当前位置:网站首页>Tiflash source code reading (IV) design and implementation analysis of tiflash DDL module
Tiflash source code reading (IV) design and implementation analysis of tiflash DDL module
2022-07-07 02:11:00 【InfoQ】
Overview
DDL Modules in TiFlash Relevant scenarios in
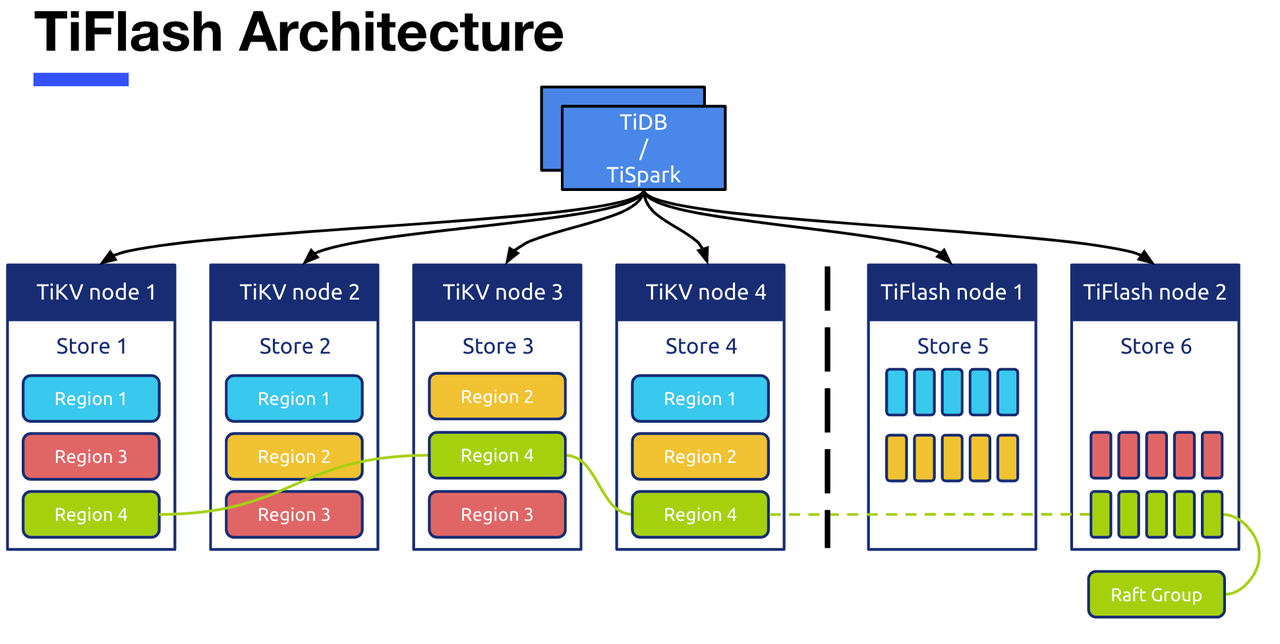
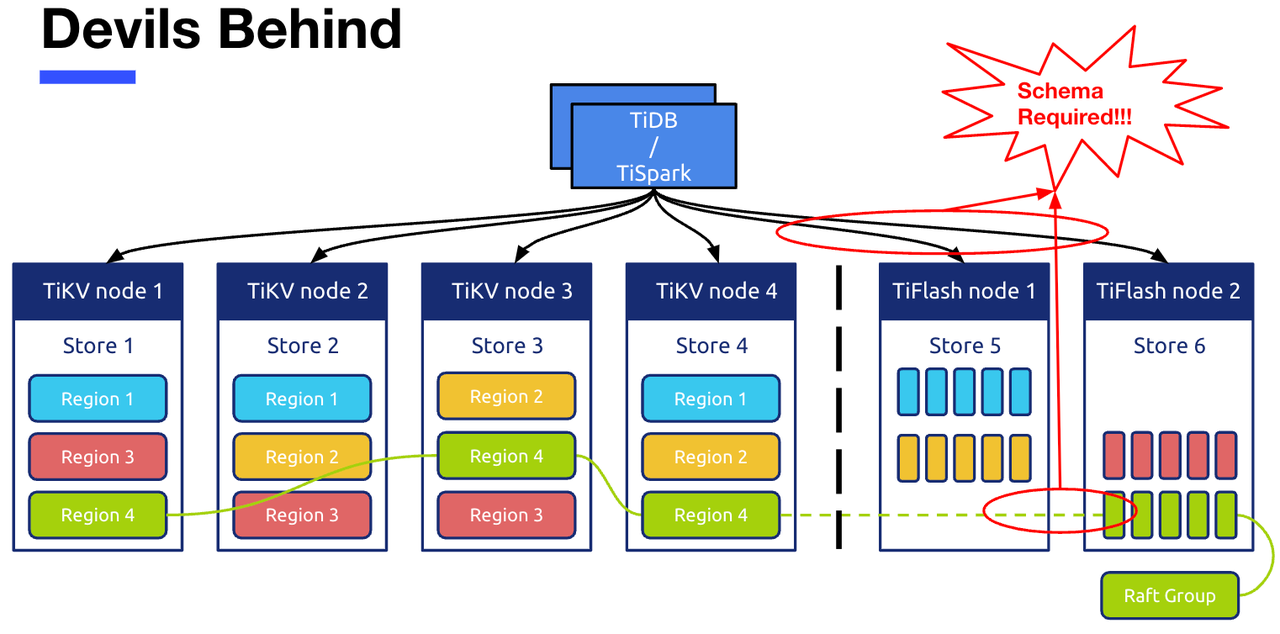
DDL The overall design idea of the module
TiDB in DDL Basic information of the module
- DDL Operation will be avoided as much as possible data reorg(data reorg It refers to the addition, deletion and modification of data in the table ).
