当前位置:网站首页>C语言【23道】经典面试题【下】
C语言【23道】经典面试题【下】
2022-07-06 18:10:00 【Choice~】
13.选择、插入、气泡排序
说明
选择排序(Selection sort)、插入排序(Insertion sort)与气泡排序(Bubble sort)这三个排序方式是初学排序所必须知道的三个基本排序方式,它们由于速度不快而不实用(平均与最快的时间复杂度都是O(n2)), 然而它们排序的方式确是值得观察与探讨的。
解法
选择排序将要排序的对象分作两部份,一个是已排序的,一个是未排序的,从后端未排序部份选择一个最小值,并放入前端已排序部份的最后一个,例如:
排序前:70 80 31 37 10 1 48 60 33 80
[1] 80 31 37 10 70 48 60 33 80 选出最小值1
[1 10] 31 37 80 70 48 60 33 80 选出最小值10
[1 10 31] 37 80 70 48 60 33 80 选出最小值31
[1 10 31 33] 80 70 48 60 37 80 …
[1 10 31 33 37] 70 48 60 80 80 …
[1 10 31 33 37 48] 70 60 80 80 …
[1 10 31 33 37 48 60] 70 80 80 …
[1 10 31 33 37 48 60 70] 80 80 …
[1 10 31 33 37 48 60 70 80] 80 …
插入排序像是玩朴克一样,我们将牌分作两堆,每次从后面一堆的牌抽出最前端的牌,然后插入前面一堆牌的适当位置,例如:
排序前:92 77 67 8 6 84 55 85 43 67
[77 92] 67 8 6 84 55 85 43 67 将77插入92前
[67 77 92] 8 6 84 55 85 43 67 将67插入77前
[8 67 77 92] 6 84 55 85 43 67 将8插入67前
[6 8 67 77 92] 84 55 85 43 67 将6插入8前
[6 8 67 77 84 92] 55 85 43 67 将84插入92前
[6 8 55 67 77 84 92] 85 43 67 将55插入67前
[6 8 55 67 77 84 85 92] 43 67 …
[6 8 43 55 67 77 84 85 92] 67 …
[6 8 43 55 67 67 77 84 85 92] …
气泡排序法
顾名思义,就是排序时,最大的元素会如同气泡一样移至右端,其利用比较相邻元素的方法,将大的元素交换至右端,所以大的元素会不断的往右移动,直到适当的位置为止。基本的气泡排序法可以利用旗标的方式稍微减少一些比较的时间,当寻访完阵列后都没有发生任何的交换动作,表示排序已经完成,而无需再进行之后的回圈比较与交换动作,例如:
排序前:95 27 90 49 80 58 6 9 18 50
27 90 49 80 58 6 9 18 50 [95] 95浮出
27 49 80 58 6 9 18 50 [90 95] 90浮出
27 49 58 6 9 18 50 [80 90 95] 80浮出
27 49 6 9 18 50 [58 80 90 95] …
27 6 9 18 49 [50 58 80 90 95] …
6 9 18 27 [49 50 58 80 90 95] …
6 9 18 [27 49 50 58 80 90 95]
由于接下来不会再发生交换动作,排序提早结束.在上面的例子当中,还加入了一个观念,就是当进行至i与i+1时没有交换的动作,表示接下来的i+2至n已经排序完毕,这也增进了气泡排序的效率。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
void selsort(int[]); // 选择排序
void insort(int[]); // 插入排序
void bubsort(int[]); // 气泡排序
int main(void) {
int number[MAX] = {
0};
int i;
srand(time(NULL));
printf("排序前:");
for(i = 0; i < MAX; i++) {
number[i] = rand() % 100;
printf("%d ", number[i]);
}
printf("\n请选择排序方式:\n");
printf("(1)选择排序\n(2)插入排序\n(3)气泡排序\n:");
scanf("%d", &i);
switch(i) {
case 1:
selsort(number); break;
case 2:
insort(number); break;
case 3:
bubsort(number); break;
default:
printf("选项错误(1..3)\n");
}
return 0;
}
void selsort(int number[]) {
int i, j, k, m;
for(i = 0; i < MAX-1; i++) {
m = i;
for(j = i+1; j < MAX; j++)
if(number[j] < number[m])
m = j;
if( i != m)
SWAP(number[i], number[m])
printf("第%d 次排序:", i+1);
for(k = 0; k < MAX; k++)
printf("%d ", number[k]);
printf("\n");
}
}
void insort(int number[]) {
int i, j, k, tmp;
for(j = 1; j < MAX; j++) {
tmp = number[j];
i = j - 1;
while(tmp < number[i]) {
number[i+1] = number[i];
i--;
if(i == -1)
break;
}
number[i+1] = tmp;
printf("第%d 次排序:", j);
for(k = 0; k < MAX; k++)
printf("%d ", number[k]);
printf("\n");
