当前位置:网站首页>[paper reading | deep reading] graphsage:inductive representation learning on large graphs
[paper reading | deep reading] graphsage:inductive representation learning on large graphs
2022-07-07 02:17:00 【Haihong Pro】
Catalog

Preface
Hello!
Thank you very much for reading Haihong's article , If there are mistakes in the text , You are welcome to point out ~
Self introduction. ଘ(੭ˊᵕˋ)੭
nickname : Sea boom
label : Program the ape |C++ player | Student
brief introduction : because C Language and programming , Then I turned to computer science , Won a National Scholarship , I was lucky to win some national awards in the competition 、 Provincial award … It has been insured .
Learning experience : Solid foundation + Take more notes + Knock more code + Think more + Learn English well !
Only hard work
Know what it is Know why !
This article only records what you are interested in
brief introduction
Link to the original text :https://dl.acm.org/doi/abs/10.5555/3294771.3294869
meeting :NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems (CCF A class )
year :2017/06/07
Abstract
Low dimensional embedding of nodes in large graphs It has been proved to be very useful in various prediction tasks, from content recommendation to protein function recognition
However , Most existing methods require that all nodes in the graph exist in the embedded training process
These previous methods are conductive in nature , It cannot be naturally extended to invisible nodes
ad locum , We proposed GraphSAGE, This is a general inductive framework , It USES Node characteristic information ( for example , Text attribute ) To effectively embed data generation nodes that have not been seen before
We are not training individual embeddings for each node , It is Learning a function , This function generates embedding by sampling and aggregating the features in the local neighborhood of nodes
1 Introduction
The fact proved that , Low dimensional vector embedding of nodes in large graphs is very useful for various prediction and graph analysis tasks [5,11,28,35,36]
The basic idea of node embedding method is to extract high-dimensional information about the neighborhood of node graph into dense vector embedding using dimension reduction technology
These nodes are embedded and can then be fed to the downstream machine learning system , And help perform such as node classification 、 Tasks such as clustering and link prediction
However , Previous work mainly focused on embedding nodes from a single fixed graph , And many real-world applications You need to quickly create new nodes for invisible nodes or ( Son ) Graph generation embedding
This inductive ability is crucial for high-throughput production machine learning systems , These systems operate on evolving charts , Constantly encounter invisible nodes ( for example ,Reddit Post on 、YouTube Users and videos on )
An inductive method of generating node embedding also promotes the generalization of graphs with the same characteristic form :
- for example , It can train proteins from model organisms - Embedded generator of protein interaction diagram , Then use the trained model to easily generate node embedding for the collected data on the new organism .
Compared with the energy exchange setting , Inductive node embedding problem Especially difficult
Because you want to generalize to invisible nodes , It is necessary to embed the newly observed subgraph with the nodes that have been optimized by the algorithm “ alignment ”
Inductive framework must learn to identify the structural attributes of the node neighborhood , These attributes not only reveal the local role of nodes in the graph , It also reveals the global location of nodes