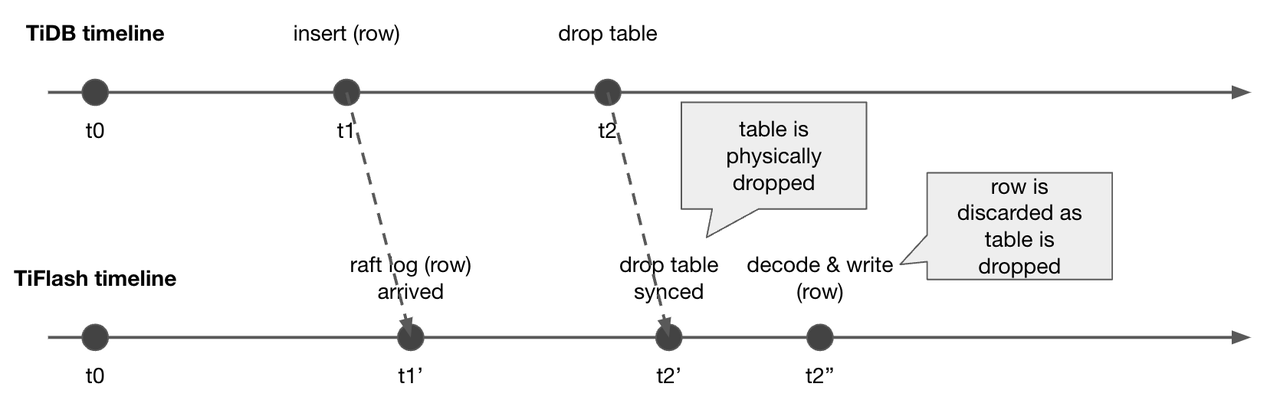
- Figure 3 this add column In the example of , The original watch has a b Two columns and two rows of data . As we go add column This DDL In operation , We will not add new lines in the original two lines c Fill in the column with the default value . If there is a subsequent read operation, the data of these two lines will be read , We will give... In the result of reading c Fill in the column with the default value . In this way , Let's avoid DDL Occurs during operation data reorg. Such as add column, drop column, And integer type column expansion , There is no need to trigger data reorg Of .

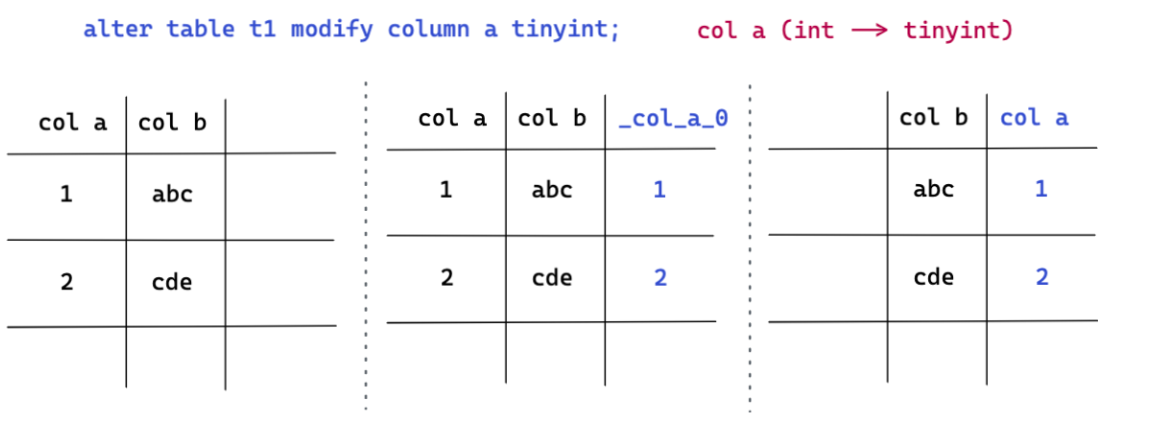
- But for those that are detrimental to the change DDL operation ( for example : Shorten the column length ( The following abbreviations are abbreviated ) The operation of , May cause user data truncation DDL change ), We will inevitably happen data reorg. But in the case of damaging changes , We will not modify or rewrite the data on the original column of the table , Instead, add new columns , Convert on the new column , Finally, delete the original column , Rename the new column DDL operation . This abbreviated column in Figure 4 (modify column) In the case of , We have a, b Two , this DDL The operation requires a List from int Type reduction tiny int type . Whole DDL The operation process is :
- First add a hidden column _col_a_0.
