当前位置:网站首页>【论文阅读|深读】ANRL: Attributed Network Representation Learning via Deep Neural Networks
【论文阅读|深读】ANRL: Attributed Network Representation Learning via Deep Neural Networks
2022-07-06 18:36:00 【海轰Pro】

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力
知其然 知其所以然!
本文仅记录自己感兴趣的内容
简介
原文链接:https://dl.acm.org/doi/abs/10.5555/3304889.3305099
会议:Twenty-Seventh International Joint Conference on Artificial Intelligence {IJCAI-18}(CCF A类)
年度:2018
Abstract
网络表示学习(RL)旨在将网络中的节点变换到低维的向量空间中,同时保持网络的固有性质。
虽然网络RL已经得到了广泛的研究,但已有的工作大多集中在网络结构或节点属性信息上。
在本文中,我们提出了一种新的框架,称为ANRL,它原则性地结合了网络结构和节点属性信息。
具体地说,我们提出了一种邻居增强自动编码器来对节点属性信息进行建模,从而重建其目标邻居而不是自身。
为了捕捉网络结构,在属性编码器的基础上设计了属性感知框架图模型,用来描述每个节点与其直接或间接邻居之间的关联。
我们在六个真实世界的网络上进行了广泛的实验,包括两个社交网络、两个引文网络和两个用户行为网络。
实验结果表明,ANRL在节点分类和链路预测任务中都能获得较大的收益。
1 Introduction
网络是探索和模拟现实世界中复杂系统的通用数据结构,包括社交网络、学术网络和万维网等
在大数据时代,网络已经成为高效存储和访问交互实体的关系知识的重要媒介
网络中的知识挖掘一直受到学术界和产业界的关注,例如在线广告定位和推荐
这些任务中的大多数都需要精心设计的模型,其中包含许多专家致力于特征工程,而RL是相对自动特征表示的替代方案
有了RL,网络中的知识发现,如聚类[Narayanan等人,2007年],链接预测[L̈u和周,2011年]和分类[Kazienko和Kajdanowicz,2012年],可以很大程度上通过在低维向量空间中的学习来促进
Network representation learning (RL)
网络RL中的相关工作可以追溯到基于图的降维方法,例如
- 局部线性嵌入(LLE)[Roweis和Saul,2000]
- 拉普拉斯特征映射(LE)[Belkin和Niyogi,2003]
LLE和LE都通过构造最近邻图来维护数据空间的局部结构
- 为了在表示空间中保持连接节点之间的距离更近,计算亲和图的相应特征向量作为其表示
这些方法的一个主要问题是
- 由于计算特征向量的计算复杂性很高
- 很难扩展到大型网络
受word2vec模型最近成功的启发[Mikolov等人,2013a;2013b],许多基于网络结构的RL方法已经被提出
并在各种应用中显示出良好的性能[Perozzi等人,2014;曹等人,2015;Tang等人,2015b;Grover和Leskovec,2016;Wang等人,2016]
然而,节点属性信息在许多应用中可能扮演着重要的角色,却没有得到足够的重视
在被称为属性信息网络(AINs) 的真实世界网络中,通常观察到附属于各种属性的节点
例如, 在Facebook社交网络中,用户节点通常与包括年龄、性别、教育程度以及发布内容的个性化简档信息相关联
最近的一些努力通过集成网络拓扑和节点属性信息来探索AINs,以学习更好的表示[Tang等人,2015a;Yang等人,2015;潘等人,2016]。
