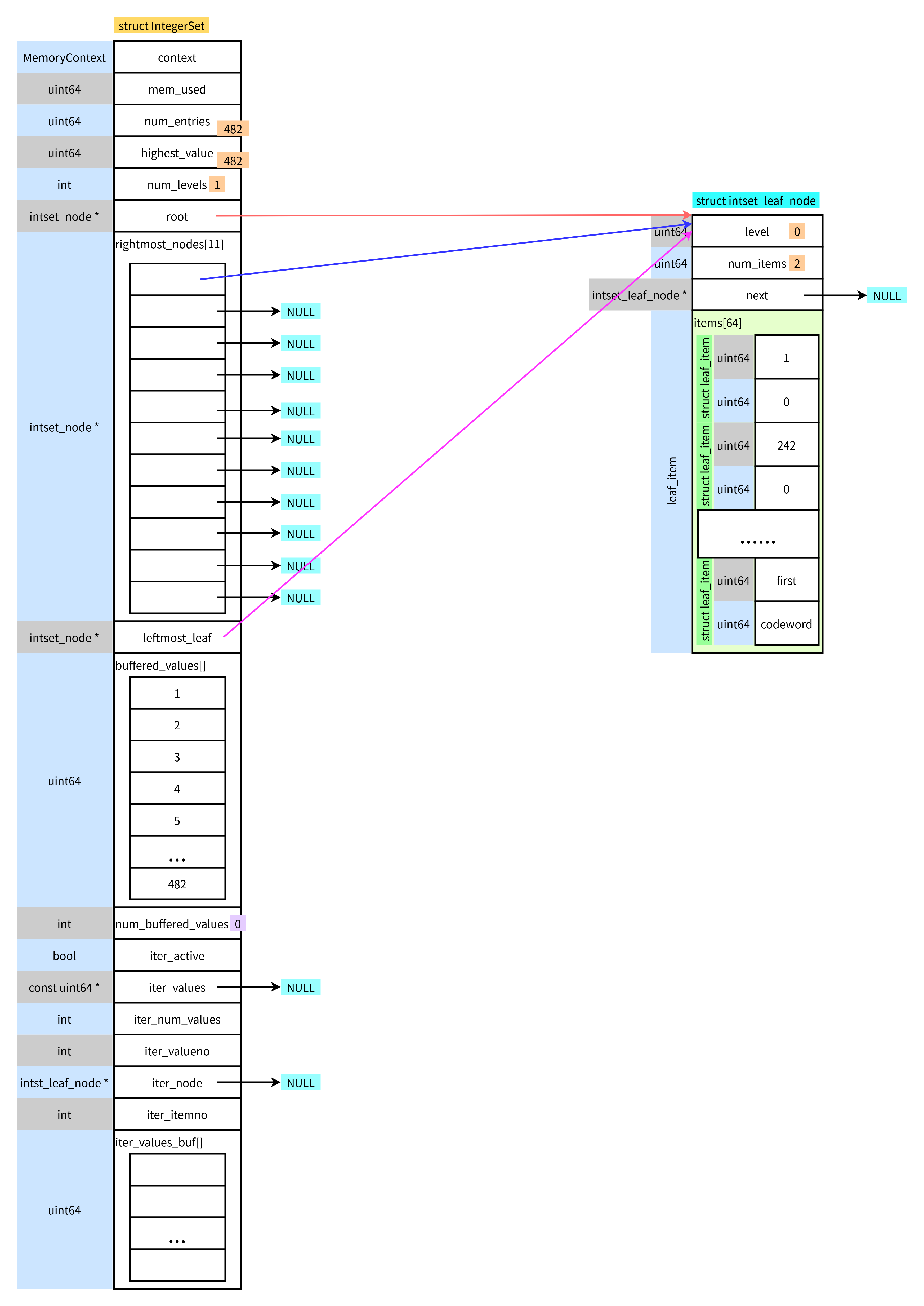
- 剩余数据继续插入缓冲区
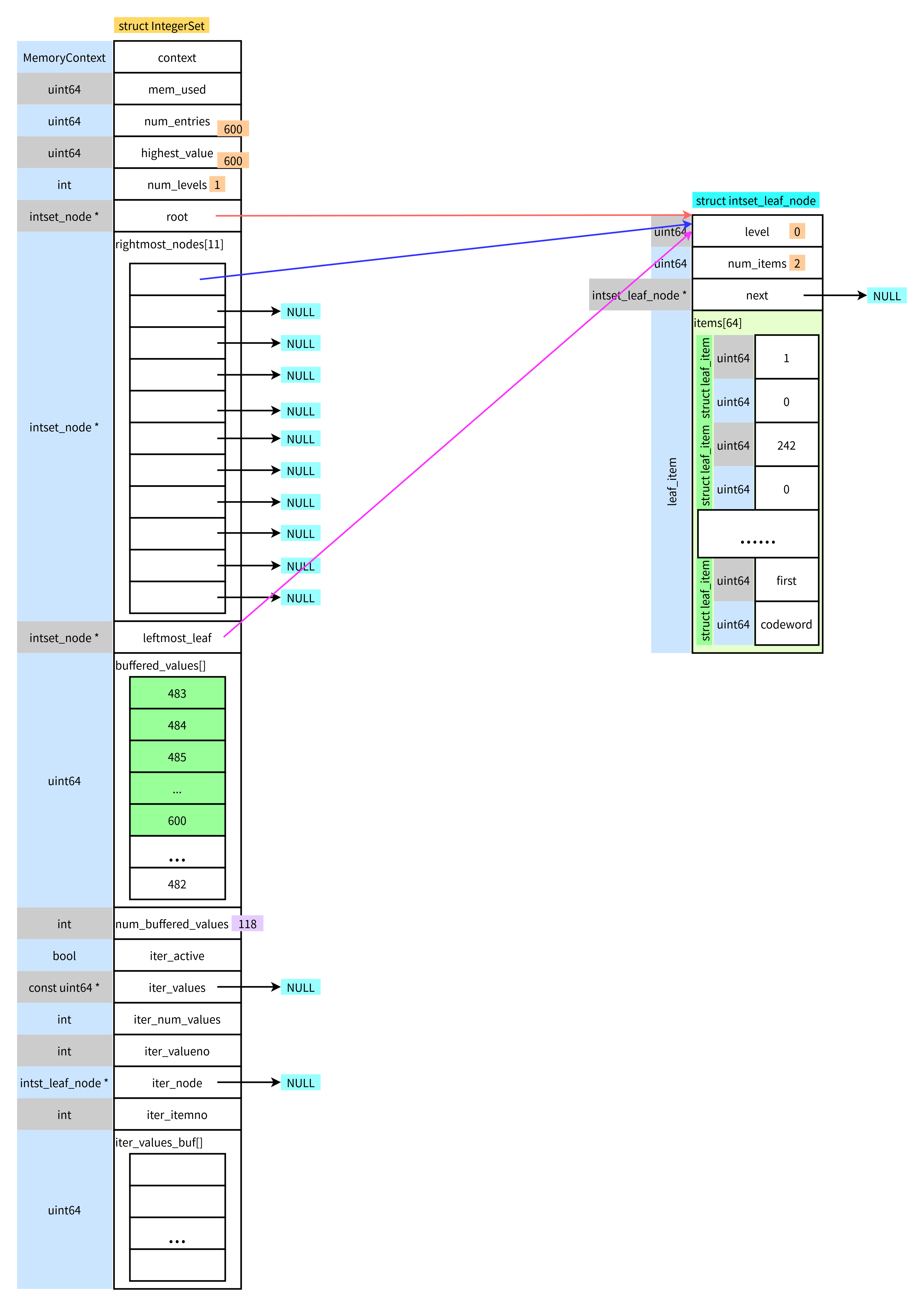
每次编码结束后,如果缓冲区中还有剩余的数据,将会拷贝到缓冲区开头
我尝试将这个缓冲区改造成一个循环队列,这样就不用进行数据的拷贝了。但是对于一些使用缓冲区 的地方都要加求余操作,看起来就没有原来的代码更清晰简单,而且随着队列的使用,将会将数组分成两个部分,两个部分依然有序,还是使用折半搜索,一次尝试还是不错的,调试,当能正常工作后,还是挺高兴的
3.2 判断某个值是否在integerset中
- 首先判断是否在缓冲区中,缓冲区是有序递增的,所以使用折半搜索
- 判断值在哪个节点范围内,因为B-tree特性,也使用折半搜索
- 最后在simple-8b编码数据中搜索, simple8b_contains函数和simple8b_decode类似
/* * Does the set contain the given value? */
bool
intset_is_member(IntegerSet *intset, uint64 x)
{
intset_node *node;
intset_leaf_node *leaf;
int level;
int itemno;
leaf_item *item;
/* * The value might be in the buffer of newly-added values. */
if (intset->num_buffered_values > 0 && x >= intset->buffered_values[0])
{
int itemno;
itemno = intset_binsrch_uint64(x,
intset->buffered_values,
intset->num_buffered_values,
false);
if (itemno >= intset->num_buffered_values)
return false;
else
return (intset->buffered_values[itemno] == x);
}
/* * Start from the root, and walk down the B-tree to find the right leaf * node. */