- Put the original a The values in the column are converted and written to the hidden column _col_a_0 On .
- After the conversion , Will be original a Column delete , And will _col_a_0 Rename the column to a Column .( The deletion mentioned here a Columns are not physically a The value of the column is deleted , By modification meta The way of information )*
- Relative data update schema Old data can always be parsed. This conclusion is also behind us TiFlash DDL An important guarantee of module dependency . This guarantee depends on the format of our row storage data . When saving data , We are will column id and column value Stored together , Instead of column name and column value Store together . In addition, our line storage format can be simplified as a column_id → data One of the map The way ( In fact, our bank deposit is not a map, It is stored in binary code , For details, please refer toProposal: A new storage row format for efficient decoding).
- We can use figure 5 as an example , To better understand this feature . On the left is a two column original table , adopt DDL operation , We deleted a Column , Added c Column , Convert to the right schema state . At this time , We need new schema Information to analyze the original old data , According to the new schema Each of the column id, We go to the old data to find each column id Corresponding value , among id_2 You can find the corresponding value , but id_3 No corresponding value was found , therefore , Just give it to id_3 Add the default value of this column . For multiple in the data id_1 Corresponding value , Choose to give up directly . In this way , We have correctly parsed the original data .

TiKV in DDL Basic information of the module
- TiKV The write operation itself does not need shcema , Because writing TiKV The data of is the data in the format of row storage that the upper layer has completed the conversion ( That is to say kv Medium v).
- about TiKV Read operation
- If the read operation only needs to put kv read out , You don't need to schema Information .
- If it is necessary to TiKV Medium coprocesser Deal with some TiDB Issue to TiKV When undertaking the downward calculation task ,TiKV Will need schema Information about . But this schema Information , Will be in TiDB The request sent contains , therefore TiKV It can be taken directly TiDB Of the requests sent schema Information to analyze data , And do some exception handling ( If the parsing fails ). therefore TiKV This kind of read operation does not need to be provided by itself schema Relevant information .
TiFlash in DDL Module design idea
- TiFlash The node will save its own schema copy. Part of it is because TiFlash Yes schema With strong dependence , need schema To help parse the data of row to column conversion and the data to be read . On the other hand, because TiFlash Is based on Clickhouse Realized , So many designs are also in Clickhouse Evolved from the original design ,Clickhouse In its own design, it keeps a schema copy.
- about TiFlash Saved on the node schema copy, We chose to go throughOn a regular basis from TiKV Pull the latest schema( The essence is to get TiDB The latest in schema Information ) To update , Because it is constantly updated schema It's very expensive , So we choose to update regularly .
- Read and write operations , MeetingDepend on schema copy To parse. If... On the node schema copy Not meet the current needs of reading and writing , We willGo pull the latest schema Information, To guarantee schema Newer than the data , In this way, it can be correctly and successfully parsed ( This is what I mentioned earlier TiDB DDL The guarantee provided by the mechanism ). Specific reading and writing are right schema copy The needs of , I will introduce it to you in detail in the later part .
DDL Core Process
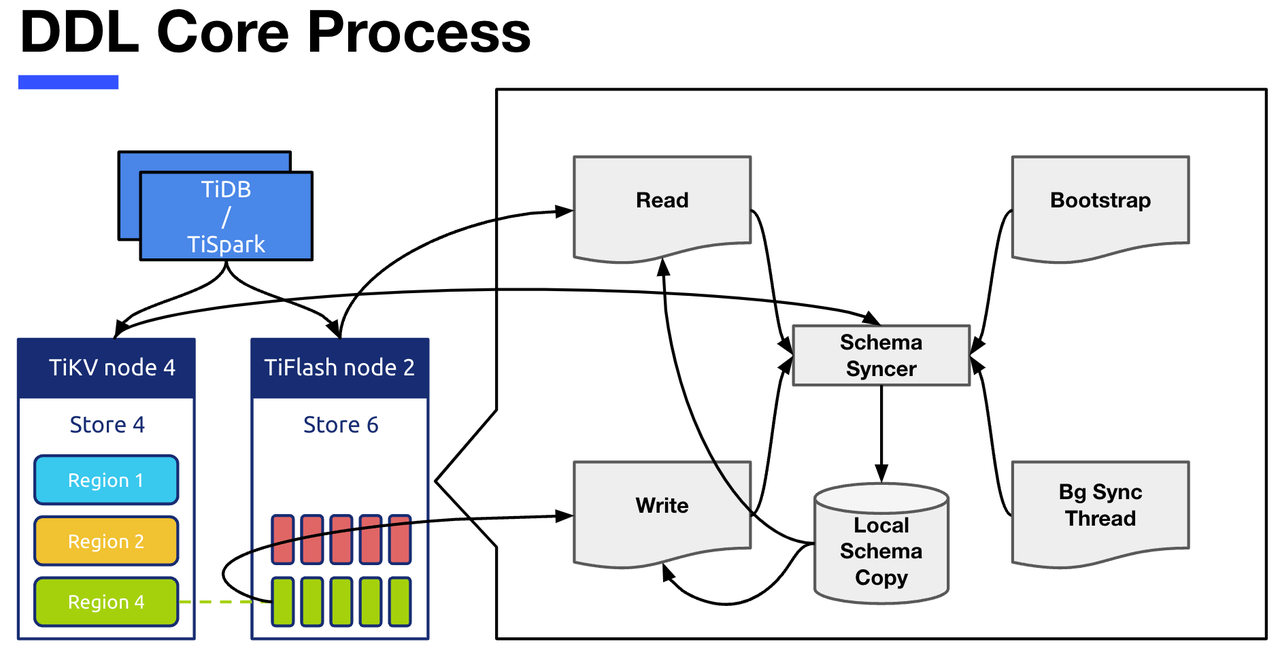
- Local Schema Copy refer to TiFlash Stored on the node schema copy Information about .