在AINs中的表示学习仍处于初级阶段,能力相当有限:
- (1)网络拓扑和节点属性是两个异构的信息源,很难将它们的属性保持在一个共同的向量空间中
- (2)观测到的网络数据往往是不完整的,甚至是噪声的,这给获取信息表示带来了更多的困难
为了解决上述挑战,我们提出了一个统一的框架,称为ANRL
- 通过联合集成网络结构和节点属性信息来学习AINs中的健壮性表示
- 更具体地说,我们利用深度神经网络强大的表示能力来捕捉两个信息源之间的复杂相关性,这两个信息源由邻居增强自动编码器和属性感知跳图模型组成
总而言之,我们的主要贡献如下:
- 我们提出了一个统一的ANRL框架,该框架无缝地将网络结构接近性和节点属性亲和性集成到低维表示空间中。更具体地说,我们设计了一种邻居增强自编码器,它可以在表示空间中更好地保持数据样本之间的相似性。我们还提出了一个属性感知跳过图模型来捕获结构相关性。这两个组件共享到编码器的连接,编码器捕获节点属性以及网络结构信息
- 我们通过链路预测和节点分类两项任务,在6个数据集上进行了大量的实验,并实证验证了所提模型的有效性。
2 Related Work
一些早期作品和其他光谱方法的目标是保留数据的局部几何结构,并以更低的维空间表示它们
这些方法是降维技术的一部分,可以被认为是图嵌入的先驱。
近年来,网络表示学习在网络分析中得到了越来越多的关注
他们专注于嵌入一个已有的网络,而不是构建其亲和力图
其中
- DeepWalk [Perozzi et al., 2014]通过截断随机漫步生成节点序列,将节点序列作为句子,送入跳图模型学习表示
- Node2vec [Grover and Leskovec, 2016]通过使用宽度优先(BFS)和深度优先(DFS)图搜索来扩展DeepWalk,以探索不同的邻域
- LINE [Tang等人,2015b]优化了一阶和二阶图邻近性,而不是执行随机漫步
- 随后,GraRep [Cao等人,2015]提出捕捉k阶关系信息用于图表示
- SDNE [Wanget al., 2016]将图结构纳入深度自编码器,以保持高度非线性的一阶和二阶邻近性
属性信息网络在许多领域中普遍存在,同时包含网络结构和节点属性信息,有望实现更好的表示
已有的一些算法研究了将这两种信息源联合嵌入统一空间的可能性
- TADW [Yang等人,2015]将DeepWalk和相关的文本特征纳入矩阵分解框架
- PTE [Tang等人,2015a]利用标签信息和不同层次的词同现信息来生成预测性文本表示
- TriDNR [Pan等人,2016]使用来自三方的信息,包括节点结构、节点内容和节点标签(如果有的话),共同学习节点表示
尽管上述方法确实将节点属性信息合并到表示中,但它们是专门为文本数据设计的,不适合许多其他类型的特征
例如,连续的数值特征
最近,一些特征类型独立的表示学习算法被提出,通过无监督或半监督的方式进一步增强性能
这些算法可以处理各种特征类型,并捕获结构接近性和属性亲和力[Huanget al., 2017;廖等,2017;Rossi等人,2018]
- AANE [Huang等人,2017]是一种分布式嵌入方法,通过分解属性亲和矩阵,利用网络套索正则化惩罚连接节点之间的嵌入差异,联合学习节点表示
- Planetoid [Yang等人,2016]开发了转导和归纳方法,共同预测图中的类标签和邻域上下文
- SNE[廖等人,2017]通过利用端到端神经网络模型来捕获网络结构和节点属性信息之间的复杂相互关系来生成嵌入
- 另一个半监督学习框架SEANO [Liang et al., 2018]以输入样本属性及其平均邻域属性的聚合形式进行输入,以减轻表示学习过程中异常值的负面影响。
异构信息网络中的表示学习也得到了一些研究