if (!intset->root)
return false;
node = intset->root;
for (level = intset->num_levels - 1; level > 0; level--)
{
intset_internal_node *n = (intset_internal_node *) node;
Assert(node->level == level);
itemno = intset_binsrch_uint64(x, n->values, n->num_items, true);
if (itemno == 0)
return false;
node = n->downlinks[itemno - 1];
}
Assert(node->level == 0);
leaf = (intset_leaf_node *) node;
/* * Binary search to find the right item on the leaf page */
itemno = intset_binsrch_leaf(x, leaf->items, leaf->num_items, true);
if (itemno == 0)
return false;
item = &leaf->items[itemno - 1];
/* Is this a match to the first value on the item? */
if (item->first == x)
return true;
Assert(x > item->first);
/* Is it in the packed codeword? */
if (simple8b_contains(item->codeword, x, item->first))
return true;
return false;
}
3.3 遍历整个integerset
/* * Begin in-order scan through all the values. * * While the iteration is in-progress, you cannot add new values to the set. */
void
intset_begin_iterate(IntegerSet *intset)
{
/* Note that we allow an iteration to be abandoned midway */
intset->iter_active = true;
intset->iter_node = intset->leftmost_leaf;
intset->iter_itemno = 0;
intset->iter_valueno = 0;
intset->iter_num_values = 0;
intset->iter_values = intset->iter_values_buf;
}
/* * Returns the next integer, when iterating. * * intset_begin_iterate() must be called first. intset_iterate_next() returns * the next value in the set. Returns true, if there was another value, and * stores the value in *next. Otherwise, returns false. */
bool
intset_iterate_next(IntegerSet *intset, uint64 *next)
{
Assert(intset->iter_active);
for (;;)
{
/* Return next iter_values[] entry if any */
if (intset->iter_valueno < intset->iter_num_values)
{
*next = intset->iter_values[intset->iter_valueno++];
return true;
}
/* Decode next item in current leaf node, if any */
if (intset->iter_node &&
intset->iter_itemno < intset->iter_node->num_items)
{
leaf_item *item;
int num_decoded;
item = &intset->iter_node->items[intset->iter_itemno++];
intset->iter_values_buf[0] = item->first;
