当前位置:网站首页>TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析
TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析
2022-07-06 18:34:00 【InfoQ】
Overview
DDL 模块在 TiFlash 中的相关场景
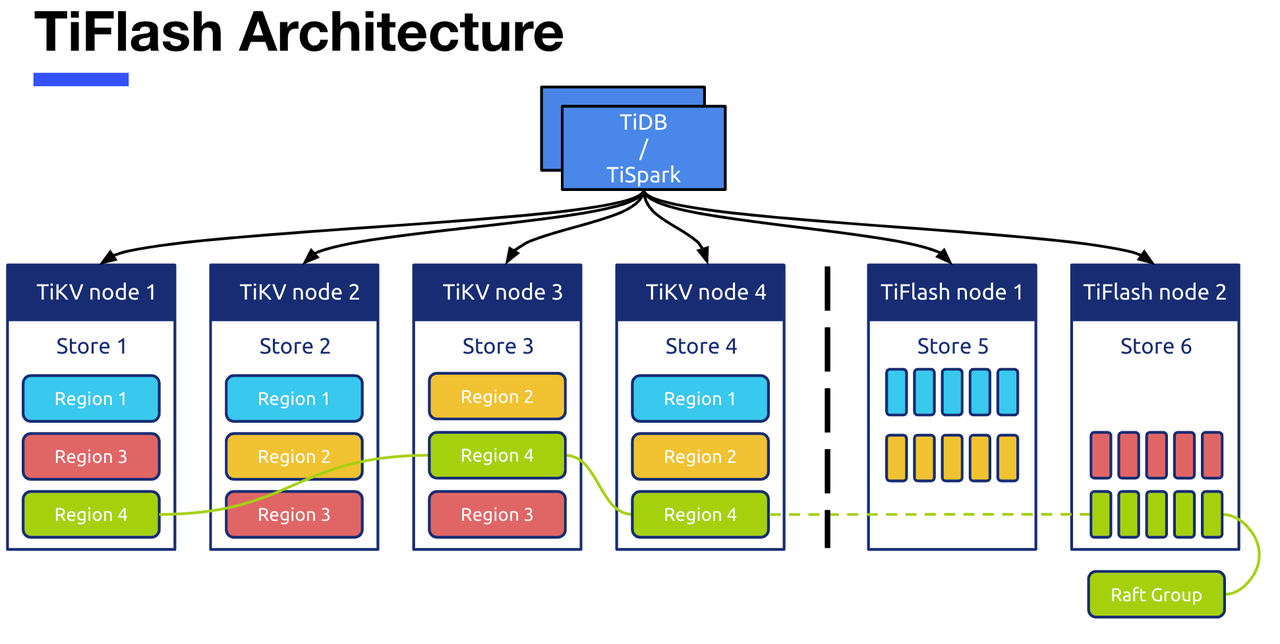
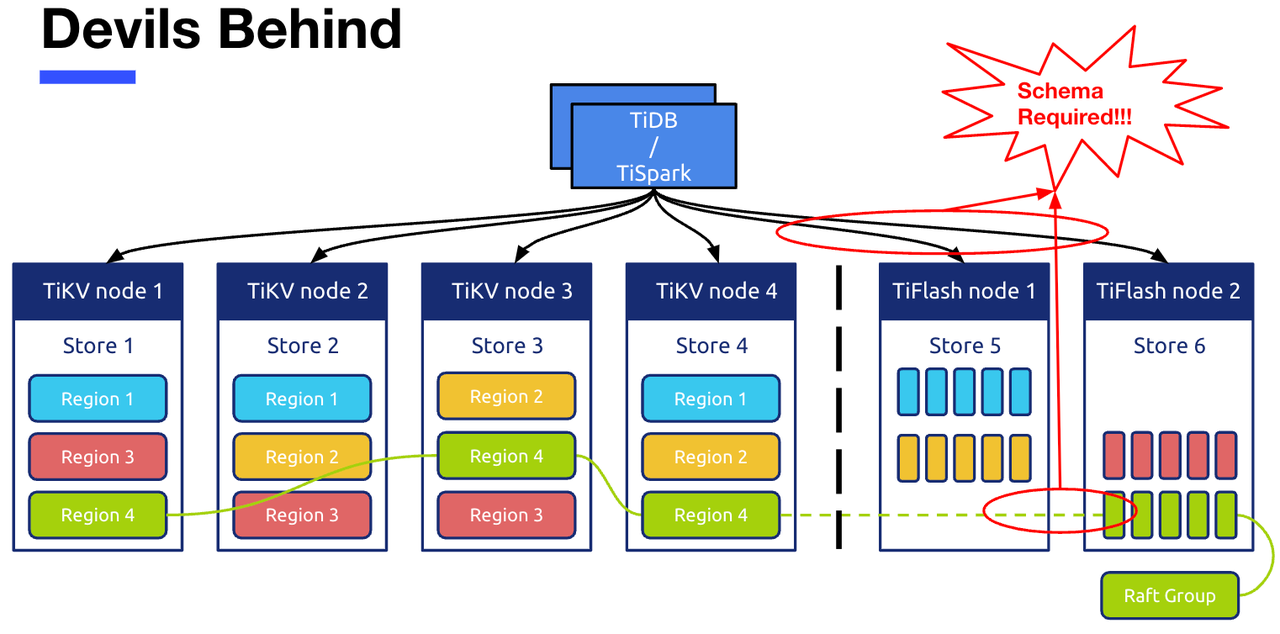
DDL 模块整体设计思想
TiDB 中 DDL 模块基本情况
- DDL 操作会尽可能避免发生 data reorg(data reorg 指的是在表中进行数据的增删改)。
- 图三这个 add column 的例子里面,原表有 a b 两列以及两行数据。当我们进行 add column 这个 DDL 操作时,我们不会在原有两行中给新增的 c 列填上默认值。如果后续有读操作会读到这两行的数据,我们则会在读的结果中给 c 列填上默认值。通过这样的方式,我们来避免在 DDL 操作的时候发生 data reorg。诸如 add column, drop column,以及整数类型的扩列操作,都不需要触发 data reorg 的。

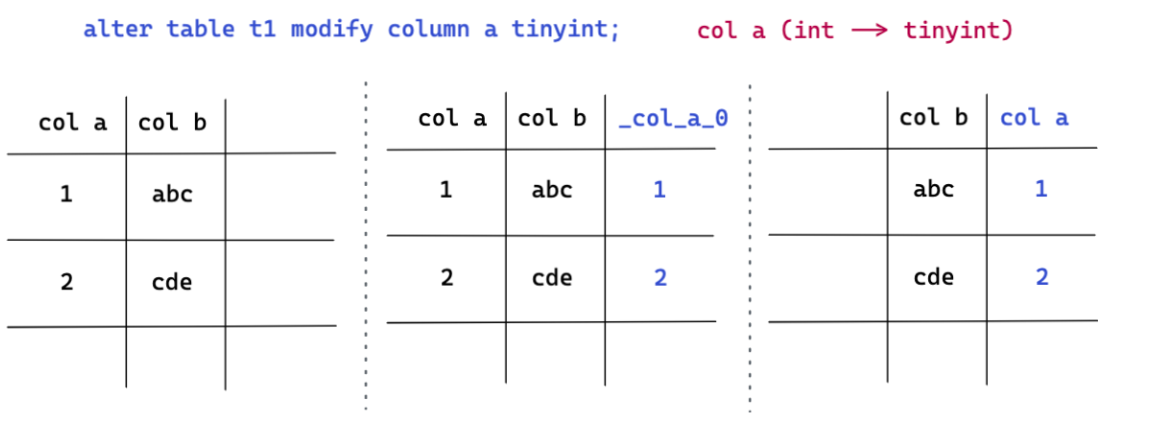
- 但是对于有损变更的 DDL 操作(例如:缩短列长度(后续简称缩列)的操作,可能会导致用户数据截断的 DDL变更),我们不可避免会发生 data reorg。但是在有损变更的场景下,我们也不会在表的原始列上进行数据修改重写的操作,而是通过新增列,在新增列上进行转换,最后删除原列,对新增列更名的方式来完成 DDL 操作。图四这个缩列 (modify column) 的例子中,我们原表中有 a, b 两列 ,此次 DDL 操作需要把 a 列从 int 类型缩成 tiny int 类型。整个 DDL 操作的过程为:
- 先新增一列隐藏列 _col_a_0。
- 把原始 a 列中的数值进行转换写到隐藏列 _col_a_0 上。
- 转换完成后,将原始的 a 列删除,并且将 _col_a_0 列重命名为 a 列。(这边提到的删除 a 列也并非物理上把 a 列的数值删除,是通过修改 meta 信息的方式来实现的)*
