当前位置:网站首页>NEON优化:性能优化经验总结
NEON优化:性能优化经验总结
2022-07-06 17:22:00 【来知晓】
NEON优化系列文章:
本文总结常用的NEON优化技巧及重要参考资料。

photo from 《Practical approach to Arm Neon Optimization》,展示了各领域如NEON优化的优秀示例代码库,Neon-enabled libraries。
优化技巧
高频常用
热点函数涉及到大量IO读写操作时,数据的内存地址尽量与NEON数组或系统位数对齐,如32位对齐,可降低访问开销
跑demo得到profile,看开销占比Top5,必须对其优化一版
重点优先搞NEON指令并行计算,能大幅降低开销
for循环
- 循环数字不大优先用4排展开;大循环用8排并行计算
- 循环变量i,尽量设置成基本数据类型,如32位
- 如for循环中if优化,if中对cnt进行计数,用4个寄存器存,末尾再将4个寄存器值相加
- 循环时用减法计数器时可降开销
- 如: for (b = 0; b < num; b++)
- 改为:for (b = 0; b < num - 3; b += 4)
- 可再改:for (b = num - 1; b - 3 >= 0; b -= 4)
- 可再改:for (b = num - 1; b >= 3; b -= 4)
- 务必记得读写数据时,将坐标前移相应位次,原读取:
cf[b], 今读取:cf[b - 3]
数组索引取值
- 数组索引以及索引内部涉及运算的,尽量换成指针偏移加减来做
- 避免大范围索引跳跃,减少cache miss,具体例子见:矩阵乘优化,分块成4*4处理
内存使用
- 优先用局部变量,而非malloc堆内存,减少cache miss
- 针对具体变量类型,手动for循环并行拷贝值,可能比memcpy()函数更高效,因为memcpy内部还涉及大量判断,以保证平台兼容性
- 涉及IO读写时,软仿数据可能无法准确反映硬仿结果,应以硬仿为准,软仿无法模拟最新芯片层面优化
指令运算
- 矩阵乘场景,在不大幅增加寄存器变量的前提下,外部的A也最好并行多读几路数据进来,跟B的各列运算,减少B各列的读取次数
- 乘加指令,add和mul可以合并为mla,一条指令完成乘加操作
算法角度
- 观察热点函数的算法,从算法层面优化时间复杂度,进行等效实现
- 数据是否有序,for循环是否可以变成二分
- 冒泡排序是否可以变成归并
- 是否有冗余逻辑,冗余变量计算
- 观察热点函数的算法,从算法层面优化时间复杂度,进行等效实现
细节
- 差1问题:注意再注意!
- 发现循环中并行计算时常有:
-4, +=4组合问题,会导致结尾处哪怕有4个值也只能单独计算。 - 应改为:
-3,+=4;其他类似:-7, +=8;不管是<=、<或>=场景。 - 举例:
- 原始:
for (i = 0; i < size; i++) - 并行:
for (i = 0; i < size - 3; i += 4) - 扫尾:
for (; i < size; i ++)
- 原始:
- 原理:以4路为例
- 并行写法,-3的目的是保证从i开始往后能有4个可用值,+4的目的是对i进行迭代,每4路前进一次
- 扫尾写法,加上扫尾的目的是为了处理size不能被4整除的场景,末尾不足4个的剩余值单独处理
- 发现循环中并行计算时常有:
- NEON优化宏开关
- 常用
#ifndef XX_NO_NEON宏开关来控制NEON开关,便于回退NEON优化版本来debug
- 常用
- 差1问题:注意再注意!
编译选项
初始编译选项:O0,Omemory(优化内存),开内联
优化编译选项:O2,Otime(优化时间),不开内联;一般开O2
建议基线优化时,尽量选
不开内联以改善视图,以便观察热点函数中实际大头开销所在- 开了内联,容易出现,有的大头开销函数I被内联到X函数中,但仅看X函数半天看不出哪里可以优化的
- 如关内联,则大头开销函数I则远超X函数,成为Top热点开销函数,便于优化分析