Most of the existing methods of generating node embedding are inherently conductive
Most of these methods use the objective based on matrix decomposition to directly optimize the embedding of each node , It is not naturally extended to invisible data
Because they predict the nodes in a single fixed graph
These methods can be modified into inductive settings ( for example ,[28]) In the operation , But these modifications are often computationally expensive , Additional rounds of gradient descent are required to make new predictions
Recently, there are also methods of using convolution operator to learn graph structure , They offer hope as an embedding method
up to now , Graph convolution network (GCNS) Only apply to the energy exchange environment with fixed figure [17,18]
In this work , We will GCNS Extended to inductive unsupervised learning tasks , A framework is proposed , This framework generalizes GCN Method to use a trainable aggregation function ( Not limited to simple convolution ).
We propose a general inductive node embedding framework , be called GraphSAGE(Sample And Aggregate)
- Different from the embedding method based on matrix decomposition , We make use of Node characteristics ( for example , Text attribute 、 Node profile information 、 Node degree ) To learn the embedding function generalized to invisible nodes
- By adding node features to the learning algorithm , At the same time, we learn the topology of each node neighborhood and the distribution of node characteristics in the neighborhood
Although we focus on charts with rich features ( for example , Citation data with text attributes , With function / Molecular marker biological data )
But our method can also take advantage of the structural features that exist in all charts ( for example , Node degree )
therefore , Our algorithm can also be applied to graphs without node features
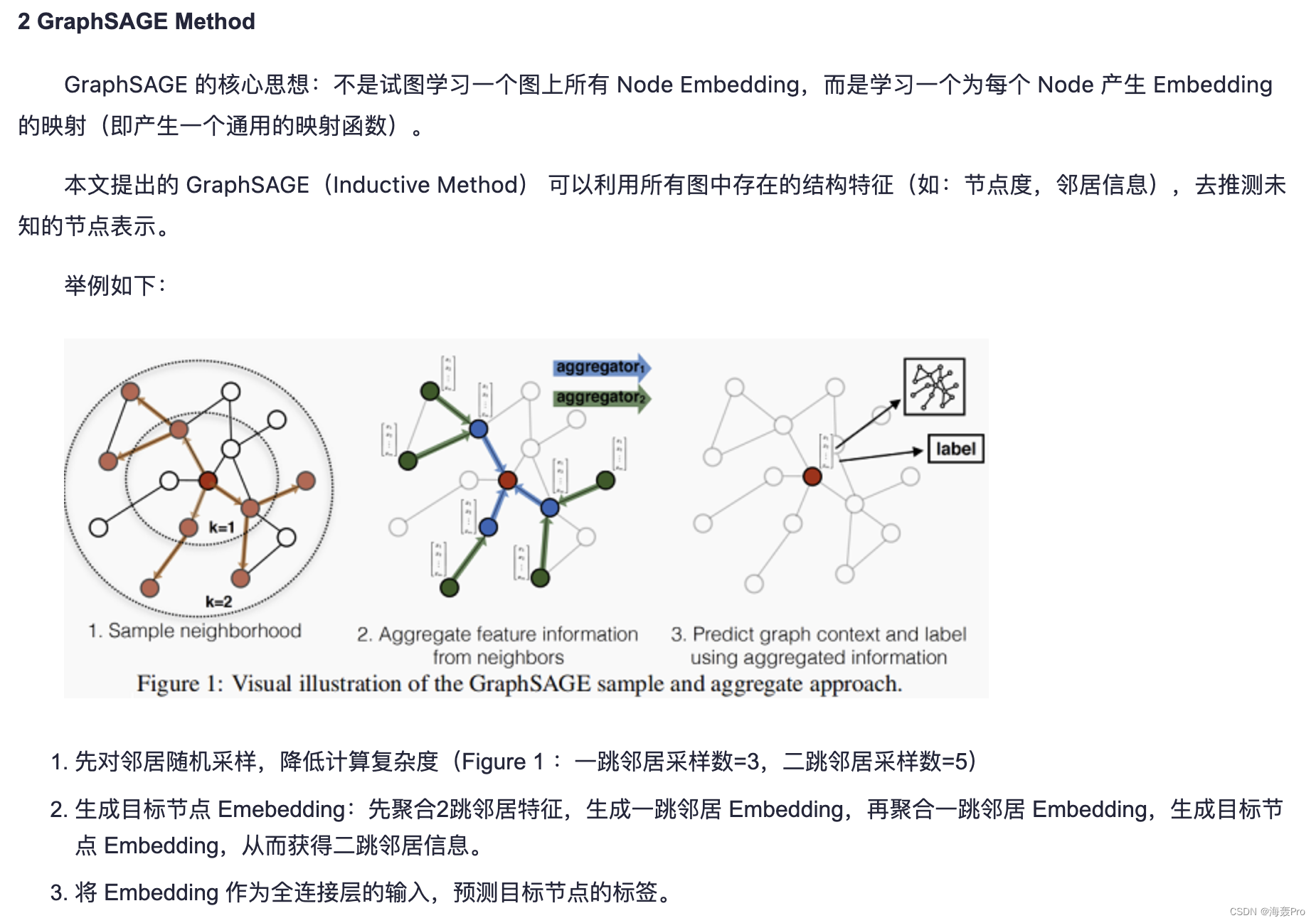
We don't train different embedding vectors for each node , Instead, it trains a set of aggregator functions , These functions learn to gather feature information from the local neighborhood of the node ( chart 1)
Each aggregator function aggregates information from different hops or search depths away from a given node
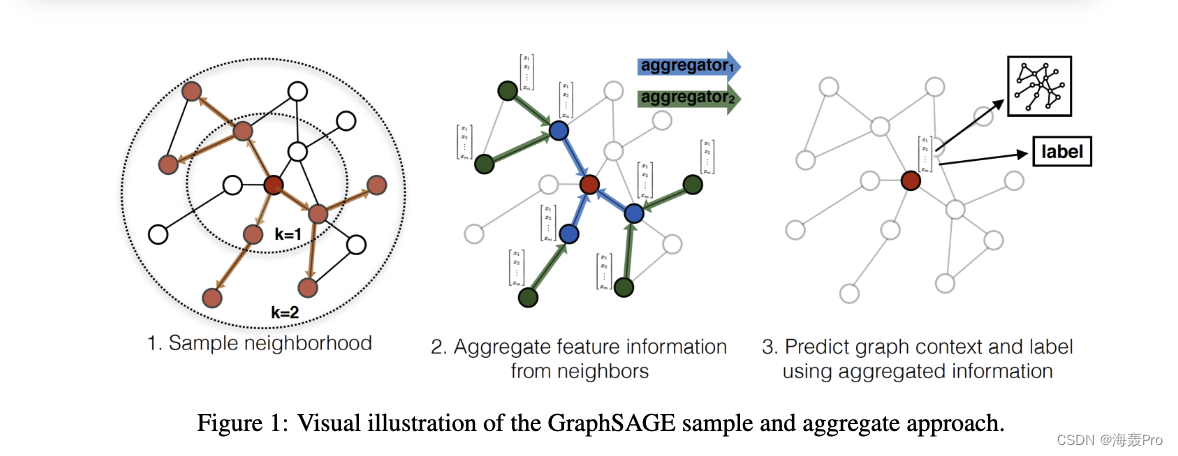
When testing or reasoning , We use our training system to generate completely invisible node embeddedness by applying the learned aggregation function
Based on the previous work on generating node embedding , We designed a Unsupervised loss function
This function allows you to monitor GraphSAGE Training
We also show that ,GraphSAGE You can train in a fully supervised way
2 Related work
Our algorithm is conceptually similar to the previous node embedding method 、 The general methods of learning on graphs are related to supervised methods and the latest progress in the application of convolutional neural networks to graph structured data
Embedding method based on factorization
Recently, many node embedding methods use random walk statistics and learning objectives based on matrix decomposition to learn low dimensional embedding [5,11,28,35,36]
These methods are also related to the more classical spectral clustering [23]、 Multidimensional scaling [19] as well as PageRank Algorithm [25] There is a close relationship
Because these embedding algorithms directly train the node embedding of each node , So they are conductive in nature , And at least expensive additional training ( for example , Descend by random gradient ) To predict new nodes
Besides , For many of these methods ( for example ,[11,28,35,36]), The objective function is invariant to the embedded orthogonal transformation , This means that the embedding space will not be naturally generalized between graphs , And may drift during retraining