}
}
void bubsort(int number[]) {
int i, j, k, flag = 1;
for(i = 0; i < MAX-1 && flag == 1; i++) {
flag = 0;
for(j = 0; j < MAX-i-1; j++) {
if(number[j+1] < number[j]) {
SWAP(number[j+1], number[j]);
flag = 1;
}
}
printf("第%d 次排序:", i+1);
for(k = 0; k < MAX; k++)
printf("%d ", number[k]);
printf("\n");
}
}
14.排序法-改良的插入排序
说明
插入排序法由未排序的后半部前端取出一个值,插入已排序前半部的适当位置,概念简单但速度不快。排序要加快的基本原则之一,是让后一次的排序进行时,尽量利用前一次排序后的结果,以加快排序的速度,Shell排序法即是基于此一概念来改良插入排序法。
解法
Shell排序法最初是D.L Shell于1959所提出,假设要排序的元素有n个,则每次进行插入排序时并不是所有的元素同时进行时,而是取一段间隔。
Shell首先将间隔设定为n/2,然后跳跃进行插入排序,再来将间隔n/4,跳跃进行排序动作,再来间隔设定为n/8、n/16,直到间隔为1之后的最后一次排序终止,由于上一次的排序动作都会将固定间隔内的元素排序好,所以当间隔越来越小时,某些元素位于正确位置的机率越高,因此最后几次的排序动作将可以大幅减低。举个例子来说,假设有一未排序的数字如右:89 12 65 97 61 81 27 2 61 98数字的总数共有10个,所以第一次我们将间隔设定为10 / 2 = 5,此时我们对间隔为5的数字进行排序,如下所示:
画线连结的部份表示要一起进行排序的部份,再来将间隔设定为5 / 2的商,也就是2,则第二次的插入排序对象如下所示:再来间隔设定为2 / 2 = 1,此时就是单纯的插入排序了,由于大部份的元素都已大致排序过了,
所以最后一次的插入排序几乎没作什么排序动作了:
将间隔设定为n / 2是D.L Shell最初所提出,在教科书中使用这个间隔比较好说明,然而Shell排序法的关键在于间隔的选定,例如Sedgewick证明选用以下的间隔可以加快Shell排序法的速度:
其中4*(2j)2 + 3*(2j) + 1不可超过元素总数n值,使用上式找出j后代入4*(2j)2 + 3*(2j) + 1求得第一个间隔,然后将2j除以2代入求得第二个间隔,再来依此类推。后来还有人证明有其它的间隔选定法可以将Shell排序法的速度再加快;另外Shell排序法的概念也可以用来改良气泡排序法。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
void shellsort(int[]);
int main(void) {
int number[MAX] = {
0};
int i;
srand(time(NULL));
printf("排序前:");
for(i = 0; i < MAX; i++) {
number[i] = rand() % 100;
printf("%d ", number[i]);
}
shellsort(number);
return 0;
}
void shellsort(int number[]) {
int i, j, k, gap, t;
gap = MAX / 2;
while(gap > 0) {
for(k = 0; k < gap; k++) {
for(i = k+gap; i < MAX; i+=gap) {
for(j = i - gap; j >= k; j-=gap) {
if(number[j] > number[j+gap]) {
SWAP(number[j], number[j+gap]);
}
else
break;
}
}
}
printf("\ngap = %d:", gap);
for(i = 0; i < MAX; i++)
printf("%d ", number[i]);
printf("\n");
gap /= 2;
}
}
15.排序法-改良的气泡排序
说明
请看看之前介绍过的气泡排序法:
for(i = 0; i < MAX-1 && flag == 1; i++) {
flag = 0;
for(j = 0; j < MAX-i-1; j++) {
if(number[j+1] < number[j]) {
SWAP(number[j+1], number[j]);
flag = 1;
}
}
}
事实上这个气泡排序法已经不是单纯的气泡排序了,它使用了旗标与右端左移两个方法来改进排序的效能,而Shaker排序法使用到后面这个观念进一步改良气泡排序法。
解法
在上面的气泡排序法中,交换的动作并不会一直进行至阵列的最后一个,而是会进行至MAX-i-1,所以排序的过程中,阵列右方排序好的元素会一直增加,使得左边排序的次数逐渐减少,如我们的例子所示:
排序前:95 27 90 49 80 58 6 9 18 50
27 90 49 80 58 6 9 18 50 [95] 95浮出
27 49 80 58 6 9 18 50 [90 95] 90浮出
27 49 58 6 9 18 50 [80 90 95] 80浮出
27 49 6 9 18 50 [58 80 90 95] …
27 6 9 18 49 [50 58 80 90 95] …
6 9 18 27 [49 50 58 80 90 95] …
6 9 18 [27 49 50 58 80 90 95]
方括号括住的部份表示已排序完毕,Shaker排序使用了这个概念,如果让左边的元素也具有这样的性质,让左右两边的元素都能先排序完成,如此未排序的元素会集中在中间,由于左右两边同时排序,中间未排序的部份将会很快的减少。方法就在于气泡排序的双向进行,先让气泡排序由左向右进行,再来让气泡排序由右往左进行,如此完成一次排序的动作,而您必须使用left与right两个旗标来记录左右两端已排序的元素位置。
一个排序的例子如下所示:
排序前:45 19 77 81 13 28 18 19 77 11
