当前位置:网站首页>What to do when encountering slow SQL? (next)
What to do when encountering slow SQL? (next)
2022-07-07 02:17:00 【Gauss squirrel Club】
In the daily use of database , It's hard to avoid slow SQL, Encounter slow SQL It's not terrible in itself , The difficulty lies in how to identify slow SQL And optimize it , So that it will not slow down the performance of the whole system , Avoid jeopardizing the normal operation of daily business .
Last issue We talked about the reasons for indexing 、 Slow due to system configuration and resource competition SQL, Today we continue to analyze and summarize .
Catalog
The table itself contains a lot of data
SQL The sentence is poorly written
The table itself contains a lot of data
Even though openGauss For large row storage tables, the processing performance is very excellent , But the data of the table itself is still slow SQL Important reasons . Generally speaking , There are several situations :
1. The table has a large amount of data , And rarely cached , There are many tuples that cause the statement to need to be scanned ;
2. The table has a large amount of data , In the revision 、 When deleting data, you need to modify more tuples ;
3. A large amount of data is inserted into the table ;
4. There is a large amount of data that needs to be retrieved in business ;
5. Frequent data modification , As a result, there are many dead tuples in the table (dead tuple), Affect scanning performance ;
The table is slow due to the large amount of data SQL problem , Generally, we need to start with business , It is slow to optimize directly by modifying the database SQL It is difficult to achieve the goal of . therefore , Users need to analyze specific businesses , Separate hot and cold business data 、 Sub database and sub table 、 Using distributed middleware, etc . If you want to optimize at the database layer , You can increase the memory of the host , And then increase max_process_memory、shared_buffers、work_mem The size of the wait ; Use better disks ; Create indexes as appropriate ; Use table space to adjust disk layout, etc .
SQL The sentence is poorly written
from SQL Slow due to the problem of sentence writing SQL It is also relatively common , Those who write poorly are slow SQL Also commonly known as “ bad SQL”. In most cases , from “ bad SQL” There are many problems of index invalidation , In this case , Refer to the previous description for SQL Statement to rewrite , Enable it to use the index .
In addition to the slow modification SQL Enable it to use indexes , Several common 、 May optimize openGauss Of database performance SQL Override rule :
Override rule | Rewrite the condition | Rewrite the description | Example of the original query statement | Example of rewritten statement |
take 'select distinct *' to 'select *' | The queried table contains unique columns or primary keys | By confirming tuple No repetition , Get rid of distinct, So as to eliminate the duplication steps , Improve efficiency | select distinct * from bmsql_customer limit 10; | select * from bmsql_customer limit 10; |
take having The condition in the clause is placed in where clause | - | Advance the predicate expression , Can effectively reduce group Data set when | select cfg_name from bmsql_config group by cfg_name having cfg_name='1' | select cfg_name from bmsql_config where cfg_name = '1' group by cfg_name |
simplify where Predicate expression in clause | - | Some complex predicates cannot be effectively triggered openGauss Internal rewrite Logic , Cannot use index scan | select o_w_id, o_d_id, o_id, o_c_id from bmsql_oorder where o_w_id + 1> 3 | select o_w_id, o_d_id, o_id, o_c_id from bmsql_oorder where o_w_id > 2 |
take order by or group by Remove the useless columns in | group by or order by The columns involved are contained in where In the equivalent expression in Clause | Remove useless fields ,SQL More concise | select cfg_name from bmsql_config where cfg_name='2' group by cfg_name order by cfg_name, cfg_value | select cfg_name from bmsql_config where cfg_name = '2' order by cfg_value |
Get rid of where An expression that is always true in a clause | - | Remove useless fields ,SQL More concise | select * from bmsql_config where 1=1 and 2=2 limit 10 | select * from bmsql_config limit 10 |
take union Convert to union all | - | Avoid the execution cost of de duplication | select * from bmsql_config union select * from bmsql_config | select * from bmsql_config union all select * from bmsql_config |
take delete The statement is converted to truncate sentence | nothing where Clause | take DML The statement is converted to DDL sentence , Reclaim table space at one time , Faster execution | delete from bmsql_config | truncate table bmsql_config |
take where clause 'or' The connected equation is transformed into 'in' structure | - | 'in' The structure can speed up the filtration | select * from bmsql_stock where s_w_id=10 or s_w_id=1 or s_w_id=100 or s_i_id=1 or s_i_id=10 | select * from bmsql_stock where s_w_id in (1,10,100) or s_i_id in(1,10) |
take self join The query is split into two more efficient sub queries | 1) self join Inquire about . 2) where Clause contains the range query of the same column difference . for example 1<a.id-b.id<10, among a,b For two of the same table alias. | Speed up the query through equivalent predicates | select a.c_id from bmsql_customer a, bmsql_customer b where a.c_id - b.c_id <= 20 and a.c_id > b.c_id | select * from (select a.c_id from bmsql_customer as a, bmsql_customer as b where trunc((a.c_id) / 20) = trunc(b.c_id / 20) and a.c_id > b.c_id union all select a.c_id from bmsql_customer as a, bmsql_customer as b where trunc((a.c_id) / 20) = trunc(b.c_id / 20 + 1) and a.c_id - b.c_id <= 20) |
For business systems ,SQL The audit work before the statement goes online can basically cover the above scenarios , The industry also has many pairs of SQL A tool for rewriting statements , However, some rewriting rules of these tools are not equivalent rewriting in the absolute sense . and , Many rewriting conditions apply to openGauss It may not be effective , because openGauss In the database, there are also rewrite Logic .