- 相对数据更新的 schema 永远可以解析旧的数据。这一条结论亦是我们后面 TiFlash DDL 模块依赖的一条重要的保证。这个保证是依赖我们行存数据的格式来实现的。在存数据的时候,我们是将column id 和 column value 一起存储的,而非column name和column value一起存储。另外我们的行存格式可以简化的理解为是一个 column_id → data 的一个 map 方式(实际上我们的行存并非一个 map,而是用二进制编码的方式来存储的,具体可以参考Proposal: A new storage row format for efficient decoding)。
- 我们可以通过图五这个例子,来更好的理解一下这条特性。左边是一个两列的原表,通过 DDL 操作,我们删除了 a 列,新增了 c 列,转换为右边的 schema 状态。这时,我们需要用新的 schema 信息去解析原有的老数据,根据新 schema 中的每个 column id,我们去老数据中找到每个 column id 对应的值,其中 id_2 可以找到对应的值,但 id_3 并没有找到对应的值,因此,就给 id_3 补上该列的默认值。而对于数据中多个 id_1 对应的值, 就选择直接舍弃。通过这样的方式,我们就正确的解析了原来的数据。

TiKV 中 DDL 模块基本情况
- TiKV 的写操作本身是不需要 shcema ,因为写入 TiKV 的数据是上层已经完成转换的行存的格式的数据(也就是 kv 中的 v)。
- 对于 TiKV 的读操作
- 如果读操作只需要直接把 kv 读出,则也不需要 schema 信息。
- 如果是需要在 TiKV 中的 coprocesser 上处理一些 TiDB 下发给 TiKV 承担的下推计算任务的时候,TiKV 会需要 schema 的信息。但是这个 schema 信息,会在 TiDB 发送来的请求中包含,所以 TiKV 可以是直接拿 TiDB 发送的请求中的 schema 信息来进行数据的解析,以及做一些异常处理(如果解析失败的话)。因此 TiKV 这一类读操作也不会需要自身提供 schema 相关的信息。
TiFlash 中 DDL 模块设计思想