往右排序:19 45 77 13 28 18 19 77 11 [81]
向左排序:[11] 19 45 77 13 28 18 19 77 [81]
往右排序:[11] 19 45 13 28 18 19 [77 77 81]
向左排序:[11 13] 19 45 18 28 19 [77 77 81]
往右排序:[11 13] 19 18 28 19 [45 77 77 81]
向左排序:[11 13 18] 19 19 28 [45 77 77 81]
往右排序:[11 13 18] 19 19 [28 45 77 77 81]
向左排序:[11 13 18 19 19] [28 45 77 77 81]
如上所示,括号中表示左右两边已排序完成的部份,当left > right时,则排序完成。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
void shakersort(int[]);
int main(void) {
int number[MAX] = {
0};
int i;
srand(time(NULL));
16.排序法-改良的选择排序
说明
选择排序法的概念简单,每次从未排序部份选一最小值,插入已排序部份的后端,其时间主要花费于在整个未排序部份寻找最小值,如果能让搜寻最小值的方式加快,选择排序法的速率也
就可以加快,Heap排序法让搜寻的路径由树根至最后一个树叶,而不是整个未排序部份,因而称之为改良的选择排序法。
解法
Heap排序法使用Heap Tree(堆积树),树是一种资料结构,而堆积树是一个二元树,也就是每一个父节点最多只有两个子节点(关于树的详细定义还请见资料结构书籍),堆积树的父节点若小于子节点,则称之为最小堆积(Min Heap),父节点若大于子节点,则称之为最大堆积(Max
Heap),而同一层的子节点则无需理会其大小关系,例如下面就是一个堆积树:
可以使用一维阵列来储存堆积树的所有元素与其顺序,为了计算方便,使用的起始索引是1而不是0,索引1是树根位置,如果左子节点储存在阵列中的索引为s,则其父节点的索引为s/2,而右子节点为s+1,就如上图所示,将上图的堆积树转换为一维阵列之后如下所示:
首先必须知道如何建立堆积树,加至堆积树的元素会先放置在最后一个树叶节点位置,然后检
查父节点是否小于子节点(最小堆积),将小的元素不断与父节点交换,直到满足堆积树的条件
为止,例如在上图的堆积加入一个元素12,则堆积树的调整方式如下所示:
建立好堆积树之后,树根一定是所有元素的最小值,您的目的就是:
将最小值取出然后调整树为堆积树
不断重复以上的步骤,就可以达到排序的效果,最小值的取出方式是将树根与最后一个树叶节点交换,然后切下树叶节点,重新调整树为堆积树,如下所示:
调整完毕后,树根节点又是最小值了,于是我们可以重覆这个步骤,再取出最小值,并调整树为堆积树,如下所示:
如此重覆步骤之后,由于使用一维阵列来储存堆积树,每一次将树叶与树根交换的动作就是将最小值放至后端的阵列,所以最后阵列就是变为已排序的状态。其实堆积在调整的过程中,就是一个选择的行为,每次将最小值选至树根,而选择的路径并不是所有的元素,而是由树根至树叶的路径,因而可以加快选择的过程, 所以Heap排序法才会被称之为改良的选择排序法。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
void createheap(int[]);
void heapsort(int[]);
int main(void) {
int number[MAX+1] = {
-1};
int i, num;
srand(time(NULL));
printf("排序前:");
for(i = 1; i <= MAX; i++) {
number[i] = rand() % 100;
printf("%d ", number[i]);
}
printf("\n建立堆积树:");
createheap(number);
for(i = 1; i <= MAX; i++)
printf("%d ", number[i]);
printf("\n");
heapsort(number);
printf("\n");
return 0;
}
void createheap(int number[]) {
int i, s, p;
int heap[MAX+1] = {
-1};
for(i = 1; i <= MAX; i++) {
heap[i] = number[i];
s = i;
p = i / 2;
while(s >= 2 && heap[p] > heap[s]) {
SWAP(heap[p], heap[s]);
s = p;
p = s / 2;
}
}
for(i = 1; i <= MAX; i++)
number[i] = heap[i];
}
void heapsort(int number[]) {
int i, m, p, s;
m = MAX;
while(m > 1) {
SWAP(number[1], number[m]);
m--;
p = 1;
s = 2 * p;
while(s <= m) {
if(s < m && number[s+1] < number[s])
s++;
if(number[p] <= number[s])
break;
SWAP(number[p], number[s]);
p = s;
s = 2 * p;
}
printf("\n排序中:");
for(i = MAX; i > 0; i--)
printf("%d ", number[i]);
}
}
17.快速排序法(一)
说明
快速排序法(quick sort)是目前所公认最快的排序方法之一(视解题的对象而定),虽然快速排序法在最差状况下可以达O(n2),但是在多数的情况下,快速排序法的效率表现是相当不错的。快速排序法的基本精神是在数列中找出适当的轴心,然后将数列一分为二,分别对左边与右边数列进行排序,而影响快速排序法效率的正是轴心的选择。这边所介绍的第一个快速排序法版本,是在多数的教科书上所提及的版本,因为它最容易理解,也最符合轴心分割与左右进行排序的概念,适合对初学者进行讲解。