- Metapath2vec [Dong等人,2017]利用基于元路径的随机漫步生成异构节点序列,并使用异构跳图模型学习节点表示
- [Li等人,2017]提出了一个模型,可以在动态环境而不是静态网络中处理表示学习
- [Wang et al., 2017]研究了符号信息网络中的表示学习问题。我们把这些可能的扩展留作以后的工作
3 Proposed Model
3.1 Notations and Problem Formulation
属性网络 G : G = ( V , ε , X ) G: G = (V, \varepsilon, X) G:G=(V,ε,X)
- V V V:顶点集合
- ε \varepsilon ε: 边集合,其实就是 E E E
- X X X: X ∈ R n × m X\in R^{n \times m} X∈Rn×m, 一个编码所有节点属性信息的矩阵, x i x_i xi表示与节点 i i i相关的属性
Definition 3.1
- 给定网络 G = ( V , E , X ) G = (V, E, X) G=(V,E,X),我们的目标是通过学习映射函数 f : v i → y i ∈ R d f: v_i →y_i∈R^d f:vi→yi∈Rd
- 将每个节点 i ∈ V i∈V i∈V表示为低维向量 y i y_i yi,其中 d ≪ ∣ V ∣ d≪|V| d≪∣V∣
- 映射函数 f f f不仅保持网络结构,而且保持节点属性接近度
3.2 Neighbor Enhancement Autoencoder
为了对节点的属性信息进行编码,我们设计了一种邻域增强的自编码器模型,以促进抗噪声表示学习过程
同样,邻居增强自编码器由一个编码器和一个解码器组成,而我们的目标是重建它的目标邻居而不是节点本身
值得注意的是,当我们的目标邻居是输入节点本身时,提出的模型退化为传统的自编码器。
具体来说,对于特征向量 x i x_i xi的节点 v i v_i vi和目标邻居函数 T ( ⋅ ) T(·) T(⋅),每一层的隐藏表示定义如下:
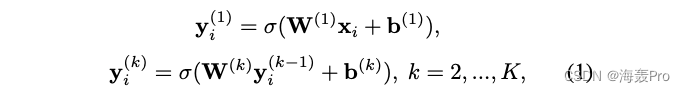
其中
- K K K为编码器和解码器的层数
- σ ( ⋅ ) σ(·) σ(⋅)表示可能的激活函数,如ReLU、sigmod或tanh
- W ( k ) W^{(k)} W(k)和 b ( k ) b^{(k)} b(k)分别为第 k k k层的变换矩阵和偏置向量
- x i x_i xi表示与节点 i i i相关的属性
我们的目标是最小化以下自动编码器的损失函数:
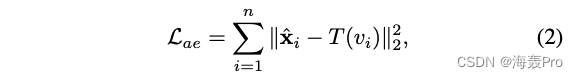
其中
- x ^ i \hat x_i x^i为解码器的重构输出
- T ( v i ) T(v_i) T(vi)返回 v i v_i vi的目标邻居
T ( ⋅ ) T(·) T(⋅)将先验知识纳入模型,可采用以下两种公式:
- Weighted Average Neighbor
- Elementwise Median Neighbor
Weighted Average Neighbor
对于给定的节点 v i v_i vi,目标邻域可以计算为相应的加权平均邻域,即
T ( v i ) = 1 ∣ N ( i ) ∣ ∑ j ∈ N ( i ) w i j x j T(v_i) = \frac{1}{|N(i)|}\sum_{j \in N(i)} w_{ij}x_j T(vi)=∣N(i)∣1j∈N(i)∑wijxj
其中
- N ( i ) N(i) N(i)为网络中节点vi的邻居
- x j x_j xj为节点 v j v_j vj的相关属性
- 加权网络为 W i j > 0 W_{ij} > 0 Wij>0,非加权网络为 W i j = 1 W_{ij} = 1 Wij=1