- TiFlash 节点上会保存自己的 schema copy。一部分是因为 TiFlash 对 schema 具有强依赖性,需要 schema 来帮助解析行转列的数据以及需要读取的数据。另一方面也因为 TiFlash 是基于 Clickhouse 实现的,所以很多设计也是在 Clickhouse 原有的设计上进行演进的,Clickhouse 本身设计中就是保持了一份 schema copy。
- 对于 TiFlash 节点上保存的 schema copy,我们选择通过定期从 TiKV 中拉取最新的 schema(本质其实是拿到 TiDB 中最新的 schema 信息)来进行更新,因为不断持续地更新 schema 的开销是非常大的,所以我们是选择了定期更新。
- 读写操作,会依赖节点上的 schema copy 来进行解析。如果节点上的 schema copy 不满足当下读写的需求,我们会去拉最新的schema信息,来保证schema 比数据新,这样就可以正确成功解析了(这个就是前面提到的 TiDB DDL 机制提供的保证)。具体读写时对 schema copy 的需求,会在后面的部分具体给大家介绍。
DDL Core Process
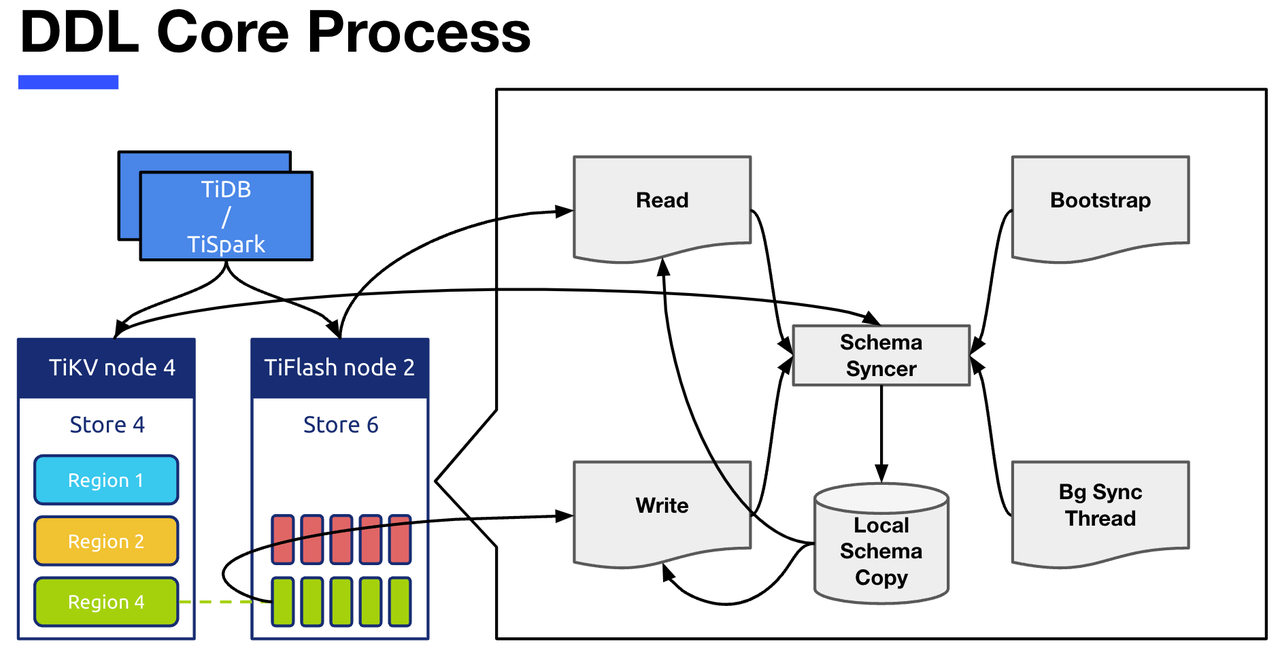
- Local Schema Copy 指的是 TiFlash 节点上存的 schema copy 的信息。
- Schema Syncer 模块负责从 TiKV 拉取 最新的 Schema 信息,依此来更新 Local Schema Copy。
- Bootstrap 指的是 TiFlash Server 启动的时候,会直接调用一次 Schema Syncer,获得目前所有的 schema 信息。
- Background Sync Thread 是负责定期调用 Schema Syncer 来更新 Local Schema Copy 模块。
- Read 和 Write 两个模块就是 TiFlash 中的读写操作,读写操作都会去依赖 Local Schema Copy,也会在有需要的时候来调用 Schema Syncer 进行更新。
Local Schema Copy
StorageDeltaMerge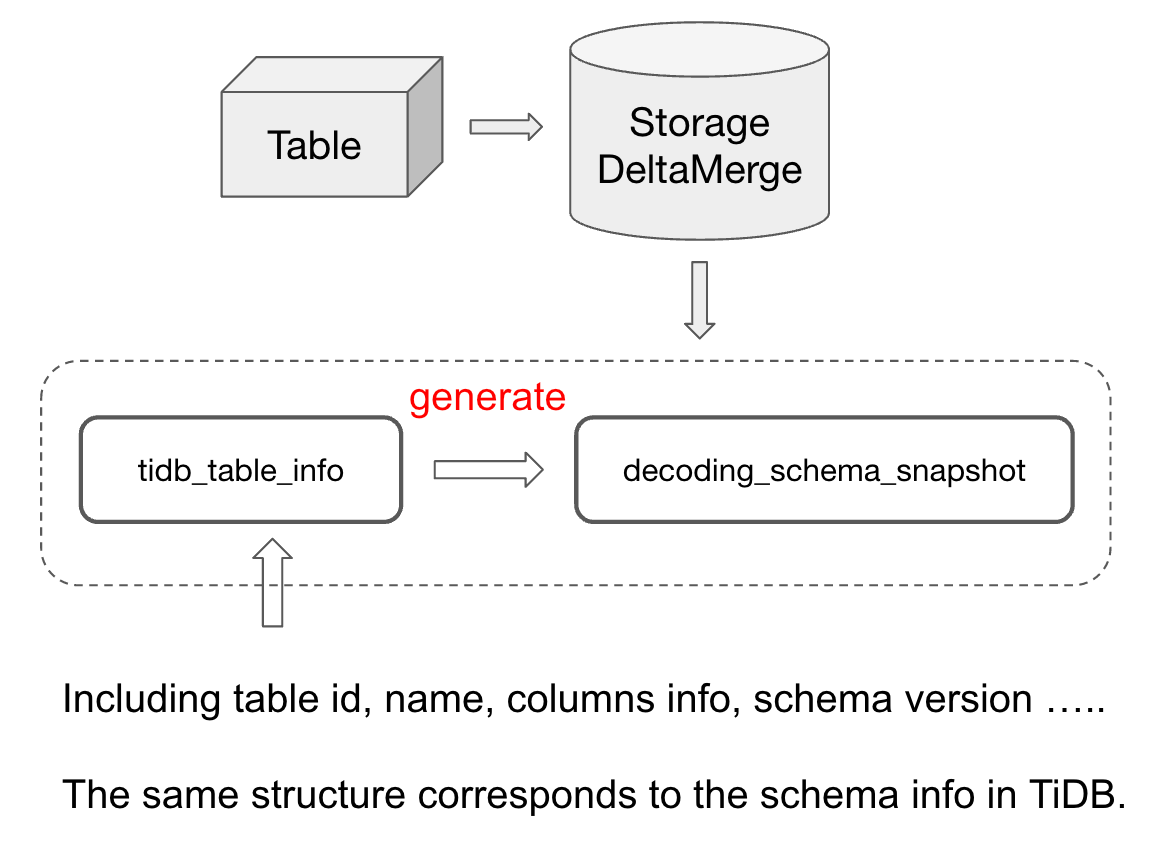