DBMind The platform will evolve further SQL Intelligent rewriting of statements , Provide users with online interactive intelligent query rewriting capability , Expect to meet users in future releases .
summary
We have listed above that can cause slow SQL Why , Basically covered in openGauss The upper causes slow SQL For most of the reasons . however ,one-by-one Slow down manually SQL Checking is really too much work for users . so ,openGauss Of DBMind The function itself has been integrated with the slow SQL The ability to perform intelligent root cause recognition , The user can start slow in the background by running the following command SQL Root cause analysis function ( You need to deploy first Prometheus as well as expoter, So that monitoring indicators can be collected ):
gs_dbmind service start -c confpath --only-run slow_query_diagnosis
notes : Explicitly specify --only-run The parameter can start only the selected DBMind Services
Slow after being diagnosed SQL Will be stored in the metabase ( A database for storing diagnostic results ) in , The user can view... Through the following command :
gs_dbmind component slow_query_diagnosis show -c confpath --query SQL --start-time timestamps0 --end-time timestamps1
You can also use the Grafana Joint to show slow SQL Analysis results of ,DBMind It also provides a simple Grafana The configuration template , For users' reference :
https://github.com/opengauss-mirror/openGauss-server/blob/master/src/gausskernel/dbmind/tools/misc/grafana-template-slow-query-analysis.json
because openGauss In the distribution package of the official website DBMind May lag behind the code hosting platform (gitee or github) The latest code on , Compile directly openGauss It takes a lot of time . so , If users just want to simply extract the latest DBMind function , You can go through the Linux Command to implement :
git clone -b master --depth 1 https://gitee.com/opengauss/openGauss-server.git
cd openGauss-server/src/gausskernel/dbmind/
mv tools dbmind
tar zcf dbmind.tar.gz gs_dbmind dbmindThe generated dbmind.tar.gz Decompress the compressed package at the appropriate deployment location .
Of course , If the user wants to manually check the slow SQL Why , It can also be checked according to the inspection items in the attached table SQL Causes of .