- Schema Syncer The module is responsible for TiKV Pull Abreast of the times Schema Information , Update based on this Local Schema Copy.
- Bootstrap refer to TiFlash Server When it starts , Will be called directly once Schema Syncer, Get all the present schema Information .
- Background Sync Thread It is responsible for calling regularly Schema Syncer To update Local Schema Copy modular .
- Read and Write The two modules are TiFlash Read and write operations in , Read and write operations will depend on Local Schema Copy, It will also be called when necessary Schema Syncer updated .
Local Schema Copy
StorageDeltaMerge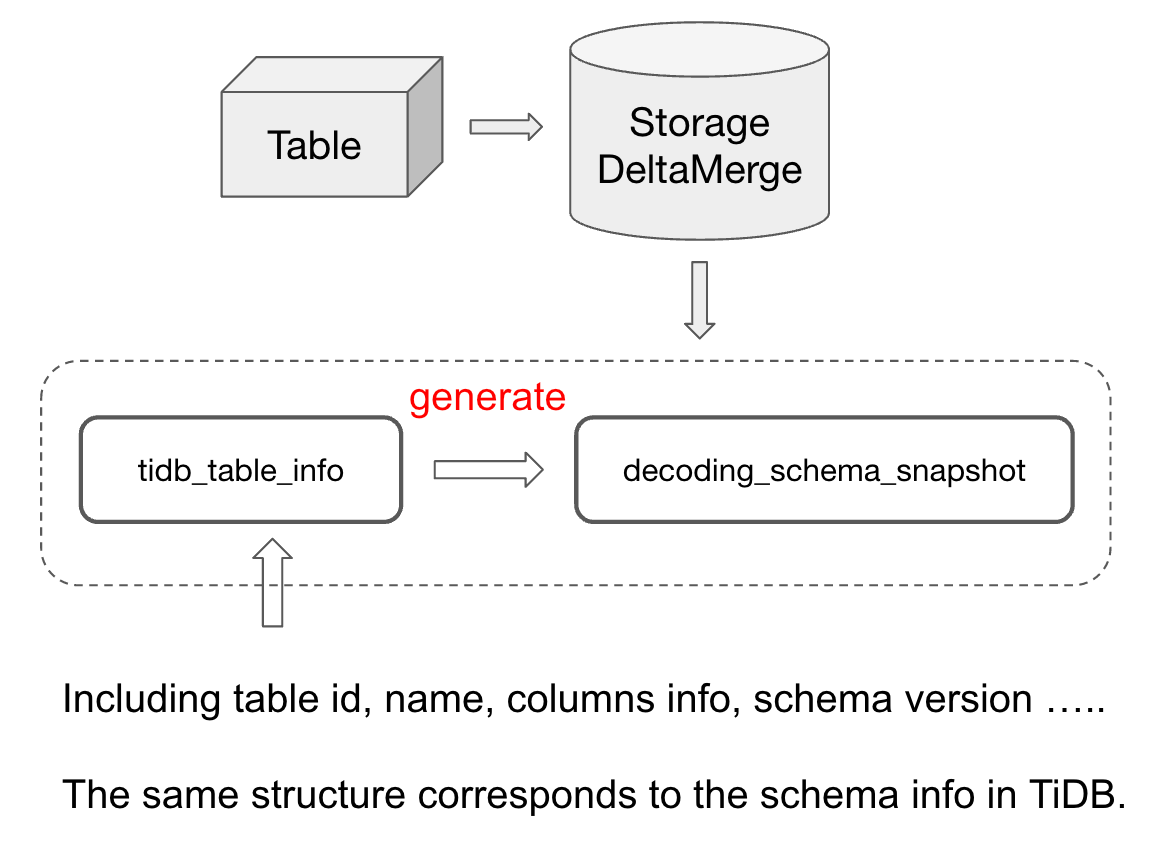
tidb_table_infoThis variable stores table All kinds of schema Information , Include table id,table name,columns infos,schema version wait . alsotidb_table_infoThe storage structure of is similar to TiDB / TiKV Storage in table schema The structure of is completely consistent .
decoding_schema_snapshotIt is based ontidb_table_infoas well asStorageDeltaMergeSome of the information inGenerateAn object of .decoding_schema_snapshotIt is proposed to optimize the performance of row column conversion in the writing process . Because we are doing row to column conversion , If you rely ontidb_table_infoGet the corresponding schema Information , You need to do a series of conversion operations to adapt . in consideration of schema It will not be updated frequently , in order toAvoid repeating these operations every time row to column parsing, We will usedecoding_schema_snapshotThis variable is used to save the converted results , And it depends ondecoding_schema_snapshotTo parse .