tidb_table_info这个变量存的是 table 中各种 schema 信息,包括 table id,table name,columns infos,schema version等等。并且tidb_table_info的存储结构跟 TiDB / TiKV 中存储 table schema 的结构是完全一致的。
decoding_schema_snapshot则是根据tidb_table_info以及StorageDeltaMerge中的一些信息生成的一个对象。decoding_schema_snapshot是为了优化写入过程中行转列的性能而提出的。因为我们在做行转列转换的时候,如果依赖tidb_table_info获取对应需要的 schema 信息,需要做一系列的转换操作来进行适配。考虑到 schema 本身也不会频繁更新,为了避免每次行转列解析都需要重复做这些操作,我们就用decoding_schema_snapshot这个变量来保存转换好的结果,并且在行转列过程中依赖decoding_schema_snapshot来进行解析。
Schema Syncer
TiDBSchemaSyncerStorageDeltaMerge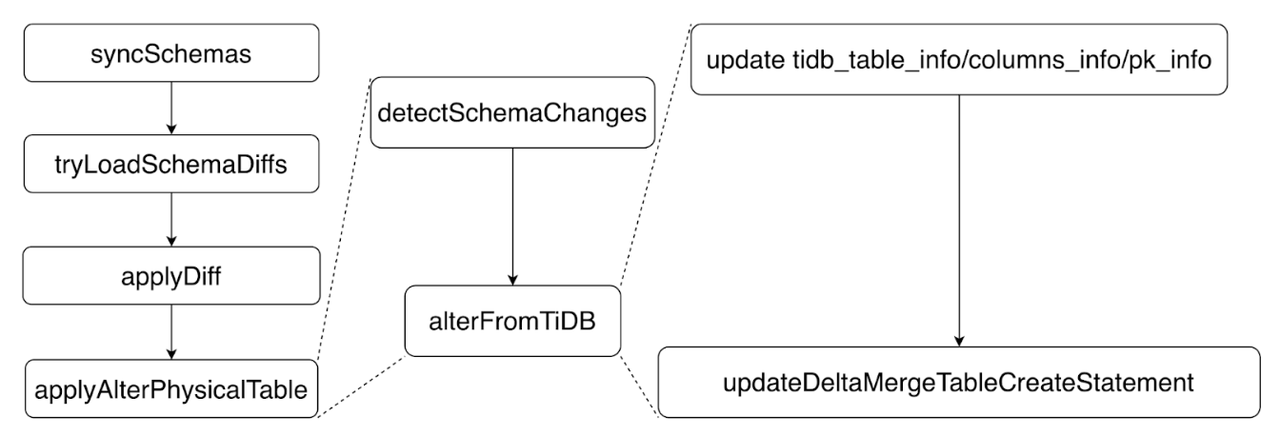
TiDBSchemaSyncersyncSchema- 通过
tryLoadSchemaDiffs, TiKV 中拿到这一轮新的 schema 变更信息。
- 随后遍历所有的 diffs 来一个个进行
applyDiff。
- 对每个 diff,我们会找到他对应的 table,进行
applyAlterPhysicalTable。
- 在这其中,我们会 detect 到这轮更新中,跟这个表相关的所有 schema 变更,然后调用
StorageDeltaMerge::alterFromTiDB来对这张表对应的StorageDeltaMerge对象进行变更。
- 具体变更中,我们会修改
tidb_table_info, 相关的 columns 和主键的信息。
- 另外我们还会更新这张表的建表语句,因为表本身发生了变化,所以他的建表语句也需要对应改变,这样后续做 recover 等操作的时候才能正确工作。