解法
这边所介绍的快速演算如下:将最左边的数设定为轴,并记录其值为s
廻圈处理:
- 令索引i 从数列左方往右方找,直到找到大于s 的数
- 令索引j 从数列左右方往左方找,直到找到小于s 的数
- 如果i >= j,则离开回圈
- 如果i < j,则交换索引i与j两处的值
- 将左侧的轴与j 进行交换
- 对轴左边进行递回
- 对轴右边进行递回
透过以下演算法,则轴左边的值都会小于s,轴右边的值都会大于s,如此再对轴左右两边进行递回,就可以对完成排序的目的,例如下面的实例,表示要交换的数,[]表示轴:
[41] 24 76 11 45 64 21 69 19 36*
[41] 24 36 11 45* 64 21 69 19* 76
[41] 24 36 11 19 64* 21* 69 45 76
[41] 24 36 11 19 21 64 69 45 76
21 24 36 11 19 [41] 64 69 45 76
在上面的例子中,41左边的值都比它小,而右边的值都比它大,如此左右再进行递回至排序完成。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
void quicksort(int[], int, int);
int main(void) {
int number[MAX] = {
0};
int i, num;
srand(time(NULL));
printf("排序前:");
for(i = 0; i < MAX; i++) {
number[i] = rand() % 100;
printf("%d ", number[i]);
}
quicksort(number, 0, MAX-1);
printf("\n排序后:");
for(i = 0; i < MAX; i++)
printf("%d ", number[i]);
printf("\n");
return 0;
}
void quicksort(int number[], int left, int right) {
int i, j, s;
if(left < right) {
s = number[left];
i = left;
j = right + 1;
while(1) {
// 向右找
while(i + 1 < number.length && number[++i] < s) ;
// 向左找
while(j -1 > -1 && number[--j] > s) ;
if(i >= j)
break;
SWAP(number[i], number[j]);
}
number[left] = number[j];
number[j] = s;
quicksort(number, left, j-1); // 对左边进行递回
quicksort(number, j+1, right); // 对右边进行递回
}
}
18.快速排序法(二)
说明
在快速排序法(一)中,每次将最左边的元素设为轴,而之前曾经说过,快速排序法的加速在于轴的选择,在这个例子中,只将轴设定为中间的元素,依这个元素作基准进行比较,这可以增加快速排序法的效率。
解法
在这个例子中,取中间的元素s作比较,同样的先得右找比s大的索引i,然后找比s小的索引j,只要两边的索引还没有交会,就交换i 与j 的元素值,这次不用再进行轴的交换了,因为在寻找交换的过程中,轴位置的元素也会参与交换的动作,例如:
41 24 76 11 45 64 21 69 19 36
首先left为0,right为9,(left+right)/2 = 4(取整数的商),所以轴为索引4的位置,比较的元素是45,您往右找比45大的,往左找比45小的进行交换:
41 24 76* 11 [45] 64 21 69 19 36
41 24 36 11 45 64 21 69 19* 76
41 24 36 11 19 64* 21* 69 45 76
[41 24 36 11 19 21] [64 69 45 76]
完成以上之后,再初别对左边括号与右边括号的部份进行递回,如此就可以完成排序的目的。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
void quicksort(int[], int, int);
int main(void) {
int number[MAX] = {
0};
int i, num;
srand(time(NULL));
printf("排序前:");
for(i = 0; i < MAX; i++) {
number[i] = rand() % 100;
printf("%d ", number[i]);
}
quicksort(number, 0, MAX-1);
printf("\n排序后:");
for(i = 0; i < MAX; i++)
printf("%d ", number[i]);
printf("\n");
return 0;
}
void quicksort(int number[], int left, int right) {
int i, j, s;
if(left < right) {
s = number[(left+right)/2];
i = left - 1;
j = right + 1;
while(1) {
while(number[++i] < s) ; // 向右找
while(number[--j] > s) ; // 向左找
if(i >= j)
break;
SWAP(number[i], number[j]);
}
quicksort(number, left, i-1); // 对左边进行递回
quicksort(number, j+1, right); // 对右边进行递回
}
}
19.快速排序法(三)
说明
之前说过轴的选择是快速排序法的效率关键之一,在这边的快速排序法的轴选择方式更加快了快速排序法的效率,它是来自演算法名书Introduction to Algorithms 之中。
解法
先说明这个快速排序法的概念,它以最右边的值s作比较的标准,将整个数列分为三个部份,一个是小于s的部份,一个是大于s的部份,一个是未处理的部份,如下所示:
在排序的过程中,i 与j 都会不断的往右进行比较与交换,最后数列会变为以下的状态:
然后将s的值置于中间,接下来就以相同的步骤会左右两边的数列进行排序的动作,如下所示:
然后将s的值置于中间,接下来就以相同的步骤会左右两边的数列进行排序的动作,如下所示:
整个演算的过程,直接摘录书中的虚拟码来作说明:
QUICKSORT(A, p, r)
if p < r
then q <- PARTITION(A, p, r)
QUICKSORT(A, p, q-1)
QUICKSORT(A, q+1, r)
end QUICKSORT
PARTITION(A, p, r)
x <- A[r]
i <- p-1
for j <- p to r-1
do if A[j] <= x
then i <- i+1
exchange A[i]<->A[j]
exchange A[i+1]<->A[r]
return i+1
end PARTITION
一个实际例子的演算如下所示:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {
int t; t = x; x = y; y = t;}
int partition(int[], int, int);
void quicksort(int[], int, int);
int main(void) {
int number[MAX] = {
0};
int i, num;
srand(time(NULL));
printf("排序前:");
for(i = 0; i < MAX; i++) {
number[i] = rand() % 100;
printf("%d ", number[i]);
}
quicksort(number, 0, MAX-1);
printf("\n排序后:");
for(i = 0; i < MAX; i++)
printf("%d ", number[i]);
printf("\n");
return 0;
}
int partition(int number[], int left, int right) {
int i, j, s;
s = number[right];
i = left - 1;
for(j = left; j < right; j++) {
if(number[j] <= s) {
i++;
SWAP(number[i], number[j]);
}
}
SWAP(number[i+1], number[right]);
return i+1;
}
void quicksort(int number[], int left, int right) {
int q;
if(left < right) {
q = partition(number, left, right);
quicksort(number, left, q-1);
quicksort(number, q+1, right);
}
}
20.多维矩阵转一维矩阵
说明
有的时候,为了运算方便或资料储存的空间问题,使用一维阵列会比二维或多维阵列来得方便,例如上三角矩阵、下三角矩阵或对角矩阵,使用一维阵列会比使用二维阵列来得节省空间。
解法
以二维阵列转一维阵列为例,索引值由0开始,在由二维阵列转一维阵列时,我们有两种方式:「以列(Row)为主」或「以行(Column)为主」。由于C/C++、Java等的记忆体配置方式都是
以列为主,所以您可能会比较熟悉前者(Fortran的记忆体配置方式是以行为主)。以列为主的二维阵列要转为一维阵列时,是将二维阵列由上往下一列一列读入一维阵列,此时索引的对应公式如下所示,其中row与column是二维阵列索引,loc表示对应的一维阵列索引:loc = column + row行数以行为主的二维阵列要转为一维阵列时,是将二维阵列由左往右一行一读入一维阵列,此时索引的对应公式如下所示:
loc = row + column列数公式的推导您画图看看就知道了,如果是三维阵列,则公式如下所示,其中i(个数u1)、j(个数u2)、k(个数u3)分别表示三维阵列的三个索引:
以列为主:loc = iu2u3 + ju3 + k
以行为主:loc = ku1u2 + ju1 + i
更高维度的可以自行依此类推,但通常更高维度的建议使用其它资料结构(例如物件包装)会比较具体,也不易搞错。在C/C++中若使用到指标时,会遇到指标运算与记忆体空间位址的处理问题,此时也是用到这边的公式,不过必须在每一个项上乘上资料型态的记忆体大小。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
int arr1[3][4] = {
{
1, 2, 3, 4},
{
5, 6, 7, 8},
{
9, 10, 11, 12}};
int arr2[12] = {
0};
int row, column, i;
printf("原二维资料:\n");
for(row = 0; row < 3; row++) {
for(column = 0; column < 4; column++) {
printf("%4d", arr1[row][column]);
}
printf("\n");
}
printf("\n以列为主:");
for(row = 0; row < 3; row++) {
for(column = 0; column < 4; column++) {
i = column + row * 4;
arr2[i] = arr1[row][column];
}
}
for(i = 0; i < 12; i++)
printf("%d ", arr2[i]);
printf("\n以行为主:");
for(row = 0; row < 3; row++) {
for(column = 0; column < 4; column++) {
i = row + column * 3;
arr2[i] = arr1[row][column];
}
}
for(i = 0; i < 12; i++)
printf("%d ", arr2[i]);
printf("\n");