An obvious exception to this trend is by Yang Et al Planetid-I Algorithm .[40] This is based on induction 、 Embedded semi supervised learning method
However ,Planetid-I No graphic structure information is used in the reasoning process ; contrary , It uses graph structure as regularization form during training
Different from previous methods , We use feature information to train the model , To generate embeddedness for invisible nodes
Supervised learning on the picture
In addition to the node embedding method , There is also a large number of literature on supervised learning on graph structured data
This includes a variety of kernel based methods , The eigenvectors of graphs are derived from various graph cores ( See [32] And its references )
Recently, there are also some neural network methods for supervised learning on graph structure [7,10,21,31]
Our method is conceptually inspired by many such algorithms
However , Although these previous methods try to apply to the whole graph ( Or subgraph ) To classify , But the focus of this work is to generate useful representations for a single node
Figure convolution network
In recent years , Several convolutional neural network structures for graph learning have been proposed ( for example ,[4,9,8,17,24])
Most of these methods are not suitable for large graphs or designed for full graph classification ( Or both )[4、9、8、24]
However , Our method and Kipf Graph convolution network proposed by et al (GCN) Is closely related to the [17,18]
The original GCN Algorithm [17] It is designed for semi supervised learning in a transformational environment , And the precise algorithm requires to know the complete graph Laplace in the training process
A simple variant of our algorithm can be considered GCN Extension of framework to inductive environment , We are 3.3 This is revisited in section .
3 Proposed method: GraphSAGE
The key idea behind our approach is : Learn how to aggregate feature information from the local neighborhood of a node ( for example , Degrees or text attributes of nearby nodes )
- First describe GraphSAGE Embedded generation ( It's forward propagation ) Algorithm , The algorithm is assumed to have been learned GraphSAGE Generate embedding for nodes in the case of model parameters (3.1 section )
- then , We describe how to use standard random gradient descent and back propagation techniques to learn GraphSAGE Model parameters ( The first 3.2 section ).
3.1 Embedding generation (i.e., forward propagation) algorithm
In this section , We describe embedded generation or forward propagation algorithms ( Algorithm 1), It assumes that the model has been trained and the parameters are fixed

To be specific , We assume that we have learned K K K Parameters of aggregator functions
Write it down as A G G R E G A T E k , ∀ k ∈ 1 , . . . , K AGGREGATE_k,∀k∈{1,...,K} AGGREGATEk,∀k∈1,...,K
They gather information from node neighbors , And a set of weight matrices W k , ∀ k ∈ 1 , . . . , K W^k,∀k∈{1,...,K} Wk,∀k∈1,...,K
They are used between different layers of the model or “ Search depth ” Spread information between
The first 3.2 Section describes how to train these parameters
Algorithm 1 The intuition behind it is , At each iteration or search depth , Nodes collect information from their local neighbors
also With the iteration of this process , Nodes gradually get more and more information from the farther range of the graph
Algorithm 1 Describes the whole diagram provided G = ( V , E ) G=(V,E) G=(V,E) And the characteristics of all nodes X v X_v Xv、 ∀ v ∈ V ∀v∈V ∀v∈V Embedded generation process in the case of input
We will describe how to generalize it to the following small batch settings