Schema Syncer
TiDBSchemaSyncerStorageDeltaMerge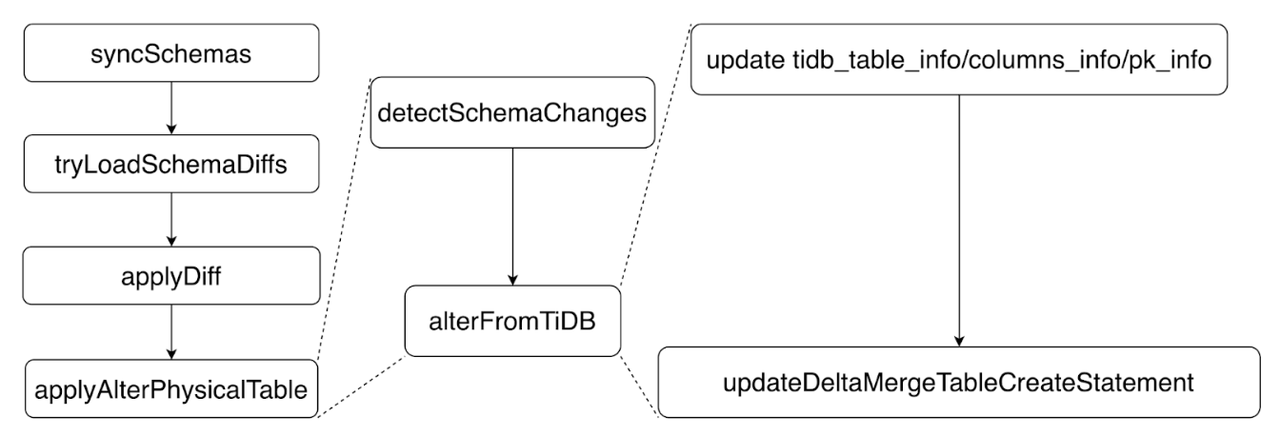
TiDBSchemaSyncersyncSchema- adopt
tryLoadSchemaDiffs, TiKV Get this round of new schema Change information .
- Then traverse all diffs One by one
applyDiff.
- For each diff, We will find his corresponding table, Conduct
applyAlterPhysicalTable.
- In the Middle East: , We will detect To this round of updates , Everything related to this table schema change , And then call
StorageDeltaMerge::alterFromTiDBCome to the table correspondingStorageDeltaMergeObject changes .
- Specific changes , We'll modify
tidb_table_info, dependent columns And primary key information .
- In addition, we will update the table creation statement of this table , Because the table itself has changed , Therefore, his statement of creating tables also needs to be changed accordingly , Do this later recover Wait for the operation to work correctly .
syncSchemadecoding_schema_snapshotdecoding_schema_snapshotdecoding_schema_snapshottidb_table_infotidb_table_infodecoding_schema_snapshot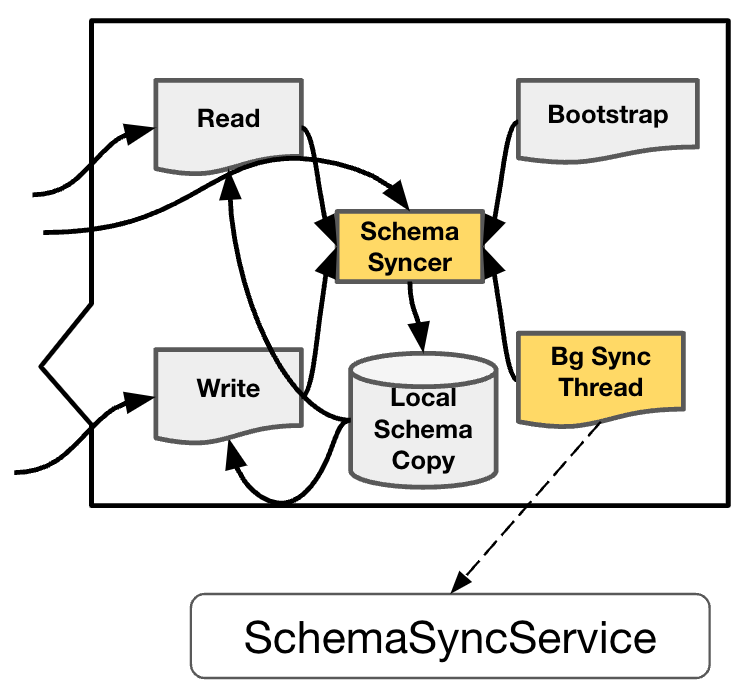
TiDBSchemaSyncer::syncSchemaSchemaSyncServicesyncSchemaSchema on Data Write
- Case oneUnknown Column, That is, the ratio of data to be written schema There's an extra column e. There are two possibilities for this to happen .