num_decoded = simple8b_decode(item->codeword,
&intset->iter_values_buf[1],
item->first);
intset->iter_num_values = num_decoded + 1;
intset->iter_valueno = 0;
continue;
}
/* No more items on this leaf, step to next node */
if (intset->iter_node)
{
intset->iter_node = intset->iter_node->next;
intset->iter_itemno = 0;
continue;
}
/* * We have reached the end of the B-tree. But we might still have * some integers in the buffer of newly-added values. */
if (intset->iter_values == (const uint64 *) intset->iter_values_buf)
{
intset->iter_values = intset->buffered_values;
intset->iter_num_values = intset->num_buffered_values;
intset->iter_valueno = 0;
continue;
}
break;
}
/* No more results. */
intset->iter_active = false;
*next = 0; /* prevent uninitialized-variable warnings */
return false;
}
从最左边的叶子节点开始遍历,叶子节点通过next指针连接成了一个链表,逐一遍历
每个叶子节点中有多个item, 逐一遍历item
每个item又是经过simple-8b编码的数据,通过解码,将数据写入临时缓冲区中
每次都从临时缓冲区中返回一个数据
当遍历完所有节点后,进行遍历缓冲区
四、总结
integerset是一个正整数集合,最大值为64bit
使用B-tree结构进行管理数据
使用simple-8b编码数据,进行压缩
插入顺序必须有序
不支持删除数据
数据压缩率依赖数据之间的差距