尽量能用O3优化就用O3,不能的部分代码单独用O2优化编译,然后链接该模块,再整体一起O3编译
不要轻易restore default编译设置,否则会导致所有配置失效,如编译平台、编译选项
注意事项
开销计算
- 算每帧开销时,要确认每帧时长是10ms、20ms,修改对应的帧长时间
- RVDS中计算的MCPS本质为MIPS,注意与硬仿的结果进行区分
其他问题
用#ifndef XX_NO_NEON来定义有关NEON的宏,用意何在,为啥不用#ifdef XX_NEON?
#ifndef ALG_NO_NEON
// opt_neon_code
...
#else
// origin code
...
#endif
- ifndef的意义在于,因为基线输出查看属于低频操作,而查看每次NEON优化的进展是高频操作,所以默认走NEON优化,而查看基线时只需要添加对应宏即可。
- 当然,如习惯
#ifdef XX_NEON也无不可,不影响效果。
相关资源
附学习过程中用到的好资源,最后一个参考链接是彩蛋,涉及:Optimizing Software in C++ - Agner Fog - PDF,C++软件性能优化。
这本书是所有C++程序员都应该要读的一本书,它事无巨细地从语言层面、编译器层面、内存访问层面、多线程层面、CPU层面讲述了如何对软件性能调优,是一本经典的电子书,欢迎进阶阅读!
资料链接汇总:
- google keywords: neon optimization,可获取大量有关资源
- NEON优化ARM官方介绍,link
- NEON优化ARM官方介绍文章翻译,link
- ARM官方相关程序员Neon编程指南,link
- Optimizing C Code with Neon Intrinsics, link
- ARM Neon Intrinsics 学习指北:从入门、进阶到学个通透,link
- How to improve software performance with NEON, link
- ittiam:印度以太公司专业优化资料,link1,link2
- AI神经网络CNN中im2col矩阵卷积核的计算优化,link
- 谷歌开发cmath.h的NEON优化,库链接:link,库说明:link
- 重磅!性能优化PDF:Optimizing software in C++,An optimization guide for Windows, Linux, and Mac platforms,link
边栏推荐
- Chapter 5 DML data operation
- Dynamic planning idea "from getting started to giving up"
- Provincial and urban level three coordinate boundary data CSV to JSON
- 阿里云中mysql数据库被攻击了,最终数据找回来了
- Niuke cold training camp 6B (Freund has no green name level)
- 【JVM调优实战100例】05——方法区调优实战(下)
- ESP Arduino (IV) PWM waveform control output
- 建立自己的网站(17)
- from .cv2 import * ImportError: libGL.so.1: cannot open shared object file: No such file or direc
- Chapter II proxy and cookies of urllib Library
猜你喜欢
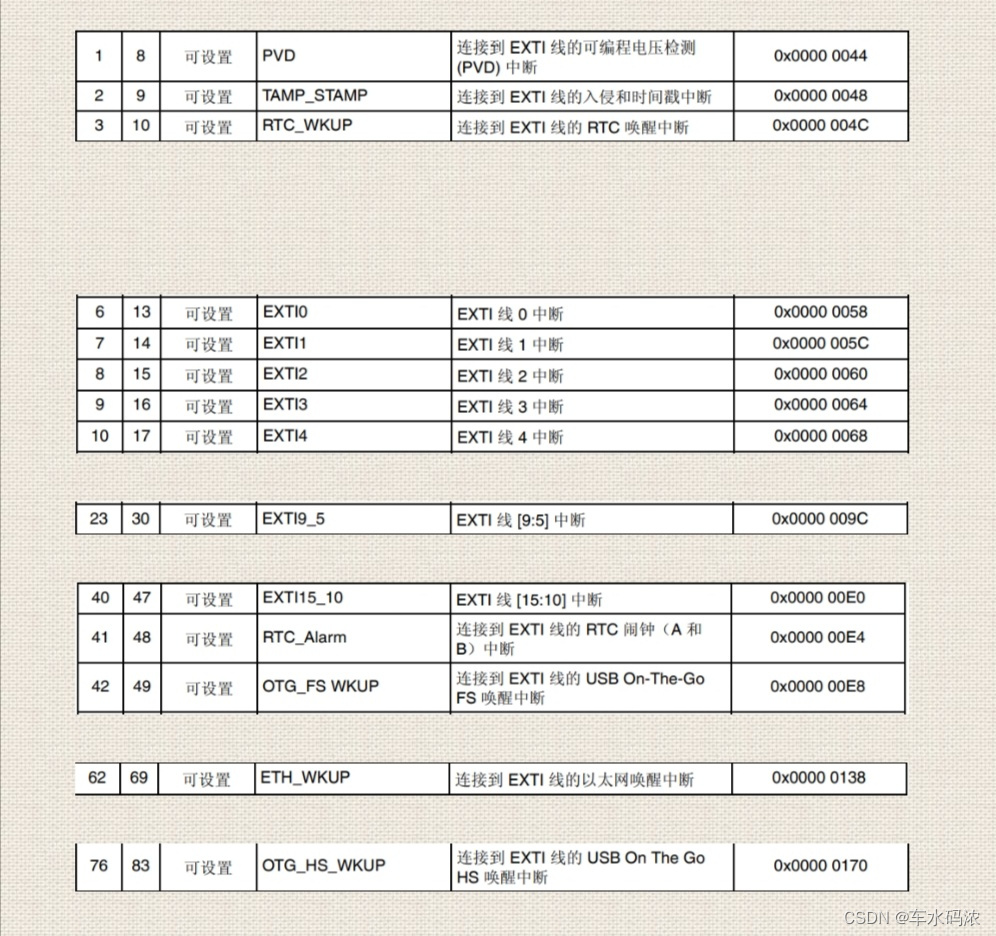
Part IV: STM32 interrupt control programming
用tkinter做一个简单图形界面
建立自己的网站(17)