Algorithm 1 Each step in the outer ring of is as follows , among
- k k k Represents the current step in the outer ring ( Or search depth )
- h k h^k hk Indicates that the node in this step indicates
First , Every node v ∈ V v∈V v∈V Gather representations of nodes in their immediate neighborhood , h u k − 1 , ∀ u ∈ N ( v ) {h^{k-1}_u,∀u∈N(v)} huk−1,∀u∈N(v), Into a single carrier h N ( v ) k − 1 h^{k-1}_{N(v)} hN(v)k−1
Be careful , This aggregation step depends on the representation generated at the previous iteration of the external loop ( namely , k − 1 k−1 k−1), also k = 0 k=0 k=0( Basic information ) The representation is defined as the input node feature
After aggregating adjacent eigenvectors ,GraphSAGE then The current representation of the node h v k − 1 h^{k-1}_v hvk−1 And the aggregated neighborhood vector h N ( v ) k − 1 h^{k-1}_{N(v)} hN(v)k−1 Connect
And the connected vector has a nonlinear activation function σ σ σ Fully connected layer feed , The representation whose transformation will be used in the next step of the algorithm ( namely , h v k , ∀ v ∈ V h^k_v,∀v∈V hvk,∀v∈V)
For the convenience of symbols , We'll go deep K K K The final representation of the output at is expressed as z v ≡ h v k , ∀ v ∈ V z_v≡ h^k_v,∀v∈V zv≡hvk,∀v∈V
The aggregation of neighbor representation can be achieved through various aggregator architectures ( By algorithm 1 Medium AGGREGATE Placeholders represent ) To complete
We'll be in the next 3.3 Different architectural choices are discussed in section
In order to put the algorithm 1 Expand to small batch settings
Given a set of input nodes , We first set the required neighborhood ( Up to depth K K K) Forward sampling
Then run the inner loop ( Algorithm 1 No 3 That's ok ), But we don't iterate over all nodes , Instead, only the representation required to satisfy recursion at each depth is computed ( appendix A Contains complete small batch pseudocode )
Relation to the Weisfeiler-Lehman Isomorphism Test
GraphSAGE The concept of algorithm Inspired by the classical algorithm of test graph isomorphism
If it's in the algorithm 1 in
- (i) Set up K = ∣ V ∣ K=|V| K=∣V∣
- (Ii) Set the weight matrix as the unit
- (iii) Use the appropriate hash function as the aggregator ( No nonlinearity )
Then algorithm 1 yes Weisfeler-Lehman(WL) An example of isomorphism testing , Also known as “ Simplicity and refinement ”[32]
If the algorithm 1 The representation set output for the two subgraphs { z v , ∀ v ∈ V } \{z_v,∀v∈V\} { zv,∀v∈V} identical , be WL The test declares that the two subgraphs are isomorphic
as everyone knows , This test will fail in some cases , But it is effective for large class diagrams [32]
GraphSAGE yes WL Continuous approximation of the test , stay WL In the test , We replace the hash function with a trainable neural network aggregator
Of course , We use GraphSAGE To generate useful node representations – Instead of testing graph isomorphism
However ,GraphSAGE And classic WL The connection between tests provides a theoretical background for our algorithm design to learn the topology of the neighborhood of nodes
Neighborhood definition
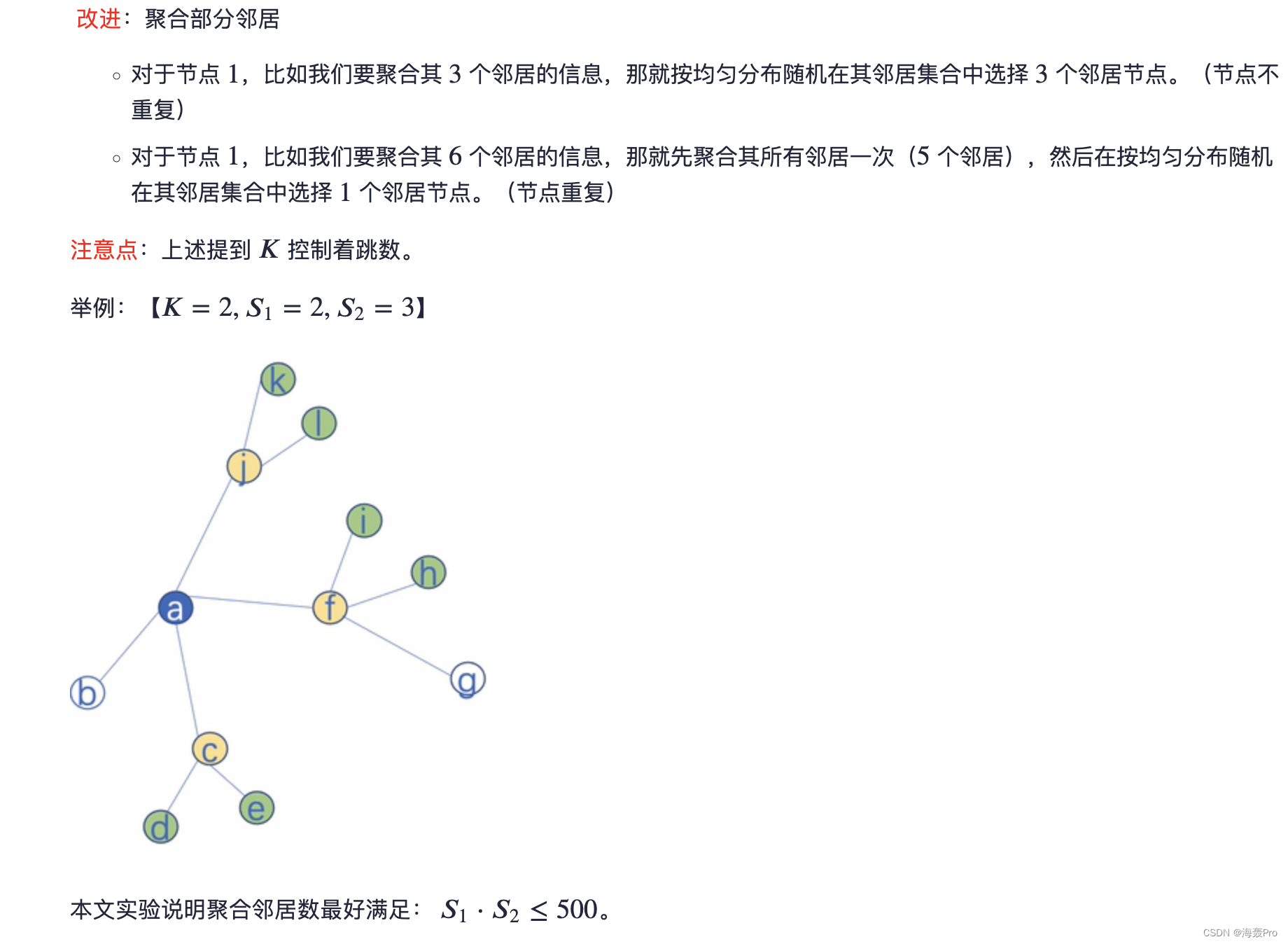
In this work , We uniformly sample a fixed size set of neighborhoods , Instead of using algorithms 1 Complete neighborhood set in , To keep the calculation space of each batch fixed
in other words , Use overloaded notation , We will N ( v ) N(v) N(v) Defined as from set u ∈ V : ( U , v ) ∈ E {u∈V:(U,v)∈E} u∈V:(U,v)∈E Uniform extraction of fixed size in , And in the algorithm 1 Each iteration in k k k Take different uniform samples at
Without this sampling , The memory and expected run time of a single batch are unpredictable , In the worst case O ( ∣ V ∣ ) O(|V|) O(∣V∣)