Schedule : slow SQL Checklist
Check the item | Inspection method ( System tables or system views ) | Check the method |
There is lock contention during statement execution | dbe_perf.statement_history(start_time,finish_time, query)、pg_locks(pid, mode, locktype, grant)、pg_stat_activity(xact_start, query_start, query, pid) | Whether the query is blocked during statement execution . |
The proportion of dead tuples in the table exceeds the set threshold | dbe_perf.statement_history(query, dbname, schemaname) pg_stat_users_tables(relname, schemaname,n_live_tup, n_dead_tup) | n_dead_tup / n_live_tup, If the proportion exceeds the threshold, it is considered that the table is over inflated ( Default threshold :0.2). |
The number of lines scanned by the statement is large | dbe_perf.statement_history(n_tuples_fetched, n_tuples_returned, n_live_tup, n_dead_tup) | n_tuples_fetched+n_tuples_returned, If the threshold is exceeded, it is considered too large ( Default threshold :10000). |
The statement cache hit rate is low | dbe_perf.statement_history(n_blocks_fetched, n_blocks_hit) | n_block_hit / n_block_fetched, Less than the threshold is considered low ( Default threshold :0.95) |
slow SQL(delete、insert、update) There are redundant indexes in related tables | dbe_perf.statement_history(dbname, schemaname, query), pg_stat_user_indexes(schemaname, relname, indexrelname, idx_scan, idx_tup_read, idx_tup_fetch) pg_indexes(schemaname, tablename, indexname, indexdef) | SQL The relevant table meets :① Not the only index ;② (idx_scan, idx_tup_read,idx_tup_fetch)=(0,0,0);③ The index is not in the database ('pg_catalog', 'information_schema','snapshot', 'dbe_pldeveloper')schema Next . If it is satisfied, the secondary index is considered redundant , Otherwise, it is a valid index . |
There is a large amount of updated data | dbe_perf.statement_history(query, n_tuples_updated) pg_stat_user_tables(n_live_tup, n_dead_tup) | n_tuples_updated If the threshold is exceeded, it is considered that there is a large amount of updated data ( Default threshold :1000). |
There is a large amount of inserted data | dbe_perf.statement_history(query, n_tuples_inserted) pg_stat_user_tables(n_live_tup, n_dead_tup) | n_tuples_inserted If the threshold is exceeded, it is considered that there is a large amount of inserted data ( Default threshold :1000). |
Delete a large amount of data | dbe_perf.statement_history(query, n_tuples_deleted) pg_stat_user_tables(n_live_tup, n_dead_tup) | n_tuples_deleted If the threshold is exceeded, it is considered that there is a large amount of deleted data ( Default threshold :1000). |
There are many indexes in related tables | pg_stat_user_indexes(relname,schemaname, indexrelname) | If the index number in the table is greater than the threshold and the ratio of index to field number exceeds the set threshold , It is considered that there are many indexes ( Index number threshold :3, Ratio default threshold :0.6). |
Disk dropping occurs when executing a statement ( External sorting ) Behavior | dbe_perf.statement(sort_count, sort_spilled_count, sort_mem_used, hash_count, hash_spilled_count, hash_ued_mem, n_calls) | Analyze the indicators to determine whether there is hash perhaps order Resulting drop behavior , The main logic is : 1 If sort_count perhaps hash_count Not for 0,sort_mem_used perhaps hash_mem_used by 0, Then this SQL There must have been a drop ; 2 If sort_spilled_count perhaps hash_spilled_count Not for 0, Then the execution may cause the disk dropping behavior ; |
Related tables are executing during statement execution AUTOVACUUM or AUTOANALYZE operation | dbe_perf.statement_history(start_time, finish_time, query) pg_stat_user_tables(last_autovacuum, last_autoanalyze) | perform SQL period , Is happening vacuum perhaps analyze Behavior . |
database TPS more | dbe_perf.statement_history(start_time, finish_time) pg_stat_database(datname, xact_commit, xact_rolback) | Compared with normal business TPS, At present TPS Large growth , Database TPS more ;TPS Abnormal growth in the short term is considered as a business storm . |
IOWait The indicator is greater than the set threshold | System IOWait The index rises abnormally | IOWait Greater than the user set threshold ( Default threshold :10%) |
IOPS The indicator is greater than the set threshold | System IOPS Indicators are abnormal | IOPS The indicator is greater than the threshold set by the user ( Default threshold :1000). |
load average The indicator is greater than the set threshold | System load average Indicators are abnormal | load average The ratio of logical cores to the server is greater than the threshold set by the user ( Default threshold :0.6). |