syncSchemadecoding_schema_snapshotdecoding_schema_snapshotdecoding_schema_snapshottidb_table_infotidb_table_infodecoding_schema_snapshot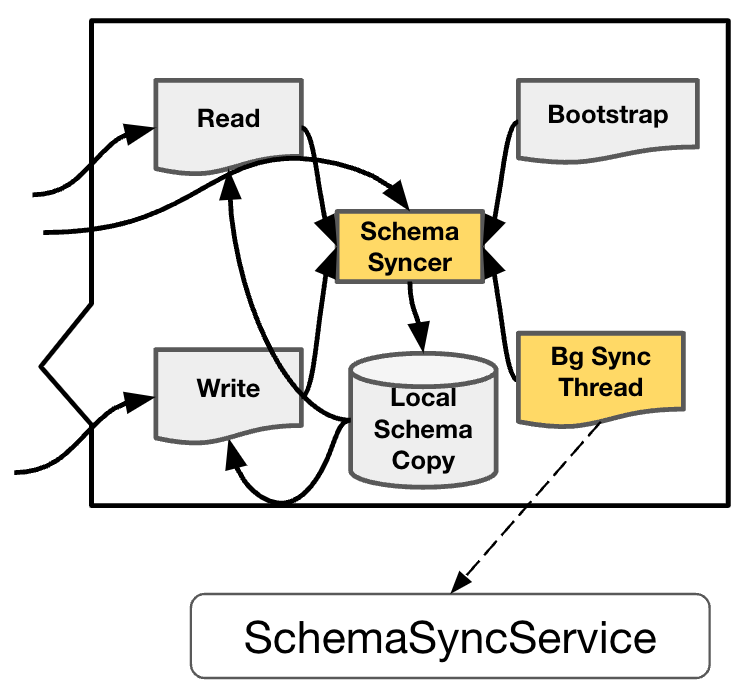
TiDBSchemaSyncer::syncSchemaSchemaSyncServicesyncSchemaSchema on Data Write
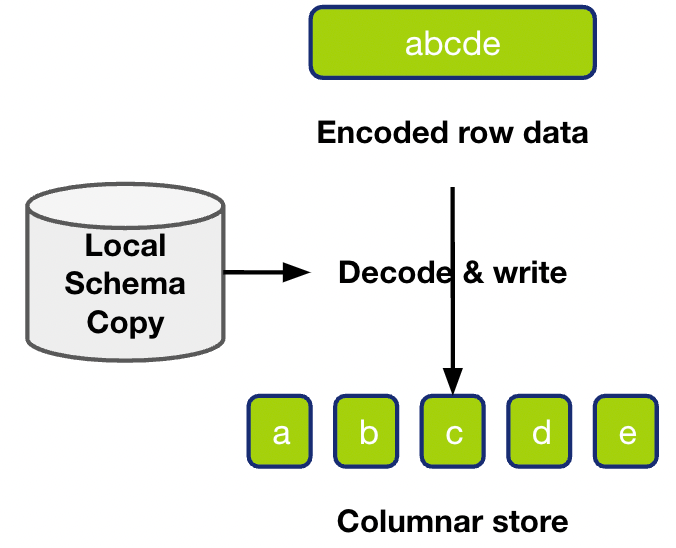
- 第一种情况Unknown Column, 即待写入的数据比 schema 多了一列 e。发生这种情况的可能有下面两种可能。
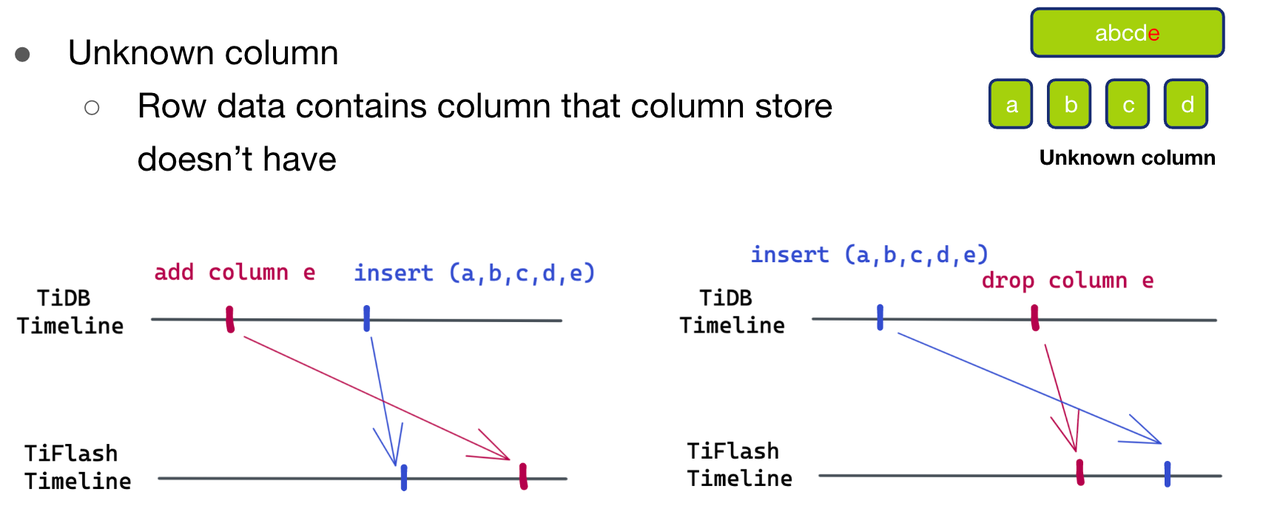
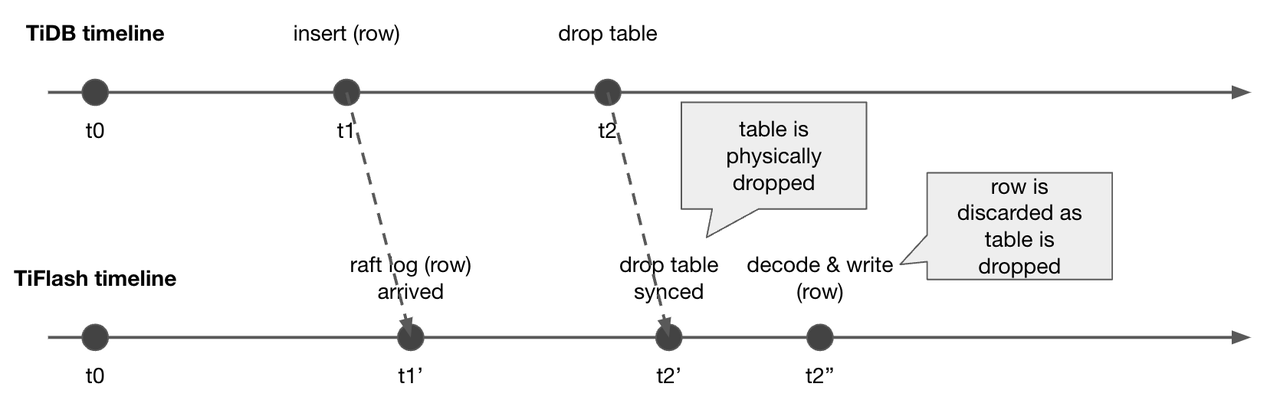
- 第一种可能,如图十一(左)所示,待写入的数据比 schema 新。在 TiDB 的时间线上,先新增了一列 e,随后再插入了 (a,b,c,d,e) 这行数据。但是插入的数据先到到了 TiFlash ,add column e 的 schema 变更还没到 TiFlash 侧,所以就出现了数据比 schema 多一列的情况。
- 第二种可能,如图十一(右)所示,待写入的数据比 schema 旧。在 TiDB 的时间线上,先插入了这行数据 (a,b,c,d,e),然后 drop column e。但是 drop column e 的 schema 变更先到达 TiFlash 侧, 插入的数据后到达,也会出现了数据比 schema 多一列的情况。在这种情况下,我们也没有办法判断到底属于上述是哪一种情况,也没有一个共用的方法能处理,所以就只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。
- 第二种情况Missing Column,即待写入的数据比 schema 少了一列 e。同样,也有两种产生的可能性。
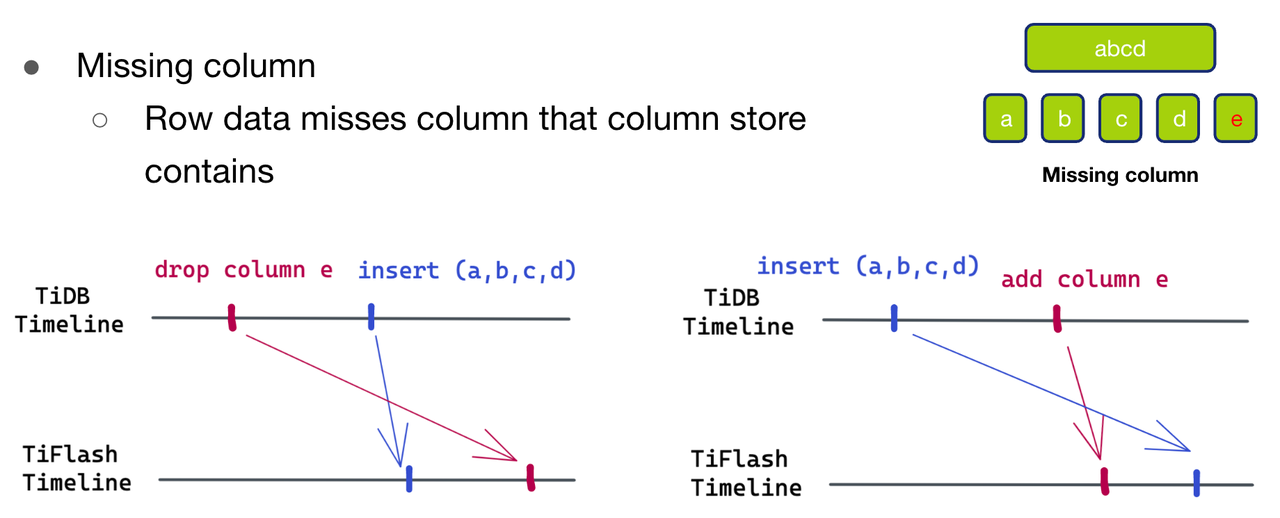
- 第一种可能,如图十二(左)所示,待写入的数据比 schema 新。在 TiDB 时间线上,先 drop column e,再插入数据(a,b,c,d)。