Elementwise Median Neighbor
与加权平均邻居相似,节点 v i v_i vi的Elementwise Median Neighbor定义为:
T ( v i ) = x ~ i = [ x ~ 1 , x ~ 2 , . . . . , x ~ m ] T(v_i) = \widetilde x_i = [\widetilde x_1, \widetilde x_2, ...., \widetilde x_m] T(vi)=xi=[x1,x2,....,xm]
- x ~ k \widetilde x_k xk是其相关邻域特征向量在第 k k k维的中值
- 例如: x ~ k = M e d i a n ( w i 1 x 1 k , w i 2 x 2 k , . . . . , w i ∣ N ( i ) ∣ x ∣ N ( i ) ∣ k ) \widetilde x_k = Median(w_{i1}x_{1k}, w_{i2}x_{2k}, .... , w_{i|N(i)|}x_{|N(i)|k}) xk=Median(wi1x1k,wi2x2k,....,wi∣N(i)∣x∣N(i)∣k)
- M e d a i n ( ⋅ ) Medain(·) Medain(⋅)返回其输入的中值
简单理解:邻域中节点每个向量中每一个维度中取中值
比如:邻域节点向量表示为【1,2,3】【2,3,4】【3,4,5】
那么结果为【2,3,4】,【1,2,3】【2,3,4】【3,4,5】每个向量第一个元素的中值
2 = mid【1,2,3】
3 = mid【2,3,4】
4 = mid 【3,4,5】
我们的方法比传统的自动编码器在保持节点之间更好的接近性方面有更多的优势
直观地说
- 获得的表示对变化具有更强的鲁棒性
- 因为它通过强迫距离较近的节点重构相似的目标邻居来约束它们拥有相似的表示
- 因此,它既捕获了节点属性信息,又捕获了本地网络结构信息
- 此外,提出的邻域增强自编码器模型是一个通用的框架
- 可应用于去噪自编码器和变分自编码器等自编码器变量
3.3 Attribute-aware Skip-gram Model
为了表述网络结构信息,Skip-gram模型在最近的著作中被广泛采用[Perozziet al., 2014;Grover和Leskovec, 2016]
该算法假设具有相似语境的节点在潜在语义空间中应该是相似的
在此基础上,我们提出了一种属性感知的skipgram模型,该模型融合了属性信息,以实现更平滑的表示
具体来说,目标函数通过给定当前节点 v i v_i vi及其相关属性 x i x_i xi,使所有随机游走上下文 c ∈ C c∈C c∈C的 skip-gram模型的以下对数概率最小:
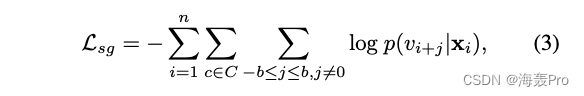
其中
- v i + j v_{i+j} vi+j为生成的随机序列中的节点上下文
- b b b为窗口大小
p ( v i + j ∣ x i ) p(v_{i+j}|x_i) p(vi+j∣xi)的条件概率是给定节点属性的目标上下文的可能性,我们正式定义 p ( v i + j ∣ x i ) p(v_{i+j}|x_i) p(vi+j∣xi)为
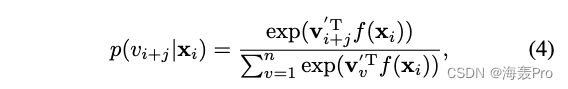
其中
- x i x_i xi是与节点 v i v_i vi相关联的属性信息
- f ( ⋅ ) f(·) f(⋅)可以是任意的属性编码器函数
- 例如,CNN用于图像数据,RNN用于序列数据
- v i ′ v_i' vi′是节点 v i v_i vi被视为“上下文”节点时的对应表示