return 0;
}
21.上三角、下三角、对称矩阵
说明
上三角矩阵是矩阵在对角线以下的元素均为0,即Aij = 0,i > j,例如:
1 2 3 4 5
0 6 7 8 9
0 0 10 11 12
0 0 0 13 14
0 0 0 0 15
下三角矩阵是矩阵在对角线以上的元素均为0,即Aij = 0,i < j,例如:
1 0 0 0 0
2 6 0 0 0
3 7 10 0 0
4 8 11 13 0
5 9 12 14 15
对称矩阵是矩阵元素对称于对角线,例如:
1 2 3 4 5
2 6 7 8 9
3 7 10 11 12
4 8 11 13 14
5 9 12 14 15
上三角或下三角矩阵也有大部份的元素不储存值(为0),我们可以将它们使用一维阵列来储存以节省储存空间,而对称矩阵因为对称于对角线,所以可以视为上三角或下三角矩阵来储存。
解法
假设矩阵为nxn,为了计算方便,我们让阵列索引由1开始,上三角矩阵化为一维阵列,若以列为主,其公式为:loc = n*(i-1) - i*(i-1)/2 + j化为以行为主,其公式为:loc = j*(j-1)/2 + i下三角矩阵化为一维阵列,若以列为主,其公式为:loc = i*(i-1)/2 + j若以行为主,其公式为:loc = n*(j-1) - j*(j-1)/2 + i公式的导证其实是由等差级数公式得到,您可以自行绘图并看看就可以导证出来,对于C/C++或Java等索引由0开始的语言来说,只要将i与j各加1,求得loc之后减1即可套用以上的公式。
#include <stdio.h>
#include <stdlib.h>
#define N 5
int main(void) {
int arr1[N][N] = {
{
1, 2, 3, 4, 5},
{
0, 6, 7, 8, 9},
{
0, 0, 10, 11, 12},
{
0, 0, 0, 13, 14},
{
0, 0, 0, 0, 15}};
int arr2[N*(1+N)/2] = {
0};
int i, j, loc = 0;
printf("原二维资料:\n");
for(i = 0; i < N; i++) {
for(j = 0; j < N; j++) {
printf("%4d", arr1[i][j]);
}
printf("\n");
}
printf("\n以列为主:");
for(i = 0; i < N; i++) {
for(j = 0; j < N; j++) {
if(arr1[i][j] != 0)
arr2[loc++] = arr1[i][j];
}
}
for(i = 0; i < N*(1+N)/2; i++)
printf("%d ", arr2[i]);
printf("\n输入索引(i, j):");
scanf("%d, %d", &i, &j);
loc = N*i - i*(i+1)/2 + j;
printf("(%d, %d) = %d", i, j, arr2[loc]);
printf("\n");
return 0;
}
22.m元素集合的n个元素子集
说明
假设有个集合拥有m个元素,任意的从集合中取出n个元素,则这n个元素所形成的可能子集有那些?
解法
假设有5个元素的集点,取出3个元素的可能子集如下:
{1 2 3}、{1 2 4 }、{1 2 5}、{1 3 4}、{1 3 5}、{1 4 5}、{2 3 4}、{2 3 5}、{2 4 5}、{3 4 5}
这些子集已经使用字典顺序排列,如此才可以观察出一些规则:
- 如果最右一个元素小于m,则如同码表一样的不断加1
- 如果右边一位已至最大值,则加1的位置往左移
- 每次加1的位置往左移后,必须重新调整右边的元素为递减顺序
所以关键点就在于哪一个位置必须进行加1的动作,到底是最右一个位置要加1?还是其它的位置?在实际撰写程式时,可以使用一个变数positon来记录加1的位置,position的初值设定为n-1,因为我们要使用阵列,而最右边的索引值为最大的n-1,在position位置的值若小于m就不断加1,如果大于m了,position就减1,也就是往左移一个位置;由于位置左移后,右边的元素会经过调整,所以我们必须检查最右边的元素是否小于m,如果是,则position调整回n-1,如果不是,则positon维持不变。
#include <stdio.h>
#include <stdlib.h>
#define MAX 20
int main(void) {
int set[MAX];
int m, n, position;
int i;
printf("输入集合个数m:");
scanf("%d", &m);
printf("输入取出元素n:");
scanf("%d", &n);
for(i = 0; i < n; i++)
set[i] = i + 1;
// 显示第一个集合
for(i = 0; i < n; i++)
printf("%d ", set[i]);
putchar('\n');
position = n - 1;
while(1) {
if(set[n-1] == m)
position--;
else
position = n - 1;
set[position]++;
// 调整右边元素
for(i = position + 1; i < n; i++)
set[i] = set[i-1] + 1;
for(i = 0; i < n; i++)
printf("%d ", set[i]);
putchar('\n');
if(set[0] >= m - n + 1)
break;
}
return 0;
}
23.数字拆解
说明
这个题目来自于数字拆解,我将之改为C语言的版本,并加上说明。
题目是这样的:
3 = 2+1 = 1+1+1 所以3有三种拆法
4 = 3 + 1 = 2 + 2 = 2 + 1 + 1 = 1 + 1 + 1 + 1 共五种
5 = 4 + 1 = 3 + 2 = 3 + 1 + 1 = 2 + 2 + 1 = 2 + 1 + 1 + 1 = 1 + 1 +1 +1 +1
共七种依此类推,请问一个指定数字NUM的拆解方法个数有多少个?