- 第二种可能,如图十二(右)所示,待写入的数据比 schema 旧。 在 TiDB 时间线上,先插入了数据 (a,b,c,d),然后再插入了 e 列。
- 第三种情况Overflow Column,即我们待写入的数据中有一列数值大于了我们 schema 中这一列的数据范围的。
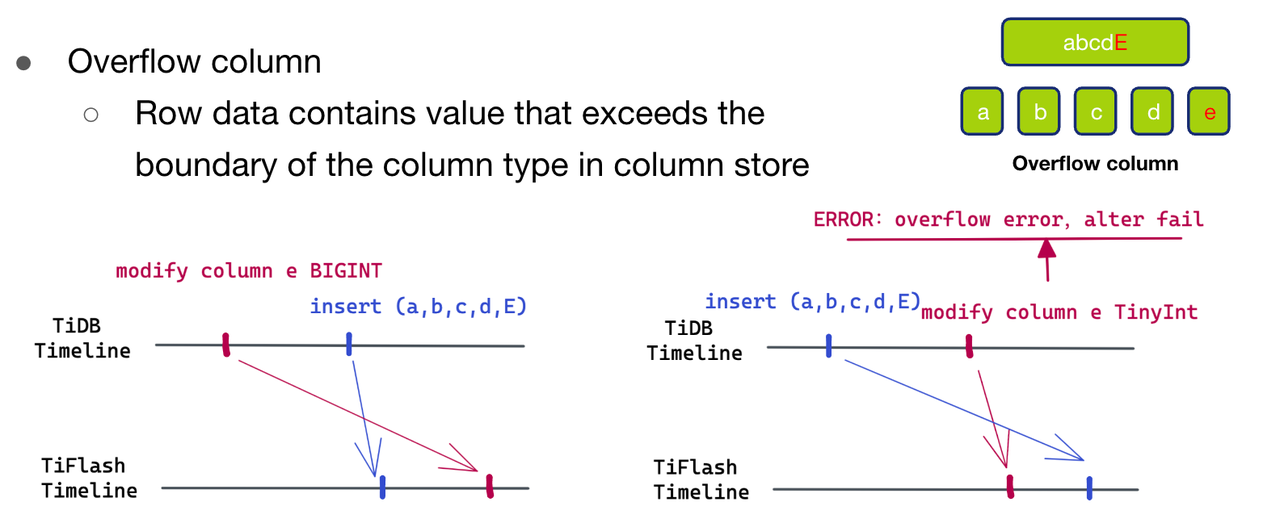

- 第一种情况 Unknown Column。因为 schema 比 待写入的数据新,所以我们可以肯定是因为在这行数据后,又发生了 drop column e 的操作,但是这个 schema change 先到达了 TiFlash 侧,所以导致了 Unknown Column 的场景。因此我们只需要直接把 e 列数据直接删除即可。
- 第二种情况 Missing Column。这种情况则是由于在这行数据后进行了 add column e 的操作造成的,因此我们直接给多余的列填上默认值即可。
- 第三种情况 Overflow Column。因为目前我们的 schema 已经比待写入的数据新了,所以再次出现 overflow column 的情况,一定是发生了异常,因此我们直接抛出异常。
writeRegionDataToStorageRegionBlockReaderdecoding_schema_snapshotRegionBlockReaderdecoding_schema_snapshotdecoding_schema_snapshottidb_table_infodecoding_schema_snapshotgetSchemaSnapshotAndBlockForDecodingSchema on Data Read
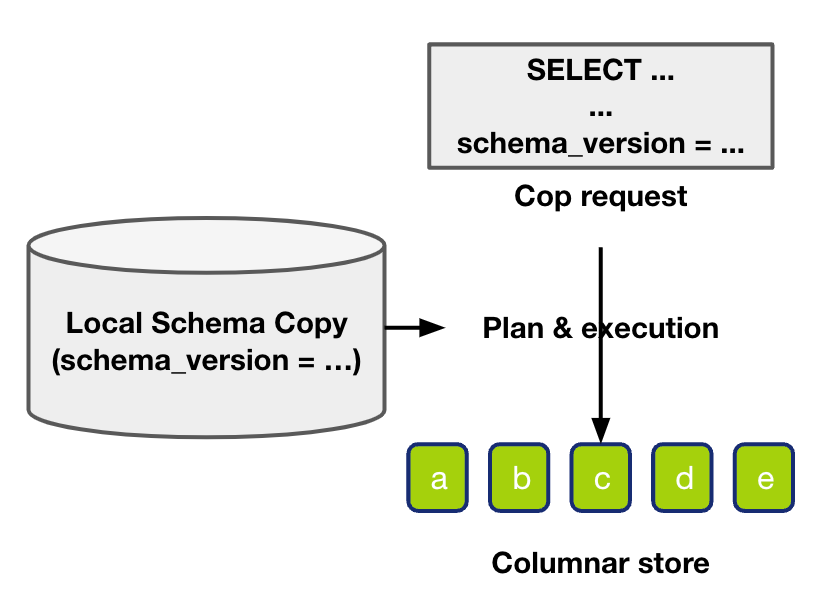
TiDBSchemaSyncer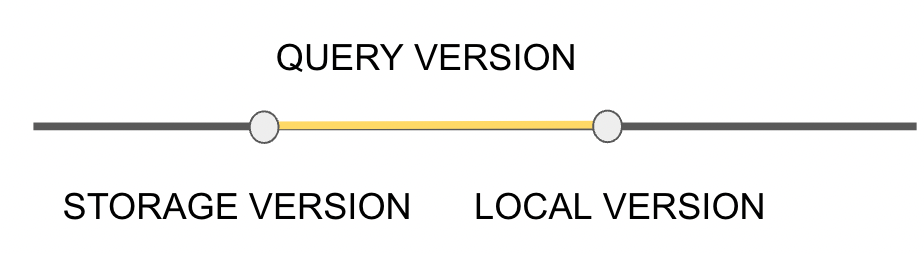
tidb_table_infoInterpreterSelectQuery.cppgetAndLockStorageWithSchemaVersionDAGStorageInterpreter.cppgetAndLockStoragesInterpreterSelectQuery.cppDAGStorageInterpreter.cppSpecial Case