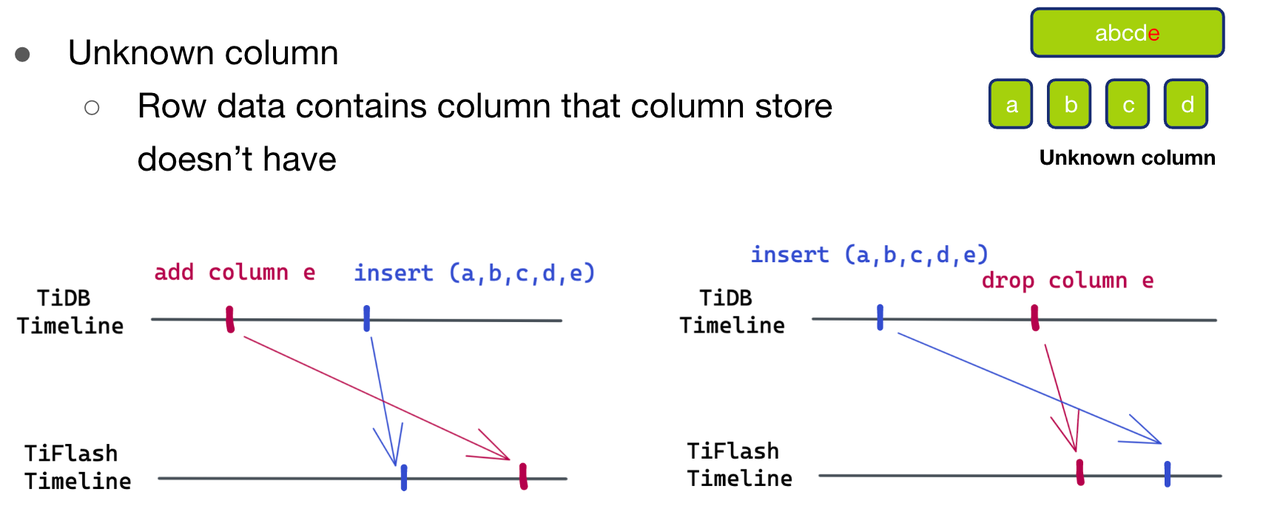
- The first possibility , As shown in Figure 11 ( Left ) Shown , The data to be written is larger than schema new . stay TiDB Time line , First, a new column is added e, Then insert (a,b,c,d,e) This line of data . But the inserted data arrived first TiFlash ,add column e Of schema The change hasn't arrived yet TiFlash Side , So there is data ratio schema One more column .
- The second possibility , As shown in Figure 11 ( Right ) Shown , The data to be written is larger than schema used . stay TiDB Time line , Insert this line of data first (a,b,c,d,e), then drop column e. however drop column e Of schema Changes arrive first TiFlash Side , The inserted data arrives , There will also be data ratio schema One more column . under these circumstances , We also have no way to judge which of the above situations , There is no common way to deal with , Therefore, only parsing failure can be returned , To trigger the pull of the latest schema Carry out the second round of analysis .
- The second caseMissing Column, That is, the ratio of data to be written schema A column is missing e. Again , There are also two possibilities .
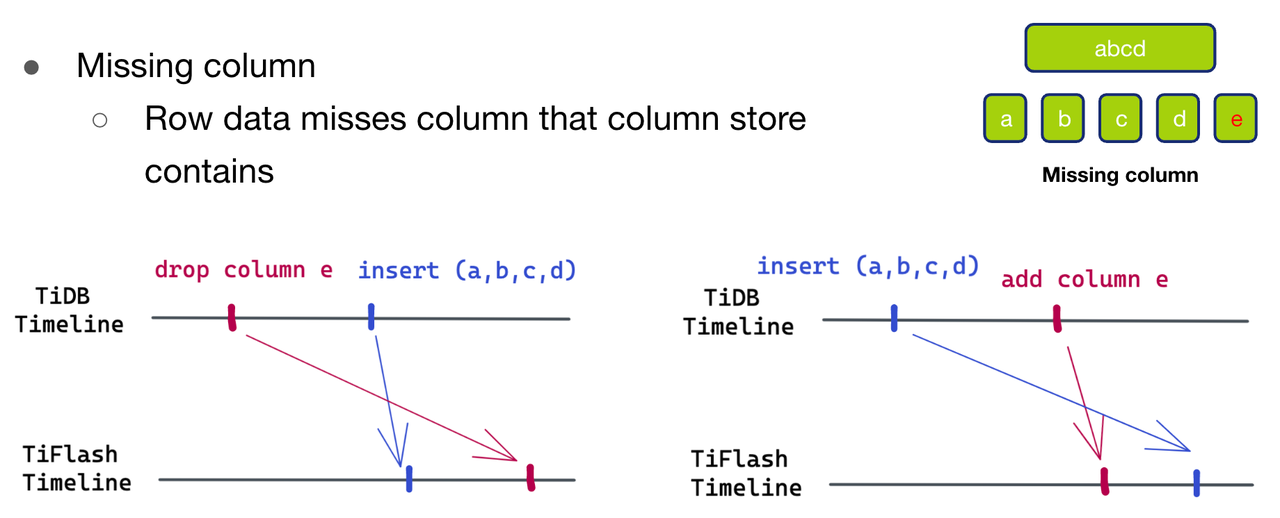
- The first possibility , As shown in Figure 12 ( Left ) Shown , The data to be written is larger than schema new . stay TiDB Time line , First drop column e, Then insert the data (a,b,c,d).
