当前位置:网站首页>Go zero micro service practical series (IX. ultimate optimization of seckill performance)
Go zero micro service practical series (IX. ultimate optimization of seckill performance)
2022-07-07 01:16:00 【Microservice practice】
In the last article, message queue was introduced to cut the peak of spike traffic , We use Kafka, It seems to work well , But there are still many hidden dangers , If these hidden dangers are not optimized and disposed , Then there may be news accumulation after the spike buying activity starts 、 Delay in consumption 、 Data inconsistency 、 Even problems such as service crash , Then the consequences can be imagined . In this article, we will work together to solve these hidden dangers .
Bulk data aggregation
stay SeckillOrder In this method , Every second kill rush purchase request is often Kafka Send a message in . If 10 million users rush to buy at the same time , Even if we have made various current limiting strategies , In an instant, millions of messages may be sent Kafka, Will produce a large number of Networks IO And disk IO cost , Everybody knows Kafka Is a log based messaging system , Although writing messages is mostly in order IO, But when a large number of messages are written at the same time, it may still be unbearable .
How to solve this problem ? The answer is to aggregate messages . Sending a message before will generate a network IO And primary disk IO, After we do message aggregation , Like polymerization 100 Send a message to Kafka, This is the time 100 A message will generate a network IO And disk IO, To the whole Kafka The throughput and performance of is a great improvement . In fact, this is an idea of small package aggregation , Or call it Batch Or the idea of batch . This kind of thought can also be seen everywhere , For example, we use Mysql When inserting batch data , You can go through one SQL Statement execution rather than loop by loop insertion , also Redis Of Pipeline Operation and so on .
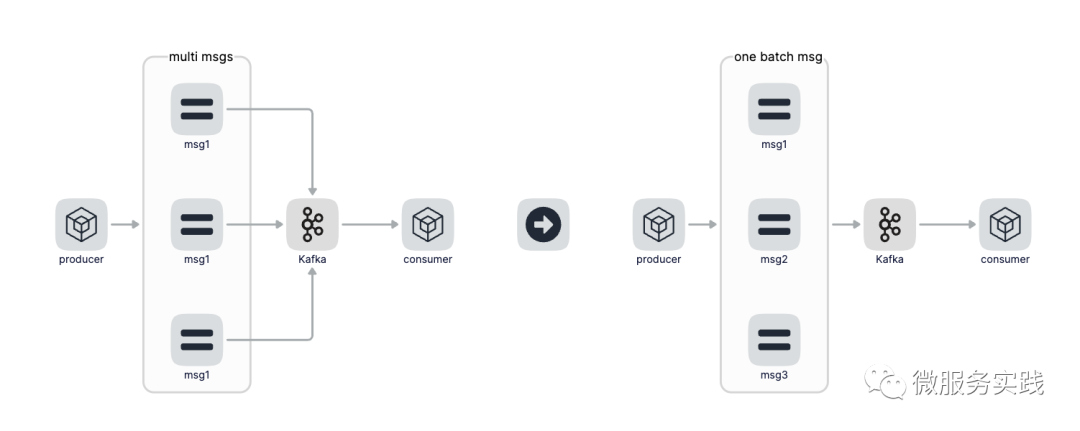
Then how to aggregate , What is the aggregation strategy ? The aggregation strategy has two dimensions: the number of aggregated messages and the aggregation time , For example, aggregate messages reach 100 We'll go to Kafka Send it once , This number can be configured , If you can't reach it all the time 100 What about this message ? Through the polymerization time to reveal , The aggregation time can also be configured , For example, configure the aggregation time to 1 Second , That is, no matter how many messages are aggregated at present, as long as the aggregation time reaches 1 second , Then go to Kafka Send data once . The relationship between the number of aggregations and the aggregation time is or , That is, as long as one condition is satisfied .