它不仅建模节点属性,而且建模全局结构信息
直接优化式(4)的计算成本较高
因为在计算 p ( v i + j ∣ x i ) p(v_{i+j}|x_i) p(vi+j∣xi)的条件概率时,需要对整个集合的节点求和
我们采用[Mikolov et al., 2013b]中提出的负采样方法:根据一些噪声分布对多个负样本进行采样
具体来说,对于特定的节点-上下文对 ( v i , v i + j ) (v_i, v_{i+j}) (vi,vi+j),我们有以下目标:
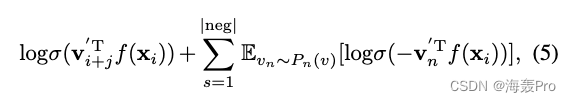
其中
- σ ( x ) = 1 / ( 1 + e x p ( − x ) ) σ(x) = 1/(1 + exp(−x)) σ(x)=1/(1+exp(−x))为sigmoid函数
- ∣ n e g ∣ |neg| ∣neg∣为负样本数
我们按照[Mikolov et al., 2013b]的建议设置 P n ( v ) ∝ d v 3 / 4 P_n(v)∝d^{3/4}_v Pn(v)∝dv3/4,其中 d v d_v dv为节点 v v v的度
3.4 ANRL Model: A Joint Optimization Framework
在本节中,我们提出ANRL模型,联合利用网络结构和节点属性信息来学习它们的潜在表示
如图1所示,整个体系结构由两个耦合模块组成,即
- 邻域增强自编码器
- 属性感知跳过图模型
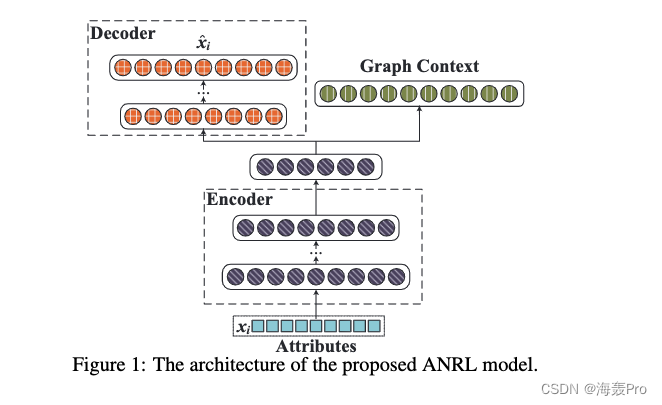
编码器将输入属性转换为低维向量空间,并扩展两个输出分支
- 左输出分支是一个译码器,它重建其输入样本的目标邻居
- 右边的输出分支预测给定输入的关联图上下文
这两个组件紧密相连,因为它们共享前几个层
通过这种方式, y i K y^K_i yiK的最终表示获取了节点属性以及网络结构信息
联合ANRL模型的目标函数表示为 L s g L_{sg} Lsg和 L a e L_{ae} Lae的加权组合,如式(2)、(3)所定义:
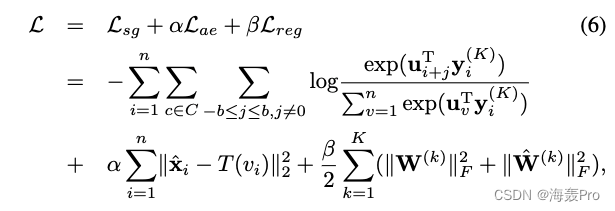
其中
- n n n为节点总数
- C C C为随机漫步生成的节点序列集
- b b b为窗口大小
- x i x_i xi表示节点 v i v_i vi的特征向量
- y i ( K ) y^{(K)}_i yi(K)表示节点 v i v_i vi经过 K K K层编码后的表示
- W ( K ) W^{(K)} W(K)、 W ^ ( K ) \hat W^{(K)} W^(K)分别为第 K K K层编码器和解码器的权值矩阵
- U U U为图上下文预测的权值矩阵, u v u_v uv对应 U U U中第 v v v列
- α α α是平衡自编码器模块和跳码模块损耗的超参数
- β β β是 ℓ 2 ℓ2 ℓ2范数正则化系数
这样,ANRL在一个统一的框架中保留了节点属性、局域网络结构和全局网络结构信息
值得注意的是,属性感知skip-gram模块的函数 f ( ⋅ ) f(·) f(⋅)正是自动编码器模块的编码器部分,它将节点属性信息转换为表示空间 y i ( K ) y^{(K)}_i yi(K)
因此,网络结构和节点属性信息会共同影响 y i ( K ) y^{(K)}_i yi(K)
此外,为了简单起见,我们只使用一个输出层来获取图的上下文信息,它可以很容易地扩展到多个非线性转换层
为了使 L L L最小化,我们采用随机梯度算法对(6)式进行优化
我们对这两个耦合分量进行迭代优化,直到模型收敛
所有模型参数记为 Θ Θ Θ,学习算法总结在算法1中:

4 Experiments
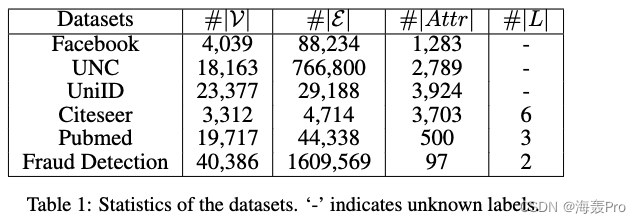
4.1 Datasets