迭代遍历过程中不能插入数据,未实现
搜索过程都使用了折半搜索
批量编码数据
待把B-tree学习清楚后,可以尝试实现非有序方式插入
边栏推荐
- The empirical asset pricing package (EAP) can be installed through pypi
- 2022 system integration project management engineer examination knowledge point: Mobile Internet
- New generation cloud native message queue (I)
- Introduction to microservice architecture
- 微服务架构介绍
- 【论文阅读|深读】ANRL: Attributed Network Representation Learning via Deep Neural Networks
- @Before, @after, @around, @afterreturning execution sequence
- How did partydao turn a tweet into a $200million product Dao in one year
- 将截断字符串或二进制数据
- Robot team learning method to achieve 8.8 times human return
猜你喜欢

STM32F4---PWM输出

微服务架构介绍
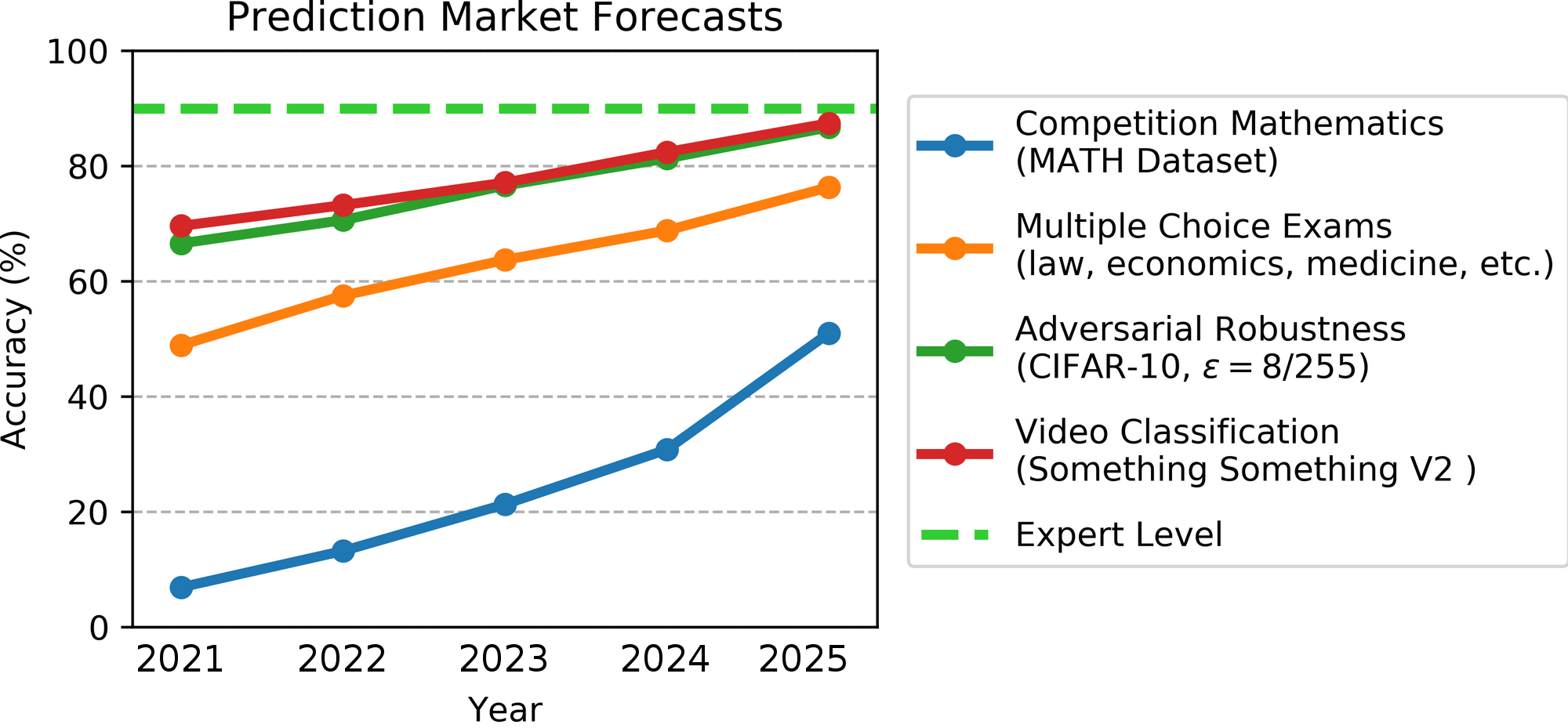
UC伯克利助理教授Jacob Steinhardt预测AI基准性能:AI在数学等领域的进展比预想要快,但鲁棒性基准性能进展较慢
ROS learning (25) rviz plugin

Introduction to FLIR blackfly s industrial camera
A new path for enterprise mid Platform Construction -- low code platform
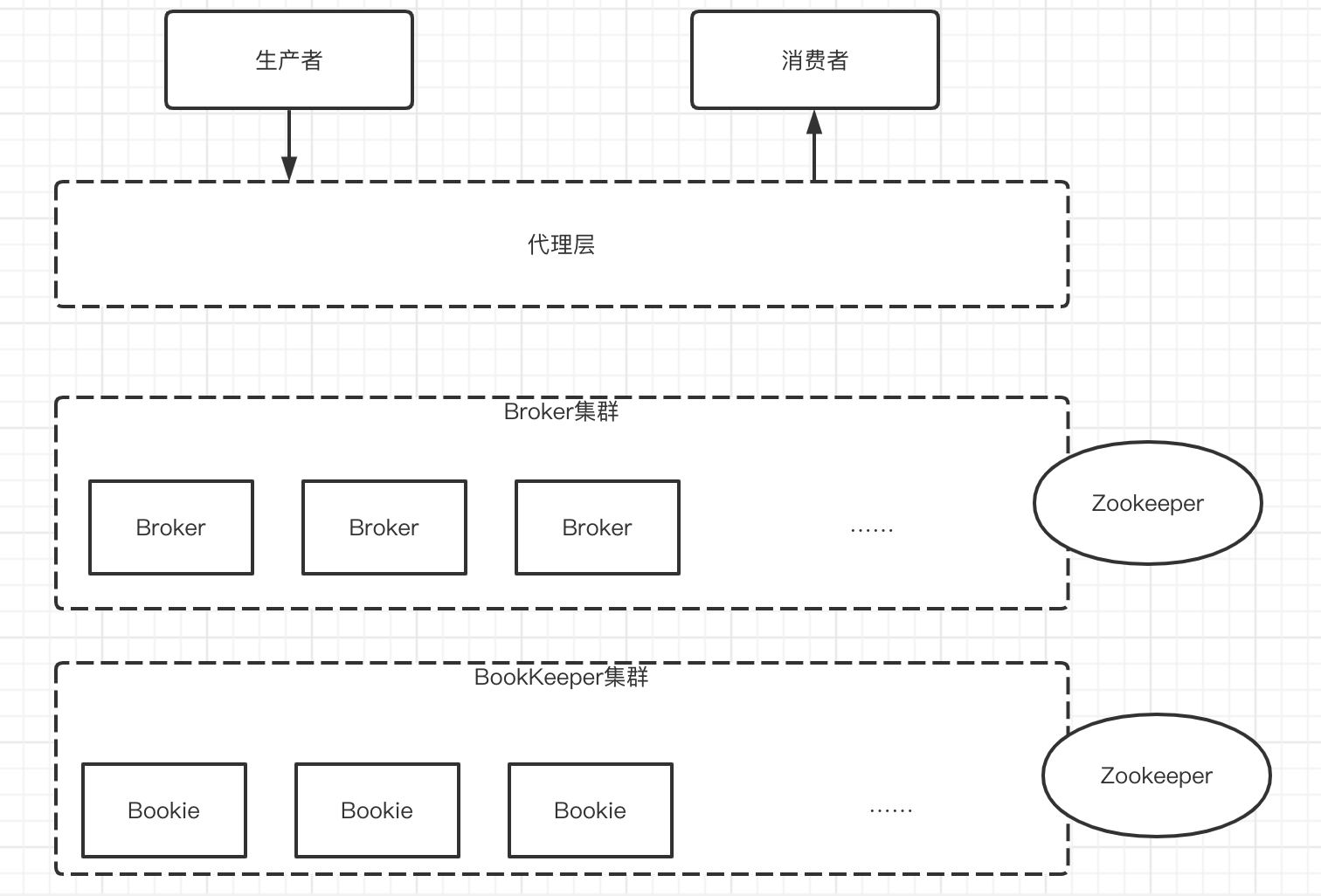
New generation cloud native message queue (I)

go swagger使用

如何从0到1构建32Core树莓派集群