contrary ,GraphSAGE The space and time complexity of each batch is fixed as O ( ∏ i = 1 K S i ) O(∏^K_{i=1}S_i) O(∏i=1KSi), among S i , i ∈ 1 , . . . , K S_i,i∈{1,...,K} Si,i∈1,...,K and K K K Is a user specified constant
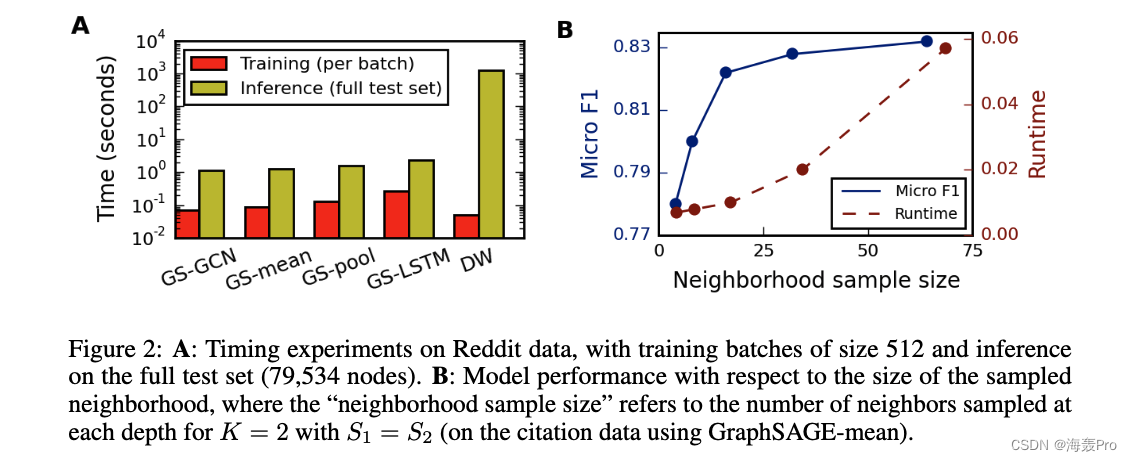
actually , We found that our method can be used in K = 2 K=2 K=2 and S 1 ⋅ S 2 ≤ 500 S1·S2≤500 S1⋅S2≤500 Get high performance ( For more information , Please refer to No 4.4 section ).
3.2 Learning the parameters of GraphSAGE
In order to learn useful predictive representations in a completely unsupervised environment
We apply the graph based loss function to The output represents z u , ∀ u ∈ V z_u,∀u∈V zu,∀u∈V, And adjust the weight matrix through random gradient descent W k , ∀ k ∈ 1 , . . . , K W^k,∀k∈{1,...,K} Wk,∀k∈1,...,K And the parameters of the aggregator function
Graph based loss functions encourage nearby nodes to have similar representations , At the same time, the representation height of different nodes is forced to be different :
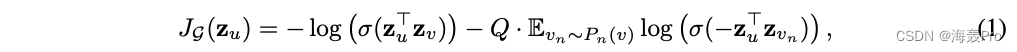
among
- v v v It's a fixed length random walk on u u u Nearby common nodes
- σ σ σ yes Sigmoid function
- P n P_n Pn Is the negative sampling distribution
- Q Q Q Defines the number of negative samples
It is important to , Different from previous embedding methods , We feed... To this loss function Express z u z_u zu It is generated from the features contained in the local neighborhood of the node , instead of ( Find by embedding ) Train unique embeddedness for each node
This unsupervised setting simulates providing node functions as services or in a static repository to downstream machine learning applications
In the case of indicating that it is only used for specific downstream tasks , You can simply use task specific goals ( for example , Cross entropy loss ) To replace or increase unsupervised losses ( The formula 1)
3.3 Aggregator Architectures
And N-D grid ( for example , The sentence 、 Image or 3-D Volume ) Machine learning on is different , The neighbors of nodes have no natural order
therefore , Algorithm 1 The aggregator function in must operate on an unordered set of vectors
Ideally , Aggregator functions should be symmetric ( namely , Does not vary with the arrangement of its inputs ), At the same time, it is still trainable , And maintain high presentation ability
The symmetry of the aggregation function ensures that our neural network model can be trained and applied to arbitrarily ordered node neighborhood feature sets
We studied three candidate aggregator functions :
Mean aggregator
Our first candidate aggregator function is the average operator , We only take { h u k − 1 , ∀ u ∈ N ( v ) } \{h^{k-1}_u,∀u∈N(v)\} { huk−1,∀u∈N(v)} The average of the elements of the vector in
The average aggregator is almost equivalent to conducting GCN Convolution propagation rules used in the framework [17]
To be specific , We can use the algorithm 1 No 4 Xing He 5 Replace the line with the following to export GCN Inductive variants of methods :
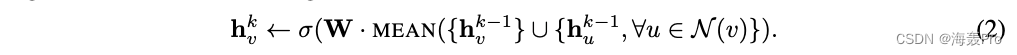
We call this modified The mean based aggregator is convolution , Because it is a rough linear approximation of local spectral convolution [17]
An important difference between this convolution aggregator and other aggregators we proposed is , It does not execute algorithms 1 The first 5 Cascading operations in rows
namely , The convolution aggregator does represent the previous layer of the node h v k − 1 h^{k-1}_v hvk−1 And the neighborhood vector of the aggregation h N ( v ) k h^k_{N(v)} hN(v)k cascade
This series connection can be regarded as GraphSAGE Different algorithms “ Search depth ” or “ layer ” Between “ Skip the connection ”[13] In a simple form , And it leads to significant performance improvements ( The first 4 section )