小结
边栏推荐
- Centos8 install MySQL 8.0 using yum x
- Flir Blackfly S USB3 工业相机:计数器和定时器的使用方法
- 将截断字符串或二进制数据
- ROS learning (XX) robot slam function package -- installation and testing of rgbdslam
- JS Es5 can also create constants?
- 开发中对集合里面的数据根据属性进行合并数量时犯的错误
- C language [23] classic interview questions [Part 2]
- Jacob Steinhardt, assistant professor of UC Berkeley, predicts AI benchmark performance: AI has made faster progress in fields such as mathematics than expected, but the progress of robustness benchma
- 建议收藏!!Flutter状态管理插件哪家强?请看岛上码农的排行榜!
- Time synchronization of livox lidar hardware -- PPS method
猜你喜欢

张平安:加快云上数字创新,共建产业智慧生态
SchedulX V1.4.0及SaaS版发布,免费体验降本增效高级功能!
Ros Learning (23) Action Communication Mechanism

Flir Blackfly S USB3 工业相机:计数器和定时器的使用方法
Processing image files uploaded by streamlit Library
![Yiwen takes you into [memory leak]](/img/a8/bd1a57ef3bde8910eff2a5f68296df.png)
Yiwen takes you into [memory leak]
解密函数计算异步任务能力之「任务的状态及生命周期管理」
FLIR blackfly s industrial camera: configure multiple cameras for synchronous shooting
String or binary data will be truncated
传感器:土壤湿度传感器(XH-M214)介绍及stm32驱动代码
随机推荐
Scenario practice: quickly build wordpress blog system based on function calculation
Golang foundation - data type
Cat recycling bin
Make DIY welding smoke extractor with lighting
ROS学习(21)机器人SLAM功能包——orbslam的安装与测试
Command injection of cisp-pte
FLIR blackfly s industrial camera: configure multiple cameras for synchronous shooting
Image watermarking, scaling and conversion of an input stream
Mongodb checks whether the table is imported successfully
刨析《C语言》【进阶】付费知识【一】
CISP-PTE之命令注入篇
ROS learning (25) rviz plugin
机器人队伍学习方法,实现8.8倍的人力回报
2022/0524/bookstrap
Shell script quickly counts the number of lines of project code
ROS学习(23)action通信机制
PartyDAO如何在1年内把一篇推文变成了2亿美金的产品DAO
Recognition of C language array
ROS learning (23) action communication mechanism
How to use strings as speed templates- How to use String as Velocity Template?