Here we provide a tool to aggregate data in batches Batcher, The definition is as follows
type Batcher struct {
opts options
Do func(ctx context.Context, val map[string][]interface{})
Sharding func(key string) int
chans []chan *msg
wait sync.WaitGroup
}
Do Method : When the aggregation condition is met, it will execute Do Method , among val Parameters are aggregated data
Sharding Method : adopt Key Conduct sharding, same key Messages are written to the same channel in , Be the same goroutine Handle
stay merge There are two triggers in the method to execute Do The conditions of the method , First, when the number of aggregated data is greater than or equal to the set number , The second is when the timer set is triggered
The code implementation is relatively simple , The following is the specific implementation :
type msg struct {
key string
val interface{}
}
type Batcher struct {
opts options
Do func(ctx context.Context, val map[string][]interface{})
Sharding func(key string) int
chans []chan *msg
wait sync.WaitGroup
}
func New(opts ...Option) *Batcher {
b := &Batcher{}
for _, opt := range opts {
opt.apply(&b.opts)
}
b.opts.check()
b.chans = make([]chan *msg, b.opts.worker)
for i := 0; i < b.opts.worker; i++ {
b.chans[i] = make(chan *msg, b.opts.buffer)
}
return b
}
func (b *Batcher) Start() {
if b.Do == nil {
log.Fatal("Batcher: Do func is nil")
}
if b.Sharding == nil {
log.Fatal("Batcher: Sharding func is nil")
}
b.wait.Add(len(b.chans))
for i, ch := range b.chans {
go b.merge(i, ch)
}
}
func (b *Batcher) Add(key string, val interface{}) error {
ch, msg := b.add(key, val)
select {
case ch <- msg:
default:
return ErrFull
}
return nil
}
func (b *Batcher) add(key string, val interface{}) (chan *msg, *msg) {
sharding := b.Sharding(key) % b.opts.worker
ch := b.chans[sharding]
msg := &msg{key: key, val: val}
return ch, msg
}
func (b *Batcher) merge(idx int, ch <-chan *msg) {
defer b.wait.Done()
var (
msg *msg
count int
closed bool
lastTicker = true
interval = b.opts.interval
vals = make(map[string][]interface{}, b.opts.size)
)
if idx > 0 {
interval = time.Duration(int64(idx) * (int64(b.opts.interval) / int64(b.opts.worker)))
}
ticker := time.NewTicker(interval)
for {
select {
case msg = <-ch:
if msg == nil {
closed = true
break
}
count++
vals[msg.key] = append(vals[msg.key], msg.val)
if count >= b.opts.size {
break
}
continue
case <-ticker.C:
if lastTicker {
ticker.Stop()
ticker = time.NewTicker(b.opts.interval)
lastTicker = false
}
}
if len(vals) > 0 {
ctx := context.Background()
b.Do(ctx, vals)
vals = make(map[string][]interface{}, b.opts.size)
count = 0
}
if closed {
ticker.Stop()
return
}
}
}
func (b *Batcher) Close() {
for _, ch := range b.chans {
ch <- nil
}
b.wait.Wait()
}
When using, you need to create a Batcher, Then define Batcher Of Sharding Methods and Do Method , stay Sharding In the method, we use ProductID Deliver the aggregation of different commodities to different goroutine In dealing with , stay Do In the method, we send the aggregated data to Kafka, The definition is as follows :
b := batcher.New(
batcher.WithSize(batcherSize),
batcher.WithBuffer(batcherBuffer),
batcher.WithWorker(batcherWorker),
batcher.WithInterval(batcherInterval),
)
b.Sharding = func(key string) int {
pid, _ := strconv.ParseInt(key, 10, 64)
return int(pid) % batcherWorker
}
b.Do = func(ctx context.Context, val map[string][]interface{}) {
var msgs []*KafkaData
for _, vs := range val {
for _, v := range vs {
msgs = append(msgs, v.(*KafkaData))
}
}
kd, err := json.Marshal(msgs)
if err != nil {
logx.Errorf("Batcher.Do json.Marshal msgs: %v error: %v", msgs, err)
}
if err = s.svcCtx.KafkaPusher.Push(string(kd)); err != nil {
logx.Errorf("KafkaPusher.Push kd: %s error: %v", string(kd), err)
}
}
s.batcher = b
s.batcher.Start()
stay SeckillOrder The method is no longer to go every time a request is made Kafka Deliver a message in , But first through batcher Provided Add Method to add to Batcher Wait until the polymerization conditions are met before going Kafka China Post .