解法
我们以上例中最后一个数字5的拆解为例,假设f( n )为数字n的可拆解方式个数,而f(x, y)为使用y以下的数字来拆解x的方法个数,则观察:
5 = 4 + 1 = 3 + 2 = 3 + 1 + 1 = 2 + 2 + 1 = 2 + 1 + 1 + 1 = 1 + 1 +1 +1 +1
使用函式来表示的话:
f(5) = f(4, 1) + f(3,2) + f(2,3) + f(1,4) + f(0,5)
其中f(1, 4) = f(1, 3) + f(1, 2) + f(1, 1),但是使用大于1的数字来拆解1没有意义,所以f(1, 4) =f(1, 1),而同样的,f(0, 5)会等于f(0, 0),所以:
f(5) = f(4, 1) + f(3,2) + f(2,3) + f(1,1) + f(0,0)
依照以上的说明,使用动态程式规画(Dynamic programming)来进行求解,其中f(4,1)其实就是f(5-1, min(5-1,1)),f(x, y)就等于f(n-y, min(n-x, y)),其中n为要拆解的数字,而min()表示取两
者中较小的数。使用一个二维阵列表格table[x][y]来表示f(x, y),刚开始时,将每列的索引0与索引1元素值设定为1,因为任何数以0以下的数拆解必只有1种,而任何数以1以下的数拆解也必只有1种:
for(i = 0; i < NUM +1; i++){
table[i][0] = 1; // 任何数以0以下的数拆解必只有1种
table[i][1] = 1; // 任何数以1以下的数拆解必只有1种
}接下来就开始一个一个进行拆解了,如果数字为NUM,则我们的阵列维度大小必须为NUM x
(NUM/2+1),以数字10为例,其维度为10 x 6我们的表格将会如下所示:
1 1 0 0 0 0
1 1 0 0 0 0
1 1 2 0 0 0
1 1 2 3 0 0
1 1 3 4 5 0
1 1 3 5 6 7
1 1 4 7 9 0
1 1 4 8 0 0
1 1 5 0 0 0
1 1 0 0 0 0
#include <stdio.h>
#include <stdlib.h>
#define NUM 10 // 要拆解的数字
#define DEBUG 0
int main(void) {
int table[NUM][NUM/2+1] = {
0}; // 动态规画表格
int count = 0;
int result = 0;
int i, j, k;
printf("数字拆解\n");
printf("3 = 2+1 = 1+1+1 所以3有三种拆法\n");
printf("4 = 3 + 1 = 2 + 2 = 2 + 1 + 1 = 1 + 1 + 1 + 1");
printf("共五种\n");
printf("5 = 4 + 1 = 3 + 2 = 3 + 1 + 1");
printf(" = 2 + 2 + 1 = 2 + 1 + 1 + 1 = 1 + 1 +1 +1 +1");
printf("共七种\n");
printf("依此类推,求%d 有几种拆法?", NUM);
// 初始化
for(i = 0; i < NUM; i++){
table[i][0] = 1; // 任何数以0以下的数拆解必只有1种
table[i][1] = 1; // 任何数以1以下的数拆解必只有1种
}
// 动态规划
for(i = 2; i <= NUM; i++){
for(j = 2; j <= i; j++){
if(i + j > NUM) // 大于NUM
continue;
count = 0;
for(k = 1 ; k <= j; k++){
count += table[i-k][(i-k >= k) ? k : i-k];
}
table[i][j] = count;
}
}
// 计算并显示结果
for(k = 1 ; k <= NUM; k++)
result += table[NUM-k][(NUM-k >= k) ? k : NUM-k];
printf("\n\nresult: %d\n", result);
if(DEBUG) {
printf("\n除错资讯\n");
for(i = 0; i < NUM; i++) {
for(j = 0; j < NUM/2+1; j++)
printf("%2d", table[i][j]);
printf("\n");
}
}
return 0;
}
边栏推荐
- 【信号与系统】
- Go zero micro service practical series (IX. ultimate optimization of seckill performance)
- C language instance_ five
- Today's question -2022/7/4 modify string reference type variables in lambda body
- JS es5 peut également créer des constantes?