View remote test data and records anytime, anywhere -- ipehub2 and ipemotion app

阿里云中mysql数据库被攻击了,最终数据找回来了
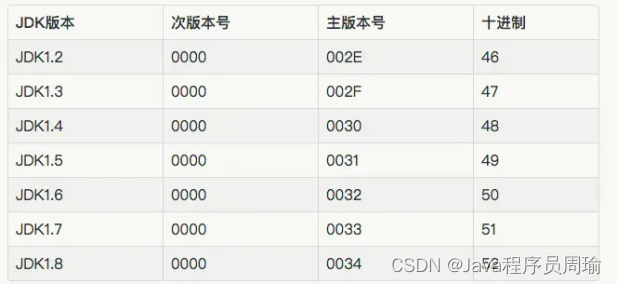
.class文件的字节码结构

Equals() and hashcode()

UI控件Telerik UI for WinForms新主题——VS2022启发式主题

「精致店主理人」青年创业孵化营·首期顺德场圆满结束!
第六篇,STM32脉冲宽度调制(PWM)编程
随机推荐
Link sharing of STM32 development materials
Learn self 3D representation like ray tracing ego3rt
[software reverse - solve flag] memory acquisition, inverse transformation operation, linear transformation, constraint solving
Part 7: STM32 serial communication programming
Js+svg love diffusion animation JS special effects
Deep learning framework TF installation
A brief history of deep learning (II)
【JVM调优实战100例】04——方法区调优实战(上)
Attention SLAM:一種從人類注意中學習的視覺單目SLAM
阿里云中mysql数据库被攻击了,最终数据找回来了
C9高校,博士生一作发Nature!
Levels - UE5中的暴雨效果
Slow database query optimization
"Exquisite store manager" youth entrepreneurship incubation camp - the first phase of Shunde market has been successfully completed!
腾讯云 WebShell 体验
ARM裸板调试之JTAG原理
UI控件Telerik UI for WinForms新主题——VS2022启发式主题
深度学习简史(二)
View remote test data and records anytime, anywhere -- ipehub2 and ipemotion app
Chapter II proxy and cookies of urllib Library