err = l.batcher.Add(strconv.FormatInt(in.ProductId, 10), &KafkaData{Uid: in.UserId, Pid: in.ProductId})
if err!= nil {
logx.Errorf("l.batcher.Add uid: %d pid: %d error: %v", in.UserId, in.ProductId, err)
}
Reduce the consumption delay of messages
Through the idea of batch message processing , We provide Batcher Tools , Improved performance , But this is mainly for the production side . When we consume data in batches , You still need to process data serially one by one , Is there any way to accelerate consumption and reduce the delay of consumption news ? There are two options :
Increase the number of consumers Increase the parallelism of message processing in a consumer
Because in Kafka in , One Topci You can configure multiple Partition, The data will be written to multiple partitions on average or in the manner specified by the producer , So when consuming ,Kafka Agree that a partition can only be consumed by one consumer , Why do you design it like this ? What I understand is that if there are multiple Consumer Consume data of a partition at the same time , Then you need to lock when operating this consumption progress , It has a great impact on performance . So when the number of consumers is less than the number of partitions , We can increase the number of consumers to increase the message processing capacity , But when the number of consumers is greater than the number of partitions, it is meaningless to continue to increase the number of consumers .
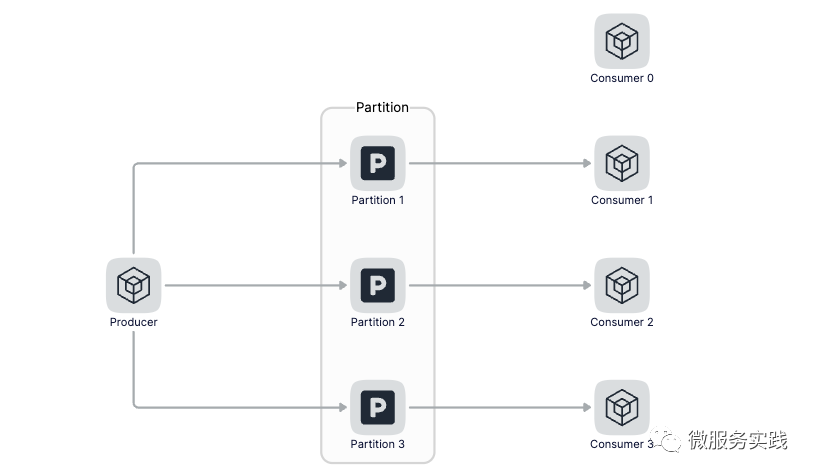
Don't add Consumer When , Can be in the same Consumer Improve the parallelism of processing messages , That is, through multiple goroutine To parallel consumption data , Let's see how to pass multiple goroutine To consume news .
stay Service In the definition of msgsChan,msgsChan by Slice,Slice The length of indicates how many goroutine Processing data in parallel , The initialization is as follows :
func NewService(c config.Config) *Service {
s := &Service{
c: c,
ProductRPC: product.NewProduct(zrpc.MustNewClient(c.ProductRPC)),
OrderRPC: order.NewOrder(zrpc.MustNewClient(c.OrderRPC)),
msgsChan: make([]chan *KafkaData, chanCount),
}
for i := 0; i < chanCount; i++ {
ch := make(chan *KafkaData, bufferCount)
s.msgsChan[i] = ch
s.waiter.Add(1)
go s.consume(ch)
}
return s
}
from Kafka After data consumption , Deliver data to Channel in , Pay attention to the delivery of messages according to the commodity id do Sharding, This can ensure that in the same Consumer The processing of the same commodity in is serial , Serial data processing will not lead to data competition caused by concurrency
func (s *Service) Consume(_ string, value string) error {
logx.Infof("Consume value: %s\n", value)
var data []*KafkaData
if err := json.Unmarshal([]byte(value), &data); err != nil {
return err
}
for _, d := range data {
s.msgsChan[d.Pid%chanCount] <- d
}
return nil
}
We defined chanCount individual goroutine Processing data at the same time , Every channel The length of is defined as bufferCount, The method of parallel processing data is consume, as follows :
func (s *Service) consume(ch chan *KafkaData) {
defer s.waiter.Done()
for {
m, ok := <-ch
if !ok {
log.Fatal("seckill rmq exit")
}
fmt.Printf("consume msg: %+v\n", m)
p, err := s.ProductRPC.Product(context.Background(), &product.ProductItemRequest{ProductId: m.Pid})
if err != nil {
logx.Errorf("s.ProductRPC.Product pid: %d error: %v", m.Pid, err)
return
}
if p.Stock <= 0 {
logx.Errorf("stock is zero pid: %d", m.Pid)
return
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
return
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
}
}
}
How to guarantee that it will not oversold
When the second kill starts , A large number of users click the second kill button on the product details page , There will be a large number of concurrent requests to query inventory , Once a request finds inventory , Then the system will deduct inventory . then , The system generates the actual order , And carry out subsequent treatment . If the request does not find inventory , It will return , Users usually continue to click the second kill button , Continue to query inventory . Simply speaking , There are three operations in this stage : Check stock , Inventory deduction 、 And order processing . Because every second kill request will query the inventory , And the request only finds that there is a surplus in inventory , Subsequent inventory deduction and order processing will be executed , therefore , The biggest concurrent pressure in this stage is the inventory check operation .