- Taro2.* applet configuration sharing wechat circle of friends
- Long press the button to execute the function
- [signal and system]
- 405 method not allowed appears when the third party jumps to the website
- AcWing 1148. 秘密的牛奶运输 题解(最小生成树)
猜你喜欢
一起看看matlab工具箱内部是如何实现BP神经网络的

Yunna | work order management measures, how to carry out work order management
Can't you understand the code of linked list in C language? An article allows you to grasp the secondary pointer and deeply understand the various forms of parameter passing in the function parameter
shell脚本快速统计项目代码行数
从底层结构开始学习FPGA----FIFO IP的定制与测试
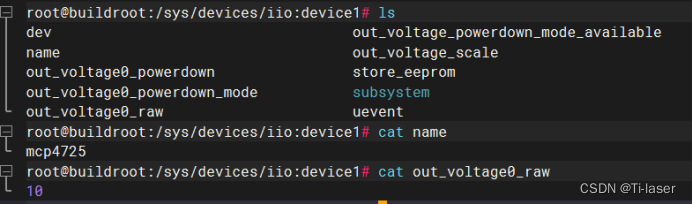
Transplant DAC chip mcp4725 to nuc980
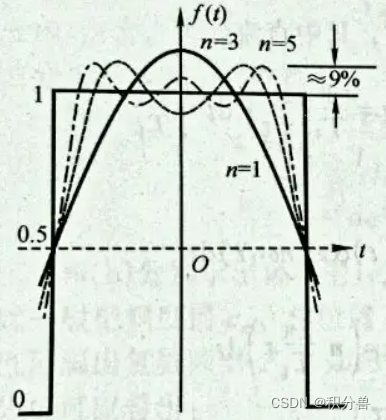
【信号与系统】
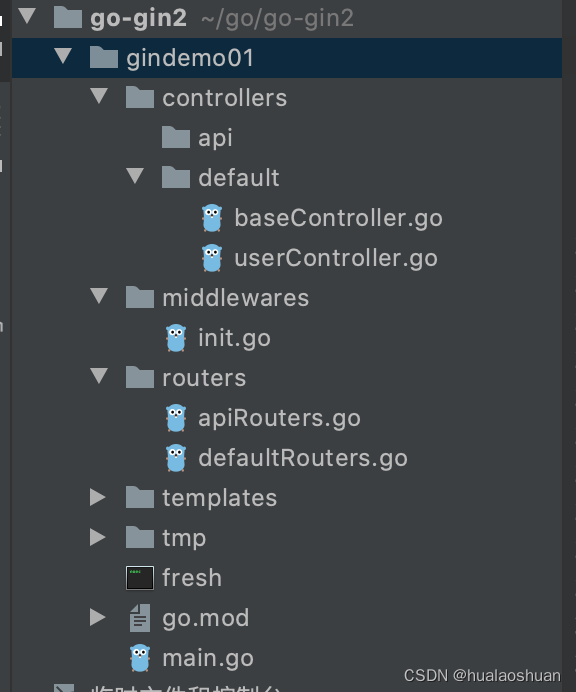
Gin introduction practice

黑马笔记---创建不可变集合与Stream流
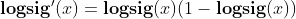
The difference between Tansig and logsig. Why does BP like to use Tansig
随机推荐
AcWing 346. Solution to the problem of water splashing festival in the corridor (deduction formula, minimum spanning tree)
Drag to change order
ZOJ Problem Set – 2563 Long Dominoes 【如压力dp】
Use nodejs to determine which projects are packaged + released
mysqlbackup 还原特定的表
454-百度面经1
Mysqlbackup restores specific tables
grep查找进程时,忽略grep进程本身
盒子拉伸拉扯(左右模式)
Yunna - work order management system and process, work order management specification
Telnet,SSH1,SSH2,Telnet/SSL,Rlogin,Serial,TAPI,RAW
交叉验证如何防止过拟合
对C语言数组的再认识
Appium foundation - appium inspector positioning tool (I)
js如何快速创建一个长度为 n 的数组
hdu 4661 Message Passing(木DP&amp;组合数学)
Dark horse notes - exception handling
Transplant DAC chip mcp4725 to nuc980
Table table setting fillet
Let's see how to realize BP neural network in Matlab toolbox