CPU USAGE The indicator is greater than the set threshold | System CPU USAGE Indicators are abnormal | CPU USAGE The indicator is greater than the threshold set by the user ( Default threshold :0.6). |
IOUTILS The indicator is greater than the set threshold | System IOUTILS Indicators are abnormal | IOUTILS( Disk utilization ) Greater than the user set threshold ( Default threshold :0.5). |
IOCAPACITY The indicator is greater than the set threshold | System IO CAPACITY Indicators are abnormal | IOCAPACITY(IO throughput ) Greater than the user set threshold ( Default threshold :50MB/s). |
IODELAY The indicator is greater than the set threshold | System IO DELAY Indicators are abnormal | IO DELAY(IO Delay ) Greater than the user set threshold ( Default threshold :50ms). |
Network card packet loss rate | The packet loss rate of the system network card is abnormal | NETWORK DROP RATE Greater than the user set threshold ( Default 0 threshold :0.01). |
Network card error rate | The error rate of the system network card is abnormal | NETWORK ERROR RATE Greater than the user set threshold ( Default threshold :0.01). |
Thread pool usage is abnormal | dbe_perf.global_threadpool_status | Database thread pool usage is greater than the threshold ( Default threshold :0.95) |
The connection pool usage is abnormal | pg_settings.max_connections,pg_stat_activity | The database connection pool occupancy is greater than the threshold ( Default threshold :0.8) |
Double write latency is large | dbe_perf.wait_events | The double write delay is greater than the threshold ( Default threshold :100us) |
The table has not been updated for a long time | pg_stat_user_tables | The table has not been updated for longer than the threshold ( Default threshold :60s) |
checkpoint Low efficiency ( This rule is only for rough judgment ) | pg_stat_bgwriter | database buffers_backend And (buffers_clean+buffers_checkpoint) The proportion is less than the threshold ( Default threshold :1000) |
The primary and standby replication efficiency is low | pg_stat_replication | The main equipment write_diff、replay_diff、sent_diff Threshold exceeded ( Default threshold :500000) |
There is an exception in the execution plan seqscan operator | Implementation plan | seqscan The ratio of operator cost to total cost exceeds the threshold ( Default threshold :0.3), This feature will also determine whether the relevant index is missing . |
There is an exception in the execution plan nestloop operator | Implementation plan | nestloop The ratio of operator cost to total cost exceeds the threshold ( Default threshold :0.3) And carry out nestloop The number of result set rows for exceeds the threshold ( Default threshold :10000). |
There is an exception in the execution plan hashjoin operator | Implementation plan | hashjoin The ratio of operator cost to total cost exceeds the threshold ( Default threshold :0.3) And carry out hashjoin The result set of is less than the threshold ( Default threshold :10000). |
There is an exception in the execution plan groupagg operator | Implementation plan | groupagg The ratio of operator cost to total cost exceeds the threshold ( Default threshold :0.3) And perform groupagg The number of rows of exceeds the threshold ( Default threshold :10000). |
SQL Poor writing | SQL Text 、pg_stat_user_tables | SQL Poor writing results in poor execution performance |
SQL Execution is affected by scheduled tasks | pg_job, dbe_perf.statement_history | Scheduled task execution affects SQL Executive performance , Consider adjusting the scheduled task time , Avoid impact . |
Execution plan generation takes a long time | dbe_perf.statement_history | SQL Execution plan generation takes a long time . |
Reference material :
[1].https://www.2ndquadrant.com/en/blog/managing-freezing/
[2]. http://mysql.taobao.org/monthly/2016/06/03/
[3].https://www.2ndquadrant.com/en/blog/basics-of-tuning-checkpoints/
[4]. https://lwn.net/Articles/591723/
[5].https://dev.mysql.com/doc/refman/8.0/en/glossary.html
[6].https://github.com/opengauss-mirror/openGauss-server/tree/master/src/gausskernel/dbmind
If you think the blogger's article is good or helpful , Please pay attention to the blogger , It would be better if the three collections support ! Thank you for your support !
边栏推荐
- Tips for web development: skillfully use ThreadLocal to avoid layer by layer value transmission
- Recent applet development records
- ROS学习(22)TF变换
- How to use strings as speed templates- How to use String as Velocity Template?