In order to support a large number of highly concurrent inventory inspection requests , We need to use Redis Store inventory separately . that , Whether inventory deduction and order processing can be handed over to Mysql To deal with it ? Actually , Order processing can be performed in the database , However, inventory deduction cannot be entrusted to Mysql Deal directly with . Because it comes to the actual order processing , The pressure of asking is not much , The database can fully support these order processing requests . Then why can't inventory deduction be performed directly in the database ? This is because , Once the request is found in stock , It means that the request is eligible for purchase , Then the order will be placed , At the same time, the inventory will be reduced by one , At this time, if you directly operate the database to reduce inventory, it may lead to oversold .
Why does directly operating the database to reduce inventory lead to oversold ? Because the processing speed of the database is slow , Unable to update inventory balance in time , This will cause a large number of requests to query inventory to read the old inventory value , And place an order , At this point, the order quantity is greater than the actual inventory , Cause oversold . therefore , It needs to be directly in Redis Make inventory deduction in , The specific operation is , When the inventory is checked , Once there is a surplus in stock , We'll be right there Redis Less inventory , meanwhile , In order to avoid the request to query the old inventory value , Inventory check and inventory deduction need to ensure atomicity .
We use Redis Of Hash To store inventory ,total Total inventory ,seckill Is the number that has been killed in seconds , In order to ensure the atomicity of inventory query and inventory reduction , We use Lua Scripts perform atomic operations , Return when the second kill is less than the inventory 1, It means that the second kill is successful , Otherwise return to 0, It means that the second kill failed , The code is as follows :
const (
luaCheckAndUpdateScript = `
local counts = redis.call("HMGET", KEYS[1], "total", "seckill")
local total = tonumber(counts[1])
local seckill = tonumber(counts[2])
if seckill + 1 <= total then
redis.call("HINCRBY", KEYS[1], "seckill", 1)
return 1
end
return 0
`
)
func (l *CheckAndUpdateStockLogic) CheckAndUpdateStock(in *product.CheckAndUpdateStockRequest) (*product.CheckAndUpdateStockResponse, error) {
val, err := l.svcCtx.BizRedis.EvalCtx(l.ctx, luaCheckAndUpdateScript, []string{stockKey(in.ProductId)})
if err != nil {
return nil, err
}
if val.(int64) == 0 {
return nil, status.Errorf(codes.ResourceExhausted, fmt.Sprintf("insufficient stock: %d", in.ProductId))
}
return &product.CheckAndUpdateStockResponse{}, nil
}
func stockKey(pid int64) string {
return fmt.Sprintf("stock:%d", pid)
}
Corresponding seckill-rmq The code is modified as follows :
func (s *Service) consume(ch chan *KafkaData) {
defer s.waiter.Done()
for {
m, ok := <-ch
if !ok {
log.Fatal("seckill rmq exit")
}
fmt.Printf("consume msg: %+v\n", m)
_, err := s.ProductRPC.CheckAndUpdateStock(context.Background(), &product.CheckAndUpdateStockRequest{ProductId: m.Pid})
if err != nil {
logx.Errorf("s.ProductRPC.CheckAndUpdateStock pid: %d error: %v", m.Pid, err)
return
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
return
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
}
}
}
Come here , We have learned how to use atomic Lua Script to check and deduct inventory . In fact, to ensure the atomicity of inventory inspection and deduction , There is another way , That is to use distributed locks .