- The second possibility , As shown in Figure 12 ( Right ) Shown , The data to be written is larger than schema used . stay TiDB Time line , First insert the data (a,b,c,d), Then insert e Column .
- The third caseOverflow Column, That is, there is a column of data to be written that is larger than our schema The data range of this column in .
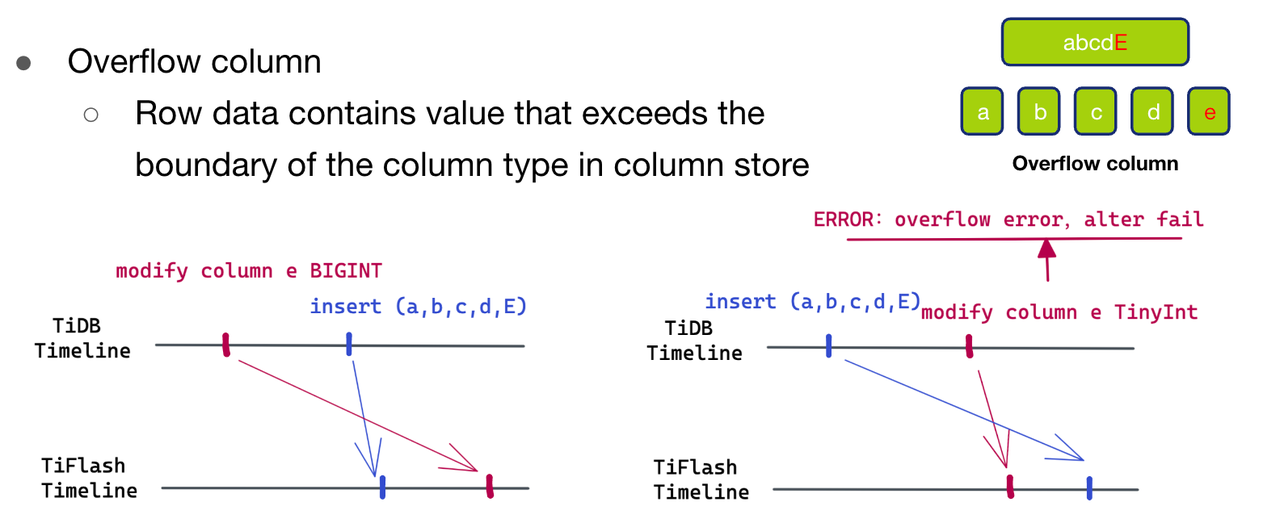

- Case one Unknown Column. because schema Than The data to be written is new , So we can be sure that it is because after this line of data , It happened again drop column e The operation of , But this schema change Arrived first TiFlash Side , So it led to Unknown Column Scene . So we just need to put e The column data can be deleted directly .
- The second case Missing Column. This situation is due to the add column e Caused by the operation of , Therefore, we can directly fill in the default values for the extra columns .
- The third case Overflow Column. Because at present our schema It is newer than the data to be written , So again overflow column The situation of , Something unusual must have happened , So we throw an exception directly .
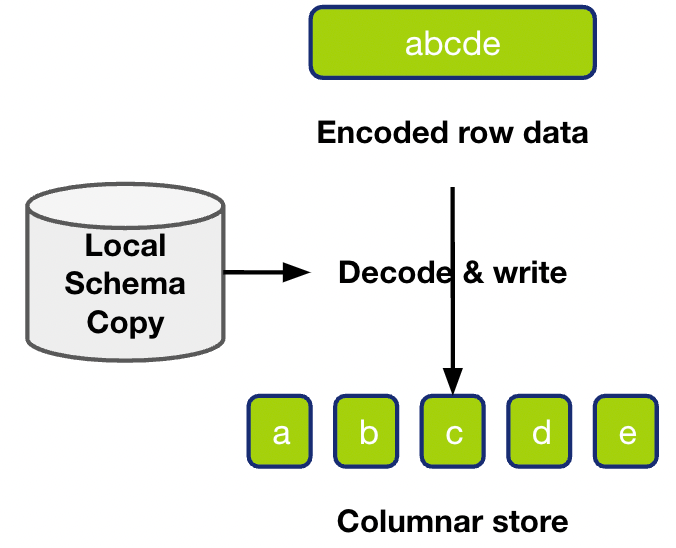
writeRegionDataToStorageRegionBlockReaderdecoding_schema_snapshotRegionBlockReaderdecoding_schema_snapshotdecoding_schema_snapshottidb_table_infodecoding_schema_snapshotgetSchemaSnapshotAndBlockForDecodingSchema on Data Read
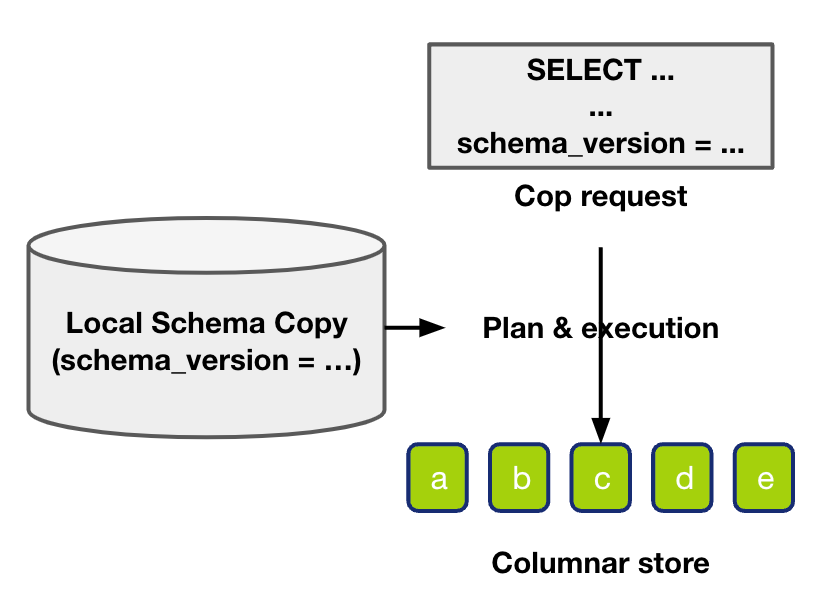
TiDBSchemaSyncer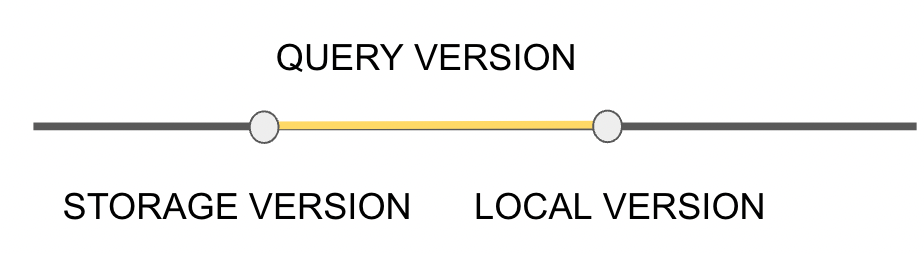
tidb_table_infoInterpreterSelectQuery.cppgetAndLockStorageWithSchemaVersionDAGStorageInterpreter.cppgetAndLockStoragesInterpreterSelectQuery.cppDAGStorageInterpreter.cppSpecial Case

Summary
边栏推荐
- 蓝桥杯2022年第十三届省赛真题-积木画
- Integrated navigation: product description and interface description of zhonghaida inav2
- Box stretch and pull (left-right mode)