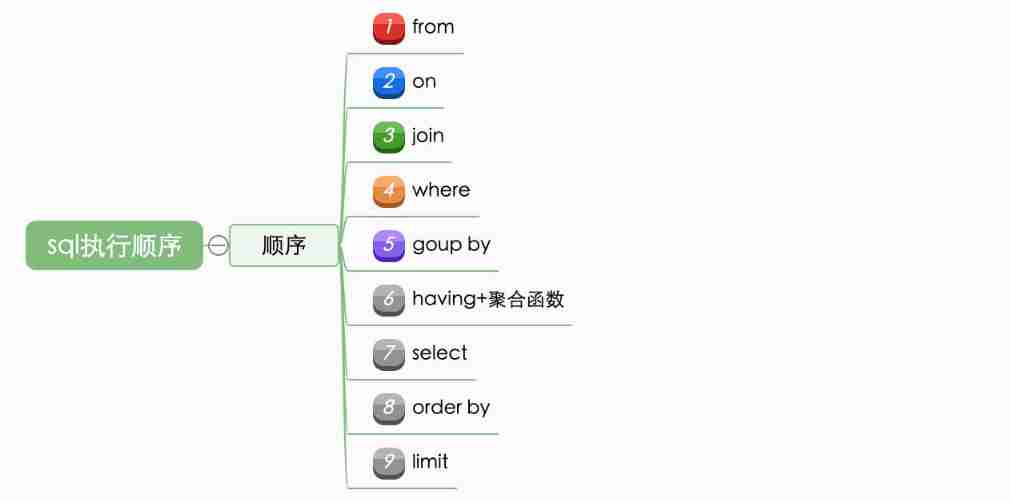
MySQL execution process and sequence
随机推荐
Introduction to microservice architecture
Cisp-pte practice explanation (II)
Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
Integrated navigation: product description and interface description of zhonghaida inav2
解密函数计算异步任务能力之「任务的状态及生命周期管理」
Cat recycling bin
Freeswitch dials extension number source code tracking
NPM install compilation times "cannot read properties of null (reading 'pickalgorithm')“
XML to map tool class xmlmaputils (tool class V)
2022/0524/bookstrap
低代码平台中的数据连接方式(上)
Several classes and functions that must be clarified when using Ceres to slam
@Before, @after, @around, @afterreturning execution sequence
豆瓣平均 9.x,分布式领域的 5 本神书!
Word wrap when flex exceeds width
张平安:加快云上数字创新,共建产业智慧生态
centos8安裝mysql報錯:The GPG keys listed for the “MySQL 8.0 Community Server“ repository are already ins
leetcode:5. 最长回文子串【dp + 抓着超时的尾巴】
Infrared camera: juge infrared mag32 product introduction
New generation cloud native message queue (I)