There are many ways to implement distributed locks , Can be based on Redis、Etcd wait , use Redis There are many articles about implementing distributed locks , Those who are interested can search for references by themselves . Here is a brief introduction based on Etcd To implement distributed locking . To simplify distributed locks 、 Distributed election 、 Implementation of distributed transactions ,etcd The community offers a program called concurrency To help us make it easier 、 Use distributed locks correctly . Its implementation is very simple , The main process is as follows :
First, through concurrency.NewSession Method creation Session, Essentially, it creates a TTL by 10 Of Lease obtain Session After the object , adopt concurrency.NewMutex Create a mutex object , It includes Lease、key prefix Etc Then I heard it mutex Object's Lock Method attempts to acquire the lock Finally through mutex Object's Unlock Method release lock
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
session, err := concurrency.NewSession(cli, concurrency.WithTTL(10))
if err != nil {
log.Fatal(err)
}
defer session.Close()
mux := concurrency.NewMutex(session, "lock")
if err := mux.Lock(context.Background()); err != nil {
log.Fatal(err)
}
if err := mux.Unlock(context.Background()); err != nil {
log.Fatal(err)
}
Conclusion
This article mainly aims to continue to optimize the seckill function . stay Kafka The production side of the message has optimized the delivery of bulk message aggregation ,Batch Ideas are often used in actual production and development , I hope you can use it flexibly , On the consumer side of the message, increase the parallelism to improve the throughput , This is also a common optimization method to improve performance . Finally, it introduces the reasons that may lead to oversold , And give the corresponding solutions . meanwhile , Based on Etcd Distributed locks for , Data competition often occurs in distributed services , Generally, it can be solved through distributed locks , However, the introduction of distributed locks will inevitably lead to performance degradation , therefore , We also need to consider whether we need to introduce distributed locks in combination with the actual situation .
I hope this article can help you , thank you .
Every Monday 、 Thursday update
Code warehouse : https://github.com/zhoushuguang/lebron
Project address
https://github.com/zeromicro/go-zero
Welcome to use go-zero and star Support us !
WeChat ac group
Focus on 『 Microservice practice 』 Official account and click Communication group Get community group QR code .
边栏推荐
- [hfctf2020]babyupload session parsing engine
- table表格设置圆角
- "Exquisite store manager" youth entrepreneurship incubation camp - the first phase of Shunde market has been successfully completed!
- mysql: error while loading shared libraries: libtinfo. so. 5: cannot open shared object file: No such
- [牛客] [NOIP2015]跳石头
- Periodic flash screen failure of Dell notebook
- windows安装mysql8(5分钟)
- Gnet: notes on the use of a lightweight and high-performance go network framework
- ClickHouse字段分组聚合、按照任意时间段粒度查询SQL
- Neon Optimization: performance optimization FAQ QA
猜你喜欢
HMM 笔记
Can the system hibernation file be deleted? How to delete the system hibernation file

"Exquisite store manager" youth entrepreneurship incubation camp - the first phase of Shunde market has been successfully completed!

Building a dream in the digital era, the Xi'an station of the city chain science and Technology Strategy Summit ended smoothly

Analysis of mutex principle in golang
Activereportsjs 3.1 Chinese version | | | activereportsjs 3.1 English version

Chenglian premium products has completed the first step to enter the international capital market by taking shares in halber international
系统休眠文件可以删除吗 系统休眠文件怎么删除

阿里云中mysql数据库被攻击了,最终数据找回来了
Send template message via wechat official account
随机推荐
What kind of experience is it to realize real-time collaboration in jupyter
重上吹麻滩——段芝堂创始人翟立冬游记
THREE.AxesHelper is not a constructor
动态规划思想《从入门到放弃》
迈动互联中标北京人寿保险,助推客户提升品牌价值
微信公众号发送模板消息
Spark TPCDS Data Gen
Installation and testing of pyflink
table表格设置圆角
ClickHouse字段分组聚合、按照任意时间段粒度查询SQL
接收用户输入,身高BMI体重指数检测小业务入门案例
Let's talk about 15 data source websites I often use
In rails, when the resource creation operation fails and render: new is called, why must the URL be changed to the index URL of the resource?
2022 Google CTF segfault Labyrinth WP
Dell笔记本周期性闪屏故障
Tencent cloud webshell experience
资产安全问题或制约加密行业发展 风控+合规成为平台破局关键
2022 Google CTF SEGFAULT LABYRINTH wp
tensorflow 1.14指定gpu运行设置
NEON优化:性能优化常见问题QA