- Jacob Steinhardt, assistant professor of UC Berkeley, predicts AI benchmark performance: AI has made faster progress in fields such as mathematics than expected, but the progress of robustness benchma
- Flir Blackfly S USB3 工业相机:计数器和定时器的使用方法
- Yiwen takes you into [memory leak]
- CISP-PTE实操练习讲解(二)
- NPM install compilation times "cannot read properties of null (reading 'pickalgorithm')“
- 企业中台建设新路径——低代码平台
- Hutool post requests to set the body parameter to JSON data
猜你喜欢
Cat recycling bin
Shell script quickly counts the number of lines of project code
Centros 8 installation MySQL Error: The gpg Keys listed for the "MySQL 8.0 Community Server" repository are already ins
ROS學習(23)action通信機制
![[unique] what is the [chain storage structure]?](/img/cd/be18c65b9d7faccc3c9b18e3b2ce8e.png)
[unique] what is the [chain storage structure]?
2022/0524/bookstrap
centos8 用yum 安装MySQL 8.0.x
新一代云原生消息队列(一)

我如何编码8个小时而不会感到疲倦。
JVM memory model
随机推荐
2022 system integration project management engineer examination knowledge point: Mobile Internet
Flir Blackfly S USB3 工业相机:计数器和定时器的使用方法
FLIR blackfly s usb3 industrial camera: white balance setting method
Flir Blackfly S工业相机:颜色校正讲解及配置与代码设置方法
ROS learning (26) dynamic parameter configuration
处理streamlit库上传的图片文件
Introduction to RC oscillator and crystal oscillator
Recent applet development records
Golang foundation - data type
Recognition of C language array
ROS学习(十九)机器人SLAM功能包——cartographer
Unicode string converted to Chinese character decodeunicode utils (tool class II)
centos8安裝mysql報錯:The GPG keys listed for the “MySQL 8.0 Community Server“ repository are already ins
MySQL's most basic select statement
ROS学习(25)rviz plugin插件
Errors made in the development of merging the quantity of data in the set according to attributes
When grep looks for a process, it ignores the grep process itself
猫猫回收站
TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析
The foreground downloads network pictures without background processing