4.2 Competitors
我们将ANRL与几种最先进的网络RL算法进行比较,这些算法可以分为以下几组:
- Attribute-only: SVM and autoencoder
- Structure-only:DeepWalk、 node2vec、 LINE、 SDNE
- Attribute + Structure:AANE、 SNE、Planetoid-T、 TriDNR、 SEANO
- ANRL Variants:ANRLWAN,使用加权平均邻居函数来构建它的目标邻居,ANRL-EMN,使用Elementwise中值邻居函数来生成它的目标邻居,如章节3.2中定义的,和ANRL-OWN,重建自己(即OWN)像传统的自动编码器
4.3 Link Prediction
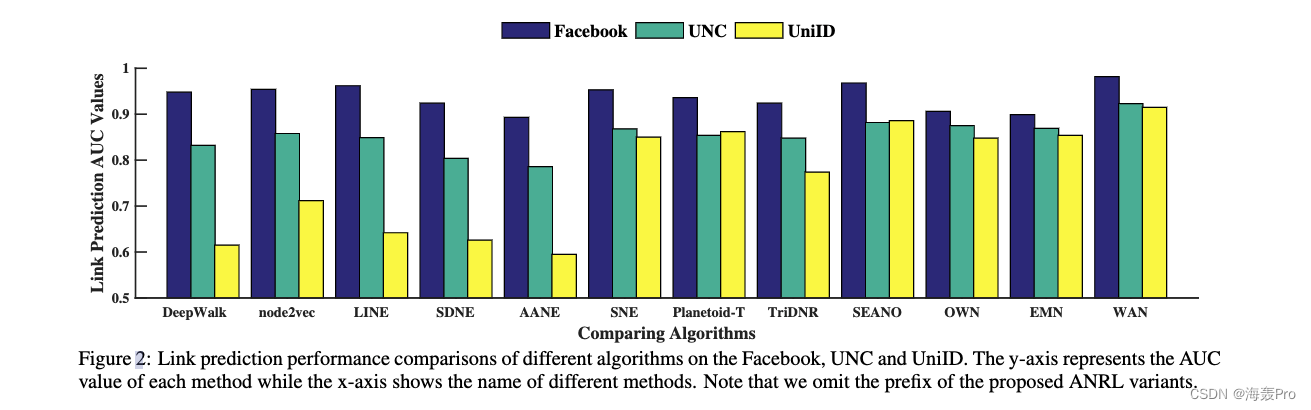
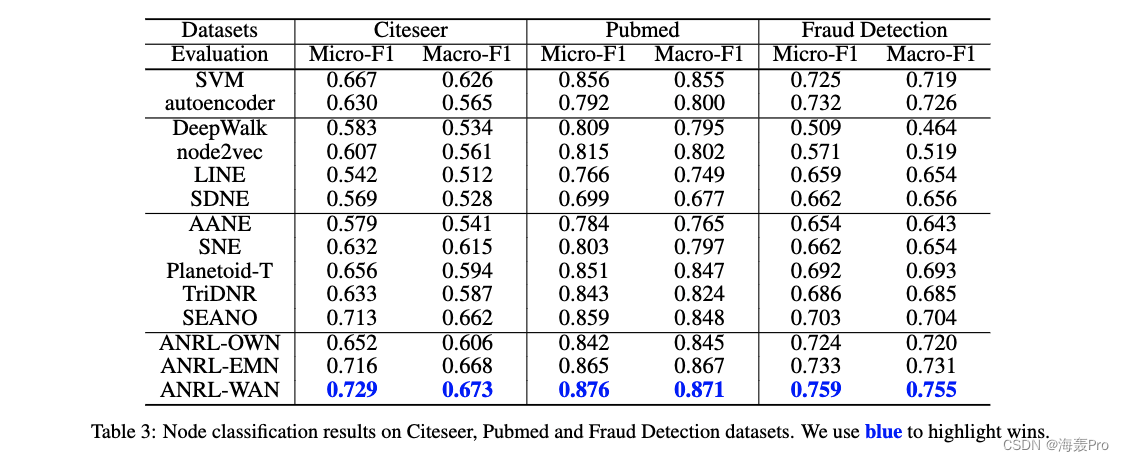
4.4 Node Classification
5 Conclusions
本文研究了有属性信息网络中的表示学习
据此,我们设计了一个耦合的深度神经网络模型,该模型将节点属性和网络结构信息融合到嵌入中
为了进一步解决结构邻近性和属性亲和性保持问题,我们开发了一种邻居增强自编码器和属性感知跳过图模型以利用结构信息和属性之间的复杂相互关系
在多个真实数据集上的实验结果表明,提出的ANRL优于代表性的最先进的嵌入方法。
读后总结
文章总体上采用编码器 + skip-gram模型结合的方式
- 确定随机游走的参数,进行随机游走,得到 C C C(类似得到了一个语料库)
- 然后利用节点的属性特征矩阵 X X X,计算 T ( ⋅ ) T(·) T(⋅) (也就是对一个节点的邻域节点的属性向量进行一定的操作)
- 然后开始进行迭代更新
- 依据AE重构后的向量 x ^ \hat x x^与 T ( ⋅ ) T(·) T(⋅)进行损失计算,计算梯度,更新AE的参数
- 再依据 x ^ \hat x x^,使用skip-gram模型,依据上下文,更新skip-gram模型的参数
- 直到达到最优
算法流程图也很重要,需要认真读
分析:
- 使用属性矩阵 X X X → \rightarrow → 保留节点属性
- 利用邻域进行损失优化 → \rightarrow → 保留局部邻域结构
- 利用skip-gram模型 → \rightarrow → 保留全局网络结构
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

边栏推荐
- 【LeetCode】Day97-移除链表元素
- @Before, @after, @around, @afterreturning execution sequence
- ROS学习(23)action通信机制
- Flir Blackfly S 工业相机:配置多个摄像头进行同步拍摄
- 传感器:土壤湿度传感器(XH-M214)介绍及stm32驱动代码
- 刨析《C语言》【进阶】付费知识【一】
- Zabbix 5.0:通过LLD方式自动化监控阿里云RDS
- Recent applet development records
- Centros 8 installation MySQL Error: The gpg Keys listed for the "MySQL 8.0 Community Server" repository are already ins
- Curl command
猜你喜欢
一文带你走进【内存泄漏】
ROS学习(26)动态参数配置

Baidu flying general BMN timing action positioning framework | data preparation and training guide (Part 1)