- UC伯克利助理教授Jacob Steinhardt预测AI基准性能:AI在数学等领域的进展比预想要快,但鲁棒性基准性能进展较慢
- @Before, @after, @around, @afterreturning execution sequence
- A new path for enterprise mid Platform Construction -- low code platform
- Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
- The mega version model of dall-e MINI has been released and is open for download
- 6 seconds to understand the book to the Kindle
猜你喜欢

猿桌派第三季开播在即,打开出海浪潮下的开发者新视野
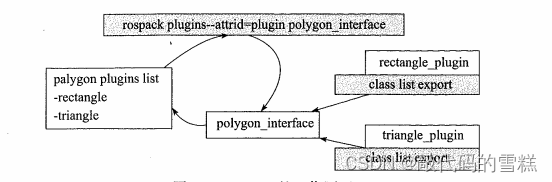
ROS learning (24) plugin
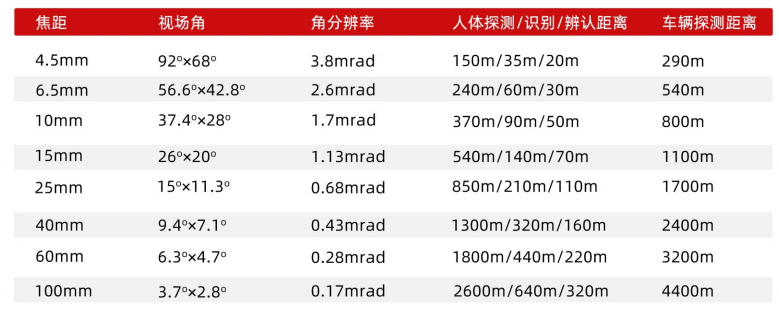
Infrared camera: juge infrared mag32 product introduction
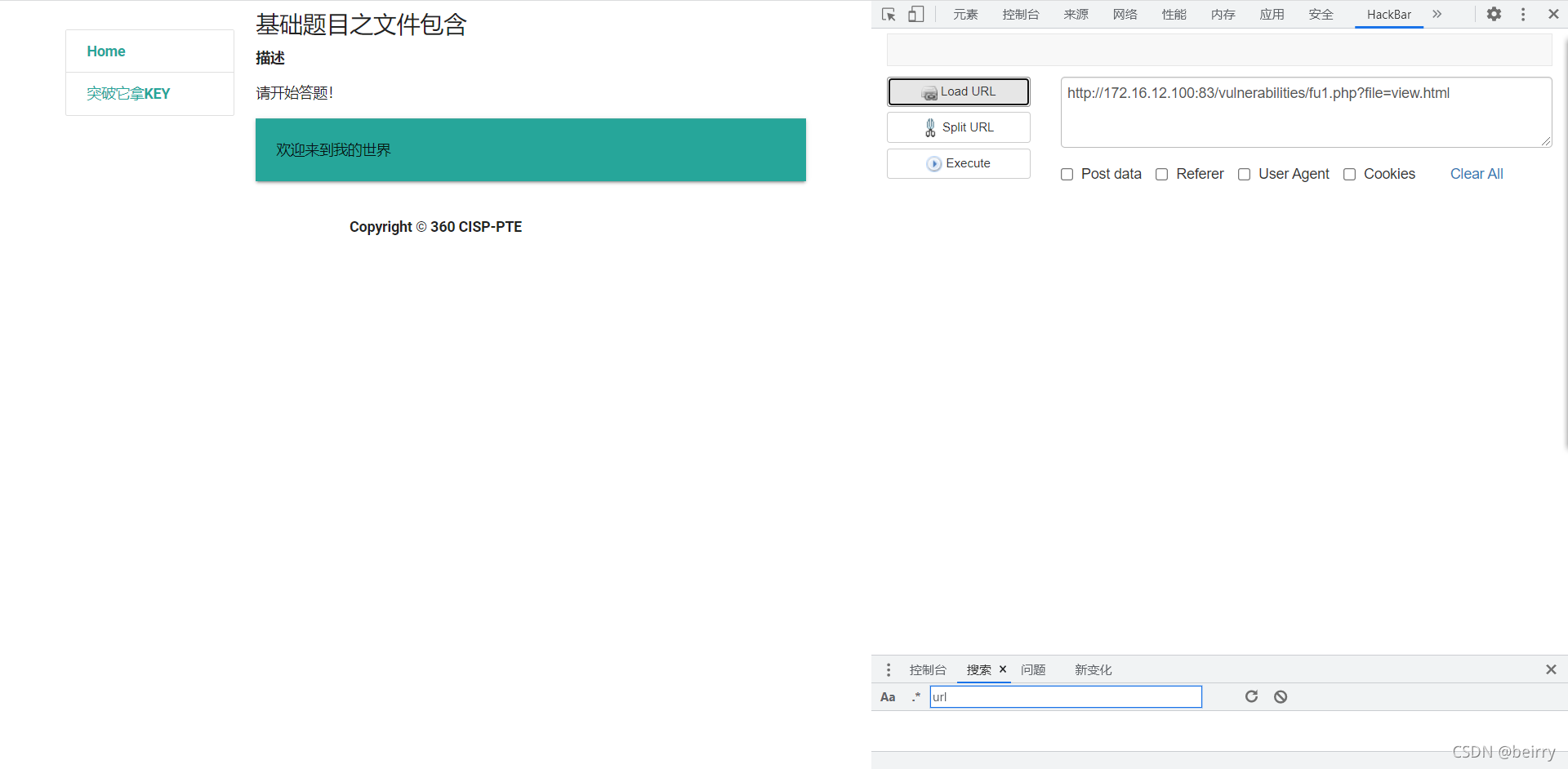
Cisp-pte practice explanation (II)
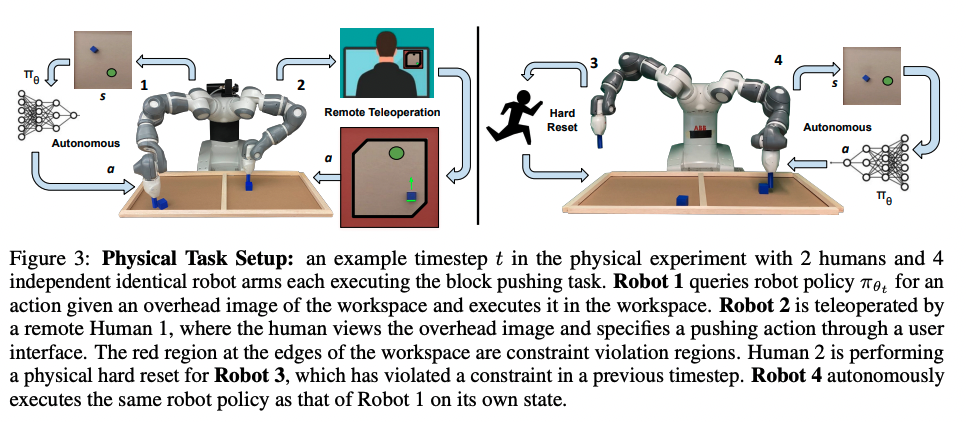
Robot team learning method to achieve 8.8 times human return
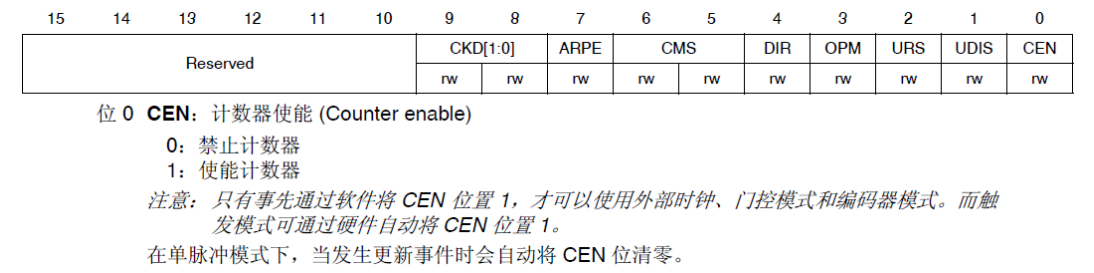
Stm32f4 --- general timer update interrupt
PartyDAO如何在1年内把一篇推文变成了2亿美金的产品DAO
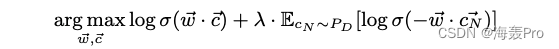
【论文阅读|深读】DNGR:Deep Neural Networks for Learning Graph Representations
Blackfly s usb3 industrial camera: buffer processing

FLIR blackfly s usb3 industrial camera: how to use counters and timers
随机推荐
阿里云中间件开源往事
The foreground downloads network pictures without background processing
FLIR blackfly s industrial camera: configure multiple cameras for synchronous shooting
3D激光SLAM:Livox激光雷达硬件时间同步
Vingt - trois mille feuilles? "Yang mou" derrière l'explosion de la consommation végétale
STM32F4---PWM输出
Integrated navigation: product description and interface description of zhonghaida inav2
ROS学习(24)plugin插件
Blackfly S USB3工业相机:缓冲区处理
Seconds understand the delay and timing function of wechat applet
猫猫回收站
ROS学习(22)TF变换
红外相机:巨哥红外MAG32产品介绍
Dall-E Mini的Mega版本模型发布,已开放下载
最近小程序开发记录
STM32F4---通用定时器更新中断
ROS学习(25)rviz plugin插件
ROS learning (22) TF transformation
Centros 8 installation MySQL Error: The gpg Keys listed for the "MySQL 8.0 Community Server" repository are already ins
Centos8 install MySQL 8.0 using yum x