LSTM aggregator
We also studied a model based on LSTM More complex aggregators for architecture [14]
Compared with mean aggregator ,LSTM It has the advantage of stronger expression ability
However , The important thing is to pay attention ,LSTM Itself is not asymmetric ( namely , They are not arranged invariably ), Because they process their input in a sequential manner
By simply putting LSTM Applied to the random arrangement of node neighbors , We make LSTM Suitable for operating on unordered sets
Pooling aggregator
The final aggregator we studied is symmetric , It's also trainable
In this pooling method , The vector of each neighbor is fed independently through a fully connected neural network
After this conversion , Apply the basic maximum pooling operation to aggregate the information in the neighbor set :
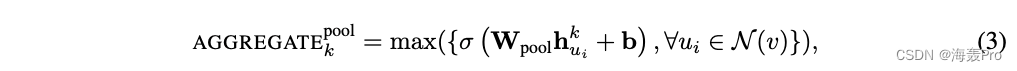
among
- max Represents element based max operator
- and σ Represents the nonlinear activation function
In principle, , The function applied before the maximum merging can be a multilayer perceptron of any depth , But in this article, we mainly focus on simple single-layer architecture
The inspiration of this method comes from the recent progress in applying neural network structure to learn general point sets [29]
Intuitively speaking , Multilayer perceptron can be considered as a set of functions that represent computational characteristics for each node in the neighbor set
By applying the maximum pooling operator to each calculated feature , The model effectively captures different aspects of neighborhood set
Also pay attention to , In principle, , You can use any symmetric vector function instead of the maximum operator ( for example , The average value of the element formula )
We didn't find Significant difference between maximum pooling and average pooling , Therefore, in the rest of our experiments, we focus on maximum pooling
4 Experiments
4.1 Inductive learning on evolving graphs: Citation and Reddit data && 4.2 Generalizing across graphs: Protein-protein interactions
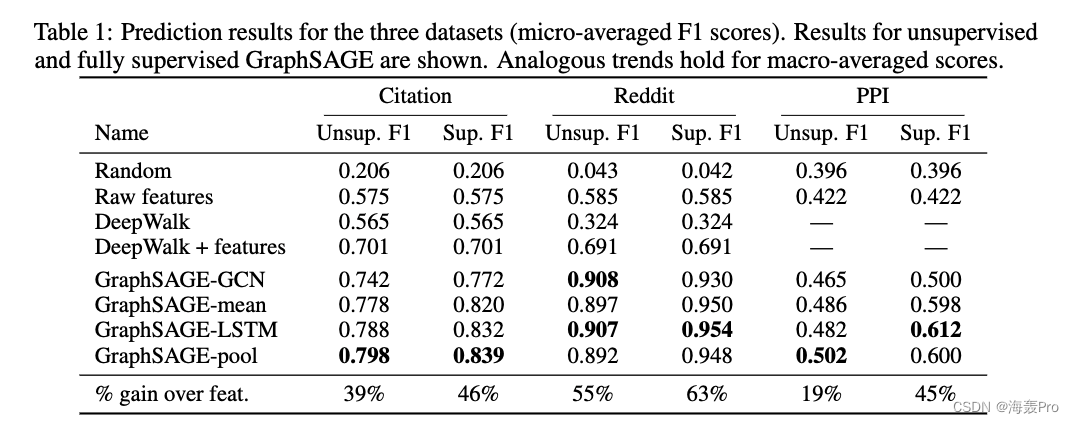
4.3 Runtime and parameter sensitivity
5 Theoretical analysis
A little
6 Conclusion
We introduced a new method , It can effectively generate embedding for invisible nodes
GraphSAGE Always better than the most advanced benchmark , The performance and running time are effectively balanced by sampling node neighbors , Our theoretical analysis provides insight into how our method understands the structure of this map
Many extensions and potential improvements are possible , For example, expand GraphSAGE To merge directed graphs or multimode graphs
A particularly interesting direction of future work is to explore non-uniform neighborhood sampling functions , It is even possible to use these functions as GraphSAGE Optimize part of learning
After reading the summary
I read this article in the afternoon honestly
I didn't understand it ha-ha
I have to read it carefully again !
Think with the help of others' blogs
- source :https://www.cnblogs.com/BlairGrowing/p/15439876.html





After reading it, I understand a little
I still don't understand the details …
Ah Take some time to read it again
Conclusion
The article is only used as a personal study note , Record from 0 To 1 A process of
Hope to help you a little bit , If you have any mistakes, you are welcome to correct them

边栏推荐
- FLIR blackfly s usb3 industrial camera: white balance setting method
- 3D laser slam: time synchronization of livox lidar hardware
- 6 seconds to understand the book to the Kindle
- ROS learning (22) TF transformation
- How to use strings as speed templates- How to use String as Velocity Template?