Schedulx v1.4.0 and SaaS versions are released, and you can experience the advanced functions of cost reduction and efficiency increase for free!
CISP-PTE实操练习讲解(二)

Blue Bridge Cup 2022 13th provincial competition real topic - block painting
ROS learning (XX) robot slam function package -- installation and testing of rgbdslam

Correct use of BigDecimal
刨析《C语言》【进阶】付费知识【完结】

Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
随机推荐
Schedulx v1.4.0 and SaaS versions are released, and you can experience the advanced functions of cost reduction and efficiency increase for free!
Baidu flying general BMN timing action positioning framework | data preparation and training guide (Part 2)
FLIR blackfly s industrial camera: configure multiple cameras for synchronous shooting
The foreground downloads network pictures without background processing
Processing image files uploaded by streamlit Library
Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
ROS学习(24)plugin插件
MySQL execution process and sequence
FLIR blackfly s industrial camera: synchronous shooting of multiple cameras through external trigger
How can I code for 8 hours without getting tired.
Introduction to RC oscillator and crystal oscillator
The cradle of eternity
Reptile practice (VI): novel of climbing pen interesting Pavilion
Shortcut keys commonly used in idea
处理streamlit库上传的图片文件
Ds-5/rvds4.0 variable initialization error
Batch delete data in SQL - set in entity
Public key \ private SSH avoid password login
Sensor: introduction of soil moisture sensor (xh-m214) and STM32 drive code
Recognition of C language array