- Stm32f4 --- PWM output
- 组合导航:中海达iNAV2产品描述及接口描述
- 处理streamlit库上传的图片文件
- MetaForce原力元宇宙开发搭建丨佛萨奇2.0系统开发
- Unicode string converted to Chinese character decodeunicode utils (tool class II)
猜你喜欢
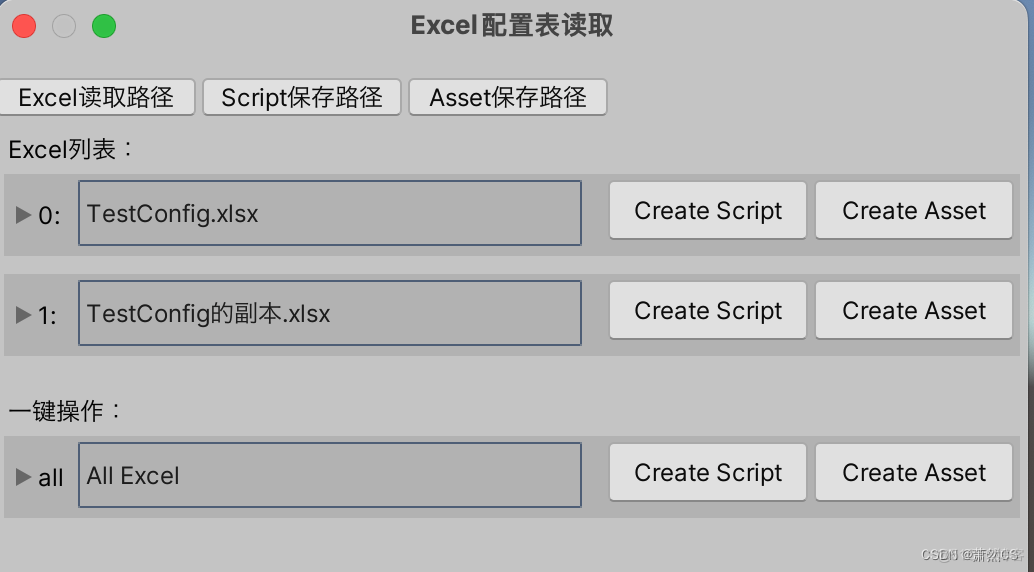
【Unity】升级版·Excel数据解析,自动创建对应C#类,自动创建ScriptableObject生成类,自动序列化Asset文件
Livox激光雷达硬件时间同步---PPS方法

FLIR blackfly s usb3 industrial camera: how to use counters and timers
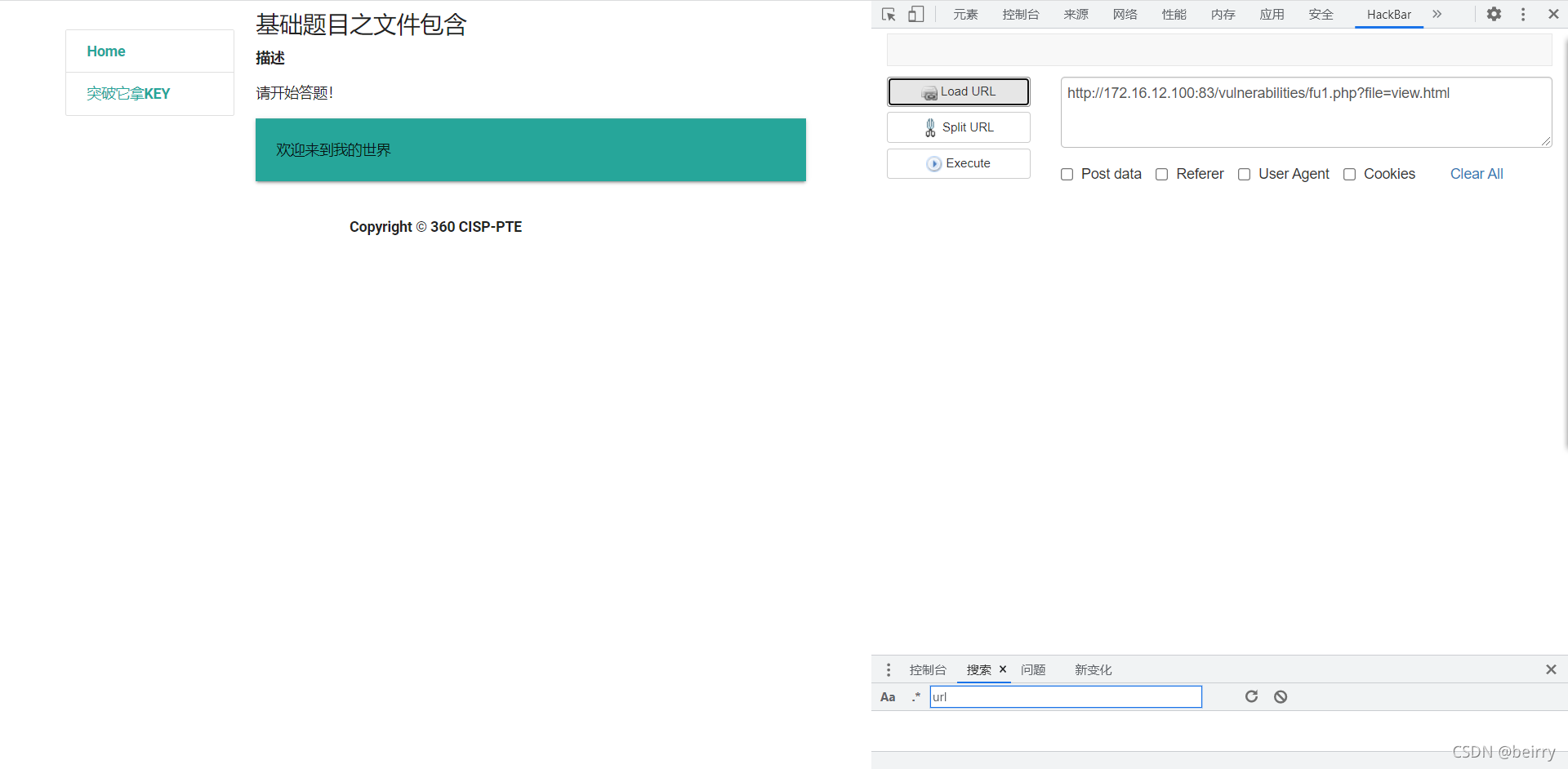
CISP-PTE实操练习讲解(二)

Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
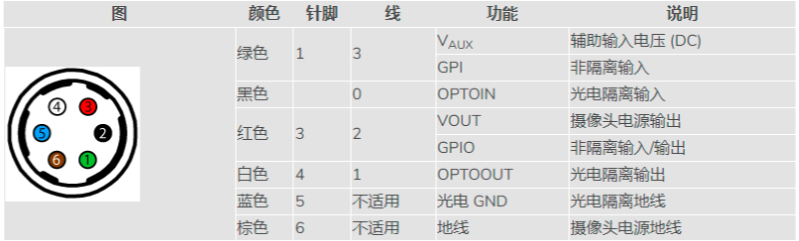
Flir Blackfly S 工业相机:配置多个摄像头进行同步拍摄

Correct use of BigDecimal
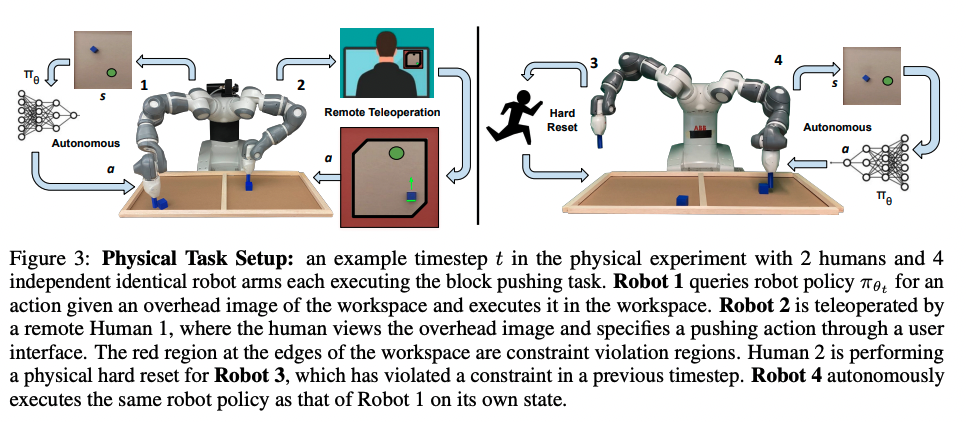
机器人队伍学习方法,实现8.8倍的人力回报
SchedulX V1.4.0及SaaS版发布,免费体验降本增效高级功能!

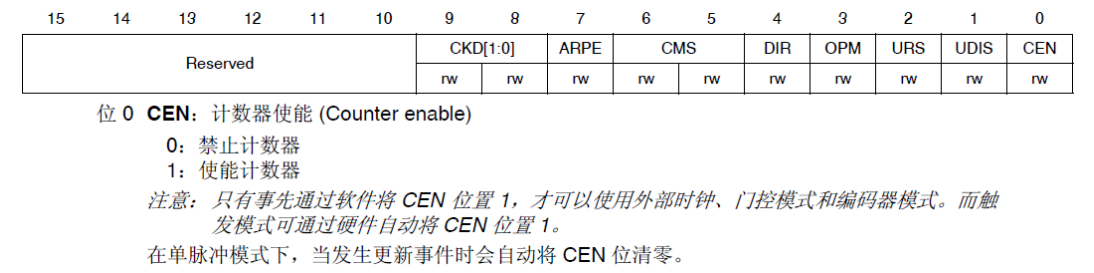
STM32F4---PWM输出
随机推荐
解密函数计算异步任务能力之「任务的状态及生命周期管理」
Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
老板被隔离了
Errors made in the development of merging the quantity of data in the set according to attributes
长安链学习笔记-证书研究之证书模式
ROS学习(十九)机器人SLAM功能包——cartographer
Make DIY welding smoke extractor with lighting
2022/0524/bookstrap
Zabbix 5.0:通过LLD方式自动化监控阿里云RDS
Shortcut keys commonly used in idea
ROS learning (23) action communication mechanism
STM32F4---PWM输出
CISP-PTE实操练习讲解(二)
3D laser slam: time synchronization of livox lidar hardware
低代码平台中的数据连接方式(上)
How to use strings as speed templates- How to use String as Velocity Template?
FLIR blackfly s industrial camera: auto exposure configuration and code
Get to know MySQL for the first time
CISP-PTE之命令注入篇
最